Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to…Apple Machine Learning Research
Consistent Collaborative Filtering via Tensor Decomposition
Collaborative filtering is the de facto standard for analyzing users’ activities and building recommendation systems for items. In this work we develop Sliced Anti-symmetric Decomposition (SAD), a new model for collaborative filtering based on implicit feedback. In contrast to traditional techniques where a latent representation of users (user vectors) and items (item vectors) are estimated, SAD introduces one additional latent vector to each item, using a novel three-way tensor view of user-item interactions. This new vector ex-tends user-item preferences calculated by standard dot products…Apple Machine Learning Research
Dataset and Network Introspection ToolKit (DNIKit)
We introduce the Data and Network Introspection toolkit DNIKit, an open source Python framework for analyzing machine learning models and datasets. DNIKit contains a collection of algorithms that all operate on intermediate network responses, providing a unique understanding of how the network perceives data throughout the different stages of computation.
With DNIKit, you can:
create a comprehensive dataset analysis report
find dataset samples that are near duplicates of each other
discover rare data samples, annotation errors, or model biases
compress networks by removing highly correlated…Apple Machine Learning Research

STUDY: Socially aware temporally causal decoder recommender systems
Reading has many benefits for young students, such as better linguistic and life skills, and reading for pleasure has been shown to correlate with academic success. Furthermore students have reported improved emotional wellbeing from reading, as well as better general knowledge and better understanding of other cultures. With the vast amount of reading material both online and off, finding age-appropriate, relevant and engaging content can be a challenging task, but helping students do so is a necessary step to engage them in reading. Effective recommendations that present students with relevant reading material helps keep students reading, and this is where machine learning (ML) can help.
ML has been widely used in building recommender systems for various types of digital content, ranging from videos to books to e-commerce items. Recommender systems are used across a range of digital platforms to help surface relevant and engaging content to users. In these systems, ML models are trained to suggest items to each user individually based on user preferences, user engagement, and the items under recommendation. These data provide a strong learning signal for models to be able to recommend items that are likely to be of interest, thereby improving user experience.
In “STUDY: Socially Aware Temporally Causal Decoder Recommender Systems”, we present a content recommender system for audiobooks in an educational setting taking into account the social nature of reading. We developed the STUDY algorithm in partnership with Learning Ally, an educational nonprofit, aimed at promoting reading in dyslexic students, that provides audiobooks to students through a school-wide subscription program. Leveraging the wide range of audiobooks in the Learning Ally library, our goal is to help students find the right content to help boost their reading experience and engagement. Motivated by the fact that what a person’s peers are currently reading has significant effects on what they would find interesting to read, we jointly process the reading engagement history of students who are in the same classroom. This allows our model to benefit from live information about what is currently trending within the student’s localized social group, in this case, their classroom.
Data
Learning Ally has a large digital library of curated audiobooks targeted at students, making it well-suited for building a social recommendation model to help improve student learning outcomes. We received two years of anonymized audiobook consumption data. All students, schools and groupings in the data were anonymized, only identified by a randomly generated ID not traceable back to real entities by Google. Furthermore all potentially identifiable metadata was only shared in an aggregated form, to protect students and institutions from being re-identified. The data consisted of time-stamped records of student’s interactions with audiobooks. For each interaction we have an anonymized student ID (which includes the student’s grade level and anonymized school ID), an audiobook identifier and a date. While many schools distribute students in a single grade across several classrooms, we leverage this metadata to make the simplifying assumption that all students in the same school and in the same grade level are in the same classroom. While this provides the foundation needed to build a better social recommender model, it’s important to note that this does not enable us to re-identify individuals, class groups or schools.
The STUDY algorithm
We framed the recommendation problem as a click-through rate prediction problem, where we model the conditional probability of a user interacting with each specific item conditioned on both 1) user and item characteristics and 2) the item interaction history sequence for the user at hand. Previous work suggests Transformer-based models, a widely used model class developed by Google Research, are well suited for modeling this problem. When each user is processed individually this becomes an autoregressive sequence modeling problem. We use this conceptual framework to model our data and then extend this framework to create the STUDY approach.
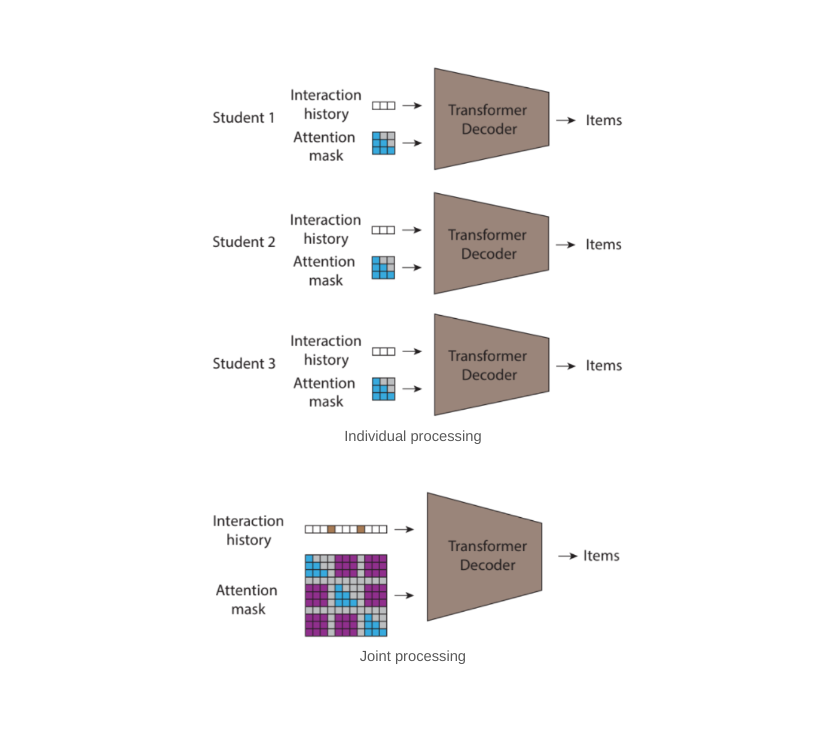
While this approach for click-through rate prediction can model dependencies between past and future item preferences for an individual user and can learn patterns of similarity across users at train time, it cannot model dependencies across different users at inference time. To recognise the social nature of reading and remediate this shortcoming we developed the STUDY model, which concatenates multiple sequences of books read by each student into a single sequence that collects data from multiple students in a single classroom.
However, this data representation requires careful diligence if it is to be modeled by transformers. In transformers, the attention mask is the matrix that controls which inputs can be used to inform the predictions of which outputs. The pattern of using all prior tokens in a sequence to inform the prediction of an output leads to the upper triangular attention matrix traditionally found in causal decoders. However, since the sequence fed into the STUDY model is not temporally ordered, even though each of its constituent subsequences is, a standard causal decoder is no longer a good fit for this sequence. When trying to predict each token, the model is not allowed to attend to every token that precedes it in the sequence; some of these tokens might have timestamps that are later and contain information that would not be available at deployment time.
 |
| In this figure we show the attention mask typically used in causal decoders. Each column represents an output and each column represents an output. A value of 1 (shown as blue) for a matrix entry at a particular position denotes that the model can observe the input of that row when predicting the output of the corresponding column, whereas a value of 0 (shown as white) denotes the opposite. |
The STUDY model builds on causal transformers by replacing the triangular matrix attention mask with a flexible attention mask with values based on timestamps to allow attention across different subsequences. Compared to a regular transformer, which would not allow attention across different subsequences and would have a triangular matrix mask within sequence, STUDY maintains a causal triangular attention matrix within a sequence and has flexible values across sequences with values that depend on timestamps. Hence, predictions at any output point in the sequence are informed by all input points that occurred in the past relative to the current time point, regardless of whether they appear before or after the current input in the sequence. This causal constraint is important because if it is not enforced at train time, the model could potentially learn to make predictions using information from the future, which would not be available for a real world deployment.
 |
| In (a) we show a sequential autoregressive transformer with causal attention that processes each user individually; in (b) we show an equivalent joint forward pass that results in the same computation as (a); and finally, in (c) we show that by introducing new nonzero values (shown in purple) to the attention mask we allow information to flow across users. We do this by allowing a prediction to condition on all interactions with an earlier timestamp, irrespective of whether the interaction came from the same user or not. |
<!–
 |
| In (a) we show a sequential autoregressive transformer with causal attention that processes each user individually; in (b) we show an equivalent joint forward pass that results in the same computation as (a); and finally, in (c) we show that by introducing new nonzero values (shown in purple) to the attention mask we allow information to flow across users. We do this by allowing a prediction to condition on all interactions with an earlier timestamp, irrespective of whether the interaction came from the same user or not. |
–><!–
 |
| In (a) we show a sequential autoregressive transformer with causal attention that processes each user individually; in (b) we show an equivalent joint forward pass that results in the same computation as (a); and finally, in (c) we show that by introducing new nonzero values (shown in purple) to the attention mask we allow information to flow across users. We do this by allowing a prediction to condition on all interactions with an earlier timestamp, irrespective of whether the interaction came from the same user or not. |
–>
Experiments
We used the Learning Ally dataset to train the STUDY model along with multiple baselines for comparison. We implemented an autoregressive click-through rate transformer decoder, which we refer to as “Individual”, a k-nearest neighbor baseline (KNN), and a comparable social baseline, social attention memory network (SAMN). We used the data from the first school year for training and we used the data from the second school year for validation and testing.
We evaluated these models by measuring the percentage of the time the next item the user actually interacted with was in the model’s top n recommendations, i.e., hits@n, for different values of n. In addition to evaluating the models on the entire test set we also report the models’ scores on two subsets of the test set that are more challenging than the whole data set. We observed that students will typically interact with an audiobook over multiple sessions, so simply recommending the last book read by the user would be a strong trivial recommendation. Hence, the first test subset, which we refer to as “non-continuation”, is where we only look at each model’s performance on recommendations when the students interact with books that are different from the previous interaction. We also observe that students revisit books they have read in the past, so strong performance on the test set can be achieved by restricting the recommendations made for each student to only the books they have read in the past. Although there might be value in recommending old favorites to students, much value from recommender systems comes from surfacing content that is new and unknown to the user. To measure this we evaluate the models on the subset of the test set where the students interact with a title for the first time. We name this evaluation subset “novel”.
We find that STUDY outperforms all other tested models across almost every single slice we evaluated against.
 |
| In this figure we compare the performance of four models, Study, Individual, KNN and SAMN. We measure the performance with hits@5, i.e., how likely the model is to suggest the next title the user read within the model’s top 5 recommendations. We evaluate the model on the entire test set (all) as well as the novel and non-continuation splits. We see STUDY consistently outperforms the other three models presented across all splits. |
Importance of appropriate grouping
At the heart of the STUDY algorithm is organizing users into groups and doing joint inference over multiple users who are in the same group in a single forward pass of the model. We conducted an ablation study where we looked at the importance of the actual groupings used on the performance of the model. In our presented model we group together all students who are in the same grade level and school. We then experiment with groups defined by all students in the same grade level and district and also place all students in a single group with a random subset used for each forward pass. We also compare these models against the Individual model for reference.
We found that using groups that were more localized was more effective, with the school and grade level grouping outperforming the district and grade level grouping. This supports the hypothesis that the STUDY model is successful because of the social nature of activities such as reading — people’s reading choices are likely to correlate with the reading choices of those around them. Both of these models outperformed the other two models (single group and Individual) where grade level is not used to group students. This suggests that data from users with similar reading levels and interests is beneficial for performance.
Future work
This work is limited to modeling recommendations for user populations where the social connections are assumed to be homogenous. In the future it would be beneficial to model a user population where relationships are not homogeneous, i.e., where categorically different types of relationships exist or where the relative strength or influence of different relationships is known.
Acknowledgements
This work involved collaborative efforts from a multidisciplinary team of researchers, software engineers and educational subject matter experts. We thank our co-authors: Diana Mincu, Lauren Harrell, and Katherine Heller from Google. We also thank our colleagues at Learning Ally, Jeff Ho, Akshat Shah, Erin Walker, and Tyler Bastian, and our collaborators at Google, Marc Repnyek, Aki Estrella, Fernando Diaz, Scott Sanner, Emily Salkey and Lev Proleev.
How Amazon Shopping uses Amazon Rekognition Content Moderation to review harmful images in product reviews
Customers are increasingly turning to product reviews to make informed decisions in their shopping journey, whether they’re purchasing everyday items like a kitchen towel or making major purchases like buying a car. These reviews have transformed into an essential source of information, enabling shoppers to access the opinions and experiences of other customers. As a result, product reviews have become a crucial aspect of any store, offering valuable feedback and insights to help inform purchase decisions.
Amazon has one of the largest stores with hundreds of millions of items available. In 2022, 125 million customers contributed nearly 1.5 billion reviews and ratings to Amazon stores, making online reviews at Amazon a solid source of feedback for customers. At the scale of product reviews submitted every month, it is essential to verify that these reviews align with Amazon Community Guidelines regarding acceptable language, words, videos, and images. This practice is in place to guarantee customers receive accurate information regarding the product, and to prevent reviews from including inappropriate language, offensive imagery, or any type of hate speech directed towards individuals or communities. By enforcing these guidelines, Amazon can maintain a safe and inclusive environment for all customers.
Content moderation automation allows Amazon to scale the process while keeping high accuracy. It’s a complex problem space with unique challenges and requiring different techniques for text, images, and videos. Images are a relevant component of product reviews, often providing a more immediate impact on customers than text. With Amazon Rekognition Content Moderation, Amazon is able to automatically detect harmful images in product reviews with higher accuracy, reducing reliance on human reviewers to moderate such content. Rekognition Content Moderation has helped to improve the well-being of human moderators and achieve significant cost savings.

