![]()
The International Conference on Learning Representations (ICLR) 2021 is being hosted virtually from May 3rd – May 7th. We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Adaptive Procedural Task Generation for Hard-Exploration Problems
Authors: Kuan Fang, Yuke Zhu, Silvio Savarese, Li Fei-Fei
Contact: kuanfang@stanford.edu
Links: Paper | Video | Website
Keywords: curriculum learning, reinforcement learning, procedural generation

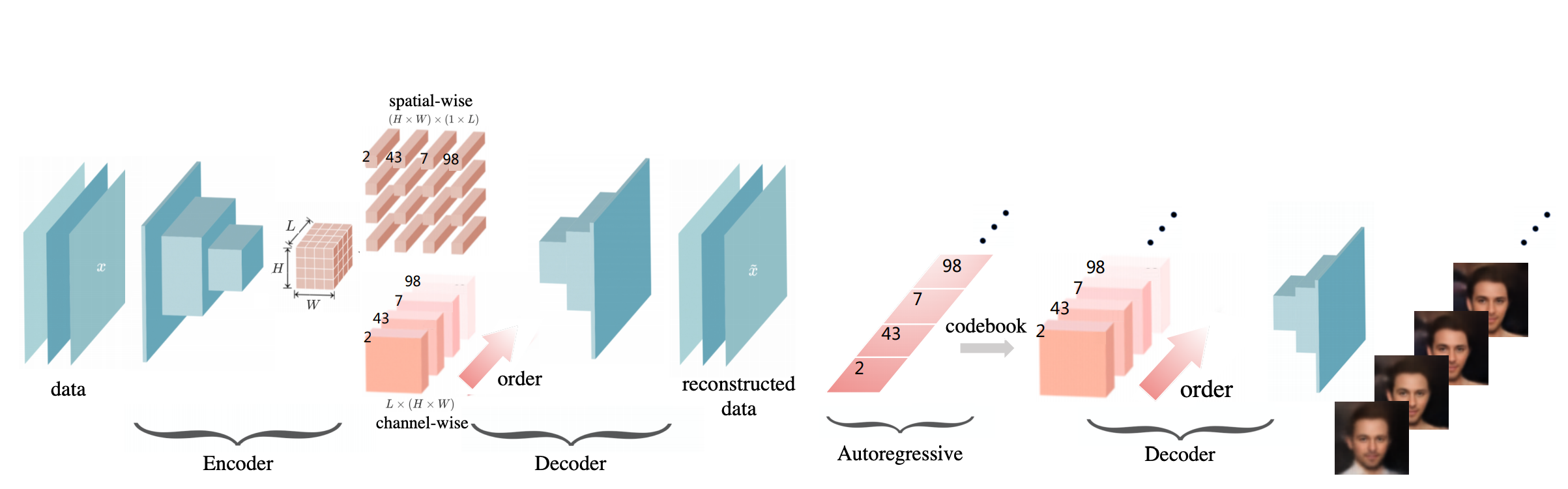
Anytime Sampling for Autoregressive Models via Ordered Autoencoding
Authors: Yilun Xu, Yang Song, Sahaj Garg, Linyuan Gong, Rui Shu, Aditya Grover, and Stefano Ermon
Contact: ylxu@mit.edu
Links: Paper
Keywords: autoregressive models, anytime algorithm, sampling
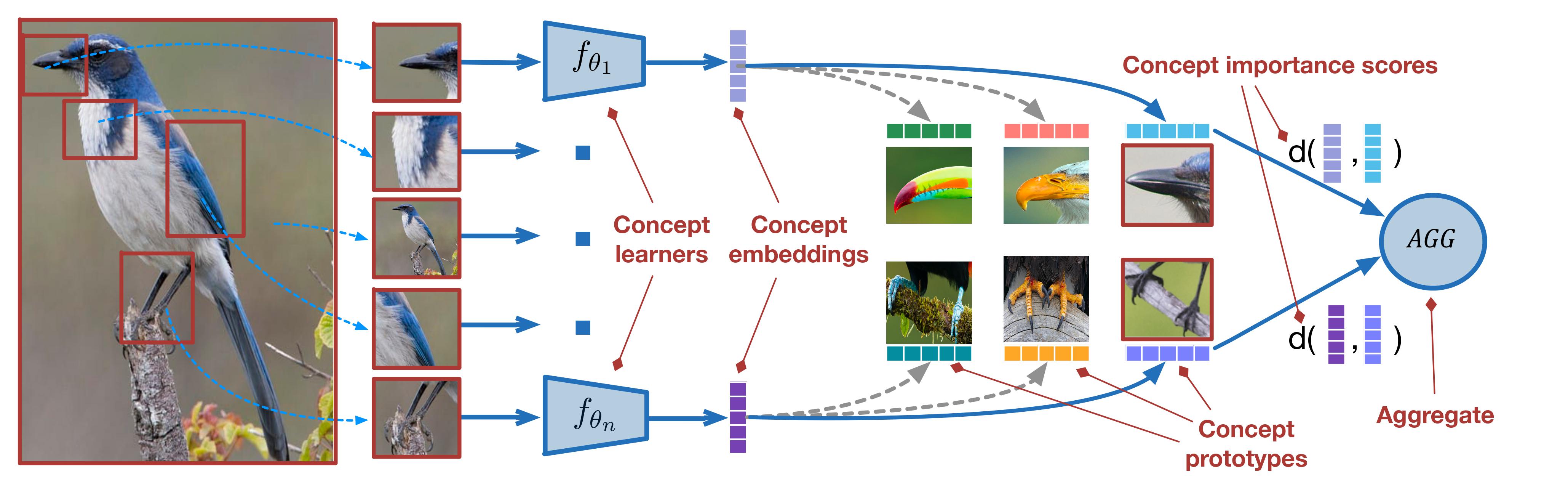
Concept Learners for Few-Shot Learning
Authors: Kaidi Cao*, Maria Brbić*, Jure Leskovec
Contact: kaidicao@cs.stanford.edu, mbrbic@cs.stanford.edu
