Predictive maintenance can be an effective way to prevent industrial machinery failures and expensive downtime by proactively monitoring the condition of your equipment, so you can be alerted to any anomalies before equipment failures occur. Installing sensors and the necessary infrastructure for data connectivity, storage, analytics, and alerting are the foundational elements for enabling predictive maintenance solutions. However, even after installing the ad hoc infrastructure, many companies use basic data analytics and simple modeling approaches that are often ineffective at detecting issues early enough to avoid downtime. Also, implementing a machine learning (ML) solution for your equipment can be difficult and time-consuming.
With Amazon Lookout for Equipment, you can automatically analyze sensor data for your industrial equipment to detect abnormal machine behavior—with no ML experience required. This means you can detect equipment abnormalities with speed and precision, quickly diagnose issues, and take action to reduce expensive downtime.
Lookout for Equipment analyzes the data from your sensors and systems, such as pressure, flow rate, RPMs, temperature, and power, to automatically train a model specific to your equipment based on your data. It uses your unique ML model to analyze incoming sensor data in real time and identifies early warning signs that could lead to machine failures. For each alert detected, Lookout for Equipment pinpoints which specific sensors are indicating the issue, and the magnitude of impact on the detected event.
With a mission to put ML in the hands of every developer, we want to present another add-on to Lookout for Equipment: an open-source Python toolbox that allows developers and data scientists to build, train, and deploy Lookout for Equipment models similarly to what you’re used to with Amazon SageMaker. This library is a wrapper on top of the Lookout for Equipment boto3 python API and is provided to kick start your journey with this service. Should you have any improvement suggestions or bugs to report, please file an issue against the toolbox GitHub repository.
In this post, we provide a step-by-step guide for using the Lookout for Equipment open-source Python toolbox from within a SageMaker notebook.
Environment setup
To use the open-source Lookout for Equipment toolbox from a SageMaker notebook, we need to grant the SageMaker notebook the necessary permissions for calling Lookout for Equipment APIs. For this post, we assume that you have already created a SageMaker notebook instance. For instructions, refer to Get Started with Amazon SageMaker Notebook Instances. The notebook instance is automatically associated with an execution role.
- To find the role that is attached to the instance, select the instance on the SageMaker console.

- On the next screen, scroll down to find the AWS Identity and Access Management (IAM) role attached to the instance in the Permissions and encryption section.
- Choose the role to open the IAM console.

Next, we attach an inline policy to our SageMaker IAM role.
- On the Permissions tab of the role you opened, choose Add inline policy.
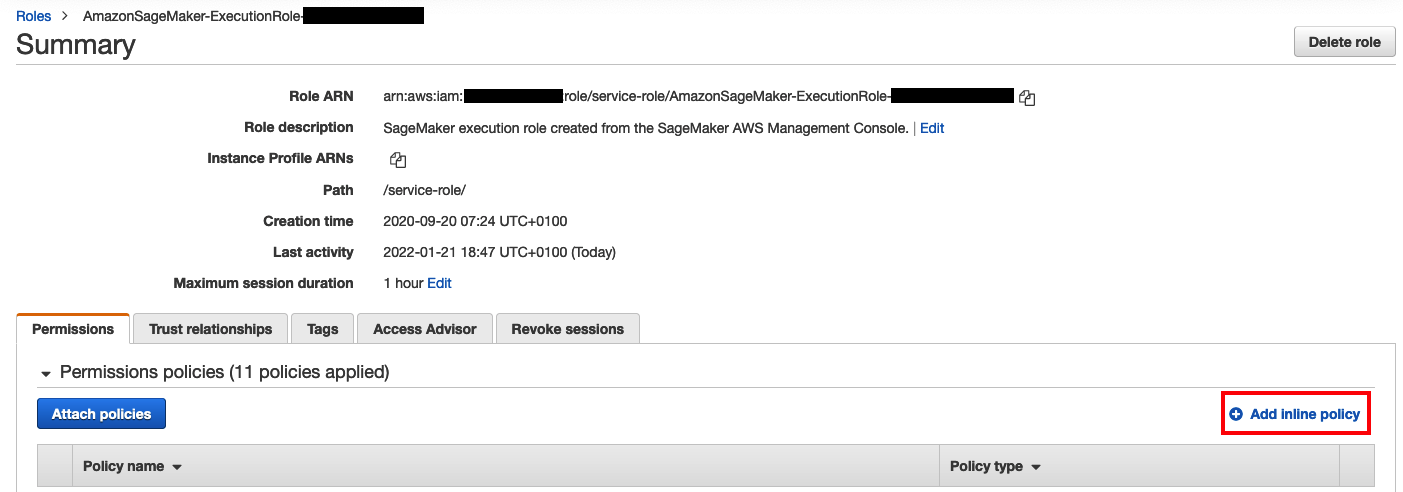
- On the JSON tab, enter the following code. We use a wild card action (
lookoutequipment:*) for the service for demo purposes. For real use cases, provide only the required permissions to run the appropriate SDK API calls. - Choose Review policy.
