Adapting natural-language-processing techniques to recommendation systems and algorithmic fairness are two central topics at this year’s conference.Read More
Parallel data processing with RStudio on Amazon SageMaker
Last year, we announced the general availability of RStudio on Amazon SageMaker, the industry’s first fully managed RStudio Workbench integrated development environment (IDE) in the cloud. You can quickly launch the familiar RStudio IDE, and dial up and down the underlying compute resources without interrupting your work, making it easy to build machine learning (ML) and analytics solutions in R at scale.
With ever-increasing data volume being generated, datasets used for ML and statistical analysis are growing in tandem. With this brings the challenges of increased development time and compute infrastructure management. To solve these challenges, data scientists have looked to implement parallel data processing techniques. Parallel data processing, or data parallelization, takes large existing datasets and distributes them across multiple processers or nodes to operate on the data simultaneously. This can allow for faster processing time of larger datasets, along with optimized usage on compute. This can help ML practitioners create reusable patterns for dataset generation, and also help reduce compute infrastructure load and cost.
Solution overview
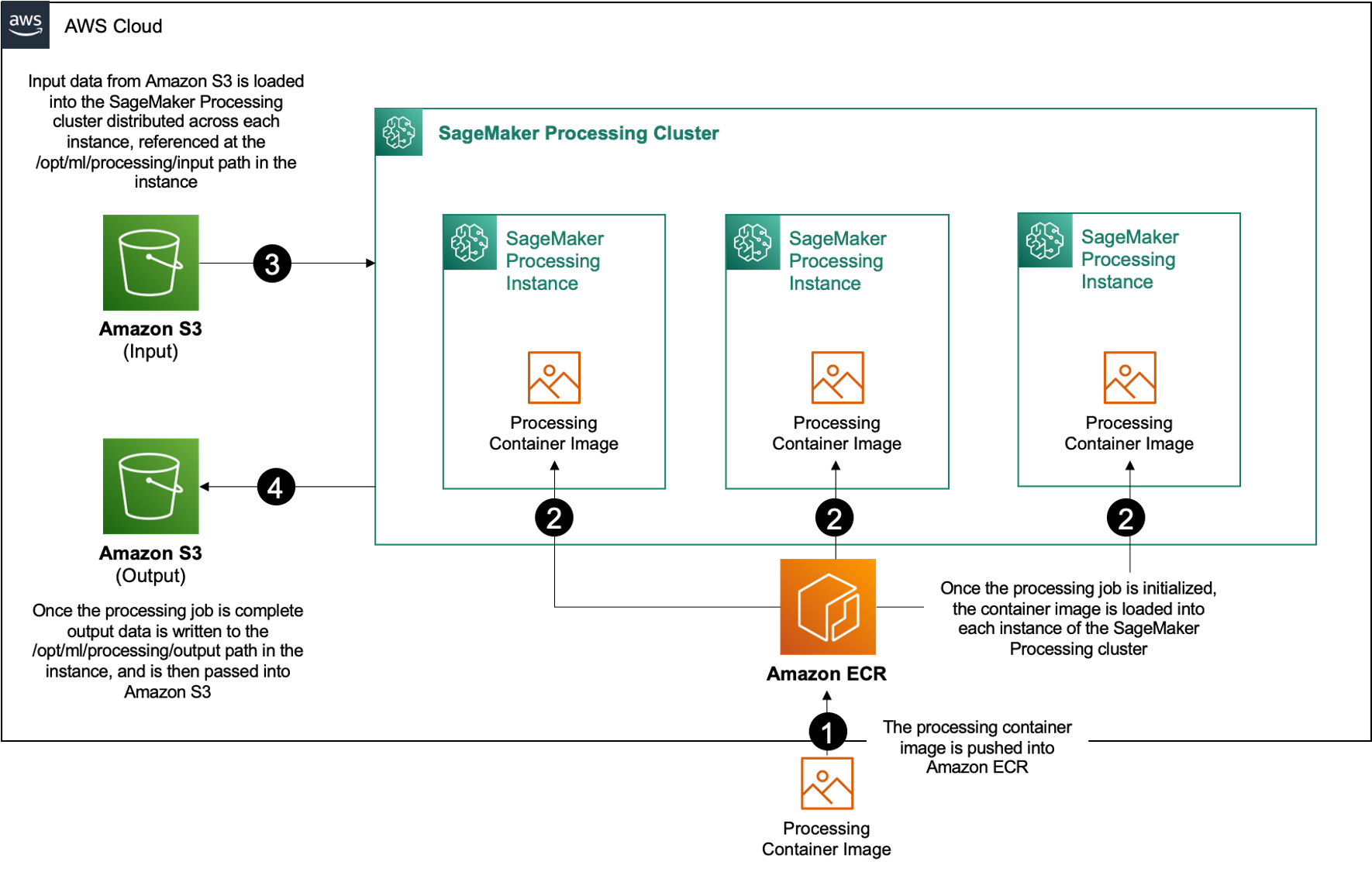
Within Amazon SageMaker, many customers use SageMaker Processing to help implement parallel data processing. With SageMaker Processing, you can use a simplified, managed experience on SageMaker to run your data processing workloads, such as feature engineering, data validation, model evaluation, and model interpretation. This brings many benefits because there’s no long-running infrastructure to manage—processing instances spin down when jobs are complete, environments can be standardized via containers, data within Amazon Simple Storage Service (Amazon S3) is natively distributed across instances, and infrastructure settings are flexible in terms of memory, compute, and storage.
SageMaker Processing offers options for how to distribute data. For parallel data processing, you must use the ShardedByS3Key option for the S3DataDistributionType. When this parameter is selected, SageMaker Processing takes the provided n instances and distribute objects 1/n objects from the input data source across the instances. For example, if two instances are provided with four data objects, each instance receives two objects.
SageMaker Processing requires three components to run processing jobs:
- A container image that has your code and dependencies to run your data processing workloads
- A path to an input data source within Amazon S3
- A path to an output data source within Amazon S3
The process is depicted in the following diagram.
In this post, we show you how to use RStudio on SageMaker to interface with a series of SageMaker Processing jobs to create a parallel data processing pipeline using the R programming language.
The solution consists of the following steps:
- Set up the RStudio project.
- Build and register the processing container image.
- Run the two-step processing pipeline:
- The first step takes multiple data files and processes them across a series of processing jobs.
- The second step concatenates the output files and splits them into train, test, and validation datasets.
Prerequisites
Complete the following prerequisites:
- Set up the RStudio on SageMaker Workbench. For more information, refer to Announcing Fully Managed RStudio on Amazon SageMaker for Data Scientists.
- Create a user with RStudio on SageMaker with appropriate access permissions.
Set up the RStudio project
To set up the RStudio project, complete the following steps:
- Navigate to your Amazon SageMaker Studio control panel on the SageMaker console.
- Launch your app in the RStudio environment.

- Start a new RStudio session.
- For Session Name, enter a name.
- For Instance Type and Image, use the default settings.
- Choose Start Session.

- Navigate into the session.
- Choose New Project, Version control, and then Select Git.
- For Repository URL, enter
https://github.com/aws-samples/aws-parallel-data-processing-r.git - Leave the remaining options as default and choose Create Project.

You can navigate to the aws-parallel-data-processing-R directory on the Files tab to view the repository. The repository contains the following files:
Container_Build.rmd-
/datasetbank-additional-full-data1.csvbank-additional-full-data2.csvbank-additional-full-data3.csvbank-additional-full-data4.csv
/dockerDockerfile-ProcessingParallel_Data_Processing.rmd-
/preprocessingfilter.Rprocess.R
Build the container
In this step, we build our processing container image and push it to Amazon Elastic Container Registry (Amazon ECR). Complete the following steps:
- Navigate to the
Container_Build.rmdfile. - Install the SageMaker Studio Image Build CLI by running the following cell. Make sure you have the required permissions prior to completing this step, this is a CLI designed to push and register container images within Studio.
