This is a guest post by Kustomer’s Senior Software & Machine Learning Engineer, Ian Lantzy, and AWS team Umesh Kalaspurkar, Prasad Shetty, and Jonathan Greifenberger.
In Kustomer’s own words, “Kustomer is the omnichannel SaaS CRM platform reimagining enterprise customer service to deliver standout experiences. Built with intelligent automation, we scale to meet the needs of any contact center and business by unifying data from multiple sources and enabling companies to deliver effortless, consistent, and personalized service and support through a single timeline view.”
Kustomer wanted the ability to rapidly analyze large volumes of support communications for their business customers — customer experience and service organizations — and automate discovery of information such as the end-customer’s intent, customer service issue, and other relevant insights related to the consumer. Understanding these characteristics can help CX organizations manage thousands of in-bound support emails by automatically classifying and categorizing the content. Kustomer leverages Amazon SageMaker to manage the analysis of the incoming support communications via their AI based Kustomer IQ platform. Kustomer IQ’s Conversation Classification service is able to contextualize conversations and automate otherwise tedious and repetitive tasks, reducing agent distraction and the overall cost per contact. This and Kustomer’s other IQ services have increased productivity and automation for its business customers.
In this post, we talk about how Kustomer uses custom Docker images for SageMaker training and inference, which eases integration and streamlines the process. With this approach, Kustomer’s business customers are automatically classifying over 50k support emails each month with up to 70% accuracy.
Background and challenges
Kustomer uses a custom text classification pipeline for their Conversation Classification service. This helps them manage thousands of requests a day via automatic classification and categorization utilizing SageMaker’s training and inference orchestration. The Conversation Classification training engine uses custom Docker images to process data and train models using historical conversations and then predicts the topics, categories, or other custom labels a particular agent needs in order to classify the conversations. Then the prediction engine utilizes the trained models with another custom docker image to categorize conversations, which organizations use to automate reporting or route conversations to a specific team based on its topic.
The SageMaker categorization process starts by establishing a training and inference pipeline that can provide text classification and contextual recommendations. A typical setup would be implemented with serverless approaches like AWS Lambda for data preprocessing and postprocessing because it has a minimal provisioning requirement with an effective on-demand pricing model. However, using SageMaker with dependencies such as TensorFlow, NumPy, and Pandas can quickly increase the model package size, making the overall deployment process cumbersome and difficult to manage. Kustomer used custom Docker images to overcome these challenges.
Custom Docker images provide substantial advantages:
- Allows for larger compressed package sizes (over 10 GB), which can contain popular machine learning (ML) frameworks such as TensorFlow, MXNet, PyTorch, or others.
- Allows you to bring custom code or algorithms developed locally to Amazon SageMaker Studio notebooks for rapid iteration and model training.
- Avoids preprocessing delays caused in Lambda while unpacking deployment packages.
- Offers flexibility to integrate seamlessly with internal systems.
- Future compatibility and scalability make it easier to convert a service using Docker rather than having to package .zip files in a Lambda function.
- Reduces the turnaround time for a CI/CD deployment pipeline.
- Provides Docker familiarity within the team and ease of use.
- Provides access to data stores via APIs and a backend runtime.
- Offers better support for intervening for any preprocessing or postprocessing that Lambda would require a separate compute service for each process (such as training or deployment).
Solution overview
Categorization and labeling of support emails is a critical step in the customer support process. It allows companies to route conversations to the right teams, and understand at a high level what their customers are contacting them about. Kustomer’s business customers handle thousands of conversations every day, so classifying at scale is a challenge. Automating this process helps agents be more effective and provide more cohesive support, and helps their customers by connecting them with the right people faster.
