Computers are crunching more numbers than ever to crack the most complex problems of our time — how to cure diseases like COVID and cancer, mitigate climate change and more.
These and other grand challenges ushered computing into today’s exascale era when top performance is often measured in exaflops.
So, What’s an Exaflop?
An exaflop is a measure of performance for a supercomputer that can calculate at least 1018 or one quintillion floating point operations per second.
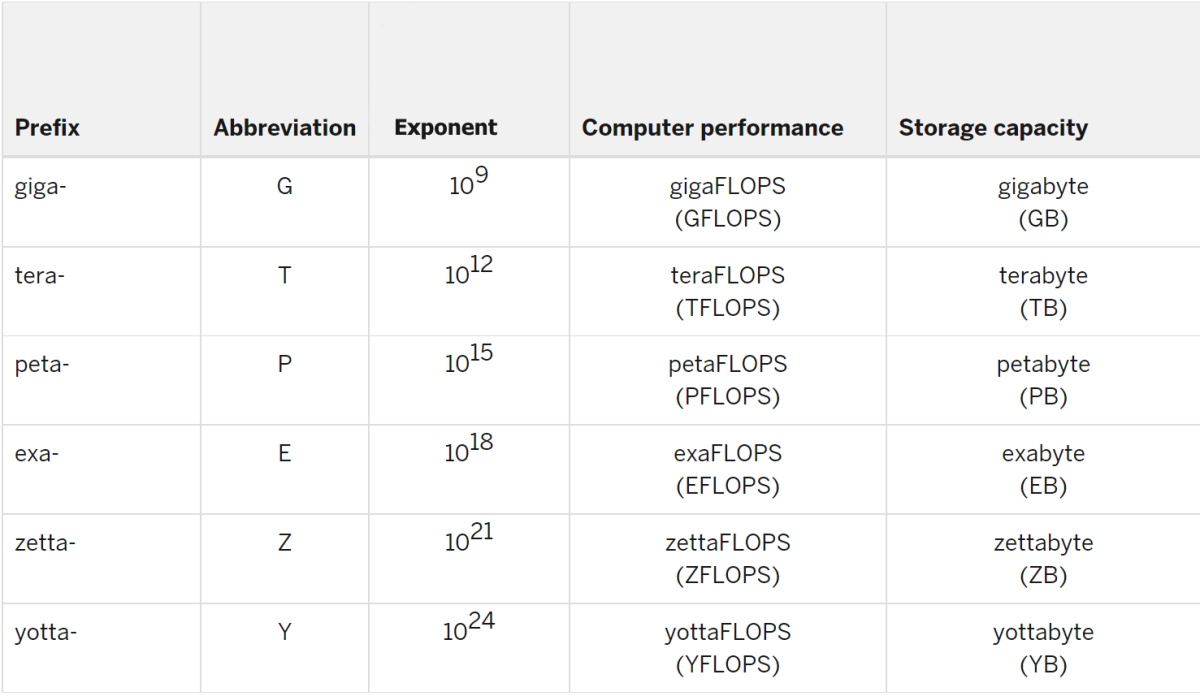
In exaflop, the exa- prefix means a quintillion, that’s a billion billion, or one followed by 18 zeros. Similarly, an exabyte is a memory subsystem packing a quintillion bytes of data.
The “flop” in exaflop is an abbreviation for floating point operations. The rate at which a system executes a flop in seconds is measured in exaflop/s.
Floating point refers to calculations made where all the numbers are expressed with decimal points.
1,000 Petaflops = an Exaflop
The prefix peta- means 1015, or one with 15 zeros behind it. So, an exaflop is a thousand petaflops.
To get a sense of what a heady calculation an exaflop is, imagine a billion people, each holding a billion calculators. (Clearly, they’ve got big hands!)
If they all hit the equal sign at the same time, they’d execute one exaflop.
Indiana University, home to the Big Red 200 and several other supercomputers, puts it this way: To match what an exaflop computer can do in just one second, you’d have to perform one calculation every second for 31,688,765,000 years.
A Brief History of the Exaflop
For most of supercomputing’s history, a flop was a flop, a reality that’s morphing as workloads embrace AI.
