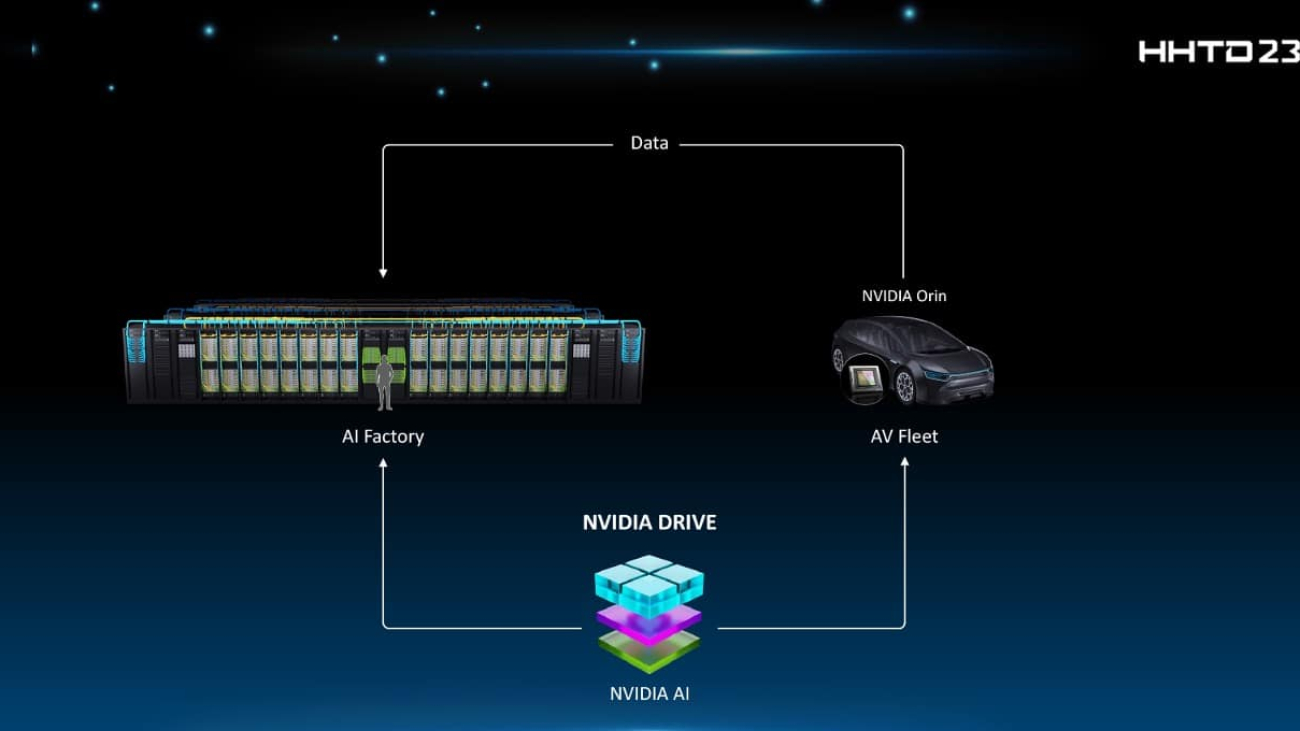
Powerful generative AI models and cloud-native APIs and microservices are coming to the edge.
Generative AI is bringing the power of transformer models and large language models to virtually every industry. That reach now includes areas that touch edge, robotics and logistics systems: defect detection, real-time asset tracking, autonomous planning and navigation, human-robot interactions and more.
NVIDIA today announced major expansions to two frameworks on the NVIDIA Jetson platform for edge AI and robotics: the NVIDIA Isaac ROS robotics framework has entered general availability, and the NVIDIA Metropolis expansion on Jetson is coming next.
To accelerate AI application development and deployments at the edge, NVIDIA has also created a Jetson Generative AI Lab for developers to use with the latest open-source generative AI models.
More than 1.2 million developers and over 10,000 customers have chosen NVIDIA AI and the Jetson platform, including Amazon Web Services, Cisco, John Deere, Medtronic, Pepsico and Siemens.
