Training on pseudo-labeled data limits the consequences of slight input variations and prevents updated models from backsliding on particular tasks.Read More
A policy agenda for responsible AI progress: Opportunity, Responsibility, Security
 For society to reap the benefits of AI, opportunity, responsibility, and national security strategies must be baked into that shared AI agenda.Read More
For society to reap the benefits of AI, opportunity, responsibility, and national security strategies must be baked into that shared AI agenda.Read More

Sparse video tubes for joint video and image vision transformers
Video understanding is a challenging problem that requires reasoning about both spatial information (e.g., for objects in a scene, including their locations and relations) and temporal information for activities or events shown in a video. There are many video understanding applications and tasks, such as understanding the semantic content of web videos and robot perception. However, current works, such as ViViT and TimeSFormer, densely process the video and require significant compute, especially as model size plus video length and resolution increase.
In “Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning”, to be presented at CVPR 2023, we introduce a simple technique that turns a Vision Transformer (ViT) model image encoder into an efficient video backbone using sparse video tubes (learnable visual representations of samples from the video) to reduce the model’s compute needs. This approach can seamlessly process both images and videos, which allows it to leverage both image and video data sources during training. This training further enables our sparse tubes ViT model to coalesce image and video backbones together to serve a dual role as either an image or video backbone (or both), depending on the input. We demonstrate that this model is scalable, can be adapted to large pre-trained ViTs without requiring full fine-tuning, and achieves state-of-the-art results across many video classification benchmarks.
 |
| Using sparse video tubes to sample a video, combined with a standard ViT encoder, leads to an efficient visual representation that can be seamlessly shared with image inputs. |
Building a joint image-video backbone
Our sparse tube ViT uses a standard ViT backbone, consisting of a stack of Transformer layers, that processes video information. Previous methods, such as ViViT, densely tokenize the video and then apply factorized attention, i.e., the attention weights for each token are computed separately for the temporal and spatial dimensions. In the standard ViT architecture, self-attention is computed over the whole token sequence. When using videos as input, token sequences become quite long, which can make this computation slow. Instead, in the method we propose, the video is sparsely sampled using video tubes, which are 3D learnable visual representations of various shapes and sizes (described in more detail below) from the video. These tubes are used to sparsely sample the video using a large temporal stride, i.e., when a tube kernel is only applied to a few locations in the video, rather than every pixel.
By sparsely sampling the video tubes, we can use the same global self-attention module, rather than factorized attention like ViViT. We experimentally show that the addition of factorized attention layers can harm the performance due to the uninitialized weights. This single stack of transformer layers in the ViT backbone also enables better sharing of the weights and improves performance. Sparse video tube sampling is done by using a large spatial and temporal stride that selects tokens on a fixed grid. The large stride reduces the number of tokens in the full network, while still capturing both spatial and temporal information and enabling the efficient processing of all tokens.
Sparse video tubes
Video tubes are 3D grid-based cuboids that can have different shapes or categories and capture different information with strides and starting locations that can overlap. In the model, we use three distinct tube shapes that capture: (1) only spatial information (resulting in a set of 2D image patches), (2) long temporal information (over a small spatial area), and (3) both spatial and temporal information equally. Tubes that capture only spatial information can be applied to both image and video inputs. Tubes that capture long temporal information or both temporal and spatial information equally are only applied to video inputs. Depending on the input video size, the three tube shapes are applied to the model multiple times to generate tokens.
A fixed position embedding, which captures the global location of each tube (including any strides, offsets, etc.) relative to all the other tubes, is applied to the video tubes. Different from the previous learned position embeddings, this fixed one better enables sparse, overlapping sampling. Capturing the global location of the tube helps the model know where each came from, which is especially helpful when tubes overlap or are sampled from distant video locations. Next, the tube features are concatenated together to form a set of N tokens. These tokens are processed by a standard ViT encoder. Finally, we apply an attention pooling to compress all the tokens into a single representation and input to a fully connected (FC) layer to make the classification (e.g., playing soccer, swimming, etc.).
 |
| Our video ViT model works by sampling sparse video tubes from the video (shown at the bottom) to enable either or both image or video inputs to be seamlessly processed. These tubes have different shapes and capture different video features. Tube 1 (yellow) only captures spatial information, resulting in a set of 2D patches that can be applied to image inputs. Tube 2 (red) captures temporal information and some spatial information and tube 3 (green) equally captures both temporal and spatial information (i.e., the spatial size of the tube x and y are the same as the number of frames t). Tubes 2 and 3 can only be applied to video inputs. The position embedding is added to all the tube features. |
Scaling video ViTs
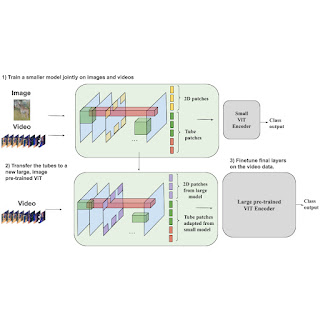
The process of building video backbones is computationally intensive, but our sparse tube ViT model enables computationally efficient scaling of video models, leveraging previously trained image backbones. Since image backbones can be adapted to a video backbone, large image backbones can be turned into large video backbones. More specifically, one can transfer the learned video feature representations from a small tube ViT to a large pre-trained image ViT and train the resulting model with video data for only a few steps, as opposed to a full training from scratch.
 |
| Our approach enables scaling a sparse tube ViT in a more efficient way. Specifically, the video features from a small video ViT (top network) can be transferred to a large, pre-trained image ViT (bottom network), and further fine-tuned. This requires fewer training steps to achieve strong performance with the large model. This is beneficial as large video models might be prohibitively expensive to train from scratch. |
Results
We evaluate our sparse tube ViT approach using Kinetics-400 (shown below), Kinetics-600 and Kinetics-700 datasets and compare its performance to a long list of prior methods. We find that our approach outperforms all prior methods. Importantly, it outperforms all state-of-the-art methods trained jointly on image+video datasets.
 |
| Performance compared to several prior works on the popular Kinetics-400 video dataset. Our sparse tube ViT outperforms state-of-the-art methods. |
Furthermore, we test our sparse tube ViT model on the Something-Something V2 dataset, which is commonly used to evaluate more dynamic activities, and also report that it outperforms all prior state-of-the-art approaches.
 |
| Performance on the Something-Something V2 video dataset. |
Visualizing some learned kernels
It is interesting to understand what kind of rudimentary features are being learned by the proposed model. We visualize them below, showing both the 2D patches, which are shared for both images and videos, and video tubes. These visualizations show the 2D or 3D information being captured by the projection layer. For example, in the 2D patches, various common features, like edges and colors, are detected, while the 3D tubes capture basic shapes and how they may change over time.
 |
| Visualizations of patches and tubes learned the sparse tube ViT model. Top row are the 2D patches and the remaining two rows are snapshots from the learned video tubes. The tubes show each patch for the 8 or 4 frames to which they are applied. |
Conclusions
We have presented a new sparse tube ViT, which can turn a ViT encoder into an efficient video model, and can seamlessly work with both image and video inputs. We also showed that large video encoders can be bootstrapped from small video encoders and image-only ViTs. Our approach outperforms prior methods across several popular video understanding benchmarks. We believe that this simple representation can facilitate much more efficient learning with input videos, seamlessly incorporate either image or video inputs and effectively eliminate the bifurcation of image and video models for future multimodal understanding.
Acknowledgements
This work is conducted by AJ Piergiovanni, Weicheng Kuo and Anelia Angelova, who are now at Google DeepMind. We thank Abhijit Ogale, Luowei Zhou, Claire Cui and our colleagues in Google Research for their helpful discussions, comments, and support.

Announcing the updated Microsoft SharePoint connector (V2.0) for Amazon Kendra
Amazon Kendra is a highly accurate and simple-to-use intelligent search service powered by machine learning (ML). Amazon Kendra offers a suite of data source connectors to simplify the process of ingesting and indexing your content, wherever it resides.
Valuable data in organizations is stored in both structured and unstructured repositories. Amazon Kendra can pull together data across several structured and unstructured knowledge base repositories to index and search on.
One such knowledge base repository is Microsoft SharePoint, and we are excited to announce that we have updated the SharePoint connector for Amazon Kendra to add even more capabilities. In this new version (V2.0), we have added support for SharePoint Subscription Edition and multiple authentication and sync modes to index contents based on new, modified, or deleted contents.
You can now also choose OAuth 2.0 to authenticate with SharePoint Online. Multiple synchronization options are available to update your index when your data source content changes. You can filter the search results based on the user and group information to ensure your search results are only shown based on user access rights.
In this post, we demonstrate how to index content from SharePoint using the Amazon Kendra SharePoint connector V2.0.
Solution overview
You can use Amazon Kendra as a central location to index the content provided by various data sources for intelligent search. In the following sections, we go through the steps to create an index, add the SharePoint connector, and test the solution.
Prerequisites
To get started, you need the following:
- A SharePoint (Server or Online) user with owner rights.
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Basic knowledge of AWS.
Create an Amazon Kendra Index
To create an Amazon Kendra index, complete the following steps:
- On the Amazon Kendra console, choose Create an index.

- For Index name, enter a name for the index (for example,
my-sharepoint-index). - Enter an optional description.
- Choose Create a new role.
- For Role name, enter an IAM role name.
- Configure optional encryption settings and tags.
- Choose Next.

- For Access control settings, choose Yes.
- For Token configuration, set Token type to JSON and leave the default values for Username and Groups.
- For User-group expansion, leave the defaults.
- Choose Next.

- For Specify provisioning, select Developer edition, which is suited for building a proof of concept and experimentation, and choose Create.

Add a SharePoint data source to your Amazon Kendra index
One of the advantages of implementing Amazon Kendra is that you can use a set of pre-built connectors for data sources such as Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), SharePoint Online, and Salesforce.
To add a SharePoint data source to your index, complete the following steps:
- On the Amazon Kendra console, navigate to the index that you created.
- Choose Data sources in the navigation pane.
- Under SharePoint Connector V2.0, choose Add connector.

- For Data source name, enter a name (for example,
my-sharepoint-data-source). - Enter an optional description.
- Choose English (en) for Default language.
- Enter optional tags.
- Choose Next.

Depending on the hosting option your SharePoint application is using, pick the appropriate hosting method. The required attributes for the connector configuration appear based on the hosting method you choose.
- If you select SharePoint Online, complete the following steps:
- Enter the URL for your SharePoint Online repository.

- Choose your authentication option (these authentication details will be used by the SharePoint connector to integrate with your SharePoint application).
- Enter the tenant ID of your SharePoint Online application.
- For AWS Secrets Manager secret, pick the secret that has SharePoint Online application credentials or create a new secret and add the connection details (for example,
AmazonKendra-SharePoint-my-sharepoint-online-secret).
- Enter the URL for your SharePoint Online repository.
To learn more about AWS Secrets Manger, refer to Getting started with Secrets Manager.
The SharePoint connector uses the clientId, clientSecret, userName, and password information to authenticate with the SharePoint Online application. These details can be accessed on the App registrations page on the Azure portal, if the SharePoint Online application is already registered.

