Pose estimation is a computer vision technique that detects a set of points on objects (such as people or vehicles) within images or videos. Pose estimation has real-world applications in sports, robotics, security, augmented reality, media and entertainment, medical applications, and more. Pose estimation models are trained on images or videos that are annotated with a consistent set of points (coordinates) defined by a rig. To train accurate pose estimation models, you first need to acquire a large dataset of annotated images; many datasets have tens or hundreds of thousands of annotated images and take significant resources to build. Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled data quality and data volume.
In this post, we show how you can use a custom labeling workflow in Amazon SageMaker Ground Truth specifically designed for keypoint labeling. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
Importance of high-quality data and reducing labeling errors
High-quality data is fundamental for training robust and reliable pose estimation models. The accuracy of these models is directly tied to the correctness and precision of the labels assigned to each pose keypoint, which, in turn, depends on the effectiveness of the annotation process. Additionally, having a substantial volume of diverse and well-annotated data ensures that the model can learn a broad range of poses, variations, and scenarios, leading to improved generalization and performance across different real-world applications. The acquisition of these large, annotated datasets involves human annotators who carefully label images with pose information. While labeling points of interest within the image, it’s useful to see the skeletal structure of the object while labeling in order to provide visual guidance to the annotator. This is helpful for identifying labeling errors before they are incorporated into the dataset like left-right swaps or mislabels (such as marking a foot as a shoulder). For example, a labeling error like the left-right swap made in the following example can easily be identified by the crossing of the skeleton rig lines and the mismatching of the colors. These visual cues help labelers recognize mistakes and will result in a cleaner set of labels.
Due to the manual nature of labeling, obtaining large and accurate labeled datasets can be cost-prohibitive and even more so with an inefficient labeling system. Therefore, labeling efficiency and accuracy are critical when designing your labeling workflow. In this post, we demonstrate how to use a custom SageMaker Ground Truth labeling workflow to quickly and accurately annotate images, reducing the burden of developing large datasets for pose estimation workflows.

Overview of solution
This solution provides an online web portal where the labeling workforce can use a web browser to log in, access labeling jobs, and annotate images using the crowd-2d-skeleton user interface (UI), a custom UI designed for keypoint and pose labeling using SageMaker Ground Truth. The annotations or labels created by the labeling workforce are then exported to an Amazon Simple Storage Service (Amazon S3) bucket, where they can be used for downstream processes like training deep learning computer vision models. This solution walks you through how to set up and deploy the necessary components to create a web portal as well as how to create labeling jobs for this labeling workflow.
The following is a diagram of the overall architecture.

This architecture is comprised of several key components, each of which we explain in more detail in the following sections. This architecture provides the labeling workforce with an online web portal hosted by SageMaker Ground Truth. This portal allows each labeler to log in and see their labeling jobs. After they’ve logged in, the labeler can select a labeling job and begin annotating images using the custom UI hosted by Amazon CloudFront. We use AWS Lambda functions for pre-annotation and post-annotation data processing.
The following screenshot is an example of the UI.

The labeler can mark specific keypoints on the image using the UI. The lines between keypoints will be automatically drawn for the user based on a skeleton rig definition that the UI uses. The UI allows many customizations, such as the following:
- Custom keypoint names
- Configurable keypoint colors
- Configurable rig line colors
- Configurable skeleton and rig structures
Each of these are targeted features to improve the ease and flexibility of labeling. Specific UI customization details can be found in the GitHub repo and are summarized later in this post. Note that in this post, we use human pose estimation as a baseline task, but you can expand it to labeling object pose with a pre-defined rig for other objects as well, such as animals or vehicles. In the following example, we show how this can be applied to label the points of a box truck.

SageMaker Ground Truth
In this solution, we use SageMaker Ground Truth to provide the labeling workforce with an online portal and a way to manage labeling jobs. This post assumes that you’re familiar with SageMaker Ground Truth. For more information, refer to Amazon SageMaker Ground Truth.
CloudFront distribution
For this solution, the labeling UI requires a custom-built JavaScript component called the crowd-2d-skeleton component. This component can be found on GitHub as part of Amazon’s open source initiatives. The CloudFront distribution will be used to host the crowd-2d-skeleton.js, which is needed by the SageMaker Ground Truth UI. The CloudFront distribution will be assigned an origin access identity, which will allow the CloudFront distribution to access the crowd-2d-skeleton.js residing in the S3 bucket. The S3 bucket will remain private and no other objects in this bucket will be available via the CloudFront distribution due to restrictions we place on the origin access identity through a bucket policy. This is a recommended practice for following the least-privilege principle.
