In this new Microsoft Research Podcast series What’s Your Story, Johannes Gehrke explores the who behind the technical and scientific advancements helping to reshape the world. A systems expert whose 10 years with Microsoft spans research and product, Gehrke talks to members of the company’s research community about what motivates their work and how they got where they are today.
Across his time at Microsoft, Desney Tan, Managing Director of Microsoft Research Redmond, has had the experience of shepherding research ideas into products multiple times, and much like the trajectory of research, his life journey has been far from linear. In this episode, Tan shares how he moved to the United States from Singapore as a teenager, how his self-described “brashness” as a Microsoft intern helped shift the course of his career, and how human impact has been a guiding force in his work.

Subscribe to the Microsoft Research Podcast:
Transcript
[TEASER] [MUSIC PLAYS UNDER DIALOGUE]DESNEY TAN: Early in the career, I always looked at successful people and it always felt like they had a goal, and it was a very nice straight line to get there, and they did all the right things, and I don’t know anyone today that I deem to be successful that had a straight-line path and did all the right things.
[TEASER ENDS]JOHANNES GEHRKE: Microsoft Research works at the cutting edge. But how much do we know about the people behind the science and technology that we create? This is What’s Your Story, and I’m Johannes Gehrke. In my 10 years with Microsoft, across product and research, I’ve been continuously excited and inspired by the people I work with, and I’m curious about how they became the talented and passionate people they are today. So I sat down with some of them. Now, I’m sharing their stories with you. In this podcast series, you’ll hear from them about how they grew up, the critical choices that shaped their lives, and their advice to others looking to carve a similar path.
[MUSIC ENDS]In this episode, I’m talking with Desney Tan, a longtime Microsoft executive whose experience with the company spans computational neuroscience, human-computer interaction, and health and the life sciences. His research contributions have impacted a wide range of Microsoft products. Desney was previously Vice President and Managing Director of Microsoft Health Futures and is now Managing Director of Microsoft Research Redmond.
Much like the trajectory of research, Desney’s life journey has been far from linear. He left Singapore to attend school in the Unites States as a teenager, then worked in autonomous navigation for NASA and in VR for Disney before landing here at Microsoft. Here’s my conversation with Desney, beginning with his childhood.
DESNEY TAN: Born and raised in Singapore. Dad was an architect. Mom did everything, um, to run the family. When I turned 13, Mom and Dad came to me and they said, “Hey, would you like to try something new?” I said sure. You know, I had no idea what they, they were thinking. Two weeks later, they sent me to the US to study. Um, looking back, sometimes I flippantly claim I was just eating too much at home and so they had to send me away. [LAUGHTER] But actually, it was, you know, I think it was prescient on their part. They sort of looked at my path. They looked at the education system. They looked at the way I learned and the way I created and the way I, I acted, and they somewhat realized, I think, very early on that the US was a great … would, would be a great place for me to sort of flourish and, and sort of experiment and explore and, and grow.
GEHRKE: And so how did it work? You just went by yourself?
TAN: So I had an aunt and an uncle in Louisiana. Spent a couple of years in high school there. Um, sort of … fun, fun side story. They looked at … the high school looked at my math curriculum in Singapore, and they said, “Oh, he’s at least a year ahead.” So they skipped me a year ahead. And then through some weird miscalculations on their part, they actually ended up skipping me nearly two years ahead.
GEHRKE: Oh, wow.
TAN: And by the time we realized, I had already integrated into school, the courses were just fine, and so I ended up skipping a lot of years.
GEHRKE: So you ended up graduating then high school what …
TAN: Pretty early. I was 15.
GEHRKE: 15 …
TAN: Graduated from high school. Got to college. Had no idea what I wanted to do. What 15-year-old does? Um, ended up in liberal arts college, so University of Notre Dame. So, so I don’t know how Mom let me do this, but, you know, I got all my acceptance letters together. I said I don’t know anything about college. I don’t know where I want to go. I don’t know what I want to do. I’m going to toss all the letters up in the air, and the one that lands on top is the school I’m going to.
GEHRKE: And that’s what you did?
