We use GPT-4 for content policy development and content moderation decisions, enabling more consistent labeling, a faster feedback loop for policy refinement, and less involvement from human moderators.OpenAI Blog
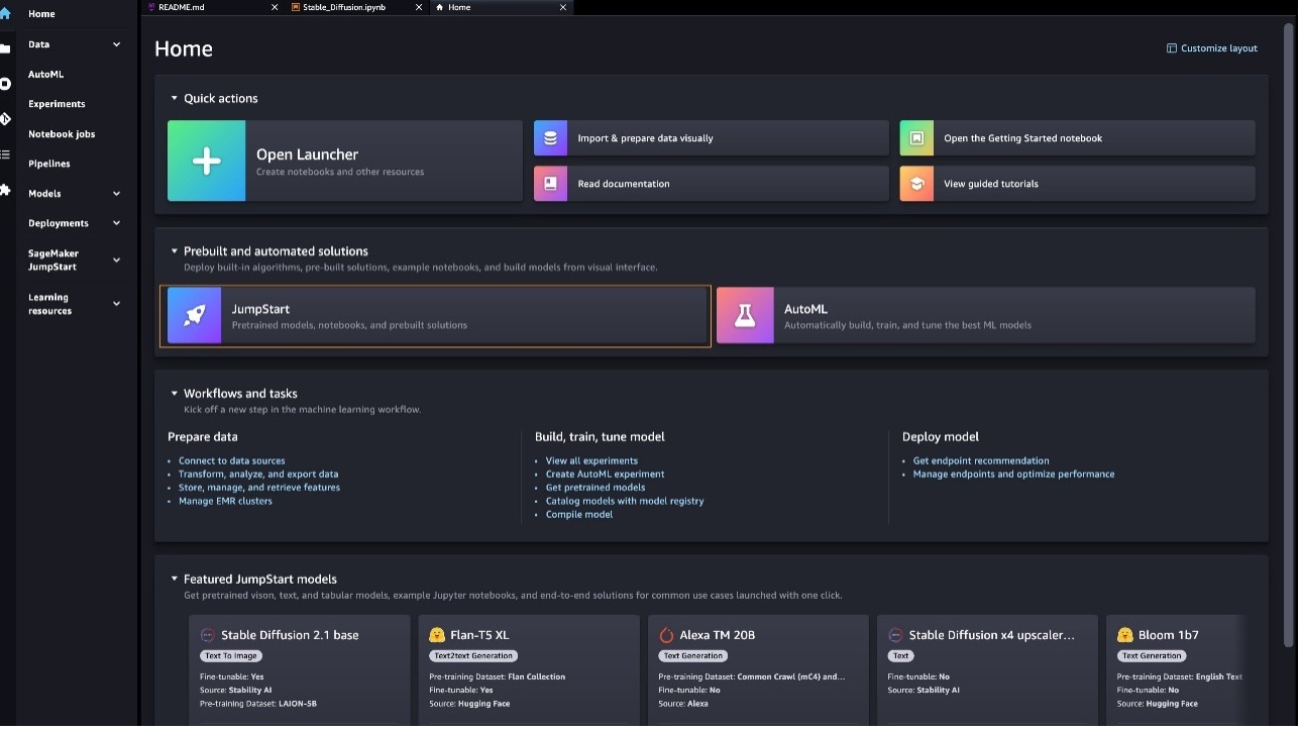
Zero-shot and few-shot prompting for the BloomZ 176B foundation model with the simplified Amazon SageMaker JumpStart SDK
Amazon SageMaker JumpStart is a machine learning (ML) hub offering algorithms, models, and ML solutions. With SageMaker JumpStart, ML practitioners can choose from a growing list of best performing and publicly available foundation models (FMs) such as BLOOM, Llama 2, Falcon-40B, Stable Diffusion, OpenLLaMA, Flan-T5/UL2, or FMs from Cohere and LightOn.
In this post and accompanying notebook, we demonstrate how to deploy the BloomZ 176B foundation model using the SageMaker Python simplified SDK in Amazon SageMaker JumpStart as an endpoint and use it for various natural language processing (NLP) tasks. You can also access the foundation models thru Amazon SageMaker Studio. The BloomZ 176B model, one of the largest publicly available models, is a state-of-the-art instruction-tuned model that can perform various in-context few-shot learning and zero-shot learning NLP tasks. Instruction tuning is a technique that involves fine-tuning a language model on a collection of NLP tasks using instructions. To learn more about instruction tuning, refer to Zero-shot prompting for the Flan-T5 foundation model in Amazon SageMaker JumpStart.
Zero-shot learning in NLP allows a pre-trained LLM to generate responses to tasks that it hasn’t been specifically trained for. In this technique, the model is provided with an input text and a prompt that describes the expected output from the model in natural language. Zero-shot learning is used in a variety of NLP tasks, such as the following:
- Multilingual text and sentiment classification
- Multilingual question and answering
- Code generation
- Paragraph rephrasing
- Summarization
- Common sense reasoning and natural language inference
- Question answering
- Sentence and sentiment classification
- Imaginary article generation based on a title
- Summarizing a title based on an article
Few-shot learning involves training a model to perform new tasks by providing only a few examples. This is useful where limited labeled data is available for training. Few-show learning is used in a variety of tasks, including the following:
- Text summarization
- Code generation
- Name entity recognition
- Question answering
- Grammar and spelling correction
- Product description and generalization
- Sentence and sentiment classification
- Chatbot and conversational AI
- Tweet generation
- Machine translation
- Intent classification
About Bloom
The BigScience Large Open-science Open-access Multilingual (BLOOM) language model is a transformer-based large language model (LLM). BLOOM is an autoregressive LLM trained to continue text from a prompt on vast amounts of text data using industrial-scale computational resources. As such, it is able to output coherent text that is hardly distinguishable from text written by humans. BLOOM can also be instructed to perform text tasks it hasn’t been explicitly trained for by casting them as text generation tasks.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French, and Arabic, BLOOM is the first language model with over 100 billion parameters ever created. Researchers can download, run, and study BLOOM to investigate the performance and behavior of recently developed LLMs down to their deepest internal operations.
Solution overview
In this post, we show how to use the state-of-the-art instruction-tuned BloomZ 176B model from Hugging Face for text generation. You can use the BloomZ 176B model with few-shot learning and zero-shot learning for many NLP tasks, without fine-tuning the model. There is no need to train a new model because models like BloomZ 176B have a significant number of parameters such that they can easily adapt to many contexts without being retrained. The BloomZ 176B model has been trained with a large amount of data, making to applicable for many general-purpose tasks.
The code for all the steps in this demo is available in the following notebook.
Instruction tuning
The size and complexity of LLMs have exploded in the last few years. LLMs have demonstrated remarkable capabilities in learning the semantics of natural language and producing human-like responses. Many recent LLMs are fine-tuned with a powerful technique called instruction tuning, which helps the model perform new tasks or generate responses to novel prompts without prompt-specific fine-tuning. An instruction-tuned model uses its understanding of related tasks or concepts to generate predictions to novel prompts. Because this technique doesn’t involve updating model weights, it avoids the time-consuming and computationally expensive process required to fine-tune a model for a new, previously unseen task.
Instruction tuning involves fine-tuning a language model on a collection of NLP tasks using instructions. In this technique, the model is trained to perform tasks by following textual instructions instead of specific datasets for each task. The model is fine-tuned with a set of input and output examples for each task, allowing the model to generalize to new tasks that it hasn’t been explicitly trained on as long as prompts are provided for the tasks. Instruction tuning helps improve the accuracy and effectiveness of models and is helpful in situations where large datasets aren’t available for specific tasks.
Prompt engineering for zero-shot and few-shot NLP tasks on BLOOM models
Prompt engineering deals with creating high-quality prompts to guide the model towards the desired responses. Prompts need to be designed based on the specific task and dataset being used. The goal here is to provide the model with necessary information to generate high-quality responses while minimizing noise. This could involve keywords, additional contexts, questions, and more.
A well-designed prompt can make the model more creative and generalized so that it can easily adapt to new tasks. Prompts can also help incorporate domain knowledge on specific tasks and improve interpretability. Prompt engineering can greatly improve the performance of zero-shot and few-shot learning models. Creating high-quality prompts requires careful consideration of the task at hand, as well as a deep understanding of the model’s strengths and limitations.
In the following table, the BloomZ 176B model is used to generate responses for various zero-shot and few-shot NLP tasks. The first column shows the task, the second column contains the prompt provided to the model (where the template text is bold and the non-bold text is the example input) and the third column is the response from the model when queried against the prompt
For all the following tasks, we set the hyperparameters as 600 to be the max_length, num_return_sequences, top_k to be 250, top_p to be 0.95, and no sampling.
| Task | Prompt Input | Output |
| Zero-shot learning tasks | ||
| Multilingual text or sentiment classification (Chinese to English) | 一个传奇的开端,一个不灭的神话,这不仅仅是一部电影,而是作为一个走进新时代的标签,永远彪炳史册。Would you rate the previous review as positive, neutral or negative? | positive |
| Multilingual question answering (English to Chinese) | Explain to me in Traditional Chinese what is the backpropagation | 梯度反向传播算法是一种机器学习算法,用于训练人工神经网络。该算法使用梯度下降来最小化损失函数。 |
| Code generation | Write a binary search tree with O(log(n)) computational complexity. {code_start} |
def binary_search(a, x): low = 0 high = len(a) – 1 while low <= high: mid = (low + high) // 2 if a[mid] < x: low = mid + 1 elif a[mid] > x: high = mid – 1 else: return mid return -1′ … else: return mid return low’ Output is truncated |
| Paragraph rephrase | Amazon Web Services (AWS) has announced nine major new updates for its cloud-based machine learning platform, SageMaker. SageMaker aims to provide a machine learning service which can be used to build, train, and deploy ML models for virtually any use case. During this year’s re:Invent conference, AWS made several announcements to further improve SageMaker’s capabilities.nnHow would you rephrase that briefly using English?,Amazon Web Services (AWS) has announced nine major new updates for its cloud-based machine learning platform, SageMaker. SageMaker aims to provide a machine learning service which can be used to build, train, and deploy ML models for virtually any use case. During this year’s re:Invent conference, AWS made several announcements to further improve SageMaker’s capabilities. nThe above sentence is very complicated. Please provide me a simplified synonymous version consisting of multiple sentences: |
Amazon SageMaker gets a major update Amazon Web Services (AWS) has announced nine major new updates for its cloud-based machine learning platform, SageMaker. SageMaker aims to provide a machine learning service that can be used to build, train and deploy ML models for virtually any use case |