Amazon S3 bucket
We use the S3 bucket to store the SageMaker Ground Truth input and output manifest files, the custom UI template, images for the labeling jobs, and the JavaScript code needed for the custom UI. This bucket will be private and not accessible to the public. The bucket will also have a bucket policy that restricts the CloudFront distribution to only being able to access the JavaScript code needed for the UI. This prevents the CloudFront distribution from hosting any other object in the S3 bucket.
Pre-annotation Lambda function
SageMaker Ground Truth labeling jobs typically use an input manifest file, which is in JSON Lines format. This input manifest file contains metadata for a labeling job, acts as a reference to the data that needs to be labeled, and helps configure how the data should be presented to the annotators. The pre-annotation Lambda function processes items from the input manifest file before the manifest data is input to the custom UI template. This is where any formatting or special modifications to the items can be done before presenting the data to the annotators in the UI. For more information on pre-annotation Lambda functions, see Pre-annotation Lambda.
Post-annotation Lambda function
Similar to the pre-annotation Lambda function, the post-annotation function handles additional data processing you may want to do after all the labelers have finished labeling but before writing the final annotation output results. This processing is done by a Lambda function, which is responsible for formatting the data for the labeling job output results. In this solution, we are simply using it to return the data in our desired output format. For more information on post-annotation Lambda functions, see Post-annotation Lambda.
Post-annotation Lambda function role
We use an AWS Identity and Access Management (IAM) role to give the post-annotation Lambda function access to the S3 bucket. This is needed to read the annotation results and make any modifications before writing out the final results to the output manifest file.
SageMaker Ground Truth role
We use this IAM role to give the SageMaker Ground Truth labeling job the ability to invoke the Lambda functions and to read the images, manifest files, and custom UI template in the S3 bucket.
Prerequisites
For this walkthrough, you should have the following prerequisites:
For this solution, we use the AWS CDK to deploy the architecture. Then we create a sample labeling job, use the annotation portal to label the images in the labeling job, and examine the labeling results.
Create the AWS CDK stack
After you complete all the prerequisites, you’re ready to deploy the solution.
Set up your resources
Complete the following steps to set up your resources:
- Download the example stack from the GitHub repo.
- Use the cd command to change into the repository.
- Create your Python environment and install required packages (see the repository README.md for more details).
- With your Python environment activated, run the following command:
- Run the following command to deploy the AWS CDK:
- Run the following command to run the post-deployment script:
python scripts/post_deployment_script.py
Create a labeling job
After you have set up your resources, you’re ready to create a labeling job. For the purposes of this post, we create a labeling job using the example scripts and images provided in the repository.
- CD into the
scripts directory in the repository.
- Download the example images from the internet by running the following code:
python scripts/download_example_images.py
This script downloads a set of 10 images, which we use in our example labeling job. We review how to use your own custom input data later in this post.
- Create a labeling job by running to following code:
python scripts/create_example_labeling_job.py <Labeling Workforce ARN>
This script takes a SageMaker Ground Truth private workforce ARN as an argument, which should be the ARN for a workforce you have in the same account you deployed this architecture into. The script will create the input manifest file for our labeling job, upload it to Amazon S3, and create a SageMaker Ground Truth custom labeling job. We take a deeper dive into the details of this script later in this post.
Label the dataset
After you have launched the example labeling job, it will appear on the SageMaker console as well as the workforce portal.

In the workforce portal, select the labeling job and choose Start working.

You’ll be presented with an image from the example dataset. At this point, you can use the custom crowd-2d-skeleton UI to annotate the images. You can familiarize yourself with the crowd-2d-skeleton UI by referring to User Interface Overview. We use the rig definition from the COCO keypoint detection dataset challenge as the human pose rig. To reiterate, you can customize this without our custom UI component to remove or add points based on your requirements.
When you’re finished annotating an image, choose Submit. This will take you to the next image in the dataset until all images are labeled.

