 Magic Editor is an experimental editing experience that uses AI to help reimagine your photos — early access is planned for select Pixel phones later this year.Read More
Magic Editor is an experimental editing experience that uses AI to help reimagine your photos — early access is planned for select Pixel phones later this year.Read More

Magic Editor is an experimental editing experience that uses AI to help reimagine your photos — early access is planned for select Pixel phones later this year.Read More

 With advancements in AI, there are new ways to understand your route with Maps. Plus, new immersive tools for developers.Read More
With advancements in AI, there are new ways to understand your route with Maps. Plus, new immersive tools for developers.Read More

 Starting today, you can sign up to try MusicLM, a new experimental AI tool that can turn your text descriptions into music.Read More
Starting today, you can sign up to try MusicLM, a new experimental AI tool that can turn your text descriptions into music.Read More
Today, data scientists who are training deep learning models need to identify and remediate model training issues to meet accuracy targets for production deployment, and require a way to utilize standard tools for debugging model training. Among the data scientist community, TensorBoard is a popular toolkit that allows data scientists to visualize and analyze various aspects of their machine learning (ML) models and training processes. It provides a suite of tools for visualizing training metrics, examining model architectures, exploring embeddings, and more. TensorFlow and PyTorch projects both endorse and use TensorBoard in their official documentation and examples.
Amazon SageMaker with TensorBoard is a capability that brings the visualization tools of TensorBoard to SageMaker. Integrated with SageMaker training jobs and domains, it provides SageMaker domain users access to the TensorBoard data and helps domain users perform model debugging tasks using the SageMaker TensorBoard visualization plugins. When they create a SageMaker training job, domain users can use TensorBoard using the SageMaker Python SDK or Boto3 API. SageMaker with TensorBoard is supported by the SageMaker Data Manager plugin, with which domain users can access many training jobs in one place within the TensorBoard application.
In this post, we demonstrate how to set up a training job with TensorBoard in SageMaker using the SageMaker Python SDK, access SageMaker TensorBoard, explore training output data visualized in TensorBoard, and delete unused TensorBoard applications.
A typical training job for deep learning in SageMaker consists of two main steps: preparing a training script and configuring a SageMaker training job launcher. In this post, we walk you through the required changes to collect TensorBoard-compatible data from SageMaker training.
To start using SageMaker with TensorBoard, you need to set up a SageMaker domain with an Amazon VPC under an AWS account. Domain user profiles for each individual user are required to access the TensorBoard on SageMaker, and the AWS Identity and Access Management (IAM) execution role needs a minimum set of permissions, including the following:
sagemaker:CreateAppsagemaker:DeleteAppsagemaker:DescribeTrainingJobsagemaker:Searchs3:GetObjects3:ListBucketFor more information on how to set up SageMaker Domain and user profiles, see Onboard to Amazon SageMaker Domain Using Quick setup and Add and Remove User Profiles.
When using Amazon SageMaker Studio, the directory structure can be organized as follows:
Here, script/train.py is your training script, and simple_tensorboard.ipynb launches the SageMaker training job.
You can use any of the following tools to collect tensors and scalars: TensorBoardX, TensorFlow Summary Writer, PyTorch Summary Writer, or Amazon SageMaker Debugger, and specify the data output path as the log directory in the training container (log_dir). In this sample code, we use TensorFlow to train a simple, fully connected neural network for a classification task. For other options, refer to Prepare a training job with a TensorBoard output data configuration. In the train() function, we use the tensorflow.keras.callbacks.TensorBoard tool to collect tensors and scalars, specify /opt/ml/output/tensorboard as the log directory in the training container, and pass it to model training callbacks argument. See the following code:
Use sagemaker.debugger.TensorBoardOutputConfig while configuring a SageMaker framework estimator, which maps the Amazon Simple Storage Service (Amazon S3) bucket you specify for saving TensorBoard data with the local path in the training container (for example, /opt/ml/output/tensorboard). You can use a different container local output path. However, it must be consistent with the value of the LOG_DIR variable, as specified in the previous step, to have SageMaker successfully search the local path in the training container and save the TensorBoard data to the S3 output bucket.
Next, pass the object of the module to the tensorboard_output_config parameter of the estimator class. The following code snippet shows an example of preparing a TensorFlow estimator with the TensorBoard output configuration parameter.
The following is the boilerplate code:
The following code is for the training container:
The following code is the TensorBoard configuration:
Launch the training job with the following code:
You can access TensorBoard with two methods: programmatically using the sagemaker.interactive_apps.tensorboard module that generates the URL or using the TensorBoard landing page on the SageMaker console. After you open TensorBoard, SageMaker runs the TensorBoard plugin and automatically finds and loads all training job output data in a TensorBoard-compatible file format from S3 buckets paired with training jobs during or after training.
The following code autogenerates the URL to the TensorBoard console landing page:
This returns the following message with a URL that opens the TensorBoard landing page.
For opening TensorBoard from the SageMaker console, please refer to How to access TensorBoard on SageMaker.
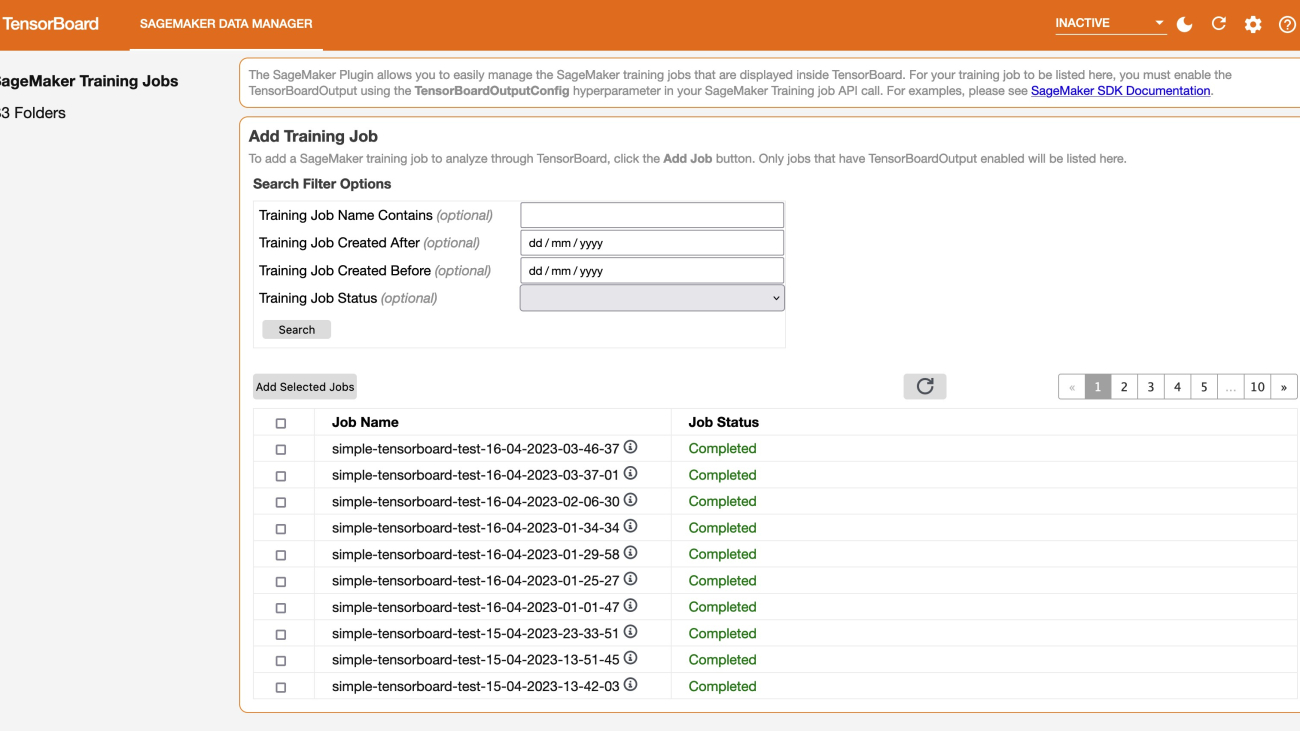
When you open the TensorBoard application, TensorBoard opens with the SageMaker Data Manager tab. The following screenshot shows the full view of the SageMaker Data Manager tab in the TensorBoard application.
