Proteins are essential molecules found in all living things. They play a central role in our bodies’ structure and function, and they are also featured in many products that we encounter every day, from medications to household items like laundry detergent. Each protein is a chain of amino acid building blocks, and just as an image may include multiple objects, like a dog and a cat, a protein may also have multiple components, which are called protein domains. Understanding the relationship between a protein’s amino acid sequence — for example, its domains — and its structure or function are long-standing challenges with far-reaching scientific implications.
| An example of a protein with known structure, TrpCF from E. coli, for which areas used by a model to predict function are highlighted (green). This protein produces tryptophan, which is an essential part of a person’s diet. |
<!–
 |
| An example of a protein with known structure, TrpCF from E. coli, for which areas used by a model to predict function are highlighted (green). This protein produces tryptophan, which is an essential part of a person’s diet. |
–>
Many are familiar with recent advances in computationally predicting protein structure from amino acid sequences, as seen with DeepMind’s AlphaFold. Similarly, the scientific community has a long history of using computational tools to infer protein function directly from sequences. For example, the widely-used protein family database Pfam contains numerous highly-detailed computational annotations that describe a protein domain’s function, e.g., the globin and trypsin families. While existing approaches have been successful at predicting the function of hundreds of millions of proteins, there are still many more with unknown functions — for example, at least one-third of microbial proteins are not reliably annotated. As the volume and diversity of protein sequences in public databases continue to increase rapidly, the challenge of accurately predicting function for highly divergent sequences becomes increasingly pressing.
