Amazon SageMaker Data Wrangler helps you understand, aggregate, transform, and prepare data for machine learning (ML) from a single visual interface. It contains over 300 built-in data transformations so you can quickly normalize, transform, and combine features without having to write any code.
Data science practitioners generate, observe, and process data to solve business problems where they need to transform and extract features from datasets. Transforms such as ordinal encoding or one-hot encoding learn encodings on your dataset. These encoded outputs are referred as trained parameters. As datasets change over time, it may be necessary to refit encodings on previously unseen data to keep the transformation flow relevant to your data.
We are excited to announce the refit trained parameter feature, which allows you to use previous trained parameters and refit them as desired. In this post, we demonstrate how to use this feature.
Overview of the Data Wrangler refit feature
We illustrate how this feature works with the following example, before we dive into the specifics of the refit trained parameter feature.
Assume your customer dataset has a categorical feature for country represented as strings like Australia and Singapore. ML algorithms require numeric inputs; therefore, these categorical values have to be encoded to numeric values. Encoding categorical data is the process of creating a numerical representation for categories. For example, if your category country has values Australia and Singapore, you may encode this information into two vectors: [1, 0] to represent Australia and [0, 1] to represent Singapore. The transformation used here is one-hot encoding and the new encoded output reflects the trained parameters.
After training the model, over time your customers may increase and you have more distinct values in the country list. The new dataset could contain another category, India, which wasn’t part of the original dataset, which can affect the model accuracy. Therefore, it’s necessary to retrain your model with the new data that has been collected over time.
To overcome this problem, you need to refresh the encoding to include the new category and update the vector representation as per your latest dataset. In our example, the encoding should reflect the new category for the country, which is India. We commonly refer to this process of refreshing an encoding as a refit operation. After you perform the refit operation, you get the new encoding: Australia: [1, 0, 0], Singapore: [0, 1, 0], and India: [0, 0, 1]. Refitting the one-hot encoding and then retraining the model on the new dataset results in better quality predictions.
Data Wrangler’s refit trained parameter feature is useful in the following cases:
- New data is added to the dataset – Retraining the ML model is necessary when the dataset is enriched with new data. To achieve optimal results, we need to refit the trained parameters on the new dataset.
- Training on a full dataset after performing feature engineering on sample data – For a large dataset, a sample of the dataset is considered for learning trained parameters, which may not represent your entire dataset. We need to relearn the trained parameters on the complete dataset.
The following are some of the most common Data Wrangler transforms performed on the dataset that benefit from the refit trained parameter option:
For more information about transformations in Data Wrangler, refer to Transform Data.
In this post, we show how to process these trained parameters on datasets using Data Wrangler. You can use Data Wrangler flows in production jobs to reprocess your data as it grows and changes.
Solution overview
For this post, we demonstrate how to use the Data Wrangler’s refit trained parameter feature with the publicly available dataset on Kaggle: US Housing Data from Zillow, For-Sale Properties in the United States. It has the home sale prices across various geo-distributions of homes.
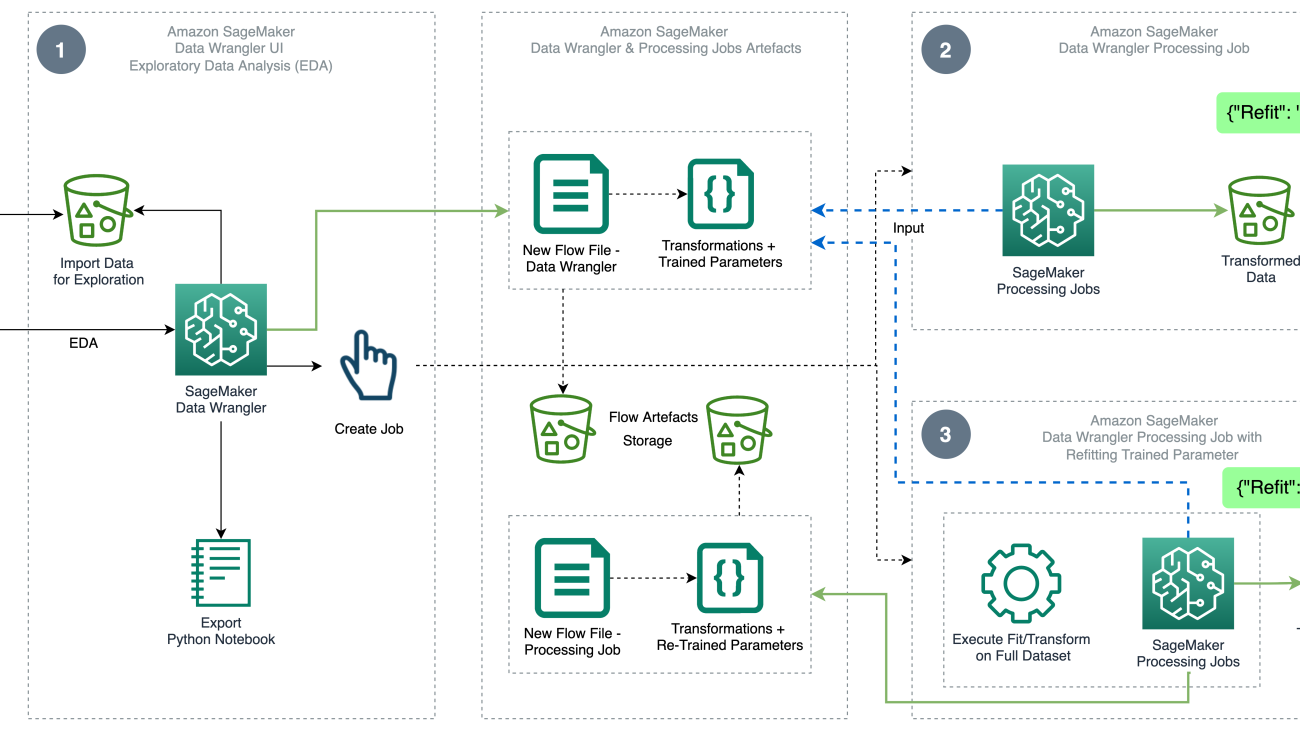
The following diagram illustrates the high-level architecture of Data Wrangler using the refit trained parameter feature. We also show the effect on the data quality without the refit trained parameter and contrast the results at the end.

