As part of our multi-year collaboration with Liverpool FC, we develop a full AI system that can advise coaches on corner kicksRead More
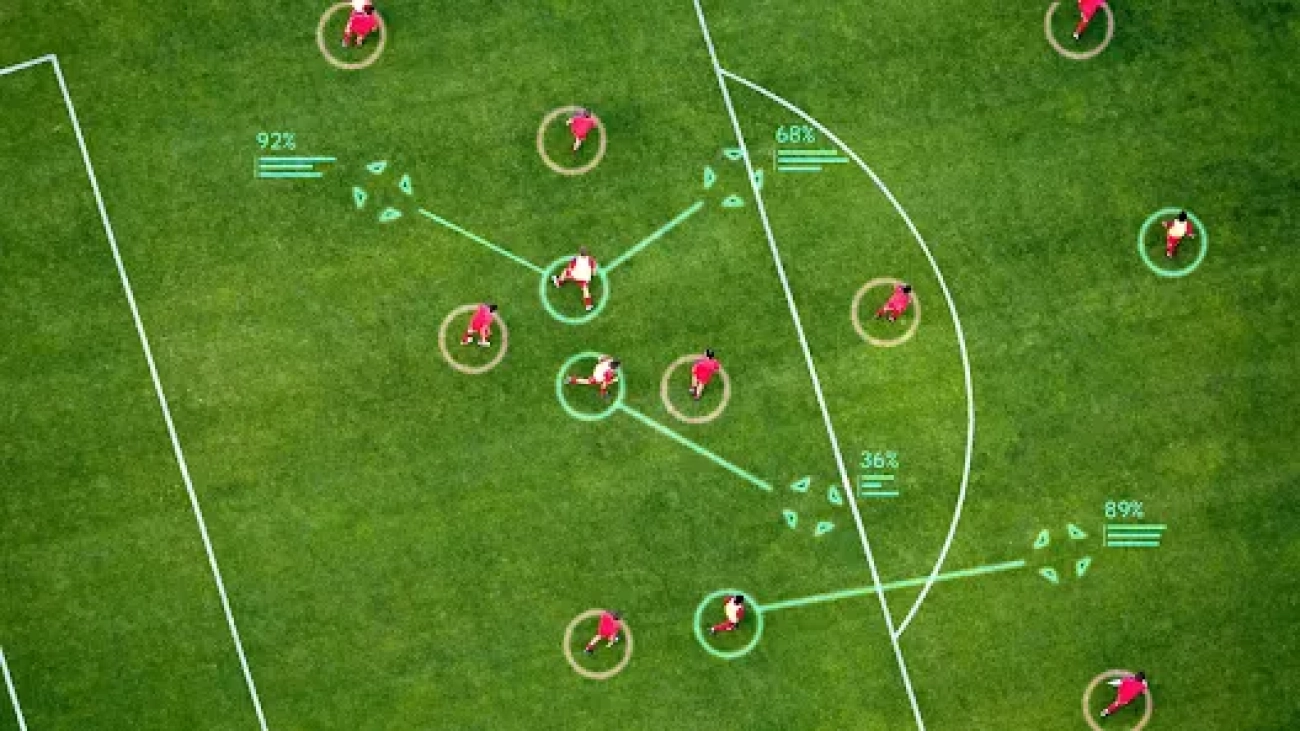
As part of our multi-year collaboration with Liverpool FC, we develop a full AI system that can advise coaches on corner kicksRead More
As part of our multi-year collaboration with Liverpool FC, we develop a full AI system that can advise coaches on corner kicksRead More
As part of our multi-year collaboration with Liverpool FC, we develop a full AI system that can advise coaches on corner kicksRead More
As part of our multi-year collaboration with Liverpool FC, we develop a full AI system that can advise coaches on corner kicksRead More

To help mitigate climate change — one of humanity’s greatest challenges — researchers are turning to AI and sustainable computing to accelerate and operationalize their work.
At this week’s NVIDIA GTC global AI conference, startups, enterprises and scientists are highlighting their environmental sustainability initiatives and latest climate innovations. Many are using NVIDIA Earth-2, a full-stack, open platform for accelerating climate and weather simulation and predictions.
Earth-2 comprises GPU-accelerated numerical weather and climate prediction models, including ICON and IFS; state-of-the-art AI-driven weather models, such as FourCastNet, GraphCast and Deep Learning Weather Prediction, offered through the NVIDIA Modulus framework; and large-scale, interactive, high-resolution data visualization and simulation enabled by the NVIDIA Omniverse platform. These capabilities are also available via cloud APIs, or application programming interfaces.
Various members of NVIDIA Inception — a free, global program for cutting-edge startups — are pioneering climate AI advancements with Earth-2. It’s critical work, as extreme-weather events are expected to take a million lives and cost $1.7 trillion per year by 2050.

