Your contact center connects your business to your community, enabling customers to order products, callers to request support, clients to make appointments, and much more. Each conversation with a caller is an opportunity to learn more about that caller’s needs, and how well those needs were addressed during the call. You can uncover insights from these conversations that help you manage script compliance and find new opportunities to satisfy your customers, perhaps by expanding your services to address reported gaps, improving the quality of reported problem areas, or by elevating the customer experience delivered by your contact center agents.
Contact Lens for Amazon Connect provides call transcriptions with rich analytics capabilities that can provide these kinds of insights, but you may not currently be using Amazon Connect. You need a solution that works with your existing contact center call recordings.
Amazon Machine Learning (ML) services like Amazon Transcribe Call Analytics and Amazon Comprehend provide feature-rich APIs that you can use to transcribe and extract insights from your contact center audio recordings at scale. Although you could build your own custom call analytics solution using these services, that requires time and resources. In this post, we introduce our new sample solution for post call analytics.
Solution overview
Our new sample solution, Post Call Analytics (PCA), does most of the heavy lifting associated with providing an end-to-end solution that can process call recordings from your existing contact center. PCA provides actionable insights to spot emerging trends, identify agent coaching opportunities, and assess the general sentiment of calls.
You provide your call recordings, and PCA automatically processes them using Transcribe Call Analytics and other AWS services to extract valuable intelligence such as customer and agent sentiment, call drivers, entities discussed, and conversation characteristics such as non-talk time, interruptions, loudness, and talk speed. Transcribe Call Analytics detects issues using built-in ML models that have been trained using thousands of hours of conversations. With the automated call categorization capability, you can also tag conversations based on keywords or phrases, sentiment, and non-talk time. And you can optionally redact sensitive customer data such as names, addresses, credit card numbers, and social security numbers from both transcript and audio files.
PCA’s web user interface has a home page showing all your calls, as shown in the following screenshot.

You can choose a record to see the details of the call, such as speech characteristics.
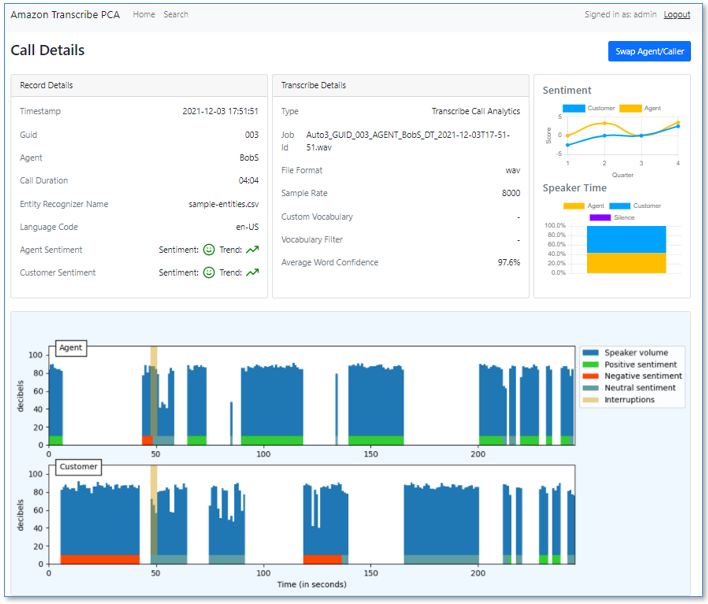
You can also scroll down to see annotated turn-by-turn call details.

You can search for calls based on dates, entities, or sentiment characteristics.