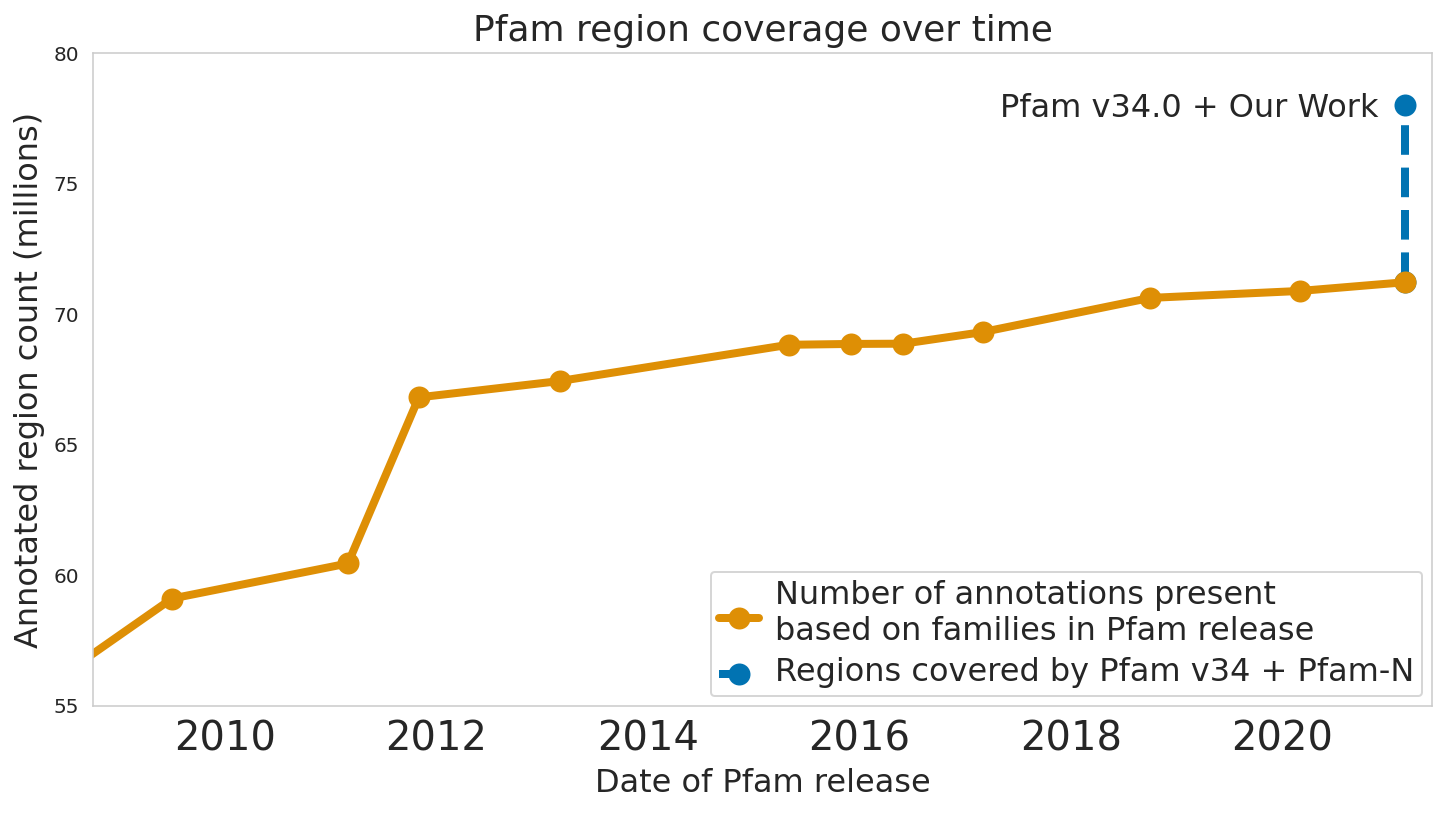
In “Using Deep Learning to Annotate the Protein Universe”, published in Nature Biotechnology, we describe a machine learning (ML) technique to reliably predict the function of proteins. This approach, which we call ProtENN, has enabled us to add about 6.8 million entries to Pfam’s well-known and trusted set of protein function annotations, about equivalent to the sum of progress over the last decade, which we are releasing as Pfam-N. To encourage further research in this direction, we are releasing the ProtENN model and a distill-like interactive article where researchers can experiment with our techniques. This interactive tool allows the user to enter a sequence and get results for a predicted protein function in real time, in the browser, with no setup required. In this post, we’ll give an overview of this achievement and how we’re making progress toward revealing more of the protein universe.
