In this post, we present a solution that combines rich mobile device intelligence with customized machine learning (ML) modeling to help you catch fraudsters who exploit mobile apps.
GrabDefence (GD), Grab’s proprietary fraud detection and prevention technology, and AWS have launched GDxAFD, a fraud detection solution tailored for mobile apps that integrates GD’s device intelligence capabilities with Amazon Fraud Detector, AWS’s fully managed ML fraud detection solution. With GDxAFD, you can take advantage of more than 20 years of fraud detection expertise from Amazon as well as extensive mobile fraud experience from Southeast Asia’s leading superapp to safeguard your mobile application from fraudsters.
This solution rides on a larger global wave of anti-fraud efforts, which experts forecast to grow to USD $62.70 billion by 2028. With the rise of the digital economy, fraud syndicates increasingly target online businesses, causing financial loss and destroying the trust between end-users and the platform. The true cost to battle fraud is also increasing rapidly as more fraud checks leads to poorer customer experience, false positives, as well as operational burden, which as a whole is estimated to be three times larger than the actual fraud losses from the True Cost of FraudTM APAC Study by LexisNexis® Risk Solutions.
From the combined industry experience, the solution team believes that many of the modus operandi in a mobile environment is driven by fraudsters having tools and methods to create fake accounts at scale and bypass a platform’s security checks on the device, thereby enabling them to exploit the platform for large returns. Therefore, preventing mobile fraud starts from clearly understanding the risk profile of the devices used to access the mobile app and then using the device risk intelligence gathered, together with additional data about the user, event, or account, to detect potential fraudulent behavior in real time and at scale. By combining rich device intelligence and ML, companies are better positioned to stay ahead of mobile-focused fraud syndicates, and reduce fraud on their platforms.
GD device intelligence
GD is a product from Grab’s fraud prevention team, which has years of experience building solutions for Grab. Grab is a NASDAQ listed company and a leading superapp in South East Asia, with over 30 million monthly transacting users (as per Grab’s Q1 2022 Results). Due to the scale of its operations as a leading superapp in SEA and the nature of a mobile-first business, Grab has been investing heavily in building fraud prevention solutions enabled by rich data, technology focus, and insights gathered from its operational experience and exposure. GD’s device intelligence service collects rich device-level data, excluding any personally identifiable information (PII), from mobile application users and securely analyzes it to understand the risk profile of the device. Learning from a large device network built via Grab’s superapp, GD’s device intelligence service can accurately generate device fingerprints and detect risky attributes such as device or app modification or tampering, emulator usage, and GPS spoofing. As mentioned earlier, many fraud modus operandi on mobile platforms involve mass creation of fake accounts, device reengineering, and location spoofing, which GD device intelligence is capable of detecting. As a result, by integrating GD device intelligence and Amazon Fraud Detector, platforms that face similar fraud attacks can expect up to a 23% increase in fraud detection based on statistical studies done by GrabDefence on Grab’s fraud prevention systems.
Custom fraud detection ML models in Amazon Fraud Detector
Amazon Fraud Detector customizes each model it creates to your own dataset, making the accuracy of models higher than one-size-fits-all ML solutions. During the fully automated model training process, a series of models that have learned patterns of fraud from AWS and Amazon’s own fraud expertise are used to boost your model performance even further.
With the GDxAFD solution, you now have step-by-step guidance and a reference architecture for how to use flexible event schemas in Amazon Fraud Detector to add GD device intelligence findings into your custom fraud detector models. The end result is an ML model that, once trained, has the benefit of learning from multiple data sources, including your own historical data, GD’s device intelligence data, fraud patterns seen across Amazon, and additional third-party data (added automatically by Amazon Fraud Detector). Based on our pilot between GD and Amazon Fraud Detector, our model using GD device intelligence has shown a 23% increase in detection performance for detecting fake account registrations. You can deploy these models to detect mobile fraud to prevent not only fake account registration but also fraudulent payments, promotion abuse, or loyalty program abuse, among others.