Moderation with self-hosted ML models
The Amazon Shopping team designed and implemented a moderation system that uses machine learning (ML) in conjunction with human-in-the-loop (HITL) review to ensure product reviews are about the customer experience with the product and don’t contain inappropriate or harmful content as per the community guidelines. The image moderation subsystem, as illustrated in the following diagram, utilized multiple self-hosted and self-trained computer vision models to detect images that violate Amazon guidelines. The decision handler determines the moderation action and provides reasons for its decision based on the ML models’ output, thereby deciding whether the image required a further review by a human moderator or could be automatically approved or rejected.
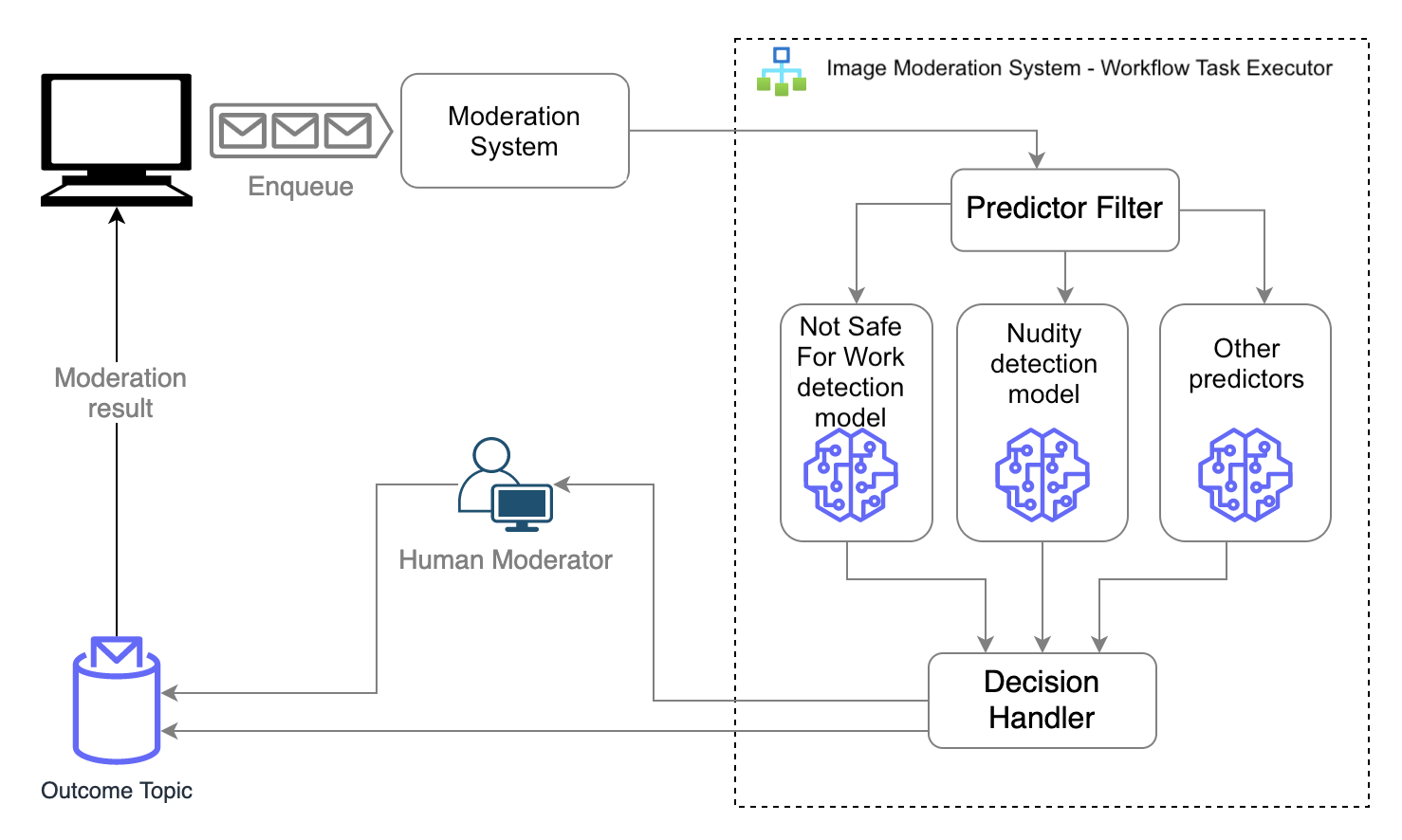
With these self-hosted ML models, the team started by automating decisions on 40% of the images received as part of the reviews and continuously worked on improving the solution through the years while facing several challenges:
- Ongoing efforts to improve automation rate – The team desired to improve the accuracy of ML algorithms, aiming to increase the automation rate. This requires continuous investments in data labeling, data science, and MLOps for models training and deployment.
- System complexity – The architecture complexity requires investments in MLOps to ensure the ML inference process scales efficiently to meet the growing content submission traffic.
Replace self-hosted ML models with the Rekognition Content Moderation API
Amazon Rekognition is a managed artificial intelligence (AI) service that offers pre-trained models through an API interface for image and video moderation. It has been widely adopted by industries such as ecommerce, social media, gaming, online dating apps, and others to moderate user-generated content (UGC). This includes a range of content types, such as product reviews, user profiles, and social media post moderation.
Rekognition Content Moderation automates and streamlines image and video moderation workflows without requiring ML experience. Amazon Rekognition customers can process millions of images and videos, efficiently detecting inappropriate or unwanted content, with fully managed APIs and customizable moderation rules to keep users safe and the business compliant.
The team successfully migrated a subset of self-managed ML models in the image moderation system for nudity and not safe for work (NSFW) content detection to the Amazon Rekognition Detect Moderation API, taking advantage of the highly accurate and comprehensive pre-trained moderation models. With the high accuracy of Amazon Rekognition, the team has been able to automate more decisions, save costs, and simplify their system architecture.
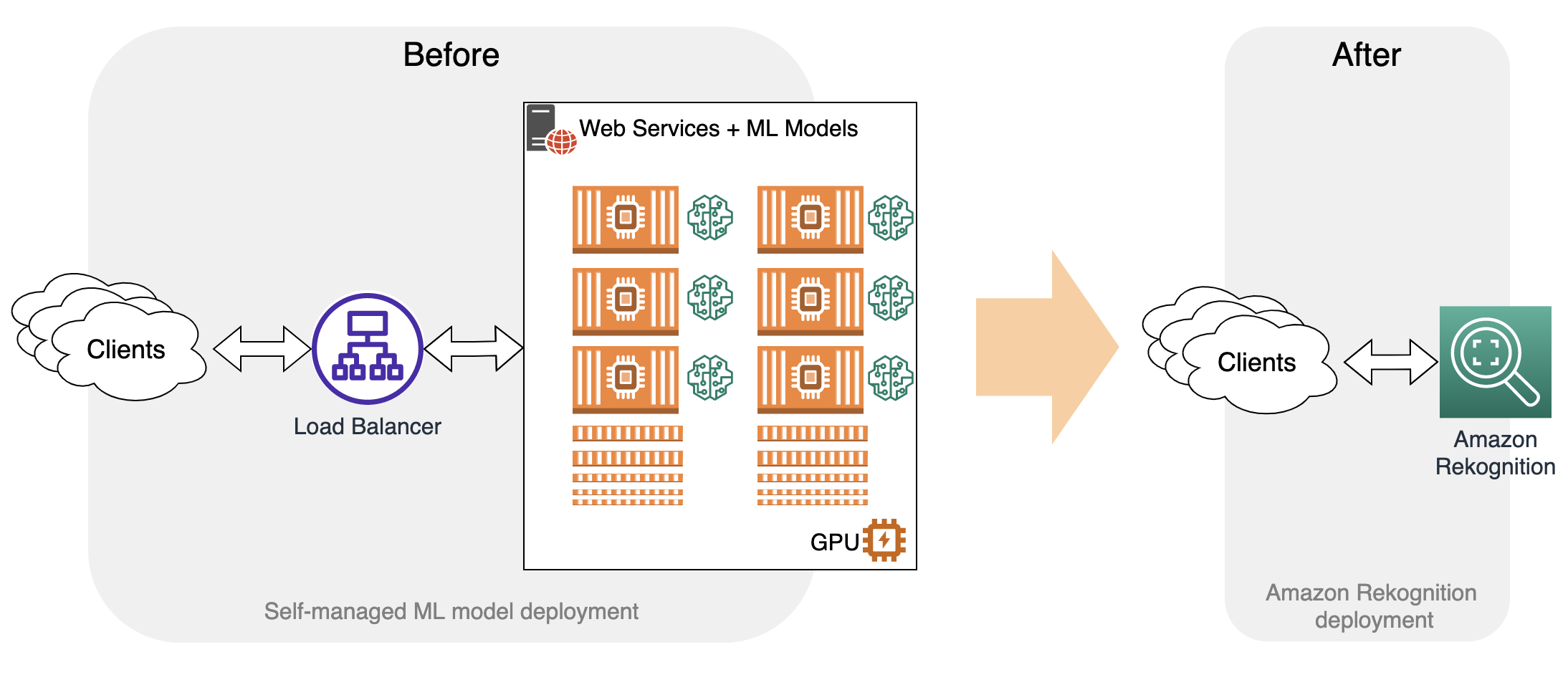
Improved accuracy and expanded moderation categories
The implementation of the Amazon Rekognition image moderation API has resulted in higher accuracy for detection of inappropriate content. This implies that an additional approximate of 1 million images per year will be automatically moderated without the need for any human review.
Operational excellence
The Amazon Shopping team was able to simplify the system architecture, reducing the operational effort required to manage and maintain the system. This approach has saved them months of DevOps effort per year, which means they can now allocate their time to developing innovative features instead of spending it on operational tasks.
Cost reduction
The high accuracy from Rekognition Content Moderation has enabled the team to send fewer images for human review, including potentially inappropriate content. This has reduced the cost associated with human moderation and allowed moderators to focus their efforts on more high-value business tasks. Combined with the DevOps efficiency gains, the Amazon Shopping team achieved significant cost savings.
Conclusion
Migrating from self-hosted ML models to the Amazon Rekognition Moderation API for product review moderation can provide many benefits for businesses, including significant cost savings. By automating the moderation process, online stores can quickly and accurately moderate large volumes of product reviews, improving the customer experience by ensuring that inappropriate or spam content is quickly removed. Additionally, by using a managed service like the Amazon Rekognition Moderation API, companies can reduce the time and resources needed to develop and maintain their own models, which can be especially useful for businesses with limited technical resources. The API’s flexibility also allows online stores to customize their moderation rules and thresholds to fit their specific needs.
Learn more about content moderation on AWS and our content moderation ML use cases. Take the first step towards streamlining your content moderation operations with AWS.
About the Authors
 Shipra Kanoria is a Principal Product Manager at AWS. She is passionate about helping customers solve their most complex problems with the power of machine learning and artificial intelligence. Before joining AWS, Shipra spent over 4 years at Amazon Alexa, where she launched many productivity-related features on the Alexa voice assistant.
Shipra Kanoria is a Principal Product Manager at AWS. She is passionate about helping customers solve their most complex problems with the power of machine learning and artificial intelligence. Before joining AWS, Shipra spent over 4 years at Amazon Alexa, where she launched many productivity-related features on the Alexa voice assistant.
 Luca Agostino Rubino is a Principal Software Engineer in the Amazon Shopping team. He works on Community features like Customer Reviews and Q&As, focusing through the years on Content Moderation and on scaling and automation of Machine Learning solutions.
Luca Agostino Rubino is a Principal Software Engineer in the Amazon Shopping team. He works on Community features like Customer Reviews and Q&As, focusing through the years on Content Moderation and on scaling and automation of Machine Learning solutions.
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.