TAN: Yeah, that’s exactly what I did. Um, divine intervention, let’s call it. Notre Dame landed on top. You know, switched majors a bunch of times. I started off in aerospace, did chemical engineering, civil engineering. I was on the steps of becoming a priest until they sent me away. They said, “Hey, if it’s not a mission and a calling, go away and come back later.” And ended up with a computer engineering degree. You know, I had great mentors, you know, who looked out for me. I had a couple of guardian angels out there, you know, guided me along, and that, you know, that was just a wonderful breadth of education. Went back to the military for a couple of years. Uh, served there for a couple of years. Did a bunch of growing up.
GEHRKE: That, that’s quite a change, right, from being like in college and then going back to the military.
TAN: Yeah, yeah, it was a mandatory service in Singapore, and so I went back. Had a ton of fun. Learned a bunch of stuff about the world, about myself. I claim the military is one of the few organizations in the world that takes an 18-year-old and teaches them leadership, um, and teaches them about themselves and teaches them about how to push themselves and where the boundaries are. And so fairly accidentally, I, I got to benefit from all of that. At the end of that, I realized my computer engineering degree was, you know … I realized two things. One, my computer engineering degree was a little outdated by the time I got out of the military, and two, that I didn’t love being told what to do. [LAUGHS]
GEHRKE: [LAUGHS] OK.
TAN: So I came back. Uh, did grad school. I was at Carnegie Mellon. Ended up getting hooked up with a wonderful professor, Randy Pausch.
GEHRKE: “The Last Lecture,” right?
TAN: Who gave “The Last Lecture” in his last days. You know, learned a ton from him not only about academics and scholarship, but also about life and, um, and leadership.
GEHRKE: And so he was at the intersection of graphics and HCI, right, if I remember correctly?
TAN: That’s correct, yeah.
GEHRKE: So what is your PhD in?
TAN: My PhD was actually looking at, um, distributed displays in virtual reality. So how, how the human brain absorbs information and uses the world around us to be able to, um, interact with digital data and analog data.
GEHRKE: Early on in a really important field already.
TAN: Yeah, no, it was great. Spent a couple of years with NASA in the Jet Propulsion Lab doing autonomous navigation. This was the early days of, um, you know, AI and, and planning.
GEHRKE: So those aerospace engineering classes, were they actually useful?
TAN: They, you know, all the classes I took ended up coming back to be useful in a number of ways. And actually, um, you know, the diversity of viewpoints and the diversity of perspectives is something that sat very deeply in me. So anyways, you know, spent some time at NASA. Um, spent some time at Disney with the Imagineers building virtual reality theme parks. This was the late ’90s, early 2000s. So Disney at the time had all the destination theme parks: Disneyland, Disney World, places you would fly for a week and, and spend a week at. Their goal was really to build a theme park in a box that they could drop down into the urban centers, and the only way to get a theme park into a building was digital experiences. And so this was the very early days of VR. We were using, you know, million-dollar military-grade headsets. They were, you know, 18, 19 pounds.
GEHRKE: Wow.
TAN: Disney was one of the companies—and, you know, it’s sat with me for a very long time—that designs experiences for every single person on earth, right. So these headsets had to work on your 2-year-old. They had to work on your 102-year-old. They had to work on, you know, a person who spoke English, who read, who didn’t read, who didn’t speak English. You know, tall, short, large, small, all of it. And they did a wonderful job finding the core of what it means to be human and designing compelling experiences for all of us, um, and that was a ton of fun. We ended up deploying these facilities called DisneyQuest. There was one in Chicago; one in Orlando. They just closed them down a couple of years ago because actually all the VR rights have now migrated into the theme parks themselves.
GEHRKE: And it was actually a VR experience? You would go and sit …
TAN: It was a VR experience. They dropped them down. They had basically buildings. There were, you know, floors full of classic and new-age arcade games. And then there were VR experiences that you could run around in and, um, interact with.
GEHRKE: Interesting. I’ve never, I mean, I lived in Madison for four years, but I’ve never heard of that Quest experience. It seems to be a fun way to experience Disney … by not going to any of the, the theme parks.
TAN: It was super fun. Um, yeah, we, I personally got to work on a couple of rides. There was Pirates of the Caribbean.
GEHRKE: Oh, wow.