The following diagram illustrates the solution architecture:
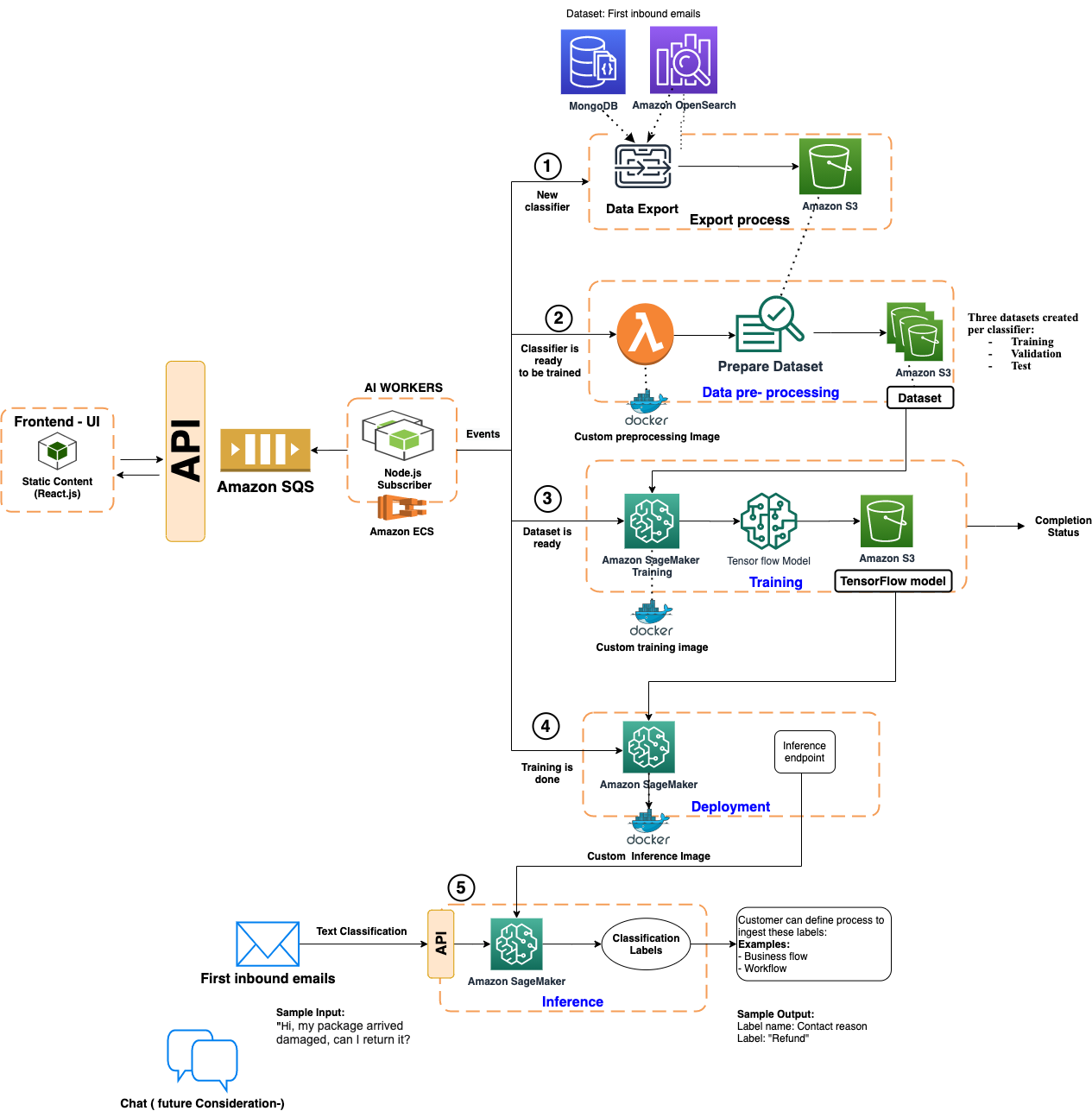
The Conversation Classification process starts with the business customer giving Kustomer permission to set up a training and inference pipeline that can help them with text classification and contextual recommendations. Kustomer exposes a user interface to their customers to monitor the training and inference process, which is implemented using SageMaker along with TensorFlow models and custom Docker images. The process of building and utilizing a classifier is split into five main workflows, which are coordinated by a worker service running on Amazon ECS. To coordinate the pipeline events and trigger the training and deployment of the model, the worker uses an Amazon SQS queue and integrates directly with SageMaker using the AWS-provided Node.js SDK. The workflows are:
- Data export
- Data preprocessing
- Training
- Deployment
- Inference
Data export
The data export process is run on demand and starts with an approval process from Kustomer’s business customer to confirm the use of email data for analysis. Data relevant to the classification process is captured via the initial email received from the end customer. For example, a support email typically contains the complete coherent thought of the problem with details about the issue. As part of the export process, the emails are collated from the data store (MongoDB and Amazon OpenSearch) and saved in Amazon Simple Storage Service (Amazon S3).
Data preprocessing
The data preprocessing stage cleans the dataset for training and inference workflows by stripping any HTML tags from customer emails and feeding them through multiple cleaning and sanitization steps to detect any malformed HTML. This process includes the use of Hugging Face tokenizers and transformers. When the cleansing process is complete, any additional custom tokens required for training are added to the output dataset.
During the preprocessing stage, a Lambda function invokes a custom Docker image. This image consists of a Python 3.8 slim base, the AWS Lambda Python Runtime Interface Client, and dependencies such as NumPy and Pandas. The custom Docker image is stored on Amazon Elastic Container Registry (Amazon ECR) and then fed through the CI/CD pipeline for deployment. The deployed Lambda function samples the data to generate three distinct datasets per classifier:
- Training – Used for the actual training process
- Validation – Used for validation during the TensorFlow training process
- Test – Used towards the end of the training process for metrics model comparisons
The generated output datasets are Pandas pickle files, which are stored in Amazon S3 to be used by the training stage.