You can also search your call transcriptions.
Lastly, you can query detailed call analytics data from your preferred business intelligence (BI) tool.
PCA currently supports the following features:
-
Transcription
- Batch turn-by-turn transcription with support for Amazon Transcribe custom vocabulary for accuracy of domain-specific terminology
- Personally identifiable information (PII) redaction from transcripts and audio files, and vocabulary filtering for masking custom words and phrases
- Multiple languages and automatic language detection
- Standard audio file formats
- Caller and agent speaker labels using channel identification or speaker diarization
-
Analytics
- Caller and agent sentiment details and trends
- Talk and non-talk time for both caller and agent
- Configurable Transcribe Call Analytics categories based on the presence or absence of keywords or phrases, sentiment, and non-talk time
- Detects callers’ main issues using built-in ML models in Transcribe Call Analytics
- Discovers entities referenced in the call using Amazon Comprehend standard or custom entity detection models, or simple configurable string matching
- Detects when caller and agent interrupt each other
- Speaker loudness
-
Search
- Search on call attributes such as time range, sentiment, or entities
- Search transcriptions
-
Other
- Detects metadata from audio file names, such as call GUID, agent’s name, and call date time
- Scales automatically to handle variable call volumes
- Bulk loads large archives of older recordings while maintaining capacity to process new recordings as they arrive
- Sample recordings so you can quickly try out PCA for yourself
- It’s easy to install with a single AWS CloudFormation template
This is just the beginning! We expect to add many more exciting features over time, based on your feedback.
Deploy the CloudFormation stack
Start your PCA experience by using AWS CloudFormation to deploy the solution with sample recordings loaded.
- Use the following Launch Stack button to deploy the PCA solution in the
us-east-1(N. Virginia) AWS Region.

The source code is available in our GitHub repository. Follow the directions in the README to deploy PCA to additional Regions supported by Amazon Transcribe.
- For Stack name, use the default value,
PostCallAnalytics. - For AdminUsername, use the default value, admin.
- For AdminEmail, use a valid email address—your temporary password is emailed to this address during the deployment.
- For loadSampleAudioFiles, change the value to
true. - For EnableTranscriptKendraSearch, change the value to
Yes, create new Kendra Index (Developer Edition).
If you have previously used your Amazon Kendra Free Tier allowance, you incur an hourly cost for this index (more information on cost later in this post). Amazon Kendra transcript search is an optional feature, so if you don’t need it and are concerned about cost, use the default value of No.
- For all other parameters, use the default values.
If you want to customize the settings later, for example to apply custom vocabulary to improve accuracy, or to customize entity detection, you can update the stack to set these parameters.
- Select the two acknowledgement boxes, and choose Create stack.
The main CloudFormation stack uses nested stacks to create the following resources in your AWS account:
- Amazon Simple Storage Service (Amazon S3) buckets to hold build artifacts and call recordings
- AWS Systems Manager Parameter Store settings to store configuration settings
- AWS Step Functions workflows to orchestrate recording file processing
- AWS Lambda functions to process audio files and turn-by-turn transcriptions and analytics
- Amazon DynamoDB tables to store call metadata
- Website components including S3 bucket, Amazon CloudFront distribution, and Amazon Cognito user pool
- Other miscellaneous supporting resources, including AWS Identity and Access Management (IAM) roles and policies (using least privilege best practices), Amazon Simple Queue Service (Amazon SQS) message queues, and Amazon CloudWatch log groups.
- Optionally, an Amazon Kendra index and AWS Amplify search application to provide intelligent call transcript search.
The stacks take about 20 minutes to deploy. The main stack status shows as CREATE_COMPLETE when everything is deployed.

Set your password
After you deploy the stack, you need to open the PCA web user interface and set your password.
- On the AWS CloudFormation console, choose the main stack,
PostCallAnalytics, and choose the Outputs tab.

- Open your web browser to the URL shown as
WebAppURLin the outputs.
You’re redirected to a login page.
- Open the email your received, at the email address you provided, with the subject “Welcome to the Amazon Transcribe Post Call Analytics (PCA) Solution!”
This email contains a generated temporary password that you can use to log in (as user admin) and create your own password.
- Set a new password.
Your new password must have a length of at least eight characters, and contain uppercase and lowercase characters, plus numbers and special characters.
You’re now logged in to PCA. Because you set loadSampleAudioFiles to true, your PCA deployment now has three sample calls pre-loaded for you to explore.
Optional: Open the transcription search web UI and set your permanent password
Follow these additional steps to log in to the companion transcript search web app, which is deployed only when you set EnableTranscriptKendraSearch when you launch the stack.
- On the AWS CloudFormation console, choose the main stack,
PostCallAnalytics, and choose the Outputs tab. - Open your web browser to the URL shown as
TranscriptionMediaSearchFinderURLin the outputs.
You’re redirected to the login page.

