
The IDP Well-Architected Custom Lens is intended for all AWS customers who use AWS to run intelligent document processing (IDP) solutions and are searching for guidance on how to build a secure, efficient, and reliable IDP solution on AWS.
Building a production-ready solution in the cloud involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS. By using the Framework, you will learn operational and architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud.
An IDP project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific terms or words. The IDP Well-Architected Custom Lens outlines the steps for performing an AWS Well-Architected review that allows you to assess and identify technical risks of your IDP workloads. It provides guidance to tackle the common challenges we see among the field, supporting you to architect your IDP workloads according to best practices.
This post focuses on the Reliability pillar of the IDP solution. Starting from the introduction of the Reliability pillar and design principles, we then dive deep into the solution design and implementation with three focus areas: foundations, change management, and failure management. By reading this post, you will learn about the Reliability pillar in the Well-Architected Framework with the IDP case study.
Design principles
The reliability pillar encompasses the ability of an IDP solution to perform document processing correctly and consistently when it’s expected and according to the defined business rules. This includes the ability to operate and test the full IDP workflow and its total lifecycle.
There are a number of principles that can help you to increase reliability. Keep these in mind as we discuss best practices:
- Automatically recover from failure – By monitoring your IDP workflow for key performance indicators (KPIs), you can run automation when a threshold is breached. This allows you to track and be notified automatically if any failure occurs and trigger automated recovery processes that work around or repair the failure. Based on KPI measures, you can also anticipate failures and apply remediation actions before they occur.
- Test recovery procedures – Test how your IDP workflow fails, and validate recovery procedures. Use automation to simulate different scenarios or recreate scenarios that led to failure before.
- Scale and adjust service capacity – Monitor IDP workflow demand and usage, and automatically adjust AWS service capacity, to maintain the optimal level to satisfy demand without over- or under-provisioning. Control and be aware of service quotas, limits, and constraints of your IDP components services, such as Amazon Textract and Amazon Comprehend.
- Automate changes – Use automation when applying changes to your IDP workflow infrastructure. Manage changes through automation, which then can be tracked and reviewed.
Focus areas
The design principles and best practices of the reliability pillar are based on insights gathered from our customers and our IDP technical specialist communities. Use them as guidance and support for your design decisions and align them with your business requirements of your IDP solution. Applying the IDP Well-Architected Lens helps you validate the resilience and efficiency of your IDP solution design, and provides recommendations to address any gaps you might identify.
The following are best practice areas for reliability of an IDP solution in the cloud:
- Foundations – AWS AI services such as Amazon Textract and Amazon Comprehend provide a set of soft and hard limits for different dimensions of usage. It’s important to review these limits and ensure your IDP solution adheres to any soft limits, while not exceeding any hard limits.
- Change management – Treat your IDP solution as infrastructure as code (IaC), allowing you to automate monitoring and change management. Use version control across components such as infrastructure and Amazon Comprehend custom models, and track changes back to point-in-time release.
- Failure management – Because an IDP workflow is an event-driven solution, your application must be resilient to handling known and unknown errors. A well-architected IDP solution has the ability to prevent failures and withstand failures when they occur by using logging and retry mechanisms. It’s important to design resilience into your IDP workflow architecture and plan for disaster recovery.
Foundations
AWS AI services provide ready-made intelligence, such as automated data extraction and analysis, using Amazon Textract, Amazon Comprehend, and Amazon Augmented AI (Amazon A2I), for your IDP workflows. There are service limits (or quotas) for these services to avoid over-provisioning and to limit request rates on API operations, protecting the services from abuse.
When planning and designing your IDP solution architecture, consider the following best practices:
- Be aware of unchangeable Amazon Textract and Amazon Comprehend service quotas, limits, and constraints – Accepted file formats, size and page count, languages, document rotations, and image size are some examples of these hard limits for Amazon Textract that can’t be changed.