- Provide a name for the policy and create the policy.
In addition to the preceding inline policy, on the same IAM role, we need to set up a trust relationship to allow Lookout for Equipment to assume this role. The SageMaker role already has the appropriate data access to Amazon Simple Storage Service (Amazon S3); allowing Lookout for Equipment to assume this role makes sure it has the same access to the data than your notebook. In your environment, you may already have a specific role ensuring Lookout for Equipment has access to your data, in which case you don’t need to adjust the trust relationship of this common role.
- Inside our SageMaker IAM role on the Trust relationships tab, choose Edit trust relationship.
- Under the policy document, replace the whole policy with the following code:
- Choose Update trust policy.
Now we’re all set to use the Lookout for Equipment toolbox in our SageMaker notebook environment. The Lookout for Equipment toolbox is an open-source Python package that allows data scientists and software developers to easily build and deploy time series anomaly detection models using Lookout for Equipment. Let’s look at what you can achieve more easily thanks to the toolbox!
Dependencies
At the time of writing, the toolbox needs the following installed:
After you satisfy these dependencies, you can install and launch the Lookout for Equipment toolbox with the following command from a Jupyter terminal:
The toolbox is now ready to use. In this post, we demonstrate how to use the toolbox by training and deploying an anomaly detection model. A typical ML development lifecycle consists of building the dataset for training, training the model, deploying the model, and performing inference on the model. The toolbox is quite comprehensive in terms of the functionalities it provides, but in this post, we focus on the following capabilities:
- Prepare the dataset
- Train an anomaly detection model using Lookout for Equipment
- Build visualizations for your model evaluation
- Configure and start an inference scheduler
- Visualize scheduler inferences results
Let’s understand how we can use the toolbox for each of these capabilities.
Prepare the dataset
Lookout for Equipment requires a dataset to be created and ingested. To prepare the dataset, complete the following steps:
- Before creating the dataset, we need to load a sample dataset and upload it to an Amazon Simple Storage Service (Amazon S3) bucket. In this post, we use the
expanderdataset:
The returned data object represents a dictionary containing the following:
-
- A training data DataFrame
- A labels DataFrame
- The training start and end datetimes
- The evaluation start and end datetimes
- A tags description DataFrame
The training and label data are uploaded from the target directory to Amazon S3 at the bucket/prefix location.
- After uploading the dataset in S3, we create an object of
LookoutEquipmentDatasetclass that manages the dataset:
The access_role_arn supplied must have access to the S3 bucket where the data is present. You can retrieve the role ARN of the SageMaker notebook instance from the previous Environment setup section and add an IAM policy to grant access to your S3 bucket. For more information, see Writing IAM Policies: How to Grant Access to an Amazon S3 Bucket.
The component_root_dir parameter should indicate the location in Amazon S3 where the training data is stored.
After we launch the preceding APIs, our dataset has been created.
