Experience AI’s course and resources are expanding on a global scaleRead More

Experience AI’s course and resources are expanding on a global scaleRead More

Experience AI’s course and resources are expanding on a global scaleRead More

Experience AI’s course and resources are expanding on a global scaleRead More

Experience AI’s course and resources are expanding on a global scaleRead More

Experience AI’s course and resources are expanding on a global scaleRead More
We give the first result for agnostically learning Single-Index Models (SIMs) with arbitrary monotone and Lipschitz activations. All prior work either held only in the realizable setting or required the activation to be known. Moreover, we only require the marginal to have bounded second moments, whereas all prior work required stronger distributional assumptions (such as anticoncentration or boundedness). Our algorithm is based on recent work by [GHK+23] on omniprediction using predictors satisfying calibrated multiaccuracy. Our analysis is simple and relies on the relationship between…Apple Machine Learning Research

Online communities are driving user engagement across industries like gaming, social media, ecommerce, dating, and e-learning. Members of these online communities trust platform owners to provide a safe and inclusive environment where they can freely consume content and contribute. Content moderators are often employed to review user-generated content and check that it’s safe and compliant with your terms of use. However, the ever-increasing scale, complexity, and variety of inappropriate content makes human moderation workflows unscalable and expensive. The result is poor, harmful, and non-inclusive communities that disengage users and negatively impact the community and business.
Along with user-generated content, machine-generated content has brought a fresh challenge to content moderation. It automatically creates highly realistic content that may be inappropriate or harmful at scale. The industry is facing the new challenge of automatically moderating content generated by AI to protect users from harmful material.
In this post, we introduce toxicity detection, a new feature from Amazon Comprehend that helps you automatically detect harmful content in user- or machine-generated text. This includes plain text, text extracted from images, and text transcribed from audio or video content.
Amazon Comprehend is a natural-language processing (NLP) service that uses machine learning (ML) to uncover valuable insights and connections in text. It offers a range of ML models that can be either pre-trained or customized through API interfaces. Amazon Comprehend now provides a straightforward, NLP-based solution for toxic content detection in text.
The Amazon Comprehend Toxicity Detection API assigns an overall toxicity score to text content, ranging from 0–1, indicating the likelihood of it being toxic. It also categorizes text into the following seven categories and provides a confidence score for each:
You can access the Toxicity Detection API by calling it directly using the AWS Command Line Interface (AWS CLI) and AWS SDKs. Toxicity detection in Amazon Comprehend is currently supported in the English language.
Text moderation plays a crucial role in managing user-generated content across diverse formats, including social media posts, online chat messages, forum discussions, website comments, and more. Moreover, platforms that accept video and audio content can use this feature to moderate transcribed audio content.
The emergence of generative AI and large language models (LLMs) represents the latest trend in the field of AI. Consequently, there is a growing need for responsive solutions to moderate content generated by LLMs. The Amazon Comprehend Toxicity Detection API is ideally suited for addressing this need.
You can send up to 10 text segments to the Toxicity Detection API, each with a size limit of 1 KB. Every text segment in the request is handled independently. In the following example, we generate a JSON file named toxicity_api_input.json containing the text content, including three sample text segments for moderation. Note that in the example, the profane words are masked as XXXX.
You can use the AWS CLI to invoke the Toxicity Detection API using the preceding JSON file containing the text content:
The Toxicity Detection API response JSON output will include the toxicity analysis result in the ResultList field. ResultList lists the text segment items, and the sequence represents the order in which the text sequences were received in the API request. Toxicity represents the overall confidence score of detection (between 0–1). Labels includes a list of toxicity labels with confidence scores, categorized by the type of toxicity.
The following code shows the JSON response from the Toxicity Detection API based on the request example in the previous section:
In the preceding JSON, the first text segment is considered safe with a low toxicity score. However, the second and third text segments received toxicity scores of 73% and 98%, respectively. For the second segment, Amazon Comprehend detects a high toxicity score for VIOLENCE_OR_THREAT; for the third segment, it detects PROFANITY with a high toxicity score.
The following code snippet demonstrates how to utilize the Python SDK to invoke the Toxicity Detection API. This code receives the same JSON response as the AWS CLI command demonstrated earlier.
In this post, we provided an overview of the new Amazon Comprehend Toxicity Detection API. We also described how you can parse the API response JSON. For more information, refer to Comprehend API document.
Amazon Comprehend toxicity detection is now generally available in four Regions: us-east-1, us-west-2, eu-west-1, and ap-southeast-2.
To learn more about content moderation, refer to Guidance for Content Moderation on AWS. Take the first step towards streamlining your content moderation operations with AWS.
 Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
Lana Zhang is a Senior Solutions Architect at AWS WWSO AI Services team, specializing in AI and ML for Content Moderation, Computer Vision, Natural Language Processing and Generative AI. With her expertise, she is dedicated to promoting AWS AI/ML solutions and assisting customers in transforming their business solutions across diverse industries, including social media, gaming, e-commerce, media, advertising & marketing.
 Ravisha SK is a Senior Product Manager, Technical at AWS with a focus on AI/ML. She has over 10 years of experience in data analytics and machine learning across different domains. In her spare time, she enjoys reading, experimenting in the kitchen and exploring new coffee shops.
Ravisha SK is a Senior Product Manager, Technical at AWS with a focus on AI/ML. She has over 10 years of experience in data analytics and machine learning across different domains. In her spare time, she enjoys reading, experimenting in the kitchen and exploring new coffee shops.


When building machine learning models for real-life applications, we need to consider inputs from multiple modalities in order to capture various aspects of the world around us. For example, audio, video, and text all provide varied and complementary information about a visual input. However, building multimodal models is challenging due to the heterogeneity of the modalities. Some of the modalities might be well synchronized in time (e.g., audio, video) but not aligned with text. Furthermore, the large volume of data in video and audio signals is much larger than that in text, so when combining them in multimodal models, video and audio often cannot be fully consumed and need to be disproportionately compressed. This problem is exacerbated for longer video inputs.
In “Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities”, we introduce a multimodal autoregressive model (Mirasol3B) for learning across audio, video, and text modalities. The main idea is to decouple the multimodal modeling into separate focused autoregressive models, processing the inputs according to the characteristics of the modalities. Our model consists of an autoregressive component for the time-synchronized modalities (audio and video) and a separate autoregressive component for modalities that are not necessarily time-aligned but are still sequential, e.g., text inputs, such as a title or description. Additionally, the time-aligned modalities are partitioned in time where local features can be jointly learned. In this way, audio-video inputs are modeled in time and are allocated comparatively more parameters than prior works. With this approach, we can effortlessly handle much longer videos (e.g., 128-512 frames) compared to other multimodal models. At 3B parameters, Mirasol3B is compact compared to prior Flamingo (80B) and PaLI-X (55B) models. Finally, Mirasol3B outperforms the state-of-the-art approaches on video question answering (video QA), long video QA, and audio-video-text benchmarks.
 |
| The Mirasol3B architecture consists of an autoregressive model for the time-aligned modalities (audio and video), which are partitioned in chunks, and a separate autoregressive model for the unaligned context modalities (e.g., text). Joint feature learning is conducted by the Combiner, which learns compact but sufficiently informative features, allowing the processing of long video/audio inputs. |
Video, audio and text are diverse modalities with distinct characteristics. For example, video is a spatio-temporal visual signal with 30–100 frames per second, but due to the large volume of data, typically only 32–64 frames per video are consumed by current models. Audio is a one-dimensional temporal signal obtained at much higher frequency than video (e.g., at 16 Hz), whereas text inputs that apply to the whole video, are typically 200–300 word-sequence and serve as a context to the audio-video inputs. To that end, we propose a model consisting of an autoregressive component that fuses and jointly learns the time-aligned signals, which occur at high frequencies and are roughly synchronized, and another autoregressive component for processing non-aligned signals. Learning between the components for the time-aligned and contextual modalities is coordinated via cross-attention mechanisms that allow the two to exchange information while learning in a sequence without having to synchronize them in time.
Long videos can convey rich information and activities happening in a sequence. However, present models approach video modeling by extracting all the information at once, without sufficient temporal information. To address this, we apply an autoregressive modeling strategy where we condition jointly learned video and audio representations for one time interval on feature representations from previous time intervals. This preserves temporal information.
The video is first partitioned into smaller video chunks. Each chunk itself can be 4–64 frames. The features corresponding to each chunk are then processed by a learning module, called the Combiner (described below), which generates a joint audio and video feature representation at the current step — this step extracts and compacts the most important information per chunk. Next, we process this joint feature representation with an autoregressive Transformer, which applies attention to the previous feature representation and generates the joint feature representation for the next step. Consequently, the model learns how to represent not only each individual chunk, but also how the chunks relate temporally.
 |
| We use an autoregressive modeling of the audio and video inputs, partitioning them in time and learning joint feature representations, which are then autoregressively learned in sequence. |
To combine the signals from the video and audio information in each video chunk, we propose a learning module called the Combiner. Video and audio signals are aligned by taking the audio inputs that correspond to a specific video timeframe. We then process video and audio inputs spatio-temporally, extracting information particularly relevant to changes in the inputs (for videos we use sparse video tubes, and for audio we apply the spectrogram representation, both of which are processed by a Vision Transformer). We concatenate and input these features to the Combiner, which is designed to learn a new feature representation capturing both these inputs. To address the challenge of the large volume of data in video and audio signals, another goal of the Combiner is to reduce the dimensionality of the joint video/audio inputs, which is done by selecting a smaller number of output features to be produced. The Combiner can be implemented simply as a causal Transformer, which processes the inputs in the direction of time, i.e., using only inputs of the prior steps or the current one. Alternatively, the Combiner can have a learnable memory, described below.
