Two papers from Amazon Web Services AI present algorithms that alleviate the intensive hyperparameter search and fine-tuning required by privacy-preserving deep learning at very large scales.Read More
Differential privacy for deep learning at GPT scale
Two new methods — automatic gradient clipping and bias-term-only fine-tuning — improve the efficiency of differentially private model training.Read More

Startup’s AI Slashes Paperwork for Doctors Across Africa
As a medical doctor in Nigeria, Tobi Olatunji knows the stress of practicing in Africa’s busy hospitals. As a machine-learning scientist, he has a prescription for it.
“I worked at one of West Africa’s largest hospitals, where I would routinely see more than 30 patients a day — it’s a very hard job,” said Olatunji.
The need to write detailed patient notes and fill out forms makes it even harder. Paper records slowed the pace of medical research, too.
In his first years of practice, Olatunji imagined a program to plow through the mounds of paperwork, freeing doctors to help more patients.
It’s been a journey, but that software is available today from his company, Intron Health, a member of the NVIDIA Inception program, which nurtures cutting-edge startups.
A Side Trip in Tech
With encouragement from med school mentors, Olatunji got a master’s degree in medical informatics from the University of San Francisco and another in computer science at Georgia Tech. He started working as a machine-learning scientist in the U.S. by day and writing code on nights and weekends to help digitize Africa’s hospitals.
A pilot test during the pandemic hit a snag.
The first few doctors to use the code took 45 minutes to finish their patient notes. Feeling awkward in front of a keyboard, some health workers said they prefer pen and paper.
“We made a hard decision to invest in natural language processing and speech recognition,” he said. It’s technology he was already familiar with in his day job.
Building AI Models
“The combination of medical terminology and thick African accents produced horrible results with most existing speech-to-text software, so we knew there would be no shortcut to training our own models,” he said.

The Intron team evaluated several commercial and open-source speech recognition frameworks and large language models before choosing to build with NVIDIA NeMo, a software framework for text-based generative AI. In addition, the resulting models were trained on NVIDIA GPUs in the cloud.
“We initially tried to train with CPUs as the cheapest option, but it took forever, so we started with a single GPU and eventually grew to using several of them in the cloud,” he said.
The resulting Transcribe app captures doctors’ dictated messages with more than 92% accuracy across more than 200 African accents. It slashes the time they spend on paperwork by 6x on average, according to an ongoing study Intron is conducting across hospitals in four African countries.
“Even the doctor with the fastest typing skills in the study got a 40% speedup,” he said of the software now in use at several hospitals across Africa.
Listening to Africa’s Voices
Olatunji knew his models needed high quality audio data. So, the company created an app to capture sound bites of medical terms spoken in different accents.
To date, the app’s gathered more than a million clips from more than 7,000 people across 24 countries, including 13 African nations. It’s one of the largest datasets of its type, parts of which have been released as open source to support African speech research.
Today, Intron refreshes its models every other month as more data comes in.
Nurturing Diversity in Medtech
Very little research exists on speech recognition for African accents in a clinical setting. So, working with Africa’s tech communities like DSN, Masakhane and Zindi, Intron launched AfriSpeech-200, a developer challenge to kickstart research using its data.
Similarly, for all its sophistication, medtech lags in diversity and inclusion, so Olatunji recently launched an effort that addresses that issue, too.
Bio-RAMP Lab is a global community of minority researchers working on problems they care about at the intersection of AI and healthcare. The group already has a half dozen papers under review at major conferences.

“For seven years, I was the only Black person on every team I worked on,” he said. “There were no Black scientists or managers, even in my job interviews.”
Meanwhile, Intron is even helping hospitals in Africa find creative ways to acquire the hardware they need. It’s another challenge on the way to opening up huge opportunities.
“Once healthcare data gets digitized, you unlock a whole new world for research into areas like predictive models that can be early warning systems for epidemics — we can’t do it without data,” Olatunji said.
Watch a masterclass (starting at 20:30) with Olatunji, HuggingFace and NVIDIA on AI for speech recognition.