Access the labeling results
When you have finished labeling all the images in the labeling job, SageMaker Ground Truth will invoke the post-annotation Lambda function and produce an output.manifest file containing all of the annotations. This output.manifest will be stored in the S3 bucket. In our case, the location of the output manifest should follow the S3 URI path s3://<bucket name> /labeling_jobs/output/<labeling job name>/manifests/output/output.manifest. The output.manifest file is a JSON Lines file, where each line corresponds to a single image and its annotations from the labeling workforce. Each JSON Lines item is a JSON object with many fields. The field we are interested in is called label-results. The value of this field is an object containing the following fields:
- dataset_object_id – The ID or index of the input manifest item
- data_object_s3_uri – The image’s Amazon S3 URI
- image_file_name – The image’s file name
- image_s3_location – The image’s Amazon S3 URL
- original_annotations – The original annotations (only set and used if you are using a pre-annotation workflow)
- updated_annotations – The annotations for the image
- worker_id – The workforce worker who made the annotations
- no_changes_needed – Whether the no changes needed check box was selected
- was_modified – Whether the annotation data differs from the original input data
- total_time_in_seconds – The time it took the workforce worker to annotation the image
With these fields, you can access your annotation results for each image and do calculations like average time to label an image.
Create your own labeling jobs
Now that we have created an example labeling job and you understand the overall process, we walk you through the code responsible for creating the manifest file and launching the labeling job. We focus on the key parts of the script that you may want to modify to launch your own labeling jobs.
We cover snippets of code from the create_example_labeling_job.py script located in the GitHub repository. The script starts by setting up variables that are used later in the script. Some of the variables are hard-coded for simplicity, whereas others, which are stack dependent, will be imported dynamically at runtime by fetching the values created from our AWS CDK stack.
# Setup/get variables values from our CDK stack
s3_upload_prefix = "labeling_jobs"
image_dir = 'scripts/images'
manifest_file_name = "example_manifest.txt"
s3_bucket_name = read_ssm_parameter('/crowd_2d_skeleton_example_stack/bucket_name')
pre_annotation_lambda_arn = read_ssm_parameter('/crowd_2d_skeleton_example_stack/pre_annotation_lambda_arn')
post_annotation_lambda_arn = read_ssm_parameter('/crowd_2d_skeleton_example_stack/post_annotation_lambda_arn')
ground_truth_role_arn = read_ssm_parameter('/crowd_2d_skeleton_example_stack/sagemaker_ground_truth_role')
ui_template_s3_uri = f"s3://{s3_bucket_name}/infrastructure/ground_truth_templates/crowd_2d_skeleton_template.html"
s3_image_upload_prefix = f'{s3_upload_prefix}/images'
s3_manifest_upload_prefix = f'{s3_upload_prefix}/manifests'
s3_output_prefix = f'{s3_upload_prefix}/output'
The first key section in this script is the creation of the manifest file. Recall that the manifest file is a JSON lines file that contains the details for a SageMaker Ground Truth labeling job. Each JSON Lines object represents one item (for example, an image) that needs to be labeled. For this workflow, the object should contain the following fields:
- source-ref – The Amazon S3 URI to the image you wish to label.
- annotations – A list of annotation objects, which is used for pre-annotating workflows. See the crowd-2d-skeleton documentation for more details on the expected values.
The script creates a manifest line for each image in the image directory using the following section of code:
# For each image in the image directory lets create a manifest line
manifest_items = []
for filename in os.listdir(image_dir):
if filename.endswith('.jpg') or filename.endswith('.png'):
img_path = os.path.join(
image_dir,
filename
)
object_name = os.path.join(
s3_image_upload_prefix,
filename
).replace("\", "/")
# upload to s3_bucket
s3_client.upload_file(img_path, s3_bucket_name, object_name)
f
# add it to manifest file
manifest_items.append({
"source-ref": f's3://{s3_bucket_name}/{object_name}',
"annotations": [],
})
If you want to use different images or point to a different image directory, you can modify that section of the code. Additionally, if you’re using a pre-annotation workflow, you can update the annotations array with a JSON string consisting of the array and all its annotation objects. The details of the format of this array are documented in the crowd-2d-skeleton documentation.
