Posted by Nicholas Rubin, Senior Research Scientist, and Ryan Babbush, Head of Quantum Algorithms, Quantum AI Team

If you’ve paid attention to the quantum computing space, you’ve heard the claim that in the future, quantum computers will solve certain problems exponentially more efficiently than classical computers can. They have the potential to transform many industries, from pharmaceuticals to energy.
For the most part, these claims have rested on arguments about the asymptotic scaling of algorithms as the problem size approaches infinity, but this tells us very little about the practical performance of quantum computers for finite-sized problems. We want to be more concrete: Exactly which problems are quantum computers more suited to tackle than their classical counterparts, and exactly what quantum algorithms could we run to solve these problems? Once we’ve designed an algorithm, we can go beyond analysis based on asymptotic scaling — we can determine the actual resources required to compile and run the algorithm on a quantum computer, and how that compares to a classical computation.
Over the last few years, Google Quantum AI has collaborated with industry and academic partners to assess the prospects for quantum simulation to revolutionize specific technologies and perform concrete analyses of the resource requirements. In 2022, we developed quantum algorithms to analyze the chemistry of an important enzyme family called cytochrome P450. Then, in our paper released this fall, we demonstrated how to use a quantum computer to study sustainable alternatives to cobalt for use in lithium ion batteries. And most recently, as we report in a preprint titled “Quantum computation of stopping power for inertial fusion target design,” we’ve found a new application in modeling the properties of materials in inertial confinement fusion experiments, such as those at the National Ignition Facility (NIF) at Lawrence Livermore National Laboratory, which recently made headlines for a breakthrough in nuclear fusion.
Below, we describe these three industrially relevant applications for simulations with quantum computers. While running the algorithms will require an error-corrected quantum computer, which is still years away, working on this now will ensure that we are ready with efficient quantum algorithms when such a quantum computer is built. Already, our work has reduced the cost of compiling and running the algorithms significantly, as we have reported in the past. Our work is essential for demonstrating the potential of quantum computing, but it also provides our hardware team with target specifications for the number of qubits and time needed to run useful quantum algorithms in the future.
Application 1: The CYP450 mechanism
The pharmaceutical industry is often touted as a field ripe for discovery using quantum computers. But concrete examples of such potential applications are few and far between. Working with collaborators at the pharmaceutical company Boehringer Ingelheim, our partners at the startup QSimulate, and academic colleagues at Columbia University, we explored one example in the 2022 PNAS article, “Reliably assessing the electronic structure of cytochrome P450 on today’s classical computers and tomorrow’s quantum computers”.
Cytochrome P450 is an enzyme family naturally found in humans that helps us metabolize drugs. It excels at its job: more than 70% of all drug metabolism is performed by enzymes of the P450 family. The enzymes work by oxidizing the drug — a process that depends on complex correlations between electrons. The details of the interactions are too complicated for scientists to know a priori how effective the enzyme will be on a particular drug.
In the paper, we showed how a quantum computer could approach this problem. The CYP450 metabolic process is a complex chain of reactions with many intermediate changes in the electronic structure of the enzymes throughout. We first use state-of-the-art classical methods to determine the resources required to simulate this problem on a classical computer. Then we imagine implementing a phase-estimation algorithm — which is needed to compute the ground-state energies of the relevant electronic configurations throughout the reaction chain — on a surface-code error-corrected quantum computer.
With a quantum computer, we could follow the chain of changing electronic structure with greater accuracy and fewer resources. In fact, we find that the higher accuracy offered by a quantum computer is needed to correctly resolve the chemistry in this system, so not only will a quantum computer be better, it will be necessary. And as the system size gets bigger, i.e., the more quantum energy levels we include in the simulation, the more the quantum computer wins over the classical computer. Ultimately, we show that a few million physical qubits would be required to reach quantum advantage for this problem.
