An established financial services firm with over 140 years in business, Principal is a global investment management leader and serves more than 62 million customers around the world. Principal is conducting enterprise-scale near-real-time analytics to deliver a seamless and hyper-personalized omnichannel customer experience on their mission to make financial security accessible for all. They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining data integrity and security.
Solution requirements
Principal provides investment services through Genesys Cloud CX, a cloud-based contact center that provides powerful, native integrations with AWS. Each year, Principal handles millions of calls and digital interactions. As a first step, they wanted to transcribe voice calls and analyze those interactions to determine primary call drivers, including issues, topics, sentiment, average handle time (AHT) breakdowns, and develop additional natural language processing (NLP)-based analytics.
In order analyze the calls properly, Principal had a few requirements:
- Contact details: Understanding the customer journey requires understanding whether a speaker is an automated interactive voice response (IVR) system or a human agent and when a call transfer occurs between the two.
- Content redaction: Each customer audio interaction is recorded as a stereo WAV file, but could potentially include sensitive information such as HIPAA-protected and personally identifiable information (PII).
- Scalability: This architecture needed to immediately scale to thousands of calls per day and millions of calls per year. In addition, Principal needed an extensible analytics architecture that analyze other channels such as email threads and traditional voice of the customer (VoC) survey results.
- Integrity is non-negotiable at Principal—it guides everything they do. In fact, doing what’s right is one of the core values at Principal. Therefore, when the Principal team started tackling this project, they knew that ensuring the highest standard of data security such as regulatory compliance, data privacy, and data quality would be a non-negotiable, key requirement. The team needed to utilize technology with a matching stance on data security, and the ability to build custom compliance and security controls to uphold strict requirements. Attention to this key requirement allows Principal to maintain a safe and secure customer experience.
Solution overview
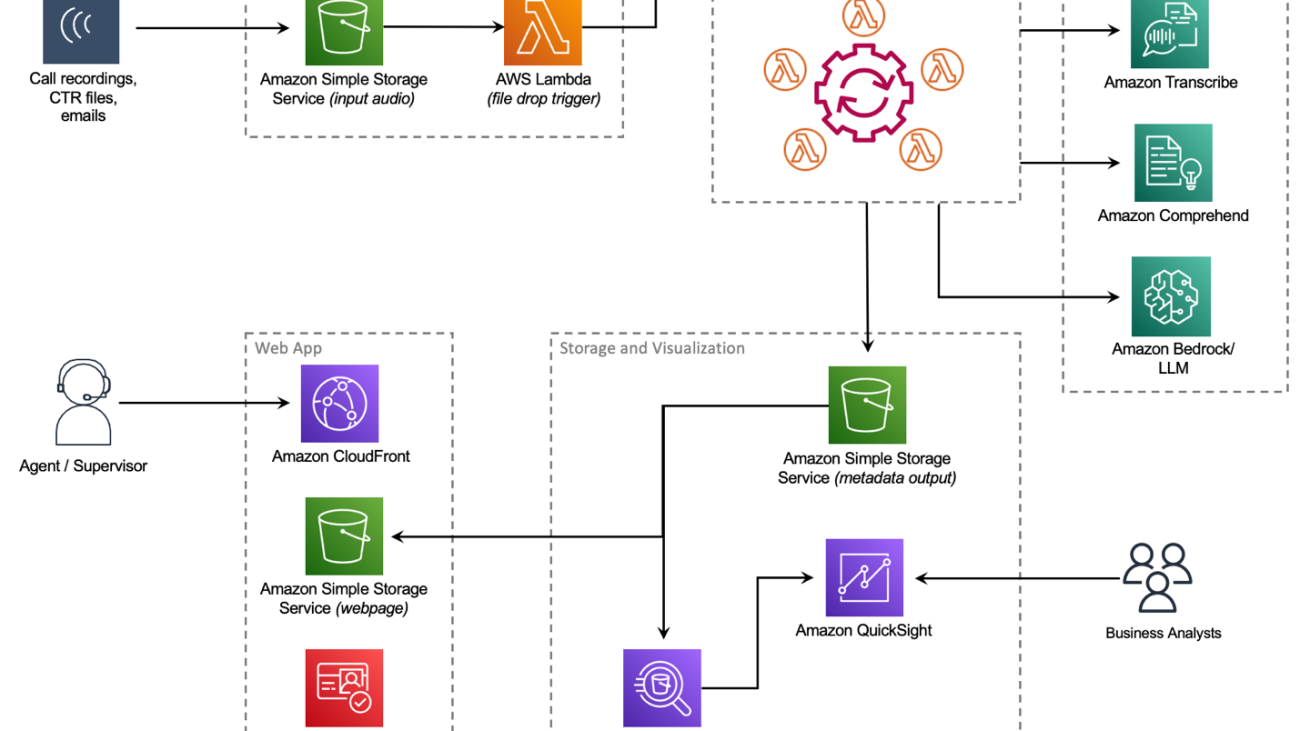
After extensive research, the Principal team finalized AWS Contact Center Intelligence (CCI) solutions, which empower companies to improve customer experience and gain conversation insights by adding AI capabilities to third-party on-premises and cloud contact centers. The CCI Post-Call Analytics (PCA) solution is part of CCI solutions suite and fit many of the identified requirements. PCA has a Solutions Library Guidance reference architecture with an open-source example repository on GitHub. Working with their AWS account team, Principal detailed the PCA solution and its deployment, and set up custom training programs and immersion days to rapidly upskill the Principal teams. The example architecture (see the following diagram) and code base in the open-source repository allowed the Principal engineering teams to jumpstart their solution around unifying the customer journey, and merging telephony records and transcript records together.
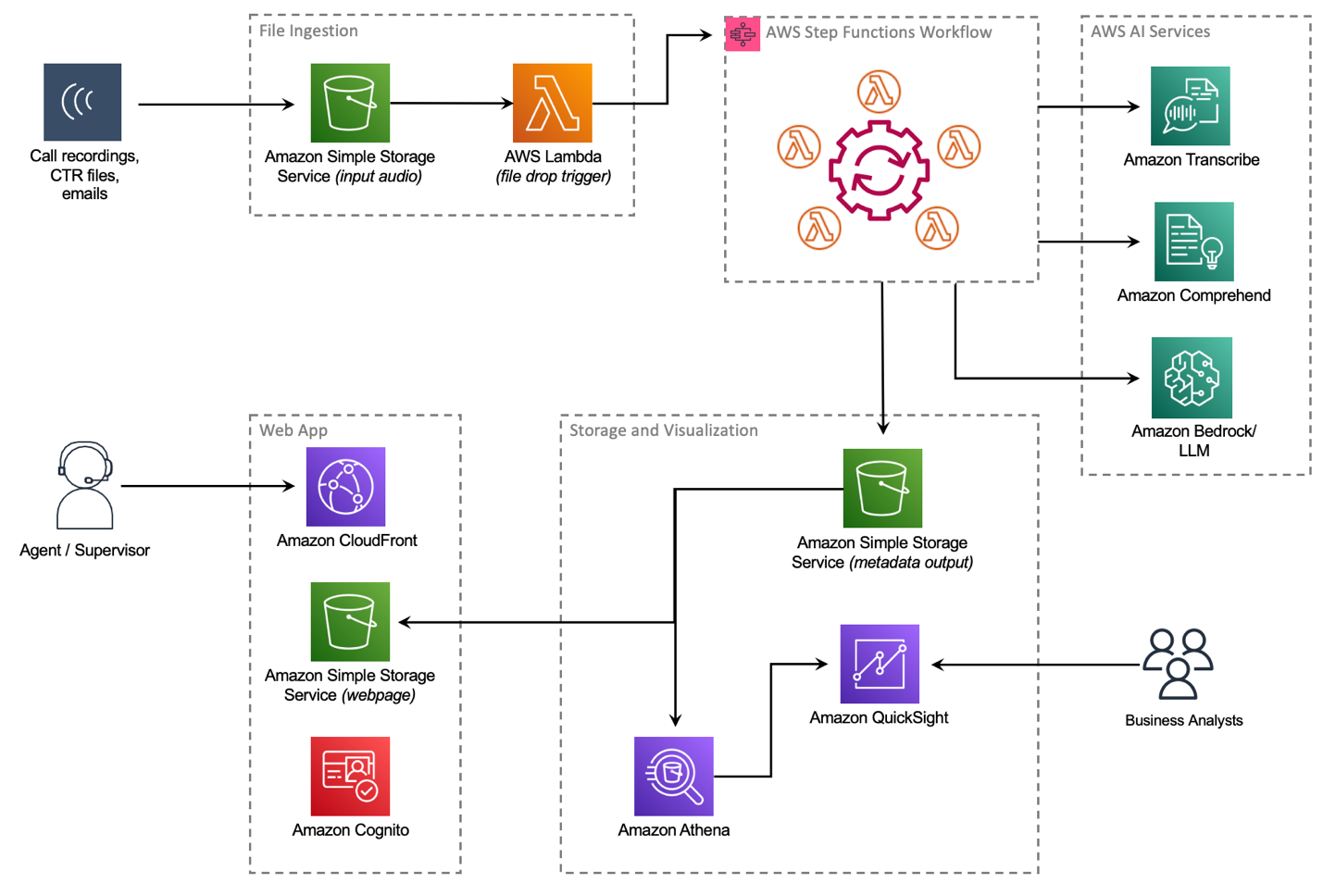
PCA provides an entire architecture around ingesting audio files in a fully automated workflow with AWS Step Functions, which is initiated when an audio file is delivered to a configured Amazon Simple Storage Service (Amazon S3) bucket. After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other business intelligence (BI) tools. PCA also offers a web-based user interface that allows customers to browse call transcripts. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself. Additionally, all data within the S3 bucket can be encrypted with keys belonging to Principal.