To get started, you first integrate GD’s mobile SDK into your mobile application to collect device-level data. Next, you use Amazon Fraud Detector to define the event you want to evaluate for fraud by specifying the event and account data points you have available for the event or account, including the device risk intelligence data points from GD. After this, you train your ML model in Amazon Fraud Detector in just a few steps. After you train the model, you can add it to a detector.
To begin performing real-time predictions, you integrate Amazon Fraud Detector’s low-latency prediction API into your application and begin sending new mobile events to generate fraud predictions. Each fraud prediction considers the GD device intelligence data for the device associated with the event as well as additional data and intelligence automatically added by Amazon Fraud Detector, including signals from fraud patterns experienced across Amazon.
Solution overview
Device intelligence is a critical type of input for risk decisions. One of the common challenges faced in fraud detection in the mobile space is the lack of enriched data availability to make risk decisions. On the other hand, mobile devices are typically the most expensive asset the fraudsters and fraud syndicates possess and, therefore, a significant level of effort is put into masking the true identity and profile of the device being used. Understanding the risk profile of the mobile device (which sometimes isn’t even a real device) and being able to drive insights from the relationship between different mobile devices can significantly improve risk decisions for any mobile business, and becomes central to any mobile-based fraud management strategy.
For generating real-time fraud predictions, the GDxAFD solution uses Amazon Fraud Detector and GrabDefence’s device intelligence SDK, along with Amazon API Gateway and AWS Lambda. You can provision the AWS portions of the solution using AWS CloudFormation.
The following diagram illustrates our solution architecture.
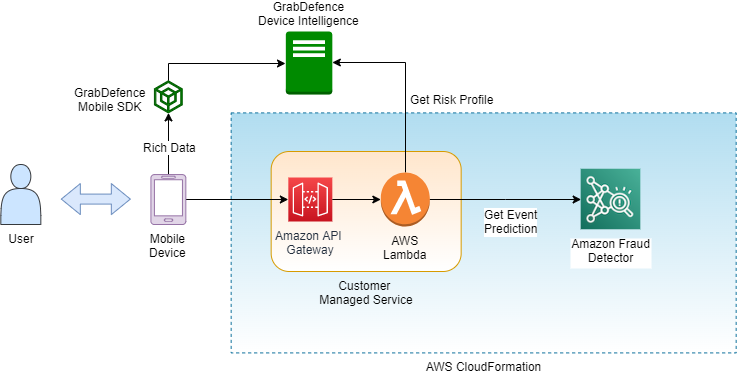
The workflow consists of the following steps:
- When an end-user interacts with your mobile app, GD’s mobile SDK passively gathers device data and streams this data to GD’s device intelligence service, where a risk profile for the device is generated.
- Then, when that user transacts using the mobile app and you want to assess fraud risk in real time, the mobile app sends the transaction data gathered by the app via API Gateway to a Lambda function.
- The Lambda function gathers the GrabDefence risk profile for the device used during the transaction, combines that profile data with the other transaction data, and sends it to the fraud detector.
- The fraud detector performs a fraud prediction using your custom fraud detection ML model and ruleset, and returns a risk score and outcome to the Lambda function. This result is sent back to your mobile app via API Gateway.
- If desired, the mobile app can then choose to adjust the end-user experience accordingly based on this risk assessment.