TAN: So you put on … a family would put on headsets and kind of run around, shooting pirates and what have you. And then the Aladdin ride was I thought one of the better rides.
GEHRKE: Oh, wow, yeah …
TAN: Where you sit on a magic carpet as you can imagine.
GEHRKE: Oh yeah. That sounds fun.
TAN: It was perfectly scripted for it. Um, anyways, ended up at Microsoft largely because entertainment technology while a lot of fun and while I learned a ton was, uh, strangely unsatisfying, and there was something in me and, you know, that was seeking human impact at scale in a much deeper and much more direct way. And so I thought I’d be here for three or four years largely to learn about the tech industry and how, you know, large pieces of software were deployed before going off and doing the impact work. And I’ve now been here for nearly 20 years.
GEHRKE: And where do you start? Did you start out right away at Microsoft Research, or were you first in a product group?
TAN: My career here has been a cycle of starting in Microsoft Research, incubating, failing, trying again. Failing again. You know, at some point, screaming “Eureka!” [LAUGHTER] and then doing my tours of duty through the product groups, commercializing … productizing, commercializing, you know, seeing it to at least robustness and sustainability if not impact and then coming back and doing it again. Um, and the thing that’s kept me here for so long is every time I’ve completed one of those cycles and thought I was done here, um, the company or the world in some cases would throw, you know, a bigger, thornier, juicier thing in front of me, and Microsoft has always been extremely encouraging, um, and supportive of, you know, taking on those challenges and really innovating and opening up all new, whole new opportunities.
GEHRKE: I mean this whole cycle that you’re talking about, right, of sort of starting out small at MSR (Microsoft Research), you know, having sort of the seed of an, of an idea and then growing it to a bigger project and at some point in time transitioning, transitioning it into, into the product group and actually really making it a business. So tell me about … you said you have done this, you know, a few times and, you know, once you were even highly successful. I’d love to learn more about this because I think it’s so inspiring for everybody to learn more about this.
TAN: Yeah. No, it’s been magical. I have to say before going into any of these stories that none of these paths were architected. As, as you well know, they never are. So actually my, my first experience was as an intern here, and, you know, I was a sort of brash, perhaps rash, intern. I was working on virtual reality, and in the evenings, I would meet with folks around the company to learn more, and I met with a team that was building out multi-monitor functionality in Windows NT. Prior to Windows NT, Windows computers had one and only one monitor, and they started to build the functionality to build multiple. As the brash grad student, you know, I, I had different thoughts about how this should be implemented and, you know, couldn’t convince anyone of it. And so in the evenings, I ended up starting just to build it. At the end of the internship, in addition to all the stuff I was doing, I said, “Hey, by the way, I’ve built this thing. You know, take it or leave it. Here you go.” And it ended up being the thing that was implemented in NT for a variety of reasons. That really got me hooked. Prior to that, I had imagined myself an academic, going back and, you know, being a professor somewhere in academia. And as soon as I saw, you know, the thing I did and that, you know, Microsoft actually polished up and made good in the real world…
GEHRKE: And shipping in millions and millions of desktops, right?
TAN: That’s right. There was no getting away from that.
GEHRKE: OK, right.
TAN: When I first got here, MSR had actually hired me thinking I’d work on virtual reality. And I got here and I said, hey, VR … I’ve just done a ton of VR. VR is probably 15 or 20 years out from being democratized and consumerized. I’m going to do something for a couple of years, and then I’ll come back to this. Um, so I got into computational neuroscience, looking at, um, sensors that scanned or sensed the brain and trying to figure out mental state of people. I had the imagination that this would be useful both for direct interaction but also for understanding human behavior and human actions a little bit better. We won’t go into that work, but, um, what happened with the productization of that was I went … this was at the time when Bill Gates was actually pushing very hard on tablet PCs and the stylus and the pen as an interesting input modality. The realization we had was, hey, we’ve got spatial temporal signal coming off the brain we’re trying to make sense of; the tablet guys had spatial temporal signal coming off a pen they were trying to make sense of in handwriting recognition. And so we went over and we said, hey, what interesting technological assets do you have that we can steal and use on the brain. Turns out they were more convincing than us. And, and so they said, hey, actually you’re right. The problems do look similar. What do you have that you could bring over? And so if you look at the handwriting recognition system even that stands today, it’s a big mess of a neural network, um, largely because that came out of interpreting neural signal that got transferred into the handwriting recognizer.