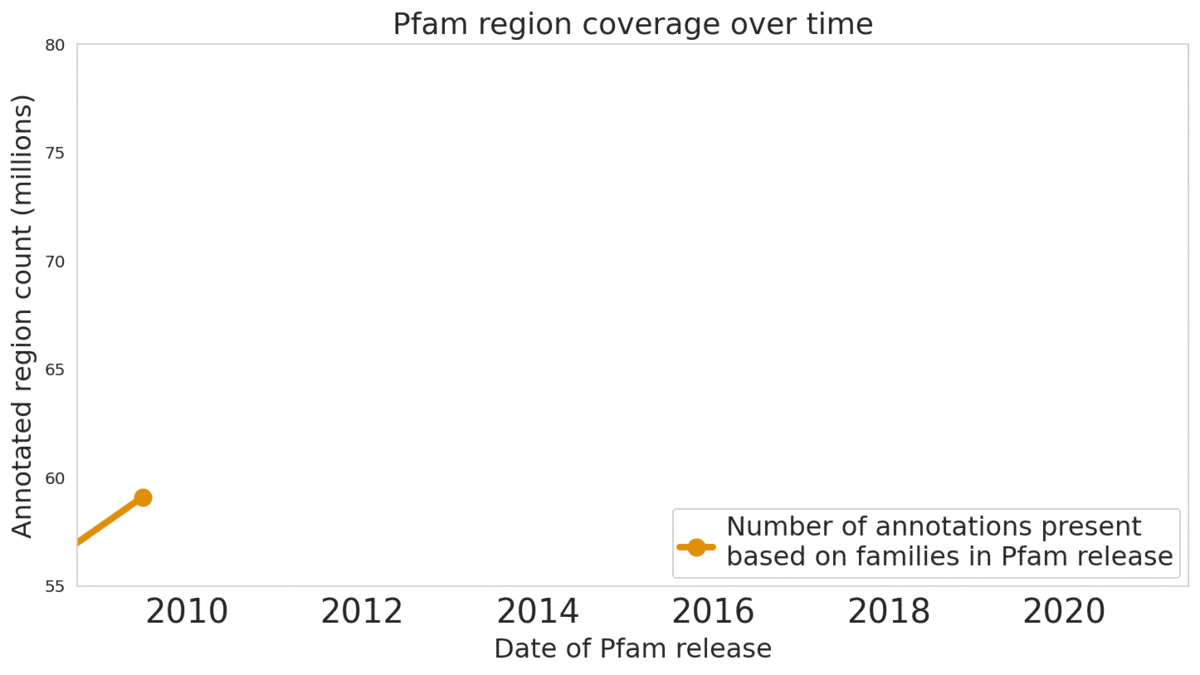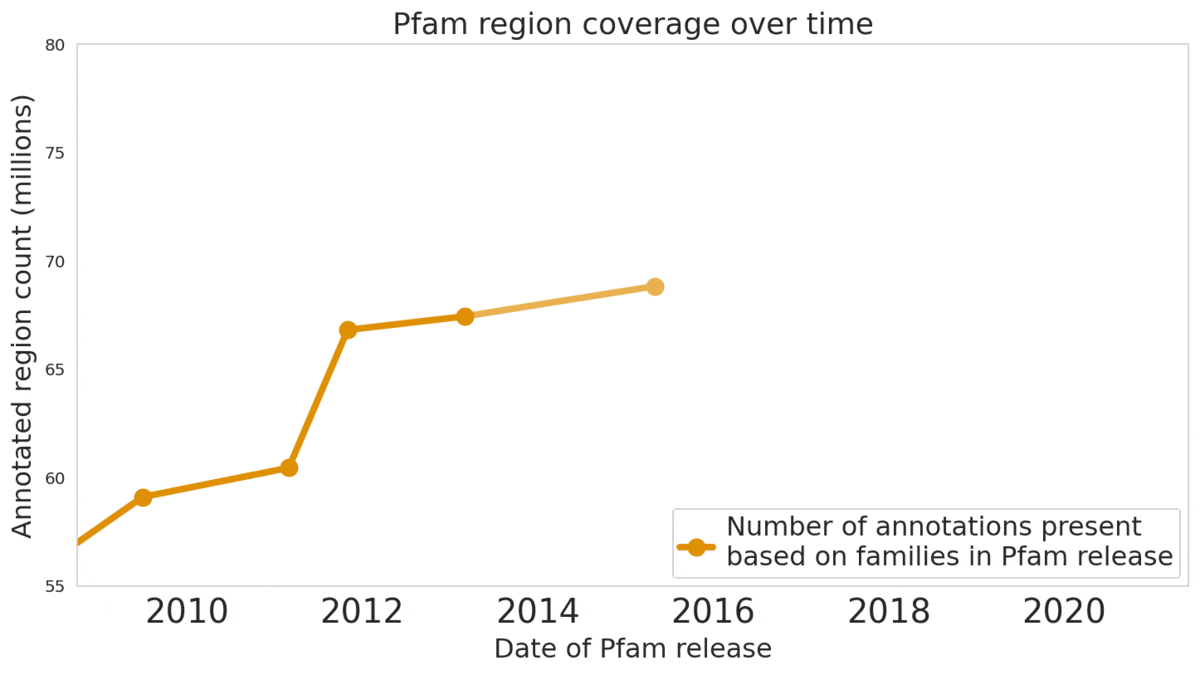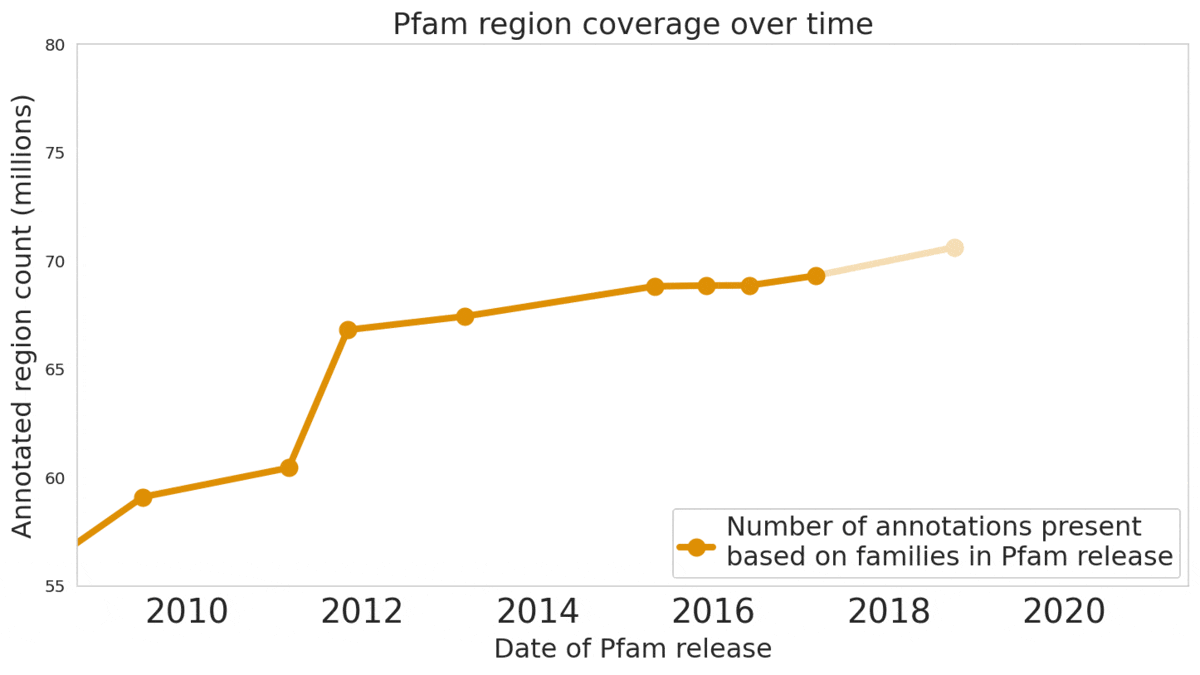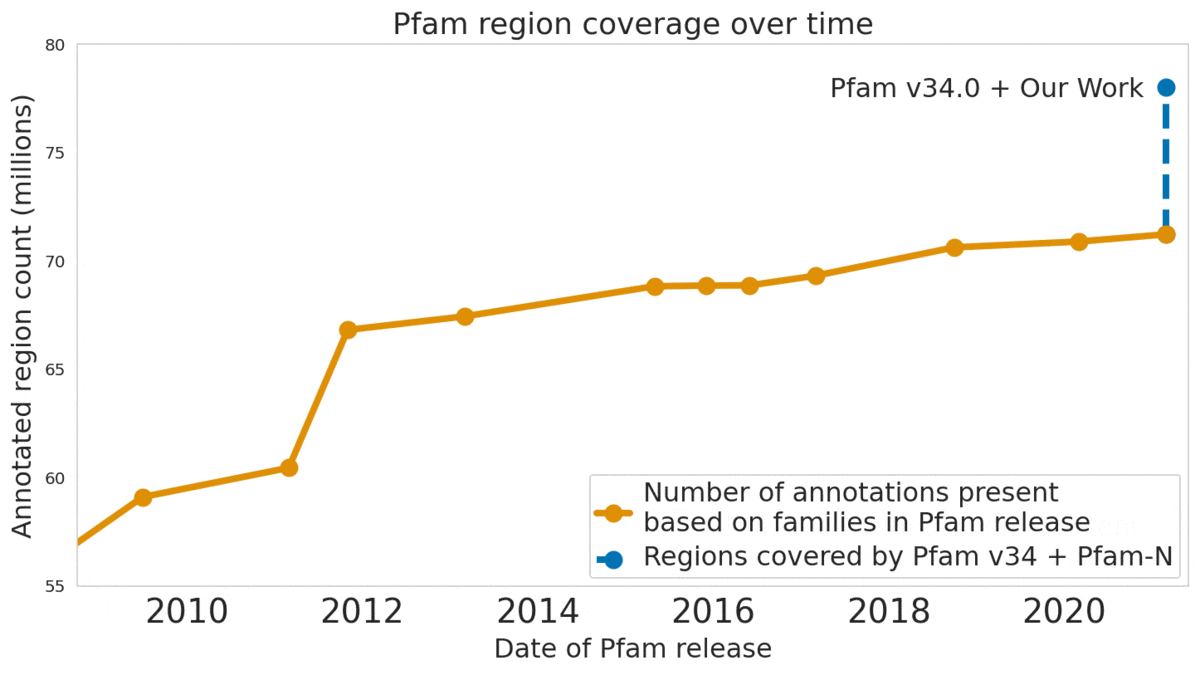 |
| The Pfam database is a large collection of protein families and their sequences. Our ML model ProtENN helped annotate 6.8 million more protein regions in the database. |
Protein Function Prediction as a Classification Problem
In computer vision, it’s common to first train a model for image classification tasks, like CIFAR-100, before extending it to more specialized tasks, like object detection and localization. Similarly, we develop a protein domain classification model as a first step towards future models for classification of entire protein sequences. We frame the problem as a multi-class classification task in which we predict a single label out of 17,929 classes — all classes contained in the Pfam database — given a protein domain’s sequence of amino acids.