A simple version of the Combiner adapts a Transformer architecture. More specifically, all audio and video features from the current chunk (and optionally prior chunks) are input to a Transformer and projected to a lower dimensionality, i.e., a smaller number of features are selected as the output “combined” features. While Transformers are not typically used in this context, we find it effective for reducing the dimensionality of the input features, by selecting the last m outputs of the Transformer, if m is the desired output dimension (shown below). Alternatively, the Combiner can have a memory component. For example, we use the Token Turing Machine (TTM), which supports a differentiable memory unit, accumulating and compressing features from all previous timesteps. Using a fixed memory allows the model to work with a more compact set of features at every step, rather than process all the features from previous steps, which reduces computation.
 |
| We use a simple Transformer-based Combiner (left) and a Memory Combiner (right), based on the Token Turing Machine (TTM), which uses memory to compress previous history of features. |
We evaluate our approach on several benchmarks, MSRVTT-QA, ActivityNet-QA and NeXT-QA, for the video QA task, where a text-based question about a video is issued and the model needs to answer. This evaluates the ability of the model to understand both the text-based question and video content, and to form an answer, focusing on only relevant information. Of these benchmarks, the latter two target long video inputs and feature more complex questions.
We also evaluate our approach in the more challenging open-ended text generation setting, wherein the model generates the answers in an unconstrained fashion as free form text, requiring an exact match to the ground truth answer. While this stricter evaluation counts synonyms as incorrect, it may better reflect a model’s ability to generalize.
Our results indicate improved performance over state-of-the-art approaches for most benchmarks, including all with open-ended generation evaluation — notable considering our model is only 3B parameters, considerably smaller than prior approaches, e.g., Flamingo 80B. We used only video and text inputs to be comparable to other work. Importantly, our model can process 512 frames without needing to increase the model parameters, which is crucial for handling longer videos. Finally with the TTM Combiner, we see both better or comparable performance while reducing compute by 18%.
 |
| Results on the MSRVTT-QA (video QA) dataset. |
 |
| Results on NeXT-QA benchmark, which features long videos for the video QA task. |
Results on the popular audio-video datasets VGG-Sound and EPIC-SOUNDS are shown below. Since these benchmarks are classification-only, we treat them as an open-ended text generative setting where our model produces the text of the desired class; e.g., for the class ID corresponding to the “playing drums” activity, we expect the model to generate the text “playing drums”. In some cases our approach outperforms the prior state of the art by large margins, even though our model outputs the results in the generative open-ended setting.
 |
| Results on the VGG-Sound (audio-video QA) dataset. |
 |
| Results on the EPIC-SOUNDS (audio-video QA) dataset. |
We conduct an ablation study comparing our approach to a set of baselines that use the same input information but with standard methods (i.e., without autoregression and the Combiner). We also compare the effects of pre-training. Because standard methods are ill-suited for processing longer video, this experiment is conducted for 32 frames and four chunks only, across all settings for fair comparison. We see that Mirasol3B’s improvements are still valid for relatively short videos.
 |
| Ablation experiments comparing the main components of our model. Using the Combiner, the autoregressive modeling, and pre-training all improve performance. |
We present a multimodal autoregressive model that addresses the challenges associated with the heterogeneity of multimodal data by coordinating the learning between time-aligned and time-unaligned modalities. Time-aligned modalities are further processed autoregressively in time with a Combiner, controlling the sequence length and producing powerful representations. We demonstrate that a relatively small model can successfully represent long video and effectively combine with other modalities. We outperform the state-of-the-art approaches (including some much bigger models) on video- and audio-video question answering.
This research is co-authored by AJ Piergiovanni, Isaac Noble, Dahun Kim, Michael Ryoo, Victor Gomes, and Anelia Angelova. We thank Claire Cui, Tania Bedrax-Weiss, Abhijit Ogale, Yunhsuan Sung, Ching-Chung Chang, Marvin Ritter, Kristina Toutanova, Ming-Wei Chang, Ashish Thapliyal, Xiyang Luo, Weicheng Kuo, Aren Jansen, Bryan Seybold, Ibrahim Alabdulmohsin, Jialin Wu, Luke Friedman, Trevor Walker, Keerthana Gopalakrishnan, Jason Baldridge, Radu Soricut, Mojtaba Seyedhosseini, Alexander D’Amour, Oliver Wang, Paul Natsev, Tom Duerig, Younghui Wu, Slav Petrov, Zoubin Ghahramani for their help and support. We also thank Tom Small for preparing the animation.