Links: Paper | Website
Keywords: few-shot learning, meta learning
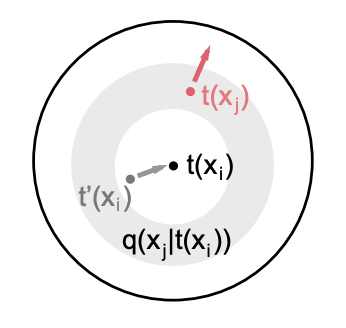
Conditional Negative Sampling for Contrastive Learning of Visual Representations
Authors: Mike Wu, Milan Mosse, Chengxu Zhuang, Daniel Yamins, Noah Goodman
Contact: wumike@stanford.edu
Links: Paper
Keywords: contrastive learning, negative samples, mutual information
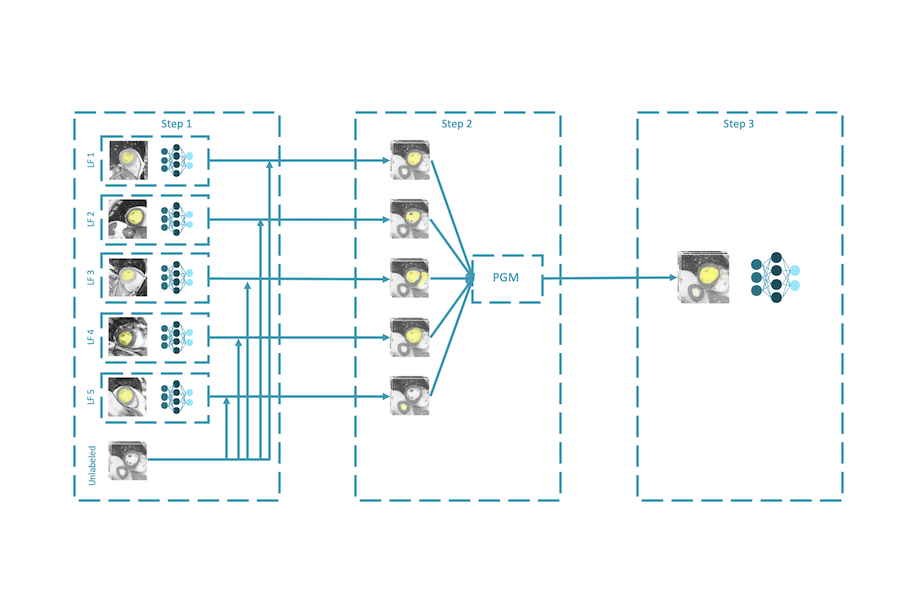
Cut out the annotator, keep the cutout: better segmentation with weak supervision
Authors: Sarah Hooper, Michael Wornow, Ying Hang Seah, Peter Kellman, Hui Xue, Frederic Sala, Curtis Langlotz, Christopher Ré
Contact: smhooper@stanford.edu
Links: Paper
Keywords: medical imaging, segmentation, weak supervision
Evaluating the Disentanglement of Deep Generative Models through Manifold Topology
Authors: Sharon Zhou, Eric Zelikman, Fred Lu, Andrew Y. Ng, Gunnar E. Carlsson, Stefano Ermon
Contact: sharonz@cs.stanford.edu