- Open the email your received, at the email address you provided, with the subject “Welcome to Finder Web App.”
This email contains a generated temporary password that you can use to log in (as user admin).
- Create your own password, just like you already did for the PCA web application.
As before, your new password must have a length of at least eight characters, and contain uppercase and lowercase characters, plus numbers and special characters.
You’re now logged in to the transcript search Finder application. The sample audio files are indexed already, and ready for search.
Explore post call analytics features
Now, with PCA successfully installed, you’re ready to explore the call analysis features.
Home page
To explore the home page, open the PCA web UI using the URL shown as WebAppURL in the main stack outputs (bookmark this URL, you’ll use it often!)
You already have three calls listed on the home page, sorted in descending time order (most recent first). These are the sample audio files.

The calls have the following key details:
- Job Name – Is assigned from the recording audio file name, and serves as a unique job name for this call
- Timestamp – Is parsed from the audio file name if possible, otherwise it’s assigned the time when the recording is processed by PCA
- Customer Sentiment and Customer Sentiment Trend – Show the overall caller sentiment and, importantly, whether the caller was more positive at the end of the call than at the beginning
- Language Code – Shows the specified language or the automatically detected dominant language of the call
Call details
Choose the most recently received call to open and explore the call detail page. You can review the call information and analytics such as sentiment, talk time, interruptions, and loudness.

Scroll down to see the following details:
- Entities grouped by entity type. Entities are detected by Amazon Comprehend and the sample entity recognizer string map.
- Categories detected by Transcribe Call Analytics. By default, there are no categories; see Call categorization for more information.
- Issues detected by the Transcribe Call Analytics built-in ML model. Issues succinctly capture the main reasons for the call. For more information, see Issue detection.

Scroll further to see the turn-by-turn transcription for the call, with annotations for speaker, time marker, sentiment, interruptions, issues, and entities.
Use the embedded media player to play the call audio from any point in the conversation. Set the position by choosing the time marker annotation on the transcript or by using the player time control. The audio player remains visible as you scroll down the page.
PII is redacted from both transcript and audio—redaction is enabled using the CloudFormation stack parameters.
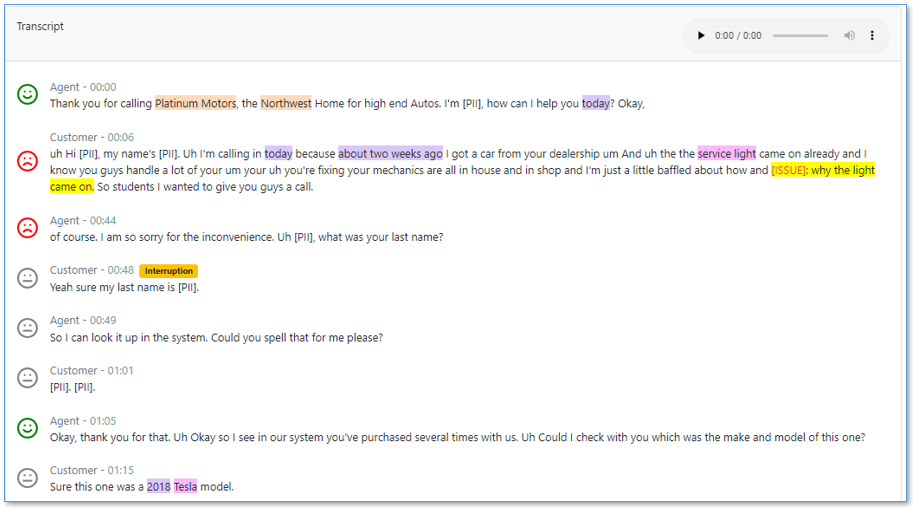
Search based on call attributes
To try PCA’s built-in search, choose Search at the top of the screen. Under Sentiment, choose Average, Customer, and Negative to select the calls that had average negative customer sentiment.