| Summarization | Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases. You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. You can run real-time analysis for small workloads or you can start asynchronous analysis jobs for large document sets. You can use the pre-trained models that Amazon Comprehend provides, or you can train your own custom models for classification and entity recognition. All of the Amazon Comprehend features accept UTF-8 text documents as the input. In addition, custom classification and custom entity recognition accept image files, PDF files, and Word files as input. Amazon Comprehend can examine and analyze documents in a variety of languages, depending on the specific feature. For more information, see Languages supported in Amazon Comprehend. Amazon Comprehend’s Dominant language capability can examine documents and determine the dominant language for a far wider selection of languages.nn===nWrite a summary of the previous text in English: |
Amazon Comprehend uses natural language processing (NLP) to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document. Use Amazon Comprehend to create new products based on understanding the structure of documents. For example, using Amazon Comprehend you can search social networking feeds for mentions of products or scan an entire document repository for key phrases. You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. You can run real-time analysis for small workloads or you can start asynchronous analysis jobs for large document sets. You can use the pre-trained models that Amazon Comprehend provides, or you can train your own custom models for classification and entity recognition. All of the Amazon Comprehend features accept UTF-8 text documents as the input. In addition, custom classification and custom entity recognition accept image files, PDF files, and Word files as input. Amazon Comprehend can examine and analyze documents in a variety of languages, depending on the specific feature. For more information, see Languages supported in Amazon Comprehend. Amazon Comprehend’s Dominant language capability can examine documents and determine the dominant language for a far wider selection of languages. |
| Common sense reasoning and natural language inference | Given that The world cup has kicked off in Los Angeles, United States. Does it follow that The world cup takes place in United States. Yes or no?, The world cup has kicked off in Los Angeles, United States. Using only the above description and what you know about the world, is “The world cup takes place in United States” definitely correct? Yes or no?, |
Yes |
| Question answering | question: what are the key features of new Kindle?\nnContext: The newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. For readers who have always wished they could write in their eBooks, Amazon’s new Kindle lets them do just that. The Kindle Scribe is the first Kindle for reading and writing and allows users to supplement their books and documents with notes, lists, and more. Here’s everything you need to know about the Kindle Scribe, including frequently asked questions. The Kindle Scribe makes it easy to read and write like you would on paper The Kindle Scribe features a 10.2-inch, glare-free screen (the largest of all Kindle devices), crisp 300 ppi resolution, and 35 LED front lights that automatically adjust to your environment. Further personalize your experience with the adjustable warm light, font sizes, line spacing, and more. It comes with your choice of the Basic Pen or the Premium Pen, which you use to write on the screen like you would on paper. They also attach magnetically to your Kindle and never need to be charged. The Premium Pen includes a dedicated eraser and a customizable shortcut button. The Kindle Scribe has the most storage options of all Kindle devices: choose from 8 GB, 16 GB, or 32 GB to suit your level of reading and writing. \nnAnswer |
take notes on millions of books and documents, write lists and journals, and more |
| Sentence and sentiment classification | Review:nThis moive is so great and once again dazzles and delights usnIs this movie review sentence negative or positive?nOPTIONS:n-positive n-negative | Positive |
| Imaginary article generation based on title | Title: “University has new facility coming up”\nGiven the above title of an imaginary article, imagine the article.\n””” |
The £1.2m project will see the creation of a new teaching and learning centre at the University of the Highlands and Islands (UHI) in Inverness. It will be built on the site of the former Inverness College of Commerce. UHI said the new facility would be used for teaching and learning, as well as student support and administration. The university said it would also be used for conferences and events. The new building will be built on the site of the former Inverness College of Commerce The university said the new building would be built on the site of the former Inverness College of Commerce, which closed in 2013. It said the new facility would be used for teaching and learning, as well as student support and administration. It would also be used for conferences and events. UHI said the new facility would be built on the site of the former Inverness College of Commerce The university said the new building would be built on the site of the former Inverness College of Commerce, which closed in 2013. It said the new facility would be used for teaching and learning, as well as student support and administration. UHI said the new facility would be built on the site of the former Inverness… |
| Summarizing a title based on the article | ‘The newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. For readers who have always wished they could write in their eBooks, Amazon’s new Kindle lets them do just that. The Kindle Scribe is the first Kindle for reading and writing and allows users to supplement their books and documents with notes, lists, and more. Here’s everything you need to know about the Kindle Scribe, including frequently asked questions. The Kindle Scribe makes it easy to read and write like you would on paper The Kindle Scribe features a 10.2-inch, glare-free screen (the largest of all Kindle devices), crisp 300 ppi resolution, and 35 LED front lights that automatically adjust to your environment. Further personalize your experience with the adjustable warm light, font sizes, line spacing, and more. It comes with your choice of the Basic Pen or the Premium Pen, which you use to write on the screen like you would on paper. They also attach magnetically to your Kindle and never need to be charged. The Premium Pen includes a dedicated eraser and a customizable shortcut button. The Kindle Scribe has the most storage options of all Kindle devices: choose from 8 GB, 16 GB, or 32 GB to suit your level of reading and writing. nn \n\nGive me a good title for the article above. |
Amazon’s Kindle Scribe: Everything you need to know |
| Few-shot learning tasks | ||
| Summarization | [Original]: Amazon scientists, in collaboration with researchers from the University of Sheffield, are making a large-scale fact extraction and verification dataset publicly available for the first time. The dataset, comprising more than 185,000 evidence-backed claims, is being made available to hopefully catalyze research and development that addresses the problems of fact extraction and verification in software applications or cloud-based services that perform automatic information extraction. [Summary]: Amazon and University researchers make fact extraction and verification dataset publicly available. ### [Original]: Prime members in the U.S. can get even more delivered to their door with a Prime membership. Members can now enjoy one year of Grubhub+ valued at $9.99 per month for free—at no added cost to their Prime membership. To activate this deal, visit amazon.com/grubhub. This new offer includes unlimited, $0 food delivery fees on orders over $12 as well as exclusive perks for Grubhub+ members and rewards like free food and order discounts. Plus, diners can “eat good while doing good” by opting into Grubhub’s Donate the Change program, a donation-matching initiative that raised more than $25 million in 2021 alone, benefiting more than 20 charitable organizations across the country. [Summary]: Prime members in the U.S. can enjoy one year of Grubhub+ for free, with no food-delivery fees on eligible orders. ### [Original]: Amazon scientists, in collaboration with researchers from the University of Sheffield, are making a large-scale fact extraction and verification dataset publicly available for the first time. The dataset, comprising more than 185,000 evidence-backed claims, is being made available to hopefully catalyze research and development that addresses the problems of fact extraction and verification in software applications or cloud-based services that perform automatic information extraction. [Summary]: |
[Summary]: Amazon and University researchers make fact extraction and verification dataset publicly available. |
| Code generation | description: a orange button that says stop code: <button style=color:white; background-color:orange;>Stop</button> ### description: a blue box that contains yellow circles with red borders code: <div style=background-color: blue; padding: 20px;><div style=background-color: yellow; border: 5px solid red; border-radius: 50%; padding: 20px; width: 100px; height: 100px;> ### description: a Headline saying Welcome to AI code: |