Links: Paper | Website
Keywords: generative models, evaluation, disentanglement
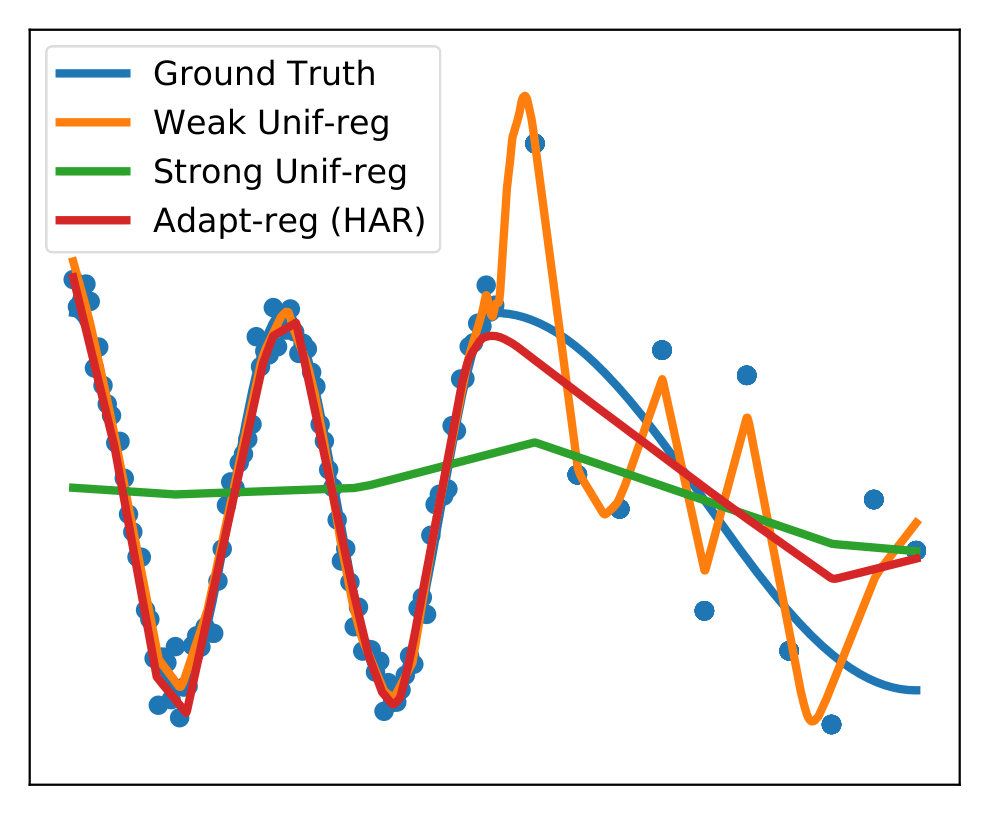
Heteroskedastic and Imbalanced Deep Learning with Adaptive Regularization
Authors: Kaidi Cao, Yining Chen, Junwei Lu, Nikos Arechiga, Adrien Gaidon, Tengyu Ma
Contact: kaidicao@cs.stanford.edu
Links: Paper
Keywords: deep learning, noise robust learning, imbalanced learning
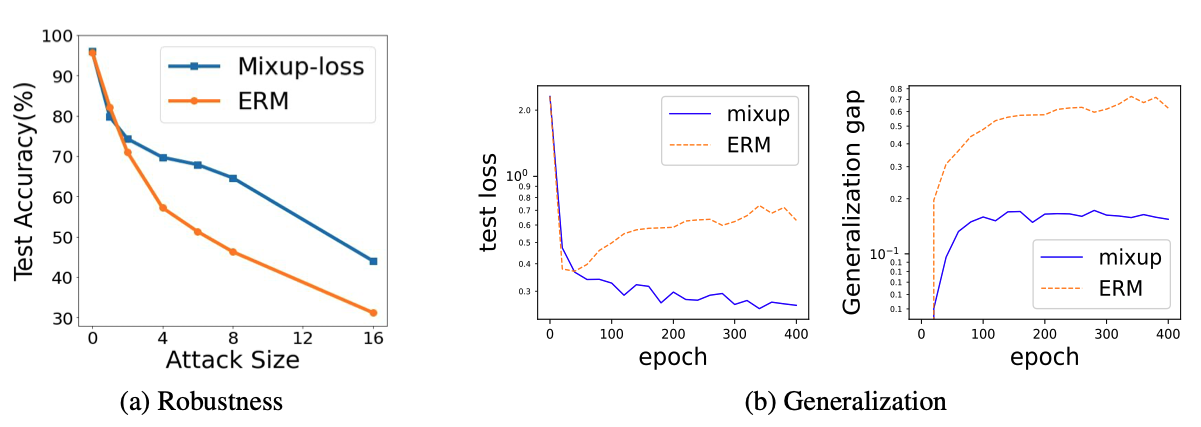
How Does Mixup Help With Robustness and Generalization?
Authors: Linjun Zhang, Zhun Deng, Kenji Kawaguchi, Amirata Ghorbani, James Zou
Contact: jamesz@stanford.edu
Links: Paper
Keywords: mixup, adversarial robustness, generalization
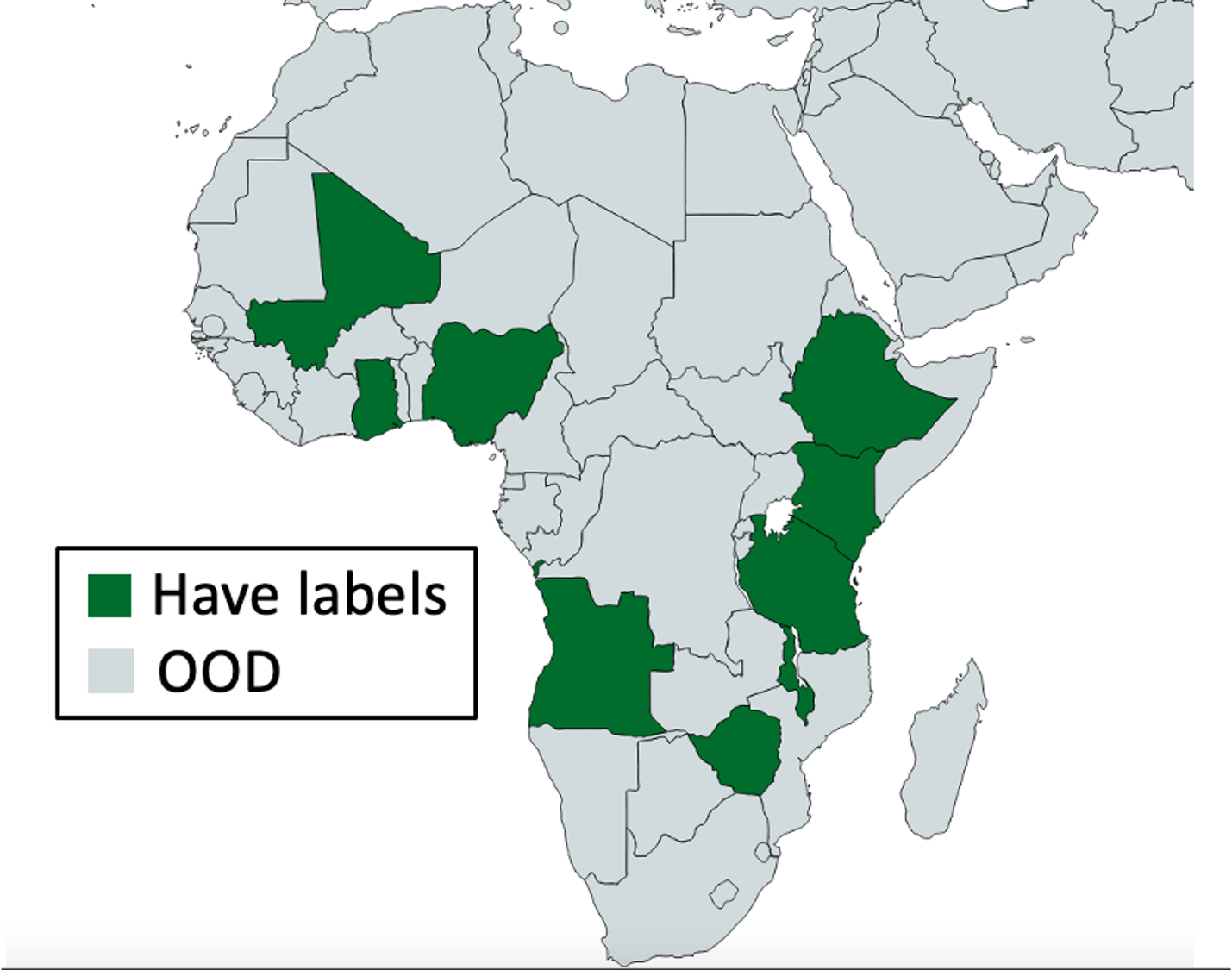
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Authors: Sang Michael Xie*, Ananya Kumar*, Robbie Jones*, Fereshte Khani, Tengyu Ma, Percy Liang
Contact: xie@cs.stanford.edu
Links: Paper | Website