- Run the next cell to build and register our processing container:
After the job has successfully run, you receive an output that looks like the following:
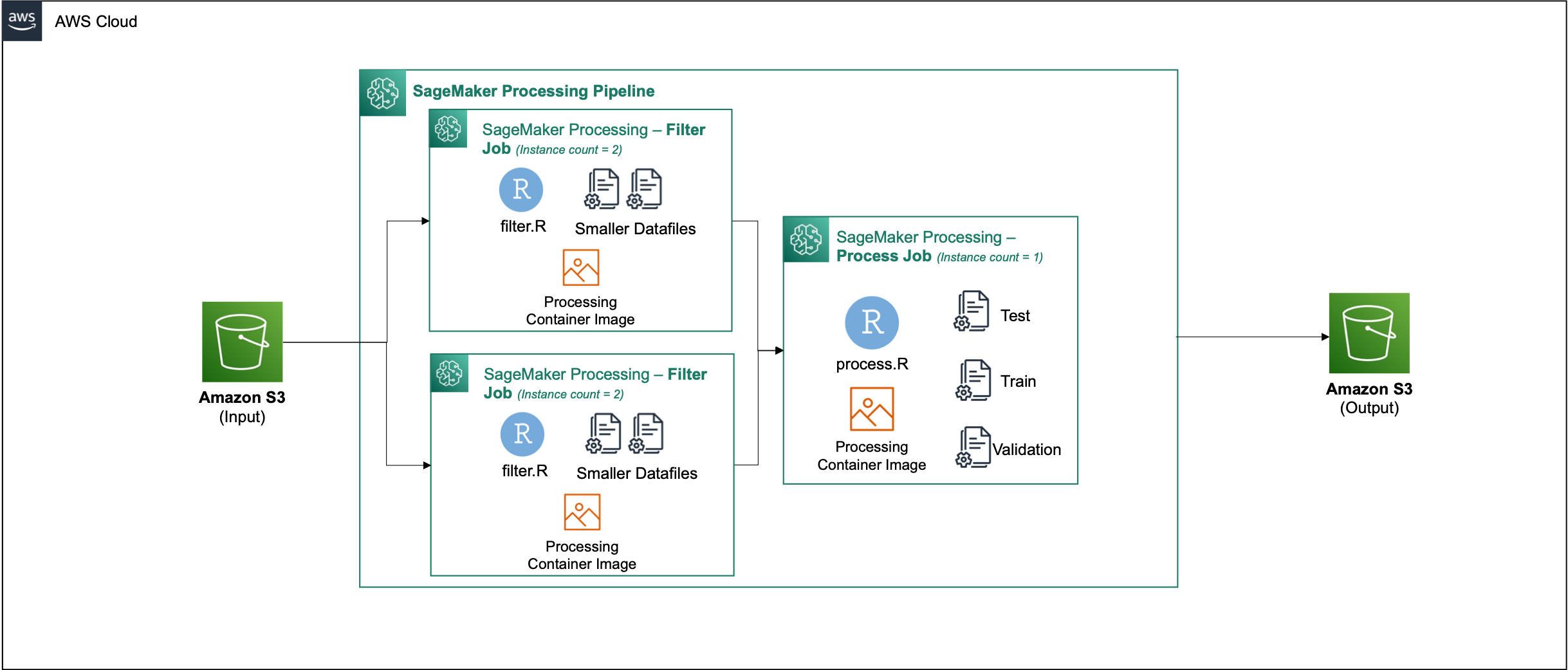
Run the processing pipeline
After you build the container, navigate to the Parallel_Data_Processing.rmd file. This file contains a series of steps that helps us create our parallel data processing pipeline using SageMaker Processing. The following diagram depicts the steps of the pipeline that we complete.
Start by running the package import step. Import the required RStudio packages along with the SageMaker SDK:
Now set up your SageMaker execution role and environment details:
Initialize the container that we built and registered in the earlier step:
From here we dive into each of the processing steps in more detail.
Upload the dataset
For our example, we use the Bank Marketing dataset from UCI. We have already split the dataset into multiple smaller files. Run the following code to upload the files to Amazon S3:
After the files are uploaded, move to the next step.
Perform parallel data processing
In this step, we take the data files and perform feature engineering to filter out certain columns. This job is distributed across a series of processing instances (for our example, we use two).
We use the filter.R file to process the data, and configure the job as follows:
As mentioned earlier, when running a parallel data processing job, you must adjust the input parameter with how the data will be sharded, and the type of data. Therefore, we provide the sharding method by S3Prefix:
After you insert these parameters, SageMaker Processing will equally distribute the data across the number of instances selected.
Adjust the parameters as necessary, and then run the cell to instantiate the job.
Generate training, test, and validation datasets
In this step, we take the processed data files, combine them, and split them into test, train, and validation datasets. This allows us to use the data for building our model.
We use the process.R file to process the data, and configure the job as follows:
Adjust the parameters are necessary, and then run the cell to instantiate the job.
Run the pipeline
After all the steps are instantiated, start the processing pipeline to run each step by running the following cell:
The time each of these jobs takes will vary based on the instance size and count selected.
Navigate to the SageMaker console to see all your processing jobs.
We start with the filtering job, as shown in the following screenshot.

When that’s complete, the pipeline moves to the data processing job.

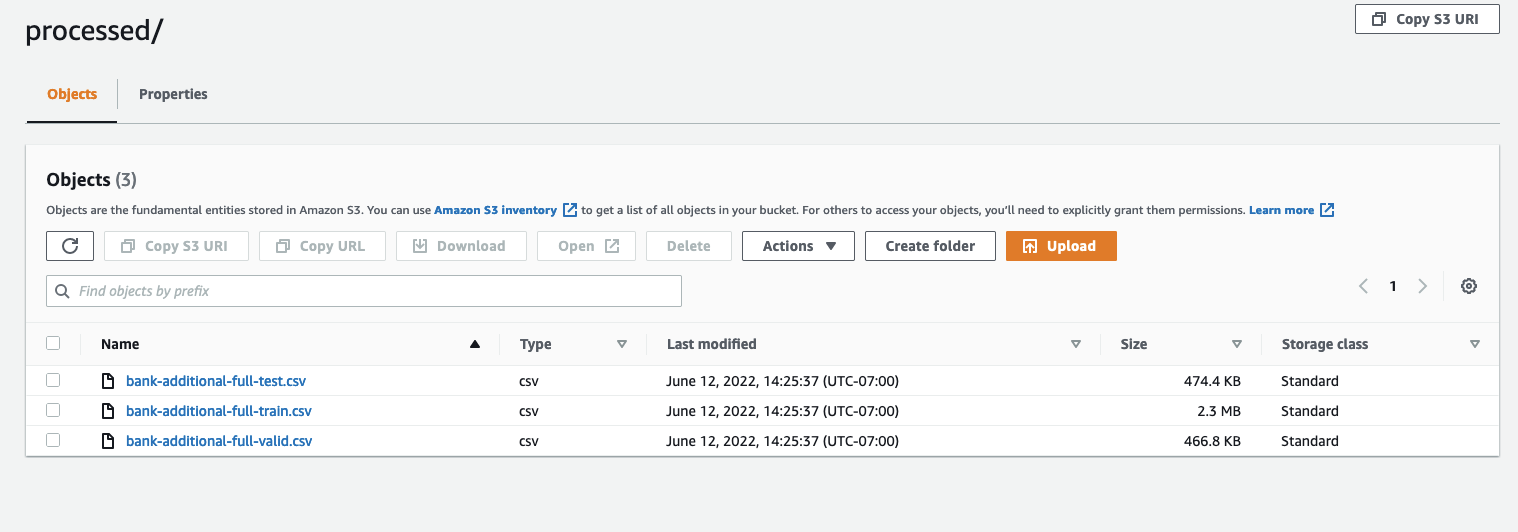
When both jobs are complete, navigate to your S3 bucket. Look within the sagemaker-rstudio-example folder, under processed. You can see the files for the train, test and validation datasets.
Conclusion
With an increased amount of data that will be required to build more and more sophisticated models, we need to change our approach to how we process data. Parallel data processing is an efficient method in accelerating dataset generation, and if coupled with modern cloud environments and tooling such as RStudio on SageMaker and SageMaker Processing, can remove much of the undifferentiated heavy lifting of infrastructure management, boilerplate code generation, and environment management. In this post, we walked through how you can implement parallel data processing within RStudio on SageMaker. We encourage you to try it out by cloning the GitHub repository, and if you have suggestions on how to make the experience better, please submit an issue or a pull request.
To learn more about the features and services used in this solution, refer to RStudio on Amazon SageMaker and Amazon SageMaker Processing.
About the authors
 Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
Raj Pathak is a Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Document Extraction, Contact Center Transformation and Computer Vision.
 Jake Wen is a Solutions Architect at AWS with passion for ML training and Natural Language Processing. Jake helps Small Medium Business customers with design and thought leadership to build and deploy applications at scale. Outside of work, he enjoys hiking.
Jake Wen is a Solutions Architect at AWS with passion for ML training and Natural Language Processing. Jake helps Small Medium Business customers with design and thought leadership to build and deploy applications at scale. Outside of work, he enjoys hiking.
 Aditi Rajnish is a first-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
Aditi Rajnish is a first-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
 Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Add-ons.
Sean Morgan is an AI/ML Solutions Architect at AWS. He has experience in the semiconductor and academic research fields, and uses his experience to help customers reach their goals on AWS. In his free time, Sean is an active open-source contributor and maintainer, and is the special interest group lead for TensorFlow Add-ons.
 Paul Wu is a Solutions Architect working in AWS’ Greenfield Business in Texas. His areas of expertise include containers and migrations.
Paul Wu is a Solutions Architect working in AWS’ Greenfield Business in Texas. His areas of expertise include containers and migrations.
AI Models vs. AI Systems: Understanding Units of Performance Assessment
As AI becomes more deeply integrated into every aspect of our lives, it is essential that AI systems perform appropriately for their intended use. We know AI models can never be perfect, so how do we decide when AI performance is ‘good enough’ for use in a real life application? Is level of accuracy a sufficient gauge? What else matters? These are questions Microsoft Research tackles every day as part of our mission to follow a responsible, human-centered approach to building and deploying future-looking AI systems.
To answer the question, “what is good enough?”, it becomes necessary to distinguish between an AI model and an AI system as the unit of performance assessment. An AI model typically involves some input data, a pattern-matching algorithm, and an output classification. For example, a radiology scan of the patient’s chest might be shown to an AI model to predict whether a patient has COVID-19. An AI system, by contrast, would evaluate a broader range of information about the patient, beyond the COVID-19 prediction, to inform a clinical decision and treatment plan.