The workflow includes the following steps:
- Perform exploratory data analysis – Create a new flow on Data Wrangler to start the exploratory data analysis (EDA). Import business data to understand, clean, aggregate, transform, and prepare your data for training. Refer to Explore Amazon SageMaker Data Wrangler capabilities with sample datasets for more details on performing EDA with Data Wrangler.
- Create a data processing job – This step exports all the transformations that you made on the dataset as a flow file stored in the configured Amazon Simple Storage Service (Amazon S3) location. The data processing job with the flow file generated by Data Wrangler applies the transforms and trained parameters learned on your dataset. When the data processing job is complete, the output files are uploaded to the Amazon S3 location configured in the destination node. Note that the refit option is turned off by default. As an alternative to executing the processing job instantly, you can also schedule a processing job in a few clicks using Data Wrangler – Create Job to run at specific times.
- Create a data processing job with the refit trained parameter feature – Select the new refit trained parameter feature while creating the job to enforce relearning of your trained parameters on your full or reinforced dataset. As per the Amazon S3 location configuration for storing the flow file, the data processing job creates or updates the new flow file. If you configure the same Amazon S3 location as in Step 2, the data processing job updates the flow file generated in the Step 2, which can be used to keep your flow relevant to your data. On completion of the processing job, the output files are uploaded to the destination node configured S3 bucket. You can use the updated flow on your entire dataset for a production workflow.
Prerequisites
Before getting started, upload the dataset to an S3 bucket, then import it into Data Wrangler. For instructions, refer to Import data from Amazon S3.
Let’s now walk through the steps mentioned in the architecture diagram.
Perform EDA in Data Wrangler
To try out the refit trained parameter feature, set up the following analysis and transformation in Data Wrangler. At the end of setting up EDA, Data Wrangler creates a flow file captured with trained parameters from the dataset.
- Create a new flow in Amazon SageMaker Data Wrangler for exploratory data analysis.
- Import the business data you uploaded to Amazon S3.
- You can preview the data and options for choosing the file type, delimiter, sampling, and so on. For this example, we use the First K sampling option provided by Data Wrangler to import first 50,000 records from the dataset.
- Choose Import.

- After you check out the data type matching applied by Data Wrangler, add a new analysis.

- For Analysis type, choose Data Quality and Insights Report.
- Choose Create.
With the Data Quality and Insights Report, you get a brief summary of the dataset with general information such as missing values, invalid values, feature types, outlier counts, and more. You can pick features property_type and city for applying transformations on the dataset to understand the refit trained parameter feature.
Let’s focus on the feature property_type from the dataset. In the report’s Feature Details section, you can see the property_type, which is a categorical feature, and six unique values derived from the 50,000 sampled dataset by Data Wrangler. The complete dataset may have more categories for the feature property_type. For a feature with many unique values, you may prefer ordinal encoding. If the feature has a few unique values, a one-hot encoding approach can be used. For this example, we opt for one-hot encoding on property_type.