Keywords: pre-training, self-training theory, robustness, out-of-distribution, unlabeled data, auxiliary information, multi-task learning theory, distribution shift
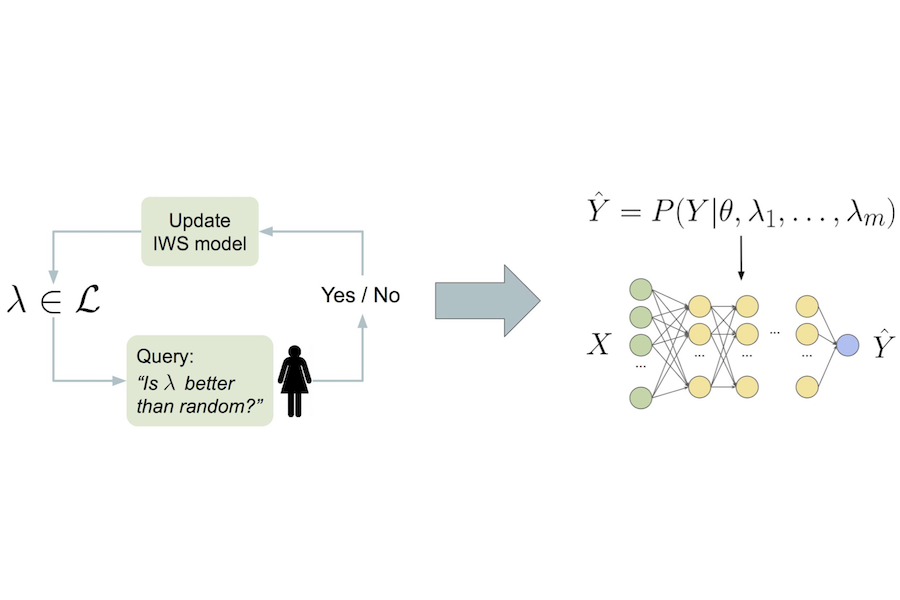
Interactive Weak Supervision: Learning Useful Heuristics for Data Labeling
Authors: Benedikt Boecking, Willie Neiswanger, Eric Xing, Artur Dubrawski
Contact: neiswanger@cs.stanford.edu
Links: Paper | Website
Keywords: weak supervision, active learning, interactive learning, data programming, level set estimation
Language-Agnostic Representation Learning of Source Code from Structure and Context
Authors: Daniel Zügner, Tobias Kirschstein, Michele Catasta, Jure Leskovec, Stephan Günnemann
Contact: pirroh@cs.stanford.edu
Links: Paper | Blog Post | Website
Keywords: transformer; source code; ml4code

Learning Energy-Based Models by Diffusion Recovery Likelihood
Authors: Ruiqi Gao, Yang Song, Ben Poole, Ying Nian Wu, and Diederik P. Kingma
Contact: ruiqigao@ucla.edu
