Posted by Khanh LeViet, Developer Advocate
 TensorFlow Lite is the official framework to run inference with TensorFlow models on edge devices. TensorFlow Lite is deployed on more than 4 billions edge devices worldwide, supporting Android, iOS, Linux-based IoT devices and microcontrollers.
TensorFlow Lite is the official framework to run inference with TensorFlow models on edge devices. TensorFlow Lite is deployed on more than 4 billions edge devices worldwide, supporting Android, iOS, Linux-based IoT devices and microcontrollers.
Since first launch in late 2017, we have been improving TensorFlow Lite to make it robust while keeping it easy to use for all developers – from the machine learning experts to the mobile developers who just started learning about machine learning.
In this blog, we will highlight recent launches that made it easier for you to go from prototyping an on-device use case to deploying in production.  If you prefer a video format, check out this talk from TensorFlow DevSummit 2020.
If you prefer a video format, check out this talk from TensorFlow DevSummit 2020.
Prototype: jump-start with state-of-the-art models
As machine learning is a very fast-moving field, it is very important to be able to know what is possible with current technologies before investing resources into building a feature. We have a repository of pretrained models and sample applications that implement the models so that you can try out TensorFlow Lite models on real devices without writing any code. Then, you can quickly integrate the models into your application to prototype and test how your user experiences will be like before spending time on training your own model.
We have published several new pretrained models, including a question & answer model and a style transfer model.
We are also committed to bringing more state-of-the-art models from research teams to TensorFlow Lite. Recently we have enabled 3 new model architectures: EfficientNet-Lite (paper), MobileBERT (paper) and ALBERT-Lite (paper).
- EfficientNet-Lite is a novel image classification model that achieves state-of-the-art accuracy with an order of magnitude of fewer computations and parameters. It is optimized for TensorFlow Lite, supporting quantization with negligible accuracy loss and fully supported by the GPU delegate for faster inference. Find out more in our blog post.

Benchmark on Pixel 4 CPU, 4 Threads, March 2020 - MobileBERT is an optimized version of the popular BERT (paper) model that achieved state-of-the-art accuracy on a range of NLP tasks, including question and answer, natural language inference and others. MobileBERT is about 4x faster and smaller than BERT but retains similar accuracy.
- ALBERT is another light-weight version of the BERT that was optimized for model size while retaining the same accuracy. ALBERT-Lite is the TensorFlow Lite compatible version of ALBERT, which is 6x smaller than BERT, or 1.5x smaller than MobileBERT, while the latency is on par with BERT.
 |
| Benchmark on Pixel 4 CPU, 4 Threads, March 2020 Model hyper parameters: Sequence length 128, Vocab size 30K |
Develop model: without ML expertise, create models for your dataset
When bringing state-of-the-art research models to TensorFlow Lite, we also want to make it easier for you to customize these models to your own use cases. We are excited to announce TensorFlow Lite Model Maker, an easy-to-use tool to adapt state-of-the-art machine learning models to your dataset with transfer learning. It wraps the complex machine learning concepts with an intuitive API, so that everyone can get started without any machine learning expertise. You can train a state-of-the-art image classification with only 4 lines of code:
data = ImageClassifierDataLoader.from_folder('flower_photos/')
model = image_classifier.create(data)
loss, accuracy = model.evaluate()
model.export('flower_classifier.tflite', 'flower_label.txt', with_metadata=True)Model Maker supports many state-of-the-art models that are available on TensorFlow Hub, including the EfficientNet-Lite models. If you want to get higher accuracy, you can switch to a different model architecture by changing just one line of code while keeping the rest of your training pipeline.
# EfficinetNet-Lite2.
model = image_classifier.create(data, efficientnet_lite2_spec)
# ResNet 50.
model = image_classifier.create(data, resnet_50_spec)Model Maker currently supports two use cases: image classification (tutorial) and text classification (tutorial), with more computer vision and NLP use cases coming soon.
Develop model: attach metadata for seamless model exchange
The TensorFlow Lite file format has always had the input/output tensor shape in its metadata. This works well when the model creator is also the app developer. However, as the on-device machine learning ecosystem grows, these tasks are increasingly performed by different teams within an organization or even between organizations. To facilitate these model knowledge exchanges, we have added new fields in the metadata. They fall into two broad categories:
- Machine-readable parameters – e.g. normalization parameters such as mean and standard deviation, category label files. These parameters can be read by other systems so wrapper code can be generated. You can see an example of this in the next section.