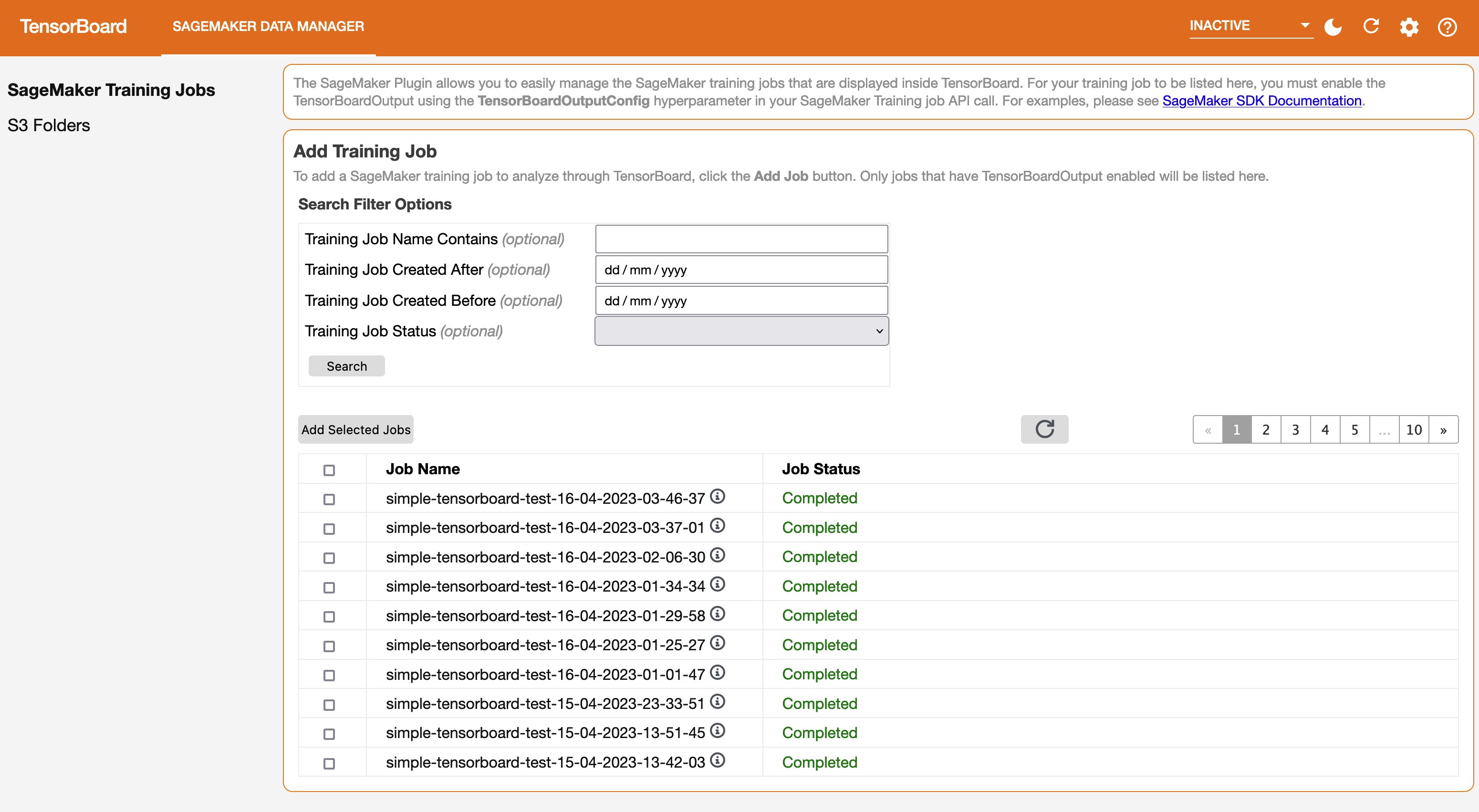
On the SageMaker Data Manager tab, you can select any training job and load TensorBoard-compatible training output data from Amazon S3.
The selected jobs should appear in the Tracked Training Jobs section.
Refresh the viewer by choosing the refresh icon in the upper-right corner, and the visualization tabs should appear after the job data is successfully loaded.
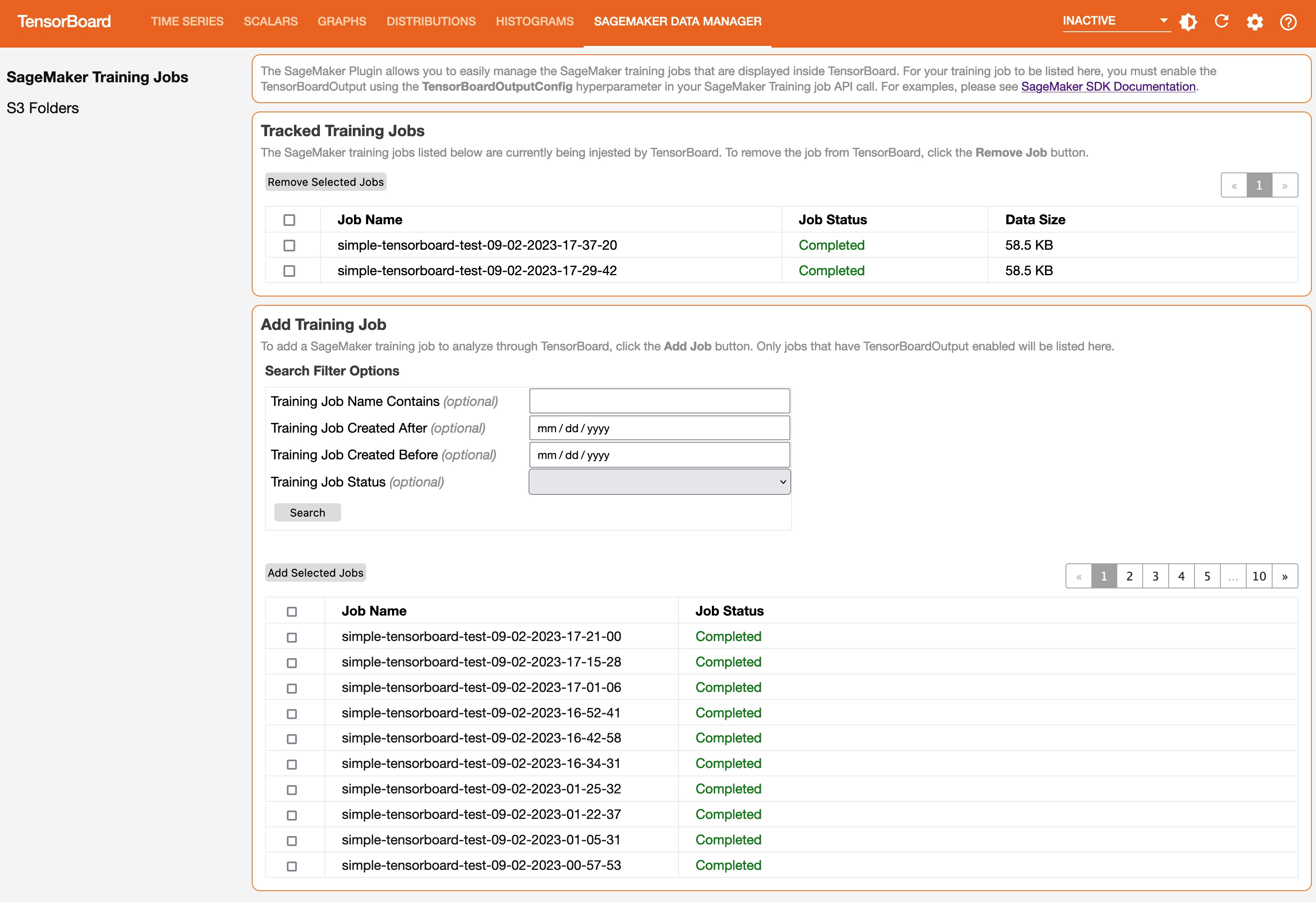
On the Time Series tab and other graphics-based tabs, you can see the list of Tracked Training Jobs in the left pane. You can also use the check boxes of the training jobs to show or hide visualizations. The TensorBoard dynamic plugins are activated dynamically depending on how you have set your training script to include summary writers and pass callbacks for tensor and scalar collection, and the graphics tabs also appear dynamically. The following screenshots show example views of each tab with visualizations of the collected metrics of two training jobs. The metrices include time series, scalar, graph, distribution, and histogram plugins.