Quality Control Patrol: Startup Builds Models for Detecting Vehicle Failure Patterns
When it comes to preserving profit margins, data scientists for vehicle and parts manufacturers are sitting in the driver’s seat.
Viaduct, which develops models for time-series inference, is helping enterprises harvest failure insights from the data captured on today’s connected cars. It does so by tapping into sensor data and making correlations.
The four-year-old startup, based in Menlo Park, Calif., offers a platform to detect anomalous patterns, track issues, and deploy failure predictions. This enables automakers and parts suppliers to get in front of problems with real-time data to reduce warranty claims, recalls and defects, said David Hallac, the founder and CEO of Viaduct.
“Viaduct has deployed on more than 2 million vehicles, helped avoid 500,000 hours of downtime and saved hundreds of millions of dollars in warranty costs across the industry,” he said.
The company relies on NVIDIA A100 Tensor Core GPUs and the NVIDIA Time Series Prediction Platform (TSPP) framework for training, tuning and deploying time-series models, which are used to forecast data.
Viaduct has deployed with more than five major manufacturers of passenger cars and commercial trucks, according to the company.
“Customers see it as a huge savings — the things that we are affecting are big in terms of profitability,” said Hallac. “It’s downtime impact, it’s warranty impact and it’s product development inefficiency.”
Viaduct is a member of NVIDIA Inception, a program that provides companies with technology support and AI platforms guidance.
How It Started: Research Hits the Road
Hallac’s path to Viaduct began at Stanford University. While he was a Ph.D. student there, Volkswagen came to the lab he was at with sensor data collected from more than 60 drivers over the course of several months and a research grant to explore uses.
The question the researchers delved into was how to understand the patterns and trends in the sizable body of vehicle data collected over months.
The Stanford researchers in coordination with Volkswagen Electronics Research Laboratory released a paper on the work, which highlighted Drive2Vec, a deep learning method for embedding sensor data.
“We developed a bunch of algorithms focused on structural inference from high-dimensional time-series data. We were discovering useful insights, and we were able to help companies train and deploy predictive algorithms at scale,” he said.
Developing a Knowledge Graph for Insights With up to 10x Inference
Viaduct handles time-series analytics with its TSI engine, which aggregates manufacturing, telematics and service data. Its model was trained with A100 GPUs tapping into NVIDIA TSPP.
“We describe it as a knowledge graph — we’re building this knowledge graph of all the different sensors and signals and how they correlate with each other,” Hallac said.
Several key features are generated using the Drive2Vec autoencoder for embedding sensor data. Correlations are learned via a Markov random field inference process, and the time series predictions tap into the NVIDIA TSPP framework.
NVIDIA GPUs on this platform enable Viaduct to achieve as much as a 30x better inference accuracy compared with CPU systems running logistics regression and gradient boosting algorithms, Hallac said.
Protecting Profits With Proactive AI
One vehicle maker using Viaduct’s platform was able to handle some of its issues proactively, fix them and then identify which vehicles were at risk of those issues and only request owners to bring those in for service. This not only affects the warranty claims but also the service desks, which get more visibility into the types of vehicle repairs coming in.
Also, as vehicle and parts manufacturers are partnered on warranties, the results matter for both.
Viaduct reduced warranty costs for one customer by more than $50 million on five issues, according to the startup.
“Everyone wants the information, everyone feels the pain and everyone benefits when the system is optimized,” Hallac said of the potential for cost-savings.
Maintaining Vehicle Reviews Ratings
Viaduct began working with a major automaker last year to help with quality-control issues. The partnership aimed to improve its time-to-identify and time-to-fix post-production quality issues.
The automaker’s JD Power IQS (Initial Quality Study) score had been falling while its warranty costs were climbing, and the company sought to reverse the situation. So, the automaker began using Viaduct’s platform and its TSI engine.
In A/B testing Viaduct’s platform against traditional reactive approaches to quality control, the automaker was able to identify issues on average 53 days earlier during the first year of a vehicle launch. The results saved “tens of millions” in warranty costs and the vehicle’s JD Power quality and reliability score increased “multiple points” compared with the previous model year, according to Hallac.
And Viaduct is getting customer traction that reflects the value of its AI to businesses, he said.
Learn more about NVIDIA A100 and NVIDIA TSPP.