GEHRKE: I see.
TAN: And so I ended up spending two, maybe 2 1/2 years, working not only on the core recognition engine itself but also the entire interface that ran around the tablet PC and, you know, the tablet input panel.
GEHRKE: But that’s sort of an interesting realization, right. You came because you thought you would land Technology X for Application Y, but actually you land it for a very different application.
TAN: That’s right. And, and each cycle has had a little bit of that surprise and that serendipity, which we’ve now built into the way we do research. And, um, you sort of head down a path because it moves you forward as quickly as possible. But you keep your eyes peeled for the serendipitous detours and the, the discovery that comes out of that. Um, and I think that’s what makes Microsoft Research as an organization, um, so compelling and, and so productive, right, as … we, we do run very fast, but we have the freedoms and, you know, the flexibility really to take these windy paths and to take these detours and, and to go flip over, you know, rocks, some of which end up being, you know, dead ends.
GEHRKE: Right.
TAN: Others of which end up being extremely productive.
GEHRKE: Right. And so if you think about, let’s say, a junior person in the lab, right. They’re sort of looking at you and your career and saying, “Wow, what steps should I take to, you know, become as successful as Desney?” What, what advice would you give them, right? Because it seems like you have always had sort of MSR as sort of your rock, right. But then you jumped over the river a few times, but then came back and jumped over again. Came back.
TAN: First off, I, I don’t know that Desney has been so successful so much as, you know, the people around Desney have been extremely successful and Desney’s gotten to ride the wave. But, yeah, no, I mean every, everyone’s … you know, as I look around the table and the board, you know, everyone has a slightly different journey, and everyone has slightly different work styles and mindsets and personalities and risk tolerance and what have you. Um, so the first thing really is, is not to try to fully emulate anyone else. I always claim we’re, we’re kind of like machine learning models, right. We, we should be taking input data, positive and negative, and building our models of ourselves and our models of the world and really operating within that context. I think having a North Star, whether it’s implicit or explicit, has been extremely useful for myself and the people around me.
GEHRKE: By North Star, you mean like a philosophical North Star or technical North Star or North Star in what you want to be? What, what do you mean?
TAN: Yes, yes, yes. All of it.
GEHRKE: So tell me more about your personal North Star.
TAN: For, for, for us … for myself, it’s really been about human impact, right. Everything we do is centered on human impact. We do research because it’s part … it’s, it’s one of the steps towards achieving human impact. We productize because it’s one of the steps towards human impact. Our jobs are not ever done until we hit the point of human impact, and then they’re not quite done because there’s always more to be had. Um, so I think having that, you know, perhaps a value system, um, at least, you know, sort of grounds you really nicely and, and creates, I think, or can create a courage and a bravery to pursue, which I think is important. You know, different people do this differently, but I have been very lucky in my career to be surrounded by people that have been way, way, way better than myself, um, and, and extremely generous of their passions and their skills and their expertise and their time. You know, ask it and just about any successful person by whatever definition and I think they’ll tell you the same thing, that it’s the people around. And then being tolerant, maybe even seeking of, this windy path. You know, when I was early in the career, I always looked at successful people, or people I deemed to be successful, and it always felt like they had a goal, and it was a very nice straight line to get there, and they did all the right things and, and took all the right steps, and, um, and I don’t know anyone today that I deem to be successful that had a straight-line path and did all the right things.
GEHRKE: Yeah, and it’s often these setbacks in, you know, one’s career that actually give you often some of the best learnings because either of some things that you’ve sort of done structurally wrong or some things that, you know, you really need more experience and, and, you know, that setback gave you that experience. So, so one other question around this is also just around change, right. Because especially right now, we’re living in this time where maybe the rate of change especially in AI is kind of unprecedented. I mean, benchmarks are falling in like a quarter of the time than they would have thought to be lasting. You know, we all have played with ChatGPT. Just extrapolate that out a few more months, if not years, right. OpenAI is here talking about AGI. So how do you think about change for yourself and evolution and learning, and do you have any, any routines? How, how do you keep up with everything that’s going on?