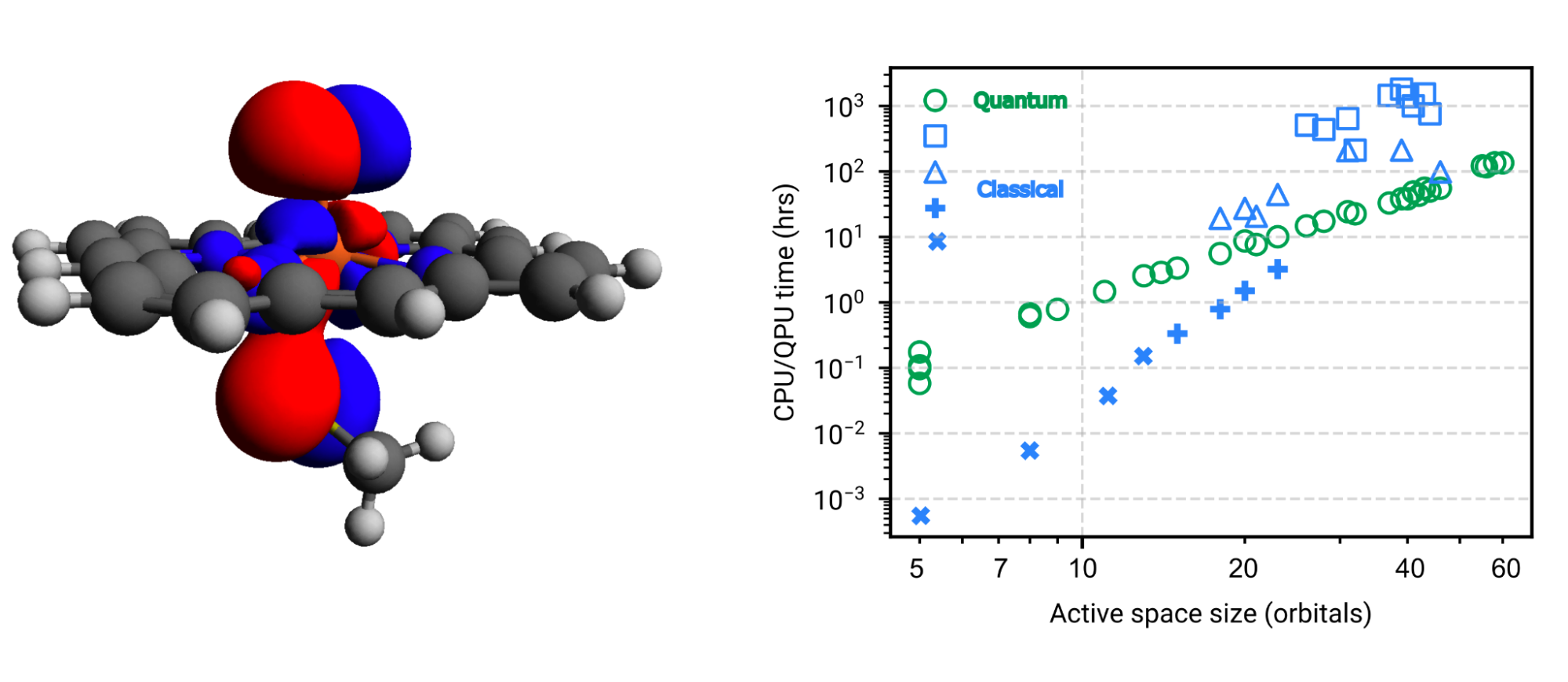 |
| Left: Example of an electron orbital (red and blue) of a CYP enzyme. More than 60 such orbitals are required to model the CYP system. Right: Comparison of actual runtime (CPU) of various classical techniques (blue) to hypothetical runtime (QPU) of a quantum algorithm (green). The lower slope of the quantum algorithm demonstrates the favorable asymptotic scaling over classical methods. Already at about 20-30 orbitals, we see a crossover to the regime where a quantum algorithm would be more efficient than classical methods. |
Application 2: Lithium-ion batteries
Lithium-ion batteries rely on the electrochemical potential difference between two lithium containing materials. One material used today for the cathodes of Li-ion batteries is LiCoO2. Unfortunately, it has drawbacks from a manufacturing perspective. Cobalt mining is expensive, destructive to the environment, and often utilizes unsafe or abusive labor practices. Consequently, many in the field are interested in alternatives to cobalt for lithium-ion cathodes.
In the 1990’s, researchers discovered that nickel could replace cobalt to form LiNiO2 (called “lithium nickel oxide” or “LNO”) for cathodes. While pure LNO was found to be unstable in production, many cathode materials used in the automotive industry today use a high fraction of nickel and hence, resemble LNO. Despite its applications to industry, however, not all of the chemical properties of LNO are understood — even the properties of its ground state remains a subject of debate.
In our recent paper, “Fault tolerant quantum simulation of materials using Bloch orbitals,” we worked with the chemical company, BASF, the molecular modeling startup, QSimulate, and collaborators at Macquarie University in Australia to develop techniques to perform quantum simulations on systems with periodic, regularly spaced atomic structure, such as LNO. We then applied these techniques to design algorithms to study the relative energies of a few different candidate structures of LNO. With classical computers, high accuracy simulations of the quantum wavefunction are considered too expensive to perform. In our work, we found that a quantum computer would need tens of millions of physical qubits to calculate the energies of each of the four candidate ground-state LNO structures. This is out of reach of the first error-corrected quantum computers, but we expect this number to come down with future algorithmic improvements.
