Three challenges in machine-based reasoning
Translating from natural to structured language, defining truth, and definitive reasoning remain topics of central concern in automated reasoning, but Amazon Web Services new Automated Reasoning checks help address all of them.
Automated reasoning
Byron CookAugust 04, 02:02 PMAugust 04, 02:02 PM
Generative AI has made the past few years the most exhilarating time in my 30+-year career in the space of mechanized reasoning. Why? Because the computer industry and even the general public are now eager to talk about ideas that those of us working in logic have been passionate about for years. The challenges of language, syntax, semantics, validity, soundness, completeness, computational complexity, and even undecidability were previously too academic and obscure to be relevant to the masses. But all of that has changed. To those of you who are now discovering these topics: welcome! Step right in, were eager to work with you.
I thought it would be useful to share what I believe are the three most vexing aspects of making correct reasoning work in AI systems, e.g., generative-AI-based systems such as chatbots. The upcoming launch of the Automated-Reasoning-checks capability in Bedrock Guardrails was in fact motivated by these challenges. But we are far from done: due to the inherent difficulty of these problems, we as a community (and we on the Automated-Reasoning-checks team) will be working on these challenges for years to come.
Difficulty #1: Translating from natural to structured language
Humans usually communicate with imprecise and ambiguous language. Often, we are able to infer disambiguating detail from context. In some cases, when it really matters, we will try to clarify with each other (did you mean to say… ?). In other cases, even when we really should, we wont.
This is often a source of confusion and conflict. Imagine that an employer defines eligibility for an employee HR benefit as having a contract of employment of 0.2 full-time equivalent (FTE) or greater. Suppose I tell you that I spend 20% of my time at work, except when I took time off last year to help a family member recover from surgery. Am I eligible for the benefit? When I said I spend 20% of my time at work, does that mean I am spending 20% of my working time, under the terms of a contract?
My statement has multiple reasonable interpretations, each with different outcomes for benefit eligibility. Something we do in Automated Reasoning checks is make multiple attempts to translate between the natural language and query predicates, using complementary approaches. This is