
One of the most common assumptions in machine learning (ML) is that the training and test data are independently and identically distributed (i.i.d.). For example, we might collect some number of data points and then randomly split them, assigning half to the training set and half to the test set.
However, this assumption is often broken in ML systems deployed in the wild. In real-world applications, distribution shifts— instances where a model is trained on data from one distribution but then deployed on data from a different distribution— are ubiquitous. For example, in medical applications, we might train a diagnosis model on patients from a few hospitals, and then deploy it more broadly to hospitals outside the training set 1; and in wildlife monitoring, we might train an animal recognition model on images from one set of camera traps and then deploy it to new camera traps 2.
A large body of prior work has shown that these distribution shifts can significantly degrade model performance in a variety of real-world ML applications: models can perform poorly out-of-distribution, despite achieving high in-distribution performance 3. To be able to reliably deploy ML models in the wild, we urgently need to develop methods for training models that are robust to real-world distribution shifts.
The WILDS benchmark
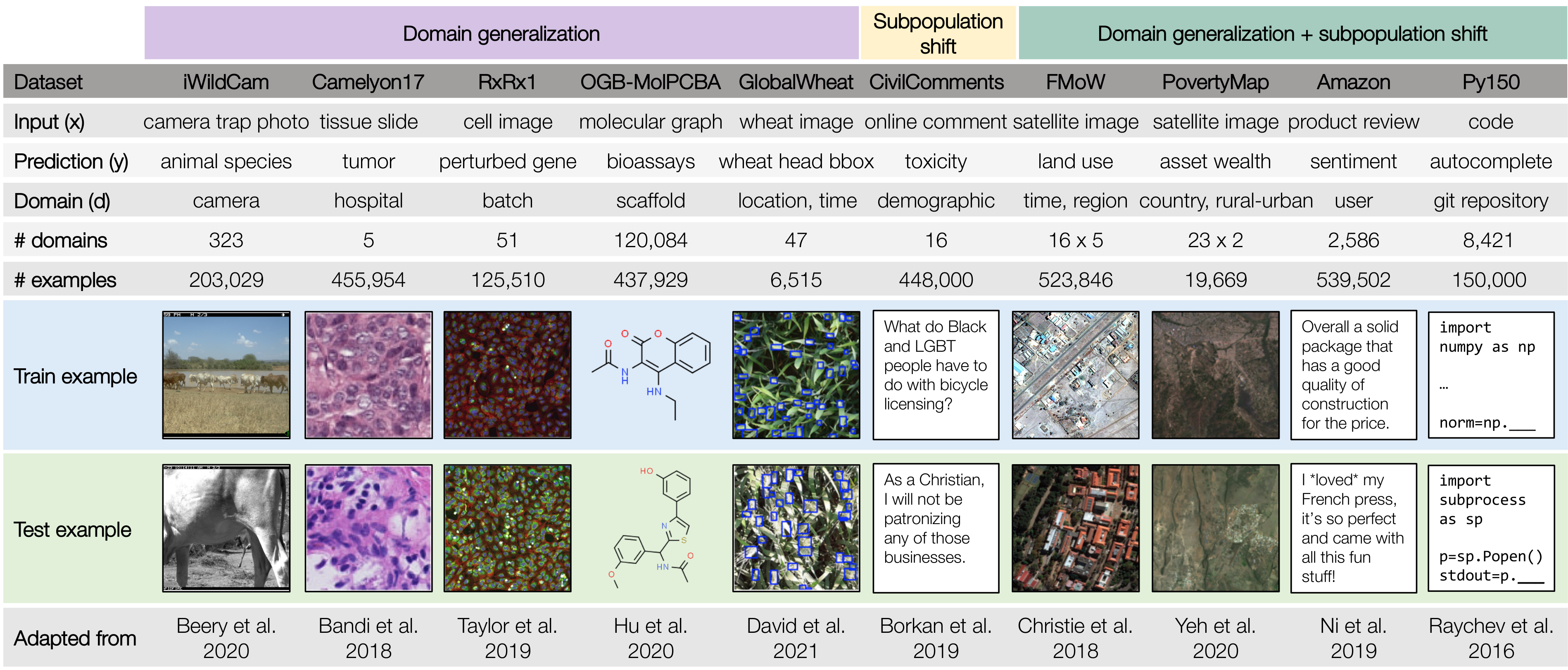
To facilitate the development of ML models that are robust to real-world distribution shifts, our ICML 2021 paper presents WILDS, a curated benchmark of 10 datasets that reflect natural distribution shifts arising from different cameras, hospitals, molecular scaffolds, experiments, demographics, countries, time periods, users, and codebases.