Choose Clear to try a different filter. For Entities, enter Hyundai and then choose Search. Select the call from the search results and verify from the transcript that the customer was indeed calling about their Hyundai.
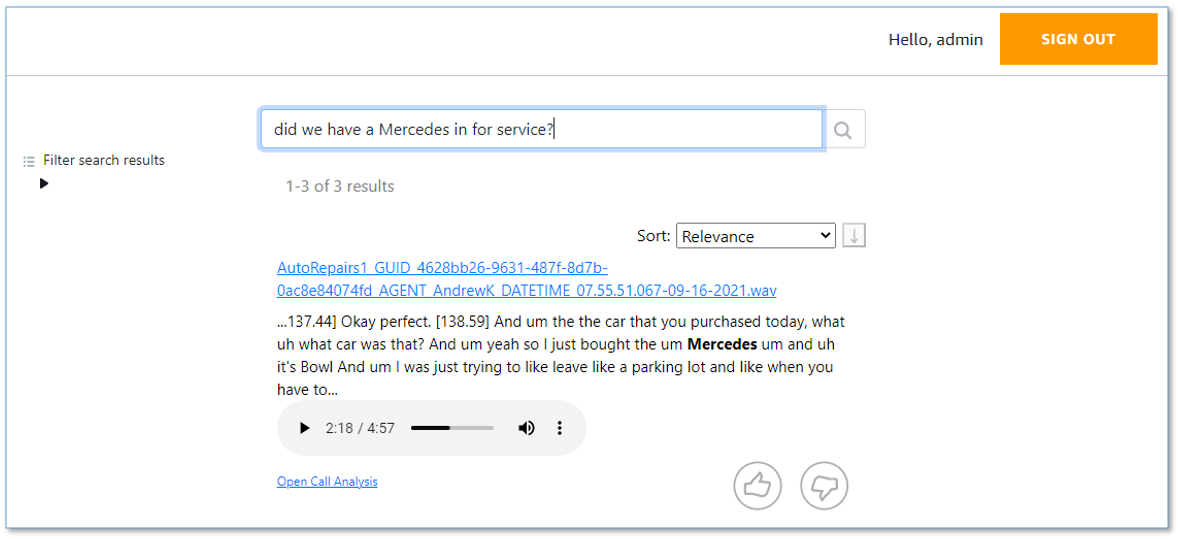
Search call transcripts
Transcript search is an experimental, optional, add-on feature powered by Amazon Kendra.
Open the transcript web UI using the URL shown as TranscriptionMediaSearchFinderURL in the main stack outputs. To find a recent call, enter the search query customer hit the wall.

The results show transcription extracts from relevant calls. Use the embedded audio player to play the associated section of the call recording.
You can expand Filter search results to refine the search results with additional filters. Choose Open Call Analytics to open the PCA call detail page for this call.
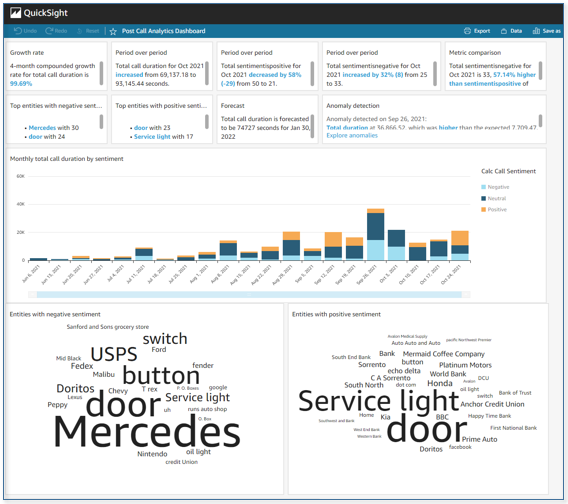
Query call analytics using SQL
You can integrate PCA call analytics data into a reporting or BI tool such as Amazon QuickSight by using Amazon Athena SQL queries. To try it, open the Athena query editor. For Database, choose pca.
Observe the table parsedresults. This table contains all the turn-by-turn transcriptions and analysis for each call, using nested structures.
You can also review flattened result sets, which are simpler to integrate into your reporting or analytics application. Use the query editor to preview the data.

Processing flow overview
How did PCA transcribe and analyze your phone call recordings? Let’s take a quick look at how it works.
The following diagram shows the main data processing components and how they fit together at a high level.