- Human-readable parameters – e.g. model description, model license. This can provide the app developer using the model crucial information on how to use the model correctly – are there strengths or weaknesses they should be aware of? Also, fields like licenses can be critical in deciding whether a model can be used. Having this attached to the model significantly reduces the barrier of adoption.
To supercharge this effort, models created by TensorFlow Lite Model Maker and image related TensorFlow Lite models on TensorFlow Hub already have metadata attached to it. If you are creating your own model, you can attach metadata to make sharing models easier.
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
# Describe input and output tensors
# ...
# Writing the metadata to your model
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()For a complete example of how we populate the metadata for MobileNet v1, please refer to this guide.
Develop app: automatically generate code from model
Instead of copy and pasting error-prone boilerplate code to transform typed objects such as Bitmap to ByteArray to feed to TensorFlow Lite interpreter, a code generator can generate the wrapper code ready for integration using the machine-readable parts of the metadata.
You can use our first code generator build for Android to generate model wrappers. We are also working on integrating this tool into Android Studio.
Develop app: discover performance with the benchmark and profiling tools
Once a model is created, we would like to check how it performs on mobile devices. TensorFlow Lite provides benchmark tools to measure model performance of models. We have added support for running benchmarks with all runtime options, including running models on GPU or other supported hardware accelerators, specifying the number of threads and more. You can also get inference latency breakdown to the granularity of a single operation to identify the most time consuming operations and optimize your model inference.
After integrating a model to your application, you may encounter other performance issues so that you may resort to platform-provided performance profiling tools. For example, on Android, one could investigate performance issues via various tracing tools. We have launched a TensorFlow Lite performance tracing module on Android that helps to poke into TensorFlow Lite internals. It is installed by default in our nightly release. With tracing, one may find whether there is resource contention during inference. Please refer to our documentation to learn more about how to use the module in the context of the Android benchmark tool.
We will continue working on improving TensorFlow Lite performance tooling to make it more intuitive and more helpful to measure and tune TensorFlow Lite performance on various devices.
Deploy: easily scale to multiple platforms
Nowadays, most applications need to support multiple platforms. That’s why we built TensorFlow Lite to work seamlessly across platforms: Android, iOS, Raspberry Pi, and other Linux-based IoT devices. All TensorFlow Lite models will just work out-of-the-box on any officially supported platforms, so that you can focus on creating good models instead of worrying about how to adapt your models to different platforms.
Each platform has its own hardware accelerator that can be used to speed up model inference. TensorFlow Lite has already supported running models on NNAPI for Android, GPU for both iOS and Android. We are excited to add more hardware accelerators:
- On Android, we have added support for Qualcomm Hexagon DSP which is available on millions of devices. This enables developers to leverage the DSP on older Android devices below Android 8.1 where Android NN API is unavailable.
- On iOS, we have launched CoreML delegate to allow running TensorFlow Lite models on Apple’s Neural Engine.
Besides, we continued to improve performance on existing supported platforms as you can see from the graph below comparing the performance between May 2019 and February 2020. You only need to upgrade to the latest version of TensorFlow Lite library to benefit from these improvements.
