Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. Increasingly, sustainability (energy efficiency) is becoming an additional objective for customers. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks. In addition, more and more applications around us have become infused with ML, and new ML-powered applications are conceived every day. A popular example is OpenAI’s ChatGPT, which is powered by a state-of-the-art large language model (LMM). For reference, GPT-3, an earlier generation LLM has 175 billion parameters and requires months of non-stop training on a cluster of thousands of accelerated processors. The Carbontracker study estimates that training GPT-3 from scratch may emit up to 85 metric tons of CO2 equivalent, using clusters of specialized hardware accelerators.
There are several ways AWS is enabling ML practitioners to lower the environmental impact of their workloads. One way is through providing prescriptive guidance around architecting your AI/ML workloads for sustainability. Another way is by offering managed ML training and orchestration services such as Amazon SageMaker Studio, which automatically tears down and scales up ML resources when not in use, and provides a host of out-of-the-box tooling that saves cost and resources. Another major enabler is the development of energy efficient, high-performance, purpose-built accelerators for training and deploying ML models.
The focus of this post is on hardware as a lever for sustainable ML. We present the results of recent performance and power draw experiments conducted by AWS that quantify the energy efficiency benefits you can expect when migrating your deep learning workloads from other inference- and training-optimized accelerated Amazon Elastic Compute Cloud (Amazon EC2) instances to AWS Inferentia and AWS Trainium. Inferentia and Trainium are AWS’s recent addition to its portfolio of purpose-built accelerators specifically designed by Amazon’s Annapurna Labs for ML inference and training workloads.
AWS Inferentia and AWS Trainium for sustainable ML
To provide you with realistic numbers of the energy savings potential of AWS Inferentia and AWS Trainium in a real-world application, we have conducted several power draw benchmark experiments. We have designed these benchmarks with the following key criteria in mind:
- First, we wanted to make sure that we captured direct energy consumption attributable to the test workload, including not just the ML accelerator but also the compute, memory, and network. Therefore, in our test setup, we measured power draw at that level.
- Second, when running the training and inference workloads, we ensured that all instances were operating at their respective physical hardware limits and took measurements only after that limit was reached to ensure comparability.
- Finally, we wanted to be certain that the energy savings reported in this post could be achieved in a practical real-world application. Therefore, we used common customer-inspired ML use cases for benchmarking and testing.
The results are reported in the following sections.
Inference experiment: Real-time document understanding with LayoutLM
Inference, as opposed to training, is a continuous, unbounded workload that doesn’t have a defined completion point. It therefore makes up a large portion of the lifetime resource consumption of an ML workload. Getting inference right is key to achieving high performance, low cost, and sustainability (better energy efficiency) along the full ML lifecycle. With inference tasks, customers are usually interested in achieving a certain inference rate to keep up with the ingest demand.
The experiment presented in this post is inspired by a real-time document understanding use case, which is a common application in industries like banking or insurance (for example, for claims or application form processing). Specifically, we select LayoutLM, a pre-trained transformer model used for document image processing and information extraction. We set a target SLA of 1,000,000 inferences per hour, a value often considered as real time, and then specify two hardware configurations capable of meeting this requirement: one using Amazon EC2 Inf1 instances, featuring AWS Inferentia, and one using comparable accelerated EC2 instances optimized for inference tasks. Throughout the experiment, we track several indicators to measure inference performance, cost, and energy efficiency of both hardware configurations. The results are presented in the following figure.

