Amazon SageMaker Data Wrangler is a new capability of Amazon SageMaker that makes it faster for data scientists and engineers to prepare data for machine learning (ML) applications by using a visual interface. It contains over 300 built-in data transformations so you can quickly normalize, transform, and combine features without having to write any code.
Today, we’re excited to announce new transformations that allow you to balance your datasets easily and effectively for ML model training. We demonstrate how these transformations work in this post.
New balancing operators
The newly announced balancing operators are grouped under the Balance data transform type in the ADD TRANFORM pane.

Currently, the transform operators support only binary classification problems. In binary classification problems, the classifier is tasked with classifying each sample to one of two classes. When the number of samples in the majority class (bigger) is considerably larger than the number of samples in the minority (smaller) class, the dataset is considered imbalanced. This skew is challenging for ML algorithms and classifiers because the training process tends to be biased towards the majority class.
Balancing schemes, which augment the data to be more balanced before training the classifier, were proposed to address this challenge. The simplest balancing methods are either oversampling the minority class by duplicating minority samples or undersampling the majority class by removing majority samples. The idea of adding synthetic minority samples to tabular data was first proposed in the Synthetic Minority Oversampling Technique (SMOTE), where synthetic minority samples are created by interpolating pairs of the original minority points. SMOTE and other balancing schemes were extensively studied empirically and shown to improve prediction performance in various scenarios, as per the publication To SMOTE, or not to SMOTE.
Data Wrangler now supports the following balancing operators as part of the Balance data transform:
- Random oversampler – Randomly duplicate minority samples
- Random undersampler – Randomly remove majority samples
- SMOTE – Generate synthetic minority samples by interpolating real minority samples

