Example of embodied commonsense reasoning. A robot proactively identifies a remote on the floor and knows it is out of place without instruction. Then, the robot figures out where to place it in the scene and manipulates it there.
For robots to operate effectively in the world, they should be more than explicit step-by-step instruction followers. Robots should take actions in situations when there is a clear violation of the normal circumstances and be able to infer relevant context from partial instruction. Consider a situation where a home robot identifies a remote control which has fallen to the kitchen floor. The robot should not need to wait until a human instructs the robot to “pick the remote control off the floor and place it on the coffee table”. Instead, the robot should understand that the remote on the floor is clearly out of place, and act to pick it up and place it in a reasonable location. Even if a human were to spot the remote control first and instruct the agent to “put away the remote that is on the living room floor”, the robot should not require a second instruction for where to put the remote, but instead infer from experience that a reasonable location would be, for example, on the coffee table. After all, it would become tiring for a home robot user to have to specify every desire in excruciating detail (think about for each item you want the robot to move, specifying an instruction such as “pick up the shoes beneath the coffee table and place them next to the door, aligned with the wall”).
The type of reasoning that would permit such partial or self-generated instruction following involves a deep sense of how things in the world (objects, physics, other agents, etc.) ought to behave. Reasoning and acting of this kind are all aspects of embodied commonsense reasoning and are vastly important for robots to act and interact seamlessly in the physical world.
There has been much work on embodied agents that follow detailed step-by-step instructions, but less on embodied commonsense reasoning, where the task involves learning how to perceive and act without explicit instruction. One task in which to study embodied commonsense reasoning is that of tidying up, where the agent must identify objects which are out of their natural locations and act in order bring the identified objects to plausible locations. This task combines many desirable capabilities of intelligent agents with commonsense reasoning of object placements. The agent must search in likely locations for objects to be displaced, identify when objects are out of their natural locations in the context of the current scene, and figure out where to reposition the objects so that they are in proper locations – all while intelligently navigating and manipulating.
In our recent work, we propose TIDEE, an embodied agent that can tidy up never-before-seen rooms without any explicit instruction. TIDEE is the first of its kind for its ability to search a scene for out of place objects, identify where in the scene to reposition the out of place objects, and effectively manipulate the objects to the identified locations. We’ll walk through how TIDEE is able to do this in a later section, but first let’s describe how we create a dataset to train and test our agent for the task of tidying up.
Creating messy homes
To create clean and messy scenes for our agent to learn from for what constitutes a tidy scene and what constitute a messy scene, we use a simulation environment called ai2thor. Ai2thor is an interactive 3D environment of indoor scenes that allows objects to be picked up and moved around. The simulator comes ready with 120 scenes of kitchens, bathrooms, living rooms, and bedrooms with over 116 object categories (and significantly more object instances) scattered throughout. Each of the scenes comes with a default initialization of object placements that are meticulously chosen by humans to be highly structured and “neat”. These default object locations make up our “tidy” scenes for providing our agent examples of objects in their natural locations. To create messy scenes, we apply forces to a subset of the objects with a random direction and magnitude (we “throw” the objects around) so they end up in uncommon locations and poses. You can see below some examples of objects which have been moved out of place.

Next, let’s see how TIDEE learns from this dataset to be able to tidy up rooms.
How does TIDEE work?
We give our agent a depth and RGB sensor to use for perceiving the scene. From this input, the agent must navigate around, detect objects, pick them up, and place them. The goal of the tidying task is to rearrange a messy room back to a tidy state.
TIDEE tidies up rooms in three phases. In the first phase, TIDEE explores around the room and runs an out of place object detector at each time step until one is identified. Then, TIDEE navigates over to the object, and picks it up. In the second phase, TIDEE uses graph inference in its joint external graph memory and scene graph to infer a plausible receptacle to place the object on within the scene. It then explores the scene guided by a visual search network that suggests where the receptacle may be found if TIDEE has not identified it in a previous time step. For navigation and keeping track objects, TIDEE maintains a obstacle map of the scene and stores in memory the estimated 3D centroids of previously detected objects.

The out of place detector uses visual and relational language features to determine if an object is in or out of place in the context of the scene. The visual features for each object are obtained from an off-the-shelf object detector, and the relational language features are obtained by giving predicted 3D relations of the objects (e.g. next to, supported by, above, etc.) to a pretrained language model. We combine the visual and language features to classify whether each detected object is in or out of place. We find that combining the visual and relational modalities performs best for out of place classification over using a single modality.