Learn as you search (and browse) using generative AI
 New updates to Search Generative Experience (SGE) help people easily learn new things and understand key concepts while searching online.Read More
New updates to Search Generative Experience (SGE) help people easily learn new things and understand key concepts while searching online.Read More
Intelligent video and audio Q&A with multilingual support using LLMs on Amazon SageMaker
Digital assets are vital visual representations of products, services, culture, and brand identity for businesses in an increasingly digital world. Digital assets, together with recorded user behavior, can facilitate customer engagement by offering interactive and personalized experiences, allowing companies to connect with their target audience on a deeper level. Efficiently discovering and searching for specific content within digital assets is crucial for businesses to optimize workflows, streamline collaboration, and deliver relevant content to the right audience. According to a study, by 2021, videos already make up 81% of all consumer internet traffic. This observation comes as no surprise because video and audio are powerful mediums offering more immersive experiences and naturally engages target audiences on a higher emotional level.
As companies accumulate large volumes of digital assets, it becomes more challenging to organize and manage them effectively to maximize their value. Traditionally, companies attach metadata, such as keywords, titles, and descriptions, to these digital assets to facilitate search and retrieval of relevant content. But this requires a well-designed digital asset management system and additional efforts to store these assets in the first place. In reality, most of the digital assets lack informative metadata that enables efficient content search. Additionally, you often need to do an analysis of different segments of the whole file and discover the concepts that are covered there. This is time consuming and requires a lot of manual effort.
Generative AI, particularly in the realm of natural language processing and understanding (NLP and NLU), has revolutionized the way we comprehend and analyze text, enabling us to gain deeper insights efficiently and at scale. The advancements in large language models (LLMs) have led to richer representations of texts, which provides better search capabilities for digital assets. Retrieval Augmented Generation (RAG), built on top of LLMs and advanced prompt techniques, is a popular approach to provide more accurate answers based on information hidden in the enterprise digital asset store. By taking advantage of embedding models of LLMs, and powerful indexers and retrievers, RAG can comprehend and process spoken or written queries and quickly find the most relevant information in the knowledge base. Previous studies have shown how RAG can be applied to provide a Q&A solution connecting with an enterprise’s private domain knowledge. However, among all types of digital assets, video and audio assets are the most common and important.
The RAG-based video/audio question answering solution can potentially solve business problems of locating training and reference materials that are in the form of non-text content. With limited tags or metadata associated of these assets, the solution is trying to make users interact with the chatbot and get answers to their queries, which could be links to specific video training (“I need link to Amazon S3 data storage training”) links to documents (“I need link to learn about machine learning”), or questions that were covered in the videos (“Tell me how to create an S3 bucket”). The response from the chatbot will be able to directly answer the question and also include the links to the source videos with the specific timestamp of the contents that are most relevant to the user’s request.
In this post, we demonstrate how to use the power of RAG in building a Q&A solution for video and audio assets on Amazon SageMaker.
Solution overview
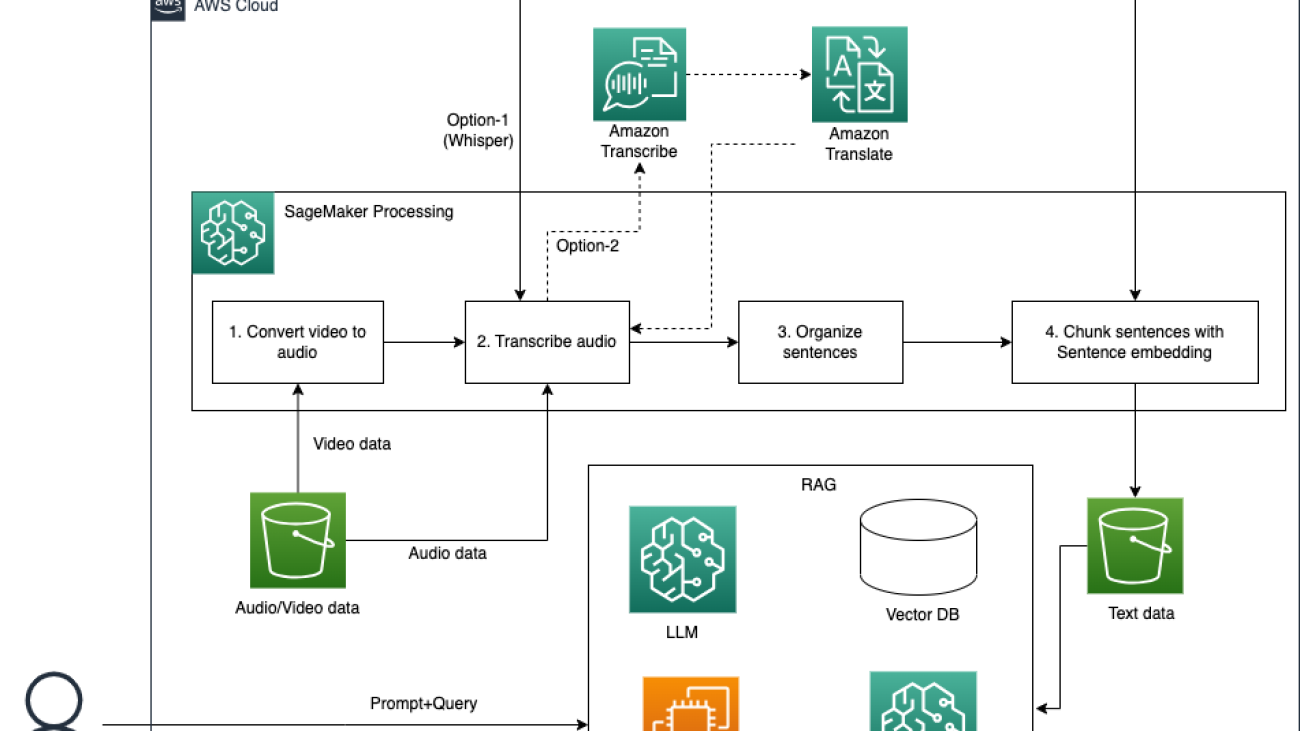
The following diagram illustrates the solution architecture.

