Posted by Pohung Chen, Creative Technologist, Google Partner Innovation
 Today we are releasing LipSync, a web experience that lets you lip sync to music live in the web browser. LipSync was created as a playful way to demonstrate the facemesh model for TensorFlow.js. We partnered with Australian singer Tones and I to let you lip sync to Dance Monkey in this demonstration.
Today we are releasing LipSync, a web experience that lets you lip sync to music live in the web browser. LipSync was created as a playful way to demonstrate the facemesh model for TensorFlow.js. We partnered with Australian singer Tones and I to let you lip sync to Dance Monkey in this demonstration.
Using TensorFlow.js FaceMesh
The TensorFlow.js FaceMesh model provides a real-time high density estimate of key points of your facial expression using only a webcam and on device machine learning – meaning no data ever leaves your machine for inference. We essentially use the key points around the mouth and lips to estimate how well you synchronize to the lyrics of the Dance Monkey song.
Determining Correctness
When first testing the demo, many people assumed we used a complex lip reading algorithm to match the mouth shapes with lyrics. Lip reading is quite difficult to achieve, so we came up with a simpler solution. We capture a frame by frame recording of the “correct” mouth shapes lined up with the music, and then when the user is playing the game, we compare the mouth shapes to the pre-recorded baseline.
Measuring the shape of your mouth
What is a mouth shape? There are many different ways to measure the shape of your mouth. We needed a technique that allows the user to move their head around while singing and is relatively forgiving in different mouth shapes, sizes, and distance to the camera.