To infer where to place an object once it has picked up, TIDEE includes a neural graph module which is trained to predict plausible object placement proposals of objects. The modules works by passing information between the object to be placed, a memory graph encoding plausible contextual relations from training scenes, and a scene graph encoding the object-relation configuration in the current scene. For our memory graph, we take inspiration from “Beyond Categories: The Visual Memex Model for Reasoning About Object Relationships” by Tomasz Malisiewicz and Alexei A. Efros (2009), which models instance-level object features and their relations to provide more complete appearance-based context. Our memory graph consists of the tidy object instances in the training to provide fine-grain contextualization of tidy object placements. We show in the paper that this fine-grain visual and relational information is important for TIDEE to place objects in human-preferred locations.

To search for objects that have not been previously found, TIDEE uses a visual search network that takes as input the semantic obstacle map and a search category and predicts the likelihood of the object being present at each spatial location in the obstacle map. The agent then searches in those likely locations for the object of interest.
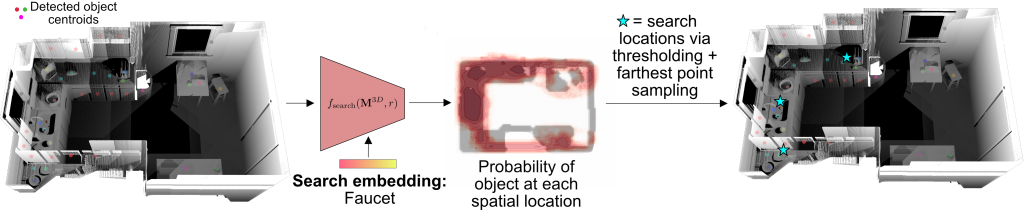
Combining all the above modules provides us with a method to be able to detect out of place objects, infer where they should go, search intelligently, and navigate & manipulate effectively. In the next section, we’ll show you how well our agent performs at tidying up rooms.
How good is TIDEE at tidying up?

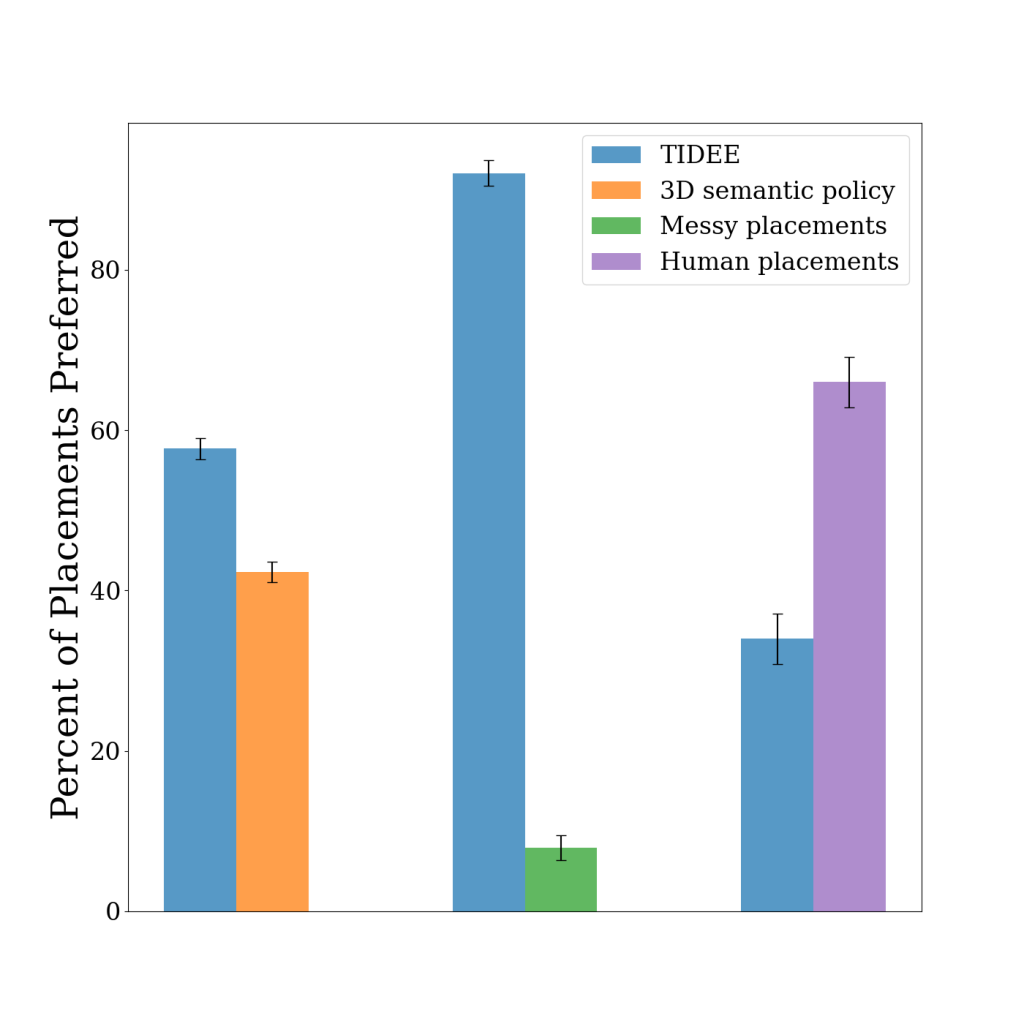
Using a set of messy test scenes that TIDEE has never seen before, we task our agent with reconfiguring the messy room to a tidy state. Since a single object may be tidy in multiple locations within a scene, we evaluate our method by asking humans whether they prefer the placements of TIDEE compared to baseline placements that do not make use of one or more of TIDEE’s commonsense priors. Below we show that TIDEE placements are significantly preferred to the baseline placements, and even competitive with human placements (last row).