code: <h1>Welcome to AI</h1>’ |
| Name entity recognition | [Text]: Fred is a serial entrepreneur. Co-founder and CEO of Platform.sh, he previously co-founded Commerce Guys, a leading Drupal ecommerce provider. His mission is to guarantee that as we continue on an ambitious journey to profoundly transform how cloud computing is used and perceived, we keep our feet well on the ground continuing the rapid growth we have enjoyed up until now. [Name]: Fred [Position]: Co-founder and CEO [Company]: Platform.sh ### [Text]: Microsoft (the word being a portmanteau of “microcomputer software”) was founded by Bill Gates on April 4, 1975, to develop and sell BASIC interpreters for the Altair 8800. Steve Ballmer replaced Gates as CEO in 2000, and later envisioned a “devices and services” strategy. [Name]: Steve Ballmer [Position]: CEO [Company]: Microsoft ### [Text]: Franck Riboud was born on 7 November 1955 in Lyon. He is the son of Antoine Riboud, the previous CEO, who transformed the former European glassmaker BSN Group into a leading player in the food industry. He is the CEO at Danone. [Name]: Franck Riboud [Position]: CEO [Company]: Danone ### [Text]: David Melvin is an investment and financial services professional at CITIC CLSA with over 30 years’ experience in investment banking and private equity. He is currently a Senior Adviser of CITIC CLSA. |
[Name]: Fred [Position]: Co-founder and CEO [Company]: Platform.sh |
| Question answering | Context: NLP Cloud was founded in 2021 when the team realized there was no easy way to reliably leverage Natural Language Processing in production. Question: When was NLP Cloud founded? Answer: 2021 ### Context: NLP Cloud developed their API by mid-2020 and they added many pre-trained open-source models since then. Question: What did NLP Cloud develop? Answer: API ### Context: All plans can be stopped anytime. You only pay for the time you used the service. In case of a downgrade, you will get a discount on your next invoice. Question: When can plans be stopped? Answer: Anytime ### Context: The main challenge with GPT-J is memory consumption. Using a GPU plan is recommended. Question: Which plan is recommended for GPT-J? Answer:””” |
Answer: GPU plan’ |
| Grammar and spelling correction | I love goin to the beach. Correction: I love going to the beach. ### Let me hav it! Correction: Let me have it! ### It have too many drawbacks. Correction: It has too many drawbacks. ### I do not wan to go Correction: |
Correction: I don’t want to go |
| Product description and generalization | Generate a product description out of keywords. Keywords: shoes, women, $59 Sentence: Beautiful shoes for women at the price of $59. ### Keywords: trousers, men, $69 Sentence: Modern trousers for men, for $69 only. ### Keywords: gloves, winter, $19 Sentence: Amazingly hot gloves for cold winters, at $19. ### Keywords: t-shirt, men, $39 Sentence: |
Sentence: Cool t-shirt for men, for $39 only. |
| Sentence and sentiment classification | Message: When the spaceship landed on Mars, the whole humanity was excited Topic: space ### Message: I love playing tennis and golf. I’m practicing twice a week. Topic: sport ### Message: Managing a team of sales people is a tough but rewarding job. Topic: business ### Message: I am trying to cook chicken with tomatoes. Topic: |
Topic: food |
| Chatbot and conversational AI | This is a discussion between a [human] and a [robot]. The [robot] is very nice and empathetic. [human]: Hello nice to meet you. [robot]: Nice to meet you too. ### [human]: How is it going today? [robot]: Not so bad, thank you! How about you? ### [human]: I am ok, but I am a bit sad… [robot]: Oh? Why that? ### [human]: I caught flu [robot]: |
[robot]: Oh no, I am sorry to hear that! |
| Tweet generation | keyword: markets tweet: Take feedback from nature and markets, not from people ### keyword: children tweet: Maybe we die so we can come back as children. ### keyword: startups tweet: Startups should not worry about how to put out fires, they should worry about how to start them. ### keyword: nlp tweet: |
tweet: NLP is a tool, not a goal. |
| Machine translation | Hugging Face a révolutionné le NLP. Translation: Hugging Face revolutionized NLP. ### Cela est incroyable! Translation: This is unbelievable! ### Désolé je ne peux pas. Translation: Sorry but I cannot. ### NLP Cloud permet de deployer le NLP en production facilement. Translation: |
Translation: NLP Cloud makes it easy to deploy NLP in production. |
| Intent classification | I want to start coding tomorrow because it seems to be so fun! Intent: start coding ### Show me the last pictures you have please. Intent: show pictures ### Search all these files as fast as possible. Intent: search files ### Can you please teach me Chinese next week? Intent: |
Intent: teach me chinese |
Access the BloomZ 176B instruction-tuned model in SageMaker
SageMaker JumpStart provides two ways to get started using these instruction-tuned Bloom models: Amazon SageMaker Studio and the SageMaker SDK. The following sections illustrate what each of these options look like and how to access them.
Access the model with the simplified SageMaker JumpStart SDK
The simplified SageMaker JumpStart SDK facilitates training and deploying built-in SageMaker JumpStart models with a couple lines of code. This gives you access to the entire library of SageMaker JumpStart models, including the latest foundation models and image generation models, without having to supply any inputs besides the model ID.
You can take advantage of the model-specific default values we provide to specify the configuration, such as the Docker image, ML instance type, model artifact location, and hyperparameters, among other fields. These attributes are only default values; you can override them and retain granular control over the AWS models you create. As a result of these changes, the effort to write Python workflows to deploy and train SageMaker JumpStart models has been reduced, enabling you to spend more time on the tasks that matter. This feature is available in all Regions where JumpStart is supported, and can be accessed with the SageMaker Python SDK version 2.154.0 or later.
You can programmatically deploy an endpoint through the SageMaker SDK. You will need to specify the model ID of your desired model in the SageMaker model hub and the instance type used for deployment. The model URI, which contains the inference script, and the URI of the Docker container are obtained through the SageMaker SDK. These URIs are provided by SageMaker JumpStart and can be used to initialize a SageMaker model object for deployment.
Deploy the model and query the endpoint
This notebook requires ipywidgets. Install ipywidgets and then use the execution role associated with the current notebook as the AWS account role with SageMaker access.
Choose the pre-trained model
We choose the bloomz-176b-fp16 pre-trained model:
The notebook in the following sections uses BloomZ 176B as an example. For a complete list of SageMaker pre-trained models, refer to Built-in Algorithms with pre-trained Model Table.
Retrieve artifacts and deploy an endpoint
With SageMaker, we can perform inference on the pre-trained model without fine-tuning it first on a new dataset. We start by retrieving the deploy_image_uri, deploy_source_uri, and model_uri for the pre-trained model. To host the pre-trained model, we create an instance of sagemaker.model.Model and deploy it. This may take a few minutes.
Now we can deploy the model using the simplified SageMaker JumpStart SDK with the following lines of code:
We use SageMaker large model inference (LMI) containers to host the BloomZ 176B model. LMI is an AWS-built LLM software stack (container) that offers easy-to-use functions and performance gain on generative AI models. It’s embedded with model parallelism, compilation, quantization, and other stacks to speed up inference. For details, refer to Deploy BLOOM-176B and OPT-30B on Amazon SageMaker with large model inference Deep Learning Containers and DeepSpeed.
Note that deploying this model requires a p4de.24xlarge instance and the deployment usually takes about 1 hour. If you don’t have quota for that instance, request a quota increate on the AWS Service Quotas console.
Query the endpoint and parse the response using various parameters to control the generated text
The input to the endpoint is any string of text formatted as JSON and encoded in utf-8 format. The output of the endpoint is a JSON file with generated text.
In the following example, we provide some sample input text. You can input any text and the model predicts the next words in the sequence. Longer sequences of text can be generated by calling the model repeatedly. The following code shows how to invoke an endpoint with these arguments:
We get the following output:
['How to make a pasta? boil a pot of water and add salt. Add the pasta to the water and cook until al dente. Drain the pasta.']
Access the model in SageMaker Studio
You can also access these models through the JumpStart landing page in Studio. This page lists available end-to-end ML solutions, pre-trained models, and example notebooks.
At the time of publishing the post, BloomZ 176B is only available in the us-east-2 Region.