Call recording audio files are uploaded to the S3 bucket and folder, identified in the main stack outputs as InputBucket and InputBucketPrefix, respectively. The sample call recordings are automatically uploaded because you set the parameter loadSampleAudioFiles to true when you deployed PCA.
As each recording file is added to the input bucket, an S3 Event Notification triggers a Lambda function that initiates a workflow in Step Functions to process the file. The workflow orchestrates the steps to start an Amazon Transcribe batch job and process the results by doing entity detection and additional preparation of the call analytics results. Processed results are stored as JSON files in another S3 bucket and folder, identified in the main stack outputs as OutputBucket and OutputBucketPrefix.
As the Step Functions workflow creates each JSON results file in the output bucket, an S3 Event Notification triggers a Lambda function, which loads selected call metadata into a DynamoDB table.
The PCA UI web app queries the DynamoDB table to retrieve the list of processed calls to display on the home page. The call detail page reads additional detailed transcription and analytics from the JSON results file for the selected call.
Amazon S3 Lifecycle policies delete recordings and JSON files from both input and output buckets after a configurable retention period, defined by the deployment parameter RetentionDays. S3 Event Notifications and Lambda functions keep the DynamoDB table synchronized as files are both created and deleted.
When the EnableTranscriptKendraSearch parameter is true, the Step Functions workflow also adds time markers and metadata attributes to the transcription, which are loaded into an Amazon Kendra index. The transcription search web application is used to search call transcriptions. For more information on how this works, see Make your audio and video files searchable using Amazon Transcribe and Amazon Kendra.
Monitoring and troubleshooting
AWS CloudFormation reports deployment failures and causes on the stack Events tab. See Troubleshooting CloudFormation for help with common deployment problems.
PCA provides runtime monitoring and logs for each component using CloudWatch:
-
Step Functions workflow – On the Step Functions console, open the workflow
PostCallAnalyticsWorkflow. The Executions tab show the status of each workflow run. Choose any run to see details. Choose CloudWatch Logs from the Execution event history to examine logs for any Lambda function that was invoked by the workflow. -
PCA server and UI Lambda functions – On the Lambda console, filter by
PostCallAnalyticsto see all the PCA-related Lambda functions. Choose your function, and choose the Monitor tab to see function metrics. Choose View logs in CloudWatch to inspect function logs.
Cost assessment
For pricing information for the main services used by PCA, see the following:
- Amazon CloudFront Pricing
- Amazon CloudWatch pricing
- Amazon Cognito Pricing
- Amazon Comprehend Pricing
- Amazon DynamoDB pricing
- Amazon API Gateway pricing
- Amazon Kendra pricing (for the optional transcription search feature)
- AWS Lambda Pricing
- Amazon Transcribe Pricing
- Amazon S3 pricing
- AWS Step Functions Pricing
When transcription search is enabled, you incur an hourly cost for the Amazon Kendra index: $1.125/hour for the Developer Edition (first 750 hours are free), or $1.40/hour for the Enterprise Edition (recommended for production workloads).
All other PCA costs are incurred based on usage, and are Free Tier eligible. After the Free Tier allowance is consumed, usage costs add up to about $0.15 for a 5-minute call recording.
To explore PCA costs for yourself, use AWS Cost Explorer or choose Bill Details on the AWS Billing Dashboard to see your month-to-date spend by service.