TAN: Yeah, it’s, uh … good question. I guess the overarching philosophy, the approach that I’ve taken with my career, is that everything’s constantly in change. You know, the rate of change may vary, and the type of change and the, the mode of change might vary, but everything’s constantly changing, and so our jobs at any given point are to understand the context in the world, in the organization, with the people around you, and really be doing the best that you can at any given moment. And as that context changes, you kind of have to dynamically morph with it. I subscribe pretty fully to the Lean Startup model. So, you know, formulate hypotheses … and this is the research process really, right. Formulate hypotheses, test them as quickly as you can, learn from that, and then do it again, and rinse and repeat. And then … and, you know, you could sort of plot your path and steer your path through based on that. Um, and so we operate very much on that. As, as the world changes, we change. As, you know, the org changes, we change. And there’s a certain robustness that comes along with that. It’s not all roses, and obviously change is and uncertainty is, is a difficult context to operate in.
GEHRKE: And super interesting because it also speaks to some of the things that one should, um, sort of look out for when doing research, right. If you’re saying, well, I have these hypotheses and I want to quickly test them, right, if I’m in a field or if I work with data that I, you know, cannot really use, where the testing of an hypothesis will take months if not years to bring out, this might not be the best research direction. So how should I think about sort of research, the choice of research problems …
TAN: It’s a good question, yeah.
GEHRKE: … sort of with this, with this change in mind, right?
TAN: Yeah, yeah. Um, I don’t know. I, I’m, I guess … again, I’m brash on this. There are, there are very few problems and spaces that can’t be navigated, um, and so things that seem impossible at first glance are often navigable, you know, with a little bit or maybe sometimes a lot of creativity. Um, you know, if our jobs are to take Microsoft and the rest of the world to places that Microsoft and the rest of the world might not get itself to—hopefully positive places—then we’re going to have to do things in a way that is probably unnatural for Microsoft and the rest of the world, um, to get there. And the company and the organization, MSR, has been extremely supportive of that level of creativity.
GEHRKE: Can you give an example of that for …?
TAN: We had Cortana, which is our speech recognition and conversational engine. We didn’t really have a platform to deploy that on. At the same time, we saw a bunch of physicians, clinicians, struggling with burnout because they were seeing patients for less than half the time. They were spending more of their time sitting in front of the computer, documenting stuff, than they were seeing patients and treating patients. We said, hey, what if you put the two together? What if you sat in the room, listened to the doctor and the patient, and started to automatically generate the documentation? And in fact, if you did that, you could structure the data, which leads for better downstream analytics. Um, and if you did that, you could start to put machine learning and AI and smarts into the system, as well. That project, which was called EmpowerMD, led eventually—after a bunch of missteps and a bunch of learnings and a bunch of creativity—to a very deep partnership with Nuance, um, and creation of Dragon Ambient eXperience and the eventual acquisition thereof of that company. And, um, it’s just a wonderful product line. It’s, you know, kind of a neat way to think about data and intelligence and human augmentation and integration into otherwise messy, noisy human processes. Um, but yeah, you know, I think with enough creativity, um, you know, we’ve, we’ve bumped into very, very few brick walls.
GEHRKE: And what I love about the story is that it’s not about a specific technology choice, but it’s more about a really important problem, right.
TAN: That’s right. Yeah. If your problem is right and if your conviction is right about the value of the solution …
GEHRKE: Yeah.
TAN: …you build teams around it. You build processes around it. You’re creative in the way you execute. And, um, I’d say more times than not, we end up getting there.
GEHRKE: Yeah, well, I love that insight because it’s often much more valuable to solve an important problem than to land some deep technology on a problem that very few people care about …
TAN: I think that’s right.
GEHRKE: …and it seems like that’s what you have done here.
TAN: Yeah.
GEHRKE: Well, it was really great and inspiring to hear from you, Desney. Thanks so much for the conversation.
[OUTRO MUSIC]TAN: Yeah, thanks for having me, Johannes.
GEHRKE: To learn more about Desney’s work or to see photos of Desney during his winding journey to Microsoft, visit aka.ms/ResearcherStories (opens in new tab).
The post What’s Your Story: Desney Tan appeared first on Microsoft Research.