People used numbers expressed in the highest of several precision formats, called double precision, as defined by the IEEE Standard for Floating Point Arithmetic. It’s dubbed double precision, or FP64, because each number in a calculation requires 64 bits, data nuggets expressed as a zero or one. By contrast, single precision uses 32 bits.
Double precision uses those 64 bits to ensure each number is accurate to a tiny fraction. It’s like saying 1.0001 + 1.0001 = 2.0002, instead of 1 + 1 = 2.
The format is a great fit for what made up the bulk of the workloads at the time — simulations of everything, from atoms to airplanes, that need to ensure their results come close to what they represent in the real world.
So, it was natural that the LINPACK benchmark, aka HPL, that measures performance on FP64 math became the default measurement in 1993, when the TOP500 list of world’s most powerful supercomputers debuted.
The Big Bang of AI
A decade ago, the computing industry heard what NVIDIA CEO Jensen Huang describes as the big bang of AI.
This powerful new form of computing started showing significant results on scientific and business applications. And it takes advantage of some very different mathematical methods.
Deep learning is not about simulating real-world objects; it’s about sifting through mountains of data to find patterns that enable fresh insights.
Its math demands high throughput, so doing many, many calculations with simplified numbers (like 1.01 instead of 1.0001) is much better than doing fewer calculations with more complex ones.
That’s why AI uses lower precision formats like FP32, FP16 and FP8. Their 32-, 16- and 8-bit numbers let users do more calculations faster.
Mixed Precision Evolves
For AI, using 64-bit numbers would be like taking your whole closet when going away for the weekend.
Finding the ideal lower-precision technique for AI is an active area of research.
For example, the first NVIDIA Tensor Core GPU, Volta, used mixed precision. It executed matrix multiplication in FP16, then accumulated the results in FP32 for higher accuracy.
Hopper Accelerates With FP8
More recently, the NVIDIA Hopper architecture debuted with a lower-precision method for training AI that’s even faster. The Hopper Transformer Engine automatically analyzes a workload, adopts FP8 whenever possible and accumulates results in FP32.
When it comes to the less compute-intensive job of inference — running AI models in production — major frameworks such as TensorFlow and PyTorch support 8-bit integer numbers for fast performance. That’s because they don’t need decimal points to do their work.
The good news is NVIDIA GPUs support all precision formats (above), so users can accelerate every workload optimally.
Last year, the IEEE P3109 committee started work on an industry standard for precision formats used in machine learning. This work could take another year or two.
Some Sims Shine at Lower Precision
While FP64 remains popular for simulations, many use lower-precision math when it delivers useful results faster.
For example, researchers run in FP32 a popular simulator for car crashes, LS-Dyna from Ansys. Genomics is another field that tends to prefer lower-precision math.
In addition, many traditional simulations are starting to adopt AI for at least part of their workflows. As workloads shift towards AI, supercomputers need to support lower precision to run these emerging applications well.
Benchmarks Evolve With Workloads
Recognizing these changes, researchers including Jack Dongarra — the 2021 Turing award winner and a contributor to HPL — debuted HPL-AI in 2019. It’s a new benchmark that’s better for measuring these new workloads.
“Mixed-precision techniques have become increasingly important to improve the computing efficiency of supercomputers, both for traditional simulations with iterative refinement techniques as well as for AI applications,” Dongarra said in a 2019 blog. “Just as HPL allows benchmarking of double-precision capabilities, this new approach based on HPL allows benchmarking of mixed-precision capabilities of supercomputers at scale.”
Thomas Lippert, director of the Jülich Supercomputing Center, agreed.
“We’re using the HPL-AI benchmark because it’s a good measure of the mixed-precision work in a growing number of our AI and scientific workloads — and it reflects accurate 64-bit floating point results, too,” he said in a blog posted last year.