The following screenshot is the Time Series tab view.

The following screenshot is the Scalars tab view.
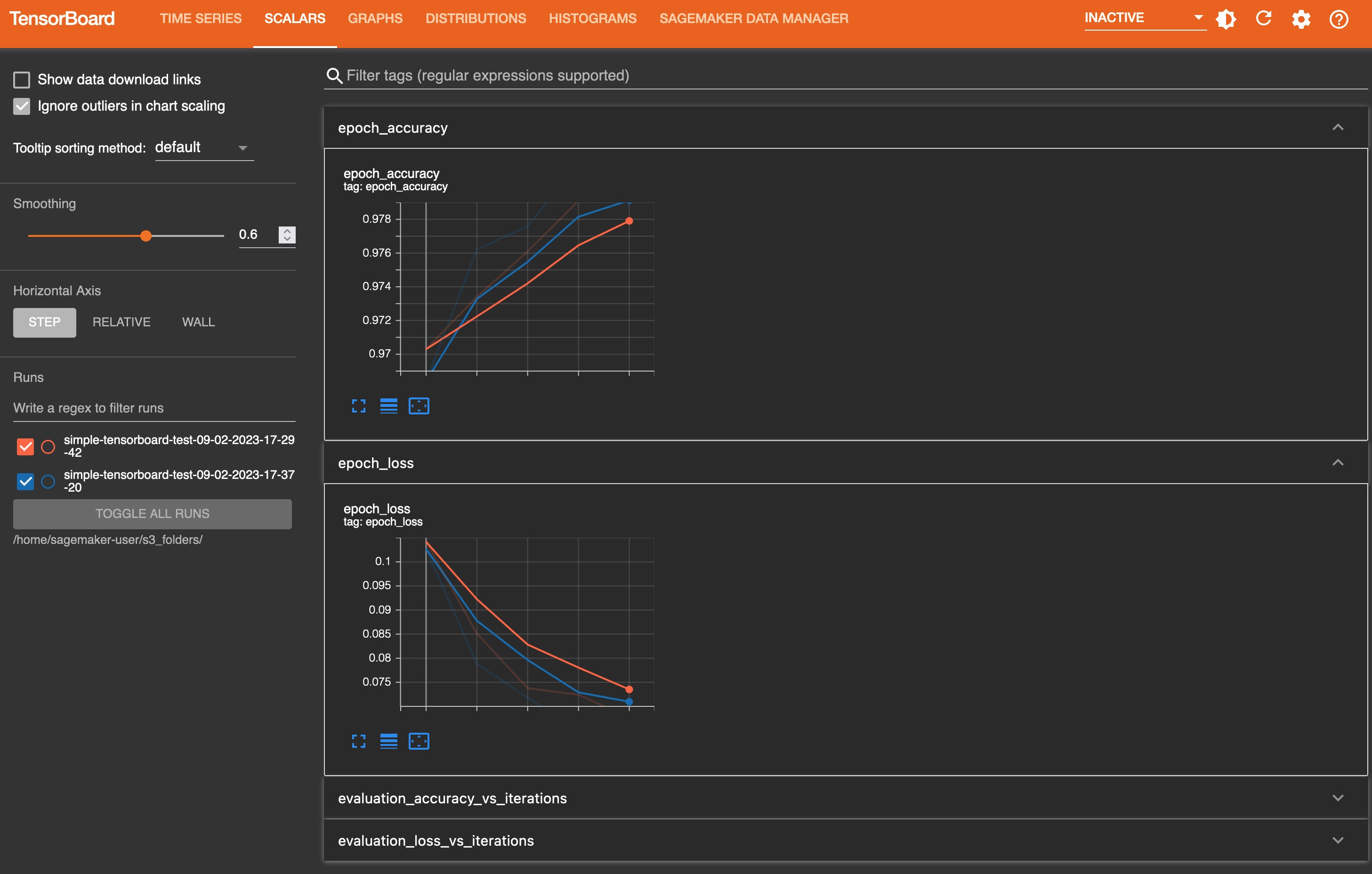
The following screenshot is the Graphs tab view.
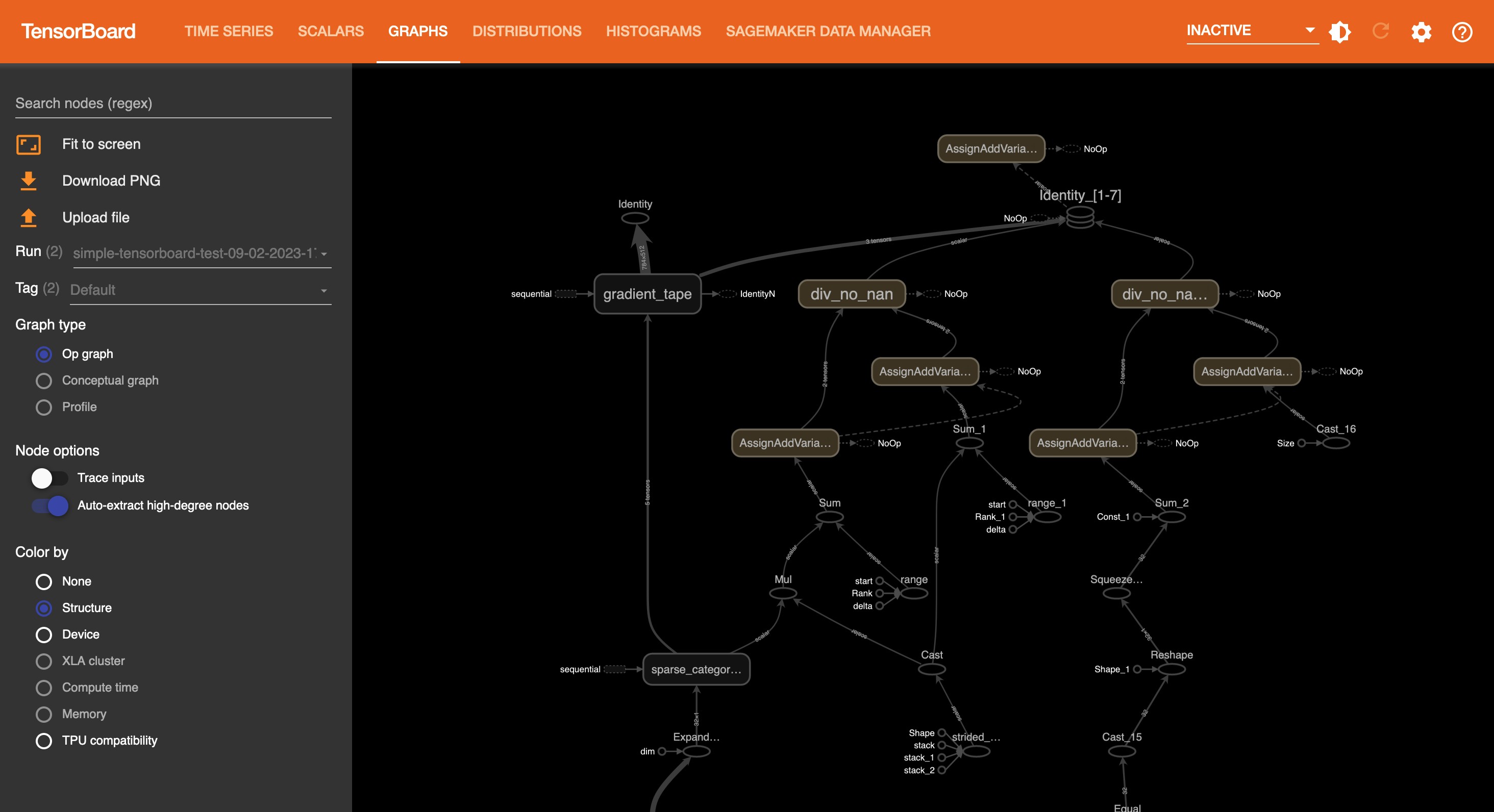
The following screenshot is the Distributions tab view.