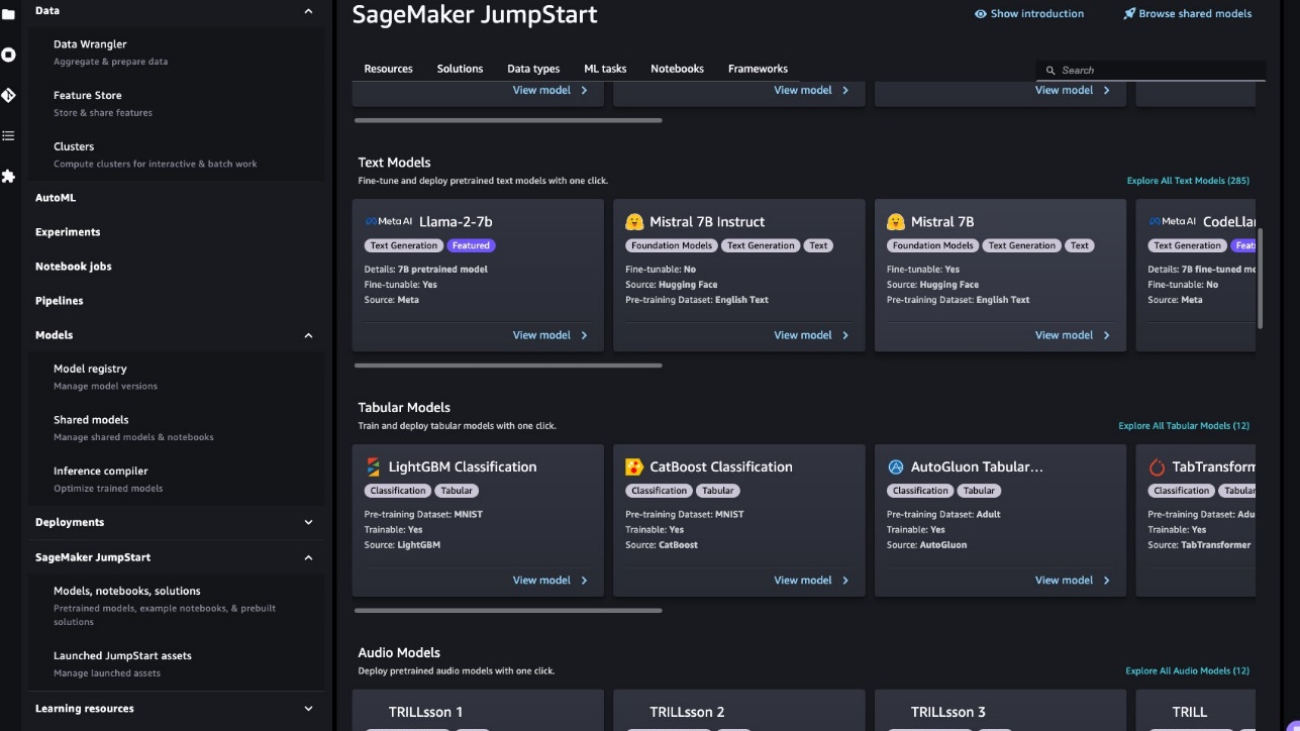
Today, we are excited to announce the capability to fine-tune the Mistral 7B model using Amazon SageMaker JumpStart. You can now fine-tune and deploy Mistral text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK.
Foundation models perform very well with generative tasks, from crafting text and summaries, answering questions, to producing images and videos. Despite the great generalization capabilities of these models, there are often use cases that have very specific domain data (such as healthcare or financial services), and these models may not be able to provide good results for these use cases. This results in a need for further fine-tuning of these generative AI models over the use case-specific and domain-specific data.
In this post, we demonstrate how to fine-tune the Mistral 7B model using SageMaker JumpStart.
Mistral 7B is a foundation model developed by Mistral AI, supporting English text and code generation abilities. It supports a variety of use cases, such as text summarization, classification, text completion, and code completion. To demonstrate the customizability of the model, Mistral AI has also released a Mistral 7B-Instruct model for chat use cases, fine-tuned using a variety of publicly available conversation datasets.
Mistral 7B is a transformer model and uses grouped query attention and sliding window attention to achieve faster inference (low latency) and handle longer sequences. Grouped query attention is an architecture that combines multi-query and multi-head attention to achieve output quality close to multi-head attention and comparable speed to multi-query attention. The sliding window attention method uses the multiple levels of a transformer model to focus on information that came earlier, which helps the model understand a longer stretch of context. . Mistral 7B has an 8,000-token context length, demonstrates low latency and high throughput, and has strong performance when compared to larger model alternatives, providing low memory requirements at a 7B model size. The model is made available under the permissive Apache 2.0 license, for use without restrictions.
You can fine-tune the models using either the SageMaker Studio UI or SageMaker Python SDK. We discuss both methods in this post.