With the manifest line items now created, you can create and upload the manifest file to the S3 bucket you created earlier:
# Create Manifest file
manifest_file_contents = "n".join([json.dumps(mi) for mi in manifest_items])
with open(manifest_file_name, "w") as file_handle:
file_handle.write(manifest_file_contents)
# Upload manifest file
object_name = os.path.join(
s3_manifest_upload_prefix,
manifest_file_name
).replace("\", "/")
s3_client.upload_file(manifest_file_name, s3_bucket_name, object_name)
Now that you have created a manifest file containing the images you want to label, you can create a labeling job. You can create the labeling job programmatically using the AWS SDK for Python (Boto3). The code to create a labeling job is as follows:
# Create labeling job
client = boto3.client("sagemaker")
now = int(round(datetime.now().timestamp()))
response = client.create_labeling_job(
LabelingJobName=f"crowd-2d-skeleton-example-{now}",
LabelAttributeName="label-results",
InputConfig={
"DataSource": {
"S3DataSource": {"ManifestS3Uri": f's3://{s3_bucket_name}/{object_name}'},
},
"DataAttributes": {},
},
OutputConfig={
"S3OutputPath": f"s3://{s3_bucket_name}/{s3_output_prefix}/",
},
RoleArn=ground_truth_role_arn,
HumanTaskConfig={
"WorkteamArn": workteam_arn,
"UiConfig": {"UiTemplateS3Uri": ui_template_s3_uri},
"PreHumanTaskLambdaArn": pre_annotation_lambda_arn,
"TaskKeywords": ["example"],
"TaskTitle": f"Crowd 2D Component Example {now}",
"TaskDescription": "Crowd 2D Component Example",
"NumberOfHumanWorkersPerDataObject": 1,
"TaskTimeLimitInSeconds": 28800,
"TaskAvailabilityLifetimeInSeconds": 2592000,
"MaxConcurrentTaskCount": 123,
"AnnotationConsolidationConfig": {
"AnnotationConsolidationLambdaArn": post_annotation_lambda_arn
},
},
)
print(response)
The aspects of this code you may want to modify are LabelingJobName, TaskTitle, and TaskDescription. The LabelingJobName is the unique name of the labeling job that SageMaker will use to reference your job. This is also the name that will appear on the SageMaker console. TaskTitle serves a similar purpose, but doesn’t need to be unique and will be the name of the job that appears in the workforce portal. You may want to make these more specific to what you are labeling or what the labeling job is for. Lastly, we have the TaskDescription field. This field appears in the workforce portal to provide extra context to the labelers as to what the task is, such as instructions and guidance for the task. For more information on these fields as well as the others, refer to the create_labeling_job documentation.
Make adjustments to the UI
In this section, we go over some of the ways you can customize the UI. The following is a list of the most common potential customizations to the UI in order to adjust it to your modeling task:
- You can define which keypoints can be labeled. This includes the name of the keypoint and its color.
- You can change the structure of the skeleton (which keypoints are connected).
- You can change the line colors for specific lines between specific keypoints.
All of these UI customizations are configurable through arguments passed into the crowd-2d-skeleton component, which is the JavaScript component used in this custom workflow template. In this template, you will find the usage of the crowd-2d-skeleton component. A simplified version is shown in the following code:
<crowd-2d-skeleton
imgSrc="{{ task.input.image_s3_uri | grant_read_access }}"
keypointClasses='<keypoint classes>'
skeletonRig='<skeleton rig definition>'
skeletonBoundingBox='<skeleton bounding box size>'
initialValues="{{ task.input.initial_values }}"
>
In the preceding code example, you can see the following attributes on the component: imgSrc, keypointClasses, skeletonRig, skeletonBoundingBox, and intialValues. We describe each attribute’s purpose in the following sections, but customizing the UI is as straightforward as changing the values for these attributes, saving the template, and rerunning the post_deployment_script.py we used previously.