Research has shown that human-AI collaboration can increase the accuracy of AI models alone (reference). In this blog, we share key learnings from the recently retired Project Talia, the prior collaboration between Microsoft Research and SilverCloud Health to understand how thinking about the AI system as a whole—beyond the AI model—can help to more precisely define and enumerate ‘good enough’ for real-life application.
In Project Talia, we developed two AI models to predict treatment outcomes for patients receiving human-supported, internet-delivered cognitive behavioral treatment (iCBT) for symptoms of depression and anxiety. These AI models have the potential to assist the work practices of iCBT coaches. These iCBT coaches are practicing behavioral health professionals specifically trained to guide patients on the use of the treatment platform, recommend specific treatments, and help the patient work through identified difficulties.
Project Talia offers an illustration of the distinction between the AI model produced during research and a resulting AI system that could potentially get implemented to support real-life patient treatment. In this scenario, we demonstrate every system element that must be considered to ensure effective system outcomes, not just AI model outcomes.
Project Talia: Improving Mental Health Outcomes
SilverCloud Health (acquired by Amwell in 2021) is an evidence-based, digital, on-demand mental health platform that delivers iCBT-based programs to patients in combination with limited but regular contact from the iCBT coach. The platform offers more than thirty iCBT programs, predominantly for treating mild-to-moderate symptoms of depression, anxiety, and stress.
Patients work through the program(s) independently and with regular assistance from the iCBT coach, who provides guidance and encouragement through weekly reviews and feedback on the treatment journey.
Previous research (reference) has shown that involving a human coach within iCBT leads to more effective treatment outcomes for patients than unsupported interventions. Aiming to maximize the effects and outcomes of human support in this format, AI models were developed to dynamically predict the likelihood of a patient achieving a reliable improvement[1] in their depression and anxiety symptoms by the end of the treatment program (typically 8 to 14 weeks in length).
Existing literature on feedback-informed therapy (reference) and Project Talia research (reference) suggest that having access to these predictions could provide reassurance for those patients ‘on track’ toward achieving a positive outcome from treatment, or prompt iCBT coaches to make appropriate adjustments therein to better meet those patients’ needs.
AI Model vs. AI System
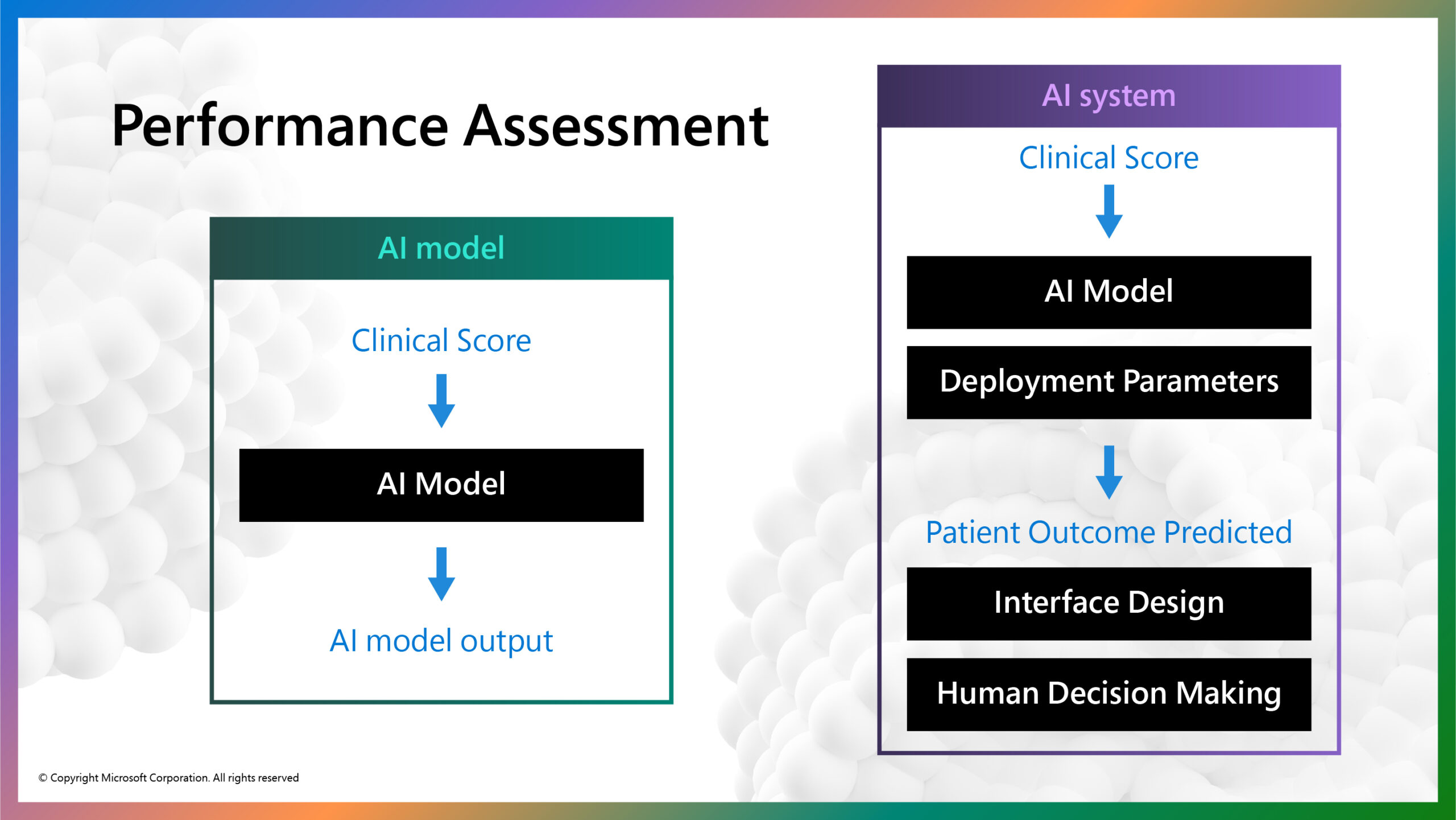
The figure above illustrates the distinction between the AI model and AI system in this example (figure 1). The AI model takes in a clinical score calculated by a patient’s responses to standardized clinical questionnaires that assess symptoms of depression and anxiety at each treatment session. After three treatment sessions, the AI model predicts whether or not the patient will achieve a clinically significant reduction in mental health symptoms at completion of the treatment program. The AI model itself is trained on fully anonymized clinical scores of nearly 50,000 previous SilverCloud Health patients and achieved an acceptable accuracy of 87% (reference).
The outcome prediction could then be embedded into the clinical management interface that guides iCBT coaches in their efforts to make more informed decisions about that patient’s treatment journey (i.e., increase level and frequency of support from the coach).
When AI models are introduced into human contexts such as this, they rarely work in isolation. In this case, the clinical score is entered into a model with parameters tuned to a particular healthcare context. This example illustrates how AI model performance metrics are not sufficient to determine whether an AI system is ‘good enough’ for real-life application. We must examine challenges that arise throughout every element of the AI system.
Following are two specific examples of how AI system performance can be altered while retaining the same model: contextual model parameters and user interface and workflow integration.
Contextual Model Parameters: Which Error Type is Most Costly
Examining overall performance metrics exclusively can limit visibility into the different types of errors an AI model can make, which can have (potentially negative) implications on the AI system as a whole. For example, an AI model’s false positive and false negative errors can impact the AI system differently. A false positive error could mean a patient who needed extra help might not receive it; a false negative would mean a patient may receive unnecessary care. In this case, false positive errors would have a much bigger impact on a patient than false negative errors. But false negative errors can also be problematic when they cause unnecessary resource allocation.
Contextual model parameters can be tuned to change the balance between error types while maintaining the overall accuracy of the model. The clinical team could define these contextual model parameters to minimize false positive errors that could be more detrimental to patients, by specifying the model to produce only 5% false positives errors. Choosing this parameter could come, however, at the expense of a higher false negative rate, which would require monitoring how AI model performance might then impact service costs or staff burn-out.
This example illustrates the challenging decisions domain experts, who may know little about the details of AI, must make and the implications these decisions can have on AI system performance. In this example, we provided a prototype visualization tool to help the clinical team in their understanding of the implications of their choices across different patient groups.
We are moving into a world in which domain experts and business decision makers, who embed AI into their work practices, will bear increasing responsibility in assessing and debugging AI systems to improve quality, functionality, and relevance to their work.
User Interface and Workflow Integration
AI model predictions need to be contextualized for a given workflow. Research on iCBT coaches has shown that listing the predictions for all patients of a coach in a single screen outside the normal patient-centered workflow can be demotivating (reference). If a coach saw that the majority of their patients were predicted to not improve, or if their patients’ outcomes were predicted to be worse for than those of their colleagues, this could lead coaches to question their own competence or invite competitive thoughts about their colleagues’ performances—both unhelpful in this context.
Displaying the AI model prediction inside the individual patient’s profile, as in the illustration below (figure 2), provides a useful indicator of how well the person is doing and therefore can guide clinical practice. It also deliberately encourages the use of the AI model prediction within the context of other relevant clinical information.
Situating the AI output with other patient information can nurture a more balanced relationship between AI-generated insight and coaches’ own patient assessments, which can counterbalance effects of over-reliance and over-trust in potentially fallible AI predictions (also referred to as automation bias).
