Modern computing workloads — including scientific simulations, visualization, data analytics, and machine learning — are pushing supercomputing centers, cloud providers and enterprises to rethink their computing architecture.
The processor or the network or the software optimizations alone can’t address the latest needs of researchers, engineers and data scientists. Instead, the data center is the new unit of computing, and organizations have to look at the full technology stack.
The latest rankings of the world’s most powerful systems show continued momentum for this full-stack approach in the latest generation of supercomputers.
NVIDIA technologies accelerate over 70 percent, or 355, of the systems on the TOP500 list released at the SC21 high performance computing conference this week, including over 90 percent of all new systems. That’s up from 342 systems, or 68 percent, of the machines on the TOP500 list released in June.
NVIDIA also continues to have a strong presence on the Green500 list of the most energy-efficient systems, powering 23 of the top 25 systems on the list, unchanged from June. On average, NVIDIA GPU-powered systems deliver 3.5x higher power efficiency than non-GPU systems on the list.
Highlighting the emergence of a new generation of cloud-native systems, Microsoft’s GPU-accelerated Azure supercomputer ranked 10th on the list, the first top 10 showing for a cloud-based system.
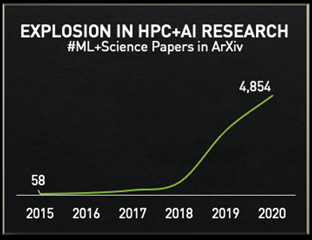
AI is revolutionizing scientific computing. The number of research papers leveraging HPC and machine learning has skyrocketed in recent years; growing from roughly 600 ML + HPC papers submitted in 2018 to nearly 5,000 in 2020.
The ongoing convergence of HPC and AI workloads is also underscored by new benchmarks such as HPL-AI and MLPerf HPC.
HPL-AI is an emerging benchmark of converged HPC and AI workloads that uses mixed-precision math — the basis of deep learning and many scientific and commercial jobs — while still delivering the full accuracy of double-precision math, which is the standard measuring stick for traditional HPC benchmarks.
And MLPerf HPC addresses a style of computing that speeds and augments simulations on supercomputers with AI, with the benchmark measuring performance on three key workloads for HPC centers: astrophysics (Cosmoflow), weather (Deepcam) and molecular dynamics (Opencatalyst).
NVIDIA addresses the full stack with GPU-accelerated processing, smart networking, GPU-optimized applications, and libraries that support the convergence of AI and HPC. This approach has supercharged workloads and enabled scientific breakthroughs.
Let’s look more closely at how NVIDIA is supercharging supercomputers.
Accelerated Computing
The combined power of the GPU’s parallel processing capabilities and over 2,500 GPU-optimized applications allows users to speed up their HPC jobs, in many cases from weeks to hours.
We’re constantly optimizing the CUDA-X libraries and the GPU-accelerated applications, so it’s not unusual for users to see an x-factor performance gain on the same GPU architecture.
As a result, the performance of the most widely used scientific applications — which we call the “golden suite” — has improved 16x over the past six years, with more advances on the way.
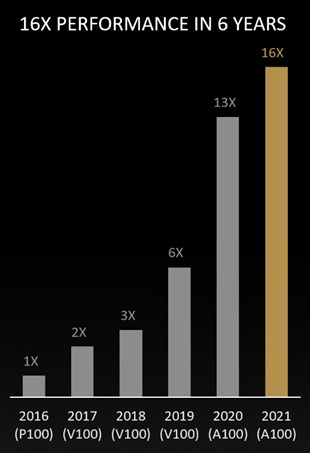
And to help users quickly take advantage of higher performance, we offer the latest versions of the AI and HPC software through containers from the NGC catalog. Users simply pull and run the application on their supercomputer, in the data center or the cloud.
Convergence of HPC and AI
The infusion of AI in HPC helps researchers speed up their simulations while achieving the accuracy they’d get with the traditional simulation approach.
That’s why an increasing number of researchers are taking advantage of AI to speed up their discoveries.
That includes four of the finalists for this year’s Gordon Bell prize, the most prestigious award in supercomputing. Organizations are racing to build exascale AI computers to support this new model, which combines HPC and AI.
That strength is underscored by relatively new benchmarks, such as HPL-AI and MLPerf HPC, highlighting the ongoing convergence of HPC and AI workloads.
To fuel this trend, last week NVIDIA announced a broad range of advanced new libraries and software development kits for HPC.
Graphs — a key data structure in modern data science — can now be projected into deep-neural network frameworks with Deep Graph Library, or DGL, a new Python package.
NVIDIA Modulus builds and trains physics-informed machine learning models that can learn and obey the laws of physics.
And NVIDIA introduced three new libraries:
- ReOpt – to increase operational efficiency for the $10 trillion logistics industry.
- cuQuantum – to accelerate quantum computing research.
- cuNumeric – to accelerate NumPy for scientists, data scientists, and machine learning and AI researchers in the Python community.
Weaving it all together is NVIDIA Omniverse — the company’s virtual world simulation and collaboration platform for 3D workflows.
Omniverse is used to simulate digital twins of warehouses, plants and factories, of physical and biological systems, of the 5G edge, robots, self-driving cars and even avatars.
Using Omniverse, NVIDIA announced last week that it will build a supercomputer, called Earth-2, devoted to predicting climate change by creating a digital twin of the planet.
Cloud-Native Supercomputing
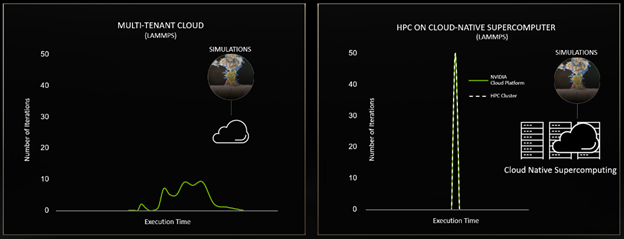
As supercomputers take on more workloads across data analytics, AI, simulation and visualization, CPUs are stretched to support a growing number of communication tasks needed to operate large and complex systems.
Data processing units alleviate this stress by offloading some of these processes.
As a fully integrated data-center-on-a-chip platform, NVIDIA BlueField DPUs can offload and manage data center infrastructure tasks instead of making the host processor do the work, enabling stronger security and more efficient orchestration of the supercomputer.
Combined with NVIDIA Quantum InfiniBand platform, this architecture delivers optimal bare-metal performance while natively supporting multinode tenant isolation.
Thanks to a zero-trust approach, these new systems are also more secure.
BlueField DPUs isolate applications from infrastructure. NVIDIA DOCA 1.2 — the latest BlueField software platform — enables next-generation distributed firewalls and wider use of line-rate data encryption. And NVIDIA Morpheus, assuming an interloper is already inside the data center, uses deep learning-powered data science to detect intruder activities in real time.
And all of the trends outlined above will be accelerated by new networking technology.
NVIDIA Quantum-2, also announced last week, is a 400Gbps InfiniBand platform and consists of the Quantum-2 switch, the ConnectX-7 NIC, the BlueField-3 DPU, as well as new software for the new networking architecture.
NVIDIA Quantum-2 offers the benefits of bare-metal high performance and secure multi-tenancy, allowing the next generation of supercomputers to be secure, cloud-native and better utilized.
** Benchmark applications: Amber, Chroma, GROMACS, MILC, NAMD, PyTorch, Quantum Espresso; Random Forest FP32 , TensorFlow, VASP | GPU node: dual-socket CPUs with 4x P100, V100, or A100 GPUs.
The post World’s Fastest Supercomputers Changing Fast appeared first on The Official NVIDIA Blog.