Today’s Exaflop Systems
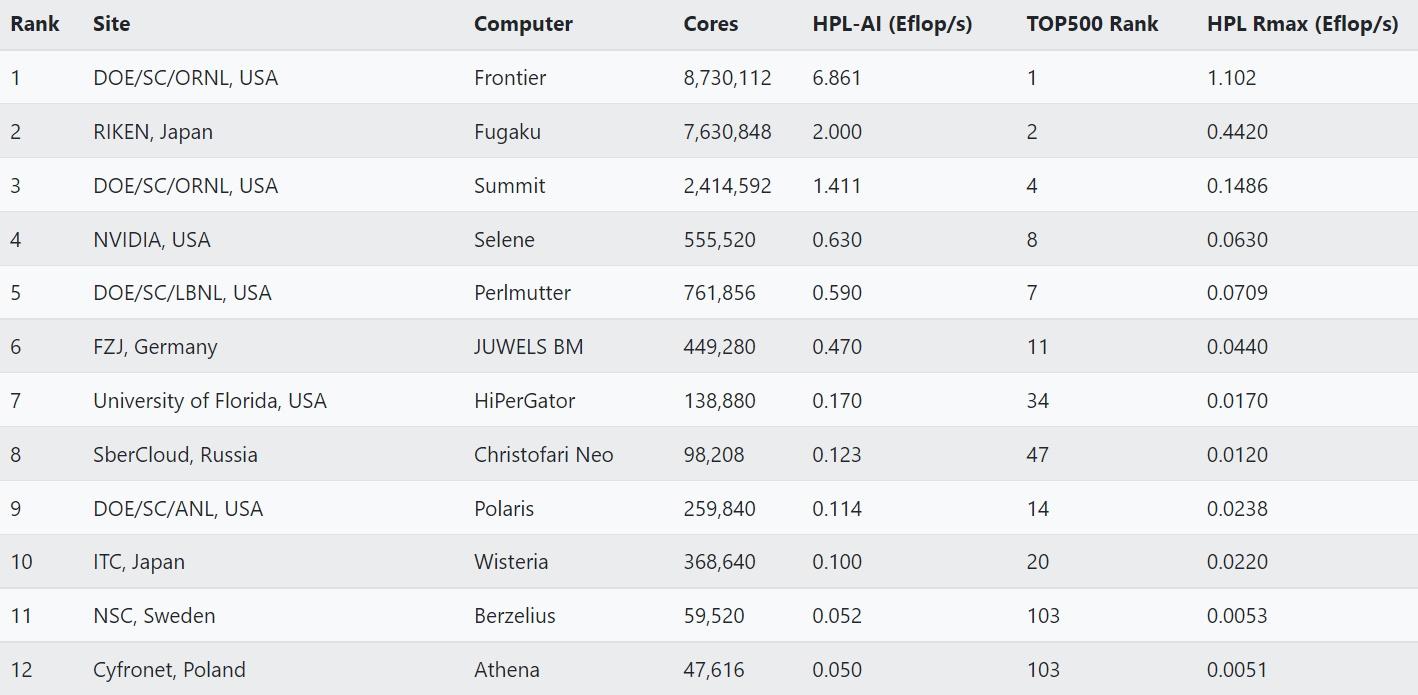
In a June report, 20 supercomputer centers around the world reported their HPL-AI results, three of them delivering more than an exaflop.
One of those systems, a supercomputer at Oak Ridge National Laboratory, also exceeded an exaflop in FP64 performance on HPL.
Two years ago, a very unconventional system was the first to hit an exaflop. The crowd-sourced supercomputer assembled by the Folding@home consortium passed the milestone after it put out a call for help fighting the COVID-19 pandemic and was deluged with donated time on more than a million computers.
Exaflop in Theory and Practice
Since then, many organizations have installed supercomputers that deliver more than an exaflop in theoretical peak performance. It’s worth noting that the TOP500 list reports both Rmax (actual) and Rpeak (theoretical) scores.
Rmax is simply the best performance a computer actually demonstrated.
Rpeak is a system’s top theoretical performance if everything could run at its highest possible level, something that almost never really happens. It’s typically calculated by multiplying the number of processors in a system by their clock speed, then multiplying the result by the number of floating point operations the processors can perform in one second.
So, if someone says their system can do an exaflop, consider asking if that’s using Rmax (actual) or Rpeak (theoretical).
Many Metrics in the Exaflop Age
It’s another one of the many nuances in this new exascale era.
And it’s worth noting that HPL and HPL-AI are synthetic benchmarks, meaning they measure performance on math routines, not real-world applications. Other benchmarks, like MLPerf, are based on real-world workloads.
In the end, the best measure of a system’s performance, of course, is how well it runs a user’s applications. That’s a measure not based on exaflops, but on ROI.
The post What Is an Exaflop? appeared first on NVIDIA Blog.