 AI has the potential to mitigate 5-10% of global greenhouse gas emissions according to our new report with Boston Consulting Group.Read More
AI has the potential to mitigate 5-10% of global greenhouse gas emissions according to our new report with Boston Consulting Group.Read More

AI has the potential to mitigate 5-10% of global greenhouse gas emissions according to our new report with Boston Consulting Group.Read More


The first of Google’s AI Principles is to “Be socially beneficial.” As AI practitioners, we’re inspired by the transformative potential of AI technologies to benefit society and our shared environment at a scale and swiftness that wasn’t possible before. From helping address the climate crisis to helping transform healthcare, to making the digital world more accessible, our goal is to apply AI responsibly to be helpful to more people around the globe. Achieving global scale requires researchers and communities to think ahead — and act — collectively across the AI ecosystem.
We call this approach Society-Centered AI. It is both an extension and an expansion of Human-Centered AI, focusing on the aggregate needs of society that are still informed by the needs of individual users, specifically within the context of the larger, shared human experience. Recent AI advances offer unprecedented, societal-level capabilities, and we can now methodically address those needs — if we apply collective, multi-disciplinary AI research to society-level, shared challenges, from forecasting hunger to predicting diseases to improving productivity.
The opportunity for AI to benefit society increases each day. We took a look at our work in these areas and at the research projects we have supported. Recently, Google announced that 70 professors were selected for the 2023 Award for Inclusion Research Program, which supports academic research that addresses the needs of historically marginalized groups globally. Through evaluation of this work, we identified a few emerging practices for Society-Centered AI:
The case examples described below show how the Society-Centered AI approach has led to impact across topics, such as accessibility, health, and climate.
There are millions of people with non-standard speech (e.g., impaired articulation, dysarthria, dysphonia) in the United States alone. In 2019, Google Research launched Project Euphonia, a methodology that allows individual users with non-standard speech to train personalized speech recognition models. Our success began with the impact we had on each individual who is now able to use voice dictation on their mobile device.
Euphonia started with a Society-Centered AI approach, including collective efforts with the non-profit organizations ALS Therapy Development Institute and ALS Residence Initiative to understand the needs of individuals with amyotrophic lateral sclerosis (ALS) and their ability to use automatic speech recognition systems. Later, we developed the world’s largest corpus of non-standard speech recordings, which enabled us to train a Universal Speech Model to better recognize disordered speech by 37% on real conversation word error rate (WER) measurement. This also led to the 2022 collaboration between the University of Illinois Urbana-Champaign, Alphabet, Apple, Meta, Microsoft, and Amazon to begin the Speech Accessibility Project, an ongoing initiative to create a publicly available dataset of disordered speech samples to improve products and make speech recognition more inclusive of diverse speech patterns. Other technologies that use AI to help remove barriers of modality and languages, include live transcribe, live caption and read aloud.
Access to timely maternal health information can save lives globally: every two minutes a woman dies during pregnancy or childbirth and 1 in 26 children die before reaching age five. In rural India, the education of expectant and new mothers around key health issues pertaining to pregnancy and infancy required scalable, low-cost technology solutions. Together with ARMMAN, Google Research supported a program that uses mobile messaging and machine learning (ML) algorithms to predict when women might benefit from receiving interventions (i.e., targeted preventative care information) and encourages them to engage with the mMitra free voice call program. Within a year, the mMitra program has shown a 17% increase in infants with tripled birth weight and a 36% increase in women understanding the importance of taking iron tablets during pregnancy. Over 175K mothers and growing have been reached through this automated solution, which public health workers use to improve the quality of information delivery.
These efforts have been successful in improving health due to the close collective partnership among the community and those building the AI technology. We have adopted this same approach via collaborations with caregivers to address a variety of medical needs. Some examples include: the use of the Automated Retinal Disease Assessment (ARDA) to help screen for diabetic retinopathy in 250,000 patients in clinics around the world; our partnership with iCAD to bring our mammography AI models to clinical settings to aid in breast cancer detection; and the development of Med-PaLM 2, a medical large language model that is now being tested with Cloud partners to help doctors provide better patient care.
Google Research’s flood prediction efforts began in 2018 with flood forecasting in India and expanded to Bangladesh to help combat the catastrophic damage from yearly floods. The initial efforts began with partnerships with India’s Central Water Commission, local governments and communities. The implementation of these efforts used SOS Alerts on Search and Maps, and, more recently, broadly expanded access via Flood Hub. Continued collaborations and advancing an AI-based global flood forecasting model allowed us to expand this capability to over 80 countries across Africa, the Asia-Pacific region, Europe, and South, Central, and North America. We also partnered with networks of community volunteers to further amplify flood alerts. By working with governments and communities to measure the impact of these efforts on society, we refined our approach and algorithms each year.
We were able to leverage those methodologies and some of the underlying technology, such as SOS Alerts, from flood forecasting to similar societal needs, such as wildfire forecasting and heat alerts. Our continued engagements with organizations led to the support of additional efforts, such as the World Meteorological Organization’s (WMO) Early Warnings For All Initiative. The continued engagement with communities has allowed us to learn about our users’ needs on a societal level over time, expand our efforts, and compound the societal reach and impact of our efforts.
We recently funded 18 university research proposals exemplifying a Society-Centered AI approach, a new track within the Google Award for Inclusion Research Program. These researchers are taking the Society-Centered AI methodology and helping create beneficial applications across the world. Examples of some of the projects funded include:
Focusing on society’s needs, working via multidisciplinary collective research, and measuring the impact on society helps lead to AI solutions that are relevant, long-lasting, empowering, and beneficial. See the AI for the Global Goals to learn more about potential Society-Centered AI research problems. Our efforts with non-profits in these areas is complementary to the research that we are doing and encouraging. We believe that further initiatives using Society-Centered AI will help the collective research community solve problems and positively impact society at large.
Many thanks to the many individuals who have worked on these projects at Google including Shruti Sheth, Reena Jana, Amy Chung-Yu Chou, Elizabeth Adkison, Sophie Allweis, Dan Altman, Eve Andersson, Ayelet Benjamini, Julie Cattiau, Yuval Carny, Richard Cave, Katherine Chou, Greg Corrado, Carlos De Segovia, Remi Denton, Dotan Emanuel, Ashley Gardner, Oren Gilon, Taylor Goddu, Brigitte Hoyer Gosselink, Jordan Green, Alon Harris, Avinatan Hassidim, Rus Heywood, Sunny Jansen, Pan-Pan Jiang, Anton Kast, Marilyn Ladewig, Ronit Levavi Morad, Bob MacDonald, Alicia Martin, Shakir Mohamed, Philip Nelson, Moriah Royz, Katie Seaver, Joel Shor, Milind Tambe, Aparna Taneja, Divy Thakkar, Jimmy Tobin, Katrin Tomanek, Blake Walsh, Gal Weiss, Kasumi Widner, Lihong Xi, and teams.

 Posted by the TensorFlow team
Posted by the TensorFlow team

TensorFlow 2.15 has been released! Highlights of this release (and 2.14) include a much simpler installation method for NVIDIA CUDA libraries for Linux, oneDNN CPU performance optimizations for Windows x64 and x86, full availability of tf.function types, an upgrade to Clang 17.0.1, and much more! For the full release note, please check here.
The tensorflow pip package has a new, optional installation method for Linux that installs necessary NVIDIA CUDA libraries through pip. As long as the NVIDIA driver is already installed on the system, you may now run pip install tensorflow[and-cuda] to install TensorFlow’s NVIDIA CUDA library dependencies in the Python environment. Aside from the NVIDIA driver, no other pre-existing NVIDIA CUDA packages are necessary. In TensorFlow 2.15, CUDA has been upgraded to version 12.2.
For Windows x64 & x86 packages, oneDNN optimizations are now enabled by default on X86 CPUs. These optimizations can be enabled or disabled by setting the environment variable TF_ENABLE_ONEDNN_OPTS to 1 (enable) or 0 (disable) before running TensorFlow. To fall back to default settings, simply unset the environment variable.
tf.function types are now fully available.
tf.types.experimental.TraceTypenow allows custom tf.function inputs to declare Tensor decomposition and type casting support.
- Introducing
tf.types.experimental.FunctionTypeas the comprehensive representation of the signature of tf.function callables. It can be accessed through thefunction_typeproperty oftf.function’sandConcreteFunctions. See thetf.types.experimental.FunctionTypedocumentation for more details.
- Introducing
tf.types.experimental.AtomicFunctionas the fastest way to perform TF computations in Python. This capability can be accessed through theinference_fnproperty ofConcreteFunctions. (Does not support gradients.) See thetf.types.experimental.AtomicFunctiondocumentation for how to call and use it.
TensorFlow PIP packages are now being built with Clang 17 and CUDA 12.2 to improve performance for NVIDIA Hopper-based GPUs. Moving forward, Clang 17 will be the default C++ compiler for TensorFlow. We recommend upgrading your compiler to Clang 17 when building TensorFlow from source.

Good news for car lovers: Two acclaimed auto shows, taking place now through next week, are delighting attendees with displays of next-generation automotive designs powered by AI.
Hundreds of thousands of auto enthusiasts worldwide are expected to visit Guangzhou, China — known as the city of flowers — to attend its auto show, running through Sunday, Nov. 26. The event will feature new developments in electric vehicles (EVs) and automated driving, with 1,100 vehicles on display.
And across the world, in the city of angels, the Los Angeles Auto Show is expected to reach its highest-ever attendee numbers. Also running through Nov. 26, the show will include classic and exotic cars from private collections, as well as a public test track where attendees can get behind the wheel of the latest EVs.