- Accepted file formats include JPEG, PNG, PDF, and TIFF files. (JPEG 2000-encoded images within PDFs are supported). Document preprocessing is required before using Amazon Textract if the file format is not supported (for example, Microsoft Word or Excel). In this case, you must convert unsupported document formats to PDF or image format.
- Amazon Comprehend has different quotas for built-in models, custom models, and flywheels. Make sure that your use case is aligned with Amazon Comprehend quotas.
- Adjust Amazon Textract and Amazon Comprehend service quotas to meet your needs – The Amazon Textract Service Quotas Calculator can help you estimate the quota values that will cover your use case. You should manage your service quotas across accounts or Regions if you’re planning a disaster recovery failover between accounts or Regions for your solution. When requesting an increase of Amazon Textract quotas, make sure to follow these recommendations:
- Use the Amazon Textract Service Quotas Calculator to estimate your optimal quota value.
- Changes in requests can cause spiky network traffic, affecting throughput. Use a queueing serverless architecture or other mechanism to smooth traffic and get the most out of your allocated transactions per second (TPS).
- Implement retry logic to handle throttled calls and dropped connections.
- Configure exponential backoff and jitter to improve throughput.
Change management
Changes to your IDP workflow or its environment, such as spikes in demand or a corrupted document file, must be anticipated and accommodated to achieve a higher reliability of the solution. Some of these changes are covered by the foundations best practices described in the previous section, but those alone are not enough to accommodate changes. The following best practices must also be considered:
- Use Amazon CloudWatch to monitor your IDP workflow components, such as Amazon Textract and Amazon Comprehend. Collect metrics from the IDP workflow, automate responses to alarms, and send notifications as required to your workflow and business objectives.
- Deploy your IDP workflow solution and all infrastructure changes with automation using IaC, such as the AWS Cloud Development Kit (AWS CDK) and pre-built IDP AWS CDK constructs. This removes the potential for introducing human error and enables you to test before changing to your production environment.
- If your use case requires an Amazon Comprehend custom model, consider using a flywheel to simplify the process of improving the custom model over time. A flywheel orchestrates the tasks associated with training and evaluating a new custom model version.
- If your use case requires it, customize the output of the Amazon Textract pre-trained Queries feature by training and using an adapter for the Amazon Textract base model. Consider the following best practices when creating queries for your adapters:
- Adapter quotas define the preceding limits for adapter training. Consider these limits and raise a service quota increase request, if required:
- Maximum number of adapters – Number of adapters allowed (you can have several adapter versions under a single adapter).
- Maximum adapter versions created per month – Number of successful adapter versions that can be created per AWS account per month.
- Maximum in-progress adapter versions – Number of in-progress adapter versions (adapter training) per account.
- Make sure to use a set of documents representative of your use case (minimum five training docs and five testing docs).
- Provide as many documents for training as possible (up to 2,500 pages of training documents and 1,000 for test documents).
- Annotate queries using a variety of answers. For example, if the answer to a query is “Yes” or “No,” the annotated samples should have occurrences of both “Yes” and “No.”
- Maintain consistency in annotation style and while annotating fields with spaces.
- Use the exact query used in training for inference.
- After each round of adapter training, review the performance metrics to determine if you need to further improve your adapter to achieve your goals. Upload a new document set for training or review document annotations that have low accuracy scores before you start a new training to create an improved version of the adapter.
- Use the
AutoUpdatefeature for custom adapters. This feature attempts automated retraining if theAutoUpdateflag is enabled on an adapter.
- Adapter quotas define the preceding limits for adapter training. Consider these limits and raise a service quota increase request, if required:
Failure management
When designing an IDP solution, one important aspect to consider is its resilience, how to handle known and unknown errors that can occur. The IDP solution should have the capabilities of logging errors and retry failed operations, during the different stages of the IDP workflow. In this section, we discuss the details on how to design your IDP workflow to handle failures.