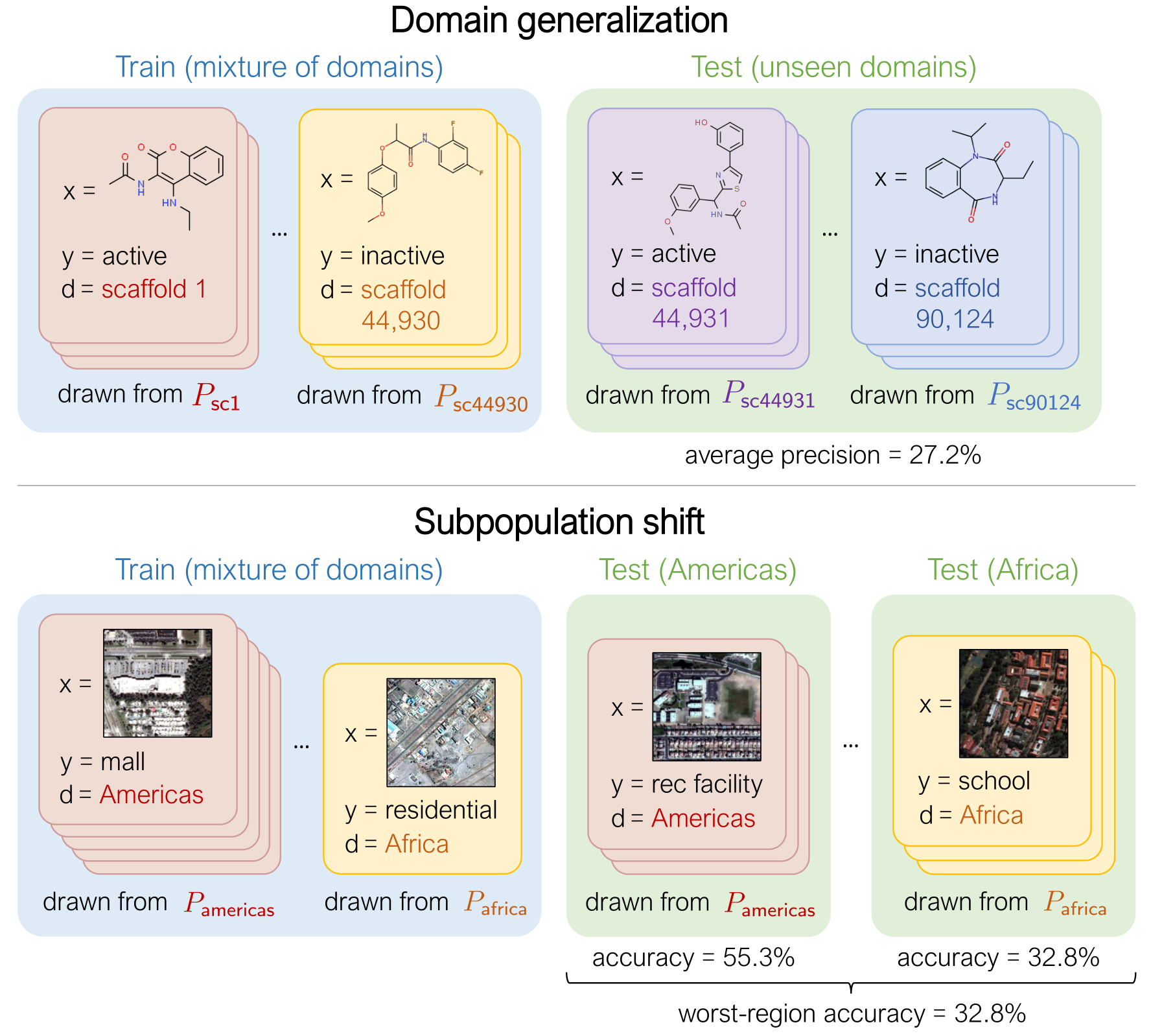
The WILDS datasets cover two common types of distribution shifts: domain generalization and subpopulation shift.