One of the most anticipated reveals is from Lotus, which is showcasing its new fully electric Emeya Hyper-GT that launched in September. This stunning luxury vehicle with sports-car agility achieves an impressive suite of intelligent features, powered by dual NVIDIA DRIVE Orin processors. The high-performance processing power enables drivers to enjoy the car’s safe and secure driving capabilities and supports future features through over-the-air (OTA) updates.
With an eye on safety, Emeya carries 34 state-of-the-art surround sensors for diverse and redundant sensor data processing in real time — giving drivers added confidence when behind the wheel. With DRIVE Orin embedded in the back of the vehicle, Emeya delivers advanced driver assistance system (ADAS) capabilities and also offers the built-in headroom to support an autonomous future.
Emeya Hyper-GT is built on Lotus’ innovative Electric Premium Architecture, which underpins the Eletre Hyper-SUV as well, also powered by NVIDIA DRIVE Orin.
In addition, Lotus is showcasing its full range of Lotus electric vehicles, including the Evija hypercar, Eletre Hyper-SUV and Type 136, its recently launched electric bike. Emira, Lotus’ final internal combustion engine vehicle, is also on display.
Several other NVIDIA DRIVE ecosystem members are featuring their next-gen EVs at Auto Guangzhou:
In addition, NVIDIA DRIVE ecosystem partner DeepRoute.ai, a smart driving solutions provider, is demonstrating its DeepRoute Driver 3.0, designed to offer a non-geofenced solution for automated vehicles.

At the LA Auto Show, Lucid Motors is showcasing its highly anticipated Gravity SUV, which will begin production in late 2024. Powered by NVIDIA DRIVE, the luxury SUV features supercar levels of performance and an impressive battery range to mitigate range anxiety.
In addition, Lucid is displaying its Lucid Air sedan, including the Air Pure and Air Touring models. All of these vehicles feature the future-ready DreamDrive Pro driver-assistance system, powered by the NVIDIA DRIVE platform.
Learn more about the industry-leading designs and technologies NVIDIA is developing with its automotive partners.

European startups will get a massive boost from a new generation of AI infrastructure, NVIDIA founder and CEO Jensen Huang said Friday in a fireside chat with iliad Group Deputy CEO Aude Durand — and it’s coming just in time.
“We’re now seeing a major second wave,” Huang said of the state of AI during a virtual appearance at Scaleway’s ai-PULSE conference in Paris for an audience of more than 1,000 in-person attendees.
Two elements are propelling this force, Huang explained in a conversation livestreamed from Station F, the world’s largest startup campus, which Huang joined via video conference from NVIDIA’s headquarters in Silicon Valley.
First, “a recognition that every region and every country needs to build their sovereign AI,” Huang said. Second, the “adoption of AI in different industries,” as generative AI spreads throughout the world, Huang explained.
“So the types of breakthroughs that we’re seeing in language I fully expect to see in digital biology and manufacturing and robotics,” Huang said, noting this could create big opportunities for Europe with its rich digital biology and healthcare industries. “And of course, Europe is also home of some of the largest industrial manufacturing companies.”
Durand kicked off the conversation by asking Huang about his views on the European AI ecosystem, especially in France, where the government has invested millions of euros in AI research and development.
“Europe has always been rich in AI expertise,” Huang said, noting that NVIDIA works with 4,000 startups in Europe, more than 400 of them in France alone, pointing to Mistral, Qubit Pharmaceuticals and Poolside AI.
“At the same time, you have to really get the computing infrastructure going,” Huang said. “And this is the reason why Scaleway is so important to the advancement of AI in France” and throughout Europe, Huang said.
Highlighting the critical role of data in AI’s regional growth, Huang noted companies’ increasing awareness of the value of training AI with region-specific data. AI systems need to reflect the unique cultural and industrial nuances of each region, an approach gaining traction across Europe and beyond.
Scaleway, a subsidiary of iliad Group, a major European telecoms player, is doing its part to kick-start that second wave in Europe, offering cloud credits for access to its AI supercomputer cluster, which packs 1,016 NVIDIA H100 Tensor Core GPUs.
As a regional cloud service provider, Scaleway also provides sovereign infrastructure that ensures access and compliance with EU data protection laws, which is critical for businesses with a European footprint.
Regional members of the NVIDIA Inception program, which provides development assistance to startups, will also be able to access NVIDIA AI Enterprise software on Scaleway Marketplace.
The software includes the NVIDIA NeMo framework and pretrained models for building LLMs, NVIDIA RAPIDS for accelerated data science and NVIDIA Triton Inference Server and NVIDIA TensorRT-LLM for boosting inference.
Recapping a month packed with announcements, Huang explained how NVIDIA is rapidly advancing high performance computing and AI worldwide to provide the infrastructure needed to power this second wave.
These systems are, in effect, “supercomputers,” Huang said, with AI systems now among the world’s most powerful.
They include Scaleway’s newly available Nabuchodonosor supercomputer, or “Nabu,” an NVIDIA DGX SuperPOD with 127 NVIDIA DGX H100 systems, which will help startups in France and across Europe scale up AI workloads.
“As you know the Scaleway system that we brought online, Nabu, is not your normal computer,” Huang said. “In every single way, it’s a supercomputer.”
Such systems are underpinning powerful new services.
Earlier this week, NVIDIA announced an AI Foundry service on Microsoft Azure, aimed at accelerating the development of customized generative AI applications.
Huang highlighted NVIDIA AI foundry’s appeal to a diverse user base, including established enterprises such as Amdocs, Getty Images, SAP and ServiceNow.
Huang noted that JUPITER, to be hosted at the Jülich facility, in Germany, and poised to be Europe’s premier exascale AI supercomputer, will run on 24,000 NVIDIA GH200 Grace Hopper Superchips, offering unparalleled computational capacity for diverse AI tasks and simulations.
Huang touched on NVIDIA’s just-announced HGX H200 AI computing platform, built on NVIDIA’s Hopper architecture and featuring the H200 Tensor Core GPU. Set for release in Q2 of 2024, it promises to redefine industry standards.
He also detailed NVIDIA’s strategy to develop ‘AI factories,’ advanced data centers that power diverse applications across industries, including electric vehicles, robotics, and generative AI services.
Finally, Durand asked Huang about the role of open source and open science in AI.
Huang said he’s a “huge fan” of open source. “Let’s acknowledge that without open source, how would AI have made the tremendous progress it has over the last decade,” Huang said.
“And so the ability for open source to energize the vibrancy and pull in the research and pull in the engagement of every startup, every researcher, every industry is really quite vital,” Huang said. “And you’re seeing it play out just presently, now going forward.”
Friday’s fireside conversation was part of Scaleway’s ai-PULSE conference, showcasing the latest AI trends and innovations. To learn more, visit https://www.ai-pulse.eu/.