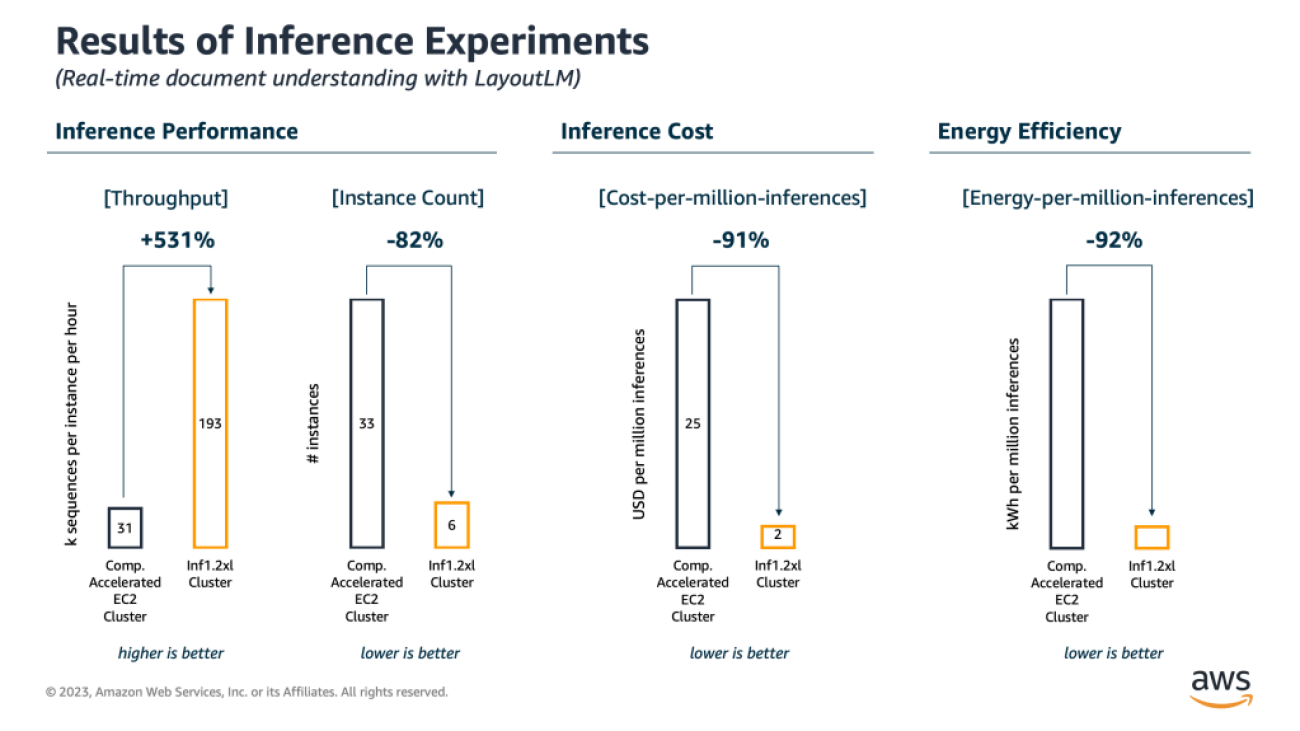
Performance, Cost and Energy Efficiency Results of Inference Benchmarks
AWS Inferentia delivers 6.3 times higher inference throughput. As a result, with Inferentia, you can run the same real-time LayoutLM-based document understanding workload on fewer instances (6 AWS Inferentia instances vs. 33 other inference-optimized accelerated EC2 instances, equivalent to an 82% reduction), use less than a tenth (-92%) of the energy in the process, all while achieving significantly lower cost per inference (USD 2 vs. USD 25 per million inferences, equivalent to a 91% cost reduction).
Training experiment: Training BERT Large from scratch
Training, as opposed to inference, is a finite process that is repeated much less frequently. ML engineers are typically interested in high cluster performance to reduce training time while keeping cost under control. Energy efficiency is a secondary (yet growing) concern. With AWS Trainium, there is no trade-off decision: ML engineers can benefit from high training performance while also optimizing for cost and reducing environmental impact.
To illustrate this, we select BERT Large, a popular language model used for natural language understanding use cases such as chatbot-based question answering and conversational response prediction. Training a well-performing BERT Large model from scratch typically requires 450 million sequences to be processed. We compare two cluster configurations, each with a fixed size of 16 instances and capable of training BERT Large from scratch (450 million sequences processed) in less than a day. The first uses traditional accelerated EC2 instances. The second setup uses Amazon EC2 Trn1 instances featuring AWS Trainium. Again, we benchmark both configurations in terms of training performance, cost, and environmental impact (energy efficiency). The results are shown in the following figure.

Performance, Cost and Energy Efficiency Results of Training Benchmarks
In the experiments, AWS Trainium-based instances outperformed the comparable training-optimized accelerated EC2 instances by a factor of 1.7 in terms of sequences processed per hour, cutting the total training time by 43% (2.3h versus 4h on comparable accelerated EC2 instances). As a result, when using a Trainium-based instance cluster, the total energy consumption for training BERT Large from scratch is approximately 29% lower compared to a same-sized cluster of comparable accelerated EC2 instances. Again, these performance and energy efficiency benefits also come with significant cost improvements: cost to train for the BERT ML workload is approximately 62% lower on Trainium instances (USD 787 versus USD 2091 per full training run).