- Ingest the data into the dataset:
Now that your data is available on Amazon S3, creating a dataset and ingesting the data in it is just a matter of three lines of code. You don’t need to build a lengthy JSON schema manually; the toolbox detects your file structure and builds it for you. After your data is ingested, it’s time to move to training!
Train an anomaly detection model
After the data has been ingested in the dataset, we can start the model training process. See the following code:
Before we launch the training, we need to specify the training and evaluation periods within the dataset. We also set the location in Amazon S3 where the labeled data is stored and set the sampling rate to 5 minutes. After we launch the training, the poll_model_training polls the training job status every 5 minutes until the training is successful.
The training module of the Lookout for Equipment toolbox allows you to train a model with less than 10 lines of code. It builds all the length creation request strings needed by the low-level API on your behalf, removing the need for you to build long, error-prone JSON documents.
After the model is trained, we can either check the results over the evaluation period or configure an inference scheduler using the toolbox.
Evaluate a trained model
After a model is trained, the DescribeModel API from Lookout for Equipment records the metrics associated to the training. This API returns a JSON document with two fields of interest to plot the evaluation results: labeled_ranges and predicted_ranges, which contain the known and predicted anomalies in the evaluation range, respectively. The toolbox provides utilities to load these in a Pandas DataFrame instead:
The advantage of loading the ranges in a DataFrame is that we can create nice visualizations by plotting one of the original time series signals and add an overlay of the labeled and predicted anomalous events by using the TimeSeriesVisualization class of the toolbox:
These few lines of code generate a plot with the following features:
- A line plot for the signal selected; the part used for training the model appears in blue while the evaluation part is in gray
- The rolling average appears as a thin red line overlaid over the time series
- The labels are shown in a green ribbon labelled “Known anomalies” (by default)