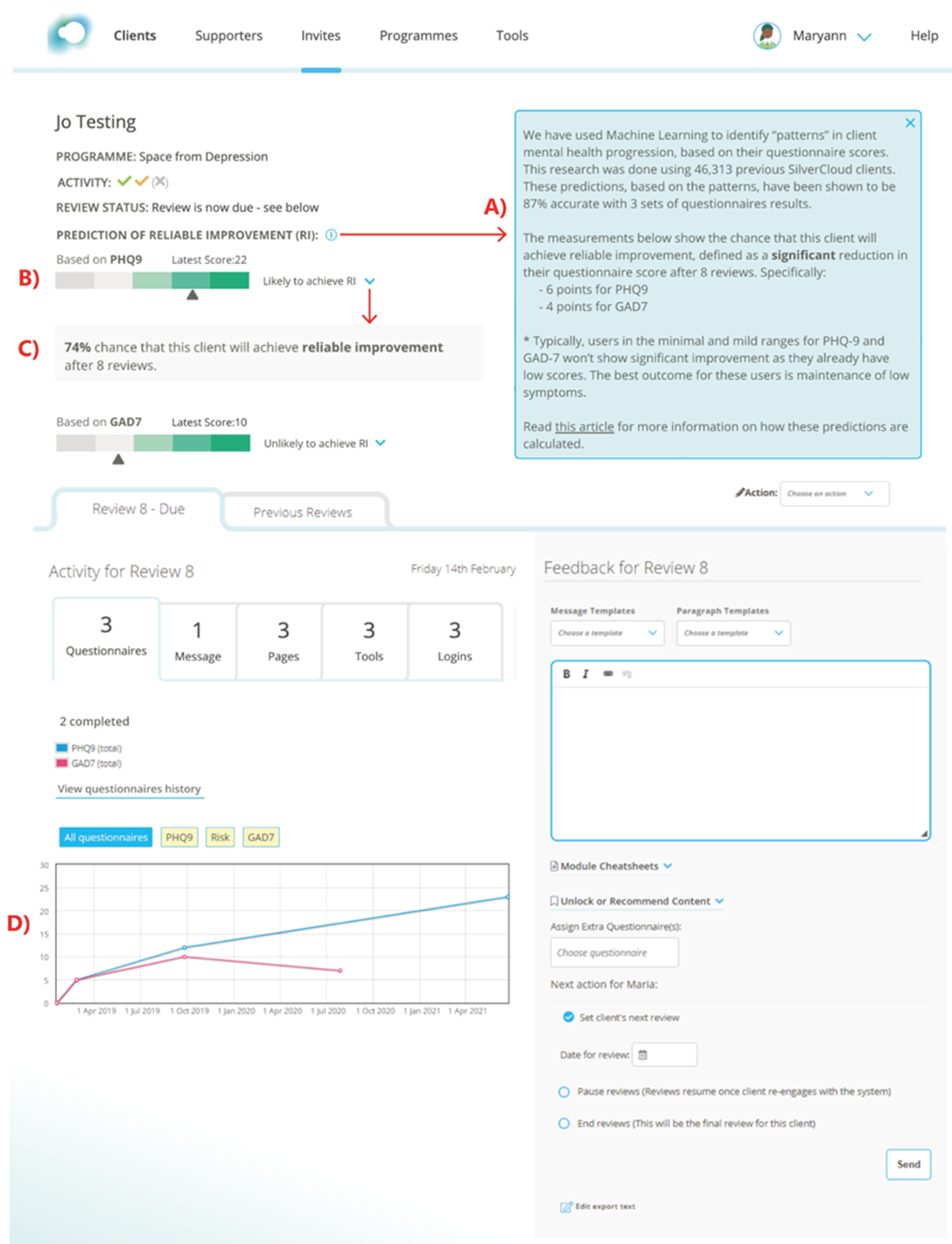
This example illustrates the importance of user interface design and workflow integration in how well AI model predictions are understood and can contribute to the success or failure of an AI system as a whole. Domain experts, user research, and service designers start to play a far more important role in the development of AI systems than the typical focus on data scientists.
Final Thoughts
Aggregate performance metrics, such as accuracy, area-under-the-curve (AUC) scores, or mean square error, are easy to calculate on an AI model, but they indicate little about the utility or function of the entire AI system in practice. So, how do we decide when AI system performance is ‘good enough’ for use in real-life application? It is clear that high levels of AI model performance alone are not sufficient—we must consider every element of the AI system.
Contextual model parameters and interface and workflow design present just two examples of how preparing domain experts with expectations, skills, and tools are necessary for optimal benefit from the incorporation of AI systems into human contexts.
[1] Defined as an improvement of 6 or more points on the PHQ-9 depression scale, or 4 or more points on the Gad-7 anxiety scale.
The post AI Models vs. AI Systems: Understanding Units of Performance Assessment appeared first on Microsoft Research.
The surprisingly subtle challenge of automating damage detection
Why detecting damage is so tricky at Amazon’s scale — and how researchers are training robots to help with that gargantuan task.Read More
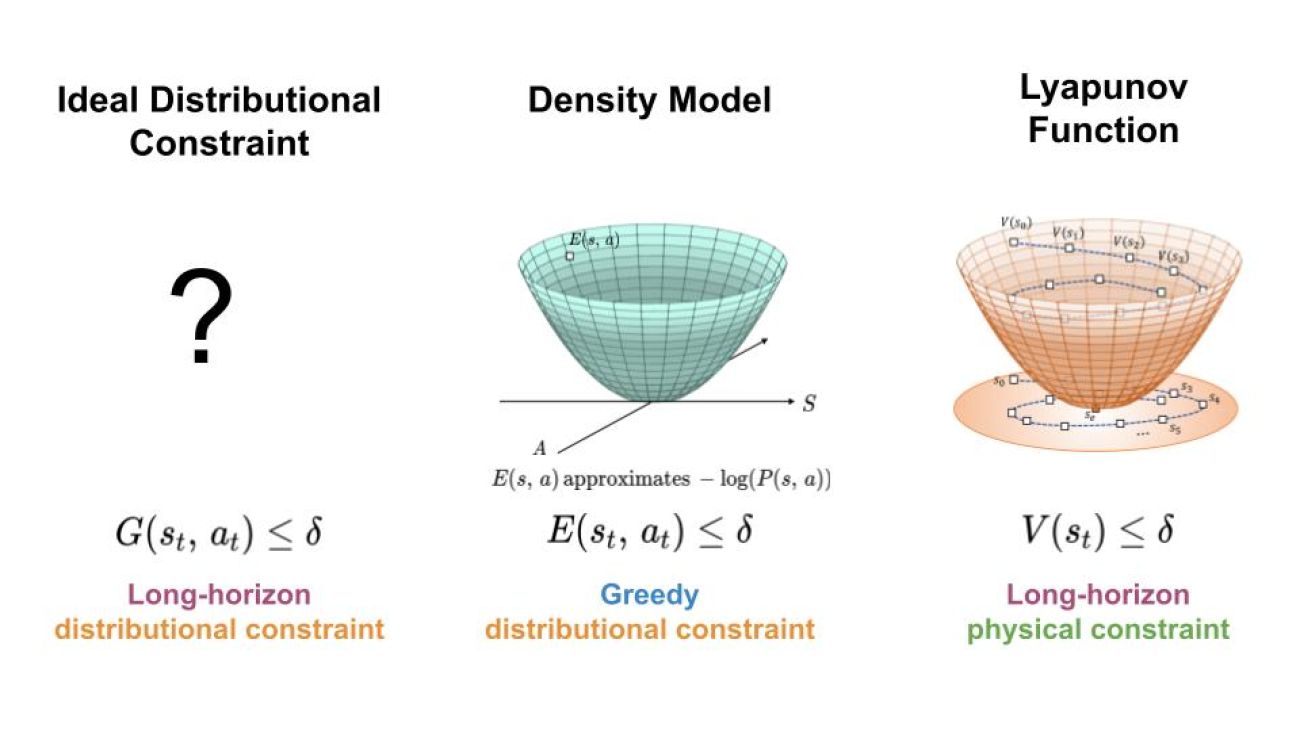
Keeping Learning-Based Control Safe by Regulating Distributional Shift
To regulate the distribution shift experience by learning-based controllers, we seek a mechanism for constraining the agent to regions of high data density throughout its trajectory (left). Here, we present an approach which achieves this goal by combining features of density models (middle) and Lyapunov functions (right).
In order to make use of machine learning and reinforcement learning in controlling real world systems, we must design algorithms which not only achieve good performance, but also interact with the system in a safe and reliable manner. Most prior work on safety-critical control focuses on maintaining the safety of the physical system, e.g. avoiding falling over for legged robots, or colliding into obstacles for autonomous vehicles. However, for learning-based controllers, there is another source of safety concern: because machine learning models are only optimized to output correct predictions on the training data, they are prone to outputting erroneous predictions when evaluated on out-of-distribution inputs. Thus, if an agent visits a state or takes an action that is very different from those in the training data, a learning-enabled controller may “exploit” the inaccuracies in its learned component and output actions that are suboptimal or even dangerous.