Boston-based Tomorrow.io provides actionable, weather-related insights to countries, businesses and individuals by applying advanced AI and machine learning models to a proprietary global dataset collected from satellites, radar and other sensors. Its weather intelligence and climate adaptation platform delivers high-resolution, accurate weather forecasts across time zones for both short- and long-term projections.
The startup is using Earth-2 to study the potential impacts of its suite of satellites on global model forecasts. By conducting observing-system simulation experiments, or OSSEs, with Earth-2 AI forecast models, Tomorrow.io can identify the optimal configurations of satellites and other instruments to improve weather-forecasting conditions. The work ultimately aims to offer users precision and simplicity, helping them easily understand complex weather situations and make the right operational decisions at the right time.
Learn more about Tomorrow.io’s work with Earth-2 by joining the GTC session, “Global Strategies: Startups, Venture Capital, and Climate Change Solutions,” taking place today, March 19, at 3 p.m. PT, at the San Jose Convention Center and online.
ClimaSens, based in Melbourne, Australia, and New York, fuses historical, real-time and future climate and weather information using advanced AI models. FloodSens, its upcoming flood risk analysis model, informs clients about the probability of flooding from rainfall, offering high-resolution assessments of flash flooding, riverine flooding and all types of flooding in between.
FloodSens, now in beta, was developed using Earth-2 APIs and the FourCastNet model for high-fidelity, physically accurate representations of future weather conditions, as well as an ensemble of other models for assessing the probabilities of low-likelihood, high-impact flooding events. Through this work, the startup aims to enable a more resilient, sustainable future for communities worldwide.
 Based in Kiel, Germany, north.io is helping to map the Earth’s largest carbon sink: oceans. Only about 25% of the ocean floor — a critical source of the world’s renewable energy and food security — has been mapped so far.
Based in Kiel, Germany, north.io is helping to map the Earth’s largest carbon sink: oceans. Only about 25% of the ocean floor — a critical source of the world’s renewable energy and food security — has been mapped so far.
North.io is collecting and analyzing massive amounts of data from autonomous underwater vehicles (AUVs) and making it accessible, shareable, visualizable and understandable for users across the globe through its TrueOcean platform.
Using Earth-2 APIs, north.io is developing AI weather forecasts for intelligent operational planning, system management and risk assessment for its AUVs. The combination of high-precision weather modeling and the use of autonomous systems drastically reduces human safety risks in rough, offshore environments.
Learn more about the latest AI, high performance computing and sustainable computing advancements for climate research at GTC, running through Thursday, March 21.