In domain generalization, the training and test distributions comprise data from related but distinct domains. The figure shows an example from the OGB-MolPCBA dataset 4 in WILDS, where the task is to predict the biochemical properties of molecules, and the goal is to generalize to molecules with different molecular scaffolds that have not been seen in the training set.
In subpopulation shift, we consider test distributions that are subpopulations of the training distribution, and seek to perform well even on the worst-case subpopulation. As an example, consider the CivilComments-WILDS dataset 5, where the task is toxicity classification on online text comments. Standard models perform well on average but poorly on comments that mention certain minority demographic groups (e.g., they might be likely to erroneously flag innocuous comments mentioning Black people as toxic), and we seek to train models that can perform equally well on comments that correspond to different demographic subpopulations.
Finally, some datasets exhibit both types of distribution shifts. For example, the second example in the figure above is from the FMoW-WILDS dataset 6, where there is both a domain generalization problem over time (the training set consists of satellite images taken before 2013, while the test images were taken after 2016) as well as a subpopulation shift problem over different geographical regions (we seek to do well over all regions).
Selection criteria for WILDS datasets
WILDS builds on extensive data collection efforts by domain experts working on applying ML methods in their application areas, and who are often forced to grapple with distribution shifts to make progress in their applications. To design WILDS, we worked with these experts to identify, select, and adapt datasets that fulfilled the following criteria:
-
Real-world relevance. The training/test splits and evaluation metrics are motivated by real-world scenarios and chosen in conjunction with domain experts. By focusing on realistic distribution shifts, WILDS complements existing distribution shift benchmarks, which have largely studied shifts that are cleanly characterized but are not likely to arise in real-world deployments. For example, many recent papers have studied datasets with shifts induced by synthetic transformations, such as changing the color of MNIST digits 7. Though these are important testbeds for systematic studies, model robustness need not transfer across shifts—e.g., a method that improves robustness on a standard vision dataset can consistently harm robustness on real-world satellite imagery datasets 8. So, in order to evaluate and develop methods for real-world distribution shifts, benchmarks like WILDS that capture shifts in the wild serve as an important complement to more synthetic benchmarks.
-
Distribution shifts with large performance gaps. The train/test splits reflect shifts that substantially degrade model performance, i.e., with a large gap between in-distribution and out-of-distribution performance. Measuring the in-distribution versus out-of-distribution gap is an important but subtle problem, as it relies on carefully constructing an appropriate in-distribution setting. We discuss its complexities and our approach in more detail in the paper.