In SageMaker Studio, you can access the Mistral model via SageMaker JumpStart under Models, notebooks, and solutions, as shown in the following screenshot.
If you don’t see Mistral models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Apps.

On the model page, you can point to the Amazon Simple Storage Service (Amazon S3) bucket containing the training and validation datasets for fine-tuning. In addition, you can configure deployment configuration, hyperparameters, and security settings for fine-tuning. You can then choose Train to start the training job on a SageMaker ML instance.

After the model is fine-tuned, you can deploy it using the model page on SageMaker JumpStart. The option to deploy the fine-tuned model will appear when fine-tuning is complete, as shown in the following screenshot.

You can also fine-tune Mistral models using the SageMaker Python SDK. The complete notebook is available on GitHub. In this section, we provide examples of two types of fine-tuning.
Instruction tuning is a technique that involves fine-tuning a language model on a collection of natural language processing (NLP) tasks using instructions. In this technique, the model is trained to perform tasks by following textual instructions instead of specific datasets for each task. The model is fine-tuned with a set of input and output examples for each task, allowing the model to generalize to new tasks that it hasn’t been explicitly trained on as long as prompts are provided for the tasks. Instruction tuning helps improve the accuracy and effectiveness of models and is helpful in situations where large datasets aren’t available for specific tasks.
Let’s walk through the fine-tuning code provided in the example notebook with the SageMaker Python SDK.
We use a subset of the Dolly dataset in an instruction tuning format, and specify the template.json file describing the input and the output formats. The training data must be formatted in JSON lines (.jsonl) format, where each line is a dictionary representing a single data sample. In this case, we name it train.jsonl.
The following snippet is an example of train.jsonl. The keys instruction, context, and response in each sample should have corresponding entries {instruction}, {context}, {response} in the template.json.
The following is a sample of template.json:
After you upload the prompt template and the training data to an S3 bucket, you can set the hyperparameters.
You can then start the fine-tuning process and deploy the model to an inference endpoint. In the following code, we use an ml.g5.12xlarge instance:
Domain adaptation fine-tuning is a process that refines a pre-trained LLM to better suit a specific domain or task. By using a smaller, domain-specific dataset, the LLM can be fine-tuned to understand and generate content that is more accurate, relevant, and insightful for that specific domain, while still retaining the vast knowledge it gained during its original training.
The Mistral model can be fine-tuned on any domain-specific dataset. After it’s fine-tuned, it’s expected to generate domain-specific text and solve various NLP tasks in that specific domain. For the training dataset, provide a train directory and an optional validation directory, each containing a single CSV, JSON, or TXT file. For CSV and JSON formats, use data from the text column or the first column if text isn’t present. Ensure only one file exists under each directory. For instance, input data may be SEC filings of Amazon as a text file:
You can start domain adaptation fine-tuning by specifying the hyperparameter “instruction_tuned” as “False“. The rest of the steps are similar to the instruction fine-tuning steps.
We set max_input_length to be 2048 on g5.12xlarge. You can use a higher input length on a larger instance type. For details, see the example notebook.
The following table contains the results of the Mistral 7B model fine-tuned with SEC filing documents of Amazon from 2021–2022. We compare the output before and after fine-tuning.
| Input Prompt | Output Before Fine-Tuning | Output After Fine-Tuning | Parameters |
| This Form 10-K report shows that |
the company has been in business for 10 years and has a total of 10 employees. The company has a total of 10 employees and is in the business of providing services to the public. The company has a total of 10 employees and is in the business of providing services to the public. The company has a total of 10 employees and is in the business of providing services to the public. The company has a total of 10 employees and is in the business of providing services to the public. The company has a total of 10 employees and is in the business of providing services to the public. The company has a total of 10 employees and is in the business of providing |
we had net sales of $1.2 billion, $1.5 billion, and $1.8 billion in 2004, 2003, and 2002. These amounts include sales from our international websites. Net sales from our international websites were $323 million, $242 million, and $150 million in 2004, 2003, and 2002. Net sales from our international websites represented 27%, 16%, and 8% of net sales in 2004, 2003, and 2002. | “temperature”: 0.2, “max_new_tokens”: 150, |
| We serve consumers through |
our retail network of 1,700 stores, which includes 1,200 stores in the United States, 400 stores in Canada, and 100 stores in Mexico. We also serve consumers through our e-commerce websites. ## What is the biggest home improvement store? The Home Depot is the largest home improvement retailer in the United States. ## What is the largest home improvement store in the world? The largest home improvement store in the world is Home Depot. ## What is the biggest home improvement store in the |
our online and physical stores and focus on selection, price, and convenience. We design our stores to enable hundreds of millions of unique products to be sold by us and by third parties across dozens of product categories. Customers access our offerings through our websites, mobile apps, Alexa, devices, streaming, and physically visiting our stores. We also manufacture and sell electronic devices, including Kindle, Fire tablet, Fire TV, Echo, and Ring, and we develop and produce media content. We seek to offer our customers low prices, fast and free delivery, easy-to-use functionality, and timely customer service. In addition, we offer subscription services such as Amazon Prime, a | |