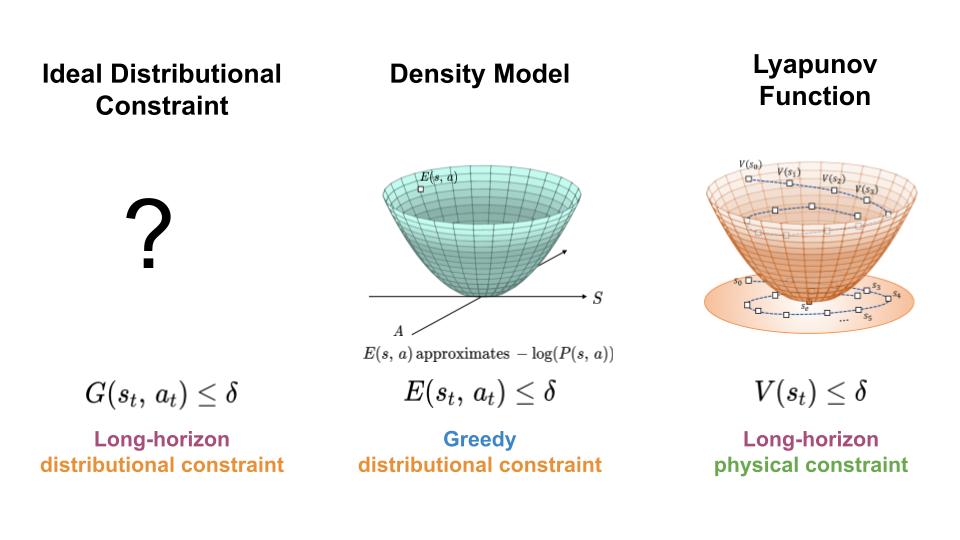
Keeping Learning-Based Control Safe by Regulating Distributional Shift
To regulate the distribution shift experience by learning-based controllers, we seek a mechanism for constraining the agent to regions of high data density throughout its trajectory (left). Here, we present an approach which achieves this goal by combining features of density models (middle) and Lyapunov functions (right).
In order to make use of machine learning and reinforcement learning in controlling real world systems, we must design algorithms which not only achieve good performance, but also interact with the system in a safe and reliable manner. Most prior work on safety-critical control focuses on maintaining the safety of the physical system, e.g. avoiding falling over for legged robots, or colliding into obstacles for autonomous vehicles. However, for learning-based controllers, there is another source of safety concern: because machine learning models are only optimized to output correct predictions on the training data, they are prone to outputting erroneous predictions when evaluated on out-of-distribution inputs. Thus, if an agent visits a state or takes an action that is very different from those in the training data, a learning-enabled controller may “exploit” the inaccuracies in its learned component and output actions that are suboptimal or even dangerous.

Protecting maternal health in Rwanda
The world is facing a maternal health crisis. According to the World Health Organization, approximately 810 women die each day due to preventable causes related to pregnancy and childbirth. Two-thirds of these deaths occur in sub-Saharan Africa. In Rwanda, one of the leading causes of maternal mortality is infected Cesarean section wounds.
An interdisciplinary team of doctors and researchers from MIT, Harvard University, and Partners in Health (PIH) in Rwanda have proposed a solution to address this problem. They have developed a mobile health (mHealth) platform that uses artificial intelligence and real-time computer vision to predict infection in C-section wounds with roughly 90 percent accuracy.
“Early detection of infection is an important issue worldwide, but in low-resource areas such as rural Rwanda, the problem is even more dire due to a lack of trained doctors and the high prevalence of bacterial infections that are resistant to antibiotics,” says Richard Ribon Fletcher ’89, SM ’97, PhD ’02, research scientist in mechanical engineering at MIT and technology lead for the team. “Our idea was to employ mobile phones that could be used by community health workers to visit new mothers in their homes and inspect their wounds to detect infection.”
This summer, the team, which is led by Bethany Hedt-Gauthier, a professor at Harvard Medical School, was awarded the $500,000 first-place prize in the NIH Technology Accelerator Challenge for Maternal Health.
“The lives of women who deliver by Cesarean section in the developing world are compromised by both limited access to quality surgery and postpartum care,” adds Fredrick Kateera, a team member from PIH. “Use of mobile health technologies for early identification, plausible accurate diagnosis of those with surgical site infections within these communities would be a scalable game changer in optimizing women’s health.”
Training algorithms to detect infection
The project’s inception was the result of several chance encounters. In 2017, Fletcher and Hedt-Gauthier bumped into each other on the Washington Metro during an NIH investigator meeting. Hedt-Gauthier, who had been working on research projects in Rwanda for five years at that point, was seeking a solution for the gap in Cesarean care she and her collaborators had encountered in their research. Specifically, she was interested in exploring the use of cell phone cameras as a diagnostic tool.
Fletcher, who leads a group of students in Professor Sanjay Sarma’s AutoID Lab and has spent decades applying phones, machine learning algorithms, and other mobile technologies to global health, was a natural fit for the project.
“Once we realized that these types of image-based algorithms could support home-based care for women after Cesarean delivery, we approached Dr. Fletcher as a collaborator, given his extensive experience in developing mHealth technologies in low- and middle-income settings,” says Hedt-Gauthier.
During that same trip, Hedt-Gauthier serendipitously sat next to Audace Nakeshimana ’20, who was a new MIT student from Rwanda and would later join Fletcher’s team at MIT. With Fletcher’s mentorship, during his senior year, Nakeshimana founded Insightiv, a Rwandan startup that is applying AI algorithms for analysis of clinical images, and was a top grant awardee at the annual MIT IDEAS competition in 2020.
The first step in the project was gathering a database of wound images taken by community health workers in rural Rwanda. They collected over 1,000 images of both infected and non-infected wounds and then trained an algorithm using that data.
A central problem emerged with this first dataset, collected between 2018 and 2019. Many of the photographs were of poor quality.
“The quality of wound images collected by the health workers was highly variable and it required a large amount of manual labor to crop and resample the images. Since these images are used to train the machine learning model, the image quality and variability fundamentally limits the performance of the algorithm,” says Fletcher.
To solve this issue, Fletcher turned to tools he used in previous projects: real-time computer vision and augmented reality.
Improving image quality with real-time image processing
To encourage community health workers to take higher-quality images, Fletcher and the team revised the wound screener mobile app and paired it with a simple paper frame. The frame contained a printed calibration color pattern and another optical pattern that guides the app’s computer vision software.
Health workers are instructed to place the frame over the wound and open the app, which provides real-time feedback on the camera placement. Augmented reality is used by the app to display a green check mark when the phone is in the proper range. Once in range, other parts of the computer vision software will then automatically balance the color, crop the image, and apply transformations to correct for parallax.
“By using real-time computer vision at the time of data collection, we are able to generate beautiful, clean, uniform color-balanced images that can then be used to train our machine learning models, without any need for manual data cleaning or post-processing,” says Fletcher.
Using convolutional neural net (CNN) machine learning models, along with a method called transfer learning, the software has been able to successfully predict infection in C-section wounds with roughly 90 percent accuracy within 10 days of childbirth. Women who are predicted to have an infection through the app are then given a referral to a clinic where they can receive diagnostic bacterial testing and can be prescribed life-saving antibiotics as needed.
The app has been well received by women and community health workers in Rwanda.
“The trust that women have in community health workers, who were a big promoter of the app, meant the mHealth tool was accepted by women in rural areas,” adds Anne Niyigena of PIH.
Using thermal imaging to address algorithmic bias
One of the biggest hurdles to scaling this AI-based technology to a more global audience is algorithmic bias. When trained on a relatively homogenous population, such as that of rural Rwanda, the algorithm performs as expected and can successfully predict infection. But when images of patients of varying skin colors are introduced, the algorithm is less effective.
To tackle this issue, Fletcher used thermal imaging. Simple thermal camera modules, designed to attach to a cell phone, cost approximately $200 and can be used to capture infrared images of wounds. Algorithms can then be trained using the heat patterns of infrared wound images to predict infection. A study published last year showed over a 90 percent prediction accuracy when these thermal images were paired with the app’s CNN algorithm.
While more expensive than simply using the phone’s camera, the thermal image approach could be used to scale the team’s mHealth technology to a more diverse, global population.
“We’re giving the health staff two options: in a homogenous population, like rural Rwanda, they can use their standard phone camera, using the model that has been trained with data from the local population. Otherwise, they can use the more general model which requires the thermal camera attachment,” says Fletcher.
While the current generation of the mobile app uses a cloud-based algorithm to run the infection prediction model, the team is now working on a stand-alone mobile app that does not require internet access, and also looks at all aspects of maternal health, from pregnancy to postpartum.
In addition to developing the library of wound images used in the algorithms, Fletcher is working closely with former student Nakeshimana and his team at Insightiv on the app’s development, and using the Android phones that are locally manufactured in Rwanda. PIH will then conduct user testing and field-based validation in Rwanda.
As the team looks to develop the comprehensive app for maternal health, privacy and data protection are a top priority.
“As we develop and refine these tools, a closer attention must be paid to patients’ data privacy. More data security details should be incorporated so that the tool addresses the gaps it is intended to bridge and maximizes user’s trust, which will eventually favor its adoption at a larger scale,” says Niyigena.