Prepare your IDP workflow to manage and withstand failures
“Everything fails, all the time,” is a famous quote from AWS CTO Werner Vogels. Your IDP solution, like everything else, will eventually fail. The question is how can it withstand failures without impacting your IDP solution users. Your IDP architecture design must be aware of failures as they occur and take action to avoid impact on availability. This must be done automatically, and without user impact. Consider the following best practices:
- Use Amazon Simple Storage Service (Amazon S3) as your scalable data store for IDP workflow documents to process. Amazon S3 provides a highly durable storage infrastructure designed for mission-critical and primary data storage.
- Back up all your IDP workflow data according to your business requirements. Implement a strategy to recover or reproduce data in case of data loss. Align this strategy with a defined Recovery Point Objective (RPO) and Recovery Time Objective (RTO) that meet your business requirements.
- If required, plan and implement a disaster recovery failover strategy of your IDP solution across AWS accounts and Regions.
- Use the Amazon Textract
OutputConfigfeature and Amazon ComprehendOutputDataConfigfeature to store the results of asynchronous processing from Amazon Textract or Amazon Comprehend to a designated S3 bucket. This allows the workflow to continue from that point rather than repeat the Amazon Textract or Amazon Comprehend invocation. The following code shows how to start an Amazon Textract asynchronous API job to analyze a document and store encrypted inference output in a defined S3 bucket. For additional information, refer to the Amazon Textract client documentation.
Design your IDP workflow to prevent failures
The reliability of a workload starts with upfront design decisions. Architecture choices will impact your workload behavior and its resilience. To improve the reliability of your IDP solution, follow these best practices.
Firstly, design your architecture following the IDP workflow. Although the stages in an IDP workflow may vary and be influenced by use case and business requirements, the stages of data capture, document classification, text extraction, content enrichment, review and validation, and consumption are typically parts of IDP workflow. These well-defined stages can be used to separate functionalities and isolate them in case of failure.
You can use Amazon Simple Queue Service (Amazon SQS) to decouple IDP workflow stages. A decoupling pattern helps isolate behavior of architecture components from other components that depend on it, increasing resiliency and agility.
Secondly, control and limit retry calls. AWS services such as Amazon Textract can fail if the maximum number of TPS allotted is exceeded, causing the service to throttle your application or drop your connection.
You should manage throttling and dropped connections by automatically retrying the operation (both synchronous and asynchronous operations). However, you should also specify a limited number of retries, after which the operation fails and throws an exception. If you make too many calls to Amazon Textract in a short period of time, it throttles your calls and sends a ProvisionedThroughputExceededExceptionerror in the operation response.
In addition, use exponential backoff and jitter for retries to improve throughput. For example, using Amazon Textract, specify the number of retries by including the config parameter when you create the Amazon Textract client. We recommend a retry count of five. In the following example code, we use the config parameter to automatically retry an operation using adaptive mode and a maximum of five retries:
Take advantage of AWS SDKs, such as the AWS SDK for Python (Boto3), to assist in retrying client calls to AWS services such as Amazon Textract and Amazon Comprehend. There are three retry modes available:
- Legacy mode – Retries calls for a limited number of errors and exceptions and include an exponential backoff by a base factor of 2.
- Standard mode – Standardizes the retry logic and behavior consistent with other AWS SDKs and extends the functionality of retries over that found in legacy mode. Any retry attempt will include an exponential backoff by a base factor of 2 for a maximum backoff time of 20 seconds.
- Adaptive mode – Includes all the features of standard mode and it introduces a client-side rate limiting through the use of a token bucket and rate limit variables that are dynamically updated with each retry attempt. It offers flexibility in client-side retries that adapts to the error or exception state response from an AWS service. With each new retry attempt, adaptive mode modifies the rate limit variables based on the error, exception, or HTTP status code presented in the response from the AWS service. These rate limit variables are then used to calculate a new call rate for the client. Each exception, error, or non-success HTTP response from an AWS service updates the rate limit variables as retries occur until a success is reached, the token bucket is exhausted, or the configured maximum attempts value is reached. Examples of exceptions, errors, or non-success HTTP responses:
Conclusion
In this post, we shared design principles, focus areas, foundations and best practices for reliability in your IDP solution.