With the rapidly evolving AI landscape addressing increasingly complicated scenarios, developers are being challenged by longer development cycles to build AI applications for the edge. Reprogramming robots and AI systems on the fly to meet changing environments, manufacturing lines and automation needs of customers is time-consuming and requires expert skills.
Generative AI offers zero-shot learning — the ability for a model to recognize things specifically unseen before in training — with a natural language interface to simplify the development, deployment and management of AI at the edge.
Transforming the AI Landscape
Generative AI dramatically improves ease of use by understanding human language prompts to make model changes. Those AI models are more flexible in detecting, segmenting, tracking, searching and even reprogramming — and help outperform traditional convolutional neural network-based models.
Generative AI is expected to add $10.5 billion in revenue for manufacturing operations worldwide by 2033, according to ABI Research.
“Generative AI will significantly accelerate deployments of AI at the edge with better generalization, ease of use and higher accuracy than previously possible,” said Deepu Talla, vice president of embedded and edge computing at NVIDIA. “This largest-ever software expansion of our Metropolis and Isaac frameworks on Jetson, combined with the power of transformer models and generative AI, addresses this need.”
Developing With Generative AI at the Edge
The Jetson Generative AI Lab provides developers access to optimized tools and tutorials for deploying open-source LLMs, diffusion models to generate stunning interactive images, vision language models (VLMs) and vision transformers (ViTs) that combine vision AI and natural language processing to provide comprehensive understanding of the scene.
Developers can also use the NVIDIA TAO Toolkit to create efficient and accurate AI models for edge applications. TAO provides a low-code interface to fine-tune and optimize vision AI models, including ViT and vision foundational models. They can also customize and fine-tune foundational models like NVIDIA NV-DINOv2 or public models like OpenCLIP to create highly accurate vision AI models with very little data. TAO additionally now includes VisualChangeNet, a new transformer-based model for defect inspection.
Harnessing New Metropolis and Isaac Frameworks
NVIDIA Metropolis makes it easier and more cost-effective for enterprises to embrace world-class, vision AI-enabled solutions to improve critical operational efficiency and safety problems. The platform brings a collection of powerful application programming interfaces and microservices for developers to quickly develop complex vision-based applications.

More than 1,000 companies, including BMW Group, Pepsico, Kroger, Tyson Foods, Infosys and Siemens, are using NVIDIA Metropolis developer tools to solve Internet of Things, sensor processing and operational challenges with vision AI — and the rate of adoption is quickening. The tools have now been downloaded over 1 million times by those looking to build vision AI applications.
To help developers quickly build and deploy scalable vision AI applications, an expanded set of Metropolis APIs and microservices on NVIDIA Jetson will be available by year’s end.
Hundreds of customers use the NVIDIA Isaac platform to develop high-performance robotics solutions across diverse domains, including agriculture, warehouse automation, last-mile delivery and service robotics, among others.
At ROSCon 2023, NVIDIA announced major improvements to perception and simulation capabilities with new releases of Isaac ROS and Isaac Sim software. Built on the widely adopted open-source Robot Operating System (ROS), Isaac ROS brings perception to automation, giving eyes and ears to the things that move. By harnessing the power of GPU-accelerated GEMs, including visual odometry, depth perception, 3D scene reconstruction, localization and planning, robotics developers gain the tools needed to swiftly engineer robotic solutions tailored for a diverse range of applications.

Isaac ROS has reached production-ready status with the latest Isaac ROS 2.0 release, enabling developers to create and bring high-performance robotics solutions to market with Jetson.
“ROS continues to grow and evolve to provide open-source software for the whole robotics community,” said Geoff Biggs, CTO of the Open Source Robotics Foundation. “NVIDIA’s new prebuilt ROS 2 packages, launched with this release, will accelerate that growth by making ROS 2 readily available to the vast NVIDIA Jetson developer community.”
Delivering New Reference AI Workflows
Developing a production-ready AI solution entails optimizing the development and training of AI models tailored to specific use cases, implementing robust security features on the platform, orchestrating the application, managing fleets, establishing seamless edge-to-cloud communication and more.
NVIDIA announced a curated collection of AI reference workflows based on Metropolis and Isaac frameworks that enable developers to quickly adopt the entire workflow or selectively integrate individual components, resulting in substantial reductions in both development time and cost. The three distinct AI workflows include: Network Video Recording, Automatic Optical Inspection and Autonomous Mobile Robot.