 Posted by Sharbani Roy – Senior Director, Product Management, Google
Posted by Sharbani Roy – Senior Director, Product Management, Google
The Women in ML Symposium is an inclusive event for anyone passionate about the transformative fields of Machine Learning (ML) and Artificial Intelligence (AI). Dive into the latest advancements in generative AI, explore the intricacies of privacy-preserving AI, dig into the underlying accelerators and ML frameworks that power models, and uncover practical applications of ML across multiple industries.
Our event offers sessions for all expertise levels, from beginners to advanced practitioners. Hear about what’s new in ML and building with Google AI from our keynote speakers, gain insights from seasoned industry leaders across Google Health, Nvidia, Adobe, and more – and discover a wealth of knowledge on topics ranging from foundational AI concepts to open source tools, techniques, and beyond.
RSVP today to secure your spot and explore our exciting agenda. We can’t wait to see you there!
Amazon Interactive Video Service (Amazon IVS) is a managed live streaming solution that is designed to provide a quick and straightforward setup to let you build interactive video experiences and handles interactive video content from ingestion to delivery.
With the increased usage of live streaming, the need for effective content moderation becomes even more crucial. User-generated content (UGC) presents complex challenges for safety. Many companies rely on human moderators to monitor video streams, which is time-consuming, error-prone, and doesn’t scale with business growth speed. An automated moderation solution supporting a human in the loop (HITL) is increasingly needed.
Amazon Rekognition Content Moderation, a capability of Amazon Rekognition, automates and streamlines image and video moderation workflows without requiring machine learning (ML) experience. In this post, we explain the common practice of live stream visual moderation with a solution that uses the Amazon Rekognition Image API to moderate live streams. You can deploy this solution to your AWS account using the AWS Cloud Development Kit (AWS CDK) package available in our GitHub repo.
The most common approach for UGC live stream visual moderation involves sampling images from the stream and utilizing image moderation to receive near-real-time results. Live stream platforms can use flexible rules to moderate visual content. For instance, platforms with younger audiences might have strict rules about adult content and certain products, whereas others might focus on hate symbols. These platforms establish different rules to match their policies effectively. Combining human and automatic review, a hybrid process is a common design approach. Certain streams will be stopped automatically, but human moderators will also assess whether a stream violates platform policies and should be deactivated.
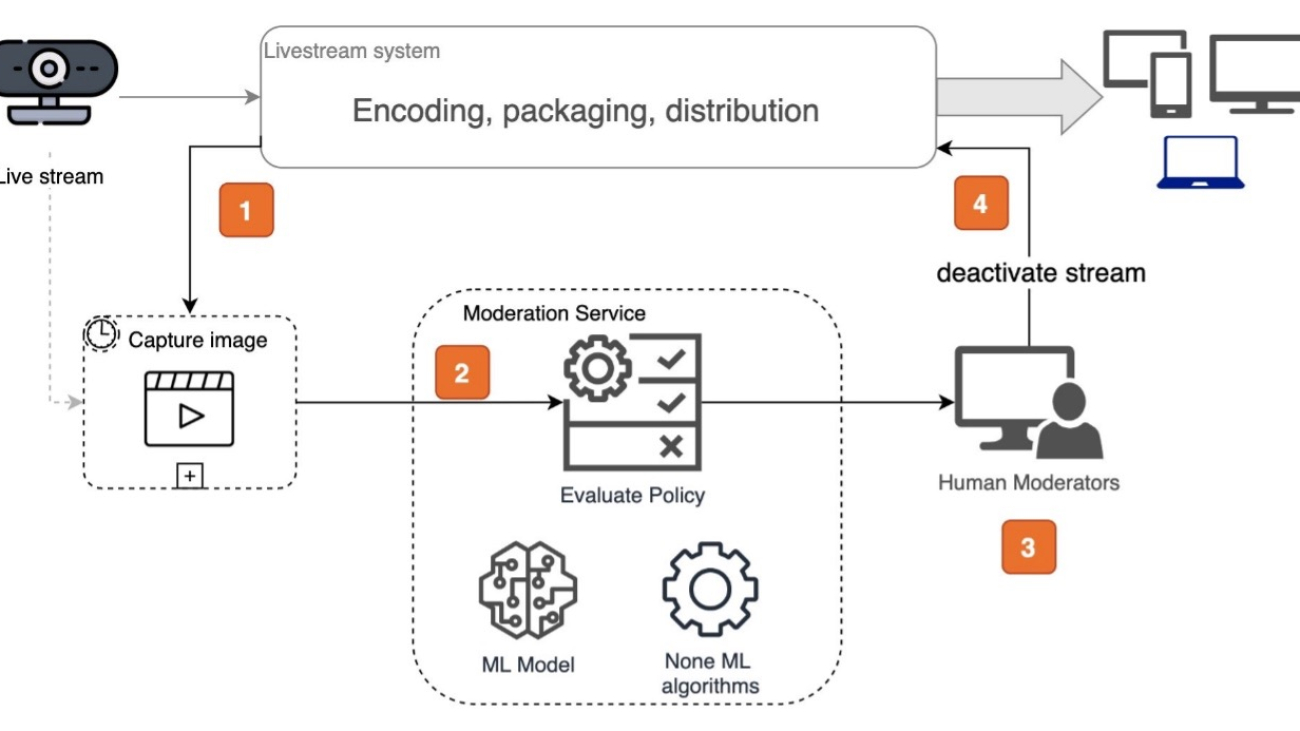
The following diagram illustrates the conceptual workflow of a near-real-time moderation system, designed with loose coupling to the live stream system.

The workflow contains the following steps:
Moderating UGC live streams is distinct from classic video moderation in media. It caters to diverse regulations. How frequently images are sampled from video frames for moderation is typically determined by the platform’s Trust & Safety policy and the service-level agreement (SLA). For instance, if a live stream platform aims to stop channels within 3 minutes for policy violations, a practical approach is to sample every 1–2 minutes, allowing time for human moderators to verify and take action. Some platforms require flexible moderation frequency control. For instance, highly reputable streamers may need less moderation, whereas new ones require closer attention. This also enables cost-optimization by reducing sampling frequency.
Cost is an important consideration in any live stream moderation solution. As UGC live stream platforms rapidly expand, moderating concurrent streams at a high frequency can raise cost concerns. The solution presented in this post is designed to optimize cost by allowing you to define moderation rules to customize sample frequency, ignore similar image frames, and other techniques.
Amazon IVS offers native solutions for recording stream content to an Amazon Simple Storage Service (Amazon S3) bucket and generating thumbnails—image frames from a video stream. It generates thumbnails every 60 seconds by default and provides users the option to customize the image quality and frequency. Using the AWS Management Console, you can create a recording configuration and link it to an Amazon IVS channel. When a recording configuration is associated with a channel, the channel’s live streams are automatically recorded to the specified S3 bucket.
There are no Amazon IVS charges for using the auto-record to Amazon S3 feature or for writing to Amazon S3. There are charges for Amazon S3 storage, Amazon S3 API calls that Amazon IVS makes on behalf of the customer, and serving the stored video to viewers. For details about Amazon IVS costs, refer to Costs (Low-Latency Streaming).
In this solution, we use the Amazon Rekognition DetectModerationLabel API to moderate Amazon IVS thumbnails in near-real time. Amazon Rekognition Content Moderation provides pre-trained APIs to analyze a wide range of inappropriate or offensive content, such as violence, nudity, hate symbols, and more. For a comprehensive list of Amazon Rekognition Content Moderation taxonomies, refer to Moderating content.
The following code snippet demonstrates how to call the Amazon Rekognition DetectModerationLabel API to moderate images within an AWS Lambda function using the Python Boto3 library:
The following is an example response from the Amazon Rekognition Image Moderation API:
For additional examples of the Amazon Rekognition Image Moderation API, refer to our Content Moderation Image Lab.
This solution integrates with Amazon IVS by reading thumbnail images from an S3 bucket and sending images to the Amazon Rekognition Image Moderation API. It provides choices for stopping the stream automatically and human-in-the-loop review. You can configure rules for the system to automatically halt streams based on conditions. It also includes a light human review portal, empowering moderators to monitor streams, manage violation alerts, and stop streams when necessary.
In this section, we briefly introduce the system architecture. For more detailed information, refer to the GitHub repo.
The following screen recording displays the moderator UI, enabling them to monitor active streams with moderation warnings, and take actions such as stopping the stream or dismissing warnings.

Users can customize moderation rules, controlling video stream sample frequency per channel, configuring Amazon Rekognition moderation categories with confidence thresholds, and enabling similarity checks, which ensures performance and cost-optimization by avoiding processing redundant images.
The following screen recording displays the UI for managing a global configuration.

The solution uses a microservices architecture, which consists of two key components loosely coupled with Amazon IVS.

The rules engine forms the backbone of the live stream moderation system. It is a live processing service that enables near-real-time moderation. It uses Amazon Rekognition to moderate images, validates results against customizable rules, employs image hashing algorithms to recognize and exclude similar images, and can halt streams automatically or alert the human review subsystem upon rule violations. The service integrates with Amazon IVS through Amazon S3-based image reading and facilitates API invocation via Amazon API Gateway.
The following architecture diagram illustrates the near-real-time moderation workflow.

There are two methods to trigger the rules engine processing workflow:
The image processing workflow, managed by AWS Step Functions, involves several steps:
The design manages rules through a Step Functions state machine, providing a drag-and-drop GUI for flexible workflow definition. You can extend the rules engine by incorporating additional Step Functions workflows.
The monitoring and management dashboard is a web application with a UI that lets human moderators monitor Amazon IVS live streams. It provides near-real-time moderation alerts, allowing moderators to stop streams or dismiss warnings. The web portal also empowers administrators to manage moderation rules for the rules engine. It supports two types of configurations:
The system is a serverless web app, featuring a static React front end hosted on Amazon S3 with Amazon CloudFront for caching. Authentication is handled by Amazon Cognito. Data is served through API Gateway and Lambda, with state storage in Amazon DynamoDB. The following diagram illustrates this architecture.