100 things we announced at I/O 2023
 Google I/O 2023 was filled with news and launches — here are 100 things announced at I/O.Read More
Google I/O 2023 was filled with news and launches — here are 100 things announced at I/O.Read More

Time to Prioritize: Upgrade to Priority at 40% Off This GFN Thursday
Make gaming a priority this GFN Thursday — time’s running out to upgrade to a GeForce NOW Priority six-month membership at 40% off the normal price. Find out how new Priority members are using the cloud to get their game on.
Plus, the week brings updates for some of the hottest games in the GeForce NOW library, and four more titles join the list.
GeForce NOW RTX 4080 SuperPODs are now live for Ultimate members in Atlanta, where the gamers game. Follow along with the server rollout, and upgrade today for the Ultimate cloud gaming experience.
Priority Check
Through Sunday, May 21, save 40% on a six-month Priority membership for $29.99, normally $49.99.
Priority memberships are perfect for those looking to try GeForce NOW or lock in a lower price for a half-year. Priority members get higher access to GeForce gaming servers, meaning less wait times than free members.
Members who claimed this offer in its first week alone played over 1,000 different titles in the GeForce NOW library, for 30,000+ streamed hours. That means these Priority members skipped the line by more than 500 hours.
They also played the best of PC gaming across multiple devices — PCs, Macs, mobile devices and smart TVs, plus new categories of devices made possible by the cloud, like gaming Chromebooks and cloud gaming handheld devices. And they experienced the cinematic quality of RTX ON in supported titles.
With more than 1,600 titles in the GeForce NOW library, there’s something for everyone to play. Jump into squad-based action in Fortnite or Destiny 2, bring home the victory League of Legends or Counter-Strike: Global Offensive, and explore in open-world role-playing games like Genshin Impact and Cyberpunk 2077. With GeForce NOW Priority, members can get straight into the action.
But don’t wait: This offer ends on Sunday, May 21, so make it a priority to upgrade today.
Game On
GFN Thursday means more games for more gamers. This week brings new additions to the GeForce NOW library, and new updates for the hottest games.

Apex Legends: Arsenal, the latest season in EA and Respawn Entertainment’s battle royale FPS, is available this week for GeForce NOW members. Meet the newest playable Legend, Ballistic, who’s come out of retirement to teach the young pups some respect. Battle through an updated World’s Edge map, hone your skills in the newly updated Firing Range and progress through the new Weapon Mastery system.

In addition, Occupy Mars, the latest open-world sandbox game from Pyramid Games, joins the GeForce NOW library this week. Explore and colonize Mars, building a home base and discovering new regions. Grow crops, conduct mining operations and survive on an unforgiving planet. As all sci-fi films that take place on Mars have shown, things don’t always go as planned. Players must learn to cope and survive on the red planet.
For more action, take a look at what’s joining the GeForce NOW library this week:
- Voidtrain (New release on Steam, May 9)
- Occupy Mars: The Game (New release on Steam, May 10)
- Far Cry 6 (New Release Steam, May 11)
- TT Isle of Man: Ride on the Edge 3 (New release on Steam, May 11)
Ultimate members can now enable real-time ray tracing in Fortnite. The island’s never looked so good.
What are you playing this weekend? We’ve got a little challenge for you this week. Let us know your response on Twitter or in the comments below.
Replace a word in a video game title with “cloud.”
We’ll go first: Cloud of Legends
—
NVIDIA GeForce NOW (@NVIDIAGFN) May 10, 2023