The workflow mainly consists of the following stages:
- Convert video to text with a speech-to-text model and text alignment with videos and organization. We store the data in Amazon Simple Storage Service (Amazon S3).
- Enable intelligent video search using a RAG approach with LLMs and LangChain. Users can get answers generated by LLMs and relevant sources with timestamps.
- Build a multi-functional chatbot using LLMs with SageMaker, where the two aforementioned solutions are wrapped and deployed.
For a detailed implementation, refer to the GitHub repo.
Prerequisites
You need an AWS account with an AWS Identity and Access Management (IAM) role with permissions to manage resources created as part of the solution. For details, refer to create an AWS account.
If this is your first time working with Amazon SageMaker Studio, you first need to create a SageMaker domain. Additionally, you may need to request a service quota increase for the corresponding SageMaker processing and hosting instances. For preprocessing the video data, we use an ml.p3.2xlarge SageMaker processing instance. For hosting Falcon-40B, we use an ml.g5.12xlarge SageMaker hosting instance.
Convert video to text with a speech-to-text model and sentence embedding model
To be able to search through video or audio digital assets and provide contextual information from videos to LLMs, we need to convert all the media content to text and then follow the general approaches in NLP to process the text data. To make our solution more flexible to handle different scenarios, we provide the following options for this task:
- Amazon Transcribe and Amazon Translate – If each video and audio file only contains one language, we highly recommend that you choose Amazon Transcribe, which is an AWS managed service to transcribe audio and video files. If you need to translate them into the same language, Amazon Translate is another AWS managed service, which supports multilingual translation.
- Whisper – In real-world use cases, video data may include multiple languages, such as foreign language learning videos. Whisper is a multitasking speech recognition model that can perform multilingual speech recognition, speech translation, and language identification. You can use a Whisper model to detect and transcribe different languages on video data, and then translate all the different languages into one language. It’s important for most RAG solutions to run on the knowledge base with the same language. Even though OpenAI provides the Whisper API, for this post, we use the Whisper model from Hugging Face.
We run this task with an Amazon SageMaker Processing job on existing data. You can refer to data_preparation.ipynb for the details of how to run this task.
Convert video data to audio data
Because Amazon Transcribe can handle both video and audio data and the Whisper model can only accept audio data, to make both options work, we need to convert video data to audio data. In the following code, we use VideoFileClip from the library moviepy to run this job:
from moviepy.editor import VideoFileClip
video = VideoFileClip(video_path)
video.audio.write_audiofile(audio_path)Transcribe audio data
When the audio data is ready, we can choose from our two transcribing options. You can choose the optimal option based on your own use case with the criteria we mentioned earlier.
Option 1: Amazon Transcribe and Amazon Translate
The first option is to use Amazon AI services, such as Amazon Transcribe and Amazon Translate, to get the transcriptions of the video and audio datasets. You can refer to the following GitHub example when choosing this option.
Option 2: Whisper
A Whisper model can handle audio data up to 30 seconds in duration. To handle large audio data, we adopt transformers.pipeline to run inference with Whisper. When searching relevant video clips or generating contents with RAG, timestamps for the relevant clips are the important references. Therefore, we turn return_timestamps on to get outputs with timestamps. By setting the parameter language in generate_kwargs, all the different languages in one video file are transcribed and translated into the same language. stride_length_s is the length of stride on the left and right of each chunk. With this parameter, we can make the Whisper model see more context when doing inference on each chunk, which will lead to a more accurate result. See the following code:
from transformers import pipeline
import torch
target_language = "en"
whisper_model = "whisper-large-v2"
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition",
model=f"openai/{whisper_model}",
device=device
)
generate_kwargs = {"task":"transcribe", "language":f"<|{target_language}|>"}
prediction = pipe(
file_path,
return_timestamps=True,
chunk_length_s=30,
stride_length_s=(5),
generate_kwargs=generate_kwargs
)The output of pipe is the dictionary format data with items of text and chunks. text contains the entire transcribed result, and chunks consists of chunks with the timestamp and corresponding transcribed result (see the following screenshot). We use data in chunks to do further processing.

As the preceding screenshot shows, lot of sentences have been cut off and split into different chunks. To make the chunks more meaningful, we need to combine sentences cut off and update timestamps in the next step.
Organize sentences
We use a very simple rule to combine sentences. When the chunk ends with a period (.), we don’t make any change; otherwise, we concatenate it with the next chunk. The following code snippet explains how we make this change:
prev_chunk = None
new_chunks = []
for chunk in chunks:
if prev_chunk:
chunk['text'] = prev_chunk['text'] + chunk['text']
chunk['timestamp'] = (prev_chunk['timestamp'][0], chunk['timestamp'][1])
if not chunk['text'].endswith('.'):
prev_chunk = chunk
else:
new_chunks.append(chunk)
prev_chunk = NoneCompared to the original chunks produced by the audio-to-text converts, we can get complete sentences that are cut off originally.

Chunk sentences
The text content in documents is normally organized by paragraph. Each paragraph focuses on the same topic. Chunking by paragraph may help embed texts into more meaningful vectors, which may improve retrieval accuracy.
Unlike the normal text content in documents, transcriptions from the transcription model are not paragraphed. Even though there are some stops in the audio files, sometimes it can’t be used to paragraph sentences. On the other hand, langchain provides the recursive chunking text splitter function RecursiveCharacterTextSplitter, which can keep all the semantically relevant content in the same chunk. Because we need to keep timestamps with chunks, we implement our own chunking process. Inspired by the post How to chunk text into paragraphs using python, we chunk sentences based on the similarity between the adjacent sentences with a sentence embedding approach. The basic idea is to take the sentences with the lowest similarity to adjacent sentences as the split points. We use all-MiniLM-L6-v2 for sentence embedding. You can refer the original post for the explanation of this approach. We have made some minor changes on the original source code; refer to our source code for the implementation. The core part for this process is as follows:
# Embed sentences
model_name = "all-minilm-l6-v2"
model = SentenceTransformer(model_name)
embeddings = model.encode(sentences_all)
# Create similarities matrix
similarities = cosine_similarity(embeddings)
# Let's apply our function. For long sentences i reccomend to use 10 or more sentences
minmimas = activate_similarities(similarities, p_size=p_size, order=order)
# Create empty string
split_points = [each for each in minmimas[0]]
text = ''
para_chunks = []
para_timestamp = []
start_timestamp = 0
for num, each in enumerate(sentences_all):
current_timestamp = timestamps_all[num]
if text == '' and (start_timestamp == current_timestamp[1]):
start_timestamp = current_timestamp[0]
if num in split_points:
para_chunks.append(text)
para_timestamp.append([start_timestamp, current_timestamp[1]])
text = f'{each}. '
start_timestamp = current_timestamp[1]
else:
text+=f'{each}. '
if len(text):
para_chunks.append(text)
para_timestamp.append([start_timestamp, timestamps_all[-1][1]])To evaluate the efficiency of chunking with sentence embedding, we conducted qualitative comparisons between different chunking mechanisms. The assumption underlying such comparisons is that if the chunked texts are more semantically different and separate, there will be less irrelevant contextual information being retrieved for the Q&A, so that the answer will be more accurate and precise. At the same time, because less contextual information is sent to LLMs, the cost of inference will also be less as charges increment with the size of tokens.
We visualized the first two components of a PCA by reducing high dimension into two dimensions. Compared to recursive chunking, we can see the distances between vectors representing different chunks with sentence embedding are more scattered, meaning the chunks are more semantically separate. This means when the vector of a query is close to the vector of one chunk, it may have less possibility to be close to other chunks. A retrieval task will have fewer opportunities to choose relevant information from multiple semantically similar chunks.