Links: Paper
Keywords: energy-based models, diffusion score models, generative modeling

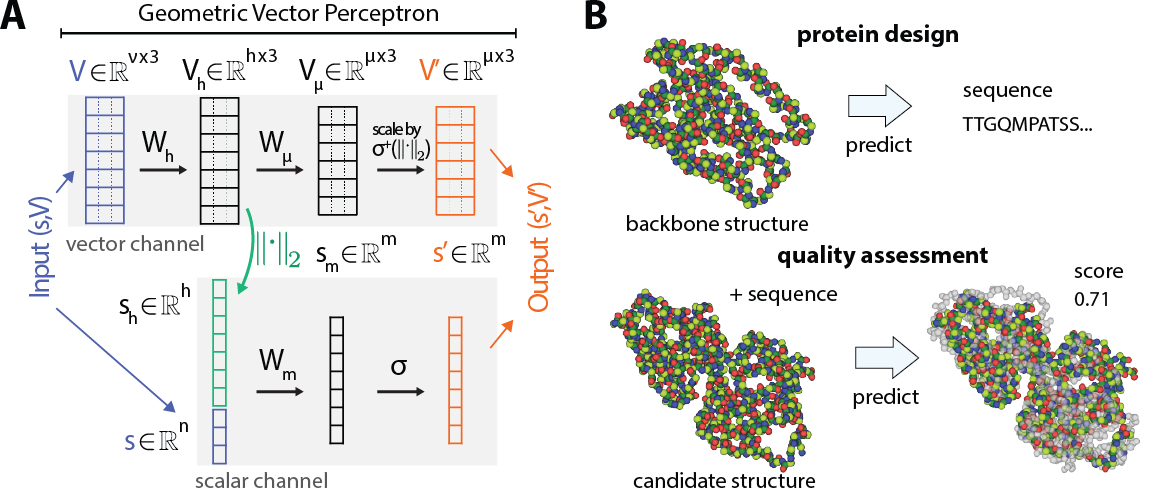
Learning from Protein Structure with Geometric Vector Perceptrons
Authors: Bowen Jing, Stephan Eismann, Patricia Suriana, Raphael John Lamarre Townshend, Ron Dror
Contact: bjing@cs.stanford.edu, seismann@cs.stanford.edu
Links: Paper | Website
Keywords: structural biology, graph neural networks, proteins, geometric deep learning
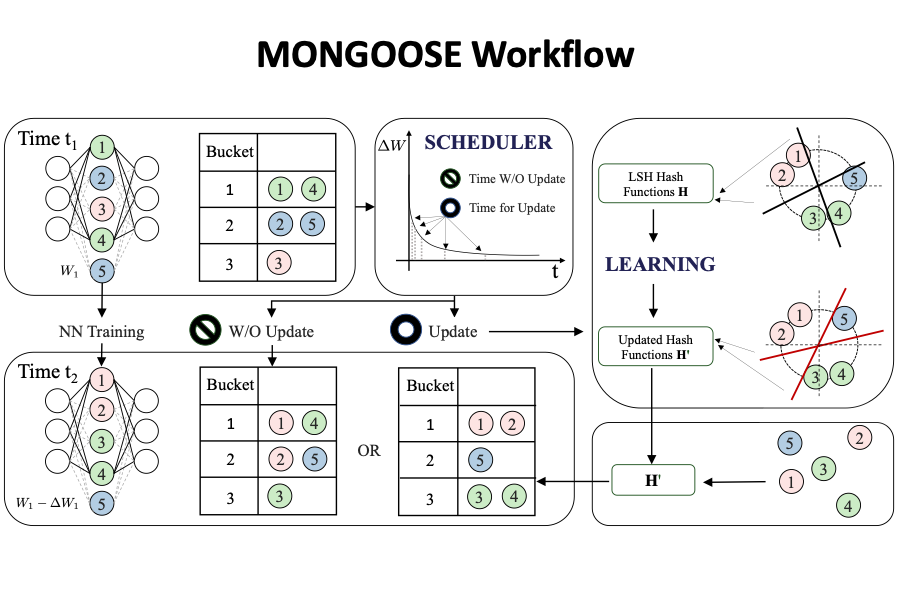
MONGOOSE: A Learnable LSH Framework for Efficient Neural Network Training
Authors: Beidi Chen, Zichang Liu, Binghui Peng, Zhaozhuo Xu, Jonathan Lingjie Li, Tri Dao, Zhao Song , Anshumali Shrivastava , Christopher Ré
Contact: beidic@stanford.edu
Award nominations: Oral
Links: Paper | Video | Website
Keywords: efficient training; locality sensitive hashing; nearest-neighbor search;
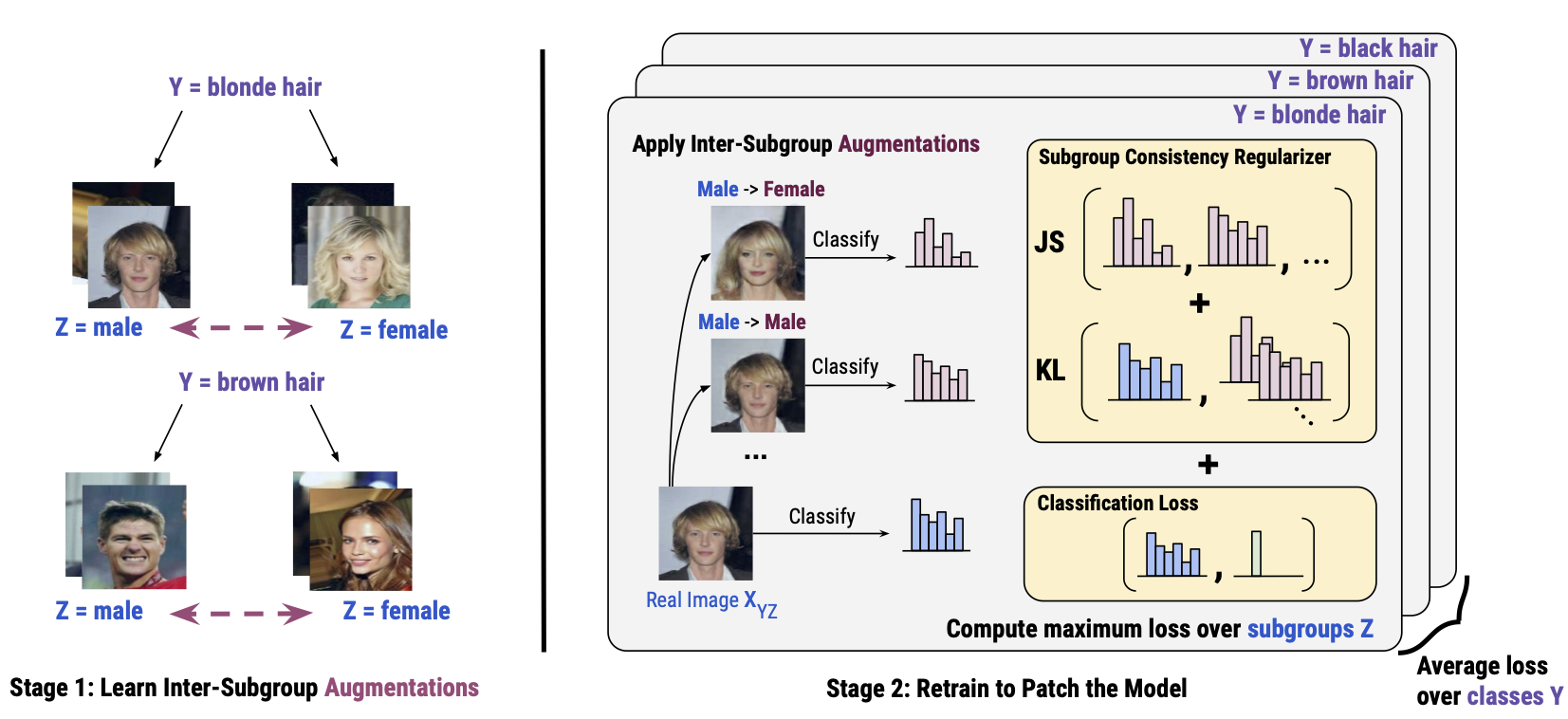