Principal worked with AWS technical teams to modify the Step Functions workflow within PCA to further achieve their goals. Call details such as interaction timestamps, call queues, agent transfers, and participant speaking times are tracked by Genesys in a file called a Contact Trace Record (CTR). Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
The teams built a new data ingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Principal and AWS collaborated on a new AWS Lambda function that was added to the Step Functions workflow. This Lambda function identifies CTR records and provides an additional processing step that outputs an enhanced transcript containing additional metadata such as queue and agent ID information, IVR identification and tagging, and how many agents (and IVRs) the customer was transferred to, all aggregated from the CTR records. This extra information enables Principal to create a map of the customer interaction throughout the lifecycle of the conversation and focus on the critical speech segments, while excluding less relevant ones.
Additionally, this postprocessing step enabled Principal to further enrich transcripts with internal information such as agent and queue names and expand the analytics capabilities of PCA, including custom NLP-based ML models for topic and customer intent identification, deployed using Amazon SageMaker endpoints, and additional transcript augmentation using foundational generative AI models hosted on Amazon Bedrock.
PCA is open source on GitHub, which allows customers such as Principal to extend and maintain their own forks with customized, private business code. It also allows the community to submit code back to the main repository for others to use. Principal and AWS technical teams partnered to merge the Genesys CTR and postprocessing placeholder features into the main release of PCA. This partnership between Principal and AWS enabled speed-to-market for Principal, while ensuring that existing and incoming business requirements could be rapidly added. The contributions to the open-source project has accelerated other customers’ Genesys CTR workloads.