When the chunking process is complete, we attach timestamps to the file name of each chunk, save it as a single file, and then upload it to an S3 bucket.
Enable intelligent video search using a RAG-based approach with LangChain
There are typically four approaches to build a RAG solution for Q&A with LangChain:
- Using the
load_qa_chainfunctionality, which feeds all information to an LLM. This is not an ideal approach given the context window size and the volume of video and audio data. - Using the
RetrievalQAtool, which requires a text splitter, text embedding model, and vector store to process texts and retrieve relevant information. - Using
VectorstoreIndexCreator, which is a wrapper around all logic in the second approach. The text splitter, text embedding model, and vector store are configured together inside the function at one time. - Using the
ConversationalRetrievalChaintool, which further adds memory of chat history to the QA solution.
For this post, we use the second approach to explicitly customize and choose the best engineering practices. In the following sections, we describe each step in detail.
To search for the relevant content based on the user input queries, we use semantic search, which can better understand the intent behind and query and perform meaningful retrieval. We first use a pre-trained embedding model to embed all the transcribed text into a vector space. At search time, the query is also embedded into the same vector space and the closest embeddings from the source corpus are found. You can deploy the pre-trained embedding model as shown in Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart to create the embeddings for semantic search. In our post, we adopt similar ways to create an intelligent video search solution using a RAG-based approach with the open-source LangChain library. LangChain is an open-source framework for developing applications powered by language models. LangChain provides a generic interface for many different LLMs.
We first deploy an embedding model GPT-J 6B provided by Amazon SageMaker JumpStart and the language model Falcon-40B Instruct from Hugging Face to prepare for the solution. When the endpoints are ready, we follow similar steps described Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart to create the LLM model and embedding model for LangChain.
The following code snippet shows how to create the LLM model using the langchain.llms.sagemaker_endpoint.SagemakerEndpoint class and transform the request and response payload for the LLM in the ContentHandler:
from langchain.llms.sagemaker_endpoint import LLMContentHandler, SagemakerEndpoint
parameters = {
"max_new_tokens": 500,
}
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs={}) -> bytes:
self.len_prompt = len(prompt)
input_str = json.dumps({"inputs": prompt , "parameters": {**model_kwargs}})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = output.read()
res = json.loads(response_json)
print(res)
ans = res[0]['generated_text'][self.len_prompt:]
return ans
content_handler = ContentHandler()
sm_llm = SagemakerEndpoint(
endpoint_name=_MODEL_CONFIG_["huggingface-falcon-40b"]["endpoint_name"],
region_name=aws_region,
model_kwargs=parameters,
content_handler=content_handler,
) When we use a SageMaker JumpStart embedding model, we need to customize the LangChain SageMaker endpoint embedding class and transform the model request and response to integrate with LangChain. Load the processed video transcripts using the LangChain document loader and create an index.
We use the DirectoryLoader package in LangChain to load the text documents into the document loader:
loader = DirectoryLoader("./data/demo-video-sagemaker-doc/", glob="*/.txt")
documents = loader.load()Next, we use the embedding models to create the embeddings of the contents and store the embeddings in a FAISS vector store to create an index. We use this index to find relevant documents that are semantically similar to the input query. With the VectorstoreIndexCreator class, you can just write a few lines of code to achieve this task:
index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
text_splitter=CharacterTextSplitter(chunk_size=500, chunk_overlap=0),
)
index = index_creator.from_loaders([loader])Now we can use the index to search for relevant context and pass it to the LLM model to generate an accurate response:
index.query(question=question, llm=sm_llm)Build a multi-functional chatbot with SageMaker
With the deployed LLM on SageMaker, we can build a multi-functional smart chatbot to show how these models can help your business build advanced AI-powered applications. In this example, the chatbot uses Streamlit to build the UI and the LangChain framework to chain together different components around LLMs. With the help of the text-to-text and speech-to-text LLMs deployed on SageMaker, this smart chatbot accepts inputs from text files and audio files so users can chat with the input files (accepts text and audio files) and further build applications on top of this. The following diagram shows the architecture of the chatbot.

When a user uploads a text file to the chatbot, the chatbot puts the content into the LangChain memory component and the user can chat with the uploaded document. This part is inspired by the following GitHub example that builds a document chatbot with SageMaker. We also add an option to allow users to upload audio files. Then the chatbot automatically invokes the speech-to-text model hosted on the SageMaker endpoint to extract the text content from the uploaded audio file and add the text content to the LangChain memory. Lastly, we allow the user to select the option to use the knowledge base when answering questions. This is the RAG capability shown in the preceding diagram. We have defined the SageMaker endpoints that are deployed in the notebooks provided in the previous sections. Note that you need to pass the actual endpoint names that are shown in your account when running the Streamlit app. You can find the endpoint names on the SageMaker console under Inference and Endpoints.
Falcon_endpoint_name = os.getenv("falcon_ep_name", default="falcon-40b-instruct-12xl")
whisper_endpoint_name = os.getenv('wp_ep_name', default="whisper-large-v2")
embedding_endpoint_name = os.getenv('embed_ep_name', default="huggingface-textembedding-gpt-j-6b")When the knowledge base option is not selected, we use the conversation chain, where we add the memory component using the ConversationBufferMemory provided by LangChain, so the bot can remember the current conversation history:
def load_chain():
memory = ConversationBufferMemory(return_messages=True)
chain = ConversationChain(llm=llm, memory=memory)
return chain
chatchain = load_chain()We use similar logic as shown in the earlier section for the RAG component and add the document retrieval function to the code. For demo purposes, we load the transcribed text stored in SageMaker Studio local storage as a document source. You can implement other RAG solutions using the vector databases based on your choice, such as Amazon OpenSearch Service, Amazon RDS, Amazon Kendra, and more.
When users use the knowledge base for the question, the following code snippet retrieves the relevant contents from the database and provides additional context for the LLM to answer the question. We used the specific method provided by FAISS, similarity_search_with_score, when searching for relevant documents. This is because it can also provide the metadata and similarity score of the retrieved source file. The returned distance score is L2 distance. Therefore, a lower score is better. This gives us more options to provide more context for the users, such as providing the exact timestamps of the source videos that are relevant to the input query. When the RAG option is selected by the user from the UI, the chatbot uses the load_qa_chain function provided by LangChain to provide the answers based on the input prompt.
docs = docsearch.similarity_search_with_score(user_input)
contexts = []
for doc, score in docs:
print(f"Content: {doc.page_content}, Metadata: {doc.metadata}, Score: {score}")
if score <= 0.9:
contexts.append(doc)
source.append(doc.metadata['source'].split('/')[-1])
print(f"n INPUT CONTEXT:{contexts}")
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.:nn{context}nnQuestion: {question}nHelpful Answer:"""
PROMPT = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
chain = load_qa_chain(llm=llm, prompt=PROMPT)
result = chain({"input_documents": contexts, "question": user_input},
return_only_outputs=True)["output_text"]
if len(source) != 0:
df = pd.DataFrame(source, columns=['knowledge source'])
st.data_editor(df)Run the chatbot app
Now we’re ready to run the Streamlit app. Open a terminal in SageMaker Studio and navigate to the cloned GitHub repository folder. You need to install the required Python packages that are specified in the requirements.txt file. Run pip install -r requirements.txt to prepare the Python dependencies.
Then run the following command to update the endpoint names in the environment variables based on the endpoints deployed in your account accordingly. When you run the chatbot.py file, it automatically updates the endpoint names based on the environment variables.
export falcon_ep_name=<the falcon endpoint name deployed in your account>
export wp_ep_name=<the whisper endpoint name deployed in your account>
export embed_ep_name=<the embedding endpoint name deployed in your account>
streamlit run app_chatbot/chatbot.py --server.port 6006 --server.maxUploadSize 6
To access the Streamlit UI, copy your SageMaker Studio URL and replace lab? with proxy/[PORT NUMBER]/. For this post, we specified the server port as 6006, so the URL should look like https://<domain ID>.studio.<region>.sagemaker.aws/jupyter/default/proxy/6006/.
Replace domain ID and region with the correct value in your account to access the UI.
Chat with your audio file
In the Conversation setup pane, choose Browse files to select local text or audio files to upload to the chatbot. If you select an audio file, it will automatically invoke the speech-to-text SageMaker endpoint to process the audio file and present the transcribed text to the console, as shown in the following screenshot. You can continue asking questions about the audio file and the chatbot will be able to remember the audio content and respond to your queries based on the audio content.