In the evolving landscape of manufacturing, the transformative power of AI and machine learning (ML) is evident, driving a digital revolution that streamlines operations and boosts productivity. However, this progress introduces unique challenges for enterprises navigating data-driven solutions. Industrial facilities grapple with vast volumes of unstructured data, sourced from sensors, telemetry systems, and equipment dispersed across production lines. Real-time data is critical for applications like predictive maintenance and anomaly detection, yet developing custom ML models for each industrial use case with such time series data demands considerable time and resources from data scientists, hindering widespread adoption.
Generative AI using large pre-trained foundation models (FMs) such as Claude can rapidly generate a variety of content from conversational text to computer code based on simple text prompts, known as zero-shot prompting. This eliminates the need for data scientists to manually develop specific ML models for each use case, and therefore democratizes AI access, benefitting even small manufacturers. Workers gain productivity through AI-generated insights, engineers can proactively detect anomalies, supply chain managers optimize inventories, and plant leadership makes informed, data-driven decisions.
Nevertheless, standalone FMs face limitations in handling complex industrial data with context size constraints (typically less than 200,000 tokens), which poses challenges. To address this, you can use the FM’s ability to generate code in response to natural language queries (NLQs). Agents like PandasAI come into play, running this code on high-resolution time series data and handling errors using FMs. PandasAI is a Python library that adds generative AI capabilities to pandas, the popular data analysis and manipulation tool.
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt.
To enhance code generation accuracy, we propose dynamically constructing multi-shot prompts for NLQs. Multi-shot prompting provides additional context to the FM by showing it several examples of desired outputs for similar prompts, boosting accuracy and consistency. In this post, multi-shot prompts are retrieved from an embedding containing successful Python code run on a similar data type (for example, high-resolution time series data from Internet of Things devices). The dynamically constructed multi-shot prompt provides the most relevant context to the FM, and boosts the FM’s capability in advanced math calculation, time series data processing, and data acronym understanding. This improved response facilitates enterprise workers and operational teams in engaging with data, deriving insights without requiring extensive data science skills.
Beyond time series data analysis, FMs prove valuable in various industrial applications. Maintenance teams assess asset health, capture images for Amazon Rekognition-based functionality summaries, and anomaly root cause analysis using intelligent searches with Retrieval Augmented Generation (RAG). To simplify these workflows, AWS has introduced Amazon Bedrock, enabling you to build and scale generative AI applications with state-of-the-art pre-trained FMs like Claude v2. With Knowledge Bases for Amazon Bedrock, you can simplify the RAG development process to provide more accurate anomaly root cause analysis for plant workers. Our post showcases an intelligent assistant for industrial use cases powered by Amazon Bedrock, addressing NLQ challenges, generating part summaries from images, and enhancing FM responses for equipment diagnosis through the RAG approach.
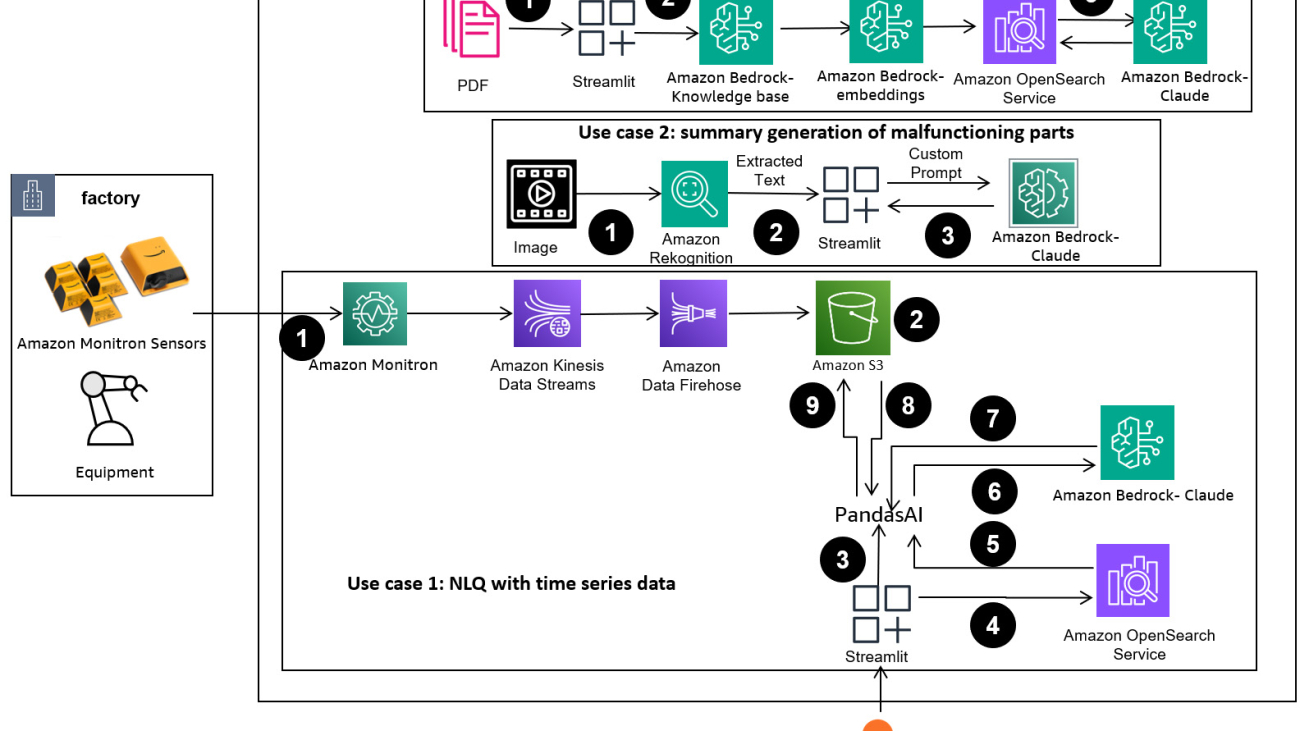
The following diagram illustrates the solution architecture.

