Posted by Lu Jiang, Senior Research Scientist and Weilong Yang, Senior Staff Software Engineer, Google Research
The success of deep neural networks depends on access to high-quality labeled training data, as the presence of label errors (label noise) in training data can greatly reduce the accuracy of models on clean test data. Unfortunately, large training datasets almost always contain examples with inaccurate or incorrect labels. This leads to a paradox: on one hand, large datasets are necessary to train better deep networks, while on the other hand, deep networks tend to memorize training label noise, resulting in poorer model performance in practice.
The research community has recognized the importance of this problem, introducing works attempting to understand noisy training labels, e.g., by Arpit et al., as well as mitigation strategies, such as MentorNet or co-teaching, to overcome them. Controlled experiments play a crucial role in understanding noisy labels by studying the impact of the noise level — the percentage of examples with incorrect labels in the dataset — on model performance. However, current experiments have only been performed on synthetic labels, in which noisy examples have randomly assigned labels, not real-world label noise, which follows a different noise distribution. Such studies may then result in very different or even contradictory findings about noisy labels compared to practical experience. In addition, methods that perform well on synthetic noise may not work as well on real-world noisy labels.
In “Beyond Synthetic Noise: Deep Learning on Controlled Noisy Labels”, published at ICML 2020, we make three contributions towards better understanding deep learning on non-synthetic noisy labels. First, we establish the first controlled dataset and benchmark of realistic, real-world label noise sourced from the web (i.e., web label noise). Second, we propose a simple but highly effective method to overcome both synthetic and real-world noisy labels. Finally, we conduct the largest study to date that compares synthetic and web label noise across a wide variety of settings.
Properties of Synthetic vs Real-World (Web) Label Noise
There are a number of differences between the distribution of images with synthetic versus real-world (web) label noise. First, images with web label noise tend to be more consistent, visually or semantically, with the true positive images. Second, synthetic label noise is at class-level (all examples in the same class are equally noisy), whereas real-world label noise is at instance-level (certain images are more likely to be mislabelled than others, regardless of the associated class). For example, images of “Honda Civic” and “Honda Accord” are more often confused when the images are taken from the side than when the vehicles are imaged from the front. Third, images with real-world label noise come from an open class vocabulary that may not overlap with the class vocabulary of a specific dataset. For example, the web noisy images of “ladybug” include classes such as “fly” and other bugs that are not included in the class list of the dataset being used. The benchmark for controlled label noise will help provide better quantitative understanding of the differences between synthetic and real-world web label noise.
Benchmark for Controlled Label Noise from the Web
The benchmark in this work is built on two public datasets: Mini-ImageNet, for coarse-grained image classification, and Stanford Cars, for fine-grained image classification. We gradually replace clean images in these datasets with incorrectly labeled images gathered from the web, following standard methods for the construction of synthetic datasets.
To do this, we collect images from the web using the class name (e.g., “ladybug”) as a keyword — an automatic approach to collect noisy labeled images from the web without manual annotations. Each retrieved image is then examined by 3-5 annotators using Google Cloud Labeling Service who identify whether or not the web label given is correct, yielding nearly 213k annotated images. We use these web images with incorrect labels to replace a percentage of the clean training images in the original Mini-ImageNet and Stanford Cars datasets. We create 10 different datasets with progressively higher levels of label noise (from 0% clean data to 80% data with erroneous labels). The datasets have been open-sourced at our Controlled Noisy Web Labels website.
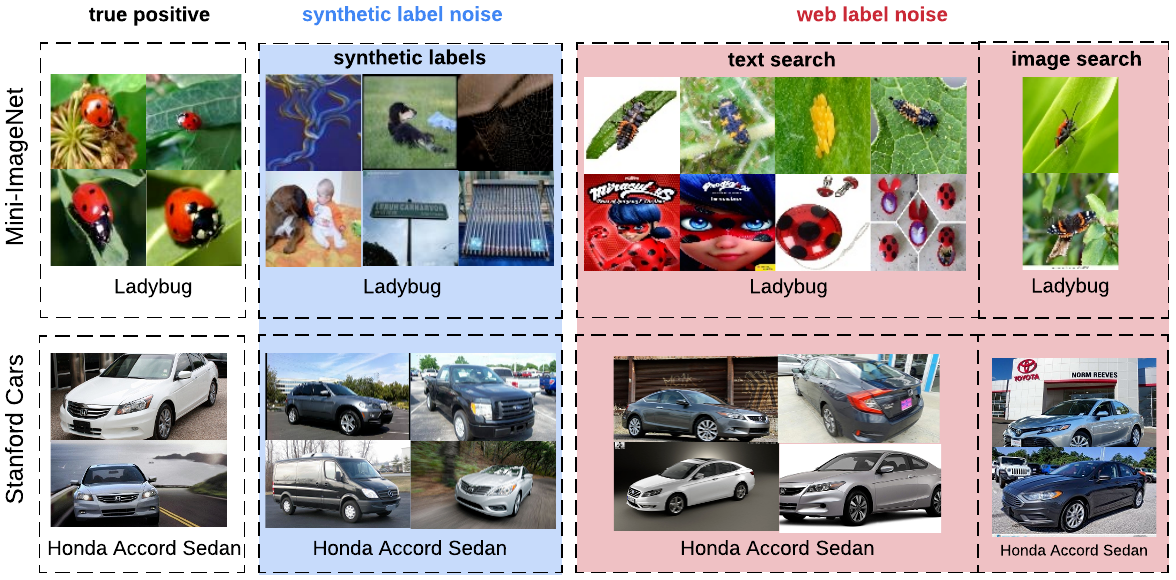 |
| Comparison of synthetic label noise and web label noise. From left to right, columns are true positive images in the Mini-ImageNet or Stanford Cars dataset, images with incorrect synthetic labels, and images with incorrect web labels (collected in the present work). |
MentorMix: A Simple Robust Learning Method
Given a dataset of some unknown noise level, our goal is to train a robust model that can generalize well on the clean test data. Building on two existing techniques, MentorNet and Mixup, we introduce a simple yet effective method called MentorMix, which works with a given model of interest to overcome both synthetic and real-world noisy labels.