- If you select SharePoint Server, complete the following steps:
- Choose your SharePoint version (for example, we use SharePoint 2019 for this post).
- Enter the site URL for your SharePoint Server repository.
- For SSL certificate location, enter the path to the S3 bucket file where the SharePoint Server SSL certificate is located.

- Enter the web proxy host name and the port number details if the SharePoint server requires a proxy connection.
For this post, no web proxy is used because the SharePoint application used for this example is a public-facing application.
-
- Select the authorization option for the Access Control List (ACL) configuration.

- Select the authorization option for the Access Control List (ACL) configuration.
These authentication details will be used by the SharePoint connector to integrate with your SharePoint instance.
- For AWS Secrets Manager secret, choose the secret that has SharePoint Server credentials or create a new secret and add the connection details (for example,
AmazonKendra-my-sharepoint-server-secret).
The SharePoint connector uses the user name and password information to authenticate with the SharePoint Server application. If you use an email ID with domain form IDP as the ACL setting, the LDAP server endpoint, search base, LDAP user name, and LDAP password are also required.
To achieve a granular level of control over the searchable and displayable content, identity crawler functionality is introduced in the SharePoint connector V2.0.
- Enable the identity crawler and select Crawl Local Group Mapping and Crawl AD Group Mapping.

- For Virtual Private Cloud (VPC), choose the VPC through which the SharePoint application is reachable from your SharePoint connector.
For this post, we choose No VPC because the SharePoint application used for this example is a public-facing application deployed on Amazon Elastic Compute Cloud (Amazon EC2) instances.
- Chose Create a new role (Recommended) and provide a role name, such as
AmazonKendra-sharepoint-v2. - Choose Next.

- Select entities that you would like to include for indexing. You can choose All or specific entities based on your use case. For this post, we choose All.
You can also include or exclude documents by using regular expressions. You can define patterns that Amazon Kendra either uses to exclude certain documents from indexing or include only documents with that pattern. For more information, refer to SharePoint Configuration.
- Select your sync mode to update the index when your data source content changes.
You can sync and index all contents in all entities, regardless of the previous sync process by selecting Full sync, or only sync new, modified, or deleted content, or only sync new or modified content. For this post, we select Full sync.
- Choose a frequency to run the sync schedule, such as Run on demand.
- Choose Next.

In this next step, you can create field mappings to add an extra layer of metadata to your documents. This enables you to improve accuracy through manual tuning, filtering, and faceting.
- Review the default field mappings information and choose Next.

- As a last step, review the configuration details and choose Add data source to create the SharePoint connector data source for the Amazon Kendra index.
Test the solution
Now you’re ready to prepare and test the Amazon Kendra search features using the SharePoint connector.
For this post, AWS getting started documents are added to the SharePoint data source. The sample dataset used for this post can be downloaded from AWS_Whitepapers.zip. This dataset has PDF documents categorized into multiple directories based on the type of documents (for example, documents related to AWS database options, security, and ML).
Also, sample dataset directories in SharePoint are configured with user email IDs and group details so that only the users and groups with permissions can access specific directories or individual files.
To achieve granular-level control over the search results, the SharePoint connector crawls the local or Active Directory (AD) group mapping in the SharePoint data source in addition to the content when the identity crawler is enabled with the local and AD group mapping options selected. With this capability, Amazon Kendra indexed content is searchable and displayable based on the access control permissions of the users and groups.
To sync our index with SharePoint content, complete the following steps:
- On the Amazon Kendra console, navigate to the index you created.
- Choose Data sources in the navigation pane and select the SharePoint data source.
- Choose Sync now to start the process to index the content from the SharePoint application and wait for the process to complete.
If you encounter any sync issues, refer to Troubleshooting data sources for more information.
When the sync process is successful, the value for Last sync status will be set to Successful – service is operating normally. The content from the SharePoint application is now indexed and ready for queries.
- Choose Search indexed content (under Data management) in the navigation pane.

- Enter a test query in the search field and press Enter.
A test query such as “What is the durability of S3?” provides the following Amazon Kendra suggested answers. Note that the results for this query are from all the indexed content. This is because there is no context of user name or group information for this query.
- To test the access-controlled search, expand Test query with username or groups and choose Apply user name or groups to add a user name (email ID) or group information.

When an Experience Builder app is used, it includes the user context, and therefore you don’t need to add user or group IDs explicitly.
- For this post, access to the Databases directory in the SharePoint site is provided to the database-specialists group only.

- Enter a new test query and press Enter.
In this example, only the content in the Databases directory is searched and the results are displayed. This is because the database-specialists group only has access to the Databases directory.
Congratulations! You have successfully used Amazon Kendra to surface answers and insights based on the content indexed from your SharePoint application.
Amazon Kendra Experience Builder
You can build and deploy an Amazon Kendra search application without the need for any front-end code. Amazon Kendra Experience Builder helps you build and deploy a fully functional search application in a few clicks so that you can start searching right away.
Refer to Building a search experience with no code for more information.
Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it if you no longer need it. If you only added a new data source using the Amazon Kendra connector for SharePoint, delete that data source after your solution review is completed.
Refer to Deleting an index and data source for more information.
Conclusion
In this post, we showed how to ingest documents from your SharePoint application into your Amazon Kendra index. We also reviewed some of the new features that are introduced in the new version of the SharePoint connector.
To learn more about the Amazon Kendra connector for SharePoint, refer to Microsoft SharePoint connector V2.0.
Finally, don’t forget to check out the other blog posts about Amazon Kendra!
About the Author
 Udaya Jaladi is a Solutions Architect at Amazon Web Services (AWS), specializing in assisting Independent Software Vendor (ISV) customers. With expertise in cloud strategies, AI/ML technologies, and operations, Udaya serves as a trusted advisor to executives and engineers, offering personalized guidance on maximizing the cloud’s potential and driving innovative product development. Leveraging his background as an Enterprise Architect (EA) across diverse business domains, Udaya excels in architecting scalable cloud solutions tailored to meet the specific needs of ISV customers.
Udaya Jaladi is a Solutions Architect at Amazon Web Services (AWS), specializing in assisting Independent Software Vendor (ISV) customers. With expertise in cloud strategies, AI/ML technologies, and operations, Udaya serves as a trusted advisor to executives and engineers, offering personalized guidance on maximizing the cloud’s potential and driving innovative product development. Leveraging his background as an Enterprise Architect (EA) across diverse business domains, Udaya excels in architecting scalable cloud solutions tailored to meet the specific needs of ISV customers.

