Posted by Anirudh Sriram, Technical Writer, and Gal Oshri, Product Manager
Performance is a key consideration of successful ML research and production solutions. Faster model training leads to faster iterations and reduced overhead. It is sometimes an essential requirement to make a particular ML solution feasible.
However, it is not always clear what should be optimized. Is there an issue with a specific operation (op), or the input pipeline?
To help answer this, we have developed an extensive set of tools for TensorFlow performance profiling. Beyond the ability to capture and investigate numerous aspects of a profile, the tools offer guidance on how to resolve performance bottlenecks (e.g. input-bound programs).
These tools are used by low-level experts improving TensorFlow’s infrastructure, as well as engineers in Google’s most popular products to optimize their model performance. We want to enable the broader community to take advantage of the tools used at Google for performance profiling. That is why we recently open sourced the new TensorFlow Profiler.
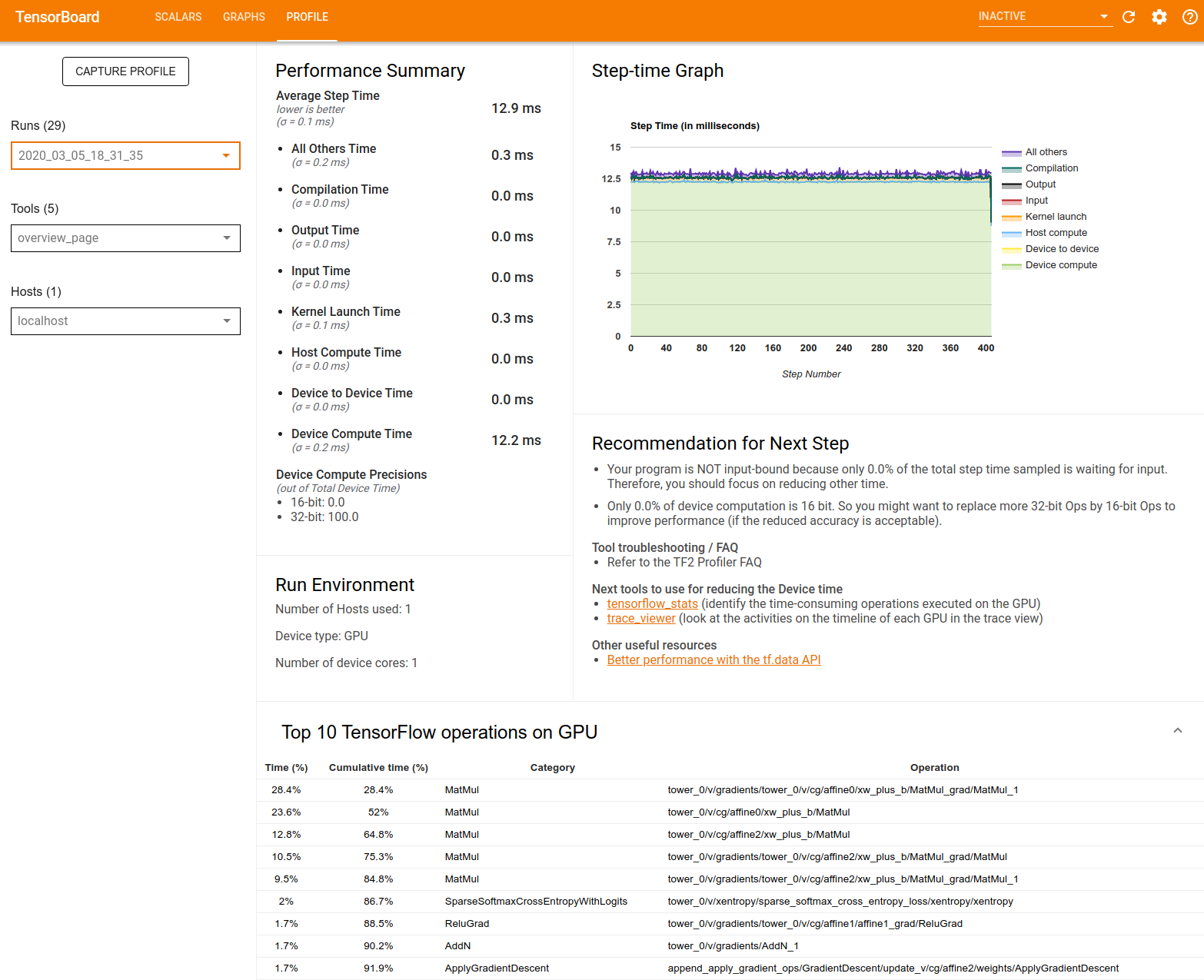 |
| TensorFlow Profiler overview page |
What is the TensorFlow Profiler?