imgSrc attribute
The imgSrc attribute controls which image to show in the UI when labeling. Usually, a different image is used for each manifest line item, so this attribute is often populated dynamically using the built-in Liquid templating language. You can see in the previous code example that the attribute value is set to {{ task.input.image_s3_uri | grant_read_access }}, which is Liquid template variable that will be replaced with the actual image_s3_uri value when the template is being rendered. The rendering process starts when the user opens an image for annotation. This process grabs a line item from the input manifest file and sends it to the pre-annotation Lambda function as an event.dataObject. The pre-annotation function takes take the information it needs from the line item and returns a taskInput dictionary, which is then passed to the Liquid rendering engine, which will replace any Liquid variables in your template. For example, let’s say you have a manifest file with the following line:
{"source-ref": "s3://my-bucket/exmaple.jpg", "annotations": []}
This data would be passed to the pre-annotation function. The following code shows how the function extracts the values from the event object:
def lambda_handler(event, context):
print("Pre-Annotation Lambda Triggered")
data_object = event["dataObject"] # this comes directly from the manifest file
annotations = data_object["annotations"]
taskInput = {
"image_s3_uri": data_object["source-ref"],
"initial_values": json.dumps(annotations)
}
return {"taskInput": taskInput, "humanAnnotationRequired": "true"}
The object returned from the function in this case would look like the following code:
{
"taskInput": {
"image_s3_uri": "s3://my-bucket/exmaple.jpg",
"annotations": "[]"
},
"humanAnnotationRequired": "true"
}
The returned data from the function is then available to the Liquid template engine, which replaces the template values in the template with the data values returned by the function. The result would be something like the following code:
<crowd-2d-skeleton
imgSrc="s3://my-bucket/exmaple.jpg" <-- This was “injected” into template
keypointClasses='<keypoint classes>'
skeletonRig='<skeleton rig definition>'
skeletonBoundingBox='<skeleton bounding box size>'
initialValues="[]"
>
keypointClasses attribute
The keypointClasses attribute defines which keypoints will appear in the UI and be used by the annotators. This attribute takes a JSON string containing a list of objects. Each object represents a keypoint. Each keypoint object should contain the following fields:
- id – A unique value to identify that keypoint.
- color – The color of the keypoint represented as an HTML hex color.
- label – The name or keypoint class.
- x – This optional attribute is only needed if you want to use the draw skeleton functionality in the UI. The value for this attribute is the x position of the keypoint relative to the skeleton’s bounding box. This value is usually obtained by the Skeleton Rig Creator tool. If you are doing keypoint annotations and don’t need to draw an entire skeleton at once, you can set this value to 0.
- y – This optional attribute is similar to x, but for the vertical dimension.
For more information on the keypointClasses attribute, see the keypointClasses documentation.
skeletonRig attribute
The skeletonRig attribute controls which keypoints should have lines drawn between them. This attribute takes a JSON string containing a list of keypoint label pairs. Each pair informs the UI which keypoints to draw lines between. For example, '[["left_ankle","left_knee"],["left_knee","left_hip"]]' informs the UI to draw lines between "left_ankle" and "left_knee" and draw lines between "left_knee" and "left_hip". This can be generated by the Skeleton Rig Creator tool.
skeletonBoundingBox attribute
The skeletonBoundingBox attribute is optional and only needed if you want to use the draw skeleton functionality in the UI. The draw skeleton functionality is the ability to annotate entire skeletons with a single annotation action. We don’t cover this feature in this post. The value for this attribute is the skeleton’s bounding box dimensions. This value is usually obtained by the Skeleton Rig Creator tool. If you are doing keypoint annotations and don’t need to draw an entire skeleton at once, you can set this value to null. It is recommended to use the Skeleton Rig Creator tool to get this value.
intialValues attribute
The initialValues attribute is used to pre-populate the UI with annotations obtained from another process (such as another labeling job or machine learning model). This is useful when doing adjustment or review jobs. The data for this field is usually populated dynamically in the same description for the imgSrc attribute. More details can be found in the crowd-2d-skeleton documentation.
Clean up
To avoid incurring future charges, you should delete the objects in your S3 bucket and delete your AWS CDK stack. You can delete your S3 objects via the Amazon SageMaker console or the AWS Command Line Interface (AWS CLI). After you have deleted all of the S3 objects in the bucket, you can destroy the AWS CDK by running the following code:
This will remove the resources you created earlier.
Considerations
Additional steps maybe needed to productionize your workflow. Here are some considerations depending on your organizations risk profile:
- Adding access and application logging
- Adding a web application firewall (WAF)
- Adjusting IAM permissions to follow least privilege
Conclusion
In this post, we shared the importance of labeling efficiency and accuracy in building pose estimation datasets. To help with both items, we showed how you can use SageMaker Ground Truth to build custom labeling workflows to support skeleton-based pose labeling tasks, aiming to enhance efficiency and precision during the labeling process. We showed how you can further extend the code and examples to various custom pose estimation labeling requirements.