You can choose the BloomZ 176B model card to view the notebook.

You can then import the notebook to run the notebook further.

Clean up
To avoid ongoing charges, delete the SageMaker inference endpoints. You can delete the endpoints via the SageMaker console or from the SageMaker Studio notebook using the following commands:
predictor.delete_model()predictor.delete_endpoint()
Conclusion
In this post, we gave an overview of the benefits of zero-shot and few-shot learning and described how prompt engineering can improve the performance of instruction-tuned models. We also showed how to easily deploy an instruction-tuned BloomZ 176B model from SageMaker JumpStart and provided examples to demonstrate how you can perform different NLP tasks using the deployed BloomZ 176B model endpoint in SageMaker.
We encourage you to deploy a BloomZ 176B model from SageMaker JumpStart and create your own prompts for NLP use cases.
To learn more about SageMaker JumpStart, check out the following:
- Zero-shot prompting for the Flan-T5 foundation model in Amazon SageMaker JumpStart
- Run text generation with Bloom and GPT models on Amazon SageMaker JumpStart
- Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart
- Run image segmentation with Amazon SageMaker JumpStart
- Run text classification with Amazon SageMaker JumpStart using TensorFlow Hub and Hugging Face models
- Amazon SageMaker JumpStart models and algorithms now available via API
- Incremental training with Amazon SageMaker JumpStart
- Transfer learning for TensorFlow object detection models in Amazon SageMaker
- Transfer learning for TensorFlow text classification models in Amazon SageMaker
- Transfer learning for TensorFlow image classification models in Amazon SageMaker
About the Authors
 Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
Rajakumar Sampathkumar is a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.
 Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
Dr. Xin Huang is an Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
 Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.
Evan Kravitz is a software engineer at Amazon Web Services, working on SageMaker JumpStart. He enjoys cooking and going on runs in New York City.
Build production-ready generative AI applications for enterprise search using Haystack pipelines and Amazon SageMaker JumpStart with LLMs
This blog post is co-written with Tuana Çelik from deepset.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. With the advent of large language models (LLMs), we can implement conversational experiences in providing the results to users. However, we need to ensure that the LLMs limit the responses to company data, thereby mitigating model hallucinations.
In this post, we showcase how to build an end-to-end generative AI application for enterprise search with Retrieval Augmented Generation (RAG) by using Haystack pipelines and the Falcon-40b-instruct model from Amazon SageMaker JumpStart and Amazon OpenSearch Service. The source code for the sample showcased in this post is available in the GitHub repository
Solution overview
To restrict the generative AI application responses to company data only, we need to use a technique called Retrieval Augmented Generation (RAG). An application using the RAG approach retrieves information most relevant to the user’s request from the enterprise knowledge base or content, bundles it as context along with the user’s request as a prompt, and then sends it to the LLM to get a response. LLMs have limitations around the maximum word count for the input prompts, so choosing the right passages among thousands or millions of documents in the enterprise has a direct impact on the LLM’s accuracy.
The RAG technique has become increasingly important in enterprise search. In this post, we show a workflow that takes advantage of SageMaker JumpStart to deploy a Falcon-40b-instruct model and uses Haystack to design and run a retrieval augmented question answering pipeline. The final retrieval augmentation workflow covers the following high-level steps:
- The user query is used for a retriever component, which does a vector search, to retrieve the most relevant context from our database.
- This context is embedded into a prompt that is designed to instruct an LLM to generate an answer only from the provided context.
- The LLM generates a response to the original query by only considering the context embedded into the prompt it received.
SageMaker JumpStart
SageMaker JumpStart serves as a model hub encapsulating a broad array of deep learning models for text, vision, audio, and embedding use cases. With over 500 models, its model hub comprises both public and proprietary models from AWS’s partners such as AI21, Stability AI, Cohere, and LightOn. It also hosts foundation models solely developed by Amazon, such as AlexaTM. Some of the models offer capabilities for you to fine-tune them with your own data. SageMaker JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for machine learning (ML) with SageMaker.
Haystack
Haystack is an open-source framework by deepset that allows developers to orchestrate LLM applications made up of different components like models, vector DBs, file converters, and countless other modules. Haystack provides pipelines and Agents, two powerful structures for designing LLM applications for various use cases including search, question answering, and conversational AI. With a big focus on state-of-the art retrieval methods and solid evaluation metrics, it provides you with everything you need to ship a reliable, trustworthy application. You can serialize pipelines to YAML files, expose them via a REST API, and scale them flexibly with your workloads, making it easy to move your application from a prototype stage to production.
Amazon OpenSearch
OpenSearch Service is a fully managed service that makes it simple to deploy, scale, and operate OpenSearch in the AWS Cloud. OpenSearch is a scalable, flexible, and extensible open-source software suite for search, analytics, security monitoring, and observability applications, licensed under the Apache 2.0 license.
In recent years, ML techniques have become increasingly popular to enhance search. Among them are the use of embedding models, a type of model that can encode a large body of data into an n-dimensional space where each entity is encoded into a vector, a data point in that space, and organized such that similar entities are closer together. A vector database provides efficient vector similarity search by providing specialized indexes like k-NN indexes.
With the vector database capabilities of OpenSearch Service, you can implement semantic search, RAG with LLMs, recommendation engines, and search rich media. In this post, we use RAG to enable us to complement generative LLMs with an external knowledge base that is typically built using a vector database hydrated with vector-encoded knowledge articles.
Application overview
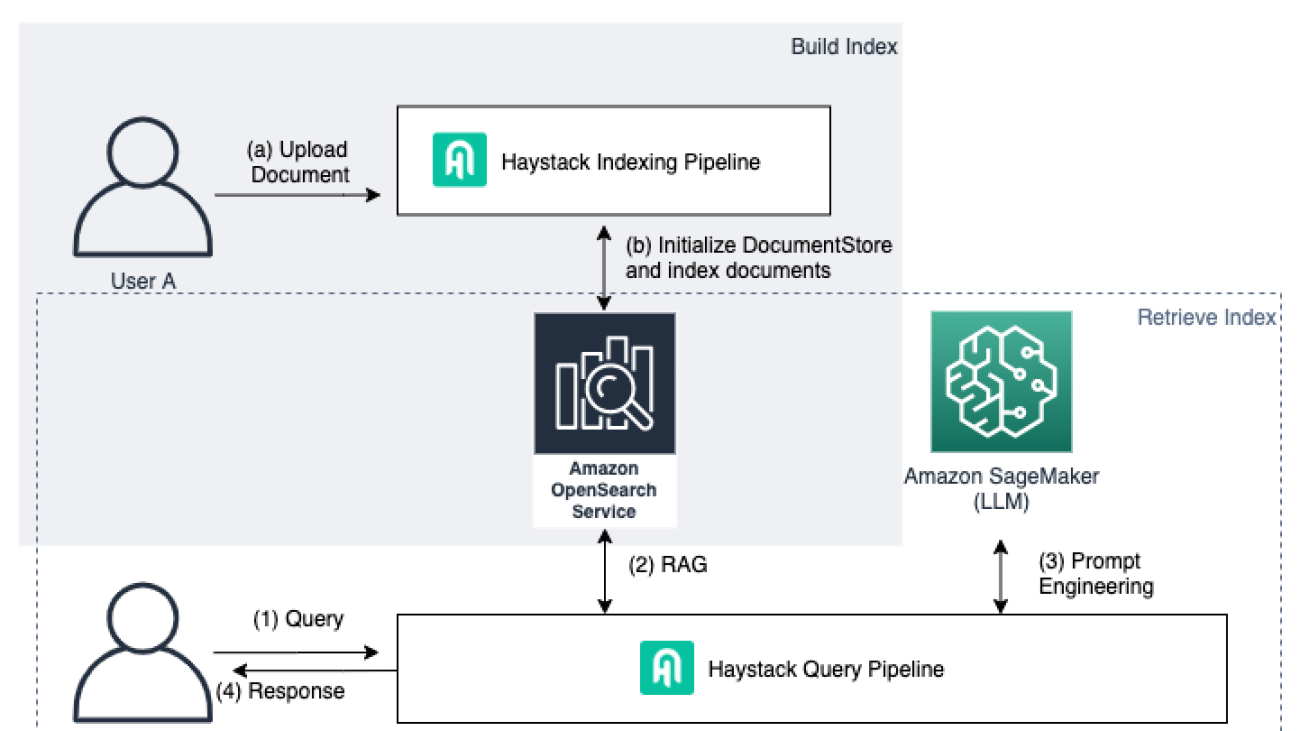
The following diagram depicts the structure of the final application.

In this application, we use the Haystack Indexing Pipeline to manage uploaded documents and index documents and the Haystack Query Pipeline to perform knowledge retrieval from indexed documents.
The Haystack Indexing Pipeline includes the following high-level steps:
- Upload a document.
- Initialize
DocumentStoreand index documents.
We use OpenSearch as our DocumentStore and a Haystack indexing pipeline to preprocess and index our files to OpenSearch. Haystack FileConverters and PreProcessor allow you to clean and prepare your raw files to be in a shape and format that your natural language processing (NLP) pipeline and language model of choice can deal with. The indexing pipeline we’ve used here also uses sentence-transformers/all-MiniLM-L12-v2 to create embeddings for each document, which we use for efficient retrieval.
The Haystack Query Pipeline includes the following high-level steps:
- We send a query to the RAG pipeline.
- An EmbeddingRetriever component acts as a filter that retrieves the most relevant
top_kdocuments from our indexed documents in OpenSearch. We use our choice of embedding model to embed both the query and the documents (at indexing) to achieve this. - The retrieved documents are embedded into our prompt to the Falcon-40b-instruct model.
- The LLM returns with a response that is based on the retrieved documents.
For model deployment, we use SageMaker JumpStart, which simplifies deploying models through a simple push of a button. Although we’ve used and tested Falcon-40b-instruct for this example, you may use any Hugging Face model available on SageMaker.
The final solution is available on the haystack-sagemaker repository and uses the OpenSearch website and documentation (for OpenSearch 2.7) as our example data to perform retrieval augmented question answering on.
Prerequisites
The first thing to do before we can use any AWS services is to make sure we have signed up for and created an AWS account. Then you should create an administrative user and group. For instructions on both steps, refer to Set Up Amazon SageMaker Prerequisites.
To be able to use the Haystack, you’ll have to install the farm-haystack package with the required dependencies. To accomplish this, use the requirements.txt file in the GitHub repository by running pip install requirements.txt.
Index documents to OpenSearch
Haystack offers a number of connectors to databases, which are called DocumentStores. For this RAG workflow, we use the OpenSearchDocumentStore. The example repository includes an indexing pipeline and AWS CloudFormation template to set up an OpenSearchDocumentStore with documents crawled from the OpenSearch website and documentation pages.
Often, to get an NLP application working for production use cases, we end up having to think about data preparation and cleaning. This is covered with Haystack indexing pipelines, which allows you to design your own data preparation steps, which ultimately write your documents to the database of your choice.
An indexing pipeline may also include a step to create embeddings for your documents. This is highly important for the retrieval step. In our example, we use sentence-transformers/all-MiniLM-L12-v2 as our embedding model. This model is used to create embeddings for all our indexed documents, but also the user’s query at query time.
To index documents into the OpenSearchDocumentStore, we provide two options with detailed instructions in the README of the example repository. Here, we walk through the steps for indexing to an OpenSearch service deployed on AWS.
Start an OpenSearch service
Use the provided CloudFormation template to set up an OpenSearch service on AWS. By running the following command, you’ll have an empty OpenSearch service. You can then either choose to index the example data we’ve provided or use your own data, which you can clean and preprocess using the Haystack Indexing Pipeline. Note that this creates an instance that is open to the internet, which is not recommended for production use.
Allow approximately 30 minutes for the stack launch to complete. You can check its progress on the AWS CloudFormation console by navigating to the Stacks page and looking for the stack named HaystackOpensearch.
Index documents into OpenSearch
Now that we have a running OpenSearch service, we can use the OpenSearchDocumentStore class to connect to it and write our documents to it.
To get the hostname for OpenSearch, run the following command:
First, export the following:
Then, you can use the opensearch_indexing_pipeline.py script to preprocess and index the provided demo data.
If you would like to use your own data, modify the indexing pipeline in opensearch_indexing_pipeline.py to include the FileConverter and PreProcessor setup steps you require.
Implement the retrieval augmented question answering pipeline
Now that we have indexed data in OpenSearch, we can perform question answering on these documents. For this RAG pipeline, we use the Falcon-40b-instruct model that we’ve deployed on SageMaker JumpStart.
You also have the option of deploying the model programmatically from a Jupyter notebook. For instructions, refer to the GitHub repo.
- Search for the Falcon-40b-instruct model on SageMaker JumpStart.

- Deploy your model on SageMaker JumpStart, and take note of the endpoint name.