Answer business questions
Once PCA was in place, Principal analysts, data scientists, engineers, and business owners worked with AWS SMEs to build numerous Amazon QuickSight dashboards to display the data insights and begin answering business questions. QuickSight is a cloud-scale BI service that you can use to deliver easy-to-understand insights from multiple datasets, from AWS data, third-party data, software as a service (SaaS) data, and more. The use of this BI tool, with its native integrations to the existing data repositories made accessible by Amazon Athena, made the creation of visualizations to display the large-scale data relatively straightforward, and enabled self-service BI. Visualizations were quickly drafted to answer some key questions, including “What are our customers calling us about,” “What topics relate to the longest AHT/most transfers,” and “What topics and issues relate to the lowest customer sentiment scores?” By ingesting additional data related to Principal custom topic models, the team was able to expand their use of QuickSight to include topic and correlation comparisons, model validation capabilities, and comparisons of sentiment based on speaker, segment, call, and conversation. In addition, the use of QuickSight insights quickly allowed the Principal teams to implement anomaly detection and volume prediction, while Amazon QuickSight Q, an ML feature within QuickSight that uses NLP, enabled rapid natural language quantitative data analytics.
When the initial initiative for PCA was complete, Principal knew they needed to immediately dive deeper into the omnichannel customer experience. Together, Principal and AWS have built data ingestion pipelines for customer email interactions and additional metadata from their customer data platform, and built data aggregation and analytics mechanisms to combine omnichannel data into a single customer insight lens. Utilization of Athena views and QuickSight dashboards has continued to enable classic analytics, and the implementation of proof of concept graph databases via Amazon Neptune will help Principal extract insights into interaction topics and intent relationships within the omnichannel view when implemented at scale.
The Results
PCA helped accelerate time to market. Principal was able to deploy the existing open-source PCA app by themselves in 1 day. Then, Principal worked together with AWS and expanded the PCA offering with numerous features like the Genesys CTR integration over a period of 3 months. The development and deployment process was a joint, iterative process that allowed Principal to test and process production call volumes on newly built features. Since the initial engagement, AWS and Principal continue to work together, sharing business requirements, roadmaps, code, and bug fixes to expand PCA.
Since its initial development and deployment, Principal has processed over 1 million customer calls through the PCA framework. This resulted in over 63 million individual speech segments spoken by a customer, agent, or IVR. With this wealth of data, Principal has been able to conduct large-scale historical and near-real-time analytics to gain insights into the customer experience.
AWS CCI solutions are a game-changer for Principal. Principal’s existing suite of CCI tools, which includes Qualtrics for simple dashboarding and opportunity identification, was expanded with the addition of PCA. The addition of PCA to the suite of CCI tools enabled Principal to rapidly conduct deep analytics on their contact center interactions. With this data, Principal now can conduct advanced analytics to understand customer interactions and call drivers, including topics, intents, issues, action items, and outcomes. Even in a small-scale, controlled production environment, the PCA data lake has spawned numerous new use cases.
Roadmap
The data generated from PCA could be used to make critical business decisions regarding call routing based on insights around which topics are driving longer average handle time, longer holds, more transfers, and negative customer sentiment. Knowledge on when customer interactions with the IVR and automated voice assistants are misunderstood or misrouted will help Principal improve the self-service experience. Understanding why a customer called instead of using the website is critical to improving the customer journey and boosting customer happiness. Product managers responsible for enhancing web experiences have shared how excited they are to be able to use data from PCA to drive their prioritization of new enhancements and measure the impact of changes. Principal is also analyzing other potential use cases such as customer profile mapping, fraud detection, workforce management, the use of additional AI/ML and large language models (LLMs), and identifying new and emerging trends within their contact centers.
In the future, Principal plans to continue expanding postprocessing capabilities with additional data aggregation, analytics, and natural language generation (NLG) models for text summarization. Principal is currently integrating generative AI and foundational models (such as Amazon Titan) to their proprietary solutions. Principal plans to use AWS generative AI to enhance employee productivity, grow assets under management, deliver high-quality customer experiences, and deliver tools that allow customers to make investment and retirement decisions efficiently. Given the flexibility and extensibility of the open-source PCA framework, the teams at Principal have an extensive list of additional enhancements, analytics, and insights that could extend the existing framework.