“NVIDIA Jetson, with its broad and diverse user base and partner ecosystem, has helped drive a revolution in robotics and AI at the edge,” said Jim McGregor, principal analyst at Tirias Research. “As application requirements become increasingly complex, we need a foundational shift to platforms that simplify and accelerate the creation of edge deployments. This significant software expansion by NVIDIA gives developers access to new multi-sensor models and generative AI capabilities.”
More Coming on the Horizon
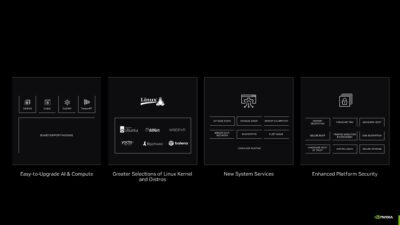
NVIDIA announced a collection of system services which are fundamental capabilities that every developer requires when building edge AI solutions. These services will simplify integration into workflows and spare developer the arduous task of building them from the ground up.
The new NVIDIA JetPack 6, expected to be available by year’s end, will empower AI developers to stay at the cutting edge of computing without the need for a full Jetson Linux upgrade, substantially expediting development timelines and liberating them from Jetson Linux dependencies. JetPack 6 will also use the collaborative efforts with Linux distribution partners to expand the horizon of Linux-based distribution choices, including Canonical’s Optimized and Certified Ubuntu, Wind River Linux, Concurrent Real’s Redhawk Linux and various Yocto-based distributions.
Partner Ecosystem Benefits From Platform Expansion
The Jetson partner ecosystem provides a wide range of support, from hardware, AI software and application design services to sensors, connectivity and developer tools. These NVIDIA Partner Network innovators play a vital role in providing the building blocks and sub-systems for many products sold on the market.
The latest release allows Jetson partners to accelerate their time to market and expand their customer base by adopting AI with increased performance and capabilities.
Independent software vendor partners will also be able to expand their offerings for Jetson.
Join us Tuesday, Nov. 7, at 9 a.m. PT for the Bringing Generative AI to Life with NVIDIA Jetson webinar, where technical experts will dive deeper into the news announced here, including accelerated APIs and quantization methods for deploying LLMs and VLMs on Jetson, optimizing vision transformers with TensorRT, and more.
Sign up for NVIDIA Metropolis early access here.














 Mason Cahill is a Senior DevOps Consultant with AWS Professional Services. He enjoys helping organizations achieve their business goals, and is passionate about building and delivering automated solutions on the AWS Cloud. Outside of work, he loves spending time with his family, hiking, and playing soccer.
Mason Cahill is a Senior DevOps Consultant with AWS Professional Services. He enjoys helping organizations achieve their business goals, and is passionate about building and delivering automated solutions on the AWS Cloud. Outside of work, he loves spending time with his family, hiking, and playing soccer. Matthew Chasse is a Data Science consultant at Amazon Web Services, where he helps customers build scalable machine learning solutions. Matthew has a Mathematics PhD and enjoys rock climbing and music in his free time.
Matthew Chasse is a Data Science consultant at Amazon Web Services, where he helps customers build scalable machine learning solutions. Matthew has a Mathematics PhD and enjoys rock climbing and music in his free time. Rushikesh Jagtap is a Solutions Architect with 5+ years of experience in AWS Analytics services. He is passionate about helping customers to build scalable and modern data analytics solutions to gain insights from the data. Outside of work, he loves watching Formula1, playing badminton, and racing Go Karts.
Rushikesh Jagtap is a Solutions Architect with 5+ years of experience in AWS Analytics services. He is passionate about helping customers to build scalable and modern data analytics solutions to gain insights from the data. Outside of work, he loves watching Formula1, playing badminton, and racing Go Karts. Tayo Olajide is a seasoned Cloud Data Engineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments. With a passion for transforming raw data into valuable insights, Tayo has played a pivotal role in designing and optimizing data pipelines for various industries, including finance, healthcare, and auto industries. As a thought leader in the field, Tayo believes that the power of data lies in its ability to drive informed decision-making and is committed to helping businesses leverage the full potential of their data in the cloud era. When he’s not crafting data pipelines, you can find Tayo exploring the latest trends in technology, hiking in the great outdoors, or tinkering with gadgetry and software.