We encourage you to use this solution for your labeling tasks and to engage with AWS for assistance or inquiries related to custom labeling workflows.
About the Authors
 Arthur Putnam is a Full-Stack Data Scientist in AWS Professional Services. Arthur’s expertise is centered around developing and integrating front-end and back-end technologies into AI systems. Outside of work, Arthur enjoys exploring the latest advancements in technology, spending time with his family, and enjoying the outdoors.
Arthur Putnam is a Full-Stack Data Scientist in AWS Professional Services. Arthur’s expertise is centered around developing and integrating front-end and back-end technologies into AI systems. Outside of work, Arthur enjoys exploring the latest advancements in technology, spending time with his family, and enjoying the outdoors.
 Ben Fenker is a Senior Data Scientist in AWS Professional Services and has helped customers build and deploy ML solutions in industries ranging from sports to healthcare to manufacturing. He has a Ph.D. in physics from Texas A&M University and 6 years of industry experience. Ben enjoys baseball, reading, and raising his kids.
Ben Fenker is a Senior Data Scientist in AWS Professional Services and has helped customers build and deploy ML solutions in industries ranging from sports to healthcare to manufacturing. He has a Ph.D. in physics from Texas A&M University and 6 years of industry experience. Ben enjoys baseball, reading, and raising his kids.
 Jarvis Lee is a Senior Data Scientist with AWS Professional Services. He has been with AWS for over six years, working with customers on machine learning and computer vision problems. Outside of work, he enjoys riding bicycles.
Jarvis Lee is a Senior Data Scientist with AWS Professional Services. He has been with AWS for over six years, working with customers on machine learning and computer vision problems. Outside of work, he enjoys riding bicycles.
Read More


 Google shares more on how it’s partnering with industry, governments and civil society to advance AI.
Google shares more on how it’s partnering with industry, governments and civil society to advance AI.










 Hamza Nadeem is an Amazon Connect Specialist Solutions Architect at AWS, based in Toronto. He works with customers throughout Canada to modernize their Contact Centers and provide solutions to their unique customer engagement challenges and business requirements. In his spare time, Hamza enjoys traveling, soccer and trying new recipes with his wife.
Hamza Nadeem is an Amazon Connect Specialist Solutions Architect at AWS, based in Toronto. He works with customers throughout Canada to modernize their Contact Centers and provide solutions to their unique customer engagement challenges and business requirements. In his spare time, Hamza enjoys traveling, soccer and trying new recipes with his wife. Parag Srivastava is a Solutions Architect at Amazon Web Services (AWS), helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Solutions Architect at Amazon Web Services (AWS), helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses. Ross Alas is a Solutions Architect at AWS based in Toronto, Canada. He helps customers innovate with AI/ML and Generative AI solutions that leads to real business outcomes. He has worked with a variety of customers from retail, financial services, technology, pharmaceutical, and others. In his spare time, he loves the outdoors and enjoying nature with his family.
Ross Alas is a Solutions Architect at AWS based in Toronto, Canada. He helps customers innovate with AI/ML and Generative AI solutions that leads to real business outcomes. He has worked with a variety of customers from retail, financial services, technology, pharmaceutical, and others. In his spare time, he loves the outdoors and enjoying nature with his family. Sangeetha Kamatkar is a Solutions Architect at Amazon Web Services (AWS), helping customers with successful cloud adoption and migration. She works with customers to craft highly scalable, flexible, and resilient cloud architectures that address customer business problems. In her spare time, she listens to music, watch movies and enjoy gardening during summer time.