- The predicted events are shown in a red ribbon labelled “Detected events”
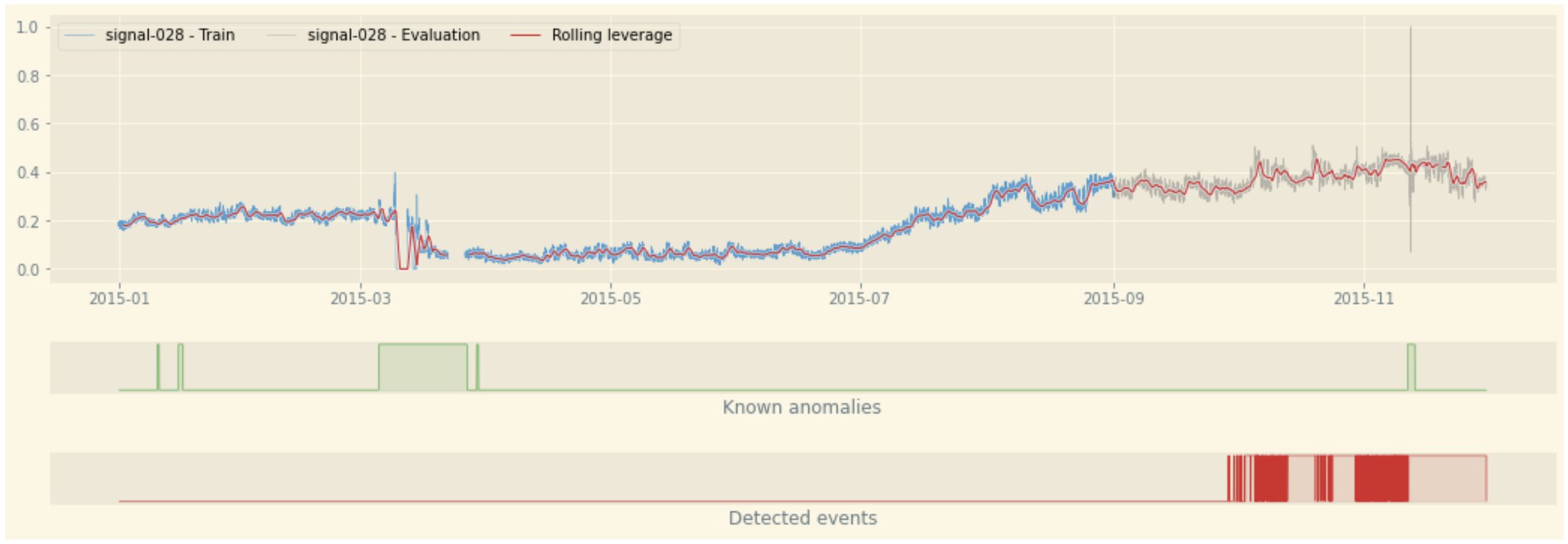
The toolbox performs all the heavy lifting of locating, loading, and parsing the JSON files while providing ready-to-use visualizations that further reduce the time to get insights from your anomaly detection models. At this stage, the toolbox lets you focus on interpreting the results and taking actions to deliver direct business value to your end-users. In addition to these time series visualizations, the SDK provides other plots such as a histogram comparison of the values of your signals between normal and abnormal times. To learn more about the other visualization capabilities you can use right out of the box, see the Lookout for Equipment toolbox documentation.
Schedule inference
Let’s see how we can schedule inferences using the toolbox:
This code creates a scheduler that processes one file every 5 minutes (matching the upload frequency set when configuring the scheduler). After 15 minutes or so, we should have some results available. To get these results from the scheduler in a Pandas DataFrame, we just have to run the following command:
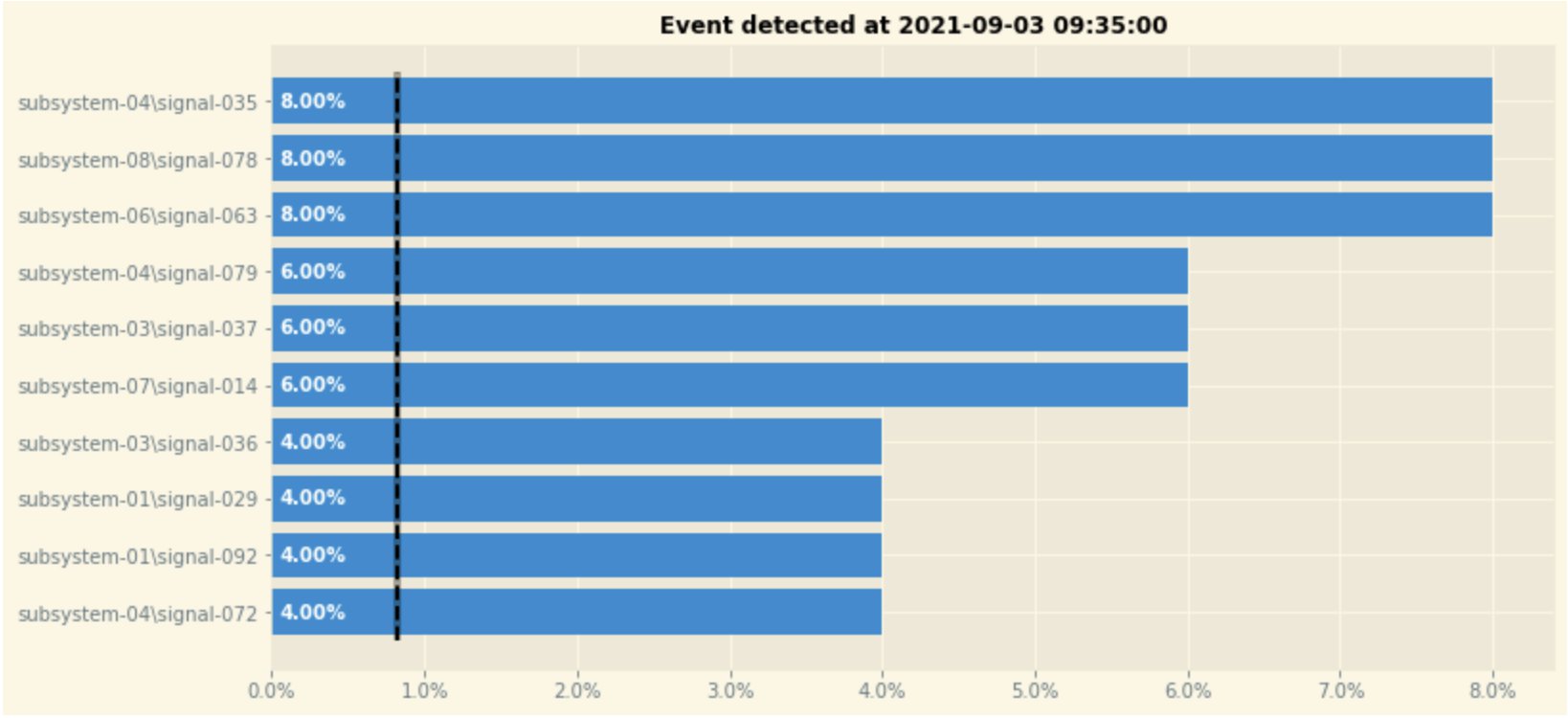
From here, we can also plot the feature importance for a prediction using the visualization APIs of the toolbox:
It produces the following feature importance visualization on the sample data.
The toolbox also provides an API to stop the scheduler. See the following code snippet:
Clean up
To delete all the artifacts created previously, we can call the delete_dataset API with the name of our dataset:
Conclusion
When speaking to industrial and manufacturing customers, a common challenge we hear regarding taking advantage of AI and ML is the sheer amount of customization and specific development and data science work needed to obtain reliable and actionable results. Training anomaly detection models and getting actionable forewarning for many different industrial machineries is a prerequisite to reduce maintenance effort, reduce rework or waste, increase product quality, and improve overall equipment efficiency (OEE) or product lines. Until now, this required a massive amount of specific development work, which is hard to scale and maintain over time.