a common interview technique: ask for the same information in different ways, and see if the facts stay consistent. In Automated Reasoning checks, we use solvers for formal logic systems to prove/disprove the equivalence of the different interpretations. If the translations differ at the semantic level, the application that uses Automated Reasoning checks can then ask for clarifications (e.g. Can you confirm that you have a contract of employment for 20% of full time or greater?).
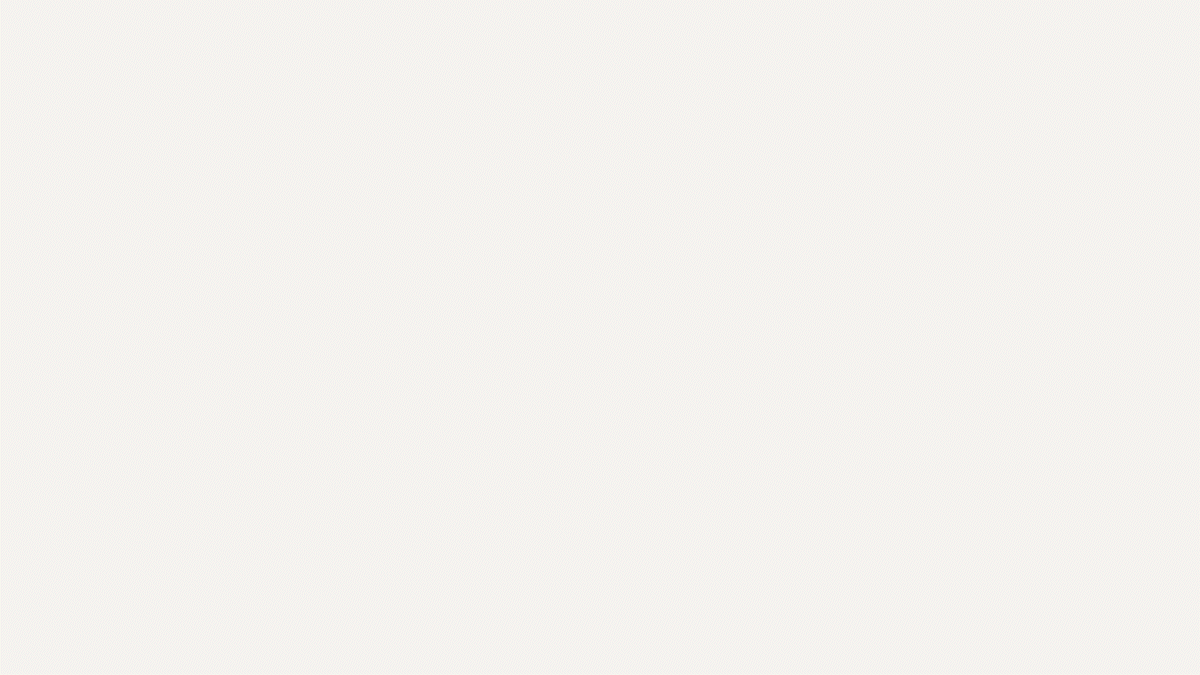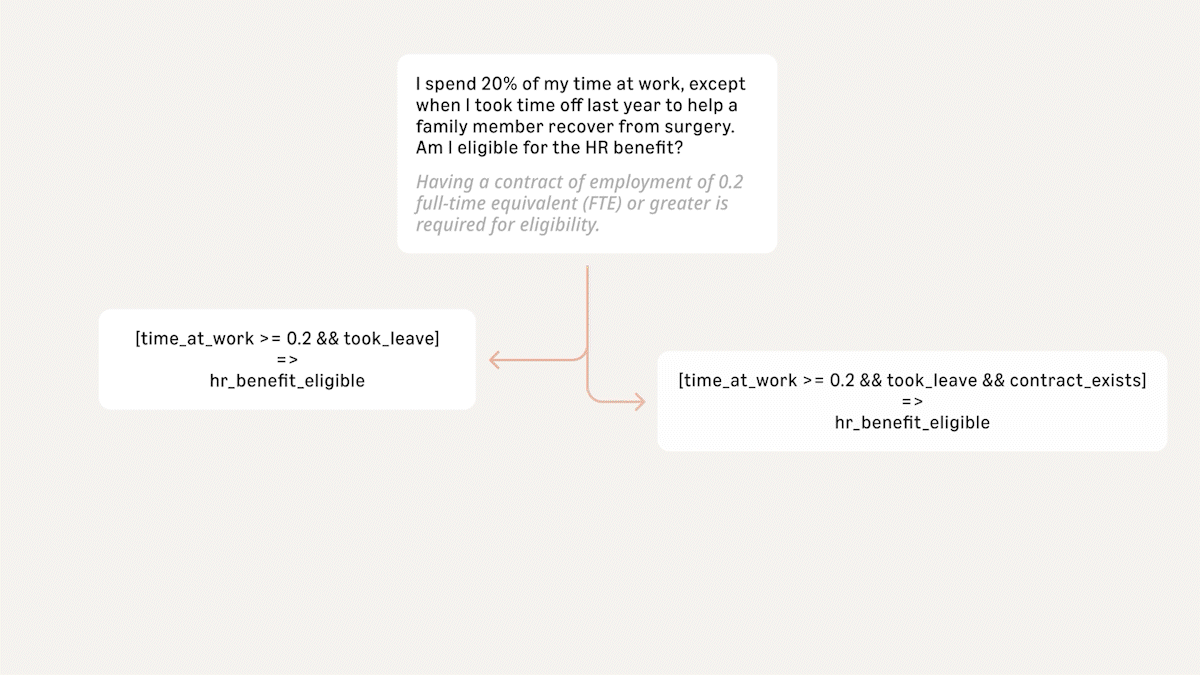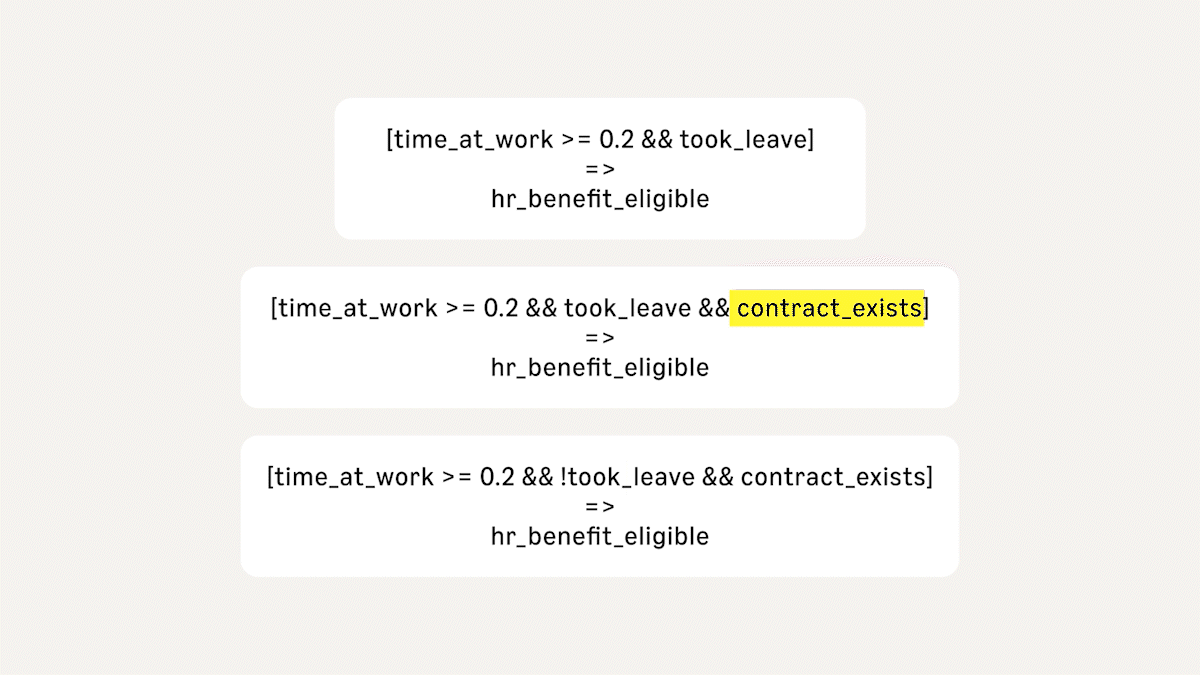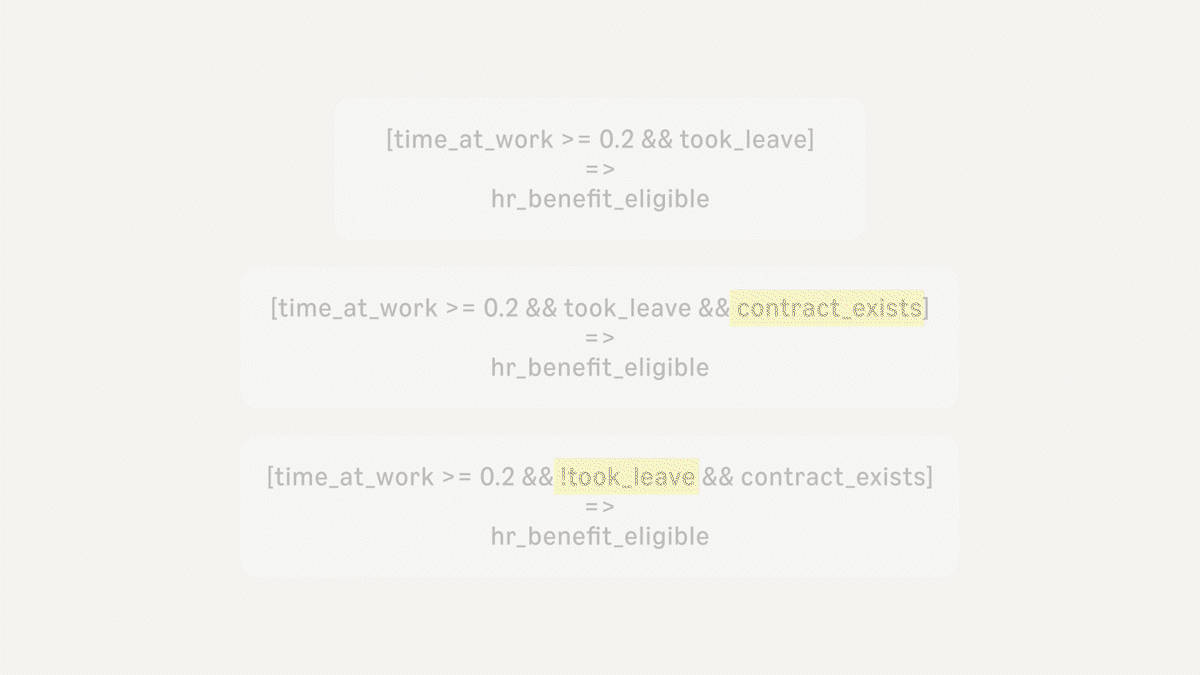
Difficulty #2: Defining truth
Something that never fails to amaze me is how difficult it is for groups of people to agree on the meanings of rules. Complex rules and laws often have subtle contradictions that can go unnoticed until someone tries to reach consensus on their interpretation. The United Kingdoms Copyrights, Designs, and Patents Act of 1988, for example, contains an inherent contradiction: it defines copyrightable works as those stemming from an authors original intellectual creation, while simultaneously offering protection to works that require no creative human input an incoherence that is particularly glaring in this age of AI-generated works.
