For a supervised machine learning (ML) problem, labels are values expected to be learned and predicted by a model. To obtain accurate labels, ML practitioners can either record them in real time or conduct offline data annotation, which are activities that assign labels to the dataset based on human intelligence. However, manual dataset annotation can be tedious and tiring for a human, especially on a large dataset. Even with labels that are obvious to a human to annotate, the process can still be error-prone due to fatigue. As a result, building training datasets takes up to 80% of a data scientist’s time.
To tackle this issue, we demonstrate in this post how to use an assisting ML model, which is trained using a small annotated dataset, to speed up the annotation on a larger dataset while having a human in the loop. As an example, we focus on a computer vision object detection use case. We detect AWS and Amazon smile logos from images collected on the AWS and Amazon website. Depending on the use case, you can start with training a model with only a few images that captures the obvious pattern in the dataset, and have a human focus on the lightweight tasks of reviewing these automatically proposed annotations and adjust mistaken labels only when necessary. This solution avoids repeating manual work, reduces human fatigue, and improves data annotation quality and efficiency.
In this post, we use AWS CloudFormation to set up a serverless stack with AWS Lambda functions as well as their corresponding permissions, Amazon Simple Storage Service (Amazon S3) for image data lake and model prediction storage, Amazon SageMaker Ground Truth for data labeling, and Amazon Rekognition Custom Labels for dataset management and model training and hosting. Code used in this post is available on the GitHub repository.
Solution overview
Our solution includes the following steps:
- Prepare an S3 bucket with images.
- Create a Ground Truth labeling workforce.
- Deploy the CloudFormation stack.
- Train the first version of your model.
- Start the feedback client.
- Perform label verification with Amazon Rekognition Custom Labels.
- Generate a manifest file.
- Train the second version of your model.
Prerequisites
Make sure to install Python3, Pillow, and the AWS Command Line Interface (AWS CLI) on your environment and set up your AWS profile configuration and credentials.
Prepare an S3 bucket with images
First, create a new S3 bucket in the designed Region (N. Virginia or Ireland) with two partitions: one with a smaller number of images, and another with a larger number. For example, in this post, s3://rekognition-custom-labels-feedback-amazon-logo/v1/train/ includes eight AWS or Amazon smile logo images, and s3://rekognition-custom-labels-feedback-amazon-logo/v2/train/ has 20 logo images.
Add the following cross -origin resource sharing (CORS) policy in the bucket permission settings:
[
{
"AllowedHeaders": [],
"AllowedMethods": [
"GET"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": []
}
]Create a Ground Truth labeling workforce
In this post, we use a Ground Truth private labeling workforce. We also add new workers, create a new private team, and add a worker into the team. Eventually, we need to record the labeling workforce Amazon Resource Name (ARN).
- On the Amazon SageMaker console, under Ground Truth, choose Labeling workforces.
- On the Private tab, choose Invite new workers.
- Enter the email address of each worker you want to invite.
- Choose Invite new workers.
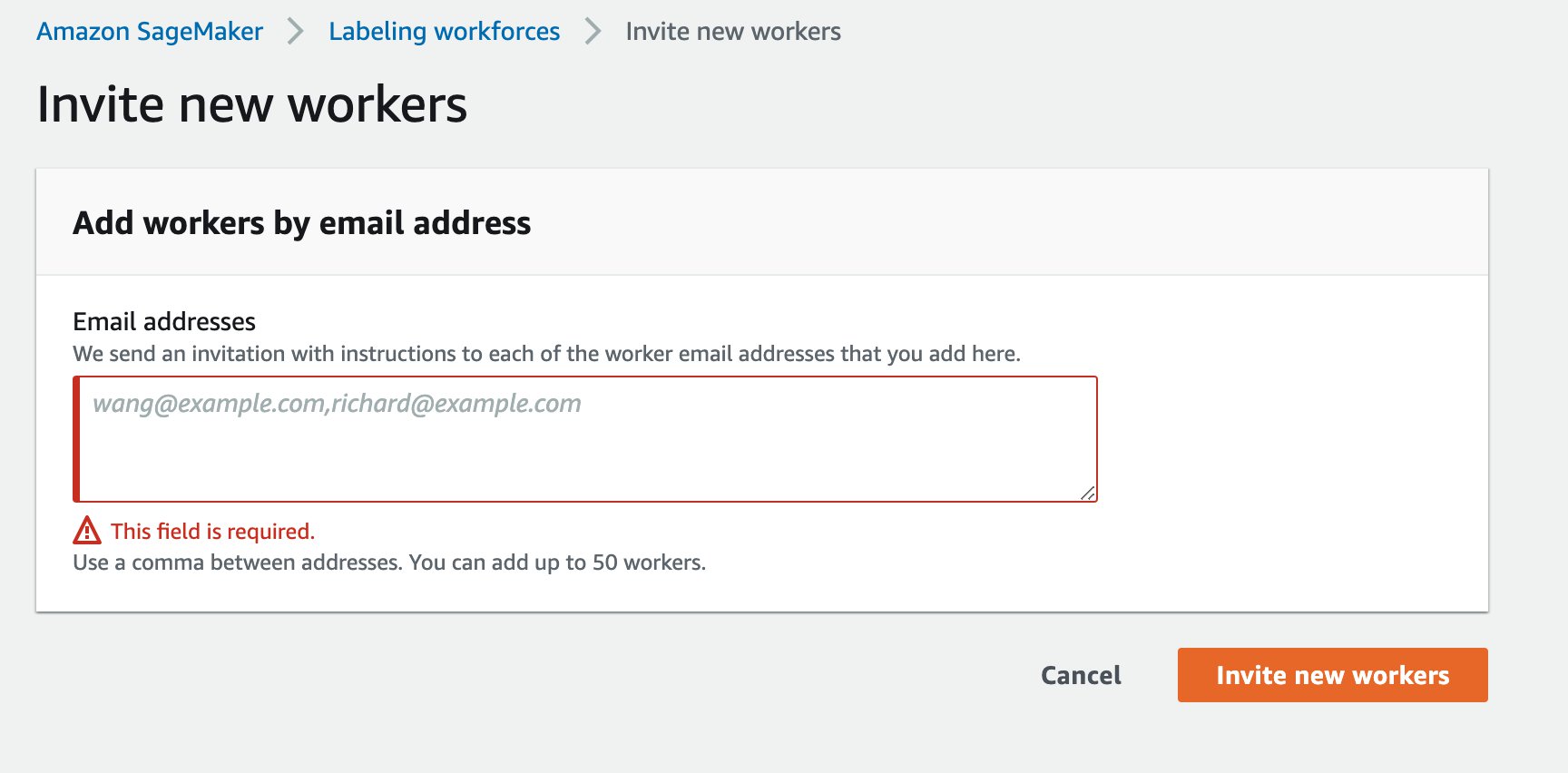
After you add the worker, they receive an email, similar to the one shown in the following screenshot.