Living on the Edge: Singtel, Microsoft and NVIDIA Dial Up AI Over 5G
For telcos around the world, one of the biggest challenges to upgrading networks has always been the question, “If you build it, will they come?”
Asia’s leading telco, Singtel, believes the key to helping customers innovate with AI across industries — for everything from traffic and video analytics to conversational AI avatars powered by large language models (LLMs) — is to offer multi-access edge compute services on its high-speed, ultra-low-latency 5G network.
Multi-access edge computing, or MEC, moves the computing of traffic and services from a centralized cloud to the edge of the network, where it’s closer to the customer. Doing so reduces network latency and lowers costs through sharing of network resources.
Singtel is collaborating with Microsoft and NVIDIA to combine AI and 5G, so enterprises can boost their innovation and productivity. Using NVIDIA’s full-stack accelerated computing platform optimized for Microsoft Azure Public MEC, the telco is creating solutions that enable customers to leverage AI video analytics for multiple use cases and to deploy 5G conversational avatars powered by LLMs.
From Sea to Shore
Singtel has been rolling out enterprise 5G and MEC across ports, airports, manufacturing facilities and other locations. In addition to running low-latency applications at the edge using Singtel’s 5G network, the solution has the potential to transform operations in sectors such as public safety, urban planning, healthcare, banking, civil service, transportation and logistics. It also offers high security for public sector customers and better performance for end users, enabling new intelligent edge scenarios.
Customers can use these capabilities through Microsoft Azure, only paying for the amount of compute and storage they use for the duration in which they use it. This replicates the cloud consumption model at the network edge and lets users save on additional operational overhead.
Edge Technologies
Singtel is working with video analytics software-makers participating in NVIDIA Inception, a free program that offers startups go-to-market support, expertise and technology. These ISVs will be able to use the NVIDIA Jetson Orin module for edge AI and robotics in conjunction with Microsoft MEC to identify traffic flows at airports and other high-population areas, retail video analytics and other use cases.
Singtel and NVIDIA are also showcasing their technology and solutions, including a real-time LLM-powered avatar developed by system integrator Quantiphi and based on NVIDIA Omniverse digital twin technology, at a May 11 launch event in Singapore. The avatar, built with NVIDIA Riva speech AI and the NeMo Megatron transformer model, enables people to interact in natural language on any topic of interest. Businesses can deploy these avatars anywhere over 5G.
Using Singtel’s high-speed, low-latency 5G — combined with NVIDIA AI accelerated infrastructure and capabilities — enterprises can explore use cases on everything from computer vision and mixed reality to autonomous guided vehicles.
Singtel plans to expand these new capabilities beyond Singapore to other countries and affiliated telcos, as well. This collaboration will help redefine what’s possible through the powerful combination of compute and next-generation networks, unlocking new operational efficiencies, revenue streams and customer experiences.