To learn more about the IDP Well-Architected Custom Lens, explore the following posts in this series:
|
AWS is committed to the IDP Well-Architected Lens as a living tool. As the IDP solutions and related AWS AI services evolve and new AWS services become available, we will update the IDP Lens Well-Architected accordingly.
If you want to learn more about the AWS Well-Architected Framework, refer to AWS Well-Architected.
If you require additional expert guidance, contact your AWS account team to engage an IDP Specialist Solutions Architect.
About the Authors
 Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
 Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
 Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
 Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
 Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
 Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.




 Christian Denich is a Global Customer Solutions Manager at AWS. He is passionate about automotive, AI/ML and developer productivity. He supports some the world’s largest automotive brands on their cloud journey, encompassing cloud and business strategy as well as technology. Before joining AWS, Christian worked at BMW Group in both hardware and software development in various projects including connected navigation.
Christian Denich is a Global Customer Solutions Manager at AWS. He is passionate about automotive, AI/ML and developer productivity. He supports some the world’s largest automotive brands on their cloud journey, encompassing cloud and business strategy as well as technology. Before joining AWS, Christian worked at BMW Group in both hardware and software development in various projects including connected navigation.

 Jerry Mannil is a software engineer at Amazon Search. He works on improving the efficiency, robustness and scalibility of the distributed training infrastructure.
Jerry Mannil is a software engineer at Amazon Search. He works on improving the efficiency, robustness and scalibility of the distributed training infrastructure. Ken Su is a software engineer at Amazon Search. He works on improving training efficiency and scalable distributed training workflow. Outside work, he likes hiking and tennis.
Ken Su is a software engineer at Amazon Search. He works on improving training efficiency and scalable distributed training workflow. Outside work, he likes hiking and tennis. RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes.
RJ is an Engineer within Amazon. He builds and optimizes systems for distributed systems for training and works on optimizing adopting systems to reduce latency for ML Inference. Outside work, he is exploring using Generative AI for building food recipes. Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference.
Abhinandan Patni is a Senior Software Engineer at Amazon Search. He focuses on building systems and tooling for scalable distributed deep learning training and real time inference. James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on
James Park is a Solutions Architect at Amazon Web Services. He works with Amazon.com to design, build, and deploy technology solutions on AWS, and has a particular interest in AI and machine learning. In h is spare time he enjoys seeking out new cultures, new experiences, and staying up to date with the latest technology trends. You can find him on 



 Jeff Demuth is a solutions architect who joined Amazon Web Services (AWS) in 2016. He focuses on the geospatial community and is passionate about geographic information systems (GIS) and technology. Outside of work, Jeff enjoys traveling, building Internet of Things (IoT) applications, and tinkering with the latest gadgets.
Jeff Demuth is a solutions architect who joined Amazon Web Services (AWS) in 2016. He focuses on the geospatial community and is passionate about geographic information systems (GIS) and technology. Outside of work, Jeff enjoys traveling, building Internet of Things (IoT) applications, and tinkering with the latest gadgets. Swagata Prateek is a Senior Software Engineer working in Amazon Location Service at Amazon Web Services (AWS) where he focuses on Generative AI and geospatial.
Swagata Prateek is a Senior Software Engineer working in Amazon Location Service at Amazon Web Services (AWS) where he focuses on Generative AI and geospatial.