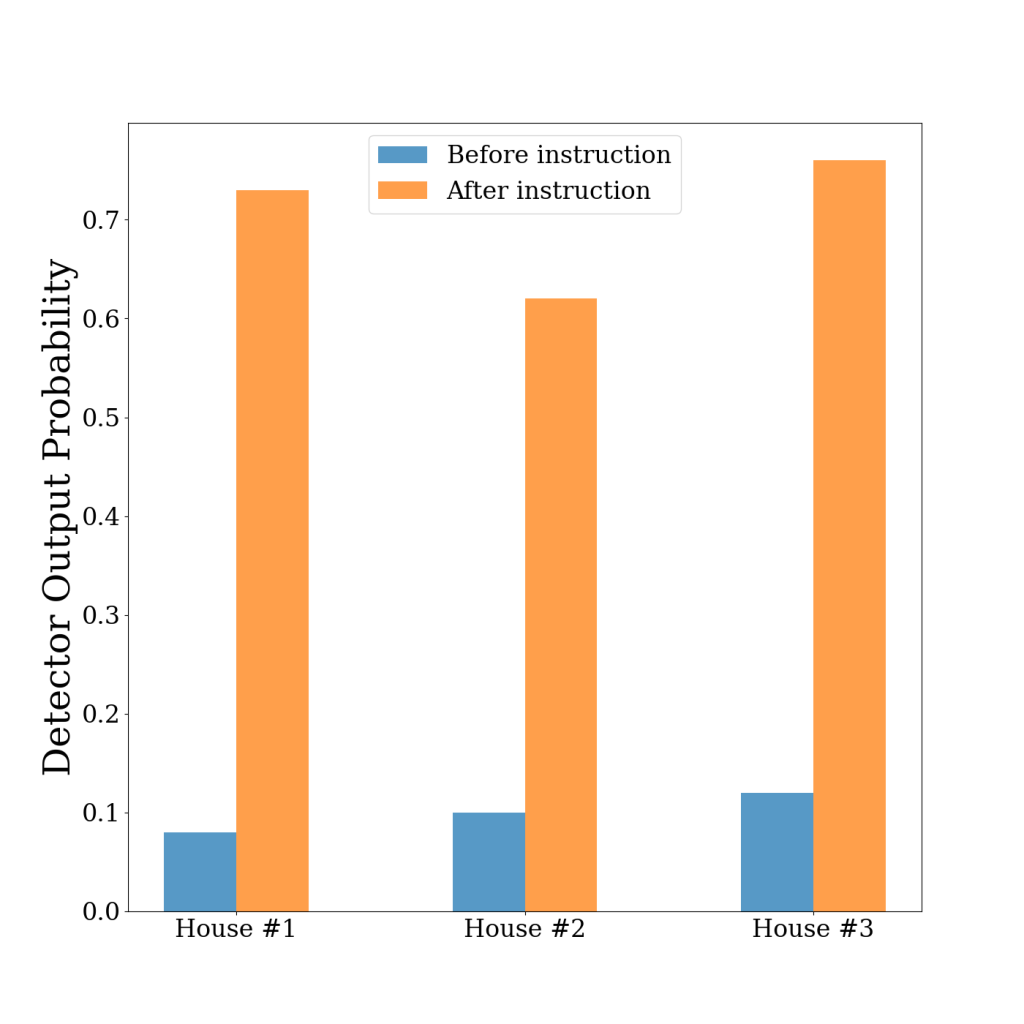
We additionally show that the placements of TIDEE can be customized based on user preferences. For example, based on user input such as “I never want my alarm on the desk”, we can use online learning techniques to change the output from the model that alarm clock being on the desk is out of place (and should be moved). Below we show some examples of locations and relations of alarm clocks that were predicted as being in the correct locations (and not out of place) within the scene after our initial training. However, after doing the user-specified finetuning, our network predicts that the alarm clock on the desk is out of place and should be repositioned.