Responsible AI at Google Research: PAIR

PAIR (People + AI Research) first launched in 2017 with the belief that “AI can go much further — and be more useful to all of us — if we build systems with people in mind at the start of the process.” We continue to focus on making AI more understandable, interpretable, fun, and usable by more people around the world. It’s a mission that is particularly timely given the emergence of generative AI and chatbots.
Today, PAIR is part of the Responsible AI and Human-Centered Technology team within Google Research, and our work spans this larger research space: We advance foundational research on human-AI interaction (HAI) and machine learning (ML); we publish educational materials, including the PAIR Guidebook and Explorables (such as the recent Explorable looking at how and why models sometimes make incorrect predictions confidently); and we develop software tools like the Learning Interpretability Tool to help people understand and debug ML behaviors. Our inspiration this year is “changing the way people think about what THEY can do with AI.” This vision is inspired by the rapid emergence of generative AI technologies, such as large language models (LLMs) that power chatbots like Bard, and new generative media models like Google’s Imagen, Parti, and MusicLM. In this blog post, we review recent PAIR work that is changing the way we engage with AI.
Generative AI research
Generative AI is creating a lot of excitement, and PAIR is involved in a range of related research, from using language models to simulate complex community behaviors to studying how artists adopted generative image models like Imagen and Parti. These latter “text-to-image” models let a person input a text-based description of an image for the model to generate (e.g., “a gingerbread house in a forest in a cartoony style”). In a forthcoming paper titled “The Prompt Artists” (to appear in Creativity and Cognition 2023), we found that users of generative image models strive not only to create beautiful images, but also to create unique, innovative styles. To help achieve these styles, some would even seek unique vocabulary to help develop their visual style. For example, they may visit architectural blogs to learn what domain-specific vocabulary they can adopt to help produce distinctive images of buildings.
We are also researching solutions to challenges faced by prompt creators who, with generative AI, are essentially programming without using a programming language. As an example, we developed new methods for extracting semantically meaningful structure from natural language prompts. We have applied these structures to prompt editors to provide features similar to those found in other programming environments, such as semantic highlighting, autosuggest, and structured data views.
The growth of generative LLMs has also opened up new techniques to solve important long-standing problems. Agile classifiers are one approach we’re taking to leverage the semantic and syntactic strengths of LLMs to solve classification problems related to safer online discourse, such as nimbly blocking newer types of toxic language as quickly as it may evolve online. The big advance here is the ability to develop high quality classifiers from very small datasets — as small as 80 examples. This suggests a positive future for online discourse and better moderation of it: instead of collecting millions of examples to attempt to create universal safety classifiers for all use cases over months or years, more agile classifiers might be created by individuals or small organizations and tailored for their specific use cases, and iterated on and adapted in the time-span of a day (e.g., to block a new kind of harassment being received or to correct unintended biases in models). As an example of their utility, these methods recently won a SemEval competition to identify and explain sexism.
We’ve also developed new state-of-the-art explainability methods to identify the role of training data on model behaviors and misbehaviours. By combining training data attribution methods with agile classifiers, we also found that we can identify mislabelled training examples. This makes it possible to reduce the noise in training data, leading to significant improvements on model accuracy.
Collectively, these methods are critical to help the scientific community improve generative models. They provide techniques for fast and effective content moderation and dialogue safety methods that help support creators whose content is the basis for generative models’ amazing outcomes. In addition, they provide direct tools to help debug model misbehavior which leads to better generation.
Visualization and education
To lower barriers in understanding ML-related work, we regularly design and publish highly visual, interactive online essays, called AI Explorables, that provide accessible, hands-on ways to learn about key ideas in ML. For example, we recently published new AI Explorables on the topics of model confidence and unintended biases. In our latest Explorable, “From Confidently Incorrect Models to Humble Ensembles,” we discuss the problem with model confidence: models can sometimes be very confident in their predictions… and yet completely incorrect. Why does this happen and what can be done about it? Our Explorable walks through these issues with interactive examples and shows how we can build models that have more appropriate confidence in their predictions by using a technique called ensembling, which works by averaging the outputs of multiple models. Another Explorable, “Searching for Unintended Biases with Saliency”, shows how spurious correlations can lead to unintended biases — and how techniques such as saliency maps can detect some biases in datasets, with the caveat that it can be difficult to see bias when it’s more subtle and sporadic in a training set.
|
| PAIR designs and publishes AI Explorables, interactive essays on timely topics and new methods in ML research, such as “From Confidently Incorrect Models to Humble Ensembles,” which looks at how and why models offer incorrect predictions with high confidence, and how “ensembling” the outputs of many models can help avoid this. |
Transparency and the Data Cards Playbook
Continuing to advance our goal of helping people to understand ML, we promote transparent documentation. In the past, PAIR and Google Cloud developed model cards. Most recently, we presented our work on Data Cards at ACM FAccT’22 and open-sourced the Data Cards Playbook, a joint effort with the Technology, AI, Society, and Culture team (TASC). The Data Cards Playbook is a toolkit of participatory activities and frameworks to help teams and organizations overcome obstacles when setting up a transparency effort. It was created using an iterative, multidisciplinary approach rooted in the experiences of over 20 teams at Google, and comes with four modules: Ask, Inspect, Answer and Audit. These modules contain a variety of resources that can help you customize Data Cards to your organization’s needs:
- 18 Foundations: Scalable frameworks that anyone can use on any dataset type
- 19 Transparency Patterns: Evidence-based guidance to produce high-quality Data Cards at scale
- 33 Participatory Activities: Cross-functional workshops to navigate transparency challenges for teams
- Interactive Lab: Generate interactive Data Cards from markdown in the browser
The Data Cards Playbook is accessible as a learning pathway for startups, universities, and other research groups.
Software Tools
Our team thrives on creating tools, toolkits, libraries, and visualizations that expand access and improve understanding of ML models. One such resource is Know Your Data, which allows researchers to test a model’s performance for various scenarios through interactive qualitative exploration of datasets that they can use to find and fix unintended dataset biases.
Recently, PAIR released a new version of the Learning Interpretability Tool (LIT) for model debugging and understanding. LIT v0.5 provides support for image and tabular data, new interpreters for tabular feature attribution, a “Dive” visualization for faceted data exploration, and performance improvements that allow LIT to scale to 100k dataset entries. You can find the release notes and code on GitHub.
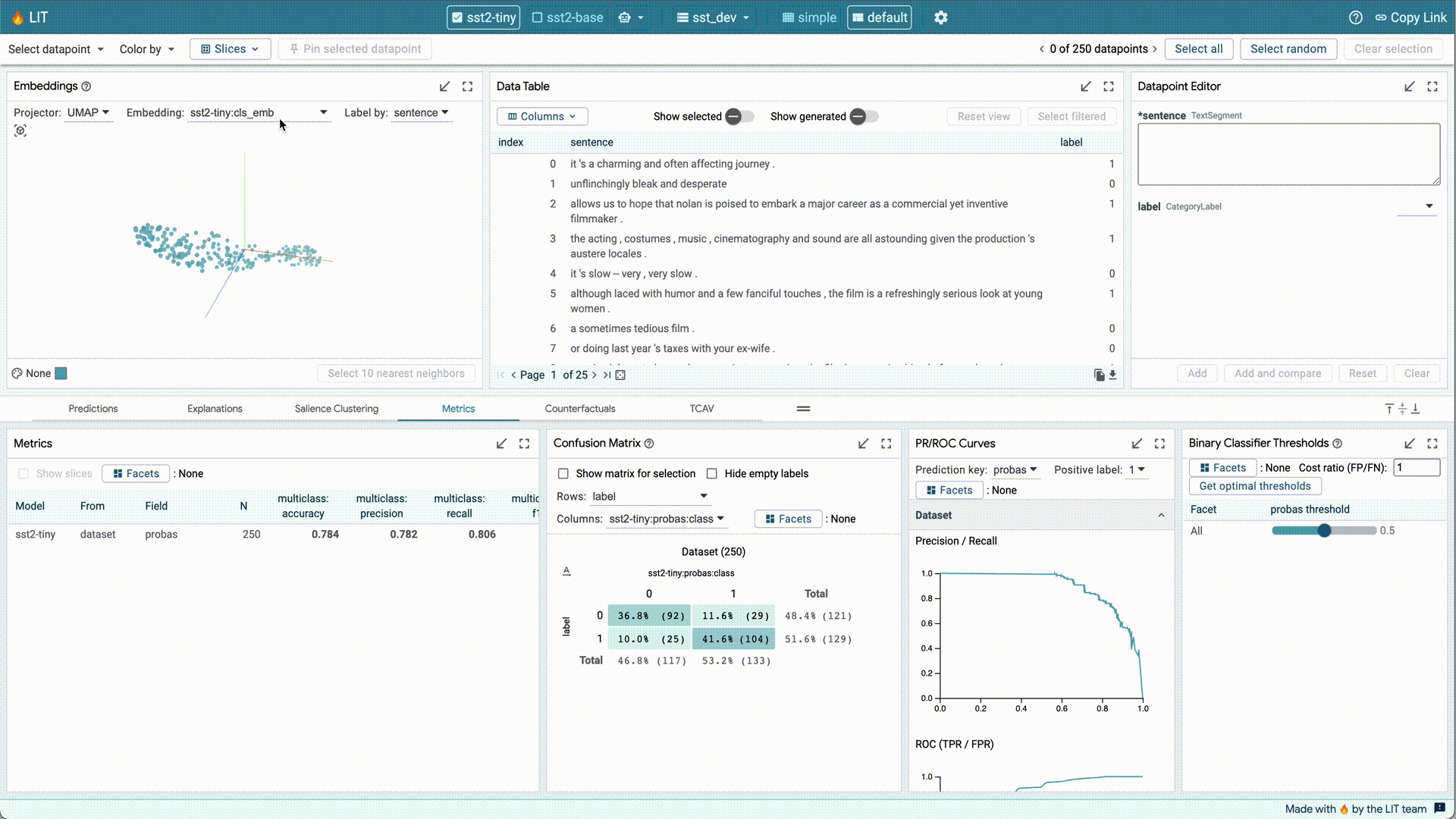 |
| PAIR’s Learning Interpretability Tool (LIT), an open-source platform for visualization and understanding of ML models. |
PAIR has also contributed to MakerSuite, a tool for rapid prototyping with LLMs using prompt programming. MakerSuite builds on our earlier research on PromptMaker, which won an honorable mention at CHI 2022. MakerSuite lowers the barrier to prototyping ML applications by broadening the types of people who can author these prototypes and by shortening the time spent prototyping models from months to minutes.
 |
| A screenshot of MakerSuite, a tool for rapidly prototyping new ML models using prompt-based programming, which grew out of PAIR’s prompt programming research. |
Ongoing work
As the world of AI moves quickly ahead, PAIR is excited to continue to develop new tools, research, and educational materials to help change the way people think about what THEY can do with AI.
For example, we recently conducted an exploratory study with five designers (presented at CHI this year) that looks at how people with no ML programming experience or training can use prompt programming to quickly prototype functional user interface mock-ups. This prototyping speed can help inform designers on how to integrate ML models into products, and enables them to conduct user research sooner in the product design process.
Based on this study, PAIR’s researchers built PromptInfuser, a design tool plugin for authoring LLM-infused mock-ups. The plug-in introduces two novel LLM-interactions: input-output, which makes content interactive and dynamic, and frame-change, which directs users to different frames depending on their natural language input. The result is more tightly integrated UI and ML prototyping, all within a single interface.
Recent advances in AI represent a significant shift in how easy it is for researchers to customize and control models for their research objectives and goals.These capabilities are transforming the way we think about interacting with AI, and they create lots of new opportunities for the research community. PAIR is excited about how we can leverage these capabilities to make AI easier to use for more people.
Acknowledgements
Thanks to everyone in PAIR and to all our collaborators.
REACT — A synergistic cloud-edge fusion architecture
This research paper was accepted by the eighth ACM/IEEE Conference on Internet of Things Design and Implementation (IoTDI), which is a premier venue on IoT. The paper describes a framework that leverages cloud resources to execute large deep neural network (DNN) models with higher accuracy to improve the accuracy of models running on edge devices.
Leveraging the cloud and edge concurrently
The internet is evolving towards an edge-computing architecture to support latency-sensitive DNN workloads in the emerging Internet of Things and mobile computing applications domains. However, unlike cloud environments, the edge has limited computing resources and cannot run large, high accuracy DNN models. As a result, past work has focused on offloading some of the computation to the cloud to get around this limitation. However, this comes at the cost of increased latency.
For example, in edge video analytics use cases, such as road traffic monitoring, drone surveillance, and driver assist technology, one can transmit occasional frames to the cloud to perform object detection—a task ideally suited to models hosted on powerful GPUs. On the other hand, the edge handles the interpolating intermediate frames through object tracking—a relatively inexpensive computational task performed using general-purpose CPUs, a low-powered edge GPU, or other edge accelerators (e.g., Intel Movidius Neural Stick). However, for most real-time applications, processing data in the cloud is infeasible due to strict latency constraints.
Spotlight: On-demand video

AI Explainer: Foundation models and the next era of AI
Explore how the transformer architecture, larger models and more data, and in-context learning have helped advance AI from perception to creation.
In our research paper, REACT: Streaming Video Analytics On The Edge With Asynchronous Cloud Support, we propose and demonstrate a novel architecture that leverages both the edge and the cloud concurrently to perform redundant computations at both ends. This helps retain the low latency of the edge while boosting accuracy with the power of the cloud. Our key technical contribution is in fusing the cloud inputs, which are received asynchronously, into the stream of computation at the edge, thereby improving the quality of detection without sacrificing latency.
Fusing edge and cloud detections