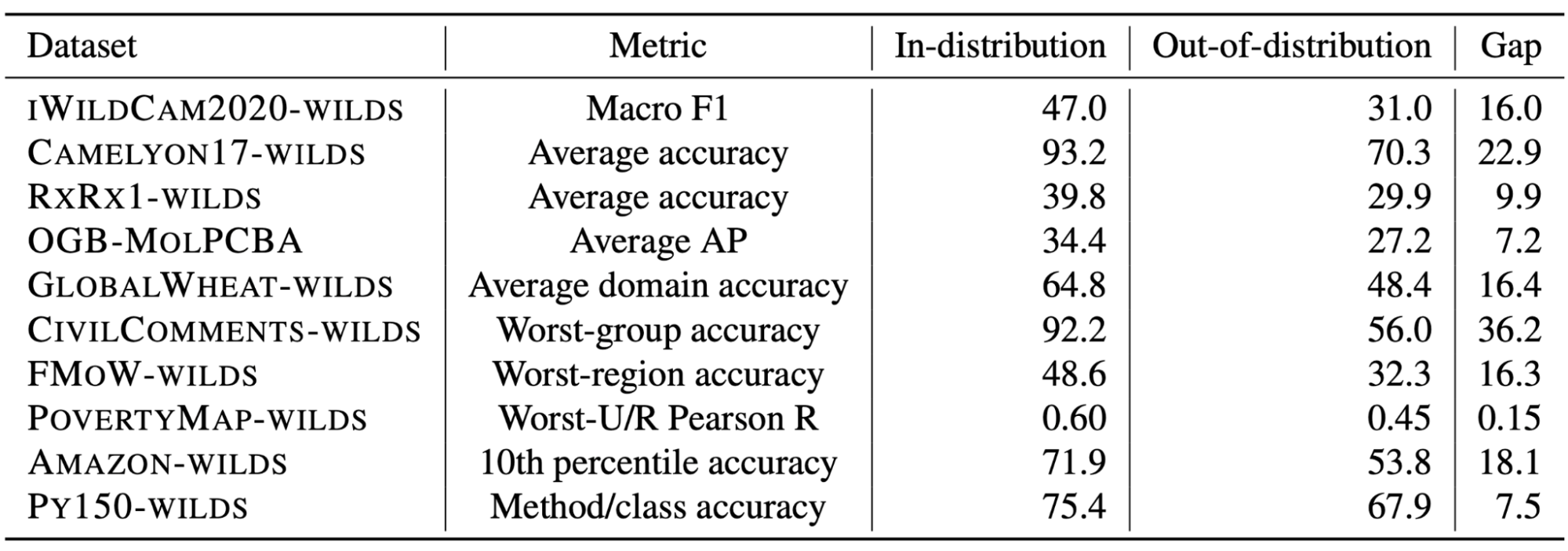
Apart from the 10 datasets in WILDS, we also survey distribution shifts that occur in other application areas—algorithmic fairness and policing, medicine and healthcare, genomics, natural language and speech processing, education, and robotics—and discuss examples of datasets from these areas that we considered but did not include in WILDS. We investigated datasets in autonomous driving, fairness in policing, and computational biology, but either did not observe substantial performance drops or found that performance disparities arose from factors beyond distribution shifts.
Using WILDS
To make it easy to work with WILDS and to enable systematic comparisons between approaches, we developed an open-source Python package that fully automates data loading and evaluation. This package also contains default models and hyperparameters that can easily reproduce all of the baseline numbers we have in our paper. The package is simple to install—just run pip install wilds—and straightforward to use with any PyTorch-based algorithms and models:

We are also hosting a public leaderboard at https://wilds.stanford.edu/leaderboard/ to track the state of the art in algorithms for learning robust models. In our paper, we benchmarked several existing algorithms for learning robust models, but found that they did not consistently improve upon standard models trained with empirical risk minimization (i.e., minimizing the average loss). We thus believe that there is substantial room for developing algorithms and model architectures that can close the gaps between in-distribution and out-of-distribution performance on the WILDS datasets.
Just in the past few months, WILDS has been used to develop methods for domain generalization—such as Fish, which introduces an inter-domain gradient matching objective and is currently state-of-the-art on our leaderboard for several datasets 9, and a Model-Based Domain Generalization (MBDG) approach that uses generative modeling 10—as well as for subpopulation shift settings through environment inference 11 or a variant of distributionally robust optimization 12. WILDS has also been used to develop methods for out-of-distribution calibration 13, uncertainty measurement 14, gradual domain adaptation 15, and self-training 16.
Finally, it has also been used to study out-of-distribution selective classification 17, and to investigate the relationship between in-distribution and out-of-distribution generalization 18.
However, we have only just begun to scratch the surface of how we can train models that are robust to the distribution shifts that are unavoidable in real-world applications, and we’re excited to see what the ML research community will come up with. If you’re interested in trying WILDS out, please check out https://wilds.stanford.edu, and let us know if you have any questions or feedback.
We’ll be presenting WILDS at ICML at 6pm Pacific Time on Thursday, July 22, 2021, with the poster session from 9pm to 11pm Pacific Time on the same day. If you’d like to find out more, please drop by https://icml.cc/virtual/2021/poster/10117! (The link requires ICML registration.)