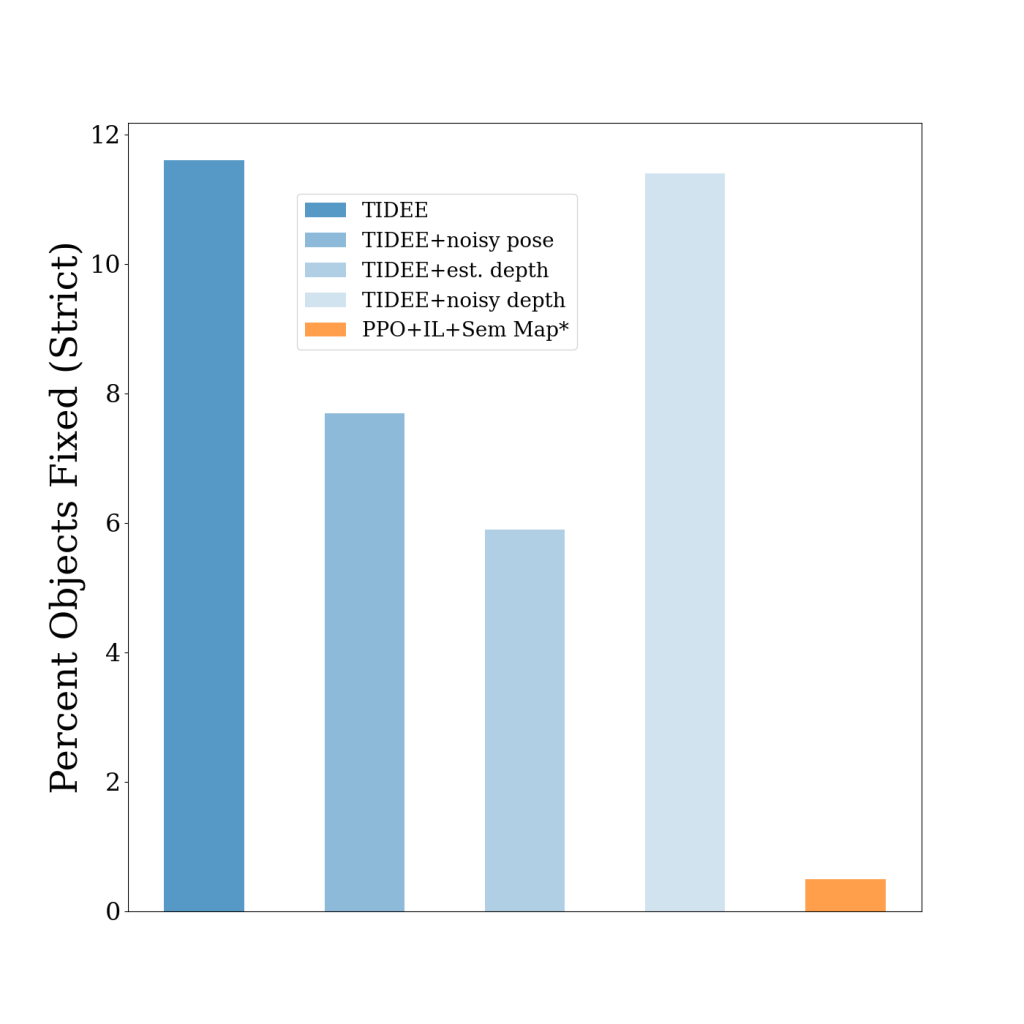
We also show that a simplified version of TIDEE can generalize to task of rearrangement, where the agent sees the original state of the objects, then some of the objects get rearranged to new locations, and the agent must rearrange the objects back to their original state. We outperform the previous state of the art model that utilizes semantic mapping and reinforcement learning, even with noisy sensor measurements.
Summary
In this article, we discussed TIDEE, an embodied agent that uses commonsense reasoning to tidy up novel messy scenes. We introduce a new benchmark to test agents in their ability to clean up messy scenes without any human instruction. To check out our paper, code, and more, please visit our website at https://tidee-agent.github.io/.
Also, feel free to shoot me an email at gsarch@andrew.cmu.edu! I would love to chat!