Similarly, for the city feature, which is a text data type with a large number of unique values, let’s apply ordinal encoding to this feature.

- Navigate to the Data Wrangler flow, choose the plus sign, and choose Add transform.

- Choose the Encode categorical option for transforming categorical features.

From the Data Quality and Insights Report, feature property_type shows six unique categories: CONDO, LOT, MANUFACTURED, SINGLE_FAMILY, MULTI_FAMILY, and TOWNHOUSE.
- For Transform, choose One-hot encode.

After applying one-hot encoding on feature property_type, you can preview all six categories as separate features added as new columns. Note that 50,000 records were sampled from your dataset to generate this preview. While running a Data Wrangler processing job with this flow, these transformations are applied to your entire dataset.

- Add a new transform and choose Encode Categorical to apply a transform on the feature
city, which has a larger number of unique categorical text values. - To encode this feature into a numeric representation, choose Ordinal encode for Transform.


- Choose Preview on this transform.
You can see that the categorical feature city is mapped to ordinal values in the output column e_city.
- Add this step by choosing Update.

- You can set the destination to Amazon S3 to store the applied transformations on the dataset to generate the output as CSV file.

Data Wrangler stores the workflow you defined in the user interface as a flow file and uploads to the configured data processing job’s Amazon S3 location. This flow file is used when you create Data Wrangler processing jobs to apply the transforms on larger datasets, or to transform new reinforcement data to retrain the model.
Launch a Data Wrangler data processing job without refit enabled
Now you can see how the refit option uses trained parameters on new datasets. For this demonstration, we define two Data Wrangler processing jobs operating on the same data. The first processing job won’t enable refit; for the second processing job, we use refit. We compare the effects at the end.
- Choose Create job to initiate a data processing job with Data Wrangler.

- For Job name, enter a name.
- Under Trained parameters, do not select Refit.
- Choose Configure job.

- Configure the job parameters like instance types, volume size, and Amazon S3 location for storing the output flow file.
- Data Wrangler creates a flow file in the flow file S3 location. The flow uses transformations to train parameters, and we later use the refit option to retrain these parameters.
- Choose Create.

Wait for the data processing job to complete to see the transformed data in the S3 bucket configured in the destination node.
Launch a Data Wrangler data processing job with refit enabled
Let’s create another processing job enabled with the refit trained parameter feature enabled. This option enforces the trained parameters relearned on the entire dataset. When this data processing job is complete, a flow file is created or updated to the configured Amazon S3 location.
- Choose Create job.

- For Job name, enter a name.
- For Trained parameters, select Refit.
- If you choose View all, you can review all the trained parameters.

- Choose Configure job.
- Enter the Amazon S3 flow file location.
- Choose Create.

Wait for the data processing job to complete.
Refer to the configured S3 bucket in the destination node to view the data generated by the data processing job running the defined transforms.
Export to Python code for running Data Wrangler processing jobs
As an alternative to starting the processing jobs using the Create job option in Data Wrangler, you can trigger the data processing jobs by exporting the Data Wrangler flow to a Jupyter notebook. Data Wrangler generates a Jupyter notebook with inputs, outputs, processing job configurations, and code for job status checks. You can change or update the parameters as per your data transformation requirements.
- Choose the plus sign next to the final Transform node.
- Choose Export to and Amazon S3 (Via Jupyter Notebook).

You can see a Jupyter notebook opened with inputs, outputs, processing job configurations, and code for job status checks.
- To enforce the refit trained parameters option via code, set the
refitparameter toTrue.
 Compare data processing job results
Compare data processing job results
After the Data Wrangler processing jobs are complete, you must create two new Data Wrangler flows with the output generated by the data processing jobs stored in the configured Amazon S3 destination.
You can refer to the configured location in the Amazon S3 destination folder to review the data processing jobs’ outputs.

To inspect the processing job results, create two new Data Wrangler flows using the Data Quality and Insights Report to compare the transformation results.
- Create a new flow in Amazon SageMaker Data Wrangler.
- Import the data processing job without refit enabled output file from Amazon S3.
- Add a new analysis.
- For Analysis type, choose Data Quality and Insights Report.
- Choose Create.


Repeat the above steps and create new data wrangler flow to analyze the data processing job output with refit enabled.
Now let’s look at the outputs of processing jobs for the feature property_type using the Data Quality and Insights Reports. Scroll to the feature details on the Data and Insights Reports listing feature_type.
The refit trained parameter processing job has refitted the trained parameters on the entire dataset and encoded the new value APARTMENT with seven distinct values on the full dataset.

