This post was co-authored by Arun Gupta, the Director of Business Intelligence at Prodege, LLC.
Prodege is a data-driven marketing and consumer insights platform comprised of consumer brands—Swagbucks, MyPoints, Tada, ySense, InboxDollars, InboxPounds, DailyRewards, PollFish, and Upromise—along with a complementary suite of business solutions for marketers and researchers. Prodege has 120 million users and has paid $2.1 billion in rewards since 2005. In 2021, Prodege launched Magic Receipts, a new way for its users to earn cash back and redeem gift cards, just by shopping in-store at their favorite retailers, and uploading a receipt.
Remaining on the cutting edge of customer satisfaction requires constant focus and innovation.
Building a data science team from scratch is a great investment, but takes time, and often there are opportunities to create immediate business impact with AWS AI services. According to Gartner, by the end of 2024, 75% of enterprises will shift from piloting to operationalizing AI. With the reach of AI and machine learning (ML) growing, teams need to focus on how to create a low-cost, high-impact solution that can be easily adopted by an organization.
In this post, we share how Prodege improved their customer experience by infusing AI and ML into its business. Prodege wanted to find a way to reward its customers faster after uploading their receipts. They didn’t have an automated way to visually inspect the receipts for anomalies before issuing rebates. Because the volume of receipts was in the tens of thousands per week, the manual process of identifying anomalies wasn’t scalable.
Using Amazon Rekognition Custom Labels, Prodege rewarded their customers 5 times faster after uploading receipts, increased the correct classification of anomalous receipts from 70% to 99%, and saved $1.5 million in annual human review costs.
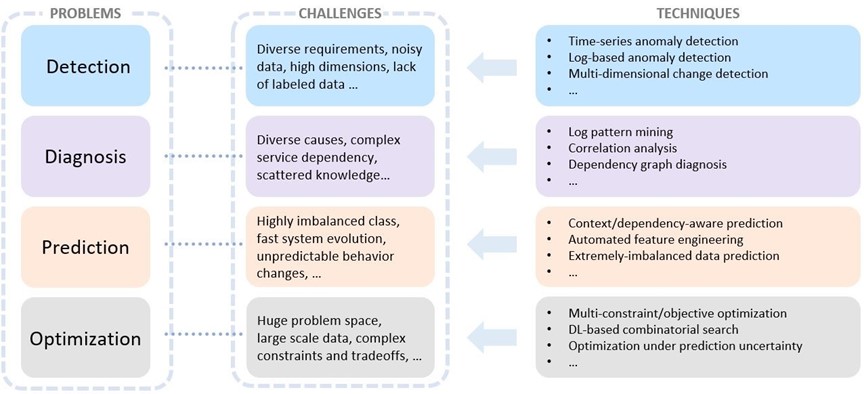
The challenge: Detecting anomalies in receipts quickly and accurately at scale
Prodege’s commitment to top-tier customer experience required an increase in the speed at which customers receive rewards for its massively popular Magic Receipts product. To do that, Prodege needed to detect receipt anomalies faster. Prodege investigated building their own deep learning models using Keras. This solution was promising in the long term, but couldn’t be implemented at Prodege’s desired speed for the following reasons:
- Required a large dataset – Prodege realized the number of images they would need for training the model would be in the tens of thousands, and they would also need heavy compute power with GPUs to train the model.
- Time consuming and costly – Prodege had hundreds of human-labeled valid and anomalous receipts, and the anomalies were all visual. Adding additional labeled images created operational expenses and could only function during normal business hours.
- Required custom code and high maintenance – Prodege would have to develop custom code to train and deploy the custom model and maintain its lifecycle.
Overview of solution: Rekognition Custom Labels
Prodege worked with the AWS account team to first identify the business use case of being able to efficiently process receipts in an automated way so that their business was only issuing rebates to valid receipts. The Prodege data science team wanted a solution that required a small dataset to get started, could create immediate business impact, and required minimal code and low maintenance.
Based on these inputs, the account team identified Rekognition Custom Labels as a potential solution to train a model to identify which receipts are valid and which ones have anomalies. Rekognition Custom Labels provides a computer vision AI capability with a visual interface to automatically train and deploy models with as few as a couple of hundred images of uploaded labeled data.
The first step was to train a model using the labeled receipts from Prodege. The receipts were categorized into two labels: valid and anomalous. Approximately a hundred receipts of each kind were carefully selected by the Prodege business team, who had knowledge of the anomalies. The key to a good model in Rekognition Custom Labels is having accurate training data. The next step was to set up training of the model with a few clicks on the Rekognition Custom Labels console. The F1 score, which is used to gauge the accuracy and quality of the model, came in at 97%. This encouraged Prodege to do some additional testing in their sandbox and use the trained model to infer if new receipts were valid or had anomalies. Setting up inference with Rekognition Custom Labels is an easy one-click process, and it provides sample code to set up programmatic inference as well.
Encouraged by the accuracy of the model, Prodege set up a pilot batch inference pipeline. The pipeline would start the model, run hundreds of receipts against the model, store the results, and then shut down the model every week. The compliance team would then evaluate the receipts to check for accuracy. The accuracy remained as high for the pilot as it was during the initial testing. The Prodege team also set up a pipeline to train new receipts in order to maintain and improve the accuracy of the model.