The monitoring dashboard is a lightweight demo app that provides essential features for moderators. To enhance functionality, you can extend the implementation to support multiple moderators with a management system and reduce latency by implementing a push mechanism using WebSockets.
The solution is designed for near-real-time moderation, with latency measured across two separate subsystems:
This post focuses on live stream visual content moderation. However, the solution is intentionally flexible, capable of accommodating complex business rules and extensible to support other media types, including moderating chat messages and audio in live streams. You can enhance the rules engine by introducing new Step Functions state machine workflows with upstream dispatching logic. We’ll delve deeper into live stream text and audio moderation using AWS AI services in upcoming posts.
In this post, we provided an overview of a sample solution that showcases how to moderate Amazon IVS live stream videos using Amazon Rekognition. You can experience the sample app by following the instructions in the GitHub repo and deploying it to your AWS account using the included AWS CDK package.
Learn more about content moderation on AWS. Take the first step towards streamlining your content moderation operations with AWS.
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
 Tony Vu is a Senior Partner Engineer at Twitch. He specializes in assessing partner technology for integration with Amazon Interactive Video Service (IVS), aiming to develop and deliver comprehensive joint solutions to our IVS customers.
Tony Vu is a Senior Partner Engineer at Twitch. He specializes in assessing partner technology for integration with Amazon Interactive Video Service (IVS), aiming to develop and deliver comprehensive joint solutions to our IVS customers.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. This post presents the capabilities of the RAG model and highlights the transformative potential of MongoDB Atlas with its Vector Search feature.
MongoDB Atlas is an integrated suite of data services that accelerate and simplify the development of data-driven applications. Its vector data store seamlessly integrates with operational data storage, eliminating the need for a separate database. This integration enables powerful semantic search capabilities through Vector Search, a fast way to build semantic search and AI-powered applications.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. You can access, customize, and deploy pre-trained models and data through the SageMaker JumpStart landing page in Amazon SageMaker Studio with just a few clicks.
Amazon Lex is a conversational interface that helps businesses create chatbots and voice bots that engage in natural, lifelike interactions. By integrating Amazon Lex with generative AI, businesses can create a holistic ecosystem where user input seamlessly transitions into coherent and contextually relevant responses.
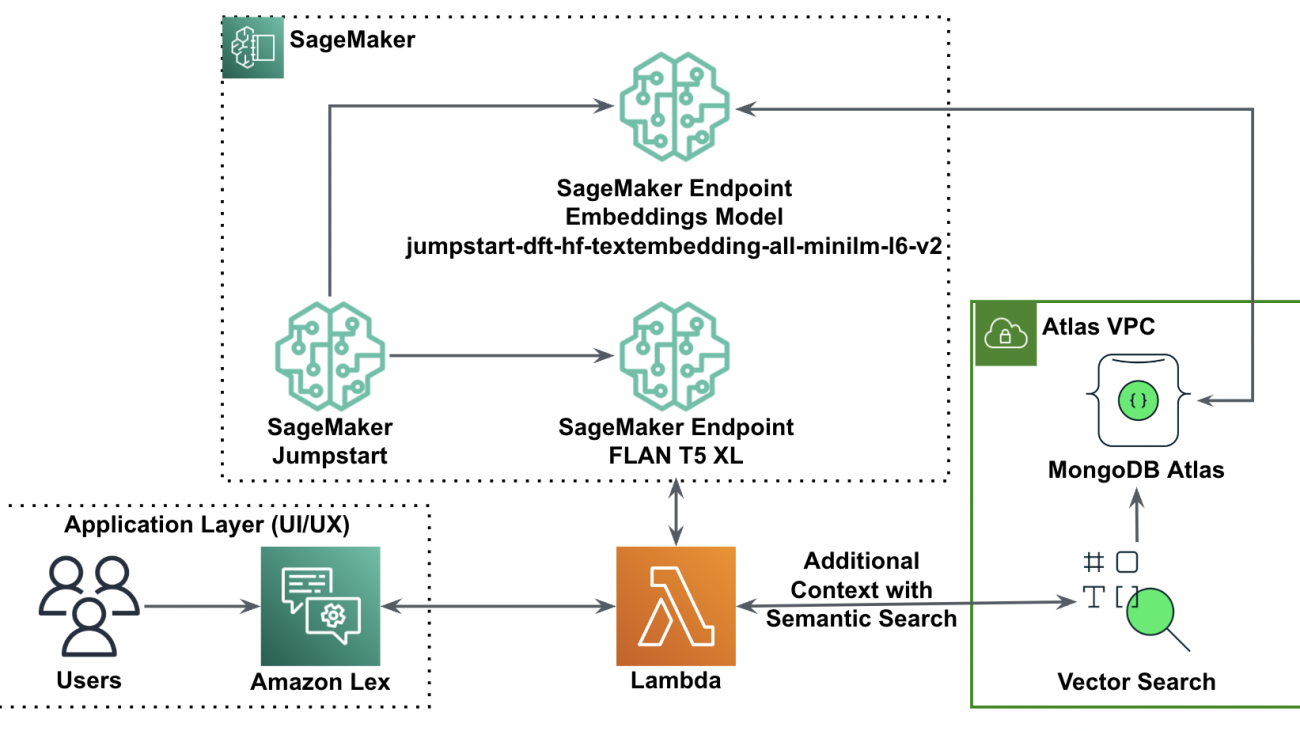
The following diagram illustrates the solution architecture.

In the following sections, we walk through the steps to implement this solution and its components.
To create a free tier MongoDB Atlas cluster, follow the instructions in Create a Cluster. Set up the database access and network access.
You can choose the embedding model (ALL MiniLM L6 v2) on the SageMaker JumpStart Models, notebooks, solutions page.

Choose Deploy to deploy the model.
Verify the model is successfully deployed and verify the endpoint is created.

Vector embedding is a process of converting a text or image into a vector representation. With the following code, we can generate vector embeddings with SageMaker JumpStart and update the collection with the created vector for every document:
payload = {"text_inputs": [document[field_name_to_be_vectorized]]}
query_response = query_endpoint_with_json_payload(json.dumps(payload).encode('utf-8'))
embeddings = parse_response_multiple_texts(query_response)
# update the document
update = {'$set': {vector_field_name : embeddings[0]}}
collection.update_one(query, update)The code above shows how to update a single object in a collection. To update all objects follow the instructions.
MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB. Vector data is a type of data that represents a point in a high-dimensional space. This type of data is often used in ML and artificial intelligence applications. MongoDB Atlas Vector Search uses a technique called k-nearest neighbors (k-NN) to search for similar vectors. k-NN works by finding the k most similar vectors to a given vector. The most similar vectors are the ones that are closest to the given vector in terms of the Euclidean distance.
Storing vector data next to operational data can improve performance by reducing the need to move data between different storage systems. This is especially beneficial for applications that require real-time access to vector data.
The next step is to create a MongoDB Vector Search index on the vector field you created in the previous step. MongoDB uses the knnVector type to index vector embeddings. The vector field should be represented as an array of numbers (BSON int32, int64, or double data types only).
Refer to Review knnVector Type Limitations for more information about the limitations of the knnVector type.
The following code is a sample index definition:
{
"mappings": {
"dynamic": true,
"fields": {
"egVector": {
"dimensions": 384,
"similarity": "euclidean",
"type": "knnVector"
}
}
}
}
Note that the dimension must match you embeddings model dimension.
You can query the vector data store using the Vector Search aggregation pipeline. It uses the Vector Search index and performs a semantic search on the vector data store.
The following code is a sample search definition:
{
$search: {
"index": "<index name>", // optional, defaults to "default"
"knnBeta": {
"vector": [<array-of-numbers>],
"path": "<field-to-search>",
"filter": {<filter-specification>},
"k": <number>,
"score": {<options>}
}
}
}
SageMaker JumpStart foundation models are pre-trained large language models (LLMs) that are used to solve a variety of natural language processing (NLP) tasks, such as text summarization, question answering, and natural language inference. They are available in a variety of sizes and configurations. In this solution, we use the Hugging Face FLAN-T5-XL model.
Search for the FLAN-T5-XL model in SageMaker JumpStart.

Choose Deploy to set up the FLAN-T5-XL model.

Verify the model is deployed successfully and the endpoint is active.

To create an Amazon Lex bot, complete the following steps:



NewIntent UI and choose Save intent.
FallbackIntent that was created for you by default and toggle Active in the Fulfillment section.



To clean up your resources, complete the following steps:
In the post, we showed how to create a simple bot that uses MongoDB Atlas semantic search and integrates with a model from SageMaker JumpStart. This bot allows you to quickly prototype user interaction with different LLMs in SageMaker Jumpstart while pairing them with the context originating in MongoDB Atlas.
As always, AWS welcomes feedback. Please leave your feedback and questions in the comments section.

Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
 Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
From enhancing the conversational experience to agent assistance, there are plenty of ways that generative artificial intelligence (AI) and foundation models (FMs) can help deliver faster, better support. With the increasing availability and diversity of FMs, it’s difficult to experiment and keep up-to-date with the latest model versions. Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon. With Amazon Bedrock’s comprehensive capabilities, you can easily experiment with a variety of top FMs, customize them privately with your data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG).
In July, AWS announced the preview of agents for Amazon Bedrock, a new capability for developers to create fully managed agents in a few clicks. Agents extend FMs to run complex business tasks—from booking travel and processing insurance claims to creating ad campaigns and managing inventory—all without writing any code. With fully managed agents, you don’t have to worry about provisioning or managing infrastructure.
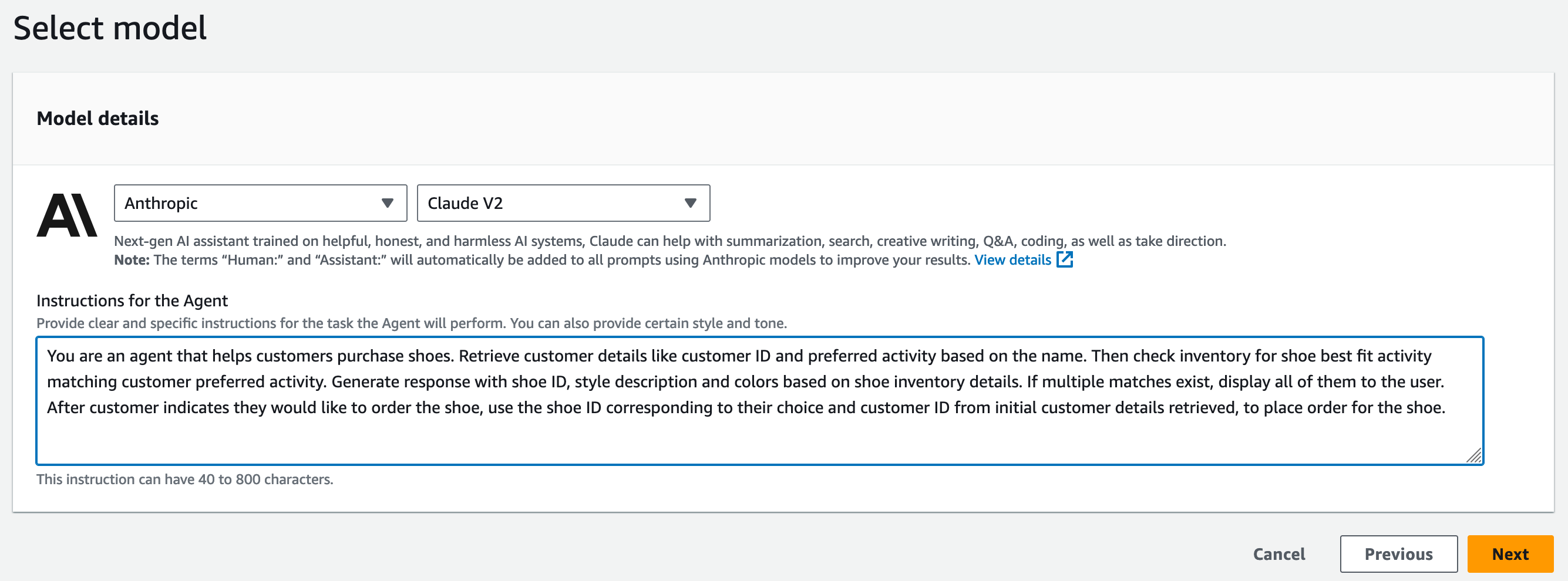
In this post, we provide a step-by-step guide with building blocks to create a customer service bot. We use a text generation model (Anthropic Claude V2) and agents for Amazon Bedrock for this solution. We provide an AWS CloudFormation template to provision the resources needed for building this solution. Then we walk you through steps to create an agent for Amazon Bedrock.
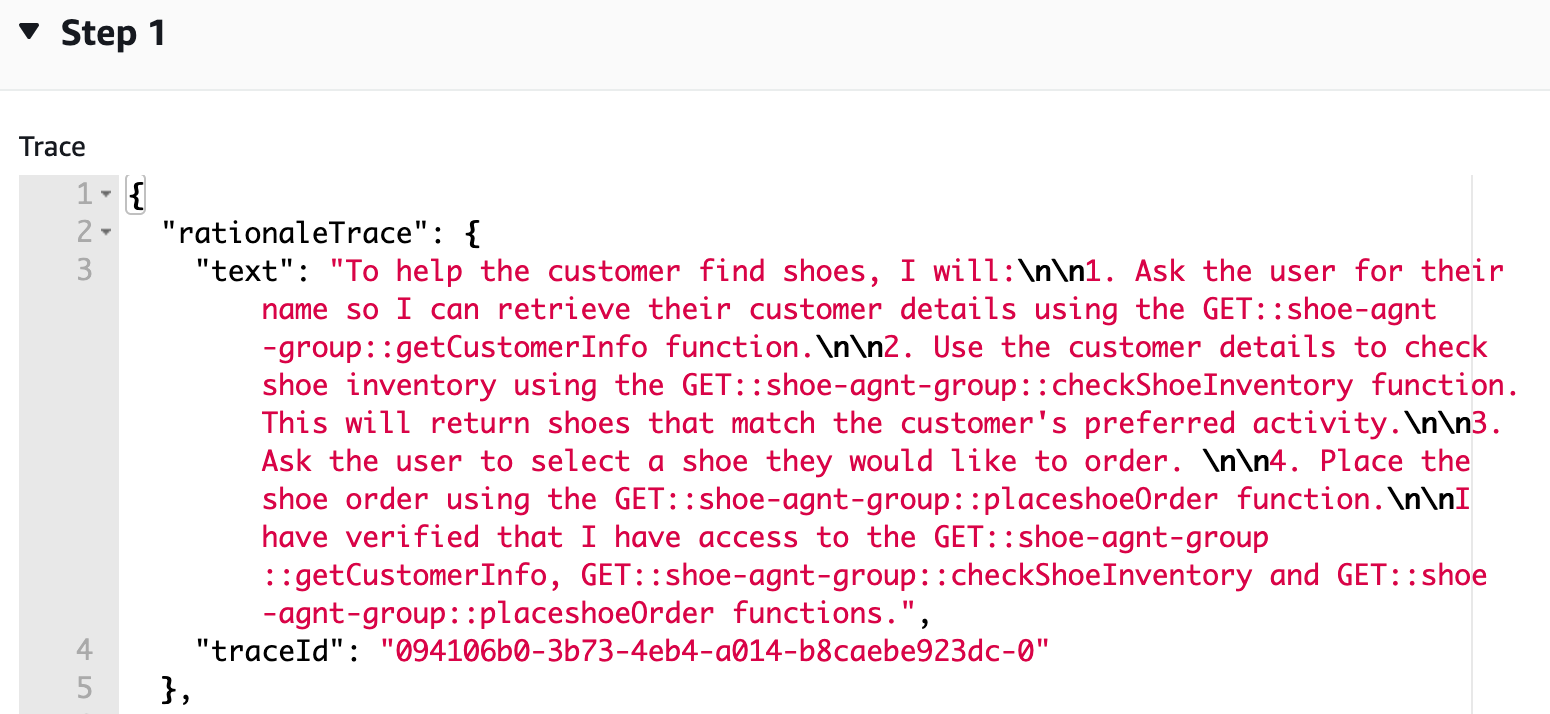
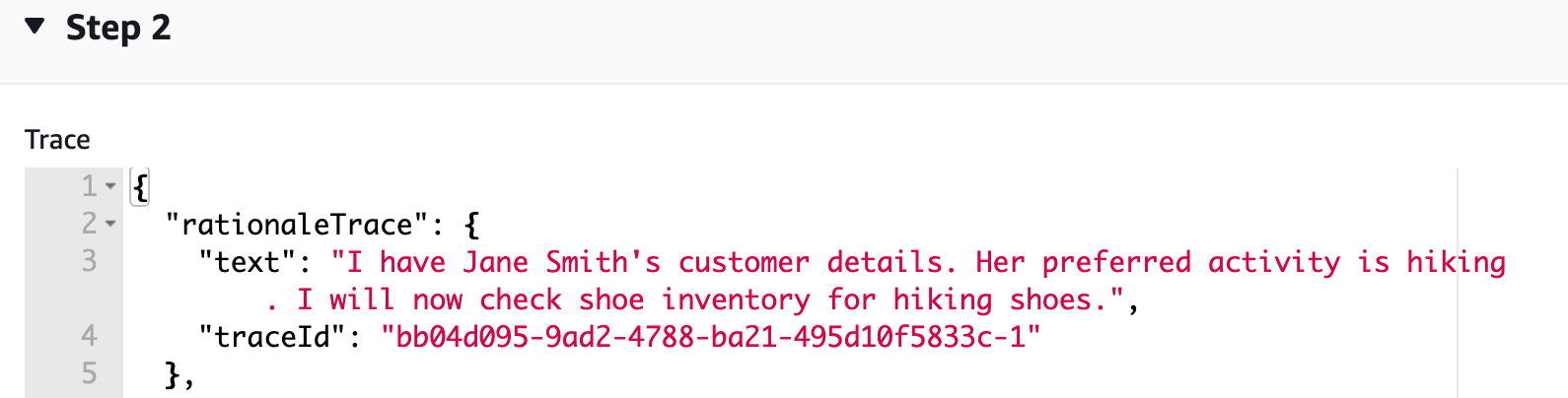
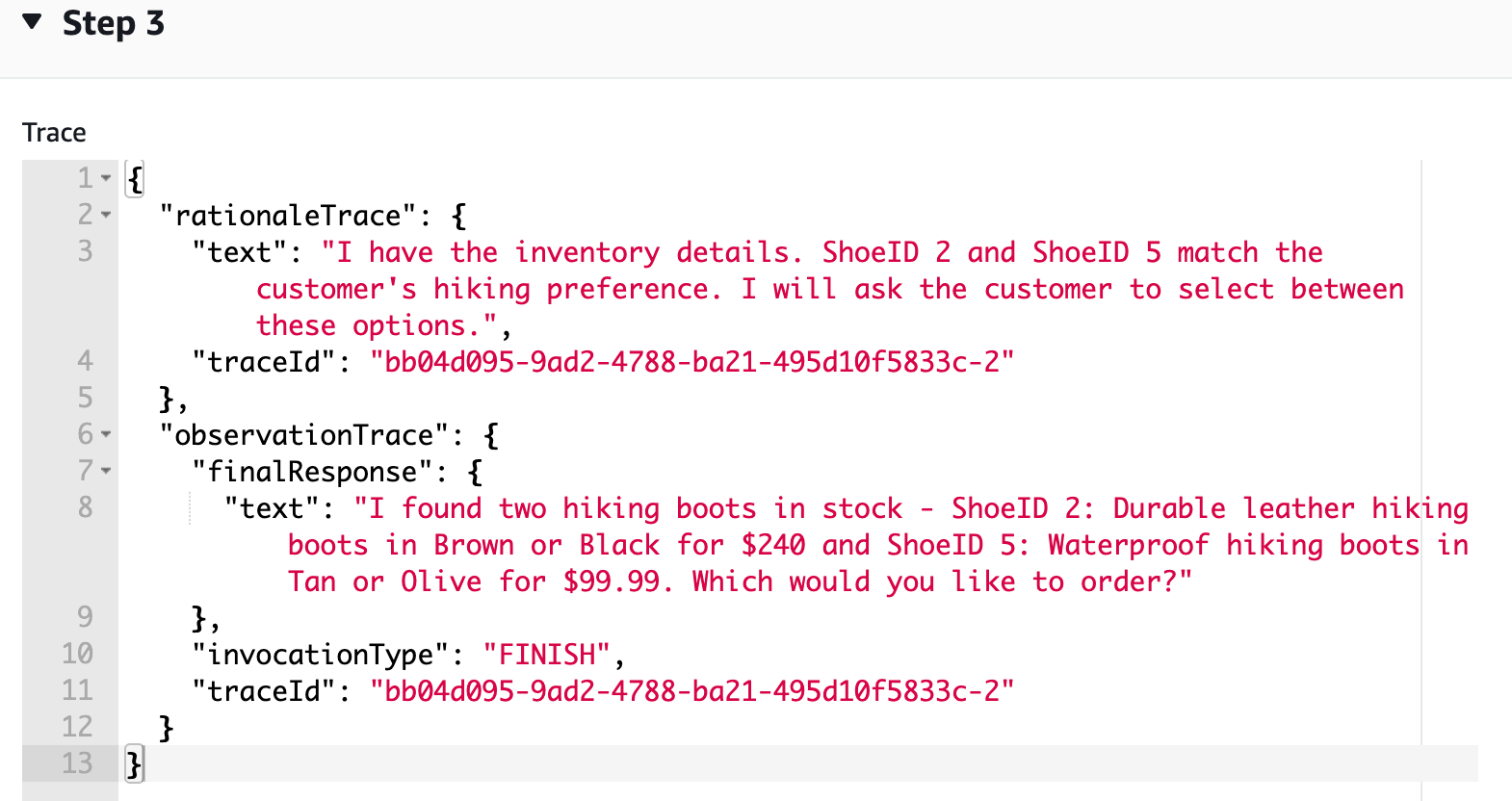
FMs determine how to solve user-requested tasks with a technique called ReAct. It’s a general paradigm that combines reasoning and acting with FMs. ReAct prompts FMs to generate verbal reasoning traces and actions for a task. This allows the system to perform dynamic reasoning to create, maintain, and adjust plans for acting while incorporating additional information into the reasoning. The structured prompts include a sequence of question-thought-action-observation examples.
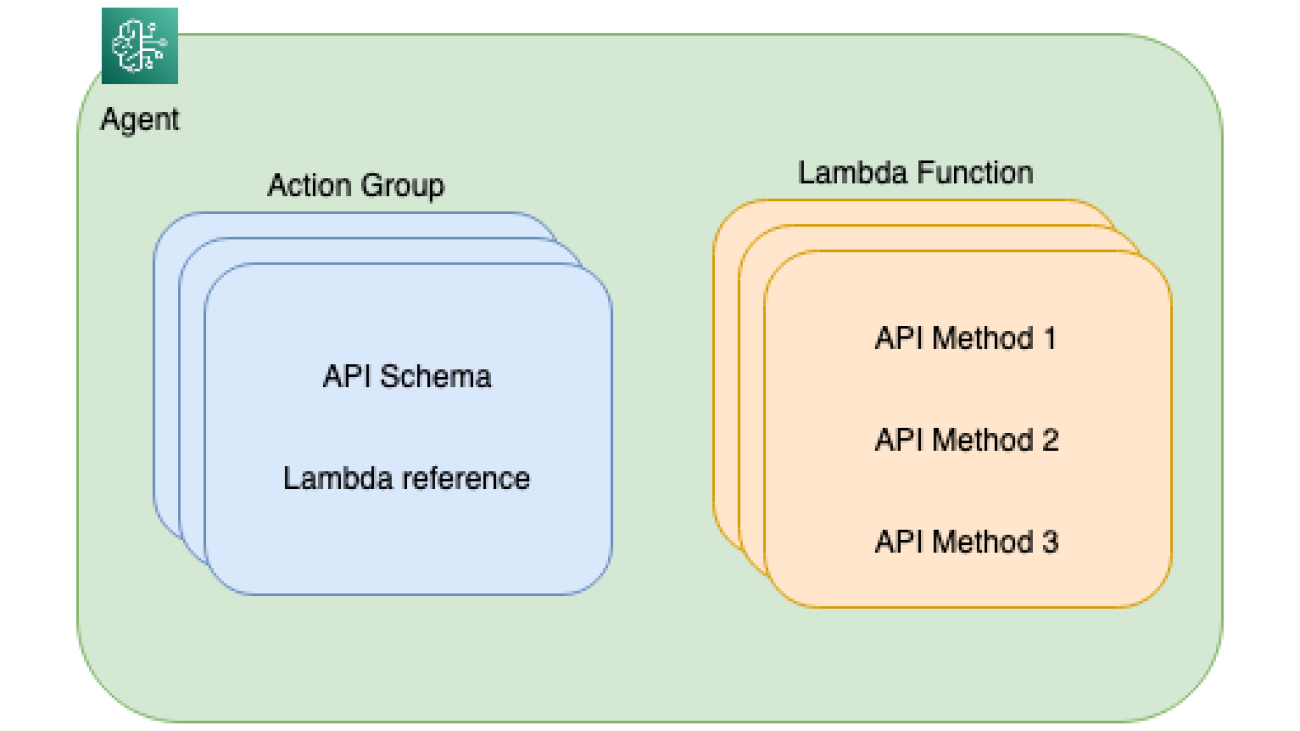