We illustrate our fusion approach in REACT for object detection in videos. Figure 1 shows the result of object detection using a lightweight edge model. This suffers from both missed objects (e.g., cars in Frame 1 are not detected) and misclassified objects (e.g., the van on the right of the frame that has been misclassified as a car).
To address the challenges of limited edge computation capacity and the drop in accuracy from using edge models, we follow a two-pronged approach. First, since the sequence of video frames are spatiotemporally correlated, it suffices to call edge object detection only once every few frames. As illustrated in Figure 1(a), edge detection runs every fifth frame. As shown in the figure, to interpose the intermediate frames, we employ a comparatively lightweight operation of object tracking. Second, to improve the accuracy of inference, select frames are asynchronously transmitted to the cloud for inference. Depending on network delay and the availability of cloud resources, cloud detections reach the edge device only after a few frames. Next, the newer cloud detections—previously undetected—are merged with the current frame. To do this, we feed the cloud detection, which was made on an old frame, into another instance of the object tracker to “fast forward” to the current time. The newly detected objects can then be merged into the current frame so long as the scene does not change abruptly. Figure 1(b) shows a visual result of our approach on a dashcam video dataset.
Here’s a more detailed description of how REACT goes about combining the edge and the cloud detections. Each detection contains objects represented by a ⟨class_label, bounding_box, confidence_score⟩ tuple. Whenever we receive a new detection (either edge or cloud), we purge from the current list the objects that were previously obtained from the same detection source (either cloud or edge). Then we form a zero matrix of size (c, n). Here, c and n are the indices associated with detections from current list and new source, respectively. We populate the matrix cell with the Intersection over Union (IoU) values—if it is greater than 0.5—corresponding to specific current and new detections. We then perform a linear sum assignment, which matches two objects with the maximum overlap. For overlapped objects, we modify the confidence values, bounding box, and class label based on the new detections’ source. Specifically, our analysis reveals that edge detection models could correctly localize objects, but often had false positives, i.e., they assigned class labels incorrectly. In contrast, cloud detections have higher localization error but lower error for class labels. Finally, newer objects (unmatched ones) will then get added to the list of current objects with the returned confidence values, bounding boxes, and class labels. Thus, REACT’s fusion algorithm must consider multiple cases —such as misaligned bounding boxes, class label mismatch, etc. — to consolidate the edge and cloud detections into a single list.
| Detector | Backbone | Where | #params |
|---|---|---|---|
| Faster R-CNN | ResNet50-FPN | Cloud | 41.5M |
| RetinaNet | ResNet50-FPN | Cloud | 36.1M |
| CenterNet | DLA34 | Cloud | 20.1M |
| TinyYOLOv3 | DN19 | Edge | 8.7M |
| SSD | MobileNetV2 | Edge | 3.4M |
In our experimentation, we leveraged state-of-the-art computer vision algorithms for getting object detections at the edge and the cloud (see Table 1). Further, we use mAP@0.5 (mean average precision at 0.5 IoU), a metric popular in the computer vision community to measure the performance of object detections. Moreover, to evaluate the efficacy of REACT, we looked at two datasets:
Based on our evaluation, we observed that REACT outperforms baseline algorithms by as much as 50%. Also, we noted that edge and cloud models can complement each other, and overall performance improves due to our edge-cloud fusion algorithm.
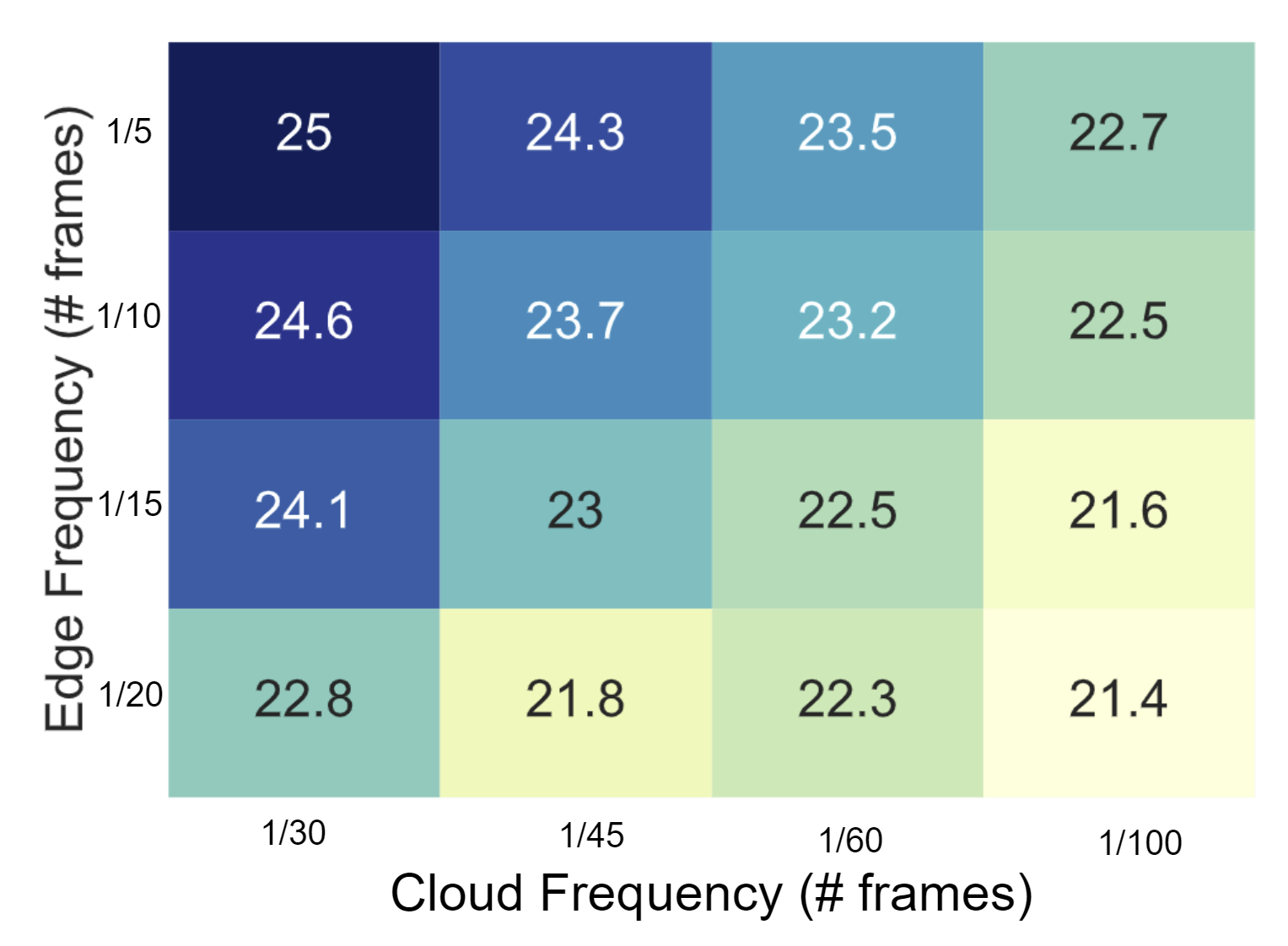
As already noted, the object detector runs only once every few frames and a lightweight object tracking is performed on intermediate frames. Running detection redundantly at both the edge and the cloud allows an application developer to flexibly trade off the frequency of edge versus cloud executions while achieving the same accuracy, as shown in Figure 2. For example, if the edge device experiences thermal throttling, we can pick a lower edge detection frequency (say, once every 20 frames) and complement it with cloud detection once every 30 frames to get mAP@0.5 of around 22.8. However, if there are fewer constraints at the edge, we can increase the edge detection frequency to once every five frames and reduce cloud detections to once every 120 frames to get similar performance (mAP@0.5 of 22.7). This provides a playground for fine-grained programmatic control.
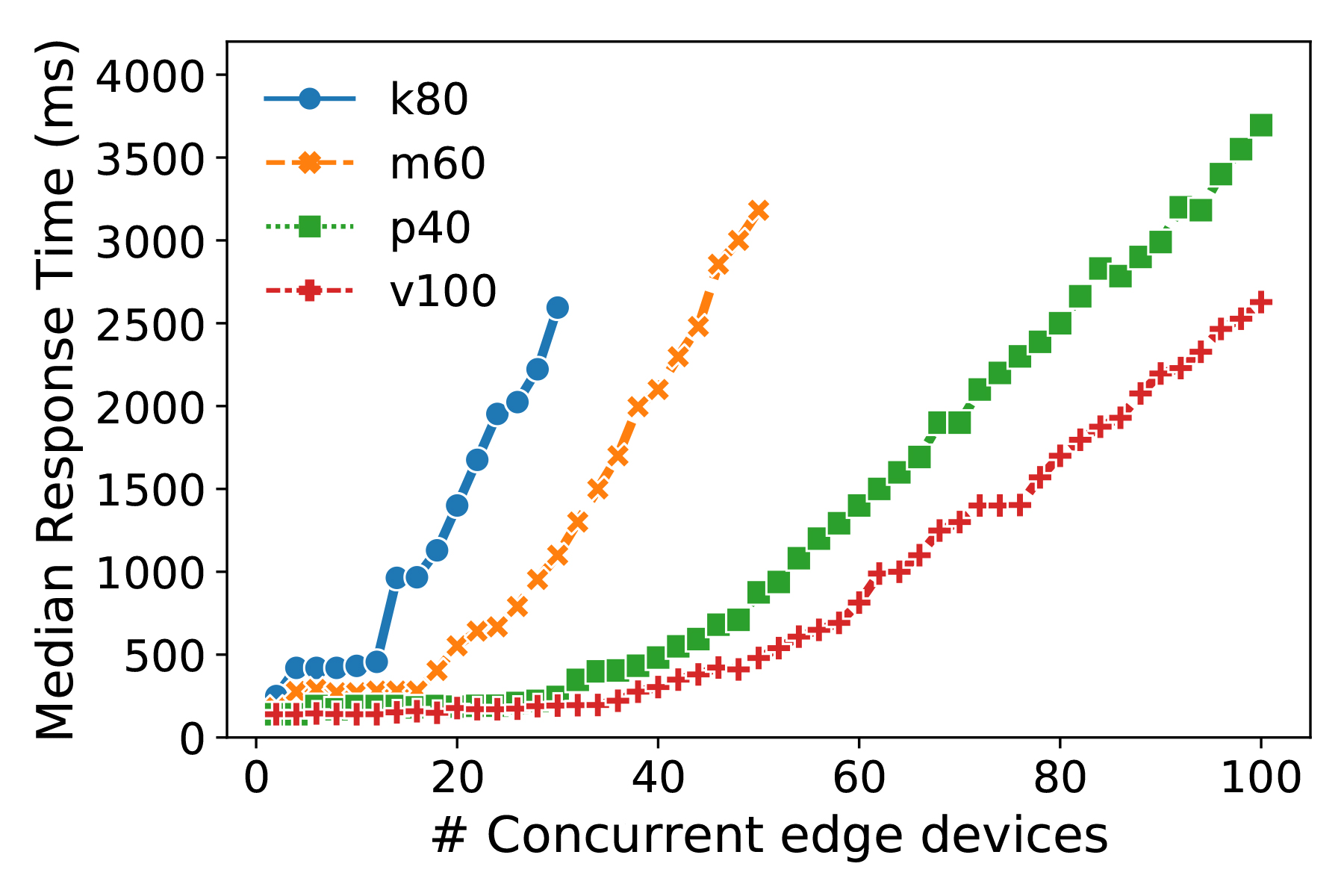
Further, one can amortize the cost of using cloud resources over multiple edge devices by having these share the same cloud hosted model. Specifically, if an application can tolerate a median latency of up to 500 ms, we can support over 60 concurrent devices at a time using the V100 GPU (Figure 3).
Conclusion
REACT represents a new paradigm of edge + cloud computing that leverages the resources of each to improve accuracy without sacrificing latency. As we have shown above, the choice between offloading and on-device inference is not binary, and redundant execution at cloud and edge locations complement each other when carefully employed. While we have focused on object detection, we believe that this approach could be employed in other contexts such as human pose-estimation, instance and semantic segmentation applications to have the “best of both worlds.”
The post REACT — A synergistic cloud-edge fusion architecture appeared first on Microsoft Research.