The following screenshot is the Histograms tab view.
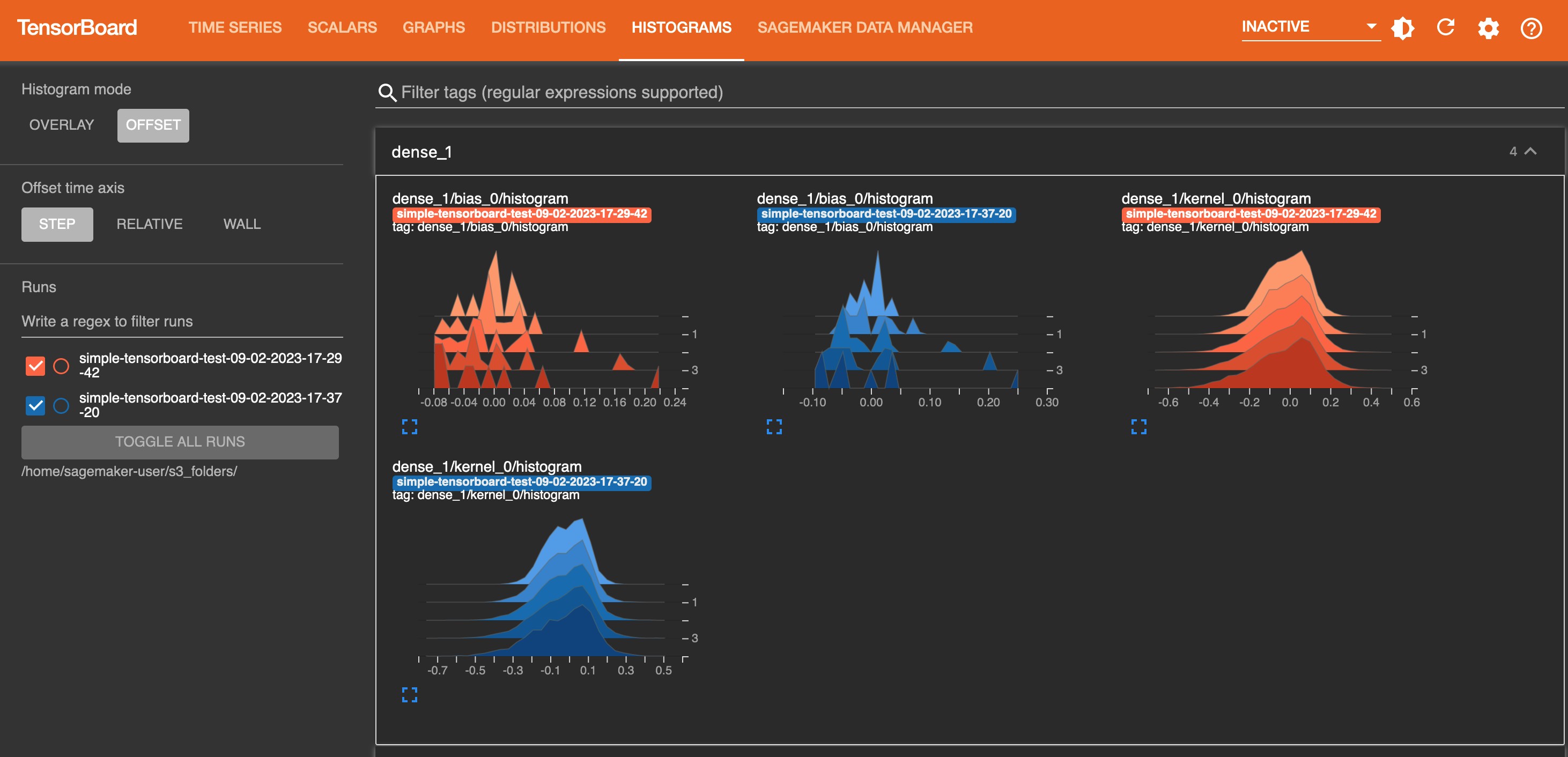
After you are done with monitoring and experimenting with jobs in TensorBoard, shut the TensorBoard application down:
A message should appear at the top of the page: “Default is being deleted”.
TensorBoard is a powerful tool for visualizing, analyzing, and debugging deep learning models. In this post, we provide a guide to using SageMaker with TensorBoard, including how to set up TensorBoard in a SageMaker training job using the SageMaker Python SDK, access SageMaker TensorBoard, explore training output data visualized in TensorBoard, and delete unused TensorBoard applications. By following these steps, you can start using TensorBoard in SageMaker for your work.
We encourage you to experiment with different features and techniques.
 Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family.
Dr. Baichuan Sun is a Senior Data Scientist at AWS AI/ML. He is passionate about solving strategic business problems with customers using data-driven methodology on the cloud, and he has been leading projects in challenging areas including robotics computer vision, time series forecasting, price optimization, predictive maintenance, pharmaceutical development, product recommendation system, etc. In his spare time he enjoys traveling and hanging out with family.
 Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.
Manoj Ravi is a Senior Product Manager for Amazon SageMaker. He is passionate about building next-gen AI products and works on software and tools to make large-scale machine learning easier for customers. He holds an MBA from Haas School of Business and a Masters in Information Systems Management from Carnegie Mellon University. In his spare time, Manoj enjoys playing tennis and pursuing landscape photography.


Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
danah boyd, a partner researcher at Microsoft Research, has been awarded MIT’s Morison Prize in Science, Technology, and Society, for outstanding work combining humanistic values with effectiveness in the world of practical affairs, particular in science and technology.
Dr. boyd, who is also a Distinguished Visiting Professor at Georgetown University, is currently conducting a multi-year ethnographic study of the U.S. census to understand how data are made legitimate. Her previous studies have focused on media manipulation, algorithmic bias, privacy practices, social media, and teen culture.
To learn more, see the Microsoft Research Summit presentation Statistical Imaginaries: An Ode to Responsible Data Science or the publications Differential Perspectives: Epistemic Disconnects Surrounding the U.S. Census Bureau’s Use of Differential Privacy.
Nicole Immorlica, a Senior Principal Researcher with Microsoft Research New England, has been awarded the 2023 SIGecom Test of Time Award for her work on a 2005 paper on matching markets. The award from the Association of Computing Machinery (ACM) recognizes “an influential paper or series of papers published between ten and twenty-five years ago that has significantly impacted research or applications exemplifying the interplay of economics and computation.”
In the award-winning paper: Marriage, honesty, and stability, Immorlica and a co-author explored centralized two-sided markets, such as the medical residency market, matching participants by running a stable marriage algorithm. While no matching mechanism based on a stable marriage algorithm can guarantee ‘truthfulness’ as a dominant strategy, the paper showed that in certain probabilistic settings, truthfulness is the best strategy for the participants.