Getting started with AWS purpose-built accelerators for ML
Although the experiments conducted here all use standard models from the natural language processing (NLP) domain, AWS Inferentia and AWS Trainium excel with many other complex model architectures including LLMs and the most challenging generative AI architectures that users are building (such as GPT-3). These accelerators do particularly well with models with over 10 billion parameters, or computer vision models like stable diffusion (see Model Architecture Fit Guidelines for more details). Indeed, many of our customers are already using Inferentia and Trainium for a wide variety of ML use cases.
To run your end-to-end deep learning workloads on AWS Inferentia- and AWS Trainium-based instances, you can use AWS Neuron. Neuron is an end-to-end software development kit (SDK) that includes a deep learning compiler, runtime, and tools that are natively integrated into the most popular ML frameworks like TensorFlow and PyTorch. You can use the Neuron SDK to easily port your existing TensorFlow or PyTorch deep learning ML workloads to Inferentia and Trainium and start building new models using the same well-known ML frameworks. For easier setup, use one of our Amazon Machine Images (AMIs) for deep learning, which come with many of the required packages and dependencies. Even simpler: you can use Amazon SageMaker Studio, which natively supports TensorFlow and PyTorch on Inferentia and Trainium (see the aws-samples GitHub repo for an example).
One final note: while Inferentia and Trainium are purpose built for deep learning workloads, many less complex ML algorithms can perform well on CPU-based instances (for example, XGBoost and LightGBM and even some CNNs). In these cases, a migration to AWS Graviton3 may significantly reduce the environmental impact of your ML workloads. AWS Graviton-based instances use up to 60% less energy for the same performance than comparable accelerated EC2 instances.
Conclusion
There is a common misconception that running ML workloads in a sustainable and energy-efficient fashion means sacrificing on performance or cost. With AWS purpose-built accelerators for machine learning, ML engineers don’t have to make that trade-off. Instead, they can run their deep learning workloads on highly specialized purpose-built deep learning hardware, such as AWS Inferentia and AWS Trainium, that significantly outperforms comparable accelerated EC2 instance types, delivering lower cost, higher performance, and better energy efficiency—up to 90%—all at the same time. To start running your ML workloads on Inferentia and Trainium, check out the AWS Neuron documentation or spin up one of the sample notebooks. You can also watch the AWS re:Invent 2022 talk on Sustainability and AWS silicon (SUS206), which covers many of the topics discussed in this post.
About the Authors
 Karsten Schroer is a Solutions Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
Karsten Schroer is a Solutions Architect at AWS. He supports customers in leveraging data and technology to drive sustainability of their IT infrastructure and build data-driven solutions that enable sustainable operations in their respective verticals. Karsten joined AWS following his PhD studies in applied machine learning & operations management. He is truly passionate about technology-enabled solutions to societal challenges and loves to dive deep into the methods and application architectures that underlie these solutions.
 Kamran Khan is a Sr. Technical Product Manager at AWS Annapurna Labs. He works closely with AI/ML customers to shape the roadmap for AWS purpose-built silicon innovations coming out of Amazon’s Annapurna Labs. His specific focus is on accelerated deep-learning chips including AWS Trainium and AWS Inferentia. Kamran has 18 years of experience in the semiconductor industry. Kamran has over a decade of experience helping developers achieve their ML goals.
Kamran Khan is a Sr. Technical Product Manager at AWS Annapurna Labs. He works closely with AI/ML customers to shape the roadmap for AWS purpose-built silicon innovations coming out of Amazon’s Annapurna Labs. His specific focus is on accelerated deep-learning chips including AWS Trainium and AWS Inferentia. Kamran has 18 years of experience in the semiconductor industry. Kamran has over a decade of experience helping developers achieve their ML goals.