Meanwhile, you can create a new labeling team.
- Choose Create private team.
- For Team name, enter a name.
- Choose Create private team to confirm.
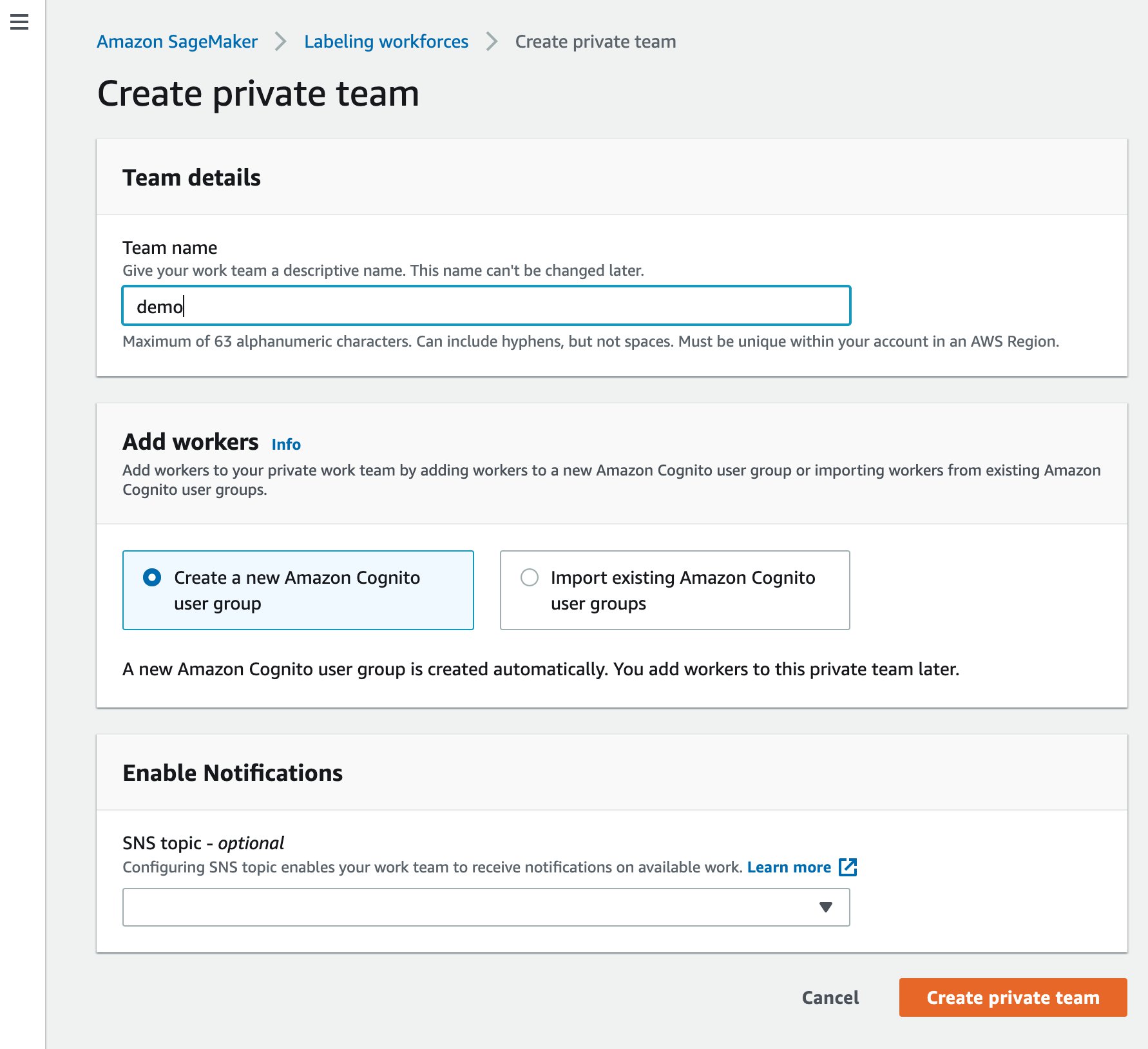