Google I/O 2023: What’s new in TensorFlow and Keras?
 Posted by Ayush Jain, Carlos Araya, and Mani Varadarajan for the TensorFlow team
Posted by Ayush Jain, Carlos Araya, and Mani Varadarajan for the TensorFlow team
Welcome to TensorFlow and Keras at Google I/O!
The world of machine learning is changing, faster than ever. The rise of Large Language Models (LLMs) is sparking the imagination of developers worldwide, with new generative AI applications reaching hundreds of millions of people around the world. These models are trained on massive datasets, and used to solve a variety of tasks, from natural language processing to image generation.
Powering all these new capabilities requires new levels of model efficiency and performance, as well as support for seamless deployment across a growing number of devices – be it on a server, the web, mobile devices, or beyond. As stewards of one of the largest machine learning communities in the world, the TensorFlow team is continually asking how we can better serve you.
To that end, this post covers a few of the many improvements and additions coming this year to the TensorFlow ecosystem. Let’s dive in!
A Growing Ecosystem
New functionality we’re covering today:
KerasCV and KerasNLP allows you to access pre-trained, state-of-the-art models in just a few lines of code.
DTensor helps you scale up your models and train them efficiently by combining different parallelism techniques.
With JAX2TF, models written with the JAX numerical library can be used in the TensorFlow ecosystem.
We also preview the TF Quantization API, which enables you to make your models more cost and resource-efficient without compromising on accuracy.
Applied ML with KerasCV & KerasNLP
KerasCV and KerasNLP are powerful, modularized libraries that give you direct access to the state-of-the-art in computer vision and natural language processing.
 |
| The KerasCV + KerasNLP suite, at a glance. |
Whether you want to classify images, auto-generate text from prompts like with Bard or anything in between, KerasCV and KerasNLP make it easy with just a few lines of code. And since it’s a part of Keras, it’s fully integrated with the TensorFlow Ecosystem.
Let’s look at some code for image generation. KerasCV is designed to support many models, and in this case we’ll use a diffusion model. Despite the complexity of the underlying architecture, you can get it up and running with just a few lines of code.
from keras_cv.models import ( |
With one line to import and another to initialize the model, you can generate completely new images:
images = model.text_to_image( |
 |
| KerasCV-generated images of an astronaut riding a horse! |
This is just one of many examples. To learn more, check out our full talk on KerasCV and KerasNLP or in-depth toolkit guides at keras.io/keras_cv and keras.io/keras_nlp.
Machine Learning at Scale with DTensor
DTensor enables larger and more performant model training by giving developers the flexibility to combine and fine-tune multiple parallelism techniques.
Traditionally, ML developers have scaled up models through data parallelism, which splits up your data and feeds it to horizontally-scaled model instances. This scales up training but has an important limitation: it requires that the model fits within a single hardware device.
As models get bigger, fitting into a single device is no longer a guarantee — developers need to be able to scale their models across hardware devices. This is where model parallelism becomes important, allowing for the model to be split up into shards that can be trained in parallel.
With DTensor, data and model parallelism are not only supported, but also can be directly combined to scale models even more efficiently. And it’s completely accelerator agnostic — whether you use TPUs, GPUs, or something else.
 |
| Mixed (data + model) parallelism, with DTensor. |
Let’s go through an example. Let’s say that you are building with a transformer model, like the Open Pre-trained Transformer (OPT) available through KerasNLP, and training it with some input dataset:
opt_lm = keras_nlp.models.OPTCasualLM.from_preset("opt_6.7b_en") |
But here’s the thing about OPT — it’s big. With variations up to 175 billion parameters, if we tried traditional data parallelism, it would have errored outright — there’s just too many weights to reasonably replicate within a single hardware device. That’s where DTensor comes in.
To work with DTensor, we need to define two things:
First is a mesh, where you define (a) a set of hardware devices and (b) a topology, here the batch and model dimensions.
mesh_dims = [("batch", 2), ("model", 4)]
mesh = dtensor.create_distributed_mesh(mesh_dims, device_type="GPU") |
Second is a layout, which defines how to shard the Tensor dimension on your defined mesh. Through our Keras domain package integrations, you can do this in just one line.
layout_map = keras_nlp.models.OPTCausalLM.create_layout_map(mesh)
From there, you create the DTensor layout’s context and include your model creation code within it. Note that at no point did we have to make any changes to the model itself!
with layout_map.scope(): |
Performance for DTensor today is already on par with industry benchmarks, nearly matching the gold-standard implementation of model parallelism offered by NVIDIA’s Megatron for GPUs. Further improvements are in the works to raise the bar even further, across hardware devices.
In the future, DTensor will be fully integrated with key interfaces like tf.distribute and Keras as a whole, with one entry point regardless of hardware and a number of other quality of life features. If you want to learn more, check out the DTensor overview or the Keras integration guide!
Bringing Research to Production with JAX2TF
Many of the ML advancements that are now household names had their beginnings in research. For example, the Transformer architecture, created and published by Google AI, underpins the fantastic advances in language models.
JAX has emerged as a trusted tool for much of this kind of discovery, but productionizing it is hard. To that end, we’ve been thinking about how to bring research more easily into TensorFlow, giving innovations built on JAX the full strength of TensorFlow’s uniquely robust and diverse production ecosystem.