Model Patching: Closing the Subgroup Performance Gap with Data Augmentation
Authors: Karan Goel*, Albert Gu*, Sharon Li, Christopher Re
Contact: kgoel@cs.stanford.edu
Links: Paper | Blog Post | Video | Website
Keywords: data augmentation, robustness, consistency training
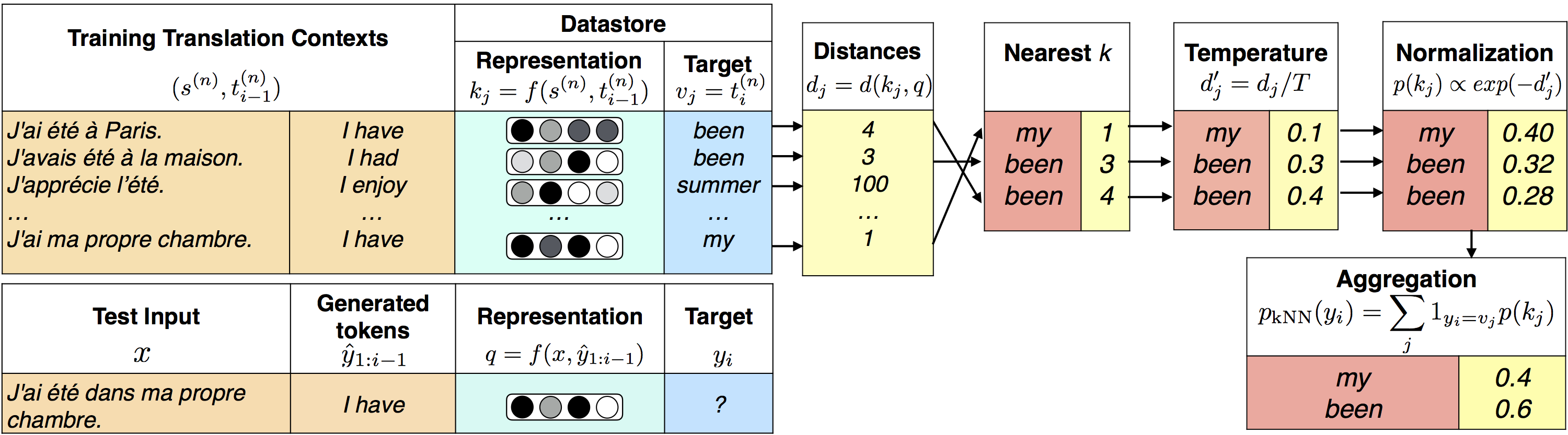
Nearest Neighbor Machine Translation
Authors: Urvashi Khandelwal, Angela Fan, Dan Jurafsky, Luke Zettlemoyer, Mike Lewis
Contact: urvashik@stanford.edu
Links: Paper
Keywords: nearest neighbors, machine translation
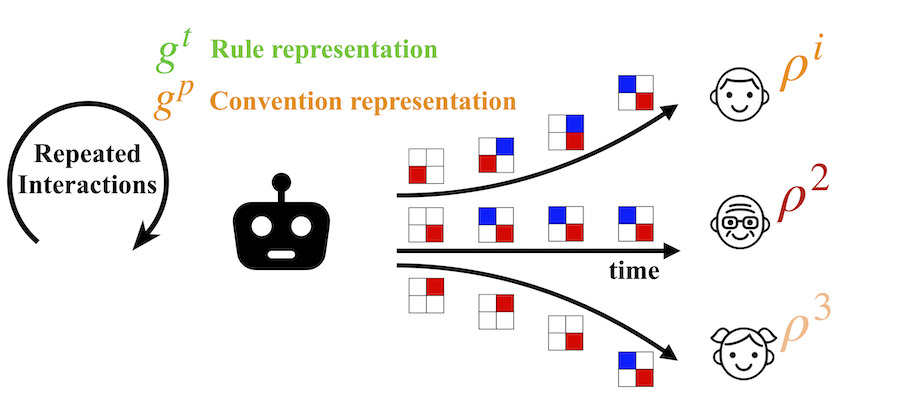
On the Critical Role of Conventions in Adaptive Human-AI Collaboration
Authors: Andy Shih, Arjun Sawhney, Jovana Kondic, Stefano Ermon, Dorsa Sadigh
Contact: andyshih@cs.stanford.edu
Links: Paper | Blog Post | Website
Keywords: multi-agent systems, human-robot interaction
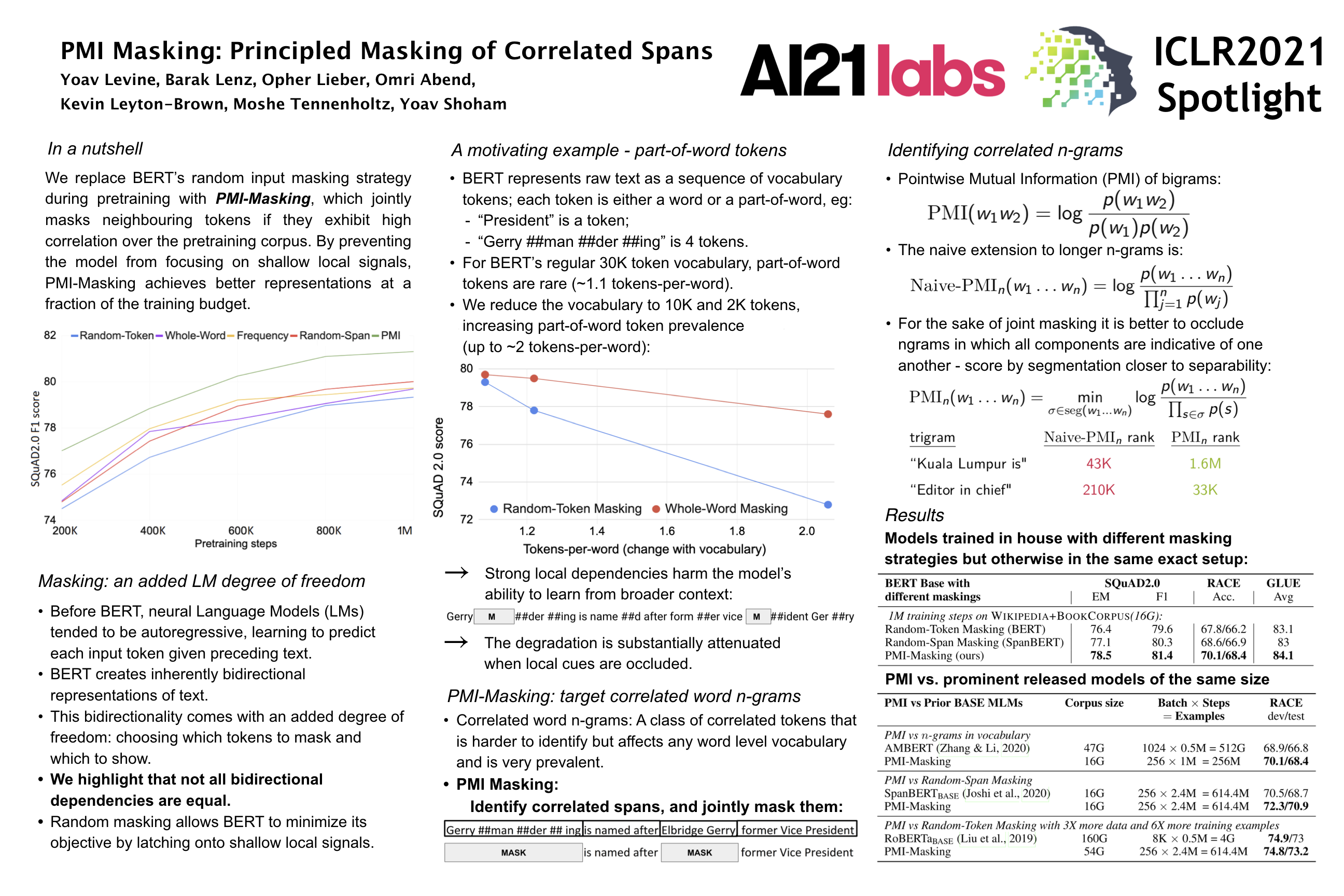
PMI-Masking: Principled masking of correlated spans