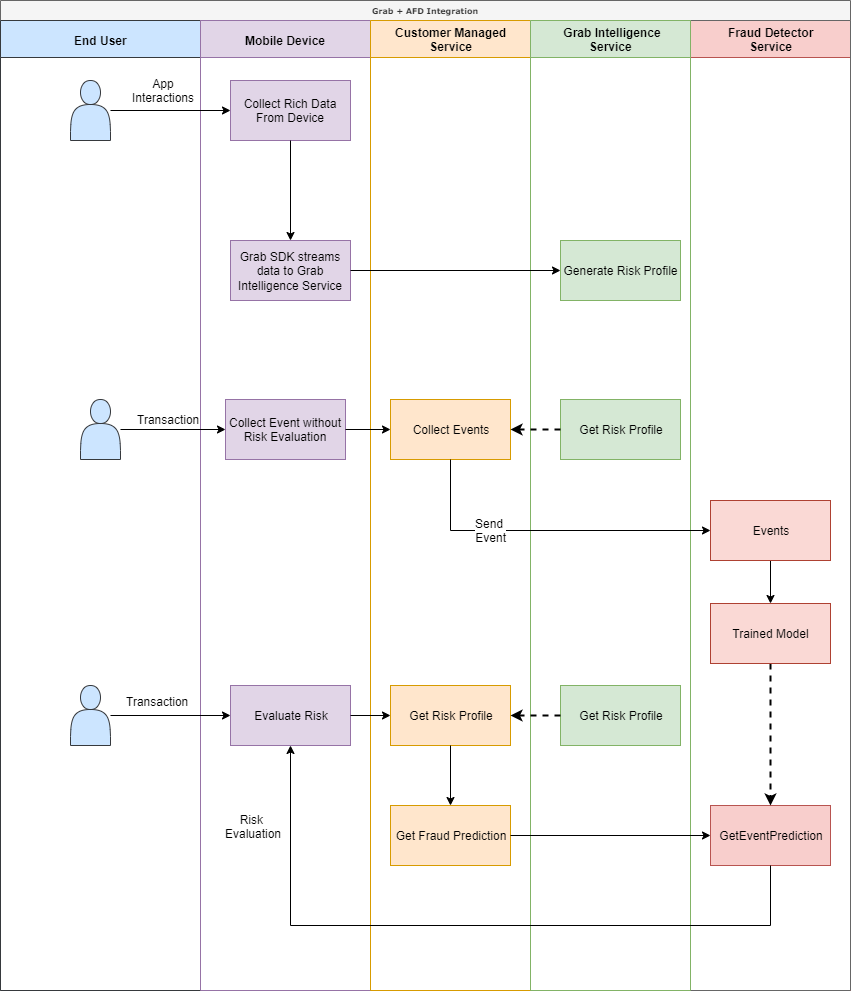
Use cases for device intelligence with Amazon Fraud Detector
The ideal end-state solution is an Amazon Fraud Detector model that is trained on a dataset of your historical events and their associated historical GD device intelligence data. To achieve this, you need to integrate the GD Guardian SDK for mobile devices and then gather device intelligence data for your events until you have enough to train a model (for example,10,000 events with at least 400 examples of fraud events). Depending on your use case and availability of fraud labels, you have a couple of ways to get started sooner as you gather data for this solution:
- Use case A: Use GD device intelligence data directly in the fraud detector rules – With this use case, you create a detector in Amazon Fraud Detector with a ruleset designed to flag high-risk events provided by the device intelligence. This works effectively when you have clear risk mitigation policies that you want to deploy for your platform. (for example, act on the user if the device is jailbroken, or don’t allow redemption of a promo if the device has more than five accounts) In such cases, you can set up your detector rules to flag events based on a combination of GD device risk score and GD device verdicts. This option requires no historical event data or labels to get started, so it can be ready to use sooner than the ML-based detection options.
- Use case B: Use GD device intelligence and an Amazon Fraud Detector ML model with the fraud detector rules – If you have a historical event dataset and are able to train an Amazon Fraud Detector ML model immediately, you can build on use case A by adding an Amazon Fraud Detector model to your rules-based detector. This way, your detector logic is evaluating device intelligence with rules and all other event data with a customized ML model. This allows you to solve for more complex fraud tactics where statistical methods are required to separate fraud from non-fraud.
Best results are often achieved when both of these scenarios work in tandem, because they can serve different use cases over time even after you have more historical data. With these methods, Amazon Fraud Detector makes it easy to transition to the ideal solution in a few steps.
In the following sections, we walk through the steps to get started using Amazon Fraud Detector with GD device intelligence data.
Integrate the GD mobile SDK and start collecting device intelligence data
Prior to using GrabDefence device intelligence within your application, you must first register as a GrabDefence client. You receive the following credentials from the GrabDefence team:
- tenant_id – A unique client identifier that represents your organization
- app_id – A unique application identifier that represents the application you’re integrating
Refer to the GrabDefence documentation for further guidance on how to integrate this SDK.