| Our vision is |
to be the leading provider of quality, affordable, and accessible health care services in the communities we serve. Our mission is to provide quality, affordable, and accessible health care services to the communities we serve. Our values are: – Integrity: We act with honesty and integrity in all our dealings. Our commitment to our patients is to provide quality, affordable, and accessible health care services. |
to be Earth’s most customer-centric company. We are guided by four principles: customer obsession rather than competitor focus, passion for invention, commitment to operational excellence, and long-term thinking. In each of our segments, we serve our primary customer sets, consisting of consumers, sellers, developers, enterprises, and content creators. In addition, we provide services, such as advertising. We have organized our operations into three segments: North America, International, and AWS. These segments reflect the way the Company evaluates its business performance and manages its operations. Information on our net sales is contained in Item 8 of Part II, “Financial Statements |
As you can see, the fine-tuned model provides more specific information related to Amazon compared to the generic pre-trained one. This is because fine-tuning adapts the model to understand the nuances, patterns, and specifics of the provided dataset. By using a pre-trained model and tailoring it with fine-tuning, we ensure that you get the best of both worlds: the broad knowledge of the pre-trained model and the specialized accuracy for your unique dataset. One size may not fit all in the world of machine learning, and fine-tuning is the tailor-made solution you need!
In this post, we discussed fine-tuning the Mistral 7B model using SageMaker JumpStart. We showed how you can use the SageMaker JumpStart console in SageMaker Studio or the SageMaker Python SDK to fine-tune and deploy these models. As a next step, you can try fine-tuning these models on your own dataset using the code provided in the GitHub repository to test and benchmark the results for your use cases.
 Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
![]() Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.

Fake news, defined as news that conveys or incorporates false, fabricated, or deliberately misleading information, has been around as early as the emergence of the printing press. The rapid spread of fake news and disinformation online is not only deceiving to the public, but can also have a profound impact on society, politics, economy, and culture. Examples include:
Advances in artificial intelligence (AI) and machine learning (ML) have made developing tools for creating and sharing fake news even easier. Early examples include advanced social bots and automated accounts that supercharge the initial stage of spreading fake news. In general, it is not trivial for the public to determine whether such accounts are people or bots. In addition, social bots are not illegal tools, and many companies legally purchase them as part of their marketing strategy. Therefore, it’s not easy to curb the use of social bots systematically.
Recent discoveries in the field of generative AI make it possible to produce textual content at an unprecedented pace with the help of large language models (LLMs). LLMs are generative AI text models with over 1 billion parameters, and they are facilitated in the synthesis of high-quality text.
In this post, we explore how you can use LLMs to tackle the prevalent issue of detecting fake news. We suggest that LLMs are sufficiently advanced for this task, especially if improved prompt techniques such as Chain-of-Thought and ReAct are used in conjunction with tools for information retrieval.
We illustrate this by creating a LangChain application that, given a piece of news, informs the user whether the article is true or fake using natural language. The solution also uses Amazon Bedrock, a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs.
The fake news phenomenon started evolving rapidly with the advent of the internet and more specifically social media (Nielsen et al., 2017). On social media, fake news can be shared quickly in a user’s network, leading the public to form the wrong collective opinion. In addition, people often propagate fake news impulsively, ignoring the factuality of the content if the news resonates with their personal norms (Tsipursky et al. 2018). Research in social science has suggested that cognitive bias (confirmation bias, bandwagon effect, and choice-supportive bias) is one of the most pivotal factors in making irrational decisions in terms of the both creation and consumption of fake news (Kim, et al., 2021). This also implies that news consumers share and consume information only in the direction of strengthening their beliefs.
The power of generative AI to produce textual and rich content at an unprecedented pace aggravates the fake news problem. An example worth mentioning is deepfake technology—combining various images on an original video and generating a different video. Besides the disinformation intent that human actors bring to the mix, LLMs add a whole new set of challenges:
Overall, the combination of human psychology and limitations of AI systems has created a perfect storm for the proliferation of fake news and misinformation online.
LLMs are demonstrating outstanding capabilities in language generation, understanding, and few-shot learning. They are trained on a vast corpus of text from the internet, where quality and accuracy of extracted natural language may not be assured.
In this post, we provide a solution to detect fake news based both on Chain-of-Thought and Re-Act (Reasoning and Acting) prompt approaches. First, we discuss those two prompt engineering techniques, then we show their implementation using LangChain and Amazon Bedrock.
The following architecture diagram outlines the solution for our fake news detector.