Integrate with your contact center
You can configure your contact center to enable call recording. If possible, configure recordings for two channels (stereo), with customer audio on one channel (for example, channel 0) and the agent audio on the other channel (channel 1).
Via the AWS Command Line Interface (AWS CLI) or SDK, copy your contact center recording files to the PCA input bucket folder, identified in the main stack outputs as InputBucket and InputBucketPrefix. Alternatively, if you already save your call recordings to Amazon S3, use deployment parameters InputBucketName and InputBucketRawAudio to configure PCA to use your existing S3 bucket and prefix, so you don’t have to copy the files again.
Customize your deployment
Use the following CloudFormation template parameters when creating or updating your stack to customize your PCA deployment:
- To enable or disable the optional (experimental) transcription search feature, use
EnableTranscriptKendraSearch. - To use your existing S3 bucket for incoming call recordings, use
InputBucketandInputBucketPrefix. - To configure automatic deletion of recordings and call analysis data when using auto-provisioned S3 input and output buckets, use
RetentionDays. - To detect call timestamp, agent name, or call identifier (GUID) from the recording file name, use
FilenameDatetimeRegex,FilenameDatetimeFieldMap,FilenameGUIDRegex, andFilenameAgentRegex. - To use the standard Amazon Transcribe API instead of the default call analytics API, use TranscribeApiMode. PCA automatically reverts to the standard mode API for audio recordings that aren’t compatible with the call analytics API (for example, mono channel recordings). When using the standard API some call analytics, metrics such as issue detection and speaker loudness aren’t available.
- To set the list of supported audio languages, use
TranscribeLanguages. - To mask unwanted words, use
VocabFilterModeand setVocabFilterNameto the name of a vocabulary filter that you already created in Amazon Transcribe. See Vocabulary filtering for more information. - To improve transcription accuracy for technical and domain specific acronyms and jargon, set
VocabularyNameto the name of a custom vocabulary that you already created in Amazon Transcribe. See Custom vocabularies for more information. - To configure PCA to use single-channel audio by default, and to identify speakers using speaker diarizaton rather than channel identification, use
SpeakerSeparationTypeandMaxSpeakers. The default is to use channel identification with stereo files using Transcribe Call Analytics APIs to generate the richest analytics and most accurate speaker labeling. - To redact PII from the transcriptions or from the audio, set
CallRedactionTranscriptorCallRedactionAudioto true. See Redaction for more information. - To customize entity detection using Amazon Comprehend, or to provide your own CSV file to define entities, use the Entity detection parameters.
See the README on GitHub for more details on configuration options and operations for PCA.
PCA is an open-source project. You can fork the PCA GitHub repository, enhance the code, and send us pull requests so we can incorporate and share your improvements!
Clean up
When you’re finished experimenting with this solution, clean up your resources by opening the AWS CloudFormation console and deleting the PostCallAnalytics stacks that you deployed. This deletes resources that you created by deploying the solution. S3 buckets containing your audio recordings and analytics, and CloudWatch log groups are retained after the stack is deleted to avoid deleting your data.
Live Call Analytics: Companion solution
Our companion solution, Live Call Analytics (LCA), offers real time-transcription and analytics capabilities by using the Amazon Transcribe and Amazon Comprehend real-time APIs. Unlike PCA, which transcribes and analyzes recorded audio after the call has ended, LCA transcribes and analyzes your calls as they are happening and provides real-time updates to supervisors and agents. You can configure LCA to store call recordings to the PCA’s ingestion S3 bucket, and use the two solutions together to get the best of both worlds. See Live call analytics for your contact center with Amazon language AI services for more information.
Conclusion
The Post Call Analytics solution offers a scalable, cost-effective approach to provide call analytics with features to help improve your callers’ experience. It uses Amazon ML services like Transcribe Call Analytics and Amazon Comprehend to transcribe and extract rich insights from your customer conversations.
The sample PCA application is provided as open source—use it as a starting point for your own solution, and help us make it better by contributing back fixes and features via GitHub pull requests. For expert assistance, AWS Professional Services and other AWS Partners are here to help.
We’d love to hear from you. Let us know what you think in the comments section, or use the issues forum in the PCA GitHub repository.
About the Authors
 Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
Bob Strahan is a Principal Solutions Architect in the AWS Language AI Services team.
 Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.
Dr. Andrew Kane is an AWS Principal WW Tech Lead (AI Language Services) based out of London. He focuses on the AWS Language and Vision AI services, helping our customers architect multiple AI services into a single use-case driven solution. Before joining AWS at the beginning of 2015, Andrew spent two decades working in the fields of signal processing, financial payments systems, weapons tracking, and editorial and publishing systems. He is a keen karate enthusiast (just one belt away from Black Belt) and is also an avid home-brewer, using automated brewing hardware and other IoT sensors.
 Steve Engledow is a Solutions Engineer working with internal and external AWS customers to build reusable solutions to common problems.
Steve Engledow is a Solutions Engineer working with internal and external AWS customers to build reusable solutions to common problems.
 Connor Kirkpatrick is an AWS Solutions Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations, and quickstarts. He is an enthusiastic rower, wobbly cyclist, and occasional baker.
Connor Kirkpatrick is an AWS Solutions Engineer based in the UK. Connor works with the AWS Solution Architects to create standardised tools, code samples, demonstrations, and quickstarts. He is an enthusiastic rower, wobbly cyclist, and occasional baker.
 Franco Rezabek is an AWS Solutions Engineer based in London, UK. Franco works with AWS Solution Architects to create standardized tools, code samples, demonstrations, and quick starts.
Franco Rezabek is an AWS Solutions Engineer based in London, UK. Franco works with AWS Solution Architects to create standardized tools, code samples, demonstrations, and quick starts.