Amazon Applied AI services such as Lookout for Equipment enables manufacturers to build AI models without having access to a versatile team of data scientists, data engineers, and process engineers. Now, with the Lookout for Equipment toolbox, your developers can further reduce the time needed to explore insights in your time series data and take action. This toolbox provides an easy-to-use, developer-friendly interface to quickly build anomaly detection models using Lookout for Equipment. The toolbox is open source and all the SDK code can be found on the amazon-lookout-for-equipment-python-sdk GitHub repo. It’s also available as a PyPi package.
This post covers only few of the most important APIs. Interested readers can check out the toolbox documentation to look at more advanced capabilities of the toolbox. Give it a try, and let us know what you think in comments!
About the Authors
 Vikesh Pandey is a Machine Learning Specialist Specialist Solutions Architect at AWS, helping customers in the UK and wider EMEA region design and build ML solutions. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
Vikesh Pandey is a Machine Learning Specialist Specialist Solutions Architect at AWS, helping customers in the UK and wider EMEA region design and build ML solutions. Outside of work, Vikesh enjoys trying out different cuisines and playing outdoor sports.
 Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
Ioan Catana is an Artificial Intelligence and Machine Learning Specialist Solutions Architect at AWS. He helps customers develop and scale their ML solutions in the AWS Cloud. Ioan has over 20 years of experience, mostly in software architecture design and cloud engineering.
 Michaël Hoarau is an AI/ML Specialist Solutions Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the power of AI/ML to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.
Michaël Hoarau is an AI/ML Specialist Solutions Architect at AWS who alternates between data scientist and machine learning architect, depending on the moment. He is passionate about bringing the power of AI/ML to the shop floors of his industrial customers and has worked on a wide range of ML use cases, ranging from anomaly detection to predictive product quality or manufacturing optimization. When not helping customers develop the next best machine learning experiences, he enjoys observing the stars, traveling, or playing the piano.