- Export the following values:
- Run
python rag_pipeline.py.
This will start a command line utility that waits for a user’s question. For example, let’s ask “How can I install the OpenSearch cli?”

This result is achieved because we have defined our prompt in the Haystack PromptTemplate to be the following:
Further customizations
You can make additional customizations to different elements in the solution, such as the following:
- The data – We’ve provided the OpenSearch documentation and website data as example data. Remember to modify the
opensearch_indexing_pipeline.pyscript to fit your needs if you chose to use your own data. - The model – In this example, we’ve used the Falcon-40b-instruct model. You are free to deploy and use any other Hugging Face model on SageMaker. Note that changing a model will likely mean you should adapt your prompt to something it’s designed to handle.
- The prompt – For this post, we created our own
PromptTemplatethat instructs the model to answer questions based on the provided context and answer “I don’t know” if the context doesn’t include relevant information. You may change this prompt to experiment with different prompts with Falcon-40b-instruct. You can also simply pull some of our prompts from the PromptHub. - The embedding model – For the retrieval step, we use a lightweight embedding model: sentence-transformers/all-MiniLM-L12-v2. However, you may also change this to your needs. Remember to modify the expected embedding dimensions in your
DocumentStoreaccordingly. - The number of retrieved documents – You may also choose to play around with the number of documents you ask the
EmbeddingRetrieverto retrieve for each query. In our setup, this is set to top_k=5. You may experiment with changing this figure to see if providing more context improves the accuracy of your results.
Production readiness
The proposed solution in this post can accelerate the time to value of the project development process. You can build a project that is easy to scale with the security and privacy environment on the AWS Cloud.
For security and privacy, OpenSearch Service provides data protection with identity and access management and cross-service confused proxy prevention. You may employ fine-grained user access control so that the user can only access the data they are authorized to access. Additionally, SageMaker provides configurable security settings for access control, data protection, and logging and monitoring. You can protect your data at rest and in transit with AWS Key Management Service (AWS KMS) keys. You can also track the log of SageMaker model deployment or endpoint access using Amazon CloudWatch. For more information, refer to Monitor Amazon SageMaker with Amazon CloudWatch.
For the high scalability on OpenSearch Service, you may adjust it by sizing your OpenSearch Service domains and employing operational best practices. You can also take advantage of auto scaling your SageMaker endpoint—you can automatically scale SageMaker models to adjust the endpoint both when the traffic is increased or the resources are not being used.
Clean up
To save costs, delete all the resources you deployed as part of this post. If you launched the CloudFormation stack, you can delete it via the AWS CloudFormation console. Similarly, you can delete any SageMaker endpoints you may have created via the SageMaker console.
Conclusion
In this post, we showcased how to build an end-to-end generative AI application for enterprise search with RAG by using Haystack pipelines and the Falcon-40b-instruct model from SageMaker JumpStart and OpenSearch Service. The RAG approach is critical in enterprise search because it ensures that the responses generated are in-domain and therefore mitigating hallucinations. By using Haystack pipelines, we are able to orchestrate LLM applications made up of different components like models and vector databases. SageMaker JumpStart provides us with a one-click solution for deploying LLMs, and we used OpenSearch Service as the vector database for our indexed data. You can start experimenting and building RAG proofs of concept for your enterprise generative AI applications, using the steps outlined in this post and the source code available in the GitHub repository.
About the Authors
 Tuana Celik is the Lead Developer Advocate at deepset, where she focuses on the open-source community for Haystack. She leads the developer relations function and regularly speaks at events about NLP and creates learning materials for the community.
Tuana Celik is the Lead Developer Advocate at deepset, where she focuses on the open-source community for Haystack. She leads the developer relations function and regularly speaks at events about NLP and creates learning materials for the community.
 Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
Roy Allela is a Senior AI/ML Specialist Solutions Architect at AWS based in Munich, Germany. Roy helps AWS customers—from small startups to large enterprises—train and deploy large language models efficiently on AWS. Roy is passionate about computational optimization problems and improving the performance of AI workloads.
 Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is an ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
 Inaam Syed is a Startup Solutions Architect at AWS, with a strong focus on assisting B2B and SaaS startups in scaling and achieving growth. He possesses a deep passion for serverless architectures and AI/ML. In his leisure time, Inaam enjoys quality moments with his family and indulges in his love for biking and badminton.
Inaam Syed is a Startup Solutions Architect at AWS, with a strong focus on assisting B2B and SaaS startups in scaling and achieving growth. He possesses a deep passion for serverless architectures and AI/ML. In his leisure time, Inaam enjoys quality moments with his family and indulges in his love for biking and badminton.
 David Tippett is the Senior Developer Advocate working on open-source OpenSearch at AWS. His work involves all areas of OpenSearch from search and relevance to observability and security analytics.
David Tippett is the Senior Developer Advocate working on open-source OpenSearch at AWS. His work involves all areas of OpenSearch from search and relevance to observability and security analytics.
Improving the Quality of Neural TTS Using Long-form Content and Multi-speaker Multi-style Modeling
Neural text-to-speech (TTS) can provide quality close to natural speech if an adequate amount of high-quality speech material is available for training. However, acquiring speech data for TTS training is costly and time-consuming, especially if the goal is to generate different speaking styles. In this work, we show that we can transfer speaking style across speakers and improve the quality of synthetic speech by training a multi-speaker multi-style (MSMS) model with long-form recordings, in addition to regular TTS recordings. In particular, we show that 1) multi-speaker modeling improves the…Apple Machine Learning Research
Amazon Translate enhances its custom terminology to improve translation accuracy and fluency
Amazon Translate is a neural machine translation service that delivers fast, high-quality, affordable, and customizable language translation. When you translate from one language to another, you want your machine translation to be accurate, fluent, and most importantly contextual. Domain-specific and language-specific customizable terminology is a key requirement for many government and commercial organizations.
Custom terminology enables you to customize your translation output such that your domain and organization-specific vocabulary, such as brand names, character names, model names, and other unique content (named entities), are translated exactly the way you need. To use the custom terminology feature, you should create a terminology file (CSV or TMX file format) and specify the custom terminology as a parameter in an Amazon Translate real-time translation or asynchronous batch processing request. Refer to Customize Amazon Translate output to meet your domain and organization specific vocabulary to get started on custom terminology.
In this post, we explore key enhancements to custom terminology, which doesn’t just do a simple match and replace but adds context-sensitive match and replace, which preserves the sentence construct. This enhancement aims to create contextually appropriate versions of matching target terms to generate translations of higher quality and fluency.
Solution overview
We use the following custom terminology file to explore the enhanced custom terminology features. For instructions on creating a custom terminology, refer to Customize Amazon Translate output to meet your domain and organization specific vocabulary.
| en | fr | es |
| tutor | éducateur | tutor |
| sheep | agneau | oveja |
| walking | promenant | para caminar |
| burger | sandwich | hamburguesa |
| action-specific | spécifique à l’action | especifico de acción |
| order | commande | commande |
Exploring the custom terminology feature
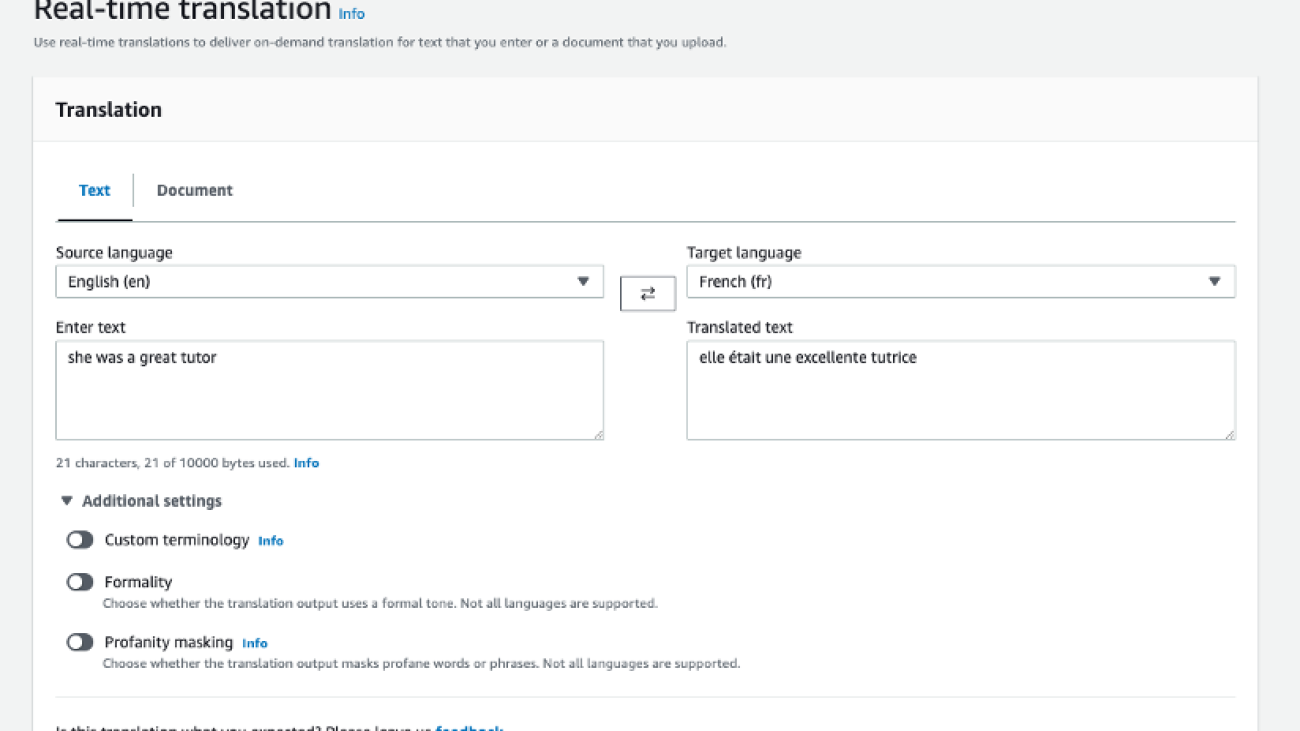
Let’s translate the sentence “she was a great tutor” with Amazon Translate. Complete the following steps:
- On Amazon Translate console, choose Real-time translation in the navigation pane.
- Choose the Text tab.
- For Target language, choose French.
- Enter the text “she was a great tutor.”
As shown in the following screenshot, the translation in French as “elle était une excellente tutrice.”