Spotlight: On-Demand EVENT

On-Demand
Watch now to learn about some of the most pressing questions facing our research community and listen in on conversations with 120+ researchers around how to ensure new technologies have the broadest possible benefit for humanity.
Lorin Crawford, a principal researcher at Microsoft Research New England, has been named a 2023 COPSS Emerging Leader by the Committee of Presidents of Statistical Societies. The award announcement cited Crawford’s path-breaking research combining theory and methods of mathematics, statistics and computing to generate new knowledge and insight about the genetic basis of disease, and exceptional mentoring of students from multiple scientific disciplines.
The award recognizes the important role of early-career statistical scientists in shaping the future of their discipline. The selection criteria are designed to highlight contributions in areas not traditionally recognized by other early-career awards in the statistical sciences.
Crawford, who is also a faculty member at Brown University’s School of Public Health, focuses on developing novel and efficient algorithms that address complex problems in quantitative genetics, cancer pharmacology, molecular genomics, and geometric morphometrics.
A paper co-authored by two Microsoft researchers has received a 2023 Seoul Test of Time Award from the International World Wide Web Conference Committee (IW3C2). The 2020 paper: A Contextual-Bandit Approach to Personalized News Article Recommendation, was written by John Langford and Robert Schapire, along with two industry colleagues. The authors proposed a new approach for personalized recommendation using contextual bandit algorithms. According to the IW3C2, the paper now has more than 2,730 citations and has become foundational research in the area of recommendation systems.
The award announcement also states: “The paper addressed fundamental challenges in real-world recommendation systems via computationally efficient algorithms grounded in learning theory. It also showed that recommendation algorithms can be reliably evaluated offline, enabling algorithm selection without operational impact, and that contextual bandits can yield significant gains in user engagement.”
The dynamics of power grids are governed by a large number of nonlinear differential and algebraic equations (DAEs). To safely run the system, operators need to check that the states described by these DAEs stay within prescribed limits after various potential faults. However, current numerical solvers of DAEs are often too slow for real-time system operations. In addition, detailed system parameters are often not exactly known. Machine learning approaches have been proposed to reduce the computational efforts, but existing methods generally suffer from overfitting and failures to predict unstable behaviors.
In a new paper: A Frequency Domain Approach to Predict Power System Transients, Microsoft researchers propose a novel framework to predict power system transients by learning in the frequency domain. The intuition is that although the system behavior is complex in the time domain, relatively few dominant modes exist in the frequency domain. Therefore, the researchers learn to predict by constructing neural networks with Fourier transform and filtering layers. System topology and fault information are encoded by taking a multi-dimensional Fourier transform, allowing researchers to leverage the fact that the trajectories are sparse both in time and spatial frequencies. This research shows that the proposed approach does not need detailed system parameters, greatly speeds up prediction computations and is highly accurate for different fault types.
The growing use of large foundation models like GPT-3.5/4 for real-world applications has raised concerns about high deployment costs. While general methodologies such as quantization, pruning, compression, and distillation help reduce costs. At test time, output tokens must be decoded (sequentially) one by one, which poses significant challenges for LLMs to be deployed at scale.
In a new paper: Inference with Reference: Lossless Acceleration of Large Language Models, Microsoft researchers study accelerating LLM inference by improving the efficiency of autoregressive decoding. In multiple real-world applications, this research shows that an LLM’s output tokens often come from its context. For example, in a retrieval-augmented generation scenario for a search engine, an LLM’s context usually includes relevant documents retrieved from an external corpus as reference according to a query, and its output usually contains many text spans found in the reference (i.e., retrieved documents). Motivated by this observation, the researchers propose an LLM accelerator (LLMA) to losslessly speed inference with references. Its improved computational parallelism allows LLMA to achieve over 2x speed-up for LLMs, with identical generation results as greedy decoding, in many practical generation scenarios where significant overlap between in-context reference and outputs exists. The researchers are collaborating with the Bing search team to explore integrating this technique into snippet/caption generation, Bing chat, and other potential scenarios.
Quantum chemical calculations on atomistic systems have evolved into a standard approach to studying molecular matter. But these calculations often involve a significant amount of manual input and expertise. Most of these calculations could be automated, alleviating the need for expertise in software and hardware accessibility.
In a new paper: High-throughput ab initio reaction mechanism exploration in the cloud with automated multi-reference validation, researchers from Microsoft present the AutoRXN workflow, an automated workflow for exploratory high-throughput electronic structure calculations of molecular systems.
This workflow i) uses density functional theory methods to deliver minimum and transition-state structures and corresponding energies and properties, (ii) launches coupled cluster calculations for optimized structures to provide more accurate energy and property estimates, and (iii) evaluates multi-reference diagnostics to back check the coupled cluster results and subjects them to automated multi-configurational calculations for potential multi-configurational cases.
All calculations take place in a cloud environment and support massive computational campaigns. Key features of all components of the AutoRXN workflow are autonomy, stability, and minimum operator interference.
The paper was recently published in the Journal of Chemistry and Physics.
The post Research Focus: Week of May 8, 2023 appeared first on Microsoft Research.
*= Equal Contributors
Structured State Spaces for Sequences (S4) is a recently proposed sequence model with successful applications in various tasks, e.g., vision, language modeling, and audio. Thanks to its mathematical formulation, it compresses its input to a single hidden state and is able to capture long-range dependencies while avoiding the need for an attention mechanism. In this work, we apply S4 to Machine Translation (MT) and evaluate several encoder-decoder variants on WMT’14 and WMT’16. In contrast with the success in language modeling, we find that S4 lags behind the Transformer…Apple Machine Learning Research


For decades, researchers worked together to assemble a complete copy of the molecular instructions for a human — a map of the human genome. The first draft was finished in 2000, but with several missing pieces. Even when a complete reference genome was achieved in 2022, their work was not finished. A single reference genome can’t incorporate known genetic variations, such as the variants for the gene determining whether a person has a blood type A, B, AB or O. Furthermore, the reference genome didn’t represent the vast diversity of human ancestries, making it less useful for detecting disease or finding cures for people from some backgrounds than others. For the past three years, we have been part of an international collaboration with 119 scientists across 60 institutions, called the Human Pangenome Research Consortium, to address these challenges by creating a new and more representative map of the human genome, a pangenome.
We are excited to share that today, in “A draft human pangenome reference”, published in Nature, this group is announcing the completion of the first human pangenome reference. The pangenome combines 47 individual genome reference sequences and better represents the genomic diversity of global populations. Building on Google’s deep learning technologies and past advances in genomics, we used tools based on convolutional neural networks (CNNs) and transformers to tackle the challenges of building accurate pangenome sequences and using them for genome analysis. These contributions helped the consortium build an information-rich resource for geneticists, researchers and clinicians around the world.
 |
In the typical analysis workflow for high-throughput DNA sequencing, a sequencing instrument reads millions of short pieces of an individual’s genome, and a program called a mapper or aligner then estimates where those pieces best fit relative to the single, linear human reference sequence. Next, variant caller software identifies the unique parts of the individual’s sequence relative to the reference.
But because humans carry a diverse set of sequences, sections that are present in an individual’s DNA but are not in the reference genome can’t be analyzed. One study of 910 African individuals found that a total of 300 million DNA base pairs — 10% of the roughly three billion base pair reference genome — are not present in the previous linear reference but occur in at least one of the 910 individuals.
To address this issue, the consortium used graph data structures, which are powerful for genomics because they can represent the sequences of many people simultaneously, which is needed to create a pangenome. Nodes in a graph genome contain the known set of sequences in a population, and paths through those nodes compactly describe the unique sequences of an individual’s DNA.
 |
| Schematic of a graph genome. Each color represents the sequence path of a different individual. Multiple paths passing through the same node indicate multiple individuals share that sequence, but some paths also show a single nucleotide variant (SNV), insertions, or deletions. Illustration credit Darryl Leja, National Human Genome Research Institute (NHGRI). |
 |
| Actual graph genome for the major histocompatibility complex (MHC) region of the genome. Genes in MHC regions are essential to immune function and are associated with a person’s resistance and susceptibility to infectious disease and autoimmune disorders (e.g., ankylosing spondylitis and lupus). The graph shows the linear human genome reference (green) and different individual person’s sequence (gray). |
Using graphs creates numerous challenges. They require reference sequences to be highly accurate and the development of new methods that can use their data structure as an input. However, new sequencing technologies (such as consensus sequencing and phased assembly methods) have driven exciting progress towards solving these problems.