Members of the prize-winning team include: Bethany Hedt-Gauthier from Harvard Medical School; Richard Fletcher from MIT; Robert Riviello from Brigham and Women’s Hospital; Adeline Boatin from Massachusetts General Hospital; Anne Niyigena, Frederick Kateera, Laban Bikorimana, and Vincent Cubaka from PIH in Rwanda; and Audace Nakeshimana ’20, founder of Insightiv.ai.
Protecting maternal health in Rwanda
The world is facing a maternal health crisis. According to the World Health Organization, approximately 810 women die each day due to preventable causes related to pregnancy and childbirth. Two-thirds of these deaths occur in sub-Saharan Africa. In Rwanda, one of the leading causes of maternal mortality is infected Cesarean section wounds.
An interdisciplinary team of doctors and researchers from MIT, Harvard University, and Partners in Health (PIH) in Rwanda have proposed a solution to address this problem. They have developed a mobile health (mHealth) platform that uses artificial intelligence and real-time computer vision to predict infection in C-section wounds with roughly 90 percent accuracy.
“Early detection of infection is an important issue worldwide, but in low-resource areas such as rural Rwanda, the problem is even more dire due to a lack of trained doctors and the high prevalence of bacterial infections that are resistant to antibiotics,” says Richard Ribon Fletcher ’89, SM ’97, PhD ’02, research scientist in mechanical engineering at MIT and technology lead for the team. “Our idea was to employ mobile phones that could be used by community health workers to visit new mothers in their homes and inspect their wounds to detect infection.”
This summer, the team, which is led by Bethany Hedt-Gauthier, a professor at Harvard Medical School, was awarded the $500,000 first-place prize in the NIH Technology Accelerator Challenge for Maternal Health.
“The lives of women who deliver by Cesarean section in the developing world are compromised by both limited access to quality surgery and postpartum care,” adds Fredrick Kateera, a team member from PIH. “Use of mobile health technologies for early identification, plausible accurate diagnosis of those with surgical site infections within these communities would be a scalable game changer in optimizing women’s health.”
Training algorithms to detect infection
The project’s inception was the result of several chance encounters. In 2017, Fletcher and Hedt-Gauthier bumped into each other on the Washington Metro during an NIH investigator meeting. Hedt-Gauthier, who had been working on research projects in Rwanda for five years at that point, was seeking a solution for the gap in Cesarean care she and her collaborators had encountered in their research. Specifically, she was interested in exploring the use of cell phone cameras as a diagnostic tool.
Fletcher, who leads a group of students in Professor Sanjay Sarma’s AutoID Lab and has spent decades applying phones, machine learning algorithms, and other mobile technologies to global health, was a natural fit for the project.
“Once we realized that these types of image-based algorithms could support home-based care for women after Cesarean delivery, we approached Dr. Fletcher as a collaborator, given his extensive experience in developing mHealth technologies in low- and middle-income settings,” says Hedt-Gauthier.
During that same trip, Hedt-Gauthier serendipitously sat next to Audace Nakeshimana ’20, who was a new MIT student from Rwanda and would later join Fletcher’s team at MIT. With Fletcher’s mentorship, during his senior year, Nakeshimana founded Insightiv, a Rwandan startup that is applying AI algorithms for analysis of clinical images, and was a top grant awardee at the annual MIT IDEAS competition in 2020.
The first step in the project was gathering a database of wound images taken by community health workers in rural Rwanda. They collected over 1,000 images of both infected and non-infected wounds and then trained an algorithm using that data.
A central problem emerged with this first dataset, collected between 2018 and 2019. Many of the photographs were of poor quality.
“The quality of wound images collected by the health workers was highly variable and it required a large amount of manual labor to crop and resample the images. Since these images are used to train the machine learning model, the image quality and variability fundamentally limits the performance of the algorithm,” says Fletcher.
To solve this issue, Fletcher turned to tools he used in previous projects: real-time computer vision and augmented reality.
Improving image quality with real-time image processing
To encourage community health workers to take higher-quality images, Fletcher and the team revised the wound screener mobile app and paired it with a simple paper frame. The frame contained a printed calibration color pattern and another optical pattern that guides the app’s computer vision software.
Health workers are instructed to place the frame over the wound and open the app, which provides real-time feedback on the camera placement. Augmented reality is used by the app to display a green check mark when the phone is in the proper range. Once in range, other parts of the computer vision software will then automatically balance the color, crop the image, and apply transformations to correct for parallax.
“By using real-time computer vision at the time of data collection, we are able to generate beautiful, clean, uniform color-balanced images that can then be used to train our machine learning models, without any need for manual data cleaning or post-processing,” says Fletcher.
Using convolutional neural net (CNN) machine learning models, along with a method called transfer learning, the software has been able to successfully predict infection in C-section wounds with roughly 90 percent accuracy within 10 days of childbirth. Women who are predicted to have an infection through the app are then given a referral to a clinic where they can receive diagnostic bacterial testing and can be prescribed life-saving antibiotics as needed.
The app has been well received by women and community health workers in Rwanda.
“The trust that women have in community health workers, who were a big promoter of the app, meant the mHealth tool was accepted by women in rural areas,” adds Anne Niyigena of PIH.
Using thermal imaging to address algorithmic bias
One of the biggest hurdles to scaling this AI-based technology to a more global audience is algorithmic bias. When trained on a relatively homogenous population, such as that of rural Rwanda, the algorithm performs as expected and can successfully predict infection. But when images of patients of varying skin colors are introduced, the algorithm is less effective.
To tackle this issue, Fletcher used thermal imaging. Simple thermal camera modules, designed to attach to a cell phone, cost approximately $200 and can be used to capture infrared images of wounds. Algorithms can then be trained using the heat patterns of infrared wound images to predict infection. A study published last year showed over a 90 percent prediction accuracy when these thermal images were paired with the app’s CNN algorithm.
While more expensive than simply using the phone’s camera, the thermal image approach could be used to scale the team’s mHealth technology to a more diverse, global population.
“We’re giving the health staff two options: in a homogenous population, like rural Rwanda, they can use their standard phone camera, using the model that has been trained with data from the local population. Otherwise, they can use the more general model which requires the thermal camera attachment,” says Fletcher.
While the current generation of the mobile app uses a cloud-based algorithm to run the infection prediction model, the team is now working on a stand-alone mobile app that does not require internet access, and also looks at all aspects of maternal health, from pregnancy to postpartum.
In addition to developing the library of wound images used in the algorithms, Fletcher is working closely with former student Nakeshimana and his team at Insightiv on the app’s development, and using the Android phones that are locally manufactured in Rwanda. PIH will then conduct user testing and field-based validation in Rwanda.
As the team looks to develop the comprehensive app for maternal health, privacy and data protection are a top priority.
“As we develop and refine these tools, a closer attention must be paid to patients’ data privacy. More data security details should be incorporated so that the tool addresses the gaps it is intended to bridge and maximizes user’s trust, which will eventually favor its adoption at a larger scale,” says Niyigena.
Members of the prize-winning team include: Bethany Hedt-Gauthier from Harvard Medical School; Richard Fletcher from MIT; Robert Riviello from Brigham and Women’s Hospital; Adeline Boatin from Massachusetts General Hospital; Anne Niyigena, Frederick Kateera, Laban Bikorimana, and Vincent Cubaka from PIH in Rwanda; and Audace Nakeshimana ’20, founder of Insightiv.ai.
Google at Interspeech 2022
This week, the 23rd Annual Conference of the International Speech Communication Association (INTERSPEECH 2022) is being held in Incheon, South Korea, representing one of the world’s most extensive conferences on research and technology of spoken language understanding and processing. Over 2,000 experts in speech-related research fields gather to take part in oral presentations and poster sessions and to collaborate with streamed events across the globe.
We are excited to be a Diamond Sponsor of INTERSPEECH 2022, where we will be showcasing nearly 50 research publications and supporting a number of workshops, special sessions and tutorials. We welcome in-person attendees to drop by the Google booth to meet our researchers and participate in Q&As and demonstrations of some of our latest speech technologies, which help to improve accessibility and provide convenience in communication for billions of users. In addition, online attendees are encouraged to visit our virtual booth in GatherTown where you can get up-to-date information on research and opportunities at Google. You can also learn more about the Google research being presented at INTERSPEECH 2022 below (Google affiliations in bold).