Models that Link Sequence to Function
While there are a number of models currently available for protein domain classification, one drawback of the current state-of-the-art methods is that they are based on the alignment of linear sequences and don’t consider interactions between amino acids in different parts of protein sequences. But proteins don’t just stay as a line of amino acids, they fold in on themselves such that nonadjacent amino acids have strong effects on each other.
Aligning a new query sequence to one or more sequences with known function is a key step of current state-of-the-art methods. This reliance on sequences with known function makes it challenging to predict a new sequence’s function if it is highly dissimilar to any sequence with known function. Furthermore, alignment-based methods are computationally intensive, and applying them to large datasets, such as the metagenomic database MGnify, which contains >1 billion protein sequences, can be cost prohibitive.
To address these challenges, we propose to use dilated convolutional neural networks (CNNs), which should be well-suited to modeling non-local pairwise amino-acid interactions and can be run on modern ML hardware like GPUs. We train 1-dimensional CNNs to predict the classification of protein sequences, which we call ProtCNN, as well as an ensemble of independently trained ProtCNN models, which we call ProtENN. Our goal for using this approach is to add knowledge to the scientific literature by developing a reliable ML approach that complements traditional alignment-based methods. To demonstrate this, we developed a method to accurately measure our method’s accuracy.
Evaluation with Evolution in Mind
Similar to well-known classification problems in other fields, the challenge in protein function prediction is less in developing a completely new model for the task, and more in creating fair training and test sets to ensure that the models will make accurate predictions for unseen data. Because proteins have evolved from shared common ancestors, different proteins often share a substantial fraction of their amino acid sequence. Without proper care, the test set could be dominated by samples that are highly similar to the training data, which could lead to the models performing well by simply “memorizing” the training data, rather than learning to generalize more broadly from it.
| We create a test set that requires ProtENN to generalize well on data far from its training set. |
<!–
 |
| We create a test set that requires ProtENN to generalize well on data far from its training set. |
–>
To guard against this, it is essential to evaluate model performance using multiple separate setups. For each evaluation, we stratify model accuracy as a function of similarity between each held-out test sequence and the nearest sequence in the train set.
The first evaluation includes a clustered split training and test set, consistent with prior literature. Here, protein sequence samples are clustered by sequence similarity, and entire clusters are placed into either the train or test sets. As a result, every test example is at least 75% different from every training example. Strong performance on this task demonstrates that a model can generalize to make accurate predictions for out-of-distribution data.
For the second evaluation, we use a randomly split training and test set, where we stratify examples based on an estimate of how difficult they will be to classify. These measures of difficulty include: (1) the similarity between a test example and the nearest training example, and (2) the number of training examples from the true class (it is much more difficult to accurately predict function given just a handful of training examples).
To place our work in context, we evaluate the performance of the most widely used baseline models and evaluation setups, with the following baseline models in particular: (1) BLAST, a nearest-neighbor method that uses sequence alignment to measure distance and infer function, and (2) profile hidden Markov models (TPHMM and phmmer). For each of these, we include the stratification of model performance based on sequence alignment similarity mentioned above. We compared these baselines against ProtCNN and the ensemble of CNNs, ProtENN.