The TensorFlow Profiler (or the Profiler) provides a set of tools that you can use to measure the training performance and resource consumption of your TensorFlow models. This new version of the Profiler is integrated into TensorBoard, and builds upon existing capabilities such as the Trace Viewer.
The Profiler has the following new profiling tools available:
- Overview Page: Provides a top-level view of model performance and recommendations to optimize performance
- Input Pipeline Analyzer: Analyzes your model’s data input pipeline for bottlenecks and recommends improvements to improve performance
- TensorFlow Stats: Displays performance statistics for every TensorFlow operation executed during the profiling session
- GPU Kernel Stats: Displays performance statistics and the originating operation for every GPU accelerated kernel
Check out the Profiler guide in the TensorFlow documentation to learn more about these tools.
Getting started
The best way to get started with the Profiler is to follow the Colab tutorial here. We will cover a few of the important steps and insights in the blog post. First, we install the Profiler plugin for TensorBoard:
pip install -U tensorboard_plugin_profileThis adds the full Profiler capabilities to our TensorBoard installation. Next, we ensure that our model training captures a profile. In this case, we will use the TensorBoard callback in Keras:
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
profile_batch = '500,510')We can choose which batches to profile with the profile_batch parameter. This enables us to choose the number of steps to capture (recommended to be no more than 10). It also helps us skip the first few batches to avoid inaccuracy due to initialization overhead. There are other methods for capturing a profile, described here. We now start TensorBoard with the following command:
tensorboard --logdir {log directory} # in terminal
%tensorboard --logdir {log directory} # in ColabAfter clicking on Profile, we see the overview page: 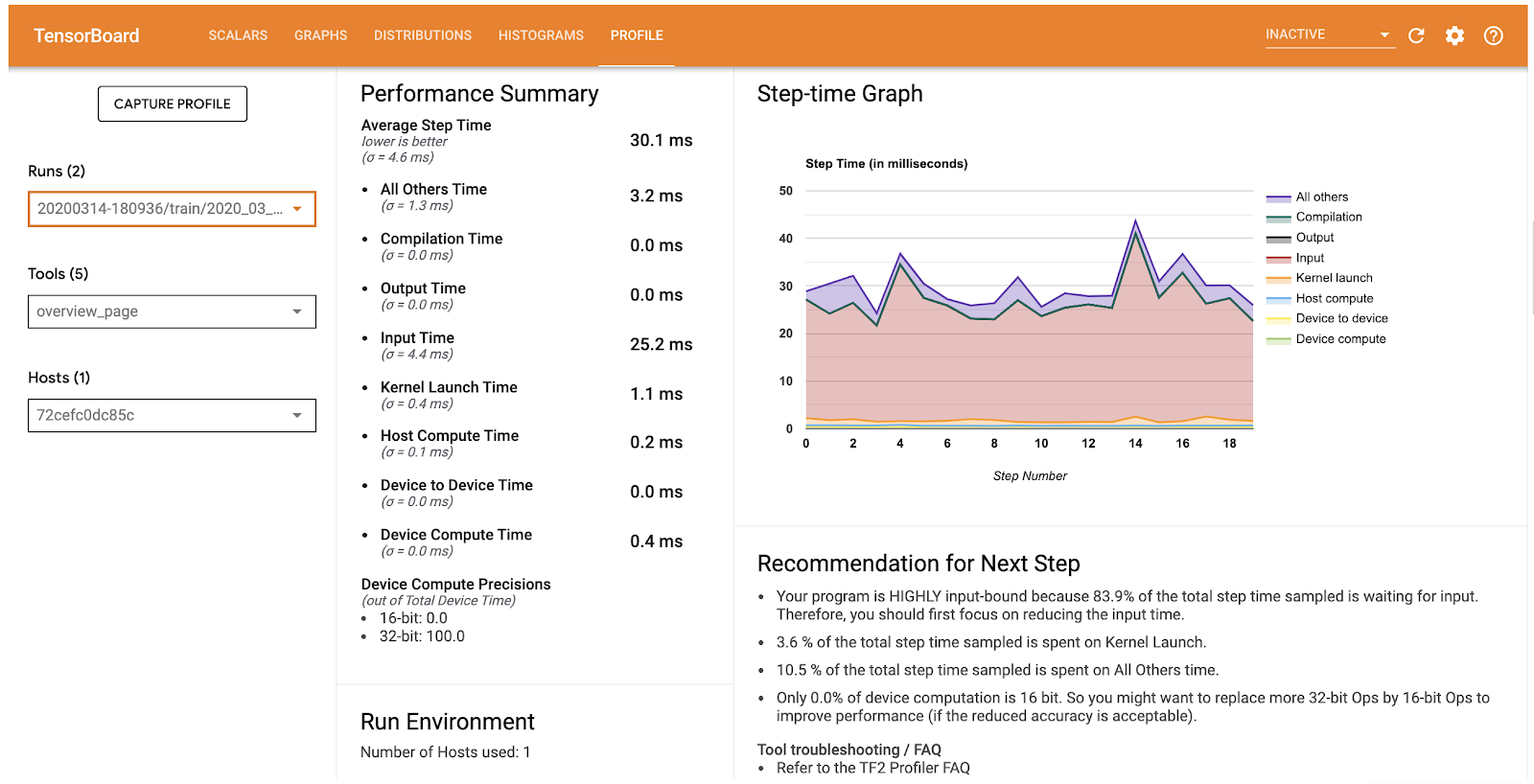 This immediately gives us an indication of our program’s performance. Besides a useful summary, we see a recommendation telling us that our program is input-bound (meaning our accelerator is wasting time waiting for input). This is a really common problem.
This immediately gives us an indication of our program’s performance. Besides a useful summary, we see a recommendation telling us that our program is input-bound (meaning our accelerator is wasting time waiting for input). This is a really common problem.