Achieving Zero-COGS with Microsoft Editor Neural Grammar Checker

Microsoft Editor provides AI-powered writing assistance to millions of users around the world. One of its features that writers of all levels and domains rely on is the grammar checker, which detects grammar errors in a user’s writing and offers suggested corrections and explanations of the detected errors.
The technology behind grammar checker has evolved significantly since the 1970s, when the first-generation tool was based on simple pattern matching. A major breakthrough occurred in 1997, when Microsoft Word 97 introduced a grammar checker that relied on a full-fledged natural language processing system (Heidorn, 2000), enabling more sophisticated and accurate error detection and correction. Another major breakthrough occurred in 2020, when Microsoft launched a neural grammar checker that leveraged deep neural networks with a novel fluency boost learning and inference mechanism, achieving state-of-the-art results on both CoNLL-2014 and JFLEG benchmark datasets[1,2]. In 2022, Microsoft released a highly optimized version of the Microsoft Editor neural grammar checker on expanded endpoints in Word Win32, Word Online, Outlook Online, and the Editor Browser Extension.
In this blog post, we will describe how we have optimized the Editor neural grammar checker model using the Aggressive Decoding algorithm pioneered by Microsoft Research (MSR) and accelerated with high performance ONNX Runtime (ORT). With the Aggressive Decoding algorithm and ORT optimizations, the server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality compared to the previous production model.
Spotlight: Microsoft Research Podcast

AI Frontiers: AI for health and the future of research with Peter Lee
Peter Lee, head of Microsoft Research, and Ashley Llorens, AI scientist and engineer, discuss the future of AI research and the potential for GPT-4 as a medical copilot.
But we did not stop there. We also implemented EdgeFormer, MSR’s cutting-edge on-device seq2seq modeling technology, to obtain a lightweight generative language model with competitive performance that can be run on a user’s device, allowing us to achieve the ultimate zero-cost-of-goods-sold (COGS) goal.
Shipping a client model offers three other key benefits in addition to achieving zero-COGS:
- Increased privacy. A client model that runs locally on the user’s device does not need to send any personal data to a remote server.
- Increased availability. A client model operates offline without relying on network connectivity, bandwidth, or server capacity.
- Reduced cost and increased scalability. Shipping a client model to a user’s device removes all the computation that a server would be required to execute, which allows us to ship to more customers.
Additionally, we leveraged GPT-3.5 (the most advanced AI model at the time) to generate high-quality training data and identify and remove low-quality training examples, leading to a boost of model performance.
Innovation: Aggressive Decoding
Behind the AI-powered grammar checker in Microsoft Editor is the transformer model, enhanced by cutting-edge research innovations[1,2,3] from MSR for grammar correction. As with most seq2seq tasks, we used autoregressive decoding for high-quality grammar correction. However, conventional autoregressive decoding is very inefficient as it cannot fully utilize modern computing devices (CPUs, GPUs) due to its low computational parallelism, which results in high model serving costs and prevents us from scaling quickly to more (web/desktop) endpoints.
To address the challenge for serving cost reduction, we adopt the latest decoding innovation, Aggressive Decoding,[3] published by MSR researchers Tao Ge and Furu Wei at ACL 2021. Unlike the previous methods that speed up inference at the cost of prediction quality drop, Aggressive Decoding is the first efficient decoding algorithm for lossless speedup of seq2seq tasks, such as grammar checking and sentence rewriting. Aggressive Decoding works for tasks whose inputs and targeted outputs are highly similar. It uses inputs as the targeted outputs and verifies them in parallel instead of decoding sequentially, one-by-one, as in conventional autoregressive decoding. As a result, it can substantially speed up the decoding process, handling trillions of requests per year, without sacrificing quality by better utilizing the powerful parallel computing capabilities of modern computing devices, such PCs with graphics processing units (GPUs).