Long-read sequencing technology, which reads larger pieces of the genome (10,000 to millions of DNA characters long) at a time, are essential to the creation of high quality reference sequences because larger pieces can be stitched together into assembled genomes more easily than the short pieces read out by earlier technologies. Short read sequencing reads pieces of the genome that are only 100 to 300 DNA characters long, but has been the highly scalable basis for high-throughput sequencing methods developed in the 2000s. Though long-read sequencing is newer and has advantages for reference genome creation, many informatics methods for short reads hadn’t been developed for long read technologies.
Google initially developed DeepVariant, an open-source CNN variant caller framework that analyzes the short-read sequencing evidence of local regions of the genome. However, we were able to re-train DeepVariant to yield accurate analysis of Pacific Bioscience’s long-read data.
 |
| Training and evaluation schematic for DeepVariant. |
We next teamed up with researchers at the University of California, Santa Cruz (UCSC) Genomics Institute to participate in a United States Food and Drug Administration competition for another long-read sequencing technology from Oxford Nanopore. Together, we won the award for highest accuracy in the nanopore category, with a single nucleotide variants (SNVs) accuracy that matched short-read sequencing. This work has been used to detect and treat genetic diseases in critically ill newborns. The use of DeepVariant on long-read technologies provided the foundation for the consortium’s use of DeepVariant for error correction of pangenomes.
DeepVariant’s ability to use multiple long-read sequencing modalities proved useful for error correction in the Telomere-to-Telomere (T2T) Consortium’s effort that generated the first complete assembly of a human genome. Completing this first genome set the stage to build the multiple reference genomes required for pangenomes, and T2T was already working closely with the Human Pangenome Project (with many shared members) to scale those practices.
With a set of high-quality human reference genomes on the horizon, developing methods that could use those assemblies grew in importance. We worked to adapt DeepVariant to use the pangenome developed by the consortium. In partnership with UCSC, we built an end-to-end analysis workflow for graph-based variant detection, and demonstrated improved accuracy across several thousand samples. The use of the pangenome allows many previously missed variants to be correctly identified.
 |
| Visualization of variant calls in the KCNE1 gene (a gene with variants associated with cardiac arrhythmias and sudden death) using a pangenome reference versus the prior linear reference. Each dot represents a variant call that is either correct (blue dot), incorrect (green dot) — when a variant is identified but is not really there —or a missed variant call (red dot). The top box shows variant calls made by DeepVariant using the pangenome reference while the bottom shows variant calls made by using the linear reference. Figure adapted from A Draft Human Pangenome Reference. |
Just as new sequencing technologies enabled new pangenome approaches, new informatics technologies enabled improvements for sequencing methods. Google adapted transformer architectures from analysis of human language to genome sequences to develop DeepConsensus. A key enabler for this was the development of a differentiable loss function that could handle the insertions and deletions common in sequencing data. This enabled us to have high accuracy without needing a decoder, allowing the speed required to keep up with terabytes of sequencer output.
 |
| Transformer architecture for DeepConsensus. DeepConsensus takes as input the repeated sequence of the DNA molecule, measured from fluorescent light detected by the addition of each base. DeepConsensus also uses as input the more detailed information about the sequencing process, including the duration of the light pulse (referred to here as pulse width or PW), the time between pulses (IP) the signal-to-noise ratio (SN) and which side of the double helix is being measured (strand). |
 |
| Effect of alignment loss function in training evaluation of model output. Better accounting of insertions and deletions by a differentiable alignment function enables the model training process to better estimate errors. |
DeepConsensus improves the yield and accuracy of instrument data. Because PacBio sequencing provides the primary sequence information for the 47 genome assemblies, we could apply DeepConsensus to improve those assemblies. With application of DeepConsensus, consortium members built a genome assembler that was able to reach 99.9997% assembly base-level accuracies.
We developed multiple new approaches to improve genetic sequencing methods, which we then used to construct pangenome references that enable more robust genome analysis.
But this is just the beginning of the story. In the next stage, a larger, worldwide group of scientists and clinicians will use this pangenome reference to study genetic diseases and make new drugs. And future pangenomes will represent even more individuals, realizing a vision summarized this way in a recent Nature story: “Every base, everywhere, all at once.” Read our post on the Keyword Blog to learn more about the human pangenome reference announcement.
Many people were involved in creating the pangenome reference, including 119 authors across 60 organizations, with the Human Pangenome Reference Consortium. This blog post highlights Google’s contributions to the broader work. We thank the research groups at UCSC Genomics Institute (GI) under Professors Benedict Paten and Karen Miga, genome polishing efforts of Arang Rhie at National Institute of Health (NIH), Genome Assembly and Polishing of Adam Phillipy’s group, and the standards group at National Institute of Standards and Technology (NIST) of Justin Zook. We thank Google contributors: Pi-Chuan Chang, Maria Nattestad, Daniel Cook, Alexey Kolesnikov, Anastaysia Belyaeva, and Gunjan Baid. We thank Lizzie Dorfman, Elise Kleeman, Erika Hayden, Cory McLean, Shravya Shetty, Greg Corrado, Katherine Chou, and Yossi Matias for their support, coordination, and leadership. Last but not least, thanks to the research participants that provided their DNA to help build the pangenome resource.
Amazon SageMaker provides a broad selection of machine learning (ML) infrastructure and model deployment options to help meet your ML inference needs. It’s a fully-managed service and integrates with MLOps tools so you can work to scale your model deployment, reduce inference costs, manage models more effectively in production, and reduce operational burden. SageMaker provides multiple inference options so you can pick the option that best suits your workload.
New generations of CPUs offer a significant performance improvement in ML inference due to specialized built-in instructions. In this post, we focus on how you can take advantage of the AWS Graviton3-based Amazon Elastic Compute Cloud (EC2) C7g instances to help reduce inference costs by up to 50% relative to comparable EC2 instances for real-time inference on Amazon SageMaker. We show how you can evaluate the inference performance and switch your ML workloads to AWS Graviton instances in just a few steps.
To cover the popular and broad range of customer applications, in this post we discuss the inference performance of PyTorch, TensorFlow, XGBoost, and scikit-learn frameworks. We cover computer vision (CV), natural language processing (NLP), classification, and ranking scenarios for models and ml.c6g, ml.c7g, ml.c5, and ml.c6i SageMaker instances for benchmarking.
AWS measured up to 50% cost savings for PyTorch, TensorFlow, XGBoost, and scikit-learn model inference with AWS Graviton3-based EC2 C7g instances relative to comparable EC2 instances on Amazon SageMaker. At the same time, the latency of inference is also reduced.
For comparison, we used four different instance types:
All four instances have 16 vCPUs and 32 GiB of memory.