- Under Additional settings¸ select Custom terminology and choose your custom terminology file.
The translation in French is changed to “elle était une excellente éducatrice.”

In the custom terminology file, we have specified the translation for “tutor” as “éducateur.” “Éducateur” is masculine in French, whereas “tutor” in English is gender neutral. Custom terminology did not perform a match and replace here, instead it used the target word and applied the correct gender based on the context.
Now let’s test the feature with the source sentence “he has 10 sheep.” The translation in French is “il a 10 agneaux.” We provided custom terminology for “sheep” as “agneau.” “Agneau” in French means “baby sheep” and is singular. In this case, the target word is changed to inflect plural.
The source sentence “walking in the evening is precious to me” is translated to “me promener le soir est précieux pour moi.” The custom terminology target word “promenant” is changed to “promener” to inflect the correct verb tense.
The source sentence “I like burger” will be translated to “J’aime les sandwichs” to inflect the correct noun based on the context.
Now let’s test sentences with the target language as Spanish.
The source sentence “any action-specific parameters are listed in the topic for that action” is translated to “odos los parámetros especificos de acción aparecen en el tema de esa acción” to inflect the correct adjective.
The source sentence “in order for us to help you, please share your name” will be translated to “pour que nous puissions vous aider, veuillez partager votre nom.”
Some words may have entirely different meanings based on context. For example, the word “order” in English can be a sequence (as is in the source sentence) or a command or instruction (as in “I order books”). It’s difficult to know which meaning is intended without explicit information. In this case, “order” should not be translated as “commande” because it means “command” or “instruct” in French.
Conclusion
The custom terminology feature in Amazon Translate can help you customize translations based on your domain or language constructs. Recent enhancements to the custom terminology feature create contextually appropriate versions of matching terms to generate translations of higher quality. This enhancement improves the translation accuracy and fluency. There is no change required for existing customers to use the enhanced feature.
For more information about Amazon Translate, visit Amazon Translate resources to find video resources and blog posts, and refer to AWS Translate FAQs.
About the Authors
 Sathya Balakrishnan is a Senior Consultant in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Senior Consultant in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Sid Padgaonkar is the Senior Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him playing squash and exploring the food scene in the Pacific Northwest.
Sid Padgaonkar is the Senior Product Manager for Amazon Translate, AWS’s natural language processing service. On weekends, you will find him playing squash and exploring the food scene in the Pacific Northwest.
Zero-shot text classification with Amazon SageMaker JumpStart
Natural language processing (NLP) is the field in machine learning (ML) concerned with giving computers the ability to understand text and spoken words in the same way as human beings can. Recently, state-of-the-art architectures like the transformer architecture are used to achieve near-human performance on NLP downstream tasks like text summarization, text classification, entity recognition, and more.
Large language models (LLMs) are transformer-based models trained on a large amount of unlabeled text with hundreds of millions (BERT) to over a trillion parameters (MiCS), and whose size makes single-GPU training impractical. Due to their inherent complexity, training an LLM from scratch is a very challenging task that very few organizations can afford. A common practice for NLP downstream tasks is to take a pre-trained LLM and fine-tune it. For more information about fine-tuning, refer to Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data and Fine-tune transformer language models for linguistic diversity with Hugging Face on Amazon SageMaker.
Zero-shot learning in NLP allows a pre-trained LLM to generate responses to tasks that it hasn’t been explicitly trained for (even without fine-tuning). Specifically speaking about text classification, zero-shot text classification is a task in natural language processing where an NLP model is used to classify text from unseen classes, in contrast to supervised classification, where NLP models can only classify text that belong to classes in the training data.
We recently launched zero-shot classification model support in Amazon SageMaker JumpStart. SageMaker JumpStart is the ML hub of Amazon SageMaker that provides access to pre-trained foundation models (FMs), LLMs, built-in algorithms, and solution templates to help you quickly get started with ML. In this post, we show how you can perform zero-shot classification using pre-trained models in SageMaker Jumpstart. You will learn how to use the SageMaker Jumpstart UI and SageMaker Python SDK to deploy the solution and run inference using the available models.
Zero-shot learning
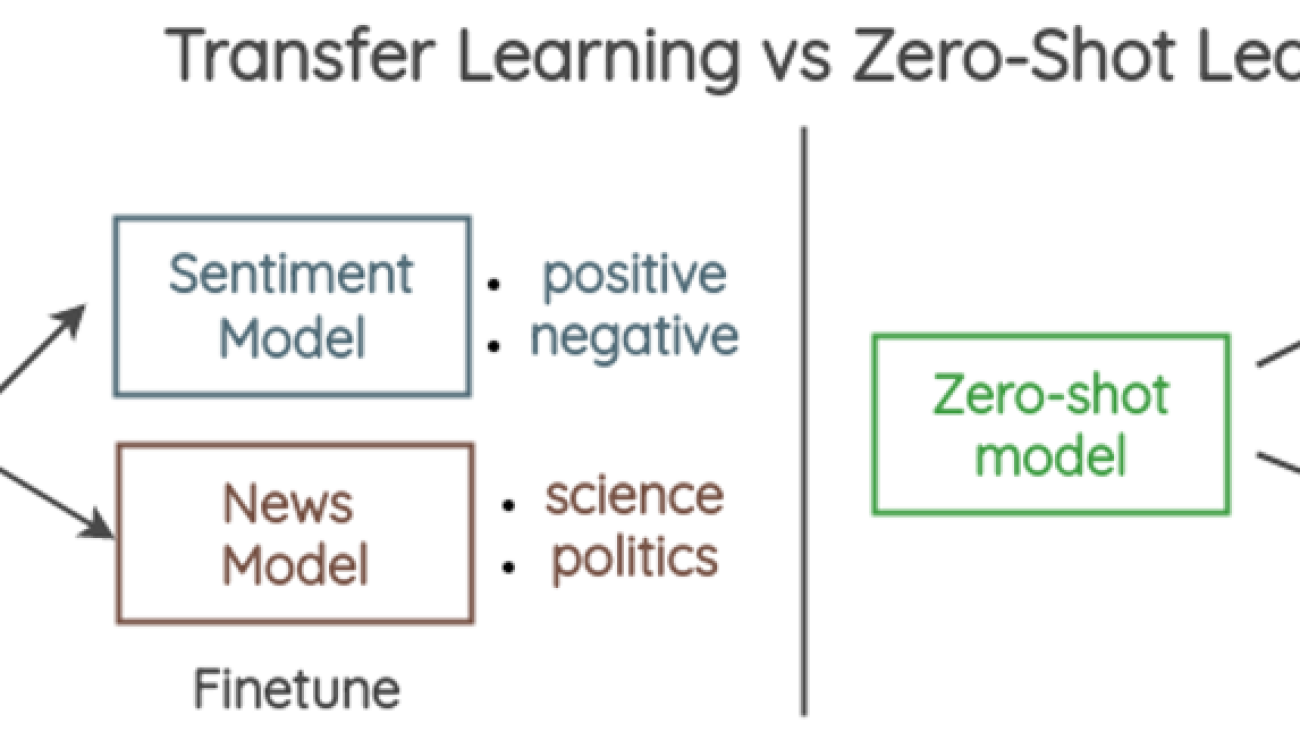
Zero-shot classification is a paradigm where a model can classify new, unseen examples that belong to classes that were not present in the training data. For example, a language model that has beed trained to understand human language can be used to classify New Year’s resolutions tweets on multiple classes like career, health, and finance, without the language model being explicitly trained on the text classification task. This is in contrast to fine-tuning the model, since the latter implies re-training the model (through transfer learning) while zero-shot learning doesn’t require additional training.
The following diagram illustrates the differences between transfer learning (left) vs. zero-shot learning (right).