That’s why we’ve built JAX2TF, a lightweight API that provides a pathway from the JAX ecosystem to the TensorFlow ecosystem. There are many examples of how this can be useful – here’s just a few:
- Inference: Taking a model written for JAX and deploying it either on a server using TF Serving or on-device using TFLite.
- Fine Tuning: Taking a model that was trained using JAX, we can bring its components to TF using JAX2TF, and continue training it in TensorFlow with your existing training data and setup.
- Fusion: Combining parts of models that were trained using JAX with those trained using TensorFlow for maximum flexibility.
The key to enabling this kind of interoperation between JAX and TensorFlow is baked into jax2tf.convert, which takes in model components created on top of JAX (e.g. your loss function, prediction function, etc.) and creates equivalent representations of them as TensorFlow functions, which can then be exported as a TensorFlow SavedModel.
We’ve created a code walkthrough for one of the examples above: a quick fine-tuning setup, creating a simple model using modeling libraries in the JAX ecosystem (like Flax and Optax) and bringing it into TF to finish training. Check it out here.
JAX2TF is already baked into various tools in the TensorFlow ecosystem, under the hood. For example, here are code guides for simple conversion from JAX to TFLite for mobile devices and from JAX to TF.js for web deployment!
Coming Soon: The TensorFlow Quantization API
ML developers today face a wide variety of real-world constraints introduced by the settings they’re working in, like the size of a model or where it gets deployed.
With TensorFlow, we want developers to be able to quickly adjust and accommodate for these kinds of constraints, and to do so without sacrificing model quality. To do this, we’re building the TF Quantization API, a native quantization toolkit for TF2 which will be available publicly later in 2023.
Briefly, quantization is a group of techniques designed to make models faster, smaller, and generally less resource- and infrastructure-intensive to train and serve.
Quantization does this by reducing the precision of a model’s parameters, just like reducing pixel depth in an image like the one of Albert Einstein below. Note that even with reduced precision, we can still make out the key details:
 |
| Renderings of a photograph of Albert Einstein with increasingly reduced bit precision. |
At a high level, this works by taking a range of values in your starting precision, and mapping that range to a single bucket in your ending precision. Let’s illustrate this with an example:
 |
| Quantizing float representation to 4-bit integers. |
Take a look at the range [0.27, 0.49] on the x-axis: for float32, the blue line actually represents 7381976 unique numbers! The red line represents the int4 quantization of this range, condensing all of those numbers into a single bucket: 1001 (the number 9 in decimal).
By lowering precision through quantization, we can store model weights in a much more efficient, compressed form.
There’s a few different ways to quantize.
- Post-Training Quantization (PTQ): Convert to a quantized model after training. This is as simple as it gets and most readily accessible, but there can be a small quality drop.
- Quantization-Aware Training (QAT): Simulate quantization during just the forward pass, providing for maximal flexibility with a minimal quality tradeoff.
- Quantized Training: Quantize all computations while training. This is still nascent, and needs a lot more testing, but is a powerful tool we want to make sure TensorFlow users have access to.
TensorFlow previously has had a few tools for developers to quantize their models, like this guide for PTQ and this one for QAT. However, these have been limited – with PTQ depending on conversion to TFLite for mobile deployment and QAT requiring you to rewrite your model.
The TF Quantization API is different – it’s designed to work regardless of where you’re deploying, and without you having to rewrite a single line of existing modeling code. We’re building it with flexibility and fidelity in mind, so you get the benefits of a smaller quantized model with new levels of fine-grained control and without any concerns about how it’ll all fit into your stack.
Since you’ve made it this far into the blog, here’s a sneak peek at how it’ll look. We’ll start with a typical setup for a TensorFlow model, just a few layers in Keras. From there, we can load in a predefined quantization schema to apply as a config map to our model.
# Step 1: Define your model, just like always. |
But if you need more flexibility, TF Quantization API will also let you fully customize how you quantize. There’s built-in support for you to curate your schema to apply different behaviors for every layer, operation, or tensor!
# ...or just as easily configure your own, whether per-layer: |
With that, we can directly apply quantization and train or save within a quantization context. Our model still has natural compatibility with the rest of the TF ecosystem, where quantization truly bears fruit.
# Now you can generate a quantization-aware model! |
We ran a bunch of tests using the MobileNetV2 model on the Pixel 7, and saw up to 16.7x gains in serving throughput versus the non-quantized baseline. This gain comes without any noticeable detriment to quality: both the float32 baseline and the int8 quantized model reported 73% accuracy.
The TF Quantization API isn’t public just yet, but will be available very soon and will continue to evolve to provide even more benefits.
That’s a wrap!
Today, we’ve shown you just a few of the key things we’ve been working on, and there’s a lot more to come.
We can’t wait to see what you’ll build, and we’re always inspired by our community’s enduring enthusiasm and continued partnership. Thanks for stopping by!
Acknowledgements
Special thanks to George Necula, Francois Chollet, Jonathan Bischof, Scott Zhu, Martin Gorner, Dong Li, Adam Koch, Bruce Fontaine, Laurence Moroney, Josh Gordon, Lauren Usui, and numerous others for their contributions to this post.