Use the knowledge base for the Q&A
When you want to answer questions that require specific domain knowledge or use the knowledge base, select Use knowledge base. This lets the chatbot retrieve relevant information from the knowledge base built earlier (the vector database) to add additional context to answer the question. For example, when we ask the question “what is the recommended way to first customize a foundation model?” to the chatbot without the knowledge base, the chatbot returns an answer similar to the following screenshot.

When we use the knowledge base to help answer this question, the chatbot returns a different response. In the demo video, we read the SageMaker document about how to customize a model in SageMaker Jumpstart.

The output also provides the original video file name with the retrieved timestamp of the corresponding text. Users can go back to the original video file and locate the specific clips in the original videos.

This example chatbot demonstrates how businesses can use various types of digital assets to enhance their knowledge base and provide multi-functional assistance to their employees to improve productivity and efficiency. You can build the knowledge database from documents, audio and video datasets, and even image datasets to consolidate all the resources together. With SageMaker serving as an advanced ML platform, you accelerate project ideation to production speed with the breadth and depth of the SageMaker services that cover the whole ML lifecycle.
Clean up
To save costs, delete all the resources you deployed as part of the post. You can follow the provided notebook’s cleanup section to programmatically delete the resources, or you can delete any SageMaker endpoints you may have created via the SageMaker console.
Conclusion
The advent of generative AI models powered by LLMs has revolutionized the way businesses acquire and apply insights from information. Within this context, digital assets, including video and audio content, play a pivotal role as visual representations of products, services, and brand identity. Efficiently searching and discovering specific content within these assets is vital for optimizing workflows, enhancing collaboration, and delivering tailored experiences to the intended audience. With the power of generative AI models on SageMaker, businesses can unlock the full potential of their video and audio resources. The integration of generative AI models empowers enterprises to build efficient and intelligent search solutions, enabling users to access relevant and contextual information from their digital assets, and thereby maximizing their value and fostering business success in the digital landscape.
For more information on working with generative AI on AWS, refer to Announcing New Tools for Building with Generative AI on AWS.
About the authors
 Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices across many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He supports strategic customers with AI/ML best practices across many industries. He is passionate about computer vision, NLP, generative AI, and MLOps. In his spare time, he loves running and hiking.
 Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
Melanie Li is a Senior AI/ML Specialist TAM at AWS based in Sydney, Australia. She helps enterprise customers build solutions using state-of-the-art AI/ML tools on AWS and provides guidance on architecting and implementing ML solutions with best practices. In her spare time, she loves to explore nature and spend time with family and friends.
 Guang Yang is a Senior Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art generative AI solutions.
Guang Yang is a Senior Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers across various verticals and applies creative problem solving to generate value for customers with state-of-the-art generative AI solutions.
 Harjyot Malik is a Senior Program Manager at AWS based in Sydney, Australia. He works with the APJC Enterprise Support teams and helps them build and deliver strategies. He collaborates with business teams, delving into complex problems to unearth innovative solutions that in return drive efficiencies for the business. In his spare time, he loves to travel and explore new places.
Harjyot Malik is a Senior Program Manager at AWS based in Sydney, Australia. He works with the APJC Enterprise Support teams and helps them build and deliver strategies. He collaborates with business teams, delving into complex problems to unearth innovative solutions that in return drive efficiencies for the business. In his spare time, he loves to travel and explore new places.
Amazon intern Qing Guo explores the interface between statistics and machine learning
Guo’s second internship is linked to a fellowship awarded through the Amazon–Virginia Tech Initiative for Efficient and Robust Machine Learning.Read More

Best-in-Class is in Session: New NVIDIA Studio Laptops Supercharge Content, Gaming and Education
Editor’s note: This post is part of our weekly In the NVIDIA Studio series, which celebrates featured artists, offers creative tips and tricks, and demonstrates how NVIDIA Studio technology improves creative workflows. We’re also deep diving on new GeForce RTX 40 Series GPU features, technologies and resources, and how they dramatically accelerate content creation.
The start of a new school year is an ideal time for students to upgrade their content creation, gaming and educational capabilities by picking up an NVIDIA Studio laptop, powered by GeForce RTX 40 Series graphics cards.
Marmoset Toolbag — a fully fledged 3D art production tool — just released version 4.06, a free update for Toolbag 4 users. It extends support of the OpenUSD file format and adds NVIDIA Omniverse compatibility, NVIDIA DLSS capability, AI OptiX denoising and speedups in rendering and baking — all RTX-accelerated.
Finally, this week In the NVIDIA Studio, popular influencer JiffyVFX talks about his viral video series, Doors to Realities, which garnered over 1.2 million views.
Create, Game, Study
GeForce and NVIDIA Studio RTX 40 Series laptops use the power of AI to accelerate content creation, gaming and study apps.
GeForce RTX 40 Series laptops deliver the ultimate performance for creative projects. Creators can quickly render 3D models and edit up to 8K HDR RAW videos to bring ideas to life — fast. The NVIDIA Studio platform supercharges over 110 creative apps and includes exclusive access to tools like the NVIDIA Broadcast app for enhanced creation, collaboration and remote learning. NVIDIA Studio Drivers provide maximum stability and lightning-fast performance for the most popular creative apps.
Gamers equipped with GeForce RTX 40 Series GPUs have access to ray tracing-powered realistic and immersive graphics, a quantum leap in performance with the AI-powered DLSS 3, and the lowest latency and best system responsiveness for the ultimate competitive advantage.
For students in engineering, architecture, computer science and other STEM fields, Studio laptops can accelerate dozens of apps, aiding in the creation of smoother 3D design and modeling, faster AI training and simulation and more accurate machine learning models.
Fifth-generation Max-Q technologies use AI to optimize laptop performance, power and acoustics for peak efficiency. This enables thinner and lighter designs and a 70% improved battery life suited to serving student and creator needs alike. And DLSS is now optimized for laptops, giving creators incredible 3D rendering performance with DLSS 3 optical multi-frame generation and super resolution in Omniverse and D5 Render, as well as in hit games like Cyberpunk 2077.
Get the latest and greatest deals on Studio laptops today.
Marmoset Toolbag 4.06 Adds OpenUSD
Content exported from Toolbag to Universal Scene Description (known as OpenUSD) is now fully compatible with the Omniverse ecosystem.
The OpenUSD format delivers the notable advantages of preserving physically accurate material, mesh and lighting properties, even as content travels between 3D apps such as Blender, Marmoset and Unreal Engine.

RTX GPU-accelerated OptiX denoising is also available for smooth, interactive ray tracing in the viewport. Artists can now navigate in full quality without visual artifacts and performance disruptions.
Toolbag also integrated NVIDIA DLSS, which renders the viewport at a reduced resolution and uses sophisticated AI-based technology to upscale images, improving performance while minimizing reductions in image quality. This works especially well with high-DPI displays and is a great tool for maintaining smooth performance while working on full resolution with more complex scenes.