“With AWS Post Call analytics solution, Principal can currently conduct large-scale historical analytics to understand where customer experiences can be improved, generate actionable insights, and prioritize where to act. Now, we are adding generative AI using Amazon Bedrock to help our business users make data-driven decisions with higher speed and accuracy, while reducing costs. We look forward to exploring the post call summarization feature in Amazon Transcribe Call Analytics in order to enable our agents to focus their time and resources engaging with customers, rather than manual after contact work.”
– says Miguel Sanchez Urresty, Director of Data & Analytics at Principal Financial Group.
Conclusion
The AWS CCI PCA solution is designed to improve customer experience, derive customer insights, and reduce operational costs by adding AI and ML to the contact center provider of your choice. To learn more about other CCI solutions, such as Live Call Analytics, refer to AWS Contact Center Intelligence (CCI) Solutions.
About Principal Financial Group
Principal Financial Group and affiliates, Des Moines IA is a financial company with 19,000 employees. In business for more than 140 years, we’re helping more than 62 million customers in various countries around the world as of December 31, 2022.
AWS and Amazon are not affiliates of any company of the Principal Financial Group Insurance products issued by Principal National Life Insurance Co (except in NY) and Principal Life Insurance Company. Plan administrative services offered by Principal Life. Principal Funds, Inc. is distributed by Principal Funds Distributor, Inc. Securities offered through Principal Securities, Inc., member SIPC and/or independent broker/dealers. Referenced companies are members of the Principal Financial Group, Des Moines, IA 50392. ©2023 Principal Financial Services, Inc.
This communication is intended to be educational in nature and is not intended to be taken as a recommendation. Insurance products and plan administrative services provided through Principal Life Insurance Company, a member of the Principal Financial Group, Des Moines, IA 50392
About the authors
 Christopher Lott is a Senior Solutions Architect in the AWS AI Language Services team. He has 20 years of enterprise software development experience. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/general aviation, and traveling the world.
Christopher Lott is a Senior Solutions Architect in the AWS AI Language Services team. He has 20 years of enterprise software development experience. Chris lives in Sacramento, California, and enjoys gardening, cooking, aerospace/general aviation, and traveling the world.
 Dr. Nicki Susman is a Senior Data Scientist and the Technical Lead of the Principal Language AI Services team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps.
Dr. Nicki Susman is a Senior Data Scientist and the Technical Lead of the Principal Language AI Services team. She has extensive experience in data and analytics, application development, infrastructure engineering, and DevSecOps.



















 Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music.
Gopi Krishnamurthy is a Senior AI/ML Solutions Architect at Amazon Web Services based in New York City. He works with large Automotive customers as their trusted advisor to transform their Machine Learning workloads and migrate to the cloud. His core interests include deep learning and serverless technologies. Outside of work, he likes to spend time with his family and explore a wide range of music. Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks.
Shreyas Subramanian is a Principal AI/ML specialist Solutions Architect, and helps customers by using Machine Learning to solve their business challenges using the AWS platform. Shreyas has a background in large scale optimization and Machine Learning, and in use of Machine Learning and Reinforcement Learning for accelerating optimization tasks. Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems.
Sujitha Martin is an Applied Scientist in the Generative AI Innovation Center (GAIIC). Her expertise is in building machine learning solutions involving computer vision and natural language processing for various industry verticals. In particular, she has extensive experience working on human-centered situational awareness and knowledge infused learning for highly autonomous systems. Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.
Francisco Calderon is a Data Scientist in the Generative AI Innovation Center (GAIIC). As a member of the GAIIC, he helps discover the art of the possible with AWS customers using Generative AI technologies. In his spare time, Francisco likes to play music and guitar, playing soccer with his daughters, and enjoying time with his family.