 Osinski’s panoramic view from the 20th floor terrace in the Upper East Side
Osinski’s panoramic view from the 20th floor terrace in the Upper East Side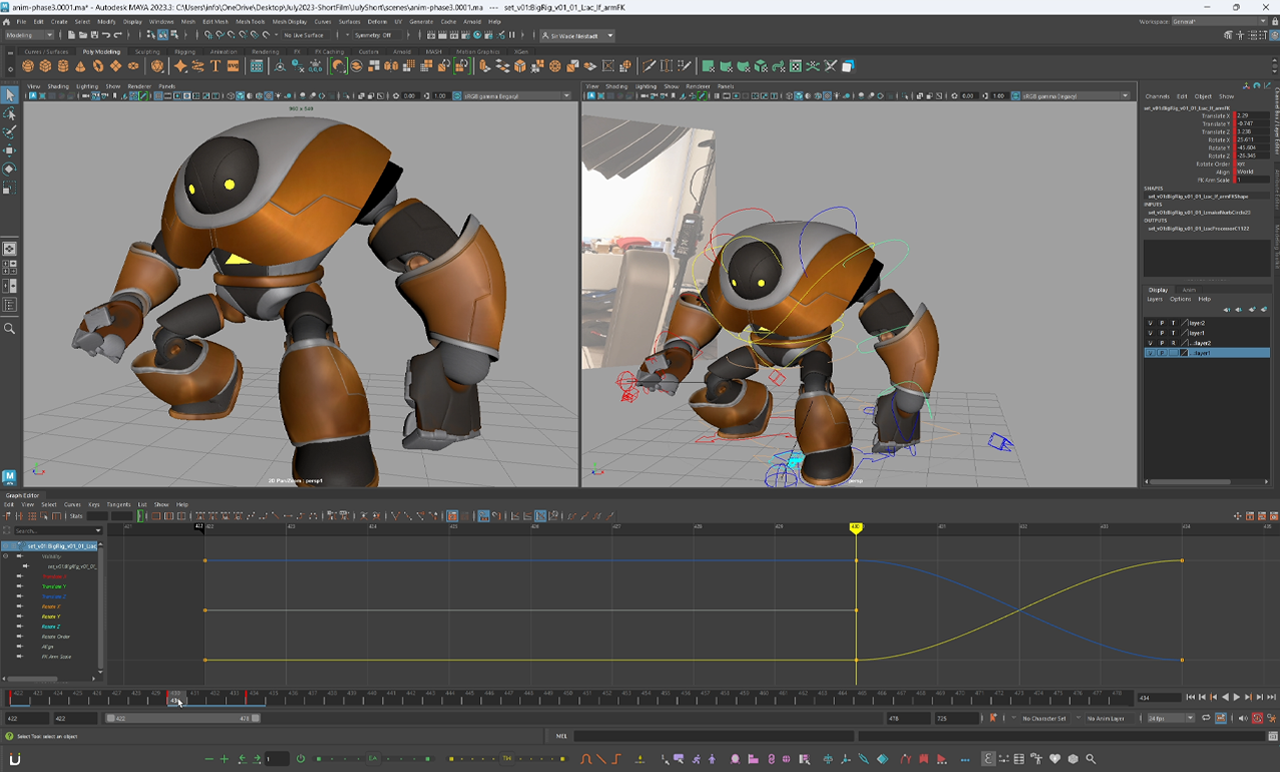 The making of Sir Wade’s VFX robot animation
The making of Sir Wade’s VFX robot animation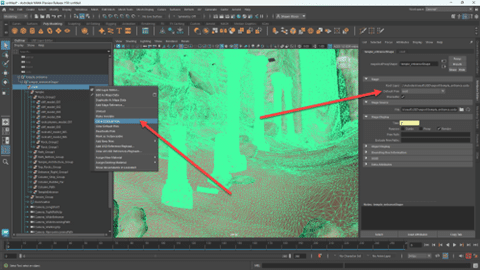 Access to default prim options in Maya UI
Access to default prim options in Maya UI





 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 
 Holiday shoppers can use generative AI to find gifts for others and themselves.
Holiday shoppers can use generative AI to find gifts for others and themselves.