The second source of trouble is that we seem to always be changing our rules. The US federal governments per-diem rates, for example, change annually, requiring constant maintenance of any system that depends on those values.
Finally, few people actually deeply understand all of the corner cases of the rules that they are supposed to abide by. Consider the question of wearing earphones while driving: In some US states (e.g., Alaska) its illegal; in some states (e.g., Florida) its legal to wear one earphone only; while in other states (e.g., Texas), its actually legal. In an informal poll, very few of my friends and colleagues were confident in their understanding of the legality of wearing headphones while driving in the place where they most recently drove a car.
Automated Reasoning checks address these challenges by helping customers define what the truth should be in their domains of interest be they tax codes, HR policies, or other rule systems and by providing mechanisms for refining those definitions over time, as the rules change. As generative-AI-based (GenAI-based) chatbots emerged, something that captured the imagination of many of us is the idea that complex rule systems could be made accessible to the general public through natural-language queries. Chatbots could in the future give direct and easy-to-understand answers to questions like Can I make a U-turn when driving in Tokyo, Japan?, and by addressing the challenge of defining truth, Automated Reasoning checks can help ensure that the answer is reliable.

Difficulty #3: definitive reasoning
Imagine we have a set of rules (lets call it R) and a statement (S) we want to verify. For example, R might be Singapores driving code, and S might be a question about U-turns at intersections in Singapore. We can encode R and S into Boolean logic, which computers understand, by combining Boolean variables in various ways.
Lets say that encoding R and S needs just 500 bits about 63 characters. This is a tiny amount of information! But even when our encoding of the rule system is small enough to fit in a text message, the number of scenarios wed need to check is astronomical. In principle, we must consider all 2
500
possible combinations before we can authoritatively declare S to be a true statement. A powerful computer today can perform hundreds of millions of operations in the time it takes you to blink. But even if we had all the computers in the world running at this blazing speed since the beginning of time, we still wouldnt be close to checking all 2
500
possibilities today.
Thankfully, the automated-reasoning community has developed a class of sophisticated tools, called SAT solvers, that make this type of combinatorial checking possible and remarkably fast in many (but not all) cases. Automated Reasoning checks make use of these tools when checking the validity of statements.
Unfortunately, not all problems can be encoded in a way that plays to the strengths of SAT solvers. For example, imagine a rule system has the provision if every even number greater than 2 is the sum of two prime numbers, then the tax withholding rate is 30%; otherwise its 40%. The problem is that to know the tax withholding rate, you need to know whether every even number greater than 2 is the sum of two prime numbers, and no one currently knows whether this is true. This statement is called Goldbachs conjecture and has been an open problem since 1742. Still, while we dont know the answer to Goldbachs conjecture, we do know that it is either true or false, so we can definitively say that the tax withholding rate must be either 30% or 40%.
It’s also fun to think about whether its possible for a customer of Automated Reasoning checks to define a policy that is contingent on the output of Automated Reasoning checks. For instance, could the policy encode the rule access is allowed if and only if Automated Reasoning checks say it is not allowed? Here, no correct answer is possible, because the rule has created a contradiction by referring recursively to its own checking procedure. The best we can possibly do is answer Unknown (which is, in fact, what Automated Reasoning checks will answer in this instance).
The fact that a tool such as Automated Reasoning checks can return neither true nor false to statements like this was first identified by Kurt Gdel in 1931. What we know from Gdels result is that systems like Automated Reasoning checks cant be both consistent and complete, so they must choose one. We have chosen to be consistent.
These three difficulties translating natural language into structured logic, defining truth in the context of ever changing and sometimes contradictory rules, and tackling the complexity of definitive reasoning are more than mere technical hurdles we face when we try to build AI systems with sound reasoning. They are problems that are deeply rooted in both the limitations of our technology and the intricacies of human systems.
With the forthcoming launch of Automated Reasoning checks in Bedrock Guardrails, we are tackling these challenges through a combination of complementary approaches: applying cross-checking methods to translate from ambiguous natural language to logical predicates, providing flexible frameworks to help customers develop and maintain rule systems, and employing sophisticated SAT solvers while carefully handling cases where definitive answers are not possible. As we work to improve the performance of the product on these challenges, we are not only advancing technology but also deepening our understanding of the fundamental questions that have shaped reasoning itself, from Gdels incompleteness theorem to the evolving nature of legal and policy frameworks.
Given our commitment to providing sound reasoning, the road ahead in the AI space is challenging. Challenge accepted!
Research areas: Automated reasoning, Conversational AI
Tags: Code generation, Responsible AI , Generative AI