Authors: Yoav Levine, Barak Lenz, Opher Lieber, Omri Abend, Kevin Leyton-Brown, Moshe Tennenholtz, Yoav Shoham
Contact: shoham@cs.stanford.edu
Award nominations: Spotlight selection
Links: Paper
Keywords: masked language models, pointwise mutual information (pmi)
Score-Based Generative Modeling through Stochastic Differential Equations
Authors: Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, Ben Poole
Contact: yangsong@cs.stanford.edu
Award nominations: Outstanding Paper Award
Links: Paper | Blog Post | Website
Keywords: generative modeling, stochastic differential equations, score matching, inverse problems, likelihood

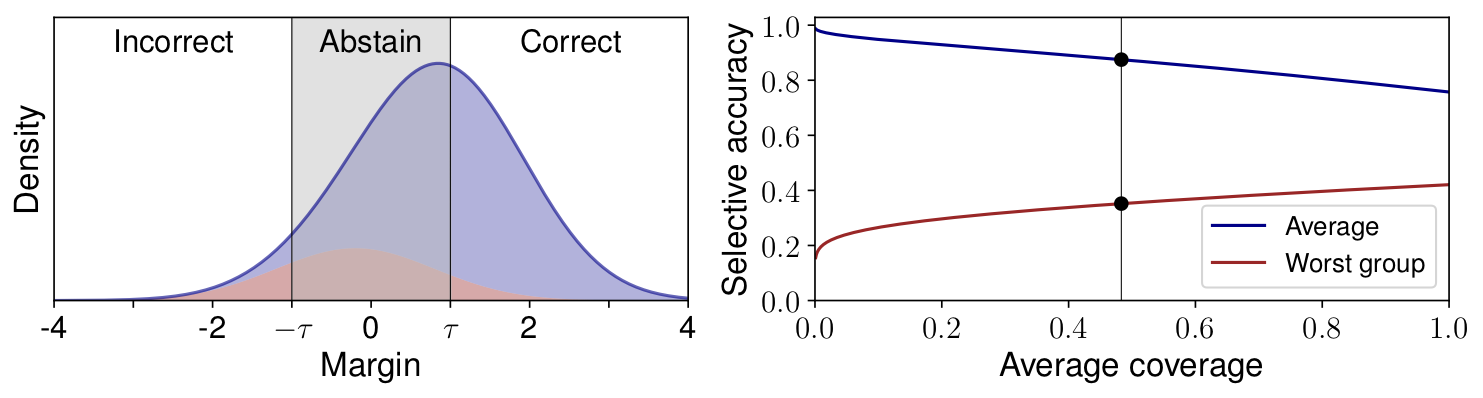
Selective Classification Can Magnify Disparities Across Groups
Authors: Erik Jones*, Shiori Sagawa*, Pang Wei Koh*, Ananya Kumar, Percy Liang
Contact: erjones@cs.stanford.edu
Links: Paper
Keywords: selective classification, group disparities, log-concavity, robustness