RTX GPU-accelerated rendering gives a 2x improvement in render times and a 4x improvement in baking. DirectX 12 migration delivers an additional 25% increase in rendering and baking performance.
Learn more about Toolbag 4.06. All new users receive a full-feature, 30-day free trial license.
Create in a Jiff
James Luke, a.k.a. JiffyVFX, never has to look far for inspiration.
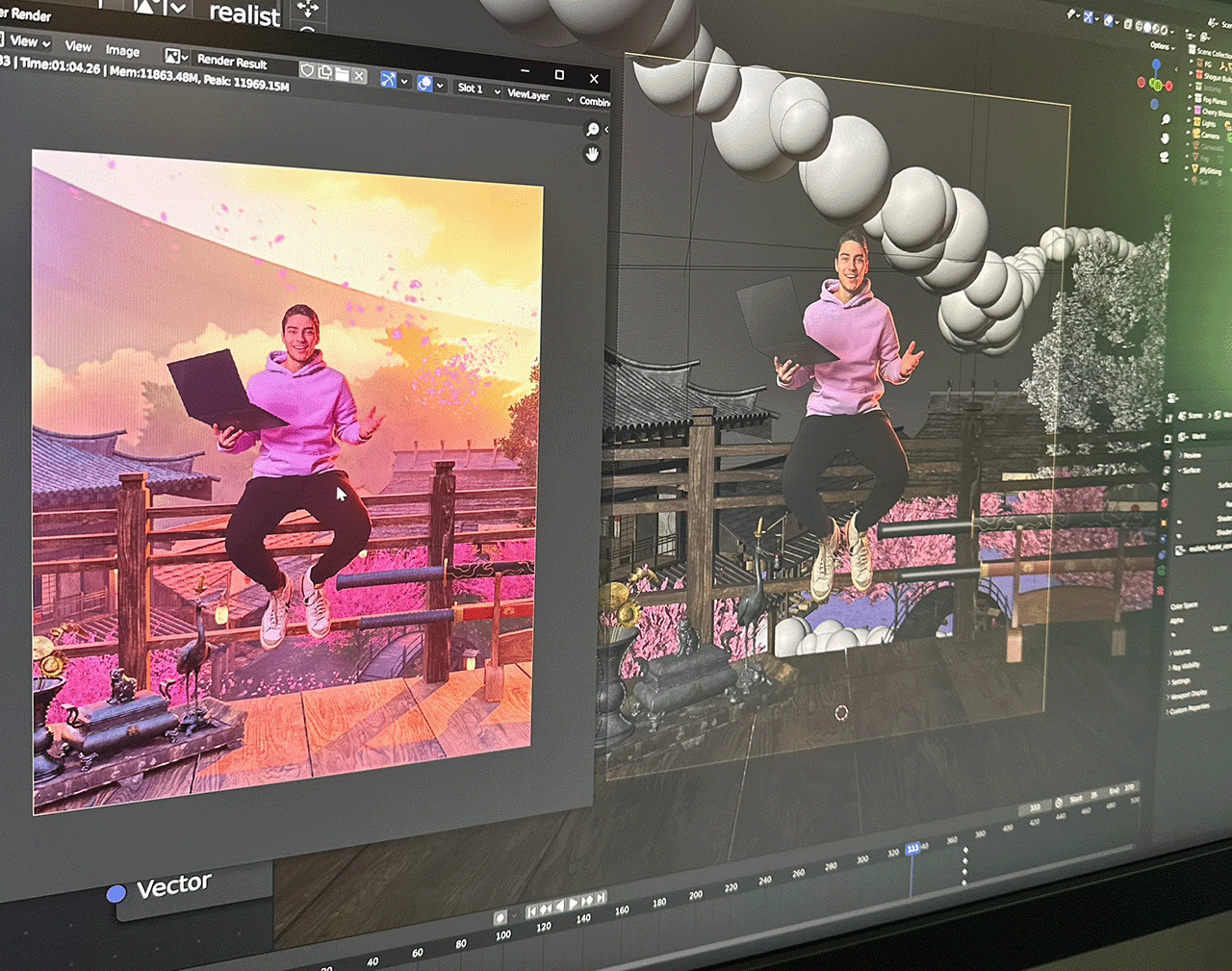
“Various films, shows, comic book characters, artists and musicians inspire me,” said Luke. “But I’d say the biggest inspirational factor is watching other artists’ works and their behind the scenes content — I’m forever watching tutorials and breakdown videos on YouTube of how other artists create their content.”
“NVIDIA GPUs are just top-of-the-line. The support, the performance, the quality. I’ve always used NVIDIA GPUs for my creative workstations over the years, and I will continue to use them for years to come.” — JiffyVFX
Luke’s Doors to Realities series began with a simple idea: put the planet Earth outside a bedroom window using the Video Copilot’s Orb plug-in for Adobe After Effects.
“I began seeing people post collages or montages of different aesthetics — things like cyberpunk, art deco, neo-noir, retro-futurism — wondering what it would look like to transport to one of those worlds through a portal or a door of some sort,” said Luke. “What would a first-person perspective of that look like?”
More recently, Luke created a Japan-themed Doors to Realities video aided by his ASUS Zenbook Pro 14 Studio laptop, powered by a GeForce RTX 4070 GPU.
Luke used 3D modeling to create the environment featured in the video. He previously used Unreal Engine for the first two installments of the series, but this time, he experimented with Kitbash 3D’s Cargo app for a one-click import into Blender. It was a game-changer — finding and uploading models into Blender was never so speedy and efficient.
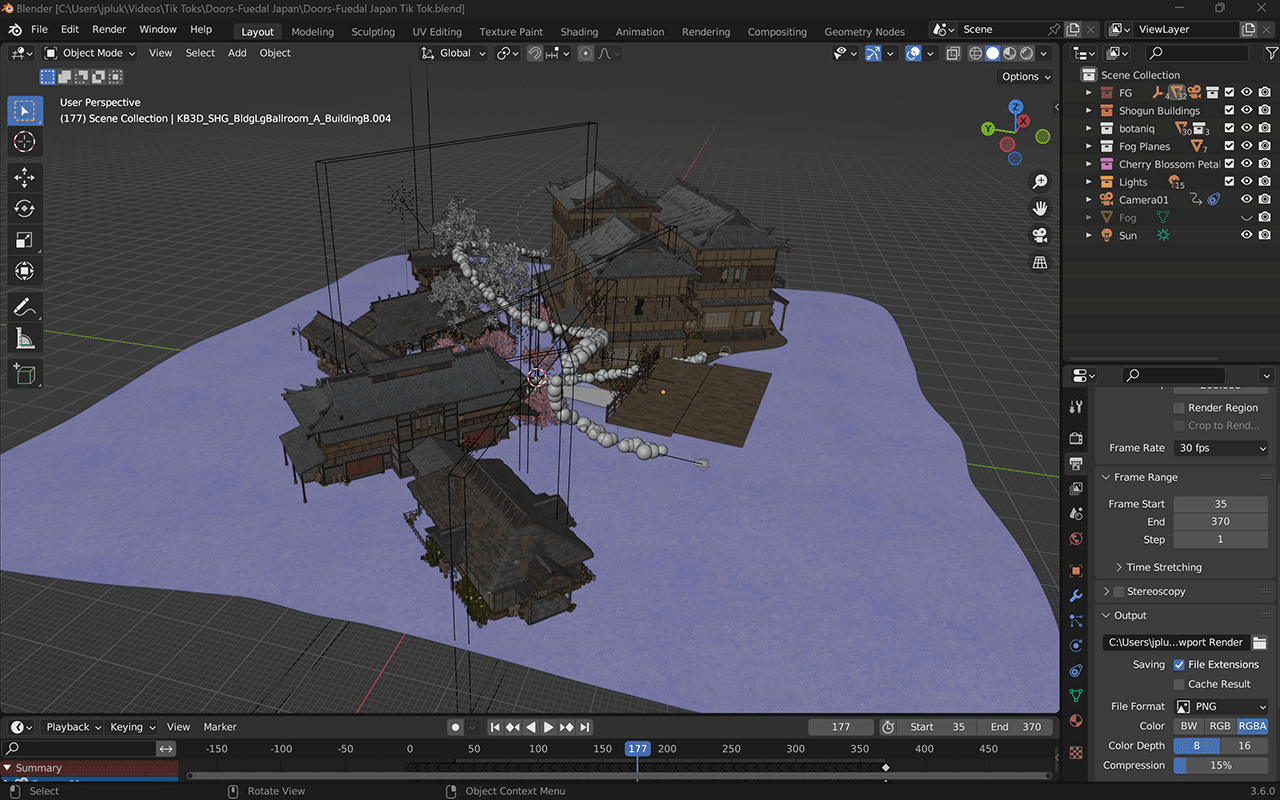
His GeForce graphics card enabled RTX-accelerated OptiX ray tracing in the viewport for interactive, photorealistic rendering. When the final renders were ready, Luke added the Doors to Realities template into an Adobe After Effects project with the clip already masked and ready to go. There, he added glow effects, one of over 30+ GPU-accelerated key effects, with keyframes set up from previous videos.
“The fact that I was able to work in rendered mode in real time on a device as small and portable as the Zenbook was mind blowing.” — JiffyVFX
“All I had to do was plop the render in, copy and paste the glow effects with their intensity keyframes and then hit render again,” said Luke.
Finally, Luke added music and background sounds like bird chirping, a river stream and the sound of leaves subtly blowing in the wind.
The Studio laptop not only enhances Luke’s content creation experience but also boosts the efficiency of his workflow. “High frame rates, DLSS 3 and ray tracing — what’s not to love?” said Luke.
He encourages other creators to push forward and continue experimenting.
“Never. Stop. Creating!” said Luke. “Never stop learning! The only way to improve is to keep pushing yourself and the limits of what you can do.”

Check out JiffyVFX on TikTok.
Follow NVIDIA Studio on Instagram, Twitter and Facebook. Access tutorials on the Studio YouTube channel and get updates directly in your inbox by subscribing to the Studio newsletter.