Yin et al. proposed a framework for creating zero-shot classifiers using natural language inference (NLI). The framework works by posing the sequence to be classified as an NLI premise and constructs a hypothesis from each candidate label. For example, if we want to evaluate whether a sequence belongs to the class politics, we could construct a hypothesis of “This text is about politics.” The probabilities for entailment and contradiction are then converted to label probabilities. As a quick review, NLI considers two sentences: a premise and a hypothesis. The task is to determine whether the hypothesis is true (entailment) or false (contradiction) given the premise. The following table provides some examples.
| Premise | Label | Hypothesis |
| A man inspects the uniform of a figure in some East Asian country. | Contradiction | The man is sleeping. |
| An older and younger man smiling. | Neutral | Two men are smiling and laughing at the cats playing on the floor. |
| A soccer game with multiple males playing. | entailment | Some men are playing a sport. |
Solution overview
In this post, we discuss the following:
- How to deploy pre-trained zero-shot text classification models using the SageMaker JumpStart UI and run inference on the deployed model using short text data
- How to use the SageMaker Python SDK to access the pre-trained zero-shot text classification models in SageMaker JumpStart and use the inference script to deploy the model to a SageMaker endpoint for a real-time text classification use case
- How to use the SageMaker Python SDK to access pre-trained zero-shot text classification models and use SageMaker batch transform for a batch text classification use case
SageMaker JumpStart provides one-click fine-tuning and deployment for a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. These features remove the heavy lifting from each step of the ML process, simplifying the development of high-quality models and reducing time to deployment. The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets.
The JumpStart model hub provides access to a large number of NLP models that enable transfer learning and fine-tuning on custom datasets. As of this writing, the JumpStart model hub contains over 300 text models across a variety of popular models, such as Stable Diffusion, Flan T5, Alexa TM, Bloom, and more.
Note that by following the steps in this section, you will deploy infrastructure to your AWS account that may incur costs.
Deploy a standalone zero-shot text classification model
In this section, we demonstrate how to deploy a zero-shot classification model using SageMaker JumpStart. You can access pre-trained models through the JumpStart landing page in Amazon SageMaker Studio. Complete the following steps:
- In SageMaker Studio, open the JumpStart landing page.
Refer to Open and use JumpStart for more details on how to navigate to SageMaker JumpStart. - In the Text Models carousel, locate the “Zero-Shot Text Classification” model card.
- Choose View model to access the
facebook-bart-large-mnlimodel.
Alternatively, you can search for the zero-shot classification model in the search bar and get to the model in SageMaker JumpStart. - Specify a deployment configuration, SageMaker hosting instance type, endpoint name, Amazon Simple Storage Service (Amazon S3) bucket name, and other required parameters.
- Optionally, you can specify security configurations like AWS Identity and Access Management (IAM) role, VPC settings, and AWS Key Management Service (AWS KMS) encryption keys.
- Choose Deploy to create a SageMaker endpoint.
This step takes a couple of minutes to complete. When it’s complete, you can run inference against the SageMaker endpoint that hosts the zero-shot classification model.
In the following video, we show a walkthrough of the steps in this section.
Use JumpStart programmatically with the SageMaker SDK
In the SageMaker JumpStart section of SageMaker Studio, under Quick start solutions, you can find the solution templates. SageMaker JumpStart solution templates are one-click, end-to-end solutions for many common ML use cases. As of this writing, over 20 solutions are available for multiple use cases, such as demand forecasting, fraud detection, and personalized recommendations, to name a few.
The “Zero Shot Text Classification with Hugging Face” solution provides a way to classify text without the need to train a model for specific labels (zero-shot classification) by using a pre-trained text classifier. The default zero-shot classification model for this solution is the facebook-bart-large-mnli (BART) model. For this solution, we use the 2015 New Year’s Resolutions dataset to classify resolutions. A subset of the original dataset containing only the Resolution_Category (ground truth label) and the text columns is included in the solution’s assets.

The input data includes text strings, a list of desired categories for classification, and whether the classification is multi-label or not for synchronous (real-time) inference. For asynchronous (batch) inference, we provide a list of text strings, the list of categories for each string, and whether the classification is multi-label or not in a JSON lines formatted text file.

The result of the inference is a JSON object that looks something like the following screenshot.

We have the original text in the sequence field, the labels used for the text classification in the labels field, and the probability assigned to each label (in the same order of appearance) in the field scores.
To deploy the Zero Shot Text Classification with Hugging Face solution, complete the following steps:
- On the SageMaker JumpStart landing page, choose Models, notebooks, solutions in the navigation pane.
- In the Solutions section, choose Explore All Solutions.

- On the Solutions page, choose the Zero Shot Text Classification with Hugging Face model card.
- Review the deployment details and if you agree, choose Launch.



The deployment will provision a SageMaker real-time endpoint for real-time inference and an S3 bucket for storing the batch transformation results.
The following diagram illustrates the architecture of this method.

Perform real-time inference using a zero-shot classification model
In this section, we review how to use the Python SDK to run zero-shot text classification (using any of the available models) in real time using a SageMaker endpoint.
- First, we configure the inference payload request to the model. This is model dependent, but for the BART model, the input is a JSON object with the following structure:
- Note that the BART model is not explicitly trained on the
candidate_labels. We will use the zero-shot classification technique to classify the text sequence to unseen classes. The following code is an example using text from the New Year’s resolutions dataset and the defined classes: - Next, you can invoke a SageMaker endpoint with the zero-shot payload. The SageMaker endpoint is deployed as part of the SageMaker JumpStart solution.
- The inference response object contains the original sequence, the labels sorted by score from max to min, and the scores per label:
Run a SageMaker batch transform job using the Python SDK
This section describes how to run batch transform inference with the zero-shot classification facebook-bart-large-mnli model using the SageMaker Python SDK. Complete the following steps:
- Format the input data in JSON lines format and upload the file to Amazon S3.
SageMaker batch transform will perform inference on the data points uploaded in the S3 file. - Set up the model deployment artifacts with the following parameters:
- model_id – Use
huggingface-zstc-facebook-bart-large-mnli. - deploy_image_uri – Use the
image_urisPython SDK function to get the pre-built SageMaker Docker image for themodel_id. The function returns the Amazon Elastic Container Registry (Amazon ECR) URI. - deploy_source_uri – Use the
script_urisutility API to retrieve the S3 URI that contains scripts to run pre-trained model inference. We specify thescript_scopeasinference. - model_uri – Use
model_urito get the model artifacts from Amazon S3 for the specifiedmodel_id.
- model_id – Use
- Use
HF_TASKto define the task for the Hugging Face transformers pipeline andHF_MODEL_IDto define the model used to classify the text:For a complete list of tasks, see Pipelines in the Hugging Face documentation.
- Create a Hugging Face model object to be deployed with the SageMaker batch transform job:
- Create a transform to run a batch job:
- Start a batch transform job and use S3 data as input:
You can monitor your batch processing job on the SageMaker console (choose Batch transform jobs under Inference in the navigation pane). When the job is complete, you can check the model prediction output in the S3 file specified in output_path.
For a list of all the available pre-trained models in SageMaker JumpStart, refer to Built-in Algorithms with pre-trained Model Table. Use the keyword “zstc” (short for zero-shot text classification) in the search bar to locate all the models capable of doing zero-shot text classification.
Clean up
After you’re done running the notebook, make sure to delete all resources created in the process to ensure that the costs incurred by the assets deployed in this guide are stopped. The code to clean up the deployed resources is provided in the notebooks associated with the zero-shot text classification solution and model.
Default security configurations
The SageMaker JumpStart models are deployed using the following default security configurations:
- The models are deployed with a default SageMaker execution role. You can specify your own role or use an existing one. For more information, refer to SageMaker Roles.
- The model will not connect to a VPC and no VPC will be provisioned for your model. You can specify VPC configuration to connect to your model from within the security options. For more information, see Give SageMaker Hosted Endpoints Access to Resources in Your Amazon VPC.
- Default KMS keys will be used to encrypt your model’s artifacts. You can specify your own KMS keys or use existing one. For more information, refer to Using server-side encryption with AWS KMS keys (SSE-KMS).
To learn more about SageMaker security-related topics, check out Configure security in Amazon SageMaker.
Conclusion
In this post, we showed you how to deploy a zero-shot classification model using the SageMaker JumpStart UI and perform inference using the deployed endpoint. We used the SageMaker JumpStart New Year’s resolutions solution to show how you can use the SageMaker Python SDK to build an end-to-end solution and implement zero-shot classification application. SageMaker JumpStart provides access to hundreds of pre-trained models and solutions for tasks like computer vision, natural language processing, recommendation systems, and more. Try out the solution on your own and let us know your thoughts.
About the authors
 David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
David Laredo is a Prototyping Architect at AWS Envision Engineering in LATAM, where he has helped develop multiple machine learning prototypes. Previously, he has worked as a Machine Learning Engineer and has been doing machine learning for over 5 years. His areas of interest are NLP, time series, and end-to-end ML.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Dr. Vivek Madan is an Applied Scientist with the Amazon SageMaker JumpStart team. He got his PhD from University of Illinois at Urbana-Champaign and was a Post Doctoral Researcher at Georgia Tech. He is an active researcher in machine learning and algorithm design and has published papers in EMNLP, ICLR, COLT, FOCS, and SODA conferences.
Voice Trigger System for Siri
Apple Machine Learning Research
Interspeech Conference 2023
Apple Machine Learning Research