The normal processing job applied the sample dataset trained parameters, which have only six distinct values for the property_type feature. For data with feature_type APARTMENT, the invalid handling strategy Skip is applied and the data processing job doesn’t learn this new category. The one-hot encoding has skipped this new category present on the new data, and the encoding skips the category APARTMENT.

Let’s now focus on another feature, city. The refit trained parameter processing job has relearned all the values available for the city feature, considering the new data.
As shown in the Feature Summary section of the report, the new encoded feature column e_city has 100% valid parameters by using the refit trained parameter feature.

In contrast, the normal processing job has 82.4% of missing values in the new encoded feature column e_city. This phenomenon is because only the sample set of learned trained parameters are applied on the full dataset and no refitting is applied by the data processing job.

The following histograms depict the ordinal encoded feature e_city. The first histogram is of the feature transformed with the refit option.

The next histogram is of the feature transformed without the refit option. The orange column shows missing values (NaN) in the Data Quality and Insights Report. The new values that aren’t learned from the sample dataset are replaced as Not a Number (NaN) as configured in the Data Wrangler UI’s invalid handling strategy.

The data processing job with the refit trained parameter relearned the property_type and city features considering the new values from the entire dataset. Without the refit trained parameter, the data processing job only uses the sampled dataset’s pre-learned trained parameters. It then applies them to the new data, but the new values aren’t considered for encoding. This will have implications on the model accuracy.
Clean up
When you’re not using Data Wrangler, it’s important to shut down the instance on which it runs to avoid incurring additional fees.
To avoid losing work, save your data flow before shutting Data Wrangler down.
- To save your data flow in Amazon SageMaker Studio, choose File, then choose Save Data Wrangler Flow. Data Wrangler automatically saves your data flow every 60 seconds.
- To shut down the Data Wrangler instance, in Studio, choose Running Instances and Kernels.
- Under RUNNING APPS, choose the shutdown icon next to the sagemaker-data-wrangler-1.0 app.

- Choose Shut down all to confirm.

Data Wrangler runs on an ml.m5.4xlarge instance. This instance disappears from RUNNING INSTANCES when you shut down the Data Wrangler app.
After you shut down the Data Wrangler app, it has to restart the next time you open a Data Wrangler flow file. This can take a few minutes.
Conclusion
In this post, we provided an overview of the refit trained parameter feature in Data Wrangler. With this new feature, you can store the trained parameters in the Data Wrangler flow, and the data processing jobs use the trained parameters to apply the learned transformations on large datasets or reinforcement datasets. You can apply this option to vectorizing text features, numerical data, and handling outliers.
Preserving trained parameters throughout the data processing of the ML lifecycle simplifies and reduces the data processing steps, supports robust feature engineering, and supports model training and reinforcement training on new data.
We encourage you to try out this new feature for your data processing requirements.
About the authors
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
 Santosh Kulkarni is an Enterprise Solutions Architect at Amazon Web Services who works with sports customers in Australia. He is passionate about building large-scale distributed applications to solve business problems using his knowledge in AI/ML, big data, and software development.
Santosh Kulkarni is an Enterprise Solutions Architect at Amazon Web Services who works with sports customers in Australia. He is passionate about building large-scale distributed applications to solve business problems using his knowledge in AI/ML, big data, and software development.
 Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
Vishaal Kapoor is a Senior Applied Scientist with AWS AI. He is passionate about helping customers understand their data in Data Wrangler. In his spare time, he mountain bikes, snowboards, and spends time with his family.
 Aniketh Manjunath is a Software Development Engineer at Amazon SageMaker. He helps support Amazon SageMaker Data Wrangler and is passionate about distributed machine learning systems. Outside of work, he enjoys hiking, watching movies, and playing cricket.
Aniketh Manjunath is a Software Development Engineer at Amazon SageMaker. He helps support Amazon SageMaker Data Wrangler and is passionate about distributed machine learning systems. Outside of work, he enjoys hiking, watching movies, and playing cricket.







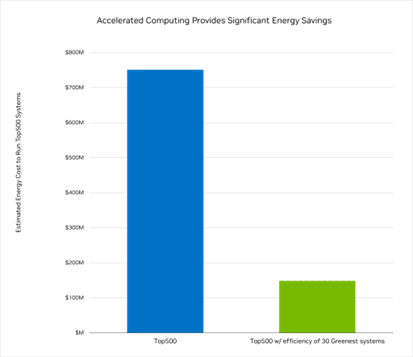 We estimate the TOP500 systems require more than 5 terawatt-hours of energy per year, or $750 million worth of energy, to operate.
We estimate the TOP500 systems require more than 5 terawatt-hours of energy per year, or $750 million worth of energy, to operate.