- On the Labeling workforces page, choose the name of the team.
- On the Workers tab, choose Add workers to team.
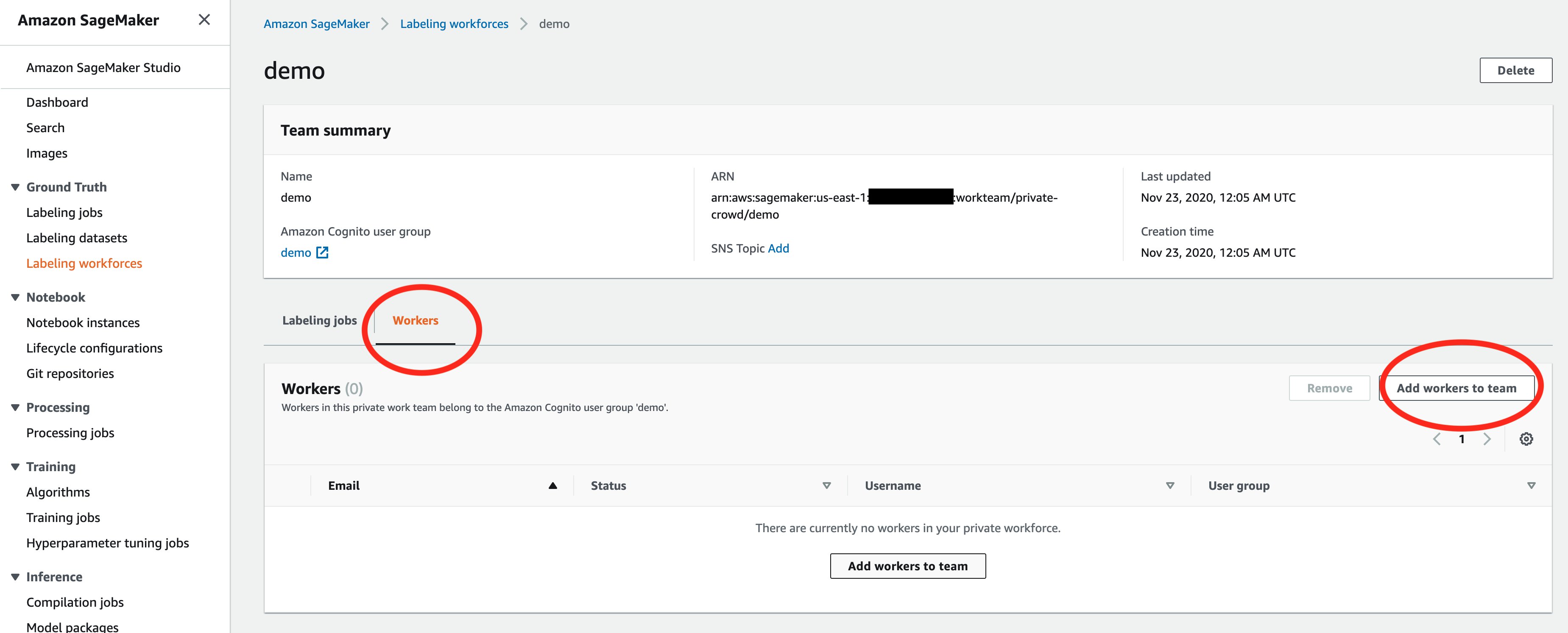
- Select the intended worker’s email address and choose Add workers to team.

Finally, we can get the labeling workforce ARN. For more details, see Create and Manage Workforces.
Deploy the CloudFormation stack
Deploy the CloudFormation stack in one of the AWS Regions where you are going to use Amazon Rekognition Custom Labels. This solution is currently available in us-east-1 (N. Virginia) and eu-west-1 (Ireland).
| Region | Launch |
| US East (N. Virginia) | |
| EU West (Ireland) | |
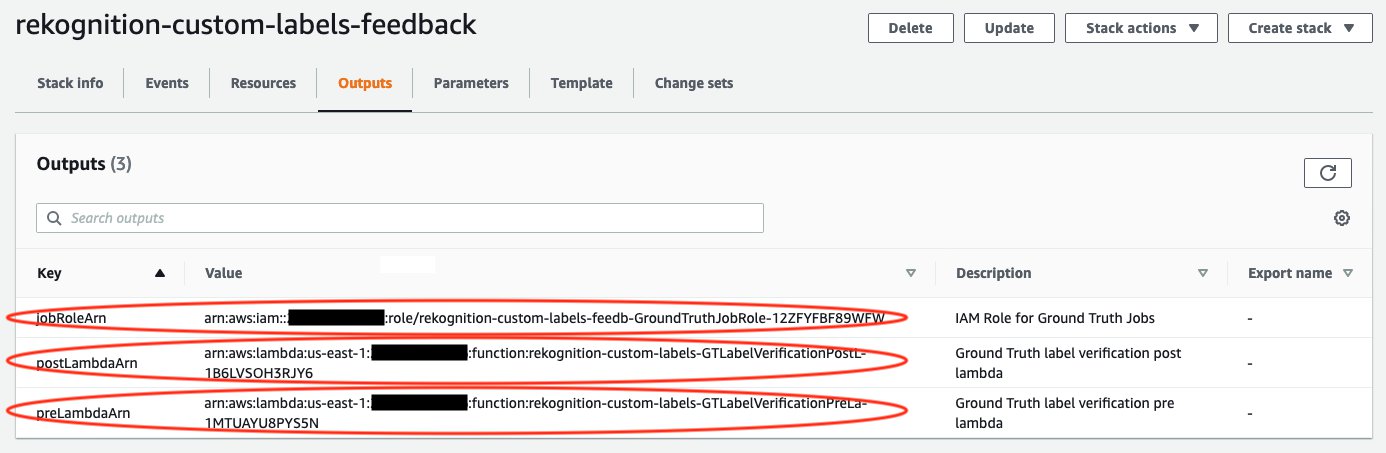
After deployment, choose the Outputs tab and make note of the three outputs: jobRoleArn, preLambdaArn, and postLambdaArn.
Train the first version of your model
For instructions on creating a project and training a model with Custom Labels, see Announcing Amazon Rekognition Custom Labels. In this post, we create a project called custom-labels-feedback. The first version model was trained and validated using the v1 dataset that includes eight AWS or Amazon smile logo images. The following screenshot shows some labeled sample data used for training.

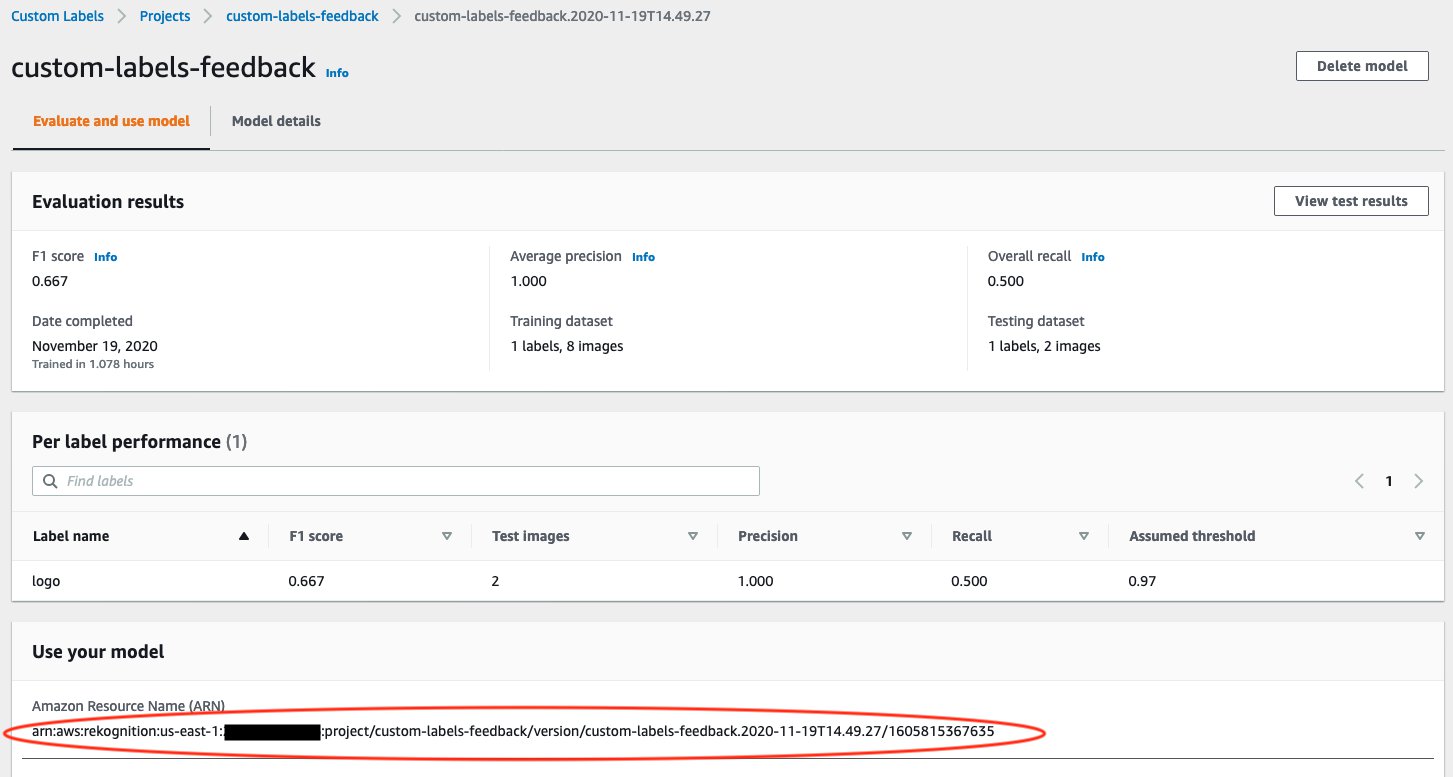
When the first version model’s training process is finished, take note of your model ARN. In our example, the model performance achieved an F1 score as 0.667. We use this model to help human workers to annotate a larger dataset (v2) for the next iteration.
Start the feedback client
To start the feedback client, complete the following steps:
- In your terminal, clone the repository:
git clone https://github.com/aws-samples/amazon-rekognition-custom-labels-feedback-solution.git- Change the working directory:
cd amazon-rekognition-custom-labels-feedback-solution/src- Update the following items in
feedback-config.jsonin thesrc/ folder:- images – The S3 bucket folder that has the larger dataset. In this post, it is the v2 dataset that contains 30 images.
- outputBucket – The output S3 bucket. For best practices, we recommend using the same image bucket here.
- jobRoleArn – The output from the CloudFormation stack.
- workforceTeamArn – The private team ARN as set earlier in the Ground Truth labeling workforces.
- preLambdaArn – The output from the CloudFormation stack.
- postLambdaArn – The output from the CloudFormation stack.
- projectVersionArn – The first model ARN.

You need to start the first version model before you call the feedback client.
- Expand the API Code section on your Amazon Rekognition Custom Labels model page, and enter the AWS CLI command
Start modelin your terminal.

The model status changes to STARTING.
- When the model status changes to RUNNING, run the following code in your terminal:
python3 start-feedback.pyIt analyzes the larger dataset of images using the first version model and starts Ground Truth label verification jobs. It also outputs a command for later usage, which generates a manifest file for the larger dataset (v2).

Perform label verification
Now human workers can log in the labeling project to verify labels proposed by the first version model. Usually, label verification jobs are sent to the workers in several batches.

For most of the images that are labeled correctly by the first version model, human workers only need to confirm these labels without any adjustment, which accelerates the whole data annotation process.

Generate a manifest file for the second dataset
After the label verification jobs are complete, (the status of the labeling jobs in Ground Truth changes from In progress to Complete), run the following command that you got from the feedback client’s output in your terminal:
python3 get-feedback.py --jobs-manifest s3://......This command generates a manifest file for the larger dataset that you can use to train the next version of your model in Rekognition Custom Labels. The output S3 Path indicates the manifest file location for the larger dataset.

Train the second version of your model
To train the next version of your model, we first create a new dataset.
- On the Amazon Rekognition Custom Labels console, choose Create dataset.
- For Dataset name, enter a name.
- For Image location, select Import images labeled by Amazon SageMaker Ground Truth.
- For .manifest file location, enter the S3 path you noted earlier.

Double check whether all images are labeled correctly. The following screenshot shows some sample data that we imported from Ground Truth.

With this newly added dataset in Amazon Rekognition Custom Labels, you can train the next version of your model under the same project as the first version. For example, in this post, we train the next version model using the dataset amazon-logo-v2 under the project custom-labels-feedback, and use the dataset amazon-logo-v1 as a test set.

In our example, comparing to the first version, the next version model achieves much better performance with a 0.900 F1 score.

It’s worth noting that you can apply this solution multiple times in a Amazon Rekognition Custom Labels project. You can use the next version model to easily annotate even larger datasets and train models until you’re satisfied with final model performance.
Clean up
After you finish using the custom labels feedback solution, remember to delete the CloudFormation stack via the AWS CloudFormation console, and stop running models by calling the AWS CLI command in your terminal. This helps you avoid any unnecessary charges.
Conclusion
This post presented an end-to-end demonstration of using Amazon Rekognition Custom Labels to efficiently annotate a larger dataset with assistance from a model trained on a smaller dataset. This solution enables you to gain feedback on a model’s performance and make improvements by using human verification and adjustment when necessary. As a result, data annotation, model training, and error analysis are conducted simultaneously and interactively, which improves dataset annotation efficiency.
For more information about building dataset labels with Ground Truth, see Amazon SageMaker Ground Truth and Amazon Rekognition Custom Labels.
About the Authors
 Sherry Ding is a Senior AI/ML Specialist Solutions Architect. She has extensive experience in machine learning with a PhD degree in Computer Science. She mainly works with Public Sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a Senior AI/ML Specialist Solutions Architect. She has extensive experience in machine learning with a PhD degree in Computer Science. She mainly works with Public Sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
 Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL, and machine learning.
Kashif Imran is a Principal Solutions Architect at Amazon Web Services. He works with some of the largest AWS customers who are taking advantage of AI/ML to solve complex business problems. He provides technical guidance and design advice to implement computer vision applications at scale. His expertise spans application architecture, serverless, containers, NoSQL, and machine learning.
 Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family
Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family