The workflow includes three distinct use cases:
The workflow for NLQ with time series data consists of the following steps:
Our summary generation use case consists of the following steps:
Our root cause diagnosis use case consists of the following steps:
To follow along with this post, you should meet the following prerequisites:
To set up your solution resources, complete the following steps:
genai-sagemaker.
Next, you create the knowledge base for the documents in Amazon S3.

 The Titan embeddings model is automatically selected.
The Titan embeddings model is automatically selected.


The next step is to deploy the app with the required library packages on either your PC or an EC2 instance (Ubuntu Server 22.04 LTS).
unlocking-the-potential-of-generative-ai-in-industrial-operations/src and run the setup.sh script in this folder to install the required packages, including LangChain and PandasAI:
cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src
chmod +x ./setup.sh
./setup.sh source monitron-genai/bin/activate
python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Provide the OpenSearch Service collection ARN you created in Amazon Bedrock from the previous step.
After you complete the end-to-end deployment, you can access the app via localhost on port 8501, which opens a browser window with the web interface. If you deployed the app on an EC2 instance, allow port 8501 access via the security group inbound rule. You can navigate to different tabs for various use cases.
To explore the first use case, choose Data Insight and Chart. Begin by uploading your time series data. If you don’t have an existing time series data file to use, you can upload the following sample CSV file with anonymous Amazon Monitron project data. If you already have an Amazon Monitron project, refer to Generate actionable insights for predictive maintenance management with Amazon Monitron and Amazon Kinesis to stream your Amazon Monitron data to Amazon S3 and use your data with this application.
When the upload is complete, enter a query to initiate a conversation with your data. The left sidebar offers a range of example questions for your convenience. The following screenshots illustrate the response and Python code generated by the FM when inputting a question such as “Tell me the unique number of sensors for each site shown as Warning or Alarm respectively?” (a hard-level question) or “For sensors shown temperature signal as NOT Healthy, can you calculate the time duration in days for each sensor shown abnormal vibration signal?” (a challenge-level question). The app will answer your question, and will also show the Python script of data analysis it performed to generate such results.


If you’re satisfied with the answer, you can mark it as Helpful, saving the NLQ and Claude-generated Python code to an OpenSearch Service index.

To explore the second use case, choose the Captured Image Summary tab in the Streamlit app. You can upload an image of your industrial asset, and the application will generate a 200-word summary of its technical specification and operation condition based on the image information. The following screenshot shows the summary generated from an image of a belt motor drive. To test this feature, if you lack a suitable image, you can use the following example image.

Hydraulic elevator motor label” by Clarence Risher is licensed under CC BY-SA 2.0.

To explore the third use case, choose the Root cause diagnosis tab. Input a query related to your broken industrial asset, such as, “My actuator travels slow, what might be the issue?” As depicted in the following screenshot, the application delivers a response with the source document excerpt used to generate the answer.

In this section, we discuss the design details of the application workflow for the first use case.
The user’s natural language query comes with different difficult levels: easy, hard, and challenge.
Straightforward questions may include the following requests:
For these questions, PandasAI can directly interact with the FM to generate Python scripts for processing.
Hard questions require basic aggregation operation or time series analysis, such as the following:
For hard questions, a prompt template with detailed step-by-step instructions assists FMs in providing accurate responses.
Challenge-level questions need advanced math calculation and time series processing, such as the following:
For these questions, you can use multi-shots in a custom prompt to enhance response accuracy. Such multi-shots show examples of advanced time series processing and math calculation, and will provide context for the FM to perform relevant inference on similar analysis. Dynamically inserting the most relevant examples from an NLQ question bank into the prompt can be a challenge. One solution is to construct embeddings from existing NLQ question samples and save these embeddings in a vector store like OpenSearch Service. When a question is sent to the Streamlit app, the question will be vectorized by BedrockEmbeddings. The top N most-relevant embeddings to that question are retrieved using opensearch_vector_search.similarity_search and inserted into the prompt template as a multi-shot prompt.
The following diagram illustrates this workflow.

The embedding layer is constructed using three key tools:
At the outset of app development, we began with only 23 saved examples in the OpenSearch Service index as embeddings. As the app goes live in the field, users start inputting their NLQs via the app. However, due to the limited examples available in the template, some NLQs may not find similar prompts. To continuously enrich these embeddings and offer more relevant user prompts, you can use the Streamlit app for gathering human-audited examples.
Within the app, the following function serves this purpose. When