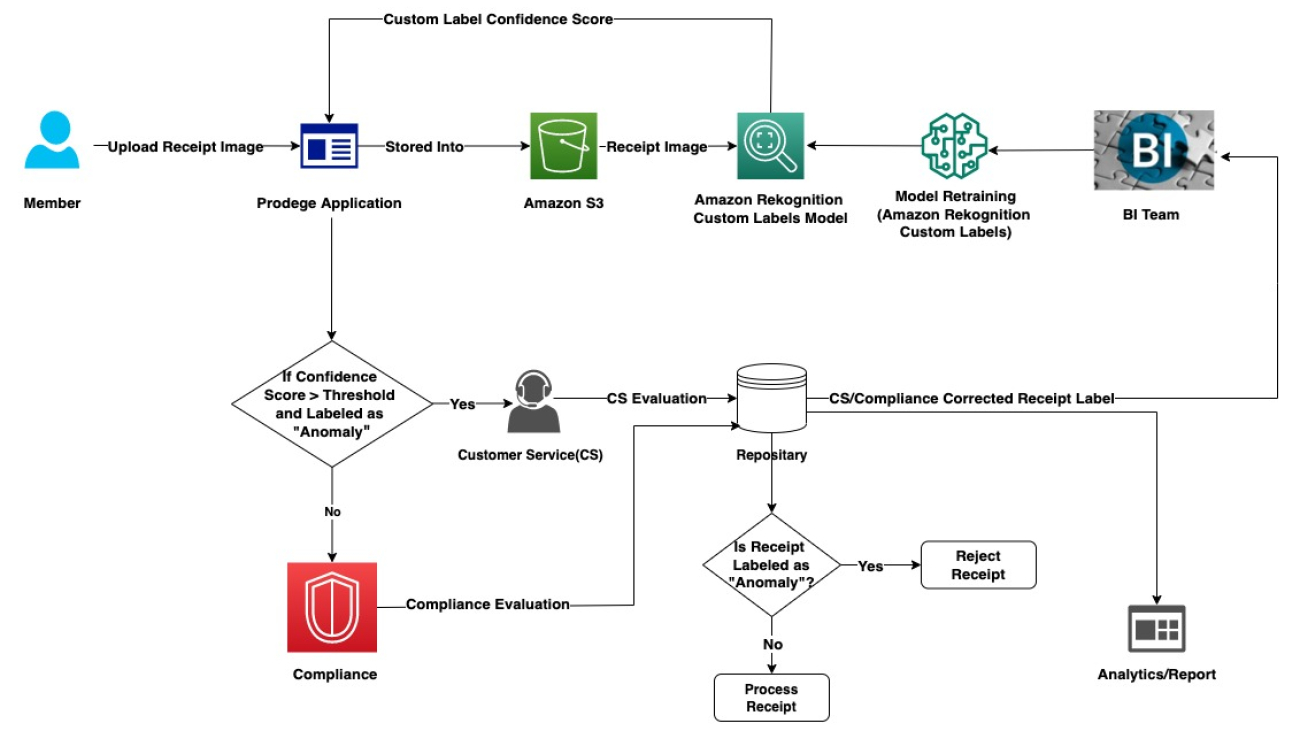
Finally, the Prodege business intelligence team worked with the application team and support from the AWS account and product team to set up an inference endpoint that would work with their application to predict the validity of uploaded receipts in real time and provide its users a best-in-class consumer rewards experience. The solution is highlighted in the following figure. Based on the prediction and confidence score from Rekognition Custom Labels, the Prodege business intelligence team applied business logic to either have it processed or go through additional scrutiny. By introducing a human in the loop, Prodege is able to monitor the quality of the predictions and retrain the model as needed.

Prodege Anomaly Detection Architecture
Results
With Rekognition Custom Labels, Prodege increased the correct classification of anomalous receipts from 70% to 99% and saved $1.5 million in annual human review costs. This allowed Prodege to reward its customers 5 times faster after uploading their receipts. The best part of Rekognition Custom Labels was that it was easy to set up and required only a small set of pre-classified images to train the ML model for high confidence image detection (approximately 200 images vs. 50,000 required to train a model from scratch). The model’s endpoints could be easily accessed using the API. Rekognition Custom Labels has been an extremely effective solution for Prodege to enable the smooth functioning of their validated receipt scanning product, and helped Prodege save a lot of time and resources performing manual detection.
Conclusion
Remaining on the cutting edge of customer satisfaction requires constant focus and innovation, and is a strategic goal for businesses today. AWS computer vision services allowed Prodege to create immediate business impact with a low-cost and low-code solution. In partnership with AWS, Prodege continues to innovate and remain on the cutting edge of customer satisfaction. You can get started today with Rekognition Custom Labels and improve your business outcomes.
About the Authors
 Arun Gupta is the Director of Business Intelligence at Prodege LLC. He is passionate about applying Machine Learning technologies to provide effective solutions across diverse business problems.
Arun Gupta is the Director of Business Intelligence at Prodege LLC. He is passionate about applying Machine Learning technologies to provide effective solutions across diverse business problems.
 Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.
 Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Amit Gupta is an AI Services Solutions Architect at AWS. He is passionate about enabling customers with well-architected machine learning solutions at scale.
Nick  Ramos is a Senior Account Manager with AWS. He is passionate about helping customers solve their most complex business challenges, infusing AI/ML into customers’ businesses, and help customers grow top-line revenue.
Ramos is a Senior Account Manager with AWS. He is passionate about helping customers solve their most complex business challenges, infusing AI/ML into customers’ businesses, and help customers grow top-line revenue.























 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 