AI and Machine Learning @ I/O Recap

Posted by Lauren Usui and Joe Fernandez

Artificial intelligence is a topic of kitchen table conversations around the world today, and as AI becomes more accessible for users and developers, we want to make it easier and more useful for everyone. This year at Google I/O, we highlighted how we are helping developers like you build with generative AI, use machine learning in spreadsheets and applications, create ML models from the ground up, and scale them up to serve millions of users.
While AI technology is advancing rapidly, we must continue to ensure it is used responsibly. So we also took some time to explain how Google is taking a principled approach to applying generative AI and how you can apply our guidelines and tools to make sure your AI-powered products and projects are built responsibly to serve all your users.
If you are new to AI and want to get a quick overview of the technology, check out the getting started video from Google’s AI advocate lead, Laurence Moroney.
Develop generative AI apps with PaLM 2
Everyone seems to be chatting with—or about—generative AI recently, and we want you to be able to use Google’s latest large language model, PaLM 2, to power new and helpful experiences for your users with the PaLM API. Our session on Generative AI reveals more about how you can easily prompt models with MakerSuite to quickly prototype generative AI applications. We demonstrate how you can use the PaLM API for prompting using examples, conversational chat interactions, and using embedding functionality to compress and compare text data in useful ways. We also showed off how to use the PaLM API in Google Colab notebooks with a simple, magical syntax. Check out this talk and sign up to request access to the PaLM API and MakerSuite!
Crunch numbers with AI-powered spreadsheets
Hundreds of millions of people use spreadsheets to organize, manage, and analyze data for everything from business transactions, to inventory accounting, to family budgets. We’re making it easy for everyone to bring the power of AI into spreadsheets with Simple ML for Sheets, a Google Sheets add-on. We recently updated this tool to include anomaly detection and forecasting features. Check out the demonstration of how to predict missing data values and forecast sales with the tool. No coding required!
Simplify on-device ML applications with MediaPipe
AI is finding its way into applications across multiple platforms and MediaPipe makes it easy to build, customize, and deploy on-device ML solutions. We upgraded MediaPipe Solutions this year, improving existing solutions and adding new ones, including interactive segmentation to blur the background behind a selected subject and face stylization to render that selfie in your favorite graphic style.
Do more with Web ML
Every week, hundreds of thousands of developers build AI-powered applications to run in the browser or Node.js using JavaScript and web technologies. Web ML has advanced in multiple areas, and we provide a round up of the top updates in this year’s I/O talk. We announced Visual Blocks for ML, an open JavaScript framework for quickly and interactively building custom ML pipelines. You can now run machine learning models even faster with improved WebGL performance and the release of WebGPU in Chrome. More tools and resources are also now available for web ML developers, including TensorFlow Decision Forest support, a visual debugger for models, JAX to JS conversion support, and a new Zero to Hero training course to grow your skills in Web ML.
Find pre-trained models fast with Kaggle Models
Building machine learning models can take a huge amount of time and effort: collecting data, training, evaluating, and optimizing. Kaggle is making it a whole lot easier for developers to discover and use pretrained models. With Kaggle Models, you can search thousands of open-licensed models from leading ML researchers for multiple ML platforms. Find the model you need quickly with filters for tasks, supported data types, model architecture, and more. Combine this new feature with Kaggle’s huge repository of over 200K datasets and accelerate your next ML project.
Apply ML to vision and text with Keras
Lots of developers are exploring AI technologies and many of you are interested in working on computer vision and natural language processing applications. Keras released new, easy-to-use libraries for computer vision and natural language processing with KerasCV and KerasNLP. Using just a few lines of code, you can apply the latest techniques and models for data augmentation, object detection, image and text generation, and text classification. These new libraries provide modular implementations that are easy to customize and are tightly integrated with the broader TensorFlow ecosystem including TensorFlow Lite, TPUs, and DTensor.
Build ML flexibly and scalably with TensorFlow
With one of the largest ML development communities in the world, the TensorFlow ecosystem helps hundreds of thousands of developers like you build, train, deploy, and manage machine learning models. ML technology is rapidly evolving, and we’re upgrading TensorFlow with new tools to give you more flexibility, scalability, and efficiency. If you’re using JAX, you can now bring your model components into the TensorFlow ecosystem with JAX2TF. We also improved DTensor support for model parallelization, allowing you to scale up execution of larger models by running portions of a single model, or shards, across multiple machines. We also announced a toolkit for applying quantization techniques to practically any TensorFlow model, helping you gain substantial efficiency improvements for your AI applications. The quantization toolkit will be available later this year.
Scale large language models with Google Cloud
When it’s time to deploy your AI-powered applications to your business, enterprise, or the world, you need reliable tools and services that scale with you. Google Cloud’s Vertex AI is an end-to-end ML platform that helps you develop ML models quickly and easily, and deploy them at any scale. To help you build generative AI technology for your product or business, we’ve introduced Model Garden and the Generative AI Studio as part of the Vertex AI platform. Model Garden gives you quick access to the latest foundation models such as Google PaLM 2, and many more to build AI-powered applications for text processing, imagery, and code. Generative AI Studio lets you quickly prototype generative AI applications right in your browser, and when you are ready to deploy, Vertex AI and Google Cloud services enable you to scale up to hundreds, thousands, or millions of users.
Explore new resources to build with Google AI
As tools, technology, and techniques for AI development rapidly advance, finding what you need to get started or take the next step with your project can be challenging. We’re making it easier to find the right resources to accelerate your AI development at Build with Google AI. This new site brings together tools, guidance, and community for building, deploying, and managing ML. Whether you are creating AI for on-device apps or deploying AI at scale, we help you navigate the options and find your path. Check out our latest toolkits on Building an LLM on Android and Text Classification with Keras.
Making Generative AI safe and responsible
AI is a powerful tool, and it’s up to all of us to ensure that it is used responsibly and for the benefit of all. We’re committed to ensuring Google’s AI systems are developed according to our AI principles. This year at Google I/O, we shared how we’ve created guidelines and tools for building generative AI safely and responsibly, and how you can apply those same guidelines and tools for your own projects.
Aaannnd that’s a wrap! Check out the full playlist of all the AI-related sessions we mentioned above. We are excited to share these new tools, resources, and technologies with you, and we can’t wait to see what you build with them!