Create your event type in Amazon Fraud Detector
An event type defines the schema for the event you want to assess for fraud. When creating an event type in Amazon Fraud Detector, you define all the data elements you will have available at the time of the fraud evaluation, including the GD device intelligence risk profile data elements such as the unique device ID and various device verdicts, to Amazon Fraud Detector variables. You need to include event variables (such as IP, email, or billing address) that are unique to the type of event you’re evaluating for fraud, as well as GD device intelligence data. The following table shows examples of event variables, the GD device intelligence data, and the recommended Amazon Fraud Detector variable type to map each element to.
| Event Variable Type | Event Variable (Not Exhaustive) | Amazon Fraud Detector Event Variable | Example |
| Event Metadata | EVENT_TIMESTAMP | EVENT_TIMESTAMP | 2019-11-30T13:01:01Z |
| EVENT_ID | EVENT_ID | test0299df10-e2db-11eb-96e2-f7dgje3d3k03 | |
| ENTITY_ID | ENTITY_ID | 123 | |
| EVENT_LABEL | EVENT_LABEL | FRAUD or LEGIT | |
| LABEL_TIMESTAMP | LABEL_TIMESTAMP | 2019-11-30T13:01:01Z | |
| Event Variables | EMAIL_ADDRESS | test@example.com | |
| IP | IP_ADDRESS | 192.0.2.1 | |
| Phone | PHONE_NUMBER | 555-0123 | |
| GD Device Intelligence Verdicts | Verdict: IOS Jailbroken Device | CUSTOM: CATEGORICAL | GV_IOS_JAIL_BROKEN |
| Verdict: Debugger Detected | CUSTOM: CATEGORICAL | GV_DEBUGGER_DETECTED | |
| Verdict: Event Token Signature Mismatch | CUSTOM: CATEGORICAL | GV_EVENT_TOKEN_SIGNATURE_MISMATCH | |
| Verdict: Server Challenge Mismatch | CUSTOM: CATEGORICAL | GV_SERVER_CHALLENGE_MISMATCH | |
| GD Risk Scores | User account risk score | CUSTOM: NUMERICAL | 0.9 etc |
Build your detection logic in Amazon Fraud Detector
At this point, you need to decide whether you want to start with use case A or use case B. For use case A, you start building a rules-based detector. For use case B, you build an Amazon Fraud Detector model first and, once finished, add the model to your detector.
For instructions on building an Amazon Fraud Detector model and detector, refer to the Amazon Fraud Detector user guide.
The following screenshot shows sample detector rules on the Amazon Fraud Detector console.

Test your detector using Amazon Fraud Detector batch predictions
You can use a batch predictions job to test your detector against a set of events using either the Amazon Fraud Detector console or the CreateBatchPredictionJob API. You need to specify the detector version (created in the previous step) and provide the events via a CSV file (up to 50 MB large) stored in an Amazon Simple Storage Service (Amazon S3) bucket. The output file containing the original input data along with appended results of the detector’s predictions will be available in the same S3 bucket (unless you specify a different location).
For more information on running an Amazon Fraud Detector batch prediction, refer to Amazon Fraud Detector batch predictions documentation page.
Set up the supporting infrastructure
To perform real-time predictions using the detector you built, you must set up a Lambda function that performs the following actions:
- Receives transaction data (via API Gateway) gathered from your mobile app. This includes data such as IP address, email address, shipping and billing info, and so on, that is unique to the transaction and use case.
- Collects the risk profile from the GD API. This includes device intelligence data and risk signals from GD. You need to convert the GD verdicts to the appropriate Amazon Fraud Detector variable
CUSTOM: CATEGORICALtypes. For example, if the GD verdict list containsGV_IOS_JAIL_BROKEN, you need to set theVerdict: IOS Jailbroken Devicevariable toTRUEwhen sending to Amazon Fraud Detector (as detailed in the next section). - Sends the data to the detector using the
GetEventPredictionAPI (see the next section).