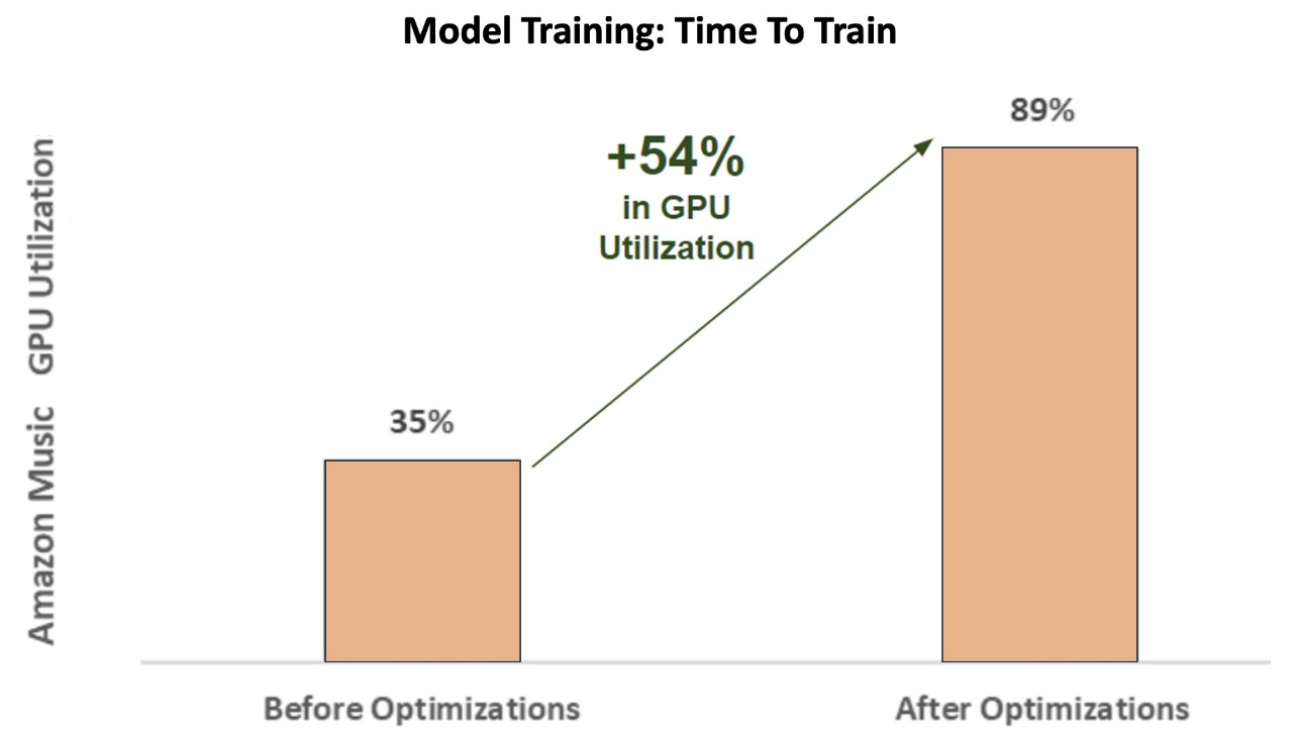
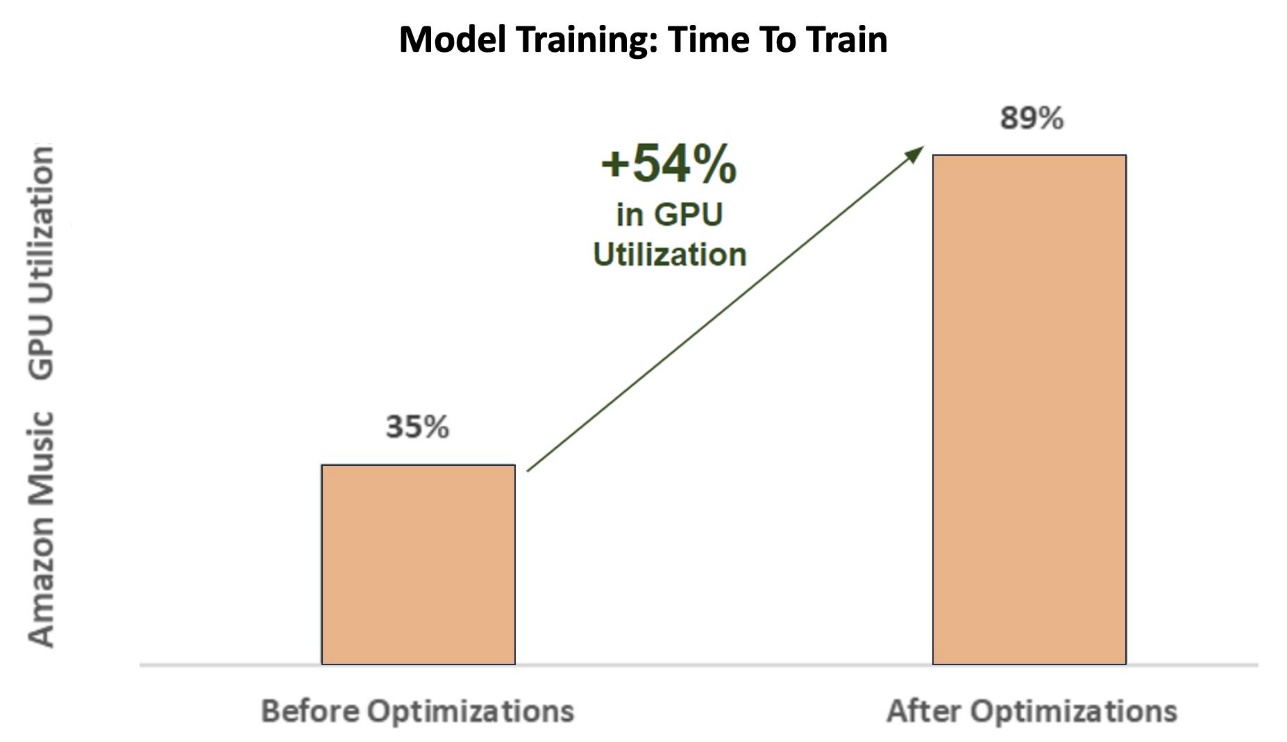
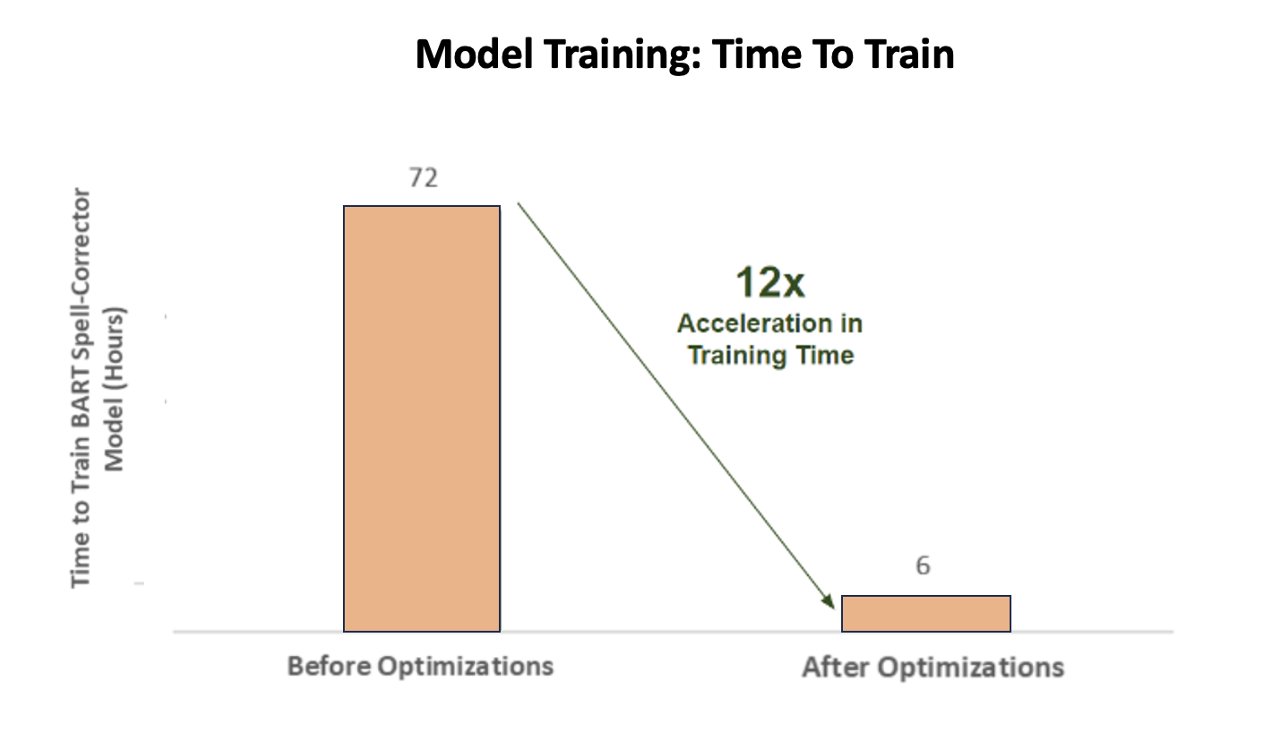
 Siddharth Sharma is a Machine Learning Tech Lead at Science & Modeling team at Amazon Music. He specializes in Search, Retrieval, Ranking and NLP related modeling problems. Siddharth has a rich back-ground working on large scale machine learning problems that are latency sensitive e.g. Ads Targeting, Multi Modal Retrieval, Search Query Understanding etc. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems. Siddharth spent early part of his career working with bay area ad-tech startups.
Siddharth Sharma is a Machine Learning Tech Lead at Science & Modeling team at Amazon Music. He specializes in Search, Retrieval, Ranking and NLP related modeling problems. Siddharth has a rich back-ground working on large scale machine learning problems that are latency sensitive e.g. Ads Targeting, Multi Modal Retrieval, Search Query Understanding etc. Prior to working at Amazon Music, Siddharth was working at companies like Meta, Walmart Labs, Rakuten on E-Commerce centric ML Problems. Siddharth spent early part of his career working with bay area ad-tech startups. Tarun Sharma is