The figure above shows how Aggressive Decoding works. If we find a bifurcation during Aggressive Decoding, we discard all the predictions after the bifurcation and re-decode them using conventional one-by-one autoregressive decoding. If we find a suffix match (i.e., some advice highlighted with the blue dotted lines) between the output and the input during one-by-one re-decoding, we switch back to Aggressive Decoding by copying the tokens (highlighted with the orange dashed lines) and following the matched tokens in the input to the decoder input by assuming they will be the same. In this way, Aggressive Decoding can guarantee that the generated tokens are identical to autoregressive greedy decoding but with much fewer decoding steps, significantly improving the decoding efficiency.
Offline evaluations
We test Aggressive Decoding in grammar correction and other text rewriting tasks, such as text simplification, with a 6+6 standard transformer as well as a transformer with deep encoder and shallow decoder. All results confirm that Aggressive Decoding can introduce a significant speedup without quality loss.
| CoNLL14 | NLCC-18 | Wikilarge | |||||
| F0.5 | speedup | F0.5 | speedup | SARI | BLEU | speedup | |
| 6+6 Transformer (beam=1) | 61.3 | 1 | 29.4 | 1 | 36.1 | 90.7 | 1 |
| 6+6 Transformer (AD) | 61.3 | 6.8 | 29.4 | 7.7 | 36.1 | 90.7 | 8 |
| CoNLL14 | ||
| F0.5 | speedup | |
| 12+2 Transformer (beam=1) | 66.4 | 1 |
| 12+2 Transformer (AD) | 66.4 | 4.2 |
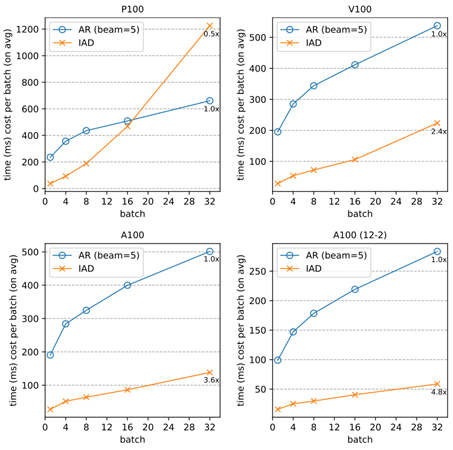
And it can work even better on more powerful computing devices that excel at parallel computing (e.g., A100):
Online evaluation
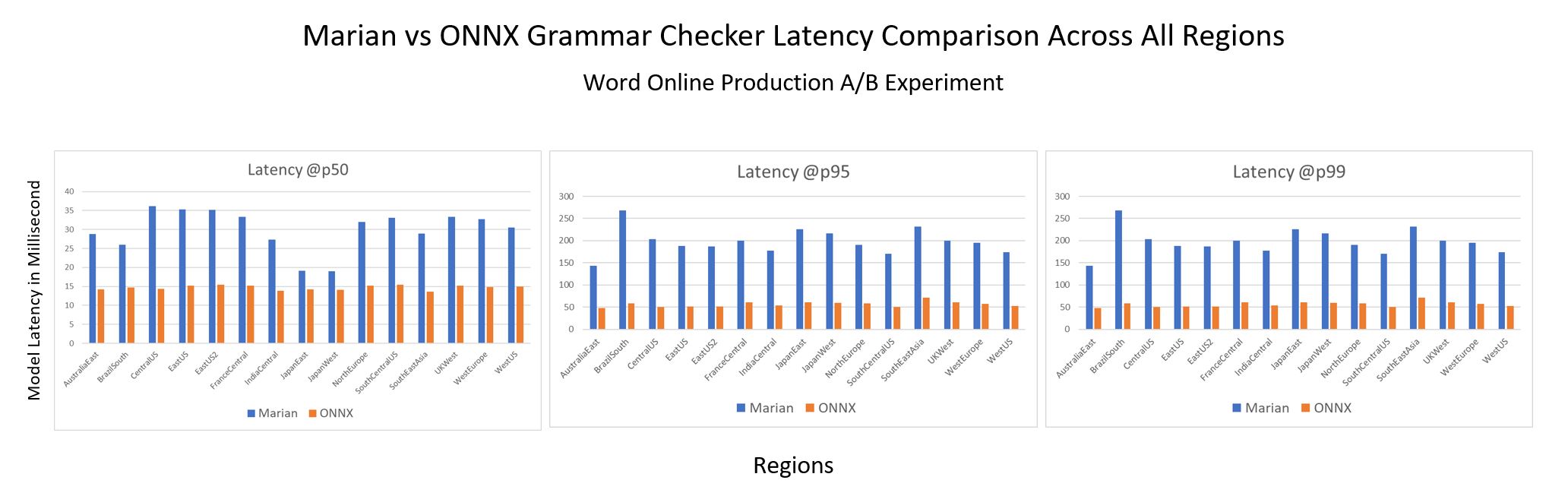
We ran an A/B experiment between a Marian server model and an equal size server model with Aggressive Decoding using ONNX Runtime. The latter shows 2x+ improvement @p50 and 3x+ improvement @p95 and @p99 over the Marian runtime, with conventional autoregressive decoding in CPU as shown in the graph below. Moreover, it offers better efficiency stability than the previous autoregressive decoding, which varies drastically in latency (approximately proportional to the sentence length), as Aggressive Decoding substantially reduces the decoding cost with only a few steps of parallel computing regardless of the sentence length. This substantial inference time speedup resulted in a two-thirds COGS reduction in the production endpoints.
Both offline/online evaluations confirm that Aggressive Decoding allows us to achieve significant COGS reduction without any loss of model prediction quality. Based on this intuition, we generalize[4]Aggressive Decoding to more general seq2seq tasks. Its high efficiency with lossless quality makes Aggressive Decoding likely to become the de facto decoding standard for seq2seq tasks and to play a vital role in the cost reduction of seq2seq model deployment.
Accelerate Grammar Checker with ONNX Runtime
ONNX Runtime is a high-performance engine, developed by Microsoft, that runs AI models across various hardware targets. A wide range of ML-powered Microsoft products leverage ONNX Runtime for inferencing performance acceleration. To further reduce the inferencing latency, the PyTorch Grammar Checker with Aggressive Decoding was exported to ONNX format using PyTorch-ONNX exporter, then inferenced with ONNX Runtime, which enables transformer optimizations and quantitation for CPU performance acceleration as well as model size reduction. A number of techniques are enabled in this end-to-end solution to run the advanced grammar checker model efficiently.
PyTorch provides a built-in function to export the PyTorch model to ONNX format with ease. To support the unique architecture of the grammar checker model, we enabled export of complex nested control flows to ONNX in the exporter. During this effort, we also extended the official ONNX specification on sequence type and operators to represent more complex scenarios (i.e., the autoregressive search algorithm). This eliminates the need to separately export model encoder and decoder components and stitch them together later with additional sequence generation implementation for production. With sequence type and operators support in PyTorch-ONNX exporter and ONNX Runtime, we were able to export one single ONNX graph, including encoder and decoder and sequence generation, which brings in both efficient computation and simpler inference logic. Furthermore, the shape type inference component of PyTorch ONNX exporter is enhanced to produce a valid ONNX model under stricter ONNX shape type constraints.
The innovative Aggressive Decoding algorithm introduced in the grammar checker model was originally implemented in Fairseq. To make it ONNX compatible, we reimplemented this Aggressive Decoding algorithm in HuggingFace for easy exporting. When diving into the implementation, we identified certain components that are not directly supported in the ONNX standard operator set (e.g., bifurcation detector). There are two approaches for exporting unsupported operators to ONNX and running with ONNX Runtime. We can either create a graph composing several standard ONNX operators that have equivalent semantics or implement a custom operator in ONNX Runtime with more efficient implementation. ONNX Runtime custom operator capability allows users to implement their own operators to run within ONNX Runtime with more flexibility. This is a tradeoff between implementation cost and performance. Considering the complexity of these components, the composition of standard ONNX operators might become a performance bottleneck. Hence, we introduced custom operators in ONNX Runtime to represent these components.
ONNX Runtime enables transformer optimizations and quantization, showing very promising performance gain on both CPU and GPU. We further enhanced encoder attention fusion and decoder reshape fusion for the grammar checker model. Another big challenge of supporting this model is multiple model subgraphs. We implemented subgraphs fusion in ONNX Runtime transformers optimizer and quantization tool. ONNX Runtime Quantization was applied to the whole model, further improving throughput and latency.
Quality Enhancement by GPT-3.5 LLMs
To further improve the precision and recall of the models in production, we employ the powerful GPT-3.5 as the teacher model. Specifically, the GPT-3.5 model works in the following two ways to help improve the result:
- Training data augmentation: We fine-tune the GPT-3.5 model and use it to generate labels for massive unannotated texts. The annotations obtained are verified to be of high quality and can be used as augmented training data to enhance the performance of our model.
- Training data cleaning: We leverage the powerful zero/few-shot capability of GPT-3.5 to distinguish between high-quality and low-quality training examples. The annotations of the identified low-quality examples are then regenerated by the GPT-3.5 model, resulting in a cleaner and higher-quality training set, which directly enhances the performance of our model.
EdgeFormer: Cost-effective parameterization for on-device seq2seq modeling
In recent years, the computational power of client devices has greatly increased, allowing for the use of deep neural networks to achieve the ultimate zero-COGS goal. However, running generative language models on these devices still poses a significant challenge, as the memory efficiency of these models must be strictly controlled. The traditional methods of compression used for neural networks in natural language understanding are often not applicable when it comes to generative language models.
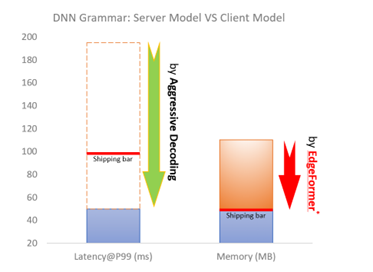
To ship a client grammar model, the model should be highly efficient (e.g., within 100ms latency), which has already been solved by Aggressive Decoding, mentioned earlier. Moreover, the client model must be memory-efficient (e.g., within a 50MB RAM footprint), which is the main bottleneck for a powerful (generative) transformer model (usually over 50 million parameters) to run on a client device.
To address this challenge, we introduce EdgeFormer[6], a cutting-edge on-device seq2seq modeling technology for obtaining lightweight generative language models with competitive performance that can be easily run on a user’s computer.
The main idea of EdgeFormer is two principles, which we proposed for cost-effective parameterization:
- Encoder-favored parameterization
- Load-balanced parameterization
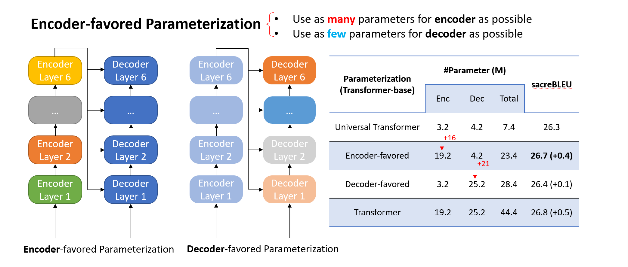
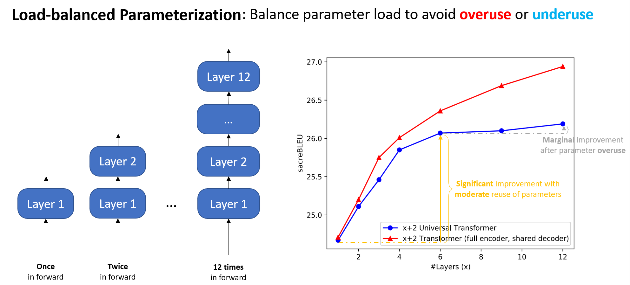
We designed EdgeFormer with the above principles of cost-effective parameterization, allowing each parameter to be utilized to its maximum potential, which achieves competitive results despite the stringent computational and memory constraints of client devices.
Based on EdgeFormer, we further propose EdgeLM – the pretrained version of EdgeFormer, which is the first publicly available pretrained on-device seq2seq model that can be easily fine-tuned for seq2seq tasks with strong results. EdgeLM serves as the foundation model of the grammar client model to realize the zero-COGS goal, which achieves over 5x model size compression with minimal quality loss compared to the server model.
Inference cost reduction to empower client-device deployment
Model deployment on client devices has strict requirements on hardware usage, such as memory and disk size, to avoid interference with other user applications. ONNX Runtime shows advantages for on-device deployment along with its lightweight engine and comprehensive client-inference focused solutions, such as ONNX Runtime quantization and ONNX Runtime extensions. In addition, to maintain service quality while meeting shipping requirements, MSR introduced a series of optimization techniques, including system-aware model optimization, model metadata simplification, and deferred parameter loading as well as customized quantization strategy. Based on the EdgeFormer modeling, these system optimizations can further reduce the memory cost by 2.7x, without sacrificing model performance.
We will elaborate on each one in the following sections:
System-aware model optimization. As the model is represented as a dataflow graph, the major memory cost for this model is from the many subgraphs generated. As shown in the figure below, a branch in the PyTorch code is mapped as a subgraph. Therefore, we optimize the model implementation to reduce the usage of branch instructions. Particularly, we leverage greedy search as the decoder search algorithm, as beam search contains more branch instructions. The usage of this method can reduce memory cost by 38%.
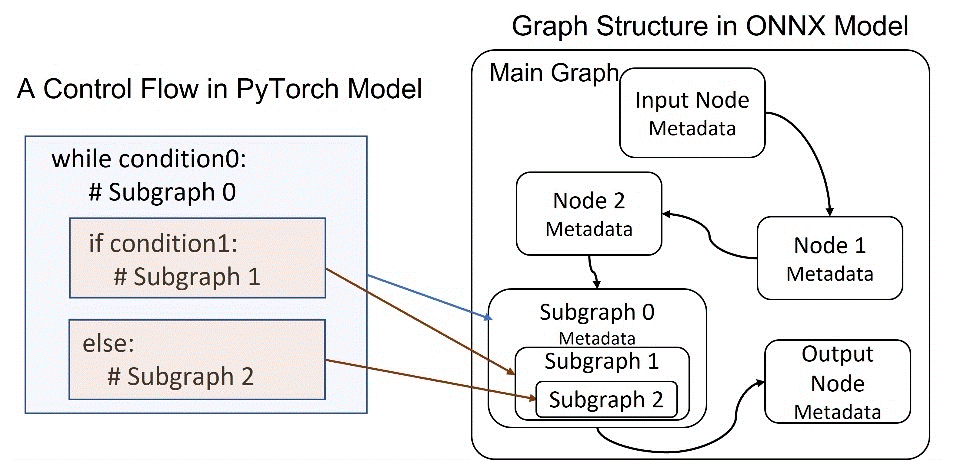
Model metadata simplification. Also shown in the figure above, the model contains a lot of metadata that consumes memory, such as the node name and type, input and output, and parameters. To reduce the cost, we simplify the metadata to keep only the basic required information for inference. For example, the node name is simplified from a long string to an index. Besides that, we optimize the model graph implementation in ONNX Runtime to keep just one copy of the metadata, rather than duplicating all the available metadata each time a subgraph is generated.
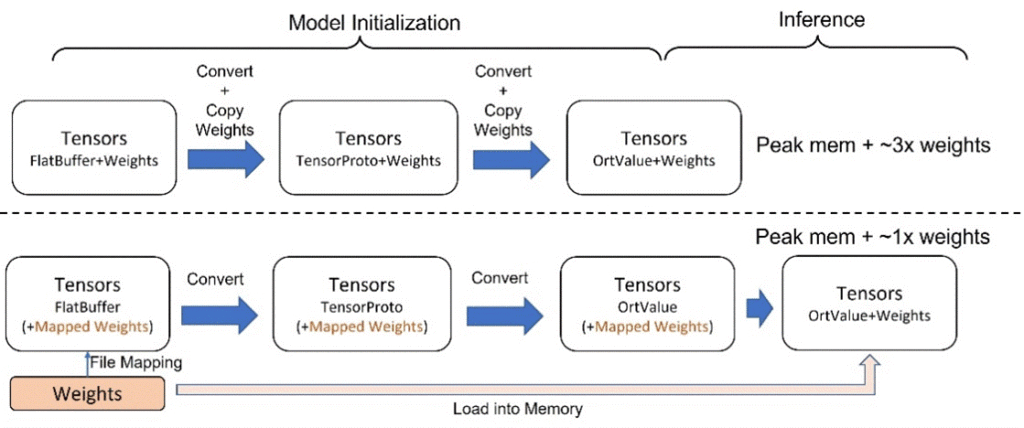
Deferred weight loading in ONNX Runtime. Current model files include both the model graphs and weights, which are then loaded into memory together during model initialization. However, this increases memory usage as shown in the figure below, because the weights will be copied repeatedly during model graph parsing and conversion. To avoid this, we save model graphs and weights separately. During initialization in ONNX Runtime, only the graphs are loaded into memory for actual parsing and conversion. The weights, on the other hand, still reside on disk with only the pointer kept in memory, through file mapping. The actual weight loading to memory will be deferred until the model inference. This technique can reduce the peak memory cost by 50%.
ONNX Runtime quantization and ONNX Runtime extensions. Quantization is a well-known model compression technique that brings in both performance acceleration and model size reduction while sacrificing model accuracy. ONNX Runtime Quantization offers diverse tuning knobs to allow us to apply customized quantization strategy. Specifically, we customize the strategy as post-training, dynamic, UINT8, per-channel and all-operator quantization, for this model for minimum accuracy impact. Onnxruntime-extensions provides a set of ONNX Runtime custom operators to support the common pre- and post-processing operators for vision, text, and natural language processing models. With it, the pre- and post-processing for this model, including tokenization, string manipulation, and so on, can be integrated into one self-contained ONNX model file, leading to improved performance, simplified deployment, reduced memory usage, and better portability.
Conclusion
In this blog post, we have presented how we leveraged the cutting-edge research innovations from MSR and ONNX Runtime to optimize the server grammar checker model and achieve the ultimate zero-COGS goal with the client grammar checker model. The server model has achieved ~200% increase in inference speed while saving two-thirds of the cost, with no loss of model prediction quality. The client model has achieved over 5x model size compression with minimal quality loss compared to the server model. These optimizations have enabled us to scale quickly to more web and desktop endpoints and provide AI-powered writing assistance to millions of users around the world.
The innovation shared in this blog post is just the first milestone in our long-term continuous effort of COGS reduction for generative AI models. Our proposed approach is not limited to accelerating the neural grammar checker; it can be easily generalized and applied more broadly to scenarios such as abstractive summarization, translation, or search engines to accelerate large language models for COGS reduction[5,8], which is critical not only for Microsoft but also for the entire industry in the artificial general intelligence (AGI) era.
Reference
[1] Tao Ge, Furu Wei, Ming Zhou: Fluency Boost Learning and Inference for Neural Grammatical Error Correction. In ACL 2018. [2] Tao Ge, Furu Wei, Ming Zhou: Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study. https://arxiv.org/abs/1807.01270 [3] Xin Sun, Tao Ge, Shuming Ma, Jingjing Li, Furu Wei, Houfeng Wang: A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-lingual Language Model. In IJCAI 2022. [4] Xin Sun, Tao Ge, Furu Wei, Houfeng Wang: Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding. In ACL 2021. [5] Tao Ge, Heming Xia, Xin Sun, Si-Qing Chen, Furu Wei: Lossless Acceleration for Seq2seq Generation with Aggressive Decoding. https://arxiv.org/pdf/2205.10350.pdf [6] Tao Ge, Si-Qing Chen, Furu Wei: EdgeFormer: A Parameter-efficient Transformer for On-device Seq2seq Generation. In EMNLP 2022. [7] Heidorn, George. “Intelligent Writing Assistance.” Handbook of Natural Language Processing. Robert Dale, Hermann L. Moisl, and H. L. Somers, editors. New York: Marcel Dekker, 2000: 181-207. [8] Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei: Inference with Reference: Lossless Acceleration of Large Language Models. https://arxiv.org/abs/2304.04487The post Achieving Zero-COGS with Microsoft Editor Neural Grammar Checker appeared first on Microsoft Research.