Training
Kustomer’s custom training image utilizes a TensorFlow 2.7 GPU-optimized docker image as a base. Custom code, dependencies, and base models are included before the custom docker training image is uploaded to ECR. P3 instance types are used for the training process and using a GPU optimized base image helps to make the training process as efficient as possible. Amazon SageMaker is used with this custom docker image to train TensorFlow models that are then stored in S3. Custom metrics are also computed and saved to help with additional capabilities such as model comparisons and automatic retraining. Once the training stage is completed, the AI worker is notified and the business customer is able to start the deployment workflow.
Deployment
For the deployment workflow, a custom docker inference image is created using a TensorFlow serving base image (built specifically for fast inference). Additional code and dependencies like numPy, Pandas, custom NL, etc. are included to provide additional functionality, such as formatting & cleaning inputs before inference. FastAPI is also included as part of the custom image, and is used to provide the REST API endpoints for inference and health checks. SageMaker is then configured to deploy the TensorFlow models saved in S3 with the inference image onto compute optimized ml.c5 AWS instances to generate high-performance inference endpoints. Each endpoint is created for use by a single customer to isolate their models and data.
Inference
Once the deployment workflow is completed, the inference workflow takes over. All first inbound support emails are passed through the inference API for the deployed classifiers specific to that customer. The deployed classifiers then perform text classification on each of these emails, each generating classification labels for the customer.
Possible enhancements and customizations
Kustomer is considering expanding the solution with the following enhancements:
- Hugging Face DLCs – Kustomer currently uses TensorFlow’s base Docker images for the data preprocessing stage and plans to migrate to Hugging Face Deep Learning Containers (DLCs). This helps you start training models immediately, skipping the complicated process of building and optimizing your training environments from scratch. For more information, see Hugging Face on Amazon SageMaker.
- Feedback loop – You can implement a feedback loop using active learning or reinforcement learning techniques to increase the overall efficiency of the model.
- Integration with other internal systems – Kustomer wants the ability to integrate the text classification with other systems like Smart Suggestions, which is another Kustomer IQ service that looks through hundreds of shortcuts and suggest the shortcuts that are most relevant to a customer query, improving agent response times and performance.
Conclusion
In this post, we discussed how Kustomer uses custom Docker images for SageMaker training and inference, which eases integration and streamlines the process. We demonstrated how Kustomer leverages Lambda and SageMaker with custom Docker images that help implement the text classification process with preprocessing and postprocessing workflows. This provides flexibility for using larger images for model creation, training, and inference. Container image support for Lambda allows you to customize your function even more, opening up many new use cases for serverless ML. The solution takes advantage of several AWS services, including SageMaker, Lambda, Docker images, Amazon ECR, Amazon ECS, Amazon SQS, and Amazon S3.
If you want to learn more about Kustomer, we encourage you to visit the Kustomer website and explore their case studies.
Click here to start your journey with Amazon SageMaker. For hands-on experience, you can reference the Amazon SageMaker workshop.
About the Authors
 Umesh Kalaspurkar is a New York based Solutions Architect for AWS. He brings more than 20 years of experience in design and delivery of Digital Innovation and Transformation projects, across enterprises and startups. He is motivated by helping customers identify and overcome challenges. Outside of work, Umesh enjoys being a father, skiing, and traveling.
Umesh Kalaspurkar is a New York based Solutions Architect for AWS. He brings more than 20 years of experience in design and delivery of Digital Innovation and Transformation projects, across enterprises and startups. He is motivated by helping customers identify and overcome challenges. Outside of work, Umesh enjoys being a father, skiing, and traveling.
 Ian Lantzy is a Senior Software & Machine Learning engineer for Kustomer and specializes in taking machine learning research tasks and turning them into production services.
Ian Lantzy is a Senior Software & Machine Learning engineer for Kustomer and specializes in taking machine learning research tasks and turning them into production services.
 Prasad Shetty is a Boston-based Solutions Architect for AWS. He has built software products and has led modernizing and digital innovation in product and services across enterprises for over 20 years. He is passionate about driving cloud strategy and adoption, and leveraging technology to create great customer experiences. In his leisure time, Prasad enjoys biking and traveling.
Prasad Shetty is a Boston-based Solutions Architect for AWS. He has built software products and has led modernizing and digital innovation in product and services across enterprises for over 20 years. He is passionate about driving cloud strategy and adoption, and leveraging technology to create great customer experiences. In his leisure time, Prasad enjoys biking and traveling.
 Jonathan Greifenberger is a New York based Senior Account Manager for AWS with 25 years of IT industry experience. Jonathan leads a team that assists clients from various industries and verticals on their cloud adoption and modernization journey.
Jonathan Greifenberger is a New York based Senior Account Manager for AWS with 25 years of IT industry experience. Jonathan leads a team that assists clients from various industries and verticals on their cloud adoption and modernization journey.