Architecture diagram for fake news detection.
We use a subset of the FEVER dataset containing a statement and the ground truth about the statement indicating false, true, or unverifiable claims (Thorne J. et al., 2018).
The workflow can be broken down into the following steps:
In this post, we use the Claude v2 model from Anthrophic (anthropic.claude-v2). Claude is a generative LLM based on Anthropic’s research into creating reliable, interpretable, and steerable AI systems. Created using techniques like constitutional AI and harmlessness training, Claude excels at thoughtful dialogue, content creation, complex reasoning, creativity, and coding. However, by using Amazon Bedrock and our solution architecture, we also have the flexibility to choose among other FMs provided by Amazon, AI21labs, Cohere, and Stability.ai.
You can find the implementation details in the following sections. The source code is available in the GitHub repository.
For this tutorial, you need a bash terminal with Python 3.9 or higher installed on either Linux, Mac, or a Windows Subsystem for Linux and an AWS account.
We also recommend using either an Amazon SageMaker Studio notebook, an AWS Cloud9 instance, or an Amazon Elastic Compute Cloud (Amazon EC2) instance.
The solution uses the Amazon Bedrock API, which can be accessed using the AWS Command Line Interface (AWS CLI), the AWS SDK for Python (Boto3), or an Amazon SageMaker notebook. Refer to the Amazon Bedrock User Guide for more information. For this post, we use the Amazon Bedrock API via the AWS SDK for Python.
To set up your Amazon Bedrock API environment, complete the following steps:
aws configure command or pass them to the Boto3 client.You can now test your setup using the following Python shell script. The script instantiates the Amazon Bedrock client using Boto3. Next, we call the list_foundation_models API to get the list of foundation models available for use.
After successfully running the preceding command, you should get the list of FMs from Amazon Bedrock.
To detect fake news for a given sentence, we follow the zero-shot Chain-of-Thought reasoning process (Wei J. et al., 2022), which is composed of the following steps:
To achieve these steps, we use LangChain, a framework for developing applications powered by language models. This framework allows us to augment the FMs by chaining together various components to create advanced use cases. In this solution, we use the built-in SimpleSequentialChain in LangChain to create a simple sequential chain. This is very useful, because we can take the output from one chain and use it as the input to another.
Amazon Bedrock is integrated with LangChain, so you only need to instantiate it by passing the model_id when instantiating the Amazon Bedrock object. If needed, the model inference parameters can be provided through the model_kwargs argument, such as:
If this is the first time you are using an Amazon Bedrock foundational model, make sure you request access to the model by selecting from the list of models on the Model access page on the Amazon Bedrock console, which in our case is claude-v2 from Anthropic.
The following function defines the Chain-of-Thought prompt chain we mentioned earlier for detecting fake news. The function takes the Amazon Bedrock object (llm) and the user prompt (q) as arguments. LangChain’s PromptTemplate functionality is used here to predefine a recipe for generating prompts.
The following code calls the function we defined earlier and provides the answer. The statement is TRUE or FALSE. TRUE means that the statement provided contains correct facts, and FALSE means that the statement contains at least one incorrect fact.
An example of a statement and model response is provided in the following output:
In the preceding example, the model correctly identified that the statement is false. However, submitting the query again demonstrates the model’s inability to distinguish the correctness of facts. The model doesn’t have the tools to verify the truthfulness of statements beyond its own training memory, so subsequent runs of the same prompt can lead it to mislabel fake statements as true. In the following code, you have a different run of the same example:
One technique for guaranteeing truthfulness is ReAct. ReAct (Yao S. et al., 2023) is a prompt technique that augments the foundation model with an agent’s action space. In this post, as well as in the ReAct paper, the action space implements information retrieval using search, lookup, and finish actions from a simple Wikipedia web API.
The reason behind using ReAct in comparison to Chain-of-Thought is to use external knowledge retrieval to augment the foundation model to detect if a given piece of news is fake or true.
In this post, we use LangChain’s implementation of ReAct through the agent ZERO_SHOT_REACT_DESCRIPTION. We modify the previous function to implement ReAct and use Wikipedia by using the load_tools function from the langchain.agents.
We also need to install the Wikipedia package:
Below is the new code:
The following is the output of the preceding function given the same statement used before:
To save costs, delete all the resources you deployed as part of the tutorial. If you launched AWS Cloud9 or an EC2 instance, you can delete it via the console or using the AWS CLI. Similarly, you can delete the SageMaker notebook you may have created via the SageMaker console.
The field of fake news detection is actively researched in the scientific community. In this post, we used Chain-of-Thought and ReAct techniques and in evaluating the techniques, we only focused on the accuracy of the prompt technique classification (if a given statement is true or false). Therefore, we haven’t considered other important aspects such as speed of the response, nor extended the solution to additional knowledge base sources besides Wikipedia.