Tayo Olajide is a seasoned Cloud Data Engineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments. With a passion for transforming raw data into valuable insights, Tayo has played a pivotal role in designing and optimizing data pipelines for various industries, including finance, healthcare, and auto industries. As a thought leader in the field, Tayo believes that the power of data lies in its ability to drive informed decision-making and is committed to helping businesses leverage the full potential of their data in the cloud era. When he’s not crafting data pipelines, you can find Tayo exploring the latest trends in technology, hiking in the great outdoors, or tinkering with gadgetry and software.





 The cover image of Halač’s book.
The cover image of Halač’s book.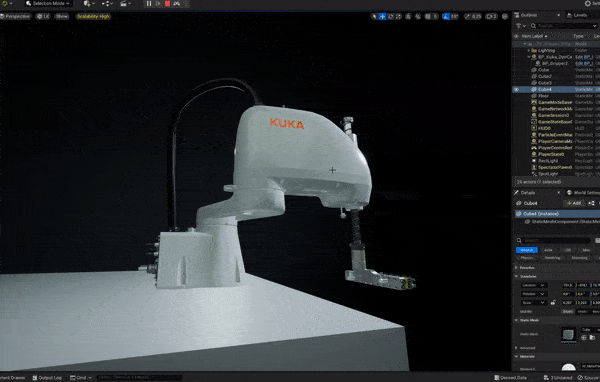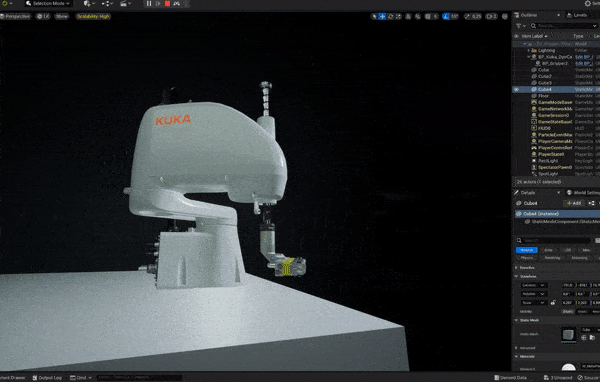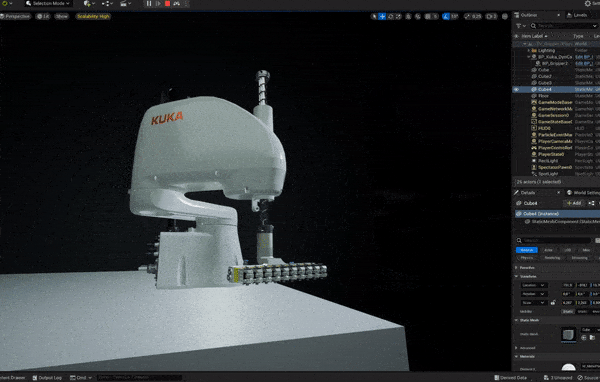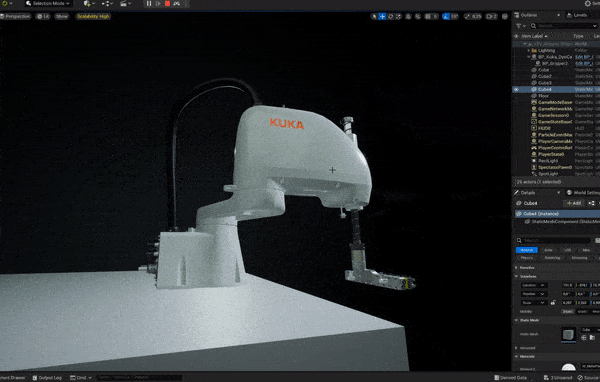 A Kuka Scara robot simulation with 10 parallel small grippers for sorting and handling pens.
A Kuka Scara robot simulation with 10 parallel small grippers for sorting and handling pens.
 courtesy of
courtesy of 
 Google shares the report: Building a Secure Foundation for American Leadership in AI.
Google shares the report: Building a Secure Foundation for American Leadership in AI.