Introducing Project Gameface: A hands-free, AI-powered gaming mouse
 Project Gameface, a new open-source hands-free gaming mouse has the potential to make gaming more accessible.Read More
Project Gameface, a new open-source hands-free gaming mouse has the potential to make gaming more accessible.Read More

Meet the Omnivore: Creative Studio Aides Fight Against Sickle Cell Disease With AI-Animated Short
Editor’s note: This post is a part of our Meet the Omnivore series, which features individual creators and developers who use NVIDIA Omniverse to accelerate their 3D workflows and create virtual worlds.
Creative studio Elara Systems doesn’t shy away from sensitive subjects in its work.
Part of its mission for a recent client was to use fun, captivating visuals to help normalize what could be considered a touchy health subject — and boost medical outcomes as a result.
In collaboration with Boston Scientific and the Sickle Cell Society, the Elara Systems team created a character-driven 3D medical animation using the NVIDIA Omniverse development platform for connecting 3D pipelines and building metaverse applications.
The video aims to help adolescents experiencing sickle cell disease understand the importance of quickly telling an adult or a medical professional if they’re experiencing symptoms like priapism — a prolonged, painful erection that could lead to permanent bodily damage.
“Needless to say, this is something that could be quite frightening for a young person to deal with,” said Benjamin Samar, technical director at Elara Systems. “We wanted to make it crystal clear that living with and managing this condition is achievable and, most importantly, that there’s nothing to be ashamed of.”
To bring their projects to life, the Elara Systems team turns to the USD Composer app, generative AI-powered Audio2Face and Audio2Gesture, as well as Omniverse Connectors to Adobe Substance 3D Painter, Autodesk 3ds Max, Autodesk Maya and other popular 3D content-creation tools like Blender, Epic Games Unreal Engine, Reallusion iClone and Unity.
For the sickle cell project, the team relied on Adobe Substance 3D Painter to organize various 3D environments and apply custom textures to all five characters. Adobe After Effects was used to composite the rendered content into a single, cohesive short film.
It’s all made possible thanks to the open and extensible Universal Scene Description (USD) framework on which Omniverse is built.
“USD is extremely powerful and solves a ton of problems that many people may not realize even exist when it comes to effectively collaborating on a project,” Samar said. “For example, I can build a scene in Substance 3D Painter, export it to USD format and bring it into USD Composer with a single click. Shaders are automatically generated and linked, and we can customize things further if desired.”
An Animation to Boost Awareness
Grounding the sickle cell awareness campaign in a relatable, personal narrative was a “uniquely human approach to an otherwise clinical discussion,” said Samar, who has nearly two decades of industry experience spanning video production, motion graphics, 3D animation and extended reality.
The team accomplished this strategy through a 3D character named Leon — a 13-year-old soccer lover who shares his experiences about a tough day when he first learned how to manage his sickle cell disease.
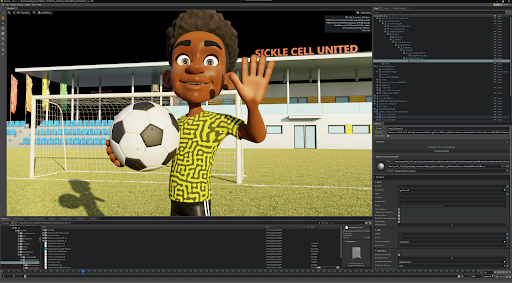
The project began with detailed discussions about Sickle Cell Society’s goals for the short, followed by scripting, storyboarding and creating various sketches. “Once an early concept begins to crystallize in the artists’ minds, the creative process is born and begins to build momentum,” Samar said.