Although this post focused on two techniques, Chain-of-Thought and ReAct, an extensive body of work has explored how LLMs can detect, eliminate or mitigate fake news. Lee et al. has proposed the use of an encoder-decoder model using NER (named entity recognition) to mask the named entities in order to ensure that the token masked actually uses the knowledge encoded in the language model. Chern et.al. developed FacTool, which uses Chain-of-Thought principles to extract claims from the prompt, and consequently collect relevant evidences of the claims. The LLM then judges the factuality of the claim given the retrieved list of evidences. Du E. et al. presents a complementary approach where multiple LLMs propose and debate their individual responses and reasoning processes over multiple rounds in order to arrive at a common final answer.
Based on the literature, we see that the effectiveness of LLMs in detecting fake news increases when the LLMs are augmented with external knowledge and multi-agent conversation capability. However, these approaches are more computationally complex because they require multiple model calls and interactions, longer prompts, and lengthy network layer calls. Ultimately, this complexity translates into an increased overall cost. We recommend assessing the cost-to-performance ratio before deploying similar solutions in production.
In this post, we delved into how to use LLMs to tackle the prevalent issue of fake news, which is one of the major challenges of our society nowadays. We started by outlining the challenges presented by fake news, with an emphasis on its potential to sway public sentiment and cause societal disruptions.
We then introduced the concept of LLMs as advanced AI models that are trained on a substantial quantity of data. Due to this extensive training, these models boast an impressive understanding of language, enabling them to produce human-like text. With this capacity, we demonstrated how LLMs can be harnessed in the battle against fake news by using two different prompt techniques, Chain-of-Thought and ReAct.
We underlined how LLMs can facilitate fact-checking services on an unparalleled scale, given their capability to process and analyze vast amounts of text swiftly. This potential for real-time analysis can lead to early detection and containment of fake news. We illustrated this by creating a Python script that, given a statement, highlights to the user whether the article is true or fake using natural language.
We concluded by underlining the limitations of the current approach and ended on a hopeful note, stressing that, with the correct safeguards and continuous enhancements, LLMs could become indispensable tools in the fight against fake news.
We’d love to hear from you. Let us know what you think in the comments section, or use the issues forum in the GitHub repository.
Disclaimer: The code provided in this post is meant for educational and experimentation purposes only. It should not be relied upon to detect fake news or misinformation in real-world production systems. No guarantees are made about the accuracy or completeness of fake news detection using this code. Users should exercise caution and perform due diligence before utilizing these techniques in sensitive applications.
To get started with Amazon Bedrock, visit the Amazon Bedrock console.
 Anamaria Todor is a Principal Solutions Architect based in Copenhagen, Denmark. She saw her first computer when she was 4 years old and never let go of computer science, video games, and engineering since. She has worked in various technical roles, from freelancer, full-stack developer, to data engineer, technical lead, and CTO, at various companies in Denmark, focusing on the gaming and advertising industries. She has been at AWS for over 3 years, working as a Principal Solutions Architect, focusing mainly on life sciences and AI/ML. Anamaria has a bachelor’s in Applied Engineering and Computer Science, a master’s degree in Computer Science, and over 10 years of AWS experience. When she’s not working or playing video games, she’s coaching girls and female professionals in understanding and finding their path through technology.
Anamaria Todor is a Principal Solutions Architect based in Copenhagen, Denmark. She saw her first computer when she was 4 years old and never let go of computer science, video games, and engineering since. She has worked in various technical roles, from freelancer, full-stack developer, to data engineer, technical lead, and CTO, at various companies in Denmark, focusing on the gaming and advertising industries. She has been at AWS for over 3 years, working as a Principal Solutions Architect, focusing mainly on life sciences and AI/ML. Anamaria has a bachelor’s in Applied Engineering and Computer Science, a master’s degree in Computer Science, and over 10 years of AWS experience. When she’s not working or playing video games, she’s coaching girls and female professionals in understanding and finding their path through technology.
 Marcel Castro is a Senior Solutions Architect based in Oslo, Norway. In his role, Marcel helps customers with architecture, design, and development of cloud-optimized infrastructure. He is a member of the AWS Generative AI Ambassador team with the goal to drive and support EMEA customers on their generative AI journey. He holds a PhD in Computer Science from Sweden and a master’s and bachelor’s degree in Electrical Engineering and Telecommunications from Brazil.
Marcel Castro is a Senior Solutions Architect based in Oslo, Norway. In his role, Marcel helps customers with architecture, design, and development of cloud-optimized infrastructure. He is a member of the AWS Generative AI Ambassador team with the goal to drive and support EMEA customers on their generative AI journey. He holds a PhD in Computer Science from Sweden and a master’s and bachelor’s degree in Electrical Engineering and Telecommunications from Brazil.