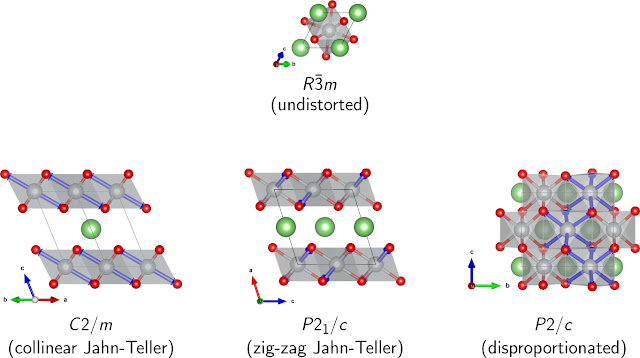 |
| Four candidate structures of LNO. In the paper, we consider the resources required to compare the energies of these structures in order to find the ground state of LNO. |
Application 3: Fusion reactor dynamics
In our third and most recent example, we collaborated with theorists at Sandia National Laboratories and our Macquarie University collaborators to put our hypothetical quantum computer to the task of simulating dynamics of charged particles in the extreme conditions typical of inertial confinement fusion (ICF) experiments, like those at the National Ignition Facility. In those experiments, high-intensity lasers are focused into a metallic cavity (hohlraum) that holds a target capsule consisting of an ablator surrounding deuterium–tritium fuel. When the lasers heat the inside of the hohlraum, its walls radiate x-rays that compress the capsule, heating the deuterium and tritium inside to 10s of millions of Kelvin. This allows the nucleons in the fuel to overcome their mutual electrostatic repulsion and start fusing into helium nuclei, also called alpha particles.
Simulations of these experiments are computationally demanding and rely on models of material properties that are themselves uncertain. Even testing these models, using methods similar to those in quantum chemistry, is extremely computationally expensive. In some cases, such test calculations have consumed >100 million CPU hours. One of the most expensive and least accurate aspects of the simulation is the dynamics of the plasma prior to the sustained fusion stage (>10s of millions of Kelvin), when parts of the capsule and fuel are a more balmy 100k Kelvin. In this “warm dense matter” regime, quantum correlations play a larger role in the behavior of the system than in the “hot dense matter” regime when sustained fusion takes place.
In our new preprint, “Quantum computation of stopping power for inertial fusion target design”, we present a quantum algorithm to compute the so-called “stopping power” of the warm dense matter in a nuclear fusion experiment. The stopping power is the rate at which a high energy alpha particle slows down due to Coulomb interactions with the surrounding plasma. Understanding the stopping power of the system is vital for optimizing the efficiency of the reactor. As the alpha particle is slowed by the plasma around it, it transfers its energy to the plasma, heating it up. This self-heating process is the mechanism by which fusion reactions sustain the burning plasma. Detailed modeling of this process will help inform future reactor designs.
We estimate that the quantum algorithm needed to calculate the stopping power would require resources somewhere between the P450 application and the battery application. But since this is the first case study on first-principles dynamics (or any application at finite temperature), such estimates are just a starting point and we again expect to find algorithmic improvements to bring this cost down in the future. Despite this uncertainty, it is still certainly better than the classical alternative, for which the only tractable approaches for these simulations are mean-field methods. While these methods incur unknown systematic errors when describing the physics of these systems, they are currently the only meaningful means of performing such simulations.
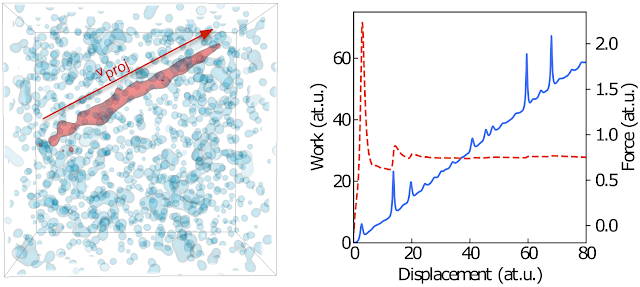 |
| Left: A projectile (red) passing through a medium (blue) with initial velocity vproj. Right: To calculate the stopping power, we monitor the energy transfer between the projectile and the medium (blue solid line) and determine its average slope (red dashed line). |
Discussion and conclusion
The examples described above are just three of a large and growing body of concrete applications for a future error-corrected quantum computer in simulating physical systems. This line of research helps us understand the classes of problems that will most benefit from the power of quantum computing. In particular, the last example is distinct from the other two in that it is simulating a dynamical system. In contrast to the other problems, which focus on finding the lowest energy, static ground state of a quantum system, quantum dynamics is concerned with how a quantum system changes over time. Since quantum computers are inherently dynamic — the qubit states evolve and change as each operation is performed — they are particularly well suited to solving these kinds of problems. Together with collaborators at Columbia, Harvard, Sandia National Laboratories and Macquarie University in Australia we recently published a paper in Nature Communications demonstrating that quantum algorithms for simulating electron dynamics can be more efficient even than approximate, “mean-field” classical calculations, while simultaneously offering much higher accuracy.
Developing and improving algorithms today prepares us to take full advantage of them when an error-corrected quantum computer is eventually realized. Just as in the classical computing case, we expect improvements at every level of the quantum computing stack to further lower the resource requirements. But this first step helps separate hyperbole from genuine applications amenable to quantum computational speedups.
Acknowledgements
We would like to thank Katie McCormick, our Quantum Science Communicator, for helping to write this blog post.
Read More





















 We’re testing new ways to get started on something you need to do — like creating an image that can bring an idea to life, or a written draft when you need a starting po…
We’re testing new ways to get started on something you need to do — like creating an image that can bring an idea to life, or a written draft when you need a starting po…