Behind the scenes, agents for Amazon Bedrock automate the prompt engineering and orchestration of user-requested tasks. They can securely augment the prompts with company-specific information to provide responses back to the user in natural language. The agent breaks the user-requested task into multiple steps and orchestrates subtasks with the help of FMs. Action groups are tasks that the agent can perform autonomously. Action groups are mapped to an AWS Lambda function and related API schema to perform API calls. The following diagram depicts the agent structure.
We use a shoe retailer use case to build the customer service bot. The bot helps customers purchase shoes by providing options in a humanlike conversation. Customers converse with the bot in natural language with multiple steps invoking external APIs to accomplish subtasks. The following diagram illustrates the sample process flow.
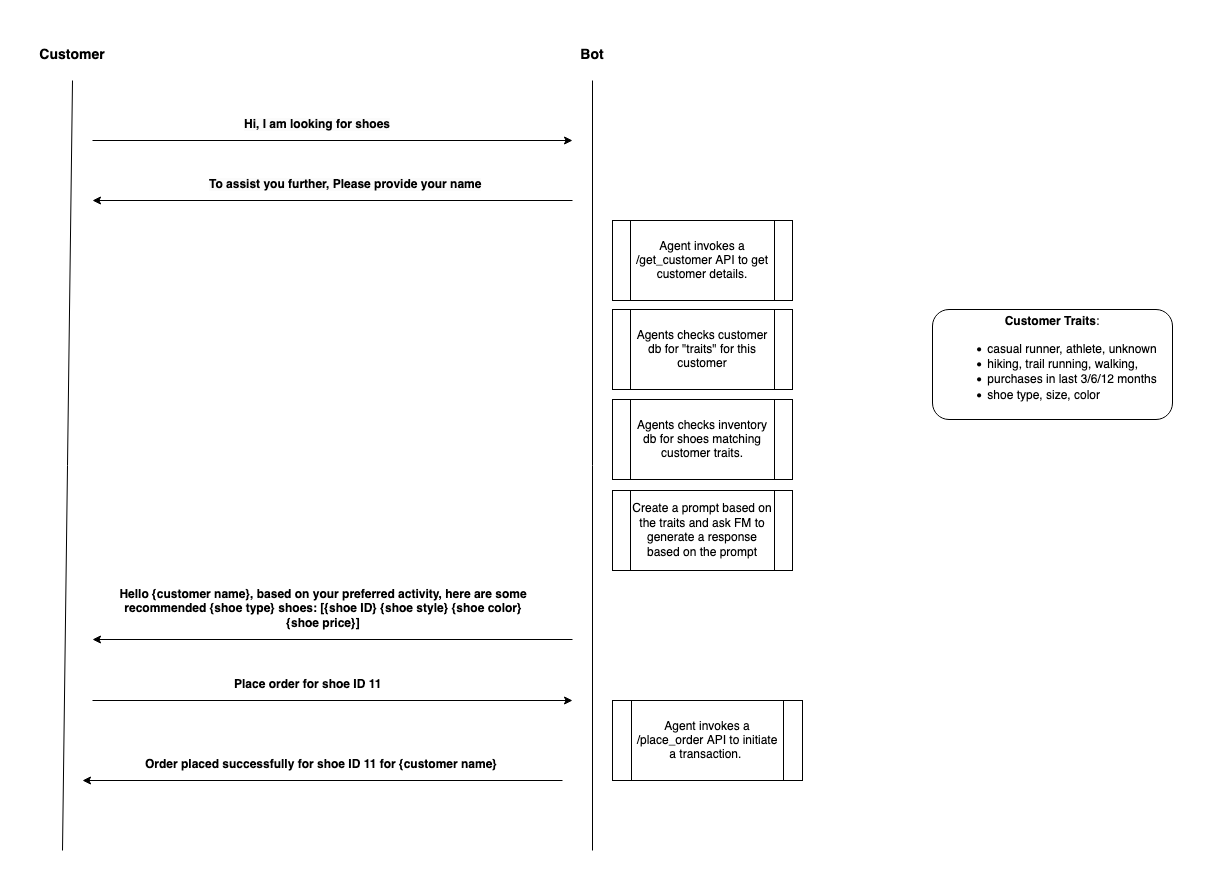
The following diagram depicts a high-level architecture of this solution.
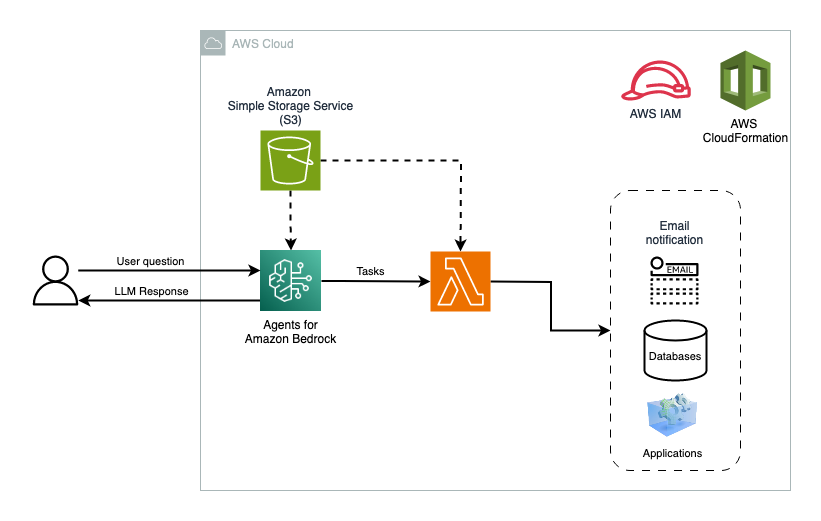
In this post, we use the Lambda function to retrieve customer details, list shoes matching customer-preferred activity, and finally, place orders. Our code is backed by an in-memory SQLite database. You can use similar constructs to write to a persistent data store.
To implement the solution provided in this post, you should have an AWS account and access to Amazon Bedrock with agents enabled (currently in preview). Use AWS CloudFormation template to create the resource stack needed for the solution.
us-east-1 |
The CloudFormation template creates two IAM roles. Update these roles to apply least-privilege permissions as discussed in Security best practices. Click here to learn what IAM features are available to use with agents for Amazon Bedrock.
LambdaBasicExecutionRole with Amazon S3 full access and CloudWatch access for logging.AmazonBedrockExecutionRoleForAgents with Amazon S3 full access and Lambda full access.Important: Agents for Amazon Bedrock must have the role name prefixed by AmazonBedrockExecutionRoleForAgents_*
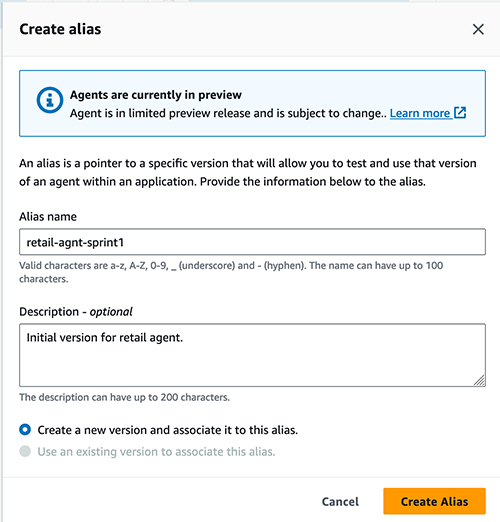
In the next two sections, we will walk you through creating and testing an agent.
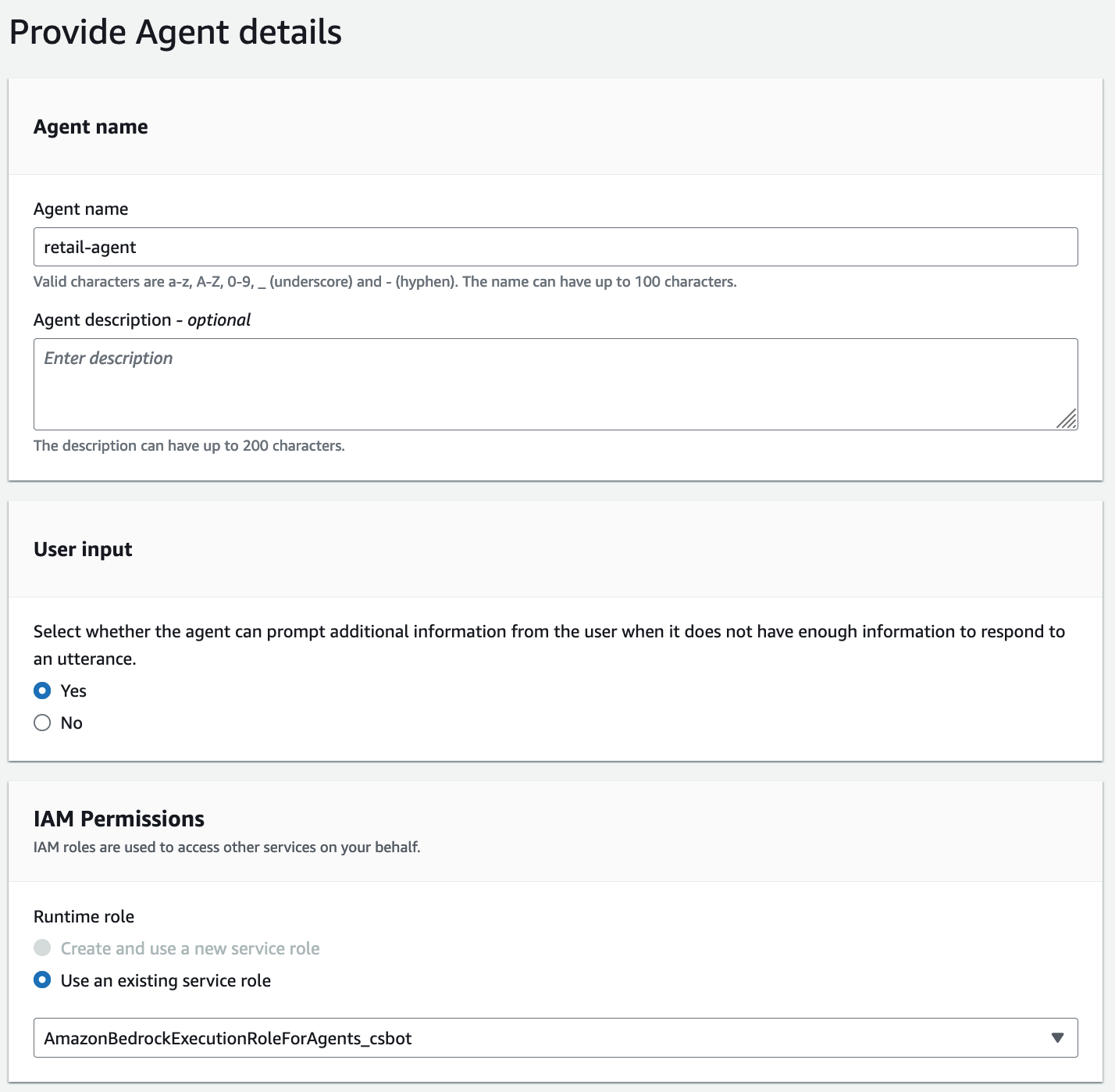
To create an agent, open the Amazon Bedrock console and choose Agents in the left navigation pane. Then select Create Agent.