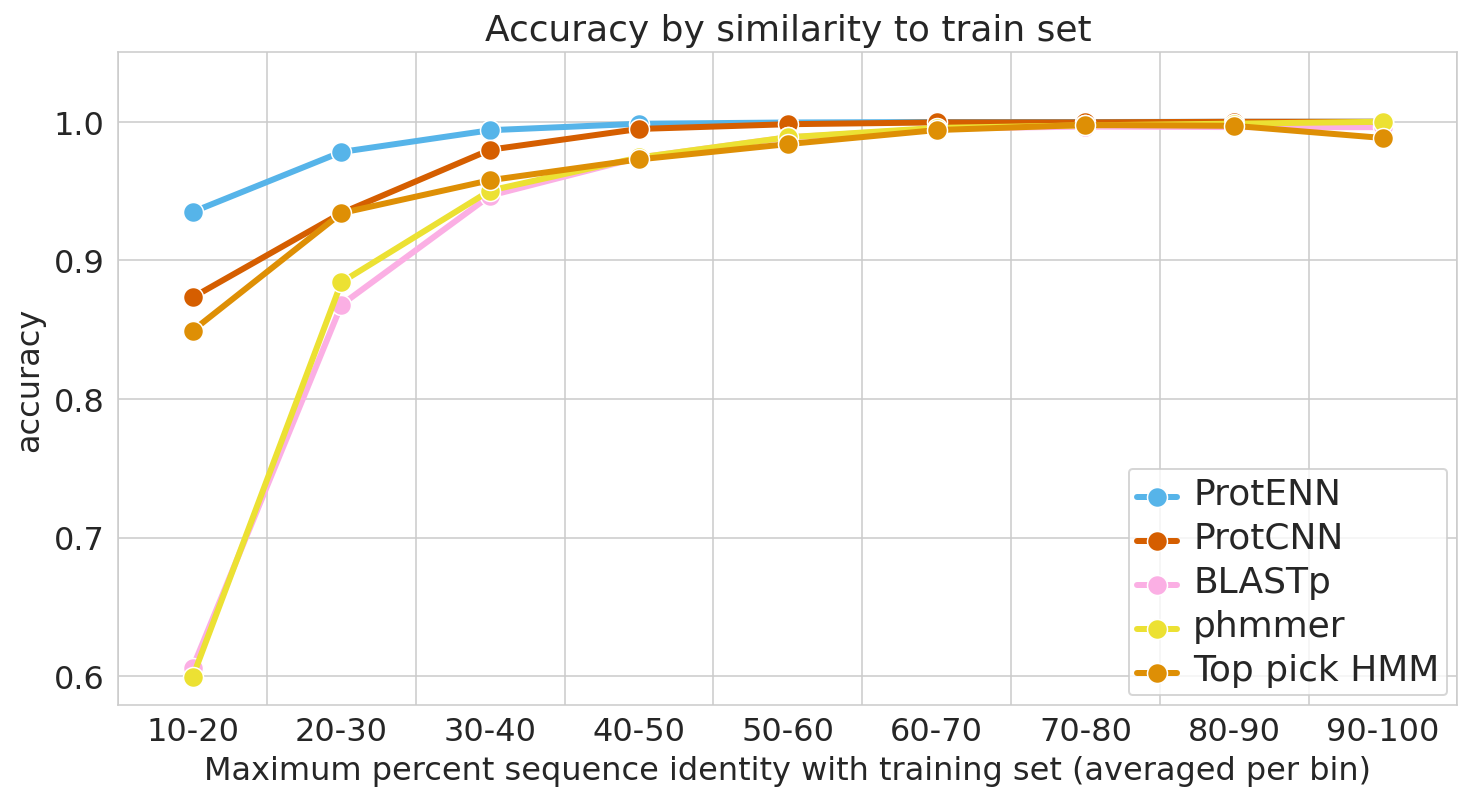 |
| We measure each model’s ability to generalize, from the hardest examples (left) to the easiest (right). |
Reproducible and Interpretable Results
We also worked with the Pfam team to test whether our methodological proof of concept could be used to label real-world sequences. We demonstrated that ProtENN learns complementary information to alignment-based methods, and created an ensemble of the two approaches to label more sequences than either method could by itself. We publicly released the results of this effort, Pfam-N, a set of 6.8 million new protein sequence annotations.
After seeing the success of these methods and classification tasks, we inspected these networks to understand whether the embeddings were generally useful. We built a tool that enables users to explore the relation between the model predictions, embeddings, and input sequences, which we have made available through our interactive manuscript, and we found that similar sequences were clustered together in embedding space. Furthermore, the network architecture that we selected, a dilated CNN, allows us to employ previously-discovered interpretability methods like class activation mapping (CAM) and sufficient input subsets (SIS) to identify the sub-sequences responsible for the neural network predictions. With this approach, we find that our network generally focuses on the relevant elements of a sequence to predict its function.
Conclusion and Future Work
We’re excited about the progress we’ve seen by applying ML to the understanding of protein structure and function over the last few years, which has been reflected in contributions from the broader research community, from AlphaFold and CAFA to the multitude of workshops and research presentations devoted to this topic at conferences. As we look to build on this work, we think that continuing to collaborate with scientists across the field who’ve shared their expertise and data, combined with advances in ML will help us further reveal the protein universe.
Acknowledgments
We’d like to thank all of the co-authors of the manuscripts, Maysam Moussalem, Jamie Smith, Eli Bixby, Babak Alipanahi, Shanqing Cai, Cory McLean, Abhinay Ramparasad, Steven Kearnes, Zack Nado, and Tom Small.