Perform real-time predictions using the Amazon Fraud Detector GetEventPrediction API
Your Lambda function can call the Amazon Fraud Detector GetEventPrediction API to perform real-time predictions and obtain results synchronously. The GetEventPrediction API returns matched outcomes based on the rules you set up earlier. If you attached a model to your detector in Amazon Fraud Detector, the model score is also returned as part of the GetEventPrediction API response. You can find examples of GetEventPrediction requests on the aws-fraud-detector-samples GitHub repository.
You can configure your Lambda function accordingly to parse the response from this API, and return the appropriate action to the mobile application (via API Gateway).
Build and train your model
After you integrate the GD SDK and are generating predictions with Amazon Fraud Detector, your events are stored in Amazon Fraud Detector and you can use the UpdateEventLabel API to add fraud labels for confirmed fraud events. When your stored dataset has 10,000 events with device data and at least 400 labelled as fraud, you can start building a custom Amazon Fraud Detector model that learns from GD’s device intelligence data.
At this point, you’re ready to train the model. This takes a few steps on the Amazon Fraud Detector console, and model training typically takes around an hour but can be longer depending on the size of your training dataset.
- On the Amazon Fraud Detector console, choose Create model.
- Choose Transaction Fraud Insights as the model type.
- Choose the event type you created earlier.
- Choose the date range for your training dataset that encompasses the period where you’ve collected GD device intelligence data.
- Add all the event type variables, including the GD device-specific elements, to your model’s input configuration.
- Strat training the model.
After your model is trained, you can review performance metrics and then deploy it by changing its status to Active. To learn more about model scores and performance metrics, see Model scores and Training performance metrics. At this point, you can now add your model to your detector, add threshold rules to interpret the risk scores that the model outputs, and continue making predictions using the GetEventPrediction API.
Automate the solution
You can use AWS CloudFormation to automate the creation of your Amazon Fraud Detector event type and related resources. For more details, refer to managing resources using AWS CloudFormation.
Conclusion
Congrats! You have successfully built an Amazon Fraud Detector model that integrates GD device intelligence into your detector. The Amazon Fraud Detector ML model you trained has learned from multiple data sources, including your own historical data, GD’s device intelligence data, fraud patterns seen across Amazon, and additional third-party data (added automatically by Amazon Fraud Detector). You can deploy this solution on your mobile apps to detect and capture various types of mobile fraud.
Special thanks to everyone who contributed to this blog including, Abhishek Ravi, Tanay Bhargava, Eric Burris, Puneet Gambhir (GrabDefence), Brian Kim (GrabDefence), and Sing Kwan Ng (GrabDefence).
About the author
 Marcel Pividal is a Sr. AI Services Solutions Architect in the World-Wide Specialist Organization. Marcel has more than 20 years of experience solving business problems through technology for Fintechs, Payment Providers, Pharma, and government agencies. His current areas of focus are Risk Management, Fraud Prevention, and Identity Verification.
Marcel Pividal is a Sr. AI Services Solutions Architect in the World-Wide Specialist Organization. Marcel has more than 20 years of experience solving business problems through technology for Fintechs, Payment Providers, Pharma, and government agencies. His current areas of focus are Risk Management, Fraud Prevention, and Identity Verification.
 Adriaan de Jonge is Partner Solutions Architect at AWS in Singapore. He is part of the AWS GSI team in the ASEAN geography. Adriaan is particularly interested in serverless, cloud-native development, and DevOps. In his spare time, he likes to bake cakes that are suitable for people with allergies.
Adriaan de Jonge is Partner Solutions Architect at AWS in Singapore. He is part of the AWS GSI team in the ASEAN geography. Adriaan is particularly interested in serverless, cloud-native development, and DevOps. In his spare time, he likes to bake cakes that are suitable for people with allergies.
 Jianbo Liu is a Research Scientist with Amazon Fraud Detector.
Jianbo Liu is a Research Scientist with Amazon Fraud Detector.