NVIDIA Cambridge-1 AI Supercomputer Expands Reach to Researchers via the Cloud
Scientific researchers need massive computational resources that can support exploration wherever it happens. Whether they’re conducting groundbreaking pharmaceutical research, exploring alternative energy sources or discovering new ways to prevent financial fraud, accessible state-of-the-art AI computing resources are key to driving innovation. This new model of computing can solve the challenges of generative AI and power the next wave of innovation.
Cambridge-1, a supercomputer NVIDIA launched in the U.K. during the pandemic, has powered discoveries from some of the country’s top healthcare researchers. The system is now becoming part of NVIDIA DGX Cloud to accelerate the pace of scientific innovation and discovery — across almost every industry.
As a cloud-based resource, it will broaden access to AI supercomputing for researchers in climate science, autonomous machines, worker safety and other areas, delivered with the simplicity and speed of the cloud, ideally located for the U.K. and European access.
DGX Cloud is a multinode AI training service that makes it possible for any enterprise to access leading-edge supercomputing resources from a browser. The original Cambridge-1 infrastructure included 80 NVIDIA DGX systems; now it will join with DGX Cloud, to allow customers access to world-class infrastructure.
History of Healthcare Insights
Academia, startups and the UK’s large pharma ecosystem used the Cambridge-1 supercomputing resource to accelerate research and design new approaches to drug discovery, genomics and medical imaging with generative AI in some of the following ways:
- InstaDeep, in collaboration with NVIDIA and the Technical University of Munich Lab, developed a 2.5 billion-parameter LLM for genomics on Cambridge-1. This project aimed to create a more accurate model for predicting the properties of DNA sequences.
- King’s College London used Cambridge-1 to create 100,000 synthetic brain images — and made them available for free to healthcare researchers. Using the open-source AI imaging platform MONAI, the researchers at King’s created realistic, high-resolution 3D images of human brains, training in weeks versus months.
- Oxford Nanopore used Cambridge-1 to quickly develop highly accurate, efficient models for base calling in DNA sequencing. The company also used the supercomputer to support inference for the ORG.one project, which aims to enable DNA sequencing of critically endangered species
- Peptone, in collaboration with a pharma partner, used Cambridge-1 to run physics-based simulations to evaluate the effect of mutations on protein dynamics with the goal of better understanding why specific antibodies work efficiently. This research could improve antibody development and biologics discovery.
- Relation Therapeutics developed a large language model which reads DNA to better understand genes, which is a key step to creating new medicines. Their research takes us a step closer to understanding how genes are controlled in certain diseases.

Beyond Fast: GeForce RTX 4060 GPU Family Gives Creators More Options to Accelerate Workflows, Starting at $299
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
The GeForce RTX 4060 family will be available starting next week, bringing massive creator benefits to the popular 60-class GPUs.
The latest GPUs in the 40 Series come backed by NVIDIA Studio technologies, including hardware acceleration for 3D, video and AI workflows; optimizations for RTX hardware in over 110 of the most popular creative apps; and exclusive Studio apps like Omniverse, Broadcast and Canvas.
Real-time ray-tracing renderer D5 Render introduced support for NVIDIA DLSS 3 technology, enabling super smooth real-time rendering experiences, so creators can work with larger scenes without sacrificing speed or interactivity.
Plus, the new Into the Omniverse series highlights the latest advancements to NVIDIA Omniverse, a platform furthering the evolution of the metaverse with the OpenUSD framework. The series showcases how artists, developers and enterprises can use the open development platform to transform their 3D workflows. The first installment highlights an update coming soon to the Adobe Substance 3D Painter Connector.
In addition, NVIDIA 3D artist Daniel Barnes returns this week In the NVIDIA Studio to share his mesmerizing, whimsical animation, Wormhole 00527.
Beyond Fast
The GeForce RTX 4060 family is powered by the ultra-efficient NVIDIA Ada Lovelace architecture with fourth-generation Tensor Cores for AI content creation, third-generation RT Cores and compatibility with DLSS 3 for ultra-fast 3D rendering, as well as the eighth-generation NVIDIA encoder (NVENC), now with support for AV1.

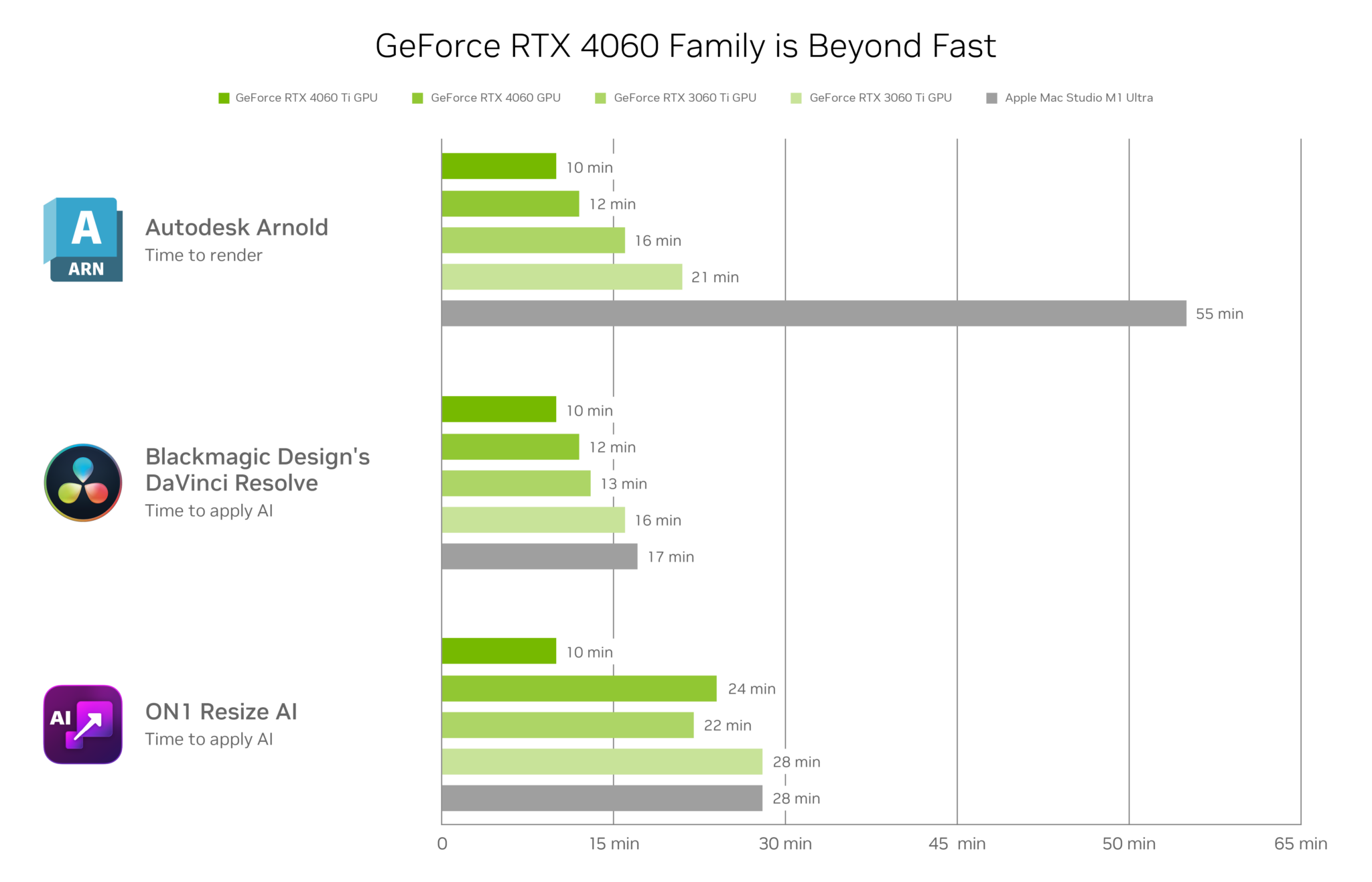
3D modelers can build and edit realistic 3D models in real time, up to 45% faster than the previous generation, thanks to third-generation RT Cores, DLSS 3 and the NVIDIA Omniverse platform.
Video editors specializing in Adobe Premiere Pro, Blackmagic Design’s DaVinci Resolve and more have at their disposal a variety of AI-powered effects, such as auto-reframe, magic mask and depth estimation. Fourth-generation Tensor Cores seamlessly hyper-accelerate these effects, so creators can stay in their flow states.
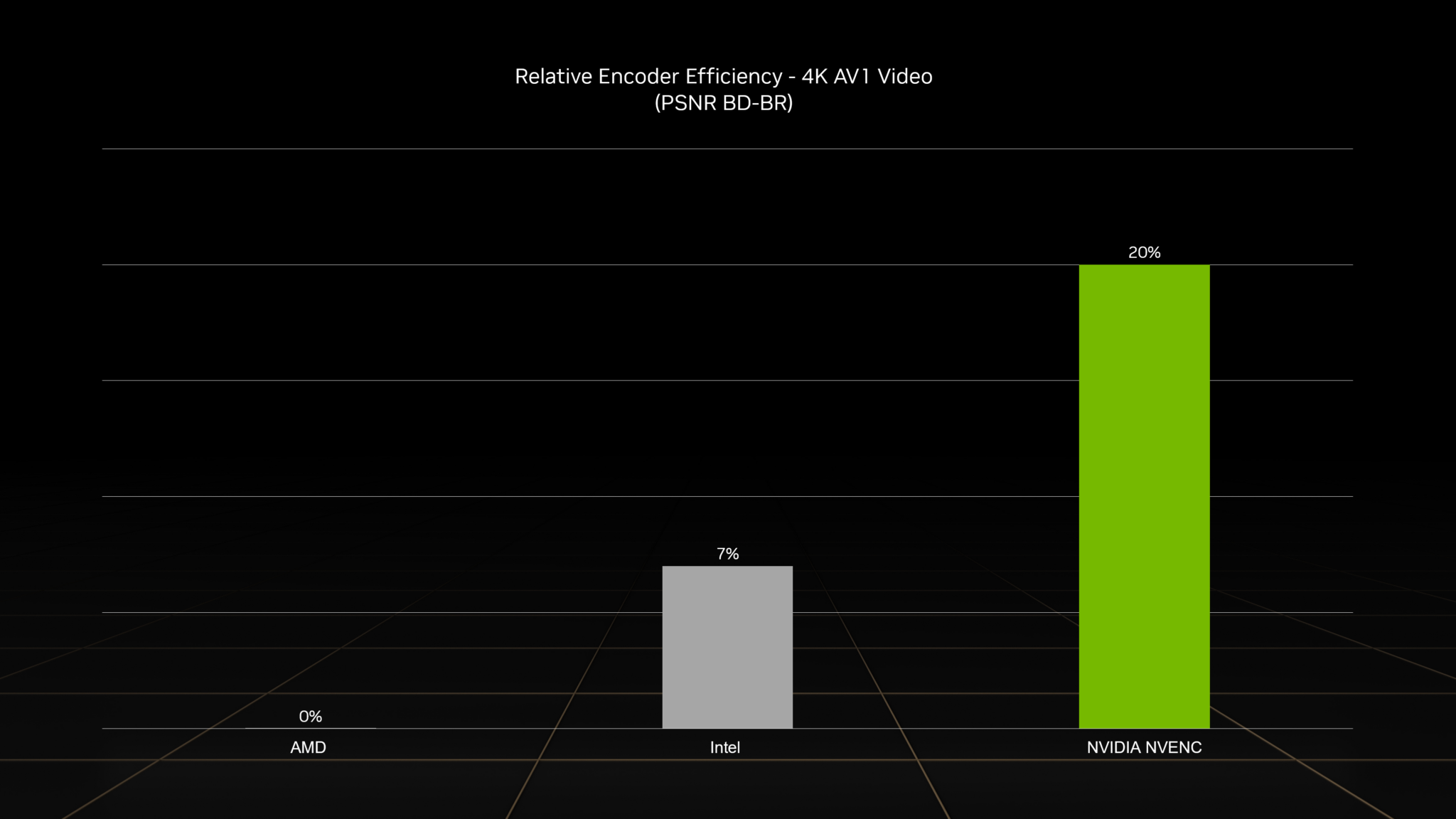
Broadcasters can jump into next-generation livestreaming with the eighth-generation NVENC with support for AV1. The new encoder is 40% more efficient, making livestreams appear as if there were a 40% increase in bitrate — a big boost in image quality that enables 4K streaming on apps like OBS Studio and platforms such as YouTube and Discord.