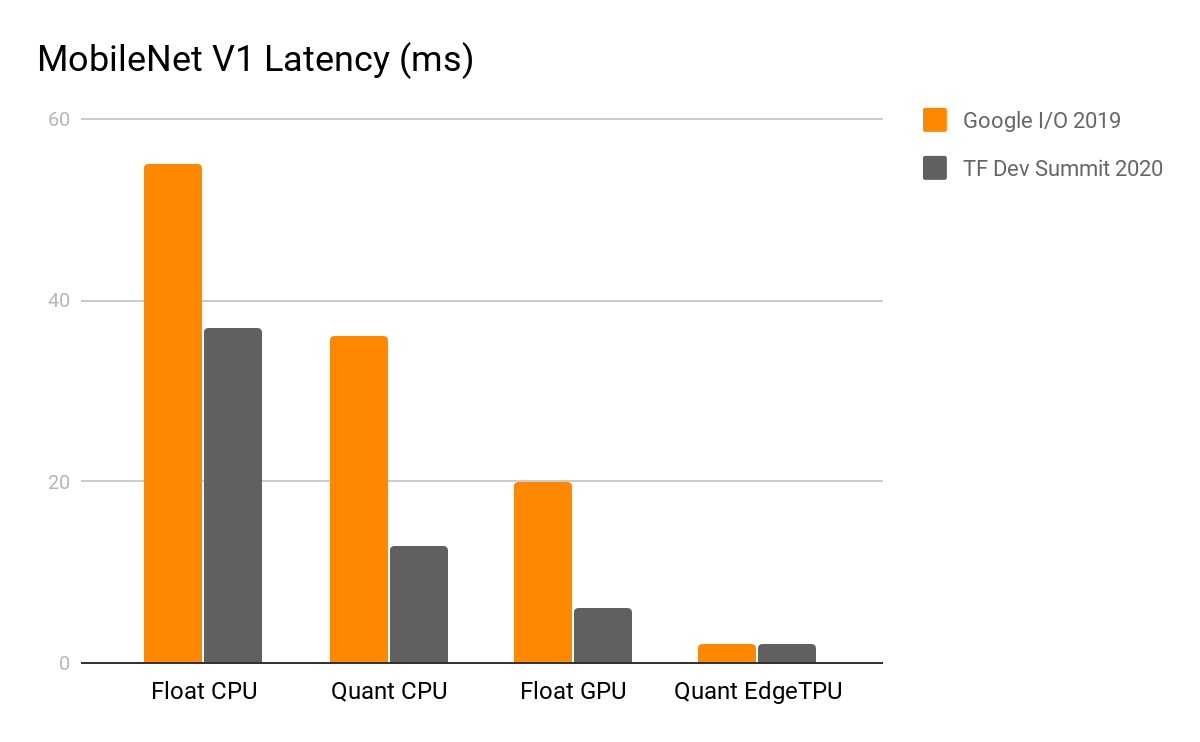 |
| Pixel 4 – Single Threaded CPU, February 2020 |
Future work
Over the coming months, we will work on supporting more use cases and improving developer experiences:
- Continuously release up-to-date state-of-the-art on-device models, including better support for BERT-family models for NLP tasks and new vision models.
- Publish new tutorials and examples demonstrating more use cases, including how to use C/C++ APIs for inference on mobile.
- Enhance Model Maker to support more tasks including object detection and several NLP tasks. We will add BERT support for NLP tasks, such as question and answer. This will empower developers without machine learning expertise to build state-of-the-art NLP models through transfer learning.
- Expand the metadata and codegen tools to support more use cases, including object detection and more NLP tasks.
- Launch more platform integration for even easier end-to-end experience, including better integration with Android Studio and TensorFlow Hub.
Feedback
We are committed to continue improving TensorFlow Lite and looking forward to seeing what you have built with TensorFlow Lite, as well as hearing your feedback. Share your use cases with us directly or on Twitter with hashtags #TFLite and #PoweredByTF. To report bugs and issues, please reach out to us on GitHub.
Acknowledgements
Thanks to Amy Jang, Andrew Selle, Arno Eigenwillig, Arun Venkatesan, Cédric Deltheil, Chao Mei, Christiaan Prins, Denny Zhou, Denis Brulé, Elizabeth Kemp, Hoi Lam, Jared Duke, Jordan Grimstad, Juho Ha, Jungshik Jang, Justin Hong, Hongkun Yu, Karim Nosseir, Khanh LeViet, Lawrence Chan, Lei Yu, Lu Wang, Luiz Gustavo Martins, Maxime Brénon, Mia Roh, Mike Liang, Mingxing Tan, Renjie Liu, Sachin Joglekar, Sarah Sirajuddin, Sebastian Goodman, Shiyu Hu, Shuangfeng Li, Sijia Ma, Tei Jeong, Tian Lin, Tim Davis, Vojtech Bardiovsky, Wei Wei, Wouter van Oortmerssen, Xiaodan Song, Xunkai Zhang, YoungSeok Yoon, Yuqi Li, Yi Zhou, Zhenzhong Lan, Zhiqing Sun and more.Read More