Organizing Committee
Industry Liaisons include: Bhuvana Ramabahdran
Area Chairs include: John Hershey, Heiga Zen, Shrikanth Narayanan, Bastiaan Kleijn
ISCA Fellows
Include: Tara Sainath, Heiga Zen
Publications
Production Federated Keyword Spotting via Distillation, Filtering, and Joint Federated-Centralized Training
Andrew Hard, Kurt Partridge, Neng Chen, Sean Augenstein, Aishanee Shah, Hyun Jin Park, Alex Park, Sara Ng, Jessica Nguyen, Ignacio Lopez Moreno, Rajiv Mathews, Françoise Beaufays
Leveraging Unsupervised and Weakly-Supervised Data to Improve Direct Speech-to-Speech Translation
Ye Jia, Yifan Ding, Ankur Bapna, Colin Cherry, Yu Zhang, Alexis Conneau, Nobu Morioka
Sentence-Select: Large-Scale Language Model Data Selection for Rare-Word Speech Recognition
W. Ronny Huang, Cal Peyser, Tara N. Sainath, Ruoming Pang, Trevor Strohman, Shankar Kumar
UserLibri: A Dataset for ASR Personalization Using Only Text
Theresa Breiner, Swaroop Ramaswamy, Ehsan Variani, Shefali Garg, Rajiv Mathews, Khe Chai Sim, Kilol Gupta, Mingqing Chen, Lara McConnaughey
SNRi Target Training for Joint Speech Enhancement and Recognition
Yuma Koizumi, Shigeki Karita, Arun Narayanan, Sankaran Panchapagesan, Michiel Bacchiani
Turn-Taking Prediction for Natural Conversational Speech
Shuo-Yiin Chang, Bo Li, Tara Sainath, Chao Zhang, Trevor Strohman, Qiao Liang, Yanzhang He
Streaming Intended Query Detection Using E2E Modeling for Continued Conversation
Shuo-Yiin Chang, Guru Prakash, Zelin Wu, Tara Sainath, Bo Li, Qiao Liang, Adam Stambler, Shyam Upadhyay, Manaal Faruqui, Trevor Strohman
Improving Distortion Robustness of Self-Supervised Speech Processing Tasks with Domain Adaptation
Kuan Po Huang, Yu-Kuan Fu, Yu Zhang, Hung-yi Lee
XLS-R: Self-Supervised Cross-Lingual Speech Representation Learning at Scale
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Ehsan Amid, Om Thakkar, Arun Narayanan, Rajiv Mathews, Françoise Beaufays
Detecting Unintended Memorization in Language-Model-Fused ASR
W. Ronny Huang, Steve Chien, Om Thakkar, Rajiv Mathews
AVATAR: Unconstrained Audiovisual Speech Recognition
Valentin Gabeur, Paul Hongsuck Seo, Arsha Nagrani, Chen Sun, Karteek Alahari, Cordelia Schmid
End-to-End Multi-talker Audio-Visual ASR Using an Active Speaker Attention Module
Richard Rose, Olivier Siohan
Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition for Single and Multi-person Video
Dmitriy Serdyuk, Otavio Braga, Olivier Siohan
Unsupervised Data Selection via Discrete Speech Representation for ASR
Zhiyun Lu, Yongqiang Wang, Yu Zhang, Wei Han, Zhehuai Chen, Parisa Haghani
Non-parallel Voice Conversion for ASR Augmentation
Gary Wang, Andrew Rosenberg, Bhuvana Ramabhadran, Fadi Biadsy, Jesse Emond, Yinghui Huang, Pedro J. Moreno
Ultra-Low-Bitrate Speech Coding with Pre-trained Transformers
Ali Siahkoohi, Michael Chinen, Tom Denton, W. Bastiaan Kleijn, Jan Skoglund
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Chao Zhang, Bo Li, Tara Sainath, Trevor Strohman, Sepand Mavandadi, Shuo-Yiin Chang, Parisa Haghani
Improving Deliberation by Text-Only and Semi-supervised Training
Ke Hu, Tara N. Sainath, Yanzhang He, Rohit Prabhavalkar, Trevor Strohman, Sepand Mavandadi, Weiran Wang
E2E Segmenter: Joint Segmenting and Decoding for Long-Form ASR
W. Ronny Huang, Shuo-yiin Chang, David Rybach, Rohit Prabhavalkar, Tara N. Sainath, Cyril Allauzen, Cal Peyser, Zhiyun Lu
CycleGAN-Based Unpaired Speech Dereverberation
Alexis Conneau, Ankur Bapna, Yu Zhang, Min Ma, Patrick von Platen, Anton Lozhkov, Colin Cherry, Ye Jia, Clara Rivera, Mihir Kale, Daan van Esch, Vera Axelrod, Simran Khanuja, Jonathan Clark, Orhan Firat, Michael Auli, Sebastian Ruder, Jason Riesa, Melvin Johnson
TRILLsson: Distilled Universal Paralinguistic Speech Representations (see blog post)
Joel Shor, Subhashini Venugopalan
Learning Neural Audio Features Without Supervision
Sarthak Yadav, Neil Zeghidour
SpeechPainter: Text-Conditioned Speech Inpainting
Zalan Borsos, Matthew Sharifi, Marco Tagliasacchi
SpecGrad: Diffusion Probabilistic Model-Based Neural Vocoder with Adaptive Noise Spectral Shaping
Yuma Koizumi, Heiga Zen, Kohei Yatabe, Nanxin Chen, Michiel Bacchiani
Distance-Based Sound Separation
Katharine Patterson, Kevin Wilson, Scott Wisdom, John R. Hershey
Analysis of Self-Attention Head Diversity for Conformer-Based Automatic Speech Recognition
Kartik Audhkhasi, Yinghui Huang, Bhuvana Ramabhadran, Pedro J. Moreno
Improving Rare Word Recognition with LM-Aware MWER Training
Wang Weiran, Tongzhou Chen, Tara Sainath, Ehsan Variani, Rohit Prabhavalkar, W. Ronny Huang, Bhuvana Ramabhadran, Neeraj Gaur, Sepand Mavandadi, Cal Peyser, Trevor Strohman, Yanzhang He, David Rybach
MAESTRO: Matched Speech Text Representations Through Modality Matching
Zhehuai Chen, Yu Zhang, Andrew Rosenberg, Bhuvana Ramabhadran, Pedro J. Moreno, Ankur Bapna, Heiga Zen
Pseudo Label is Better Than Human Label
Dongseong Hwang, Khe Chai Sim, Zhouyuan Huo, Trevor Strohman
On the Optimal Interpolation Weights for Hybrid Autoregressive Transducer Model
Ehsan Variani, Michael Riley, David Rybach, Cyril Allauzen, Tongzhou Chen, Bhuvana Ramabhadran
Streaming Align-Refine for Non-autoregressive Deliberation
Wang Weiran, Ke Hu, Tara Sainath
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Rongmei Lin*, Yonghui Xiao, Tien-Ju Yang, Ding Zhao, Li Xiong, Giovanni Motta, Françoise Beaufays
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Shaojin Ding, Weiran Wang, Ding Zhao, Tara N Sainath, Yanzhang He, Robert David, Rami Botros, Xin Wang, Rina Panigrahy, Qiao Liang, Dongseong Hwang, Ian McGraw, Rohit Prabhavalkar, Trevor Strohman
4-Bit Conformer with Native Quantization Aware Training for Speech Recognition
Shaojin Ding, Phoenix Meadowlark, Yanzhang He, Lukasz Lew, Shivani Agrawal, Oleg Rybakov
Visually-Aware Acoustic Event Detection Using Heterogeneous Graphs
Amir Shirian, Krishna Somandepalli, Victor Sanchez, Tanaya Guha
A Conformer-Based Waveform-Domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
Sankaran Panchapagesan, Arun Narayanan, Turaj Zakizadeh Shabestary, Shuai Shao, Nathan Howard, Alex Park, James Walker, Alexander Gruenstein
Reducing Domain Mismatch in Self-Supervised Speech Pre-training
Murali Karthick Baskar, Andrew Rosenberg, Bhuvana Ramabhadran, Yu Zhang, Nicolás Serrano
On-the-Fly ASR Corrections with Audio Exemplars
Golan Pundak, Tsendsuren Munkhdalai, Khe Chai Sim
A Language Agnostic Multilingual Streaming On-Device ASR System
Bo Li, Tara Sainath, Ruoming Pang*, Shuo-Yiin Chang, Qiumin Xu, Trevor Strohman, Vince Chen, Qiao Liang, Heguang Liu, Yanzhang He, Parisa Haghani, Sameer Bidichandani
XTREME-S: Evaluating Cross-Lingual Speech Representations
Alexis Conneau, Ankur Bapna, Yu Zhang, Min Ma, Patrick von Platen, Anton Lozhkov, Colin Cherry, Ye Jia, Clara Rivera, Mihir Kale, Daan van Esch, Vera Axelrod, Simran Khanuja, Jonathan Clark, Orhan Firat, Michael Auli, Sebastian Ruder, Jason Riesa, Melvin Johnson
Towards Disentangled Speech Representations
Cal Peyser, Ronny Huang, Andrew Rosenberg, Tara Sainath, Michael Picheny, Kyunghyun Cho
Personal VAD 2.0: Optimizing Personal Voice Activity Detection for On-Device Speech Recognition
Shaojin Ding, Rajeev Rikhye, Qiao Liang, Yanzhang He, Quan Wang, Arun Narayanan, Tom O’Malley, Ian McGraw
A Universally-Deployable ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement, and Voice Separation
Tom O’Malley, Arun Narayanan, Quan Wang
Training Text-To-Speech Systems From Synthetic Data: A Practical Approach For Accent Transfer Tasks
Lev Finkelstein, Heiga Zen, Norman Casagrande, Chun-an Chan, Ye Jia, Tom Kenter, Alex Petelin, Jonathan Shen*, Vincent Wan, Yu Zhang, Yonghui Wu, Robert Clark
A Scalable Model Specialization Framework for Training and Inference Using Submodels and Its Application to Speech Model Personalization
Fadi Biadsy, Youzheng Chen, Xia Zhang, Oleg Rybakov, Andrew Rosenberg, Pedro Moreno
Text-Driven Separation of Arbitrary Sounds
Kevin Kilgour, Beat Gfeller, Qingqing Huang, Aren Jansen, Scott Wisdom, Marco Tagliasacchi
Workshops, Tutorials & Special Sessions
The VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22)
Organizers include: Arsha Nagrani
Self-Supervised Representation Learning for Speech Processing
Organizers include: Tara Sainath
Learning from Weak Labels
Organizers include: Ankit Shah
RNN Transducers for Named Entity Recognition with Constraints on Alignment for Understanding Medical Conversations
Authors: Hagen Soltau, Izhak Shafran, Mingqiu Wang, Laurent El Shafey
Listening with Googlears: Low-Latency Neural Multiframe Beamforming and Equalization for Hearing Aids
Authors: Samuel Yang, Scott Wisdom, Chet Gnegy, Richard F. Lyon, Sagar Savla
Using Rater and System Metadata to Explain Variance in the VoiceMOS Challenge 2022 Dataset
Authors: Michael Chinen, Jan Skoglund, Chandan K. A. Reddy, Alessandro Ragano, Andrew Hines
Incremental Layer-Wise Self-Supervised Learning for Efficient Unsupervised Speech Domain Adaptation On Device
Authors: Zhouyuan Huo, Dongseong Hwang, Khe Chai Sim, Shefali Garg, Ananya Misra, Nikhil Siddhartha, Trevor Strohman, Françoise Beaufays
Trustworthy Speech Processing
Organizers include: Shrikanth Narayanan
*Work done while at Google. ↩Read More
Robust Online Allocation with Dual Mirror Descent
The emergence of digital technologies has transformed decision making across commercial sectors such as airlines, online retailing, and internet advertising. Today, real-time decisions need to be repeatedly made in highly uncertain and rapidly changing environments. Moreover, organizations usually have limited resources, which need to be efficiently allocated across decisions. Such problems are referred to as online allocation problems with resource constraints, and applications abound. Some examples include:
- Bidding with Budget Constraints: Advertisers increasingly purchase ad slots using auction-based marketplaces such as search engines and ad exchanges. A typical advertiser can participate in a large number of auctions in a given month. Because the supply in these marketplaces is uncertain, advertisers set budgets to control their total spend. Therefore, advertisers need to determine how to optimally place bids while limiting total spend and maximizing conversions.