Acknowledgements
WILDS is a large collaborative effort by researchers from Stanford, UC Berkeley, Cornell, INRAE, the University of Saskatchewan, the University of Tokyo, Recursion, Caltech, and Microsoft Research. This blog post is based on the WILDS paper:
WILDS: A Benchmark of in-the-Wild Distribution Shifts. Pang Wei Koh*, Shiori Sagawa*, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, Tony Lee, Etienne David, Ian Stavness, Wei Guo, Berton A. Earnshaw, Imran S. Haque, Sara Beery, Jure Leskovec, Anshul Kundaje, Emma Pierson, Sergey Levine, Chelsea Finn, and Percy Liang. ICML 2021.
We are grateful to the many people who generously volunteered their time and expertise to advise us on WILDS.
-
J. R. Zech, M. A. Badgeley, M. Liu, A. B. Costa, J. J. Titano, and E. K. Oermann. Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study. In PLOS Medicine, 2018. ↩
-
S. Beery, G. V. Horn, and P. Perona. Recognition in terra incognita. In European Conference on Computer Vision (ECCV), pages 456–473, 2018. ↩
-
J. Quiñonero-Candela, M. Sugiyama, A. Schwaighofer, and N. D. Lawrence. Dataset shift in machine learning. The MIT Press, 2009. ↩
-
W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec. Open Graph Benchmark: Datasets for machine learning on graphs. In Advances in Neural Information Processing Systems (NeurIPS), 2020. ↩
-
D. Borkan, L. Dixon, J. Sorensen, N. Thain, and L. Vasserman. Nuanced metrics for measuring unintended bias with real data for text classification. In WWW, pages 491–500, 2019. ↩
-
G. Christie, N. Fendley, J. Wilson, and R. Mukherjee. Functional map of the world. In Computer Vision and Pattern Recognition (CVPR), 2018. ↩
-
B. Kim, H. Kim, K. Kim, S. Kim, and J. Kim, 2019. Learning not to learn: Training deep neural networks with biased data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 9012-9020). ↩
-
S. M. Xie, A. Kumar, R. Jones, F. Khani, T. Ma, and P. Liang. In-N-Out: Pre-training and self-training using auxiliary information for out-of-distribution robustness. In International Conference on Learning Representations (ICLR), 2021. ↩
-
Y. Shi, J. Seely, P. H. Torr, N. Siddharth, A. Hannun, N. Usunier, and G. Synnaeve. Gradient Matching for Domain Generalization. arXiv preprint arXiv:2104.09937, 2021. ↩
-
A Robey, H. Hassani, and G. J. Pappas. Model-Based Robust Deep Learning. arXiv preprint arXiv:2005.10247, 2020. ↩
-
E. Creager, J. H. Jacobsen, and R. Zemel. Environment inference for invariant learning. In International Conference on Machine Learning, 2021. ↩
-
E. Liu, B. Haghgoo, A. Chen, A. Raghunathan, P. W. Koh, S. Sagawa, P. Liang, and C. Finn. Just Train Twice: Improving group robustness without training group information. In International Conference on Machine Learning (ICML), 2021. ↩
-
Y. Wald, A. Feder, D. Greenfeld, and U. Shalit. On calibration and out-of-domain generalization. arXiv preprint arXiv:2102.10395, 2021. ↩
-
E. Daxberger, A., Kristiadi, A., Immer, R., Eschenhagen, M., Bauer, and P. Hennig. Laplace Redux–Effortless Bayesian Deep Learning. arXiv preprint arXiv:2106.14806, 2021. ↩
-
S. Abnar, R. V. D. Berg, G. Ghiasi, M. Dehghani, N., Kalchbrenner, and H. Sedghi. Gradual Domain Adaptation in the Wild: When Intermediate Distributions are Absent. arXiv preprint arXiv:2106.06080, 2021. ↩
-
J. Chen, F. Liu, B. Avci, X. Wu, Y. Liang, and S. Jha. Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles. arXiv preprint arXiv:2106.15728, 2021. ↩
-
E. Jones, S. Sagawa, P. W. Koh, A. Kumar, and P. Liang. Selective classification can magnify disparities across groups. In International Conference on Learning Representations (ICLR), 2021. ↩
-
J. Miller, R. Taori, A. Raghunathan, S. Sagawa, P. W. Koh, V. Shankar, P. Liang, Y. Carmon, and L. Schmidt. Accuracy on the line: on the strong correlation between out-of-distribution and in-distribution generalization. In International Conference on Machine Learning (ICML), 2021. ↩