NVENC boasts the most efficient hardware encoding available, providing significantly better quality than other GPUs. At the same bitrate, images will look better, sharper and have less artifacts, like in the example above.
Creators are embracing AI en masse. DLSS 3 multiplies frame rates in popular 3D apps. ON1 ResizeAI, software that enables high-quality photo enlargement, is sped up 24% compared with last-generation hardware. DaVinci Resolve’s AI Magic Mask feature saves video editors considerable time automating the highly manual process of rotoscoping, carried out 20% faster than the previous generation.
The GeForce RTX 4060 Ti (8GB) will be available starting Wednesday, May 24, at $399. The GeForce RTX 4060 Ti (16GB) will be available in July, starting at $499. GeForce RTX 4060 will also be available in July, starting at $299.
Visit the Studio Shop for GeForce RTX 4060-powered NVIDIA Studio systems when available, and explore the range of high-performance Studio products.
D5 Render, DLSS 3 Combine to Beautiful Effect
D5 Render adds support for NVIDIA DLSS 3, bringing a vastly improved real-time experience to architects, designers, interior designers and 3D artists.
Such professionals want to navigate scenes smoothly while editing, and demonstrate their creations to clients in the highest quality. Scenes can be incredibly detailed and complex, making it difficult to maintain high real-time viewport frame rates and present in original quality.
D5 is coveted by many artists for its global illumination technology, called D5 GI, which delivers high-quality lighting and shading effects in real time, without sacrificing workflow efficiency.

By integrating DLSS 3, which combines AI-powered DLSS Frame Generation and Super Resolution technologies, real-time viewport frame rates increase up to 3x, making creator experiences buttery smooth. This allows designers to deal with larger scenes, higher-quality models and textures — all in real time — while maintaining a smooth, interactive viewport.
Learn more about the update.
Venture ‘Into the Omniverse’
NVIDIA Omniverse is a key component of the NVIDIA Studio platform and the future of collaborative 3D content creation.
A new monthly blog series, Into the Omniverse, showcases how artists, developers and enterprises can transform their creative workflows using the latest Omniverse advancements.
This month, 3D creators across industries are set to benefit from the pairing of Omniverse and the Adobe Substance 3D suite of creative tools.

An upcoming update to the Omniverse Connector for Adobe Substance 3D Painter will dramatically increase flexibility for users, with new capabilities including an export feature using Universal Scene Description (OpenUSD), an open, extensible file framework enabling non-destructive workflows and collaboration in scene creation.
Find details in the blog and check in every month for more Omniverse news.
Your Last Worm-ing
NVIDIA 3D artist Daniel Barnes has a simple initial approach to his work: sketch until something seems cool enough to act on. While his piece Wormhole 00527 was no exception to this usual process, an emotional component made a significant impact on it.
“After the pandemic and various global events, I took even more interest in spaceships and escape pods,” said Barnes. “It was just an abstract form of escapism that really played on the idea of ‘get me out of here,’ which I think we all experienced at one point, being inside so much.”
Barnes imagined Wormhole 00527 to comprise each blur one might pass by as an alternate star system — a place on the other side of the galaxy where things are really similar but more peaceful, he said. “An alternate Earth of sorts,” the artist added.
Sculpting on his tablet one night in the Nomad app, Barnes imported a primitive model into Autodesk Maya for further refinement. He retopologized the scene, converting high-resolution models into much smaller files that can be used for animation.

“I’ve been creating in 3D for over a decade now, and GeForce RTX graphics cards have been able to power multiple displays smoothly and run my 3D software viewports at great speeds. Plus, rendering in real time on some projects is great for fast development.” — Daniel Barnes
Barnes then took a screenshot, further sketched out his modeling edits and made lighting decisions in Adobe Photoshop.
His GeForce RTX 4090 GPU gives him access to over 30 GPU-accelerated features for quickly, smoothly modifying and adjusting images. These features include blur gallery, object selection and perspective warp.
Back in Autodesk Maya, Barnes used the quad-draw tool — a streamlined, one-tool workflow for retopologizing meshes — to create geometry, adding break-in panels that would be advantageous for animating.

Barnes used Chaos V-Ray with Autodesk Maya’s Z-depth feature, which provides information about each object’s distance from the camera in its current view. Each pixel representing the object is evaluated for distance individually — meaning different pixels for the same object can have varying grayscale values. This made it far easier for Barnes to tweak depth of field and add motion-blur effects.

He also added a combination of lights and applied materials with ease. Deploying RTX-accelerated ray tracing and AI denoising with the default Autodesk Arnold renderer enabled smooth movement in the viewport, resulting in beautifully photorealistic renders.

He finished the project by compositing in Adobe After Effects, using GPU-accelerated features for faster rendering with NVIDIA CUDA technology.

When asked what his favorite creative tools are, Barnes didn’t hesitate. “Definitely my RTX cards and nice large displays!” he said.
Check out Barnes’ portfolio on Instagram.
Follow NVIDIA Studio on Instagram, Twitter and Facebook. Access tutorials on the Studio YouTube channel and get updates directly in your inbox by subscribing to the Studio newsletter.
Get started with NVIDIA Omniverse by downloading the standard license free, or learn how Omniverse Enterprise can connect your team. Developers can get started with Omniverse resources. Stay up to date on the platform by subscribing to the newsletter, and follow NVIDIA Omniverse on Instagram, Medium and Twitter.
For more, join the Omniverse community and check out the Omniverse forums, Discord server, Twitch and YouTube channels.

First Xbox Title Joins GeForce NOW
Get ready for action — the first Xbox game title is now streaming from GeForce GPUs in the cloud directly to GeForce NOW members, with more to come later this month.
Gears 5 comes to the service this GFN Thursday. Keep reading to find out what other entries from the Xbox library will be streaming on GeForce NOW soon.
Also, time’s almost up on an exclusive discount for six-month GeForce NOW Priority memberships. Sign up today to save 40% before the offer ends on Sunday, May 21.
All Geared Up

NVIDIA and Microsoft have been working together to bring the first Xbox PC titles to the GeForce NOW library. With their gaming fueled by GeForce GPU servers in the cloud, members can access the best of Xbox Game Studios and Bethesda titles across nearly any device, including underpowered PCs, Macs, iOS and Android mobile devices, NVIDIA SHIELD TV, supported smart TVs and more.
Gears 5 from The Coalition is the first PC title from Xbox Game Studios to hit GeForce NOW. The latest entry in the Gears saga includes an acclaimed campaign playable solo or cooperatively, plus a variety of PvE and PvP modes to team up and battle in.
More Microsoft titles will follow shortly, starting with Deathloop, Grounded and Pentiment on Thursday, May 25.
Members will be able to stream these Xbox PC hits purchased through Steam on PCs, macOS devices, Chromebooks, smartphones and other devices. Support for Microsoft Store will become available in the coming months. Learn more about Xbox PC game support on GeForce NOW.
GeForce NOW Priority members can skip the wait and play Gears 5 or one of the other 1,600+ supported titles at 1080p 60 frames per second. Or go Ultimate for an upgraded experience, playing at up to 4K 120 fps for gorgeous graphics, or up to 240 fps for ultra-low latency that gives the competitive edge.

GeForce NOW members will see more PC games from Xbox added regularly and can keep up with the latest news and release dates through GFN Thursday updates.
Green Light Special
The latest GeForce NOW app updates are rolling out now. Version 2.0.52 brings a few fit-and-finish updates for members, including a new way to easily catch game discounts, content and more.
Promotional tags can be found on featured games throughout the app on PC and macOS. The tags are curated to highlight the most compelling offers available on the 1,600+ GeForce NOW-supported games. Keep an eye out for these promotional tags, which showcase new downloadable content, discounts, free games and more.
The update also includes in-app search improvements, surround-sound support in the browser experience on Windows and macOS, updated in-game button prompts for members using DualShock 4 and DualSense controllers, and more. Check out the in-app release highlights for more info.
Play for Today

Don’t get spooked in The Outlast Trials, newly supported this week on GeForce NOW. Go it alone or team up in this multiplayer edition of the survival horror franchise. Avoid the monstrosities waiting in the Murkoff experiments while using new tools to aid stealth, create opportunities to flee, slow enemies and more.
With support for more games every week, there’s always a new adventure around the corner. Here’s this week’s additions:
- Tin Hearts (New release on Steam, May 16)
- The Outlast Trials (New release on Steam, May 18)
- Gears 5 (Steam)
With the weekend kicking off, what are you gearing up to play? Let us know on Twitter or in the comments below.
Be ready to 𝙜𝙚𝙖𝙧 𝙪𝙥 for GFN Thursday tomorrow.
—
NVIDIA GeForce NOW (@NVIDIAGFN) May 17, 2023