- Dynamic Ad Allocation: Publishers can monetize their websites by signing deals with advertisers guaranteeing a number of impressions or by auctioning off slots in the open market. To make this choice, publishers need to trade off, in real-time, the short-term revenue from selling slots in the open market and the long-term benefits of delivering good quality spots to reservation ads.
- Airline Revenue Management: Planes have a limited number of seats that need to be filled up as much as possible before a flight’s departure. But demand for flights changes over time and airlines would like to sell airline tickets to the customers who are willing to pay the most. Thus, airlines have increasingly adopted sophisticated automated systems to manage the pricing and availability of airline tickets.
- Personalized Retailing with Limited Inventories: Online retailers can use real-time data to personalize their offerings to customers who visit their store. Because product inventory is limited and cannot be easily replenished, retailers need to dynamically decide which products to offer and at what price to maximize their revenue while satisfying their inventory constraints.
The common feature of these problems is the presence of resource constraints (budgets, contractual obligations, seats, or inventory, respectively in the examples above) and the need to make dynamic decisions in environments with uncertainty. Resource constraints are challenging because they link decisions across time — e.g., in the bidding problem, bidding too high early can leave advertisers with no budget, and thus missed opportunities later. Conversely, bidding too conservatively can result in a low number of conversions or clicks.
 |
| Two central resource allocation problems faced by advertisers and publishers in internet advertising markets. |
In this post, we discuss state-of-the-art algorithms that can help maximize goals in dynamic, resource-constrained environments. In particular, we have recently developed a new class of algorithms for online allocation problems, called dual mirror descent, that are simple, robust, and flexible. Our papers have appeared in Operations Research, ICML’20, and ICML’21, and we have ongoing work to continue progress in this space. Compared to existing approaches, dual mirror descent is faster as it does not require solving auxiliary optimization problems, is more flexible because it can handle many applications across different sectors with minimal modifications, and is more robust as it enjoys remarkable performance under different environments.
Online Allocation Problems
In an online allocation problem, a decision maker has a limited amount of total resources (B) and receives a certain number of requests over time (T). At any point in time (t), the decision maker receives a reward function (ft) and resource consumption function (bt), and takes an action (xt). The reward and resource consumption functions change over time and the objective is to maximize the total reward within the resource constraints. If all the requests were known in advance, then an optimal allocation could be obtained by solving an offline optimization problem for how to maximize the reward function over time within the resource constraints1.
The optimal offline allocation cannot be implemented in practice because it requires knowing future requests. However, this is still useful for framing the goal of online allocation problems: to design an algorithm whose performance is as close to optimal as possible without knowing future requests.
Achieving the Best of Many Worlds with Dual Mirror Descent
A simple, yet powerful idea to handle resource constraints is introducing “prices” for the resources, which enables accounting for the opportunity cost of consuming resources when making decisions. For example, selling a seat on a plane today means it can’t be sold tomorrow. These prices are useful as an internal accounting system of the algorithm. They serve the purpose of coordinating decisions at different moments in time and allow decomposing a complex problem with resource constraints into simpler subproblems: one per time period with no resource constraints. For example, in a bidding problem, the prices capture an advertiser’s opportunity cost of consuming one unit of budget and allow the advertiser to handle each auction as an independent bidding problem.
This reframes the online allocation problem as a problem of pricing resources to enable optimal decision making. The key innovation of our algorithm is using machine learning to predict optimal prices in an online fashion: we choose prices dynamically using mirror descent, a popular optimization algorithm for training machine learning predictive models. Because prices for resources are referred to as “dual variables” in the field of optimization, we call the resulting algorithm dual mirror descent.
The algorithm works sequentially by assuming uniform resource consumption over time is optimal and updating the dual variables after each action. It starts at a moment in time (t) by taking an action (xt) that maximizes the reward minus the opportunity cost of consuming resources (shown in the top gray box below). The action (e.g., how much to bid or which ad to show) is implemented if there are enough resources available. Then, the algorithm computes the error in the resource consumption (gt), which is the difference between uniform consumption over time and the actual resource consumption (below in the third gray box). A new dual variable for the next time period is computed using mirror descent based on the error, which then informs the next action. Mirror descent seeks to make the error as close as possible to zero, improving the accuracy of its estimate of the dual variable, so that resources are consumed uniformly over time. While the assumption of uniform resource consumption may be surprising, it helps avoid missing good opportunities and often aligns with commercial goals so is effective. Mirror descent also allows a variety of update rules; more details are in the paper.
 |
| An overview of the dual mirror descent algorithm. |
By design, dual mirror descent has a self-correcting feature that prevents depleting resources too early or waiting too long to consume resources and missing good opportunities. When a request consumes more or less resources than the target, the corresponding dual variable is increased or decreased. When resources are then priced higher or lower, future actions are chosen to consume resources more conservatively or aggressively.
This algorithm is easy to implement, fast, and enjoys remarkable performance under different environments. These are some salient features of our algorithm:
- Existing methods require periodically solving large auxiliary optimization problems using past data. In contrast, this algorithm does not need to solve any auxiliary optimization problem and has a very simple rule to update the dual variables, which, in many cases, can be run in linear time complexity. Thus, it is appealing for many real-time applications that require fast decisions.
- There are minimal requirements on the structure of the problem. Such flexibility allows dual mirror descent to handle many applications across different sectors with minimal modifications. Moreover, our algorithms are flexible since they accommodate different objectives, constraints, or regularizers. By incorporating regularizers, decision makers can include important objectives beyond economic efficiency, such as fairness.
- Existing algorithms for online allocation problems are tailored for either adversarial or stochastic input data. Algorithms for adversarial inputs are robust as they make almost no assumptions on the structure of the data but, in turn, obtain performance guarantees that are too pessimistic in practice. On the other hand, algorithms for stochastic inputs enjoy better performance guarantees by exploiting statistical patterns in the data but can perform poorly when the model is misspecified. Dual mirror descent, however, attains performance close to optimal in both stochastic and adversarial input models while being oblivious to the structure of the input model. Compared to existing work on simultaneous approximation algorithms, our method is more general, applies to a wide range of problems, and requires no forecasts. Below is a comparison of our algorithm to other state-of-the-art methods. Results are based on synthetic data for an ad allocation problem.
 |
| Performance of dual mirror descent, a training based method, and an adversarial method relative to the optimal offline solution. Lower values indicate performance closer to the optimal offline allocation. Results are generated using synthetic experiments based on public data for an ad allocation problem. |
Conclusion
In this post we introduced dual mirror descent, an algorithm for online allocation problems that is simple, robust, and flexible. It is particularly notable that after a long line of work in online allocation algorithms, dual mirror descent provides a way to analyze a wider range of algorithms with superior robustness priorities compared to previous techniques. Dual mirror descent has a wide range of applications across several commercial sectors and has been used over time at Google to help advertisers capture more value through better algorithmic decision making. We are also exploring further work related to mirror descent and its connections to PI controllers.
Acknowledgements
We would like to thank our co-authors Haihao Lu and Balu Sivan, and Kshipra Bhawalkar for their exceptional support and contributions. We would also like to thank our collaborators in the ad quality team and market algorithm research.
1Formalized in the equation below: ↩
 |