10 helpful ways to use Bard
 Check out 10 ways Bard can help you get things done, from brainstorming ideas to planning trip itineraries.Read More
Check out 10 ways Bard can help you get things done, from brainstorming ideas to planning trip itineraries.Read More
Microsoft at KDD 2023: Advancing health at the speed of AI
This content was given as a keynote at the Workshop of Applied Data Science for Healthcare and covered during a tutorial at the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, a premier forum for advancement, education, and adoption of the discipline of knowledge discovering and data mining.
-
Group
Real-world Evidence
Recent and noteworthy advancements in generative AI and large language models (LLMs) are leading to profound transformations in various domains. This blog explores how these breakthroughs can accelerate progress in precision health. In addition to the keynote I delivered, “Applications and New Fronters of Generative Models for Healthcare,” it includes part of a tutorial (LS-21) being given at KDD 2023. This tutorial surveys the broader research area of “Precision Health at the Age of Large Language Models,” delivered by Sheng Zhang, Javier González Hernández, Tristan Naumann, and myself.
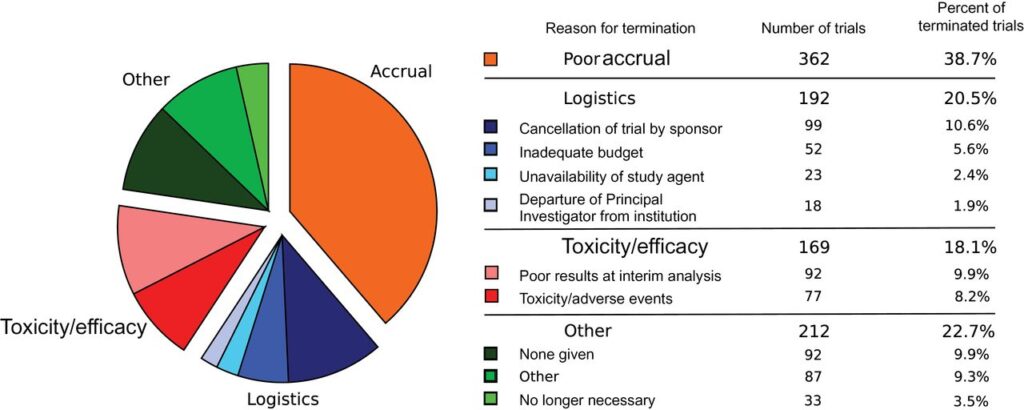
A longstanding objective within precision health is the development of a continuous learning system capable of seamlessly integrating novel information to enhance healthcare delivery and expedite advancements in biomedicine. The National Academy of Medicine has gathered leading experts to explore this key initiative, as documented in its Learning Health System series. However, the current state of health systems is far removed from this ideal. The burden of extensive unstructured data and labor-intensive manual processing hinder progress. This is evident, for instance, in the context of cancer treatment, where the traditional standard of care frequently falls short, leaving clinical trials as a last resort. Yet a lack of awareness renders these trials inaccessible, with only 3 percent of US patients finding a suitable trial. This enrollment deficiency contributes to nearly 40 percent of trial failures, as shown in Figure 1. Consequently, the process of drug discovery is exceedingly slow, demanding billions of dollars and a timeline of over a decade.
On an encouraging note, advances in generative AI provide unparalleled opportunities in harnessing real-world observational data to improve patient care—a long-standing goal in the realm of real-world evidence (RWE), which the US Food and Drug Administration (FDA) relies on to monitor and evaluate post-market drug safety. Large language models (LLMs) like GPT-4 have the capability of “universal structuring,” enabling efficient abstraction of patient information from clinical text at a large scale. This potential can be likened to the transformative impact LLMs are currently making in other domains, such as software development and productivity tools.
Microsoft Research Podcast

Collaborators: Holoportation communication technology with Spencer Fowers and Kwame Darko
communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
Digital transformation leads to an intelligence revolution
The large-scale digitization of human knowledge on the internet has facilitated the pretraining of powerful large language models. As a result, we are witnessing revolutionary changes in general software categories like programming and search. Similarly, the past couple of decades have seen rapid digitization in biomedicine, with advancements like sequencing technologies, electronic medical records (EMRs), and health sensors. By unleashing the power of generative AI in the field of biomedicine, we can achieve similarly amazing transformations in precision health, as shown in Figure 2.
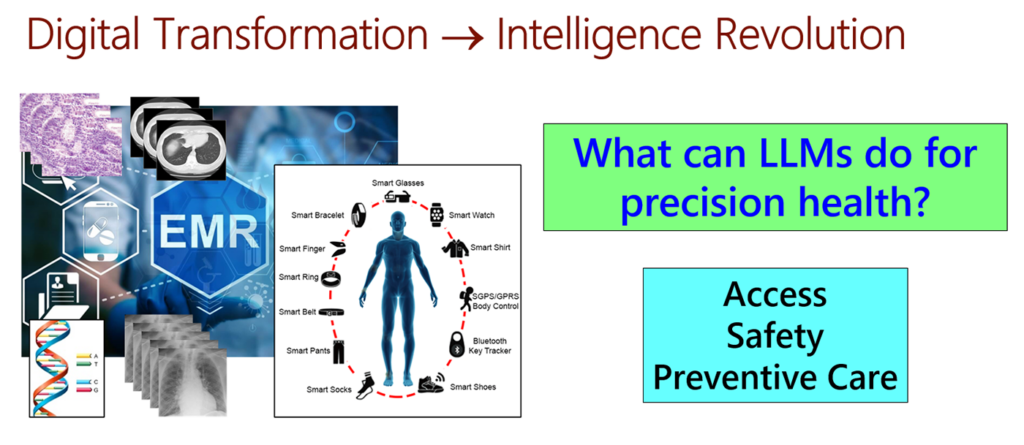
Microsoft is at the forefront of exploring the applications of LLMs in the health field, as depicted in Figure 3. Our PubMedBERT models, pretrained on biomedical abstracts and full texts, were released three years ago. They have sparked immense interest in biomedical pretraining and continue to receive an overwhelming number of downloads each month, with over one million in July 2023 alone. Numerous recent investigations have followed suit, delving deeper into this promising direction. Now, with next-generation models like GPT-4 being widely accessible, progress can be further accelerated.
Although pretrained on general web content, GPT-4 has demonstrated impressive competence in biomedical tasks straightaway and has the potential to perform previously unseen natural language processing (NLP) tasks in the biomedical domain with exceptional accuracy. Notably, research studies show that GPT-4 can achieve expert-level performance on medical question-answer datasets, like MedQA (USMLE exam), without the need for costly task-specific fine-tuning or intricate self-refinement.
Similarly, with simple prompts, GPT-4 can effectively structure complex clinical trial matching logic from eligibility criteria, surpassing prior state-of-the-art systems like Criteria2Query, which were specifically designed for this purpose, as shown in Figure 4.
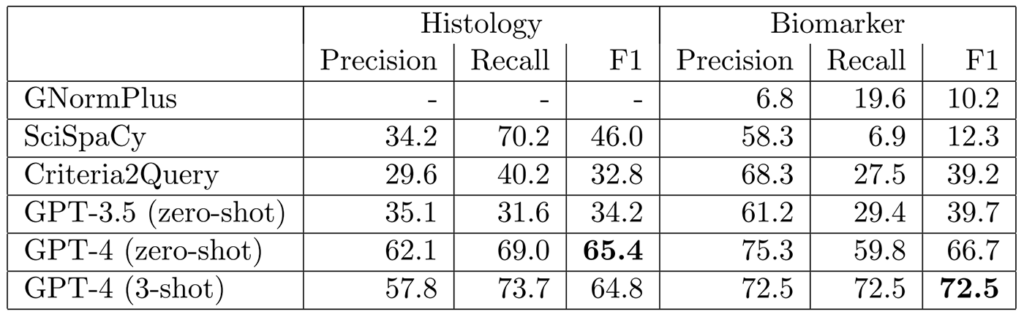
Transforming real-world data into a discovery engine
In the context of clinical trial matching, besides structuring trial eligibility criteria, the bigger challenge lies in structuring patient records at scale. Cancer patients may have hundreds of notes where critical information like histopathology or staging may be scattered across multiple entries, as shown in Figure 5. To tackle this, Microsoft and Providence, a large US-based health system, have developed state-of-the-art self-supervised LLMs like OncoBERT to extract such details. More recently, preliminary studies have found that GPT-4 can also excel at structuring such vital information. Drawing on these advancements, we developed a research system for clinical trial matching, powered by LLMs. This system is now used daily on a molecular tumor board at Providence, as well as in high-profile trials such as this adoptive T-cell trial, as reported by the New York Times.
Clinical trial matching is important in its own right, and the same underlying technologies can be used to unlock other beneficial applications. For example, in collaboration with Providence researchers, we demonstrated how real-world data can be harnessed to simulate prominent lung cancer trials under various eligibility settings. By combining the structuring capabilities of LLMs with state-of-the-art causal inference methods, we effectively transform real-world data into a discovery engine. This enables instant evaluation of clinical hypotheses, with applications spanning clinical trial design, synthetic control, post-market surveillance, comparative effectiveness, among others.
Towards precision health copilots
The significance of generative AI lies not in achieving incremental improvements, but in enabling entirely new possibilities in applications. LLM’s universal structuring capability allows for the scaling of RWE generation from patient data at the population level. Additionally, LLMs can serve as “universal annotators,” generating examples from unlabeled data to train high-performance student models. Furthermore, LLMs possess remarkable reasoning capabilities, functioning as “universal reasoners” and accelerating causal discovery from real-world data at the population level. These models can also fact-check their own answers, providing easily verifiable rationale to enhance their accuracy and facilitate human-in-the-loop verification and interactive learning.
Beyond textual data, there is immense growth potential for LLMs in health applications, particularly when dealing with multimodal and longitudinal patient data. Crucial patient information may reside in various information-rich modalities, such as imaging and multi-omics. We have explored pretraining large biomedical multimodal models by assembling the largest collection of public biomedical image-text pairs from biomedical research articles, comprising 15 million images and over 30 million image-text pairs. Recently, we investigated using GPT-4 to generate instruction-following data to train a multimodal conversational copilot called LLaVA-Med, enabling researchers to interact with biomedical imaging data. Additionally, we are collaborating with clinical stakeholders to train LMMs for precision immuno-oncology, utilizing multimodal fusion to combine EMRs, radiology images, digital pathology, and multi-omics in longitudinal data on cancer patients.
Our ultimate aspiration is to develop precision health copilots that empower all stakeholders in biomedicine and scale real-world evidence generation, optimizing healthcare delivery and accelerating discoveries. We envision a future where clinical research and care are seamlessly integrated, where every clinical observation instantly updates a patient’s health status, and decisions are supported by population-level patient-like-me information. Patients in need of advanced intervention are continuously evaluated for just-in-time clinical trial matching. Life sciences researchers have access to a global real-world data dashboard in real time, initiating in silico trials to generate and test counterfactual hypotheses. Payors and regulators base approval and care decisions on the most comprehensive and up-to-date clinical evidence at the finest granular level. This vision embodies the dream of evidence-based precision health. Generative AI, including large language models, will play a pivotal role in propelling us towards this exciting and transformative future.
The post Microsoft at KDD 2023: Advancing health at the speed of AI appeared first on Microsoft Research.