Then, the team created rough 2D mockups using the illustration app Procreate on a tablet. This stage of the artistic process centered on establishing character outfits, proportions and other details. The final concept art was used as a clear reference to drive the rest of the team’s design decisions.
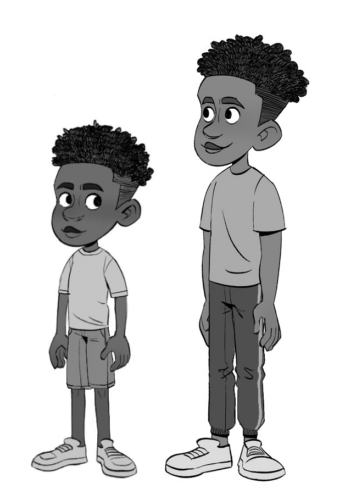
Moving to 3D, the Elara Systems team tapped Autodesk Maya to build, rig and fully animate the characters, as well as Adobe Substance 3D Painter and Autodesk 3ds Max to create the short’s various environments.
“I’ve found the animated point cache export option in the Omniverse Connector for Maya to be invaluable,” Samar said. “It helps ensure that what we’re seeing in Maya will persist when brought into USD Composer, which is where we take advantage of real-time rendering to create high-quality visuals.”
The real-time rendering enabled by Omniverse was “critically important, because without it, we would have had zero chance of completing and delivering this content anywhere near our targeted deadline,” the technical artist said.

“I’m also a big fan of the Reallusion to Omniverse workflow,” he added.
The Connector allows users to easily bring characters created using Reallusion iClone into Omniverse, which helps to deliver visually realistic skin shaders. And USD Composer can enable real-time performance sessions for iClone characters when live-linked with a motion-capture system.
“Omniverse offers so much potential to help streamline workflows for traditional 3D animation teams, and this is just scratching the surface — there’s an ever-expanding feature set for those interested in robotics, digital twins, extended reality and game design,” Samar said. “What I find most assuring is the sheer speed of the platform’s development — constant updates and new features are being added at a rapid pace.”
Join In on the Creation
Creators and developers across the world can download NVIDIA Omniverse for free, and enterprise teams can use the platform for their 3D projects.
Check out artwork from other “Omnivores” and submit projects in the gallery. Connect your workflows to Omniverse with software from Adobe, Autodesk, Epic Games, Maxon, Reallusion and more.
Follow NVIDIA Omniverse on Instagram, Medium, Twitter and YouTube for additional resources and inspiration. Check out the Omniverse forums, and join our Discord server and Twitch channel to chat with the community.