Mouth Ratio
One way of comparing mouth shapes is to use the width to height ratio of your mouth. For example, if your mouth is closed and forming the “mmm” sound, you have a high width to height ratio. If your mouth is open in an “ooo” sound, your mouth will be closer to a 1:1 width to height ratio. While this method mostly works, there were still edge cases that made the detection algorithm not as robust, so we explored another method called Hu Moments explained below.
While this method mostly works, there were still edge cases that made the detection algorithm not as robust, so we explored another method called Hu Moments explained below.
OpenCV matchShapes Hu Moments
In the OpenCV library, there is a matchShapes function which compares contours and returns a similarity score. Underneath the hood, the matchShapes function uses a technique called Hu Moments which provides a set of numbers calculated using central moments that are invariant to image transformations. This allowed us to compare shapes regardless of translation, scale, and rotation. So the user can freely rotate their head without impacting the detection of the mouth shape itself.
We use this in addition to the mouth shape above to determine how closely the shape of the mouth contours match.
Visual and Audio Feedback
In our original prototype, we wanted to create immediate audible feedback on how well the user is doing. We separated out the vocal track from the rest of the song and changed its volume based on real-time user performance score of their mouth shapes.
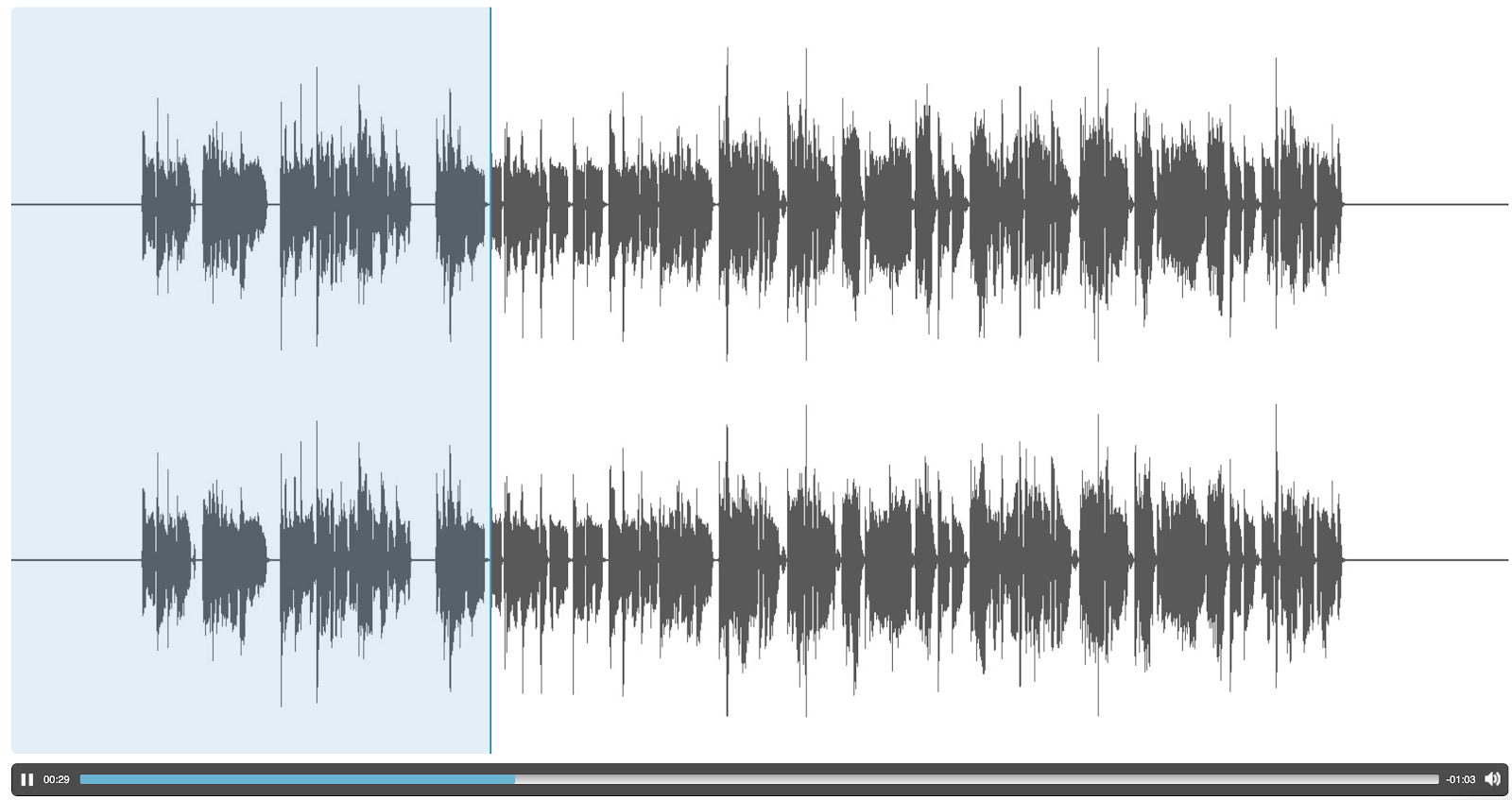 |
| Vocal Track |
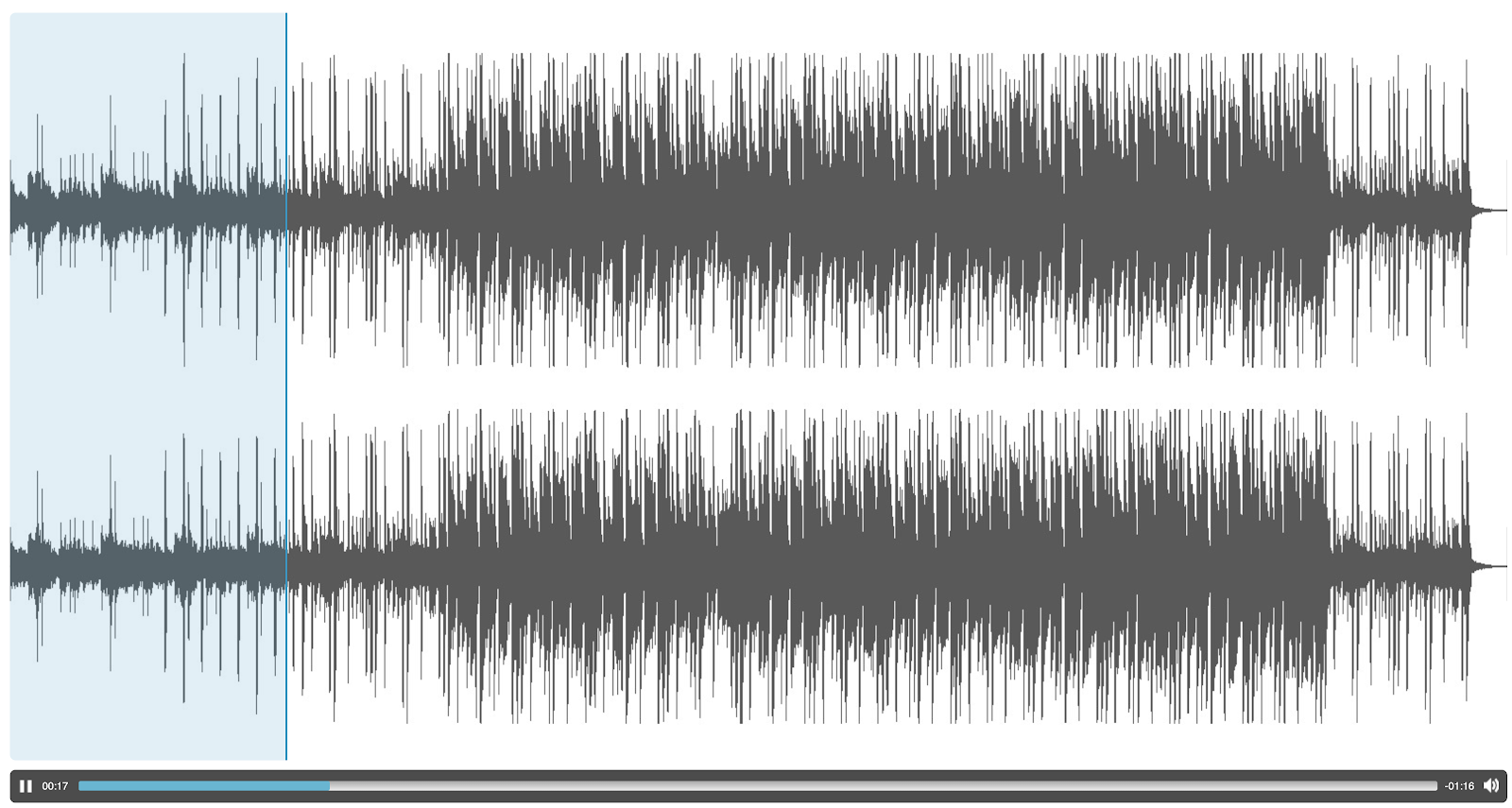 |
| Instrumental Track |