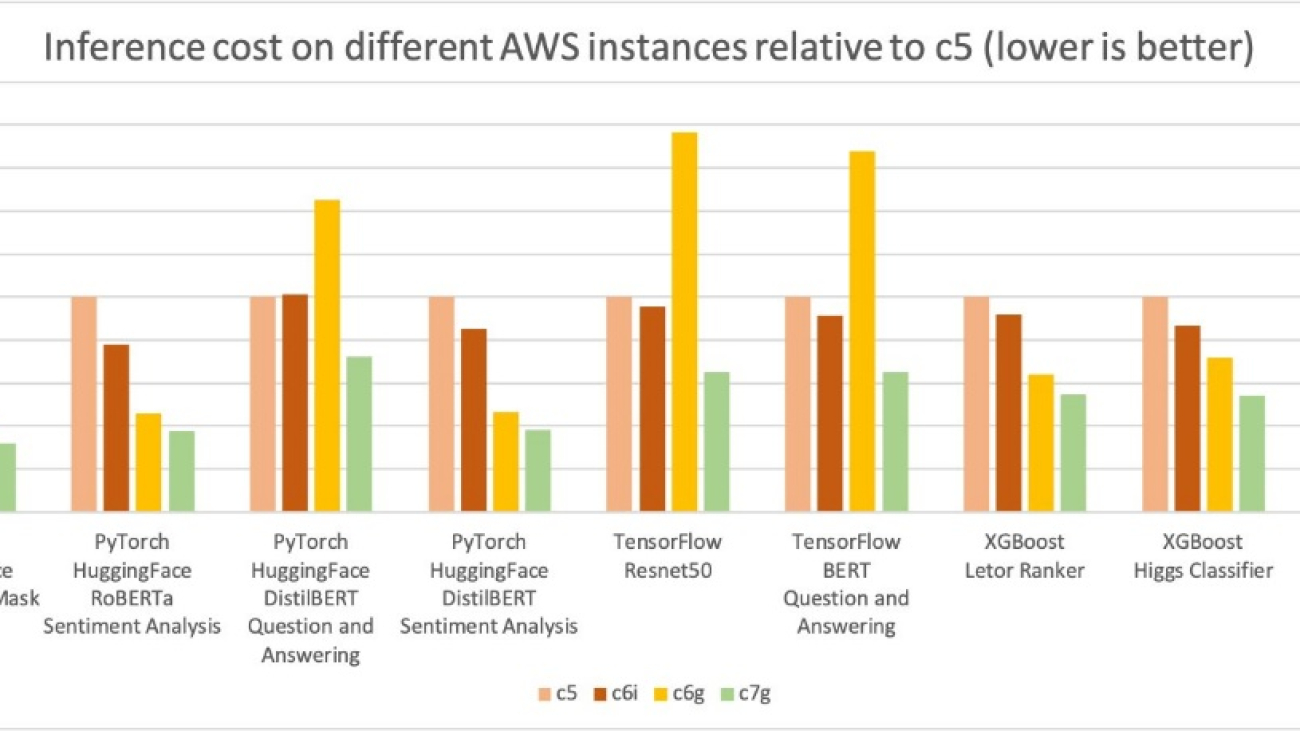
In the following graph, we measured the cost per million inference for the four instance types. We further normalized the cost per million inference results to a c5.4xlarge instance, which is measured as 1 on the Y-axis of the chart. You can see that for the XGBoost models, cost per million inference for c7g.4xlarge (AWS Graviton3) is about 50% of the c5.4xlarge and 40% of c6i.4xlarge; for the PyTorch NLP models, the cost savings is about 30–50% compared to c5 and c6i.4xlarge instances. For other models and frameworks, we measured at least 30% cost savings compared to c5 and c6i.4xlarge instances.

Similar to the preceding inference cost comparison graph, the following graph shows the model p90 latency for the same four instance types. We further normalized the latency results to the c5.4xlarge instance, which is measured as 1 in the Y-axis of the chart. The c7g.4xlarge (AWS Graviton3) model inference latency is up to 50% better than the latencies measured on c5.4xlarge and c6i.4xlarge.

To deploy your models to AWS Graviton instances, you can either use AWS Deep Learning Containers (DLCs) or bring your own containers that are compatible with the ARMv8.2 architecture.
The migration (or new deployment) of your models to AWS Graviton instances is straightforward because not only does AWS provide containers to host models with PyTorch, TensorFlow, scikit-learn, and XGBoost, but the models are architecturally agnostic as well. You can also bring your own libraries, but be sure that your container is built with an environment that supports the ARMv8.2 architecture. For more information, see Building your own algorithm container.
You will need to complete three steps in order to deploy your model:
For detailed instructions, refer to Run machine learning inference workloads on AWS Graviton-based instances with Amazon SageMaker
We used Amazon SageMaker Inference Recommender to automate performance benchmarking across different instances. This service compares the performance of your ML model in terms of latency and cost on different instances and recommends the instance and configuration that gives the best performance for the lowest cost. We have collected the aforementioned performance data using Inference Recommender. For more details, refer to the GitHub repo.
You can use the sample notebook to run the benchmarks and reproduce the results. We used the following models for benchmarking:
AWS measured up to 50% cost savings for PyTorch, TensorFlow, XGBoost, and scikit-learn model inference with AWS Graviton3-based EC2 C7g instances relative to comparable EC2 instances on Amazon SageMaker. You can migrate your existing inference use cases or deploy new ML models on AWS Graviton by following the steps provided in this post. You can also refer to the AWS Graviton Technical Guide, which provides the list of optimized libraries and best practices that will help you achieve cost benefits with AWS Graviton instances across different workloads.
If you find use cases where similar performance gains are not observed on AWS Graviton, please reach out us. We will continue to add more performance improvements to make AWS Graviton the most cost-effective and efficient general-purpose processor for ML inference.
 Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for machine learning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for machine learning, HPC, and multimedia workloads. She is passionate about open-source development and delivering cost-effective software solutions with Arm SoCs.
 Jaymin Desai is a Software Development Engineer with the Amazon SageMaker Inference team. He is passionate about taking AI to the masses and improving the usability of state-of-the-art AI assets by productizing them into features and services. In his free time, he enjoys exploring music and traveling.
Jaymin Desai is a Software Development Engineer with the Amazon SageMaker Inference team. He is passionate about taking AI to the masses and improving the usability of state-of-the-art AI assets by productizing them into features and services. In his free time, he enjoys exploring music and traveling.
 Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
Mike Schneider is a Systems Developer, based in Phoenix AZ. He is a member of Deep Learning containers, supporting various Framework container images, to include Graviton Inference. He is dedicated to infrastructure efficiency and stability.
 Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
Mohan Gandhi is a Senior Software Engineer at AWS. He has been with AWS for the last 10 years and has worked on various AWS services like EMR, EFA and RDS. Currently, he is focused on improving the SageMaker Inference Experience. In his spare time, he enjoys hiking and marathons.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Wayne Toh is a Specialist Solutions Architect for Graviton at AWS. He focuses on helping customers adopt ARM architecture for large scale container workloads. Prior to joining AWS, Wayne worked for several large software vendors, including IBM and Red Hat.
Wayne Toh is a Specialist Solutions Architect for Graviton at AWS. He focuses on helping customers adopt ARM architecture for large scale container workloads. Prior to joining AWS, Wayne worked for several large software vendors, including IBM and Red Hat.
 Lauren Mullennex is a Solutions Architect based in Denver, CO. She works with customers to help them architect solutions on AWS. In her spare time, she enjoys hiking and cooking Hawaiian cuisine.
Lauren Mullennex is a Solutions Architect based in Denver, CO. She works with customers to help them architect solutions on AWS. In her spare time, she enjoys hiking and cooking Hawaiian cuisine.
The new development process behind Amazon Web Services’ Cedar authorization-policy language.Read More
This is a guest post co-written with Trey Robinson, CTO at Sleepme Inc.
Sleepme is an industry leader in sleep temperature management and monitoring products, including an Internet of Things (IoT) enabled sleep tracking sensor suite equipped with heart rate, respiration rate, bed and ambient temperature, humidity, and pressure sensors.
Sleepme offers a smart mattress topper system that can be scheduled to cool or heat your bed using the companion application. The system can be paired with a sleep tracker that gathers insights such as heart rate, respiration rate, humidity in the room, wake up times, and when the user was in and out of bed. At the end of a given sleep session, it will aggregate sleep tracker insights, along with sleep stage data, to produce a sleep quality score.