a Software Development Manager leading Amazon Music Search Relevance. His team of scientists and ML engineers is responsible for providing contextually relevant and personalized search results to Amazon Music customers.
Tarun Sharma is a Software Development Manager leading Amazon Music Search Relevance. His team of scientists and ML engineers is responsible for providing contextually relevant and personalized search results to Amazon Music customers. Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching.
Kshitiz Gupta is a Solutions Architect at NVIDIA. He enjoys educating cloud customers about the GPU AI technologies NVIDIA has to offer and assisting them with accelerating their machine learning and deep learning applications. Outside of work, he enjoys running, hiking and wildlife watching. Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball.
Jiahong Liu is a Solution Architect on the Cloud Service Provider team at NVIDIA. He assists clients in adopting machine learning and AI solutions that leverage NVIDIA accelerated computing to address their training and inference challenges. In his leisure time, he enjoys origami, DIY projects, and playing basketball. Tugrul Konuk is a Senior Solution Architect at NVIDIA, specializing at large-scale training, multimodal deep learning, and high-performance scientific computing. Prior to NVIDIA, he worked at the energy industry, focusing on developing algorithms for computational imaging. As part of his PhD, he worked on physics-based deep learning for numerical simulations at scale. In his leisure time, he enjoys reading, playing the guitar and the piano.
Tugrul Konuk is a Senior Solution Architect at NVIDIA, specializing at large-scale training, multimodal deep learning, and high-performance scientific computing. Prior to NVIDIA, he worked at the energy industry, focusing on developing algorithms for computational imaging. As part of his PhD, he worked on physics-based deep learning for numerical simulations at scale. In his leisure time, he enjoys reading, playing the guitar and the piano. Rohil Bhargava is a Product Marketing Manager at NVIDIA, focused on deploying NVIDIA application frameworks and SDKs on specific CSP platforms.
Rohil Bhargava is a Product Marketing Manager at NVIDIA, focused on deploying NVIDIA application frameworks and SDKs on specific CSP platforms. Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.