This starts the agent creation workflow.
Give the action group a name and a description for the action. Select the Lambda function, provide an API schema file and select Next.
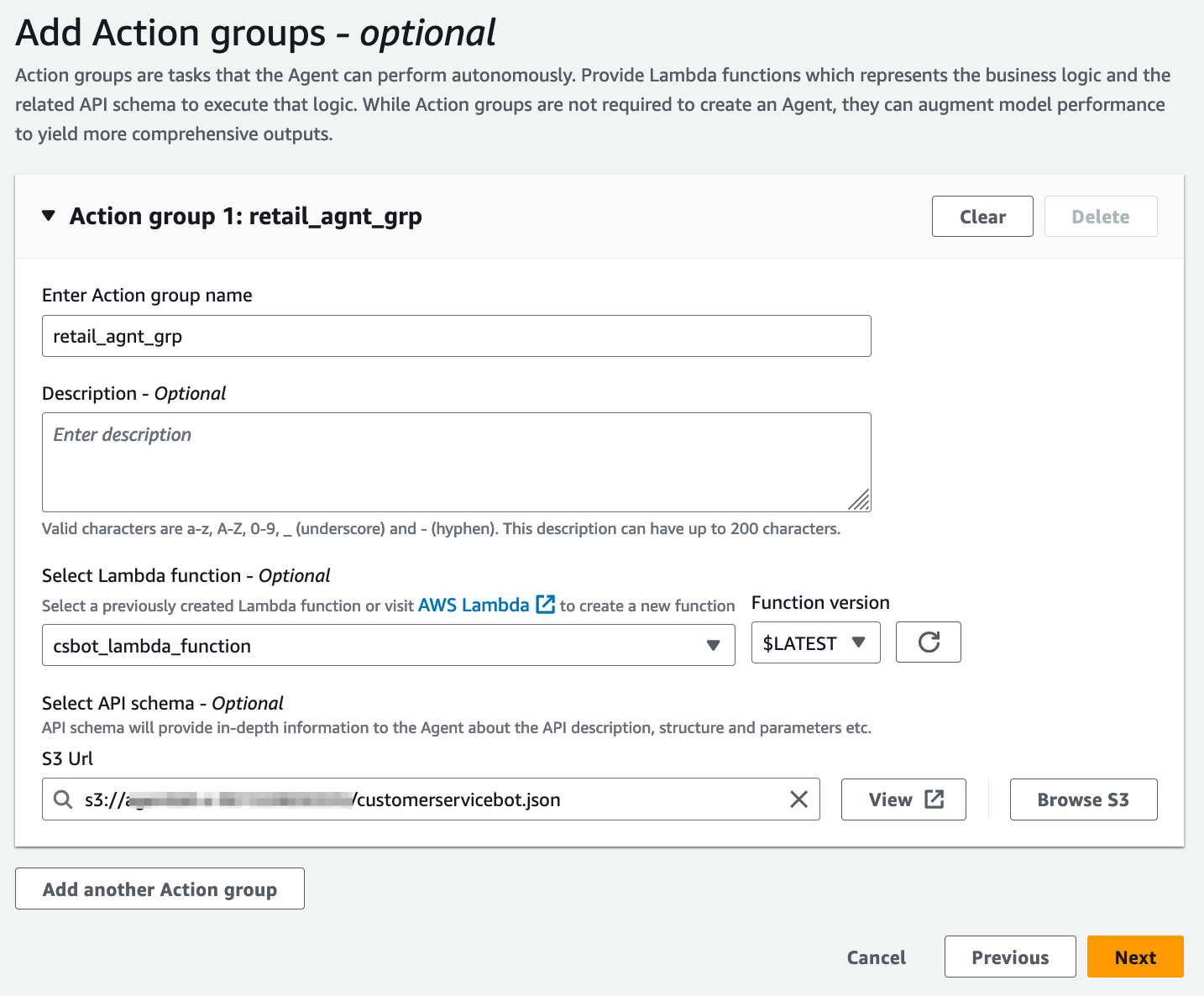
The following actions occur with the preceding agent setup and the Lambda code provided with this post:
The following screenshot displays some example responses from the agent.
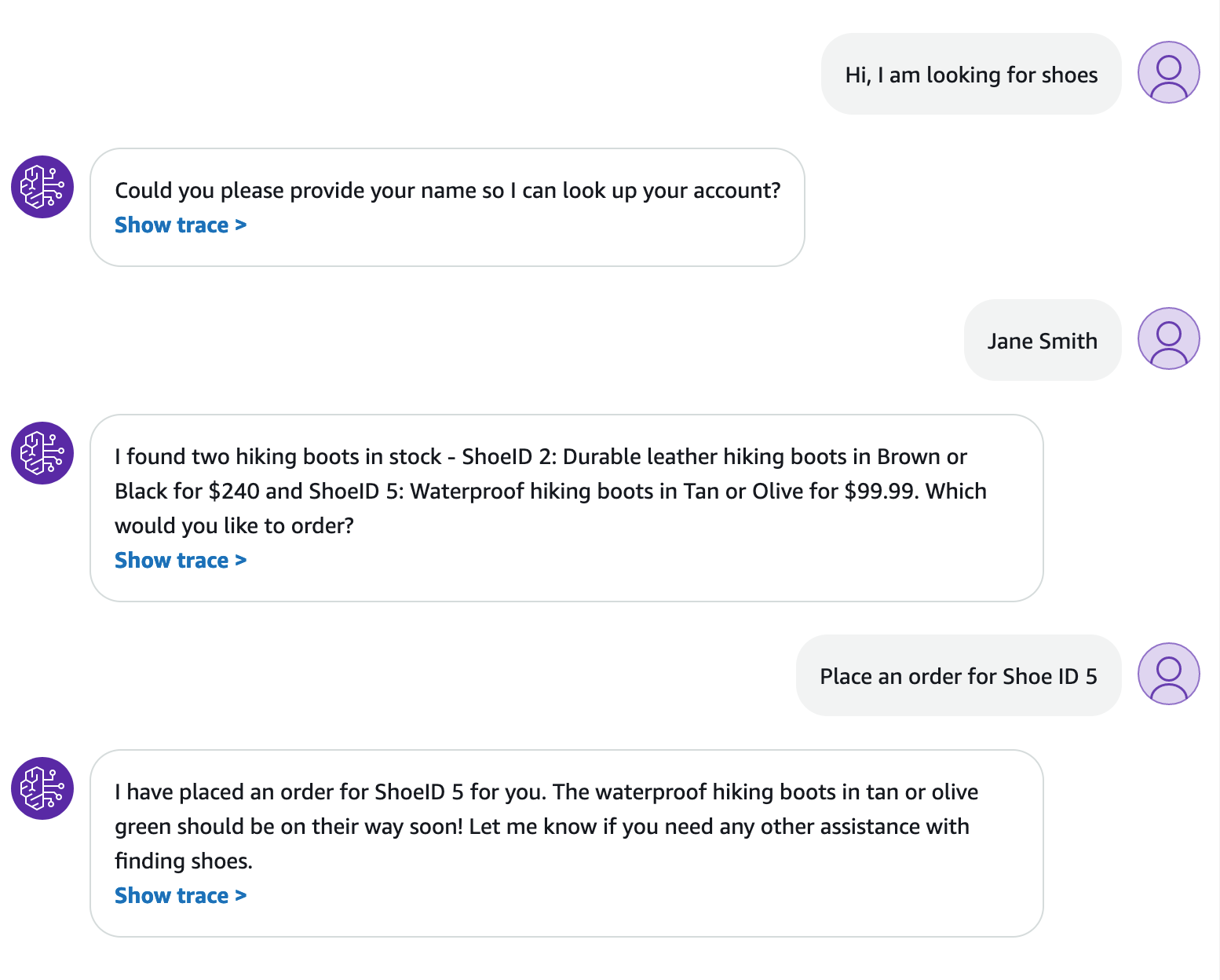
By selecting Show trace for each response, a dialog box shows the reasoning technique used by the agent and the final response generated by the FM.
To avoid incurring future charges, delete the resources. You can do this by deleting the stack from the CloudFormation console.
Feel free to download and test the code used in this post from the GitHub agents for Amazon Bedrock repository. You can also invoke the agents for Amazon Bedrock programmatically; an example Jupyter Notebook is provided in the repository.
Agents for Amazon Bedrock can help you increase productivity, improve your customer service experience, or automate DevOps tasks. In this post, we showed you how to set up agents for Amazon Bedrock to create a customer service bot.
We encourage you to learn more by reviewing additional features of Amazon Bedrock. You can use the example code provided in this post to create your implementation. Try our workshop to gain hands-on experience with Amazon Bedrock.
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Manju Prasad is a Senior Solutions Architect within Strategic Accounts at Amazon Web Services. She focuses on providing technical guidance in a variety of domains, including AI/ML to a marquee M&E customer. Prior to joining AWS, she has worked for companies in the Financial Services sector and also a startup.
Manju Prasad is a Senior Solutions Architect within Strategic Accounts at Amazon Web Services. She focuses on providing technical guidance in a variety of domains, including AI/ML to a marquee M&E customer. Prior to joining AWS, she has worked for companies in the Financial Services sector and also a startup.
 Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.
Archana Inapudi is a Senior Solutions Architect at AWS supporting Strategic Customers. She has over a decade of experience helping customers design and build data analytics, and database solutions. She is passionate about using technology to provide value to customers and achieve business outcomes.