This smart mattress topper works like a thermostat for your bed and gives customers control of their sleep climate. Sleepme products help you cool your body temperature, which is linked with falling into a deep sleep, while being hot can reduce the likelihood of falling and staying asleep.
In this post, we share how Sleepme used Amazon SageMaker to developed a machine learning (ML) model proof of concept that recommends temperatures to maximize your sleep score.
“The adoption of AI opens new avenues to improve customers’ sleeping experience. These changes will be implemented in the Sleepme product line, allowing the client to leverage the technical and marketing value of the new features during deployment.”
– Trey Robinson, Chief Technology Officer of Sleepme.
Sleepme is a science-driven organization that uses scientific studies, international journals, and cutting-edge research to bring customers the latest in sleep health and wellness. Sleepme provides sleep science information on their website.
Sleepme discusses how only 44% of Americans report a restful night’s sleep almost every night, and that 35% of adults sleep less than 7 hours per night. Getting a full night’s sleep helps you feel more energized and has proven benefits to your mind, weight, and heart. This represents a huge population of people with opportunities to improve their sleep and health.
Sleepme saw an opportunity to improve the sleep of their users by changing the user’s sleep environment during the night. By capturing environment data like temperature and humidity and connecting it with personalized user data like restlessness, heart rate, and sleep cycle, Sleepme determined they were able to change the user’s environment to optimize their rest. This use case demanded an ML model that served real-time inference.
Sleepme needed a highly available inference model that provides low-latency recommendations. With a focus on delivering new features and products for their customers, Sleepme needed an out-of-the-box solution that doesn’t require infrastructure management.
To address these challenges, Sleepme turned to Amazon SageMaker.
SageMaker accelerates the deployment of ML workloads by simplifying the ML build process. It provides a set of ML capabilities that run on a managed infrastructure on AWS. This reduces the operational overhead and complexity associated with ML development.
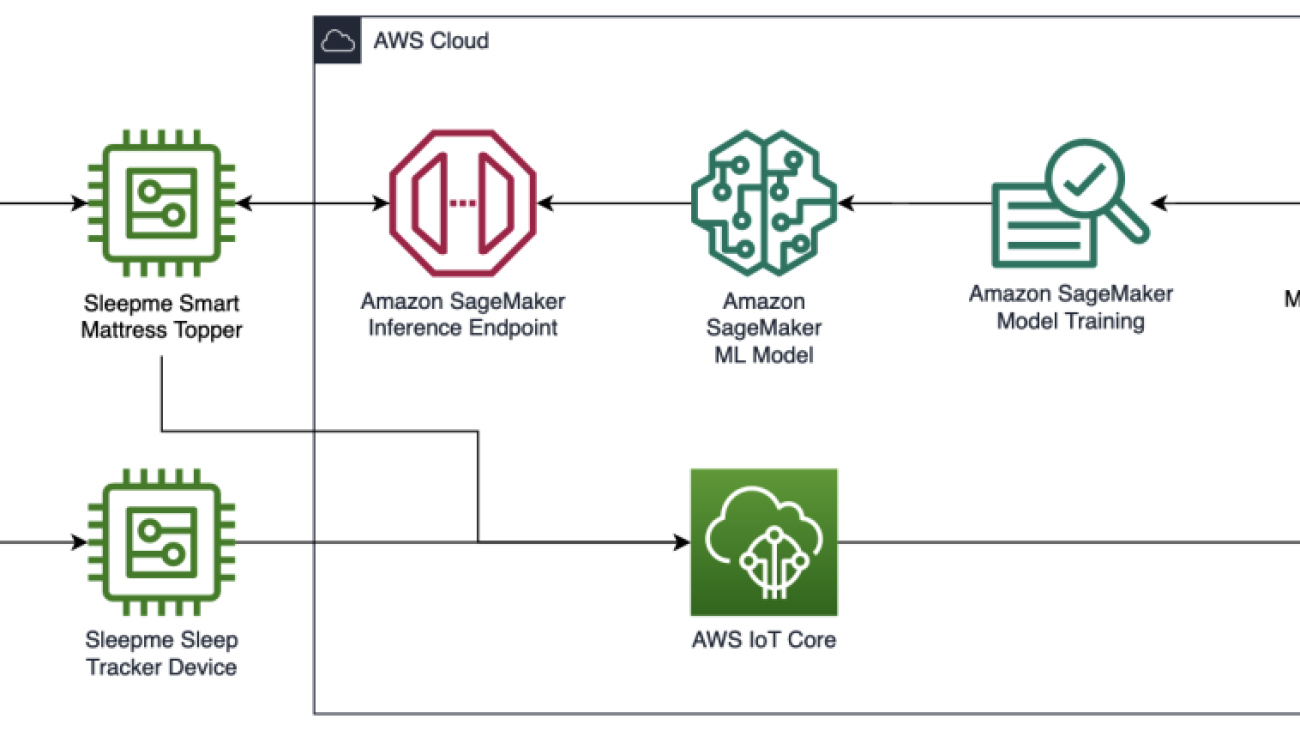
Sleepme chose SageMaker because of the capabilities it provides in model training, endpoint deployment process, and infrastructure management. The following diagram illustrates their AWS architecture.

Sleepme is focused on delivering new products and features for their customers. They didn’t want to dedicate their resources to a lengthy ML model training process.
SageMaker’s Model Training allowed Sleepme to use their historical data to quickly develop a proprietary machine learning model. SageMaker Model Training provides dozens of built-in training algorithms and hundreds of pre-trained models, increasing Sleepme’s agility in model creation. By managing the underlying compute instances, SageMaker Model Training enabled Sleepme to focus on enhancing model performance.
This ML model needed to make sleep environment adjustments in real time. To achieve this, Sleepme used a SageMaker Real-time inference to manage the hosting of their model. This endpoint receives data from Sleepme’s smart mattress topper and sleep tracker to make a temperature recommendation for the user’s sleep in real time. Additionally, with the option for automatic scaling of models, SageMaker inference offered Sleepme the option to add or remove instances to meet demand.
SageMaker also provides Sleepme with useful features as their workload evolves. They could use shadow tests to evaluate model performance of new versions before they are deployed to customers, SakeMaker Model Registry to manage model versions and automate model deployment, and SageMaker Model Monitoring to monitor the quality of their model in production. These features provide Sleepme with the opportunity to take their ML use cases to next level, without developing new capabilities on their own.
With Amazon SageMaker, Sleepme was able to build and deploy a custom ML model in a matter of weeks that identifies the recommended temperature adjustment, which the Sleepme devices mirror to the user’s environment.
Sleepme IoT devices capture sleep data and can now make adjustments to a customer’s bed in minutes. This capability proved to be a business differentiator. Now, users sleep can be optimized to provide a higher-quality sleep in real time.
To learn more about how you can quickly build ML models, refer to the Train Models or get started on the SageMaker Console.
 Trey Robinson has been a mobile and IoT-focused software engineer leading teams as the CTO of Sleepme Inc and Director of Engineering at Passport Inc. He has worked on dozens of mobile apps, backends, and IoT projects over the years. Before moving to Charlotte, NC, Trey grew up in Ninety Six, South Carolina, and studied Computer Science at Clemson University.
Trey Robinson has been a mobile and IoT-focused software engineer leading teams as the CTO of Sleepme Inc and Director of Engineering at Passport Inc. He has worked on dozens of mobile apps, backends, and IoT projects over the years. Before moving to Charlotte, NC, Trey grew up in Ninety Six, South Carolina, and studied Computer Science at Clemson University.
 Benon Boyadjian is a Solutions Architect in the Private Equity group at Amazon Web Services. Benon works directly with Private Equity Firms and their portfolio companies, helping them leverage AWS to achieve business objectives and increase enterprise value.
Benon Boyadjian is a Solutions Architect in the Private Equity group at Amazon Web Services. Benon works directly with Private Equity Firms and their portfolio companies, helping them leverage AWS to achieve business objectives and increase enterprise value.