Eliuth Triana Isaza is a Developer Relations Manager at NVIDIA empowering Amazon’s AI MLOps, DevOps, Scientists and AWS technical experts to master the NVIDIA computing stack for accelerating and optimizing Generative AI Foundation models spanning from data curation, GPU training, model inference and production deployment on AWS GPU instances. In addition, Eliuth is a passionate mountain biker, skier, tennis and poker player.









 Brad Duncan is the product manager for machine learning capabilities in the Statistics and Machine Learning Toolbox at MathWorks. He works with customers to apply AI in new areas of engineering such as incorporating virtual sensors in engineered systems, building explainable machine learning models, and standardizing AI workflows using MATLAB and Simulink. Before coming to MathWorks he led teams for 3D simulation and optimization of vehicle aerodynamics, user experience for 3D simulation, and product management for simulation software. Brad is also a guest lecturer at Tufts University in the area of vehicle aerodynamics.
Brad Duncan is the product manager for machine learning capabilities in the Statistics and Machine Learning Toolbox at MathWorks. He works with customers to apply AI in new areas of engineering such as incorporating virtual sensors in engineered systems, building explainable machine learning models, and standardizing AI workflows using MATLAB and Simulink. Before coming to MathWorks he led teams for 3D simulation and optimization of vehicle aerodynamics, user experience for 3D simulation, and product management for simulation software. Brad is also a guest lecturer at Tufts University in the area of vehicle aerodynamics. Richard Alcock is the senior development manager for Cloud Platform Integrations at MathWorks. In this role, he is instrumental in seamlessly integrating MathWorks products into cloud and container platforms. He creates solutions that enable engineers and scientists to harness the full potential of MATLAB and Simulink in cloud-based environments. He was previously a software engineering at MathWorks, developing solutions to support parallel and distributed computing workflows.
Richard Alcock is the senior development manager for Cloud Platform Integrations at MathWorks. In this role, he is instrumental in seamlessly integrating MathWorks products into cloud and container platforms. He creates solutions that enable engineers and scientists to harness the full potential of MATLAB and Simulink in cloud-based environments. He was previously a software engineering at MathWorks, developing solutions to support parallel and distributed computing workflows. Rachel Johnson is the product manager for predictive maintenance at MathWorks, and is responsible for overall product strategy and marketing. She was previously an application engineer directly supporting the aerospace industry on predictive maintenance projects. Prior to MathWorks, Rachel was an aerodynamics and propulsion simulation engineer for the US Navy. She also spent several years teaching math, physics, and engineering.
Rachel Johnson is the product manager for predictive maintenance at MathWorks, and is responsible for overall product strategy and marketing. She was previously an application engineer directly supporting the aerospace industry on predictive maintenance projects. Prior to MathWorks, Rachel was an aerodynamics and propulsion simulation engineer for the US Navy. She also spent several years teaching math, physics, and engineering. Shun Mao is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys fishing, traveling and playing Ping-Pong.
Shun Mao is a Senior AI/ML Partner Solutions Architect in the Emerging Technologies team at Amazon Web Services. He is passionate about working with enterprise customers and partners to design, deploy and scale AI/ML applications to derive their business values. Outside of work, he enjoys fishing, traveling and playing Ping-Pong. Ramesh Jatiya is a Solutions Architect in the Independent Software Vendor (ISV) team at Amazon Web Services. He is passionate about working with ISV customers to design, deploy and scale their applications in cloud to derive their business values. He is also pursuing an MBA in Machine Learning and Business Analytics from Babson College, Boston. Outside of work, he enjoys running, playing tennis and cooking.
Ramesh Jatiya is a Solutions Architect in the Independent Software Vendor (ISV) team at Amazon Web Services. He is passionate about working with ISV customers to design, deploy and scale their applications in cloud to derive their business values. He is also pursuing an MBA in Machine Learning and Business Analytics from Babson College, Boston. Outside of work, he enjoys running, playing tennis and cooking.