Sangeetha Kamatkar is a Solutions Architect at Amazon Web Services (AWS), helping customers with successful cloud adoption and migration. She works with customers to craft highly scalable, flexible, and resilient cloud architectures that address customer business problems. In her spare time, she listens to music, watch movies and enjoy gardening during summer time.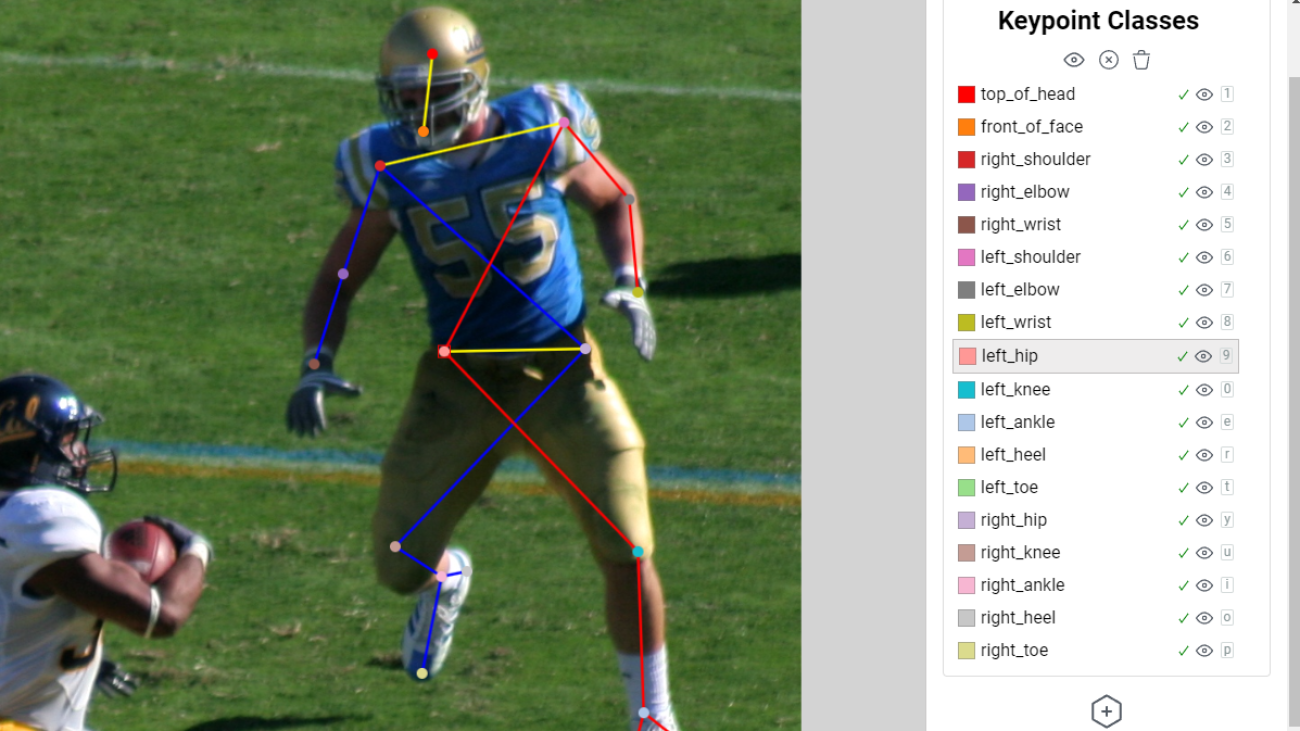









 Ravikiran Rao is a Data Architect at AWS and is passionate about solving complex data challenges for various customers. Outside of work, he is a theatre enthusiast and an amateur tennis player.
Ravikiran Rao is a Data Architect at AWS and is passionate about solving complex data challenges for various customers. Outside of work, he is a theatre enthusiast and an amateur tennis player. Jigna Gandhi is a Sr. Solutions Architect at Amazon Web Services, based in the Greater New York City area. She has over 15 years of strong experience in leading several complex, highly robust, and massively scalable software solutions for large-scale enterprise applications.
Jigna Gandhi is a Sr. Solutions Architect at Amazon Web Services, based in the Greater New York City area. She has over 15 years of strong experience in leading several complex, highly robust, and massively scalable software solutions for large-scale enterprise applications. Jason Pedreza is a Senior Redshift Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com and Amazon Devices. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is a Senior Redshift Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com and Amazon Devices. He specializes in Amazon Redshift and helps customers build scalable analytic solutions. Roopali Mahajan is a Senior Solutions Architect with AWS based out of New York. She thrives on serving as a trusted advisor for her customers, helping them navigate their journey on cloud. Her day is spent solving complex business problems by designing effective solutions using AWS services. During off-hours, she loves to spend time with her family and travel.
Roopali Mahajan is a Senior Solutions Architect with AWS based out of New York. She thrives on serving as a trusted advisor for her customers, helping them navigate their journey on cloud. Her day is spent solving complex business problems by designing effective solutions using AWS services. During off-hours, she loves to spend time with her family and travel.