This allowed us to create the effect such that if you stop lip syncing to the song, the lyrical portion of the song stops playing (but the background music continues to play).
While this was a fun way to demonstrate the mouth shape matching algorithm, however it still missed that satisfactory rush of joy you get when you hit the right notes during karaoke or nail a long sequence of moves just right in arcade rhythm games.
We started by adding a real-time score that is then accumulated over time shown to the player as they played the game. In our initial testing, this didn’t work as well as we had hoped. It was confusing what the score was and the exact numbers weren’t particularly meaningful. We also wanted the user to focus their attention on the lyrics and the center of the screen as opposed to a score off to the side.
So we went with a different approach, preferring to lean on visual effects overlaid on top of the player’s face as they lip synced to the music and colors to indicate how well the player was doing.

Try Lip Sync yourself!
The Tensorflow.js FaceMesh model enables web-based, playful, interactive experiences that go beyond basic face filters, and with a little bit of creative thinking, we could get a lip sync experience without needing the full complexity of a full lip reading ML model.
So go ahead and try our live demo yourself right now. You can also check out an example of how the mouth shape matching works in this open source repo.
We would also like to give a special shout out to Kiattiyot Panichprecha, Bryan Tanaka, KC Chung, Dave Bowman, Matty Burton, Roger Chang, Ann Yuan, Sandeep Gupta, Miguel de Andrés-Clavera, Alessandra Donati, and Ethan Converse for their help in bringing this experience to life, and to thank the MediaPipe team who designed Facemesh.Read More