Europe’s startup ecosystem is getting a boost of accelerated computing for generative AI.
NVIDIA and cloud service provider (CSP) Scaleway are working together to deliver access to GPUs, NVIDIA AI Enterprise software, and services for turbocharging large language models (LLMs) and generative AI development for European startups.
Scaleway, a subsidiary of French telecommunications provider iliad Group, is offering cloud credits for access to its AI supercomputer cluster, which packs 1,016 NVIDIA H100 Tensor Core GPUs. As a regional CSP, Scaleway also provides sovereign infrastructure that ensures access and compliance with EU data protection laws — critical to businesses with a European footprint.
Complying with regulations governing how data and metadata can be stored in cloud computing is critical. When doing business in Europe, U.S. companies, for example, need to comply with EU regulations on sovereignty to secure data against access from foreign adversaries or entities. Noncompliance risks data vulnerabilities, financial penalties and legal consequences.
Regional CSPs like Scaleway provide a strategic path forward for companies to do business in Europe with a sovereign infrastructure. iliad Group’s data centers, where Scaleway operates, are fortified by compliance certifications that ensure data security, covering key aspects like healthcare, public safety, governance and public service activities.
NVIDIA is working with Scaleway to expand access to sovereign accelerated computing in the EU, enabling companies to deploy AI applications and scale up faster.
Through the NVIDIA Inception program, startups already relying on the sovereign cloud computing capabilities of Scaleway’s NVIDIA-accelerated infrastructure include Hugging Face, with more to come. Inception is a free global program that provides technical guidance, training, discounts and networking opportunities.
Inception member Hugging Face, based in New York and with operations in France, creates tools and resources to help developers build, deploy and train AI models.
“AI is the new way of building technology, and making the fastest AI accelerators accessible within regional clouds is key to democratizing AI across the world, enabling enterprises and startups to build the experiences of tomorrow,” said Jeff Boudier, head of product at Hugging Face. “I’m really excited that selected French startups will be able to access NVIDIA H100 GPUs in Scaleway’s cluster through the new startup program Scaleway and Hugging Face just announced with Meta and Station F.”
Scaleway’s newly available Nabuchodonosor supercomputer, an NVIDIA DGX SuperPOD with 127 NVIDIA DGX H100 systems, will help startups in France and across Europe scale up AI workloads.
Regional Inception members will also be able to access NVIDIA AI Enterprise software on Scaleway Marketplace, including the NVIDIA NeMo framework and pretrained models for building LLMs, NVIDIA RAPIDS for accelerated data science, and NVIDIA Triton Inference Server and NVIDIA TensorRT-LLM for boosting inference.
NVIDIA Inception has more than 4,000 members across Europe. Member companies of Scaleway’s own startup program are eligible to join Inception for benefits and resources. Scaleway is earmarking companies to fast-track for Inception membership.
Inception members gain access to cloud computing credits, NVIDIA Deep Learning Institute courses, technology experts, preferred pricing on hardware and software, guidance on the latest software development kits and AI frameworks, as well as opportunities for matchmaking with investors.