MentorMix is an iterative approach that comprises four steps: weight, sample, mixup, and weight again. In the first step, a weight is computed for every example in a mini-batch by a MentorNet network, which can be tailored to the task at hand, and the weights are normalized into a distribution. In practice, the goal is to assign high weights for correctly labeled examples and zero weights for incorrectly labeled examples. In reality, we don’t know which are correct and which are incorrect, so MentorNet weights are based on approximations. In the example here, MentorNet uses the StudentNet training loss to determine the weights in the distribution.
Next, for each example, we use importance sampling to select another example in the same mini-batch according to the distribution. As examples with higher weights tend to have the correct label, they are favored in the sampling procedure. We then use Mixup to mix the original and sampled examples to regularize the model prediction between noisy training examples. Finally, we may compute another weight for the mixed example to scale the final loss. The impact of this second weighting strategy becomes more pronounced for high noise levels.
Conceptually, the above steps implement a new robust loss, which turns out to be more resilient to noisy training labels. More discussion on this topic can be found in our paper. The animation below illustrates the four key steps in MentorMix, where StudentNet is the model to be trained on noisy labeled data. We employ a very simple version of MentorNet, as described by Jiang et al., to compute the weight for each example.
 |
| Illustration of four steps in the MentorMix method: weight, sample, mixup, and weight again. |
Evaluation
We evaluate MentorMix on five datasets including CIFAR 10/100 with synthetic label noise, and WebVision 1.0, a large dataset of 2.2 million images with real-world noisy labels. MentorMix consistently yields improved results on the CIFAR 10/100 datasets and achieves the best published result on the WebVision dataset, improving the previous best method by a significant ~3% in terms of the top-1 classification accuracy on the ImageNet ILSVRC12 validation set.
 |
| Our model is trained only on the WebVision 2.2 million noisy training sample and is tested on the ImageNet ILSVRC12 validation set. The baseline models reported are (Lee et al. 2018), (MentorNet 2018), and (Guo et al. 2018). |
New Findings on Noisy Labels from the Web
This work represents the largest study to date into understanding deep neural networks trained on noisy labels. We propose three new findings on web label noise:
- Deep neural networks generalize much better on web label noise
While it is well known that deep neural networks generalize poorly on synthetic label noise, our results suggest that deep neural networks generalize much better on web label noise. For example, the classification accuracy of a network trained on the Stanford Cars dataset using the 60% web label noise level is 0.66, much higher than that for the same network trained at the same 60% level of synthetic noise, which achieves only 0.09. This pattern is consistent across our two datasets using both fine-tuning and training from scratch.
- Deep neural networks may NOT learn patterns first when trained on web label noise
Our common understanding is that deep neural networks learn patterns first — an interesting property in which DNNs are able to automatically capture generalizable “patterns” in the early training stage before memorizing noisy training labels. Because of this, early stopping is commonly used for training on noisy data. However, our results suggest deep neural networks may not learn patterns first when trained using datasets with web label noise, at least for the fine-grained classification task, suggesting that early stopping may not be effective on real-world label noise from the web.
- ImageNet architectures generalize on noisy training labels when the networks are fine-tuned
Kornblith et al. (2019) found that fine-tuning more advanced architectures trained on ImageNet tend to perform better on downstream tasks that have clean training labels. Our results extend this finding to noisy training data, showing that a better pre-trained architecture that exhibits better performance when pre-trained on ImageNet is likely to perform better even when it is fine-tuned on noisy training labels.
Summary
Based on our findings, we have the following practical recommendations for training deep neural networks on noisy data.
- A simple way to deal with noisy labels is to fine-tune a model that is pre-trained on clean datasets, like ImageNet. The better the pre-trained model is, the better it may generalize on downstream noisy training tasks.
- Early stopping may not be effective on the real-world label noise from the web.
- Methods that perform well on synthetic noise may not work as well on the real-world noisy labels from the web.
- The label noise from the web appears to be less harmful, yet it is more difficult for our current robust learning methods to tackle. This encourages more future research to be carried out on controlled real-world label noise.
- The proposed MentorMix can better overcome both synthetic and real-world noisy labels.
The code of MentorMix is available on GitHub, the datasets are on our Dataset Website.
Aknowledgements
This research was conducted by Lu Jiang, Di Huang, Mason Liu, and Weilong Yang. We’d like to thank Boqing Gong and Fei Sha for constructive feedback. Additional thanks go to the leadership Andrew Moore for supporting our data labeling effort, along with Tomas Izo and Rahul Sukthankar for help in releasing the dataset.