By following the instructions in the tutorial, we can bring our average step time from ~30ms to ~3ms. That’s a 10x improvement! While this is a toy example, it is common to hear from engineers and researchers at Google that they managed to improve their performance by significant factors.
Recommendations
Performance optimization is an iterative process and can sometimes be frustrating as it is tricky to pinpoint the exact location of the bottlenecks in your program. Not only can the Profiler tell you where your program has bottlenecks, it can often also tell you what you can do to resolve them and make your code execute faster. Following the recommendations provided can shorten the overall time taken to optimize your program.
When you open TensorBoard to view the profiling results, the Overview page provides code optimization recommendations below the Step time graph. One of the most common reasons for slow code execution is an improperly configured data input pipeline. Leverage the capabilities of the Input pipeline analyzer to effectively identify and eliminate bottlenecks in your data input pipeline. Read the best practices section of the Profiler guide to learn more about other strategies you can employ to get optimal performance.
More resources
Check out these resources to learn more:
- Profiler tutorial in Colab: https://www.tensorflow.org/tensorboard/tensorboard_profiling_keras
- In-depth guide: https://www.tensorflow.org/guide/profiler
- GitHub repository: https://github.com/tensorflow/profiler
- TensorFlow Dev Summit 2020 talk: https://www.youtube.com/watch?v=OTip0L8clKo
What’s next for the TensorFlow Profiler?
In addition to addressing feedback, we are expanding the profiler’s capabilities. A few areas we are currently working on:
- Memory Profiler: View memory usage over time and the associated op/training step.
- Keras Analysis: Enable linking the information in the profiler to Keras. This enables, for example, identifying which Keras layers correspond to the ops shown in the trace viewer.
- Multiworker GPU Analysis: Enable profiling multiple GPU workers and aggregate the results. Analyze the hotspot and the communication across workers.
We are excited to continue bringing the tools used at Google to improve ML performance to the broader community. If there are specific capabilities that would help you the most, or to report a bug, feel free to open an issue here!