Let’s now discuss the different balancing operators in detail.
Random oversample
Random oversampling includes selecting random examples from the minority class with a replacement and supplementing the training data with multiple copies of this instance. Therefore, it’s possible that a single instance may be selected multiple times. With the Random oversample transform type, Data Wrangler automatically oversamples the minority class for you by duplicating the minority samples in your dataset.
Random undersample
Random undersampling is the opposite of random oversampling. This method seeks to randomly select and remove samples from the majority class, consequently reducing the number of examples in the majority class in the transformed data. The Random undersample transform type lets Data Wrangler automatically undersample the majority class for you by removing majority samples in your dataset.
SMOTE
In SMOTE, synthetic minority samples are added to the data to achieve the desired ratio between majority and minority samples. The synthetic samples are generated by interpolation of pairs of the original minority points. The SMOTE transform supports balancing datasets including numeric and non-numeric features. Numeric features are interpolated by weighted average. However, you can’t apply weighted average interpolation to non-numeric features—it’s impossible to average “dog” and “cat” for example. Instead, non-numeric features are copied from either original minority sample according to the averaging weight.
For example, consider two samples, A and B:
Assume the samples are interpolated with weights 0.3 for sample A and 0.7 for sample B. Therefore, the numeric fields are averaged with these weights to yield 0.3 and 0.6, respectively. The next field is filled with “dog” with probability 0.3 and “cow” with probability 0.7. Similarly, the next one equals “carnivore” with probability 0.3 and “herbivore” with probability 0.7. The random copying is done independently for each feature, so sample C below is a possible result:
This example demonstrates how the interpolation process could result in unrealistic synthetic samples, such as an herbivore dog. This is more common with categorical features but can occur in numeric features as well. Even though some synthetic samples may be unrealistic, SMOTE could still improve classification performance.
To heuristically generate more realistic samples, SMOTE interpolates only pairs that are close in features space. Technically, each sample is interpolated only with its k-nearest neighbors, where a common value for k is 5. In our implementation of SMOTE, only the numeric features are used to calculate the distances between points (the distances are used to determine the neighborhood of each sample). It’s common to normalize the numeric features before calculating distances. Note that the numeric features are normalized only for the purpose of calculating the distance; the resulting interpolated features aren’t normalized.
Let’s now balance the Adult Dataset (also known as the Census Income dataset) using the built-in SMOTE transform provided by Data Wrangler. This multivariate dataset includes six numeric features and eight string features. The goal of the dataset is a binary classification task to predict whether the income of an individual exceeds $50,000 per year or not based on census data.
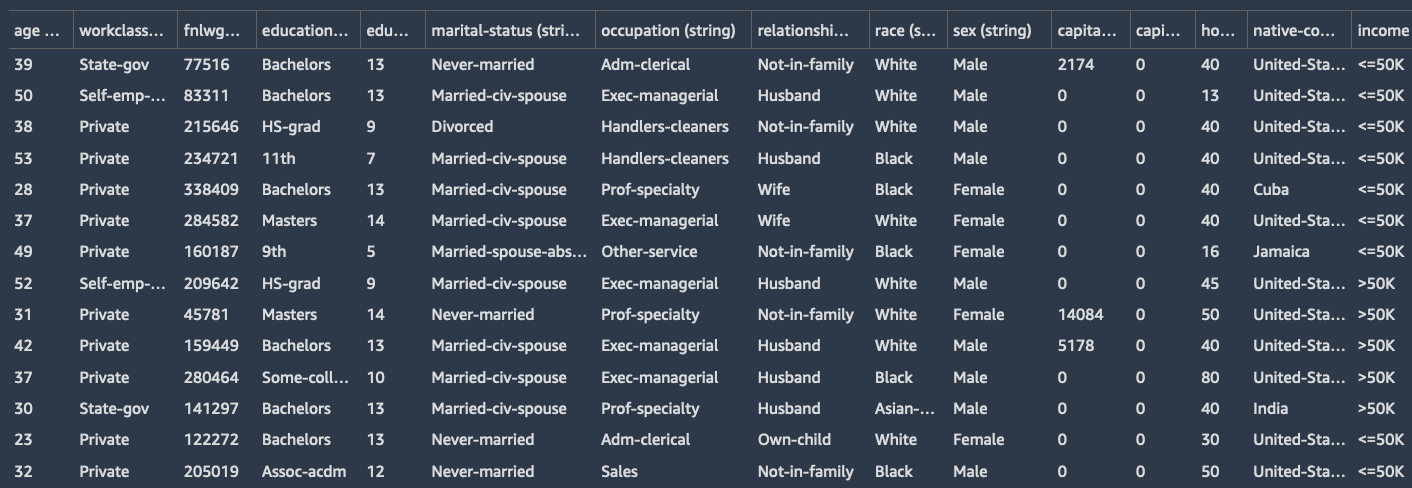
You can also see the distribution of the classes visually by creating a histogram using the histogram analysis type in Data Wrangler. The target distribution is imbalanced and the ratio of records with >50K to <=50K is about 1:4.

We can balance this data using the SMOTE operator found under the Balance Data transform in Data Wrangler with the following steps:
- Choose
incomeas the target column.
We want the distribution of this column to be more balanced.
- Set the desired ratio to
0.66.
Therefore, the ratio between the number of minority and majority samples is 2:3 (instead of the raw ratio of 1:4).
- Choose SMOTE as the transform to use.
- Leave the default values for Number of neighbors to average and whether or not to normalize.

- Choose Preview to get a preview of the applied transformation and choose Add to add the transform to your data flow.
Now we can create a new histogram similar to what we did before to see the realigned distribution of the classes. The following figure shows the histogram of the income column after balancing the dataset. The distribution of samples is now 3:2, as was intended.

We can now export this new balanced data and train a classifier on it, which could yield superior prediction quality.
Conclusion
In this post, we demonstrated how to balance imbalanced binary classification data using Data Wrangler. Data Wrangler offers three balancing operators: random undersampling, random oversampling, and SMOTE to rebalance data in your unbalanced datasets. All three methods offered by Data Wrangler support multi-modal data including numeric and non-numeric features.
As next steps, we recommend you replicate the example in this post in your Data Wrangler data flow to see what we discussed in action. If you’re new to Data Wrangler or SageMaker Studio, refer to Get Started with Data Wrangler. If you have any questions related to this post, please add it in the comment section.
About the Authors
 Yotam Elor is a Senior Applied Scientist at Amazon SageMaker. His research interests are in machine learning, particularly for tabular data.
Yotam Elor is a Senior Applied Scientist at Amazon SageMaker. His research interests are in machine learning, particularly for tabular data.
 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.