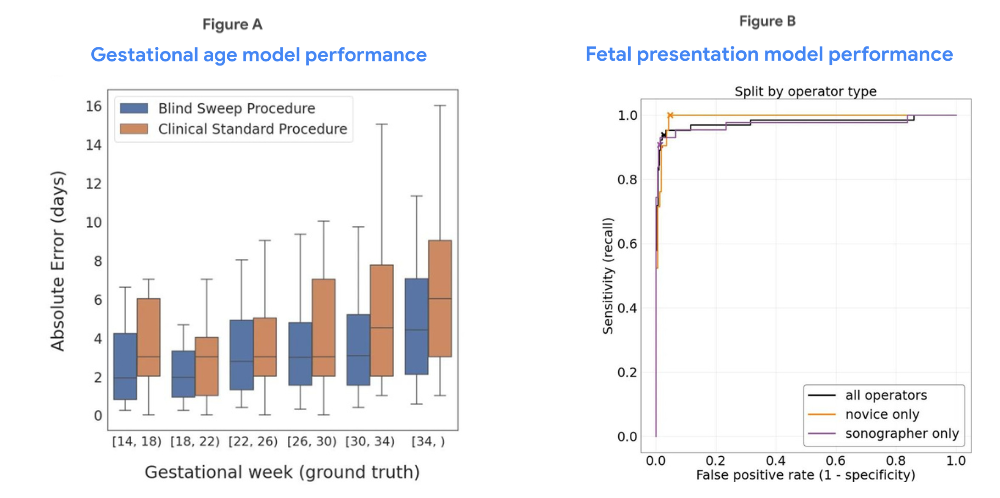
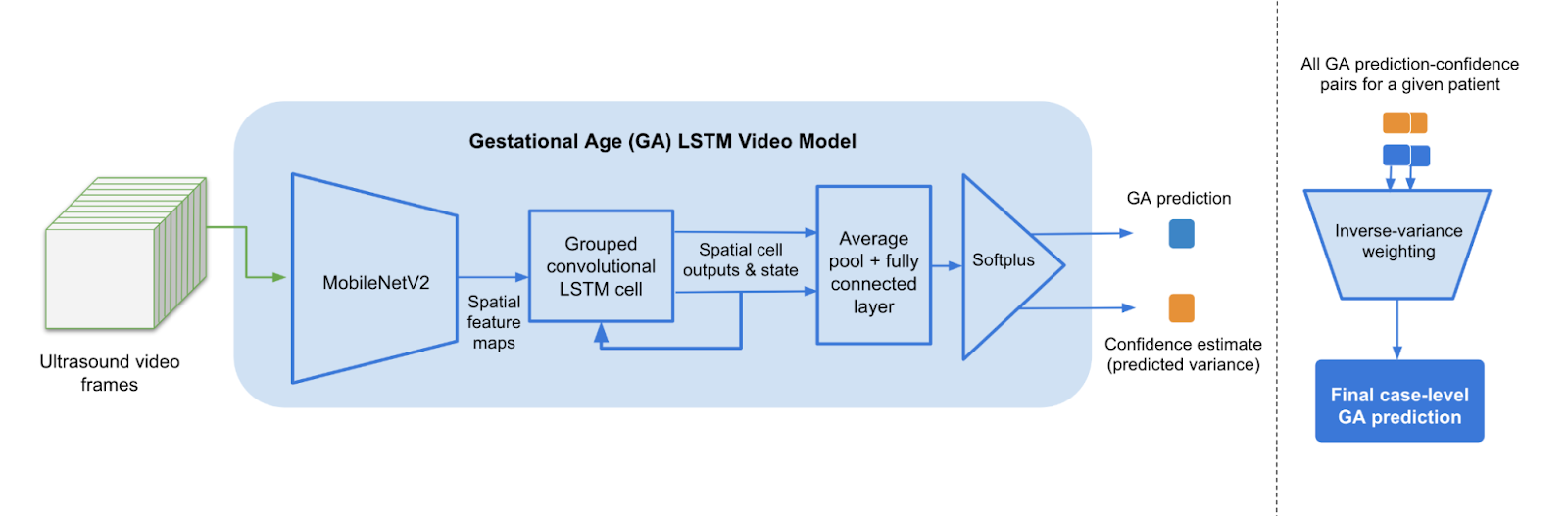
 Posted by Angelica Willis and Akib Uddin, Health AI Team, Google Research
Posted by Angelica Willis and Akib Uddin, Health AI Team, Google Research