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data
Authors: Colin Wei, Kendrick Shen, Yining Chen, Tengyu Ma
Contact: colinwei@stanford.edu
Links: Paper
Keywords: deep learning theory, domain adaptation theory, unsupervised learning theory, semi-supervised learning theory
Viewmaker Networks: Learning Views for Unsupervised Representation Learning
Authors: Alex Tamkin, Mike Wu, Noah Goodman
Contact: atamkin@stanford.edu
Links: Paper | Blog Post
Keywords: contrastive learning, domain-agnostic, pretraining, self-supervised, representation learning

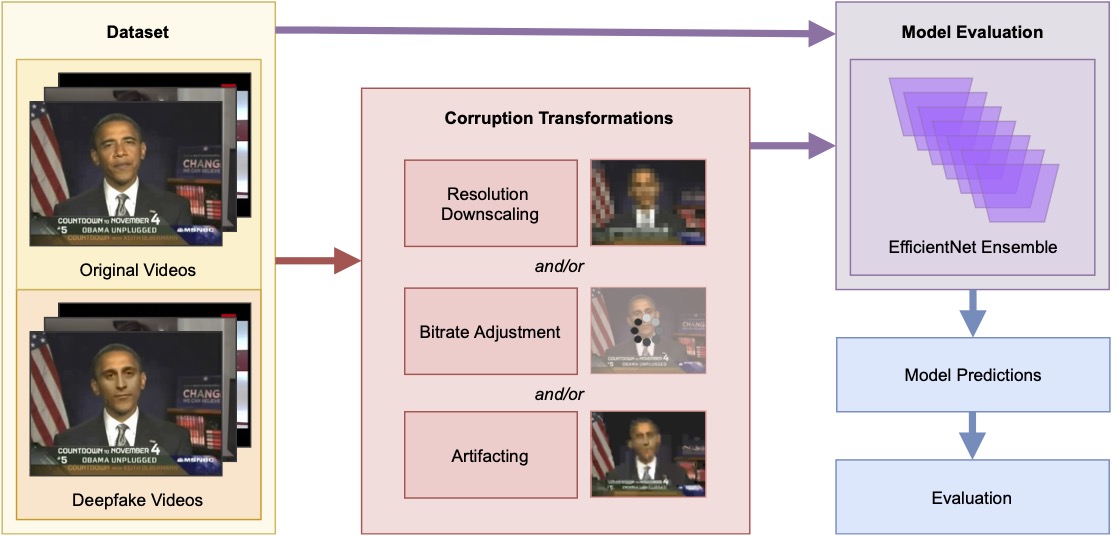
Practical Deepfake Detection: Vulnerabilities in Global Contexts
Authors: Yang Andrew Chuming, Daniel Jeffrey Wu, Ken Hong
Contact: ycm@stanford.edu
Award nominations: Spotlight talk at the ICLR-21 Workshop on Responsible AI
Keywords: deepfake, deepfakes, robustness, corruption, low-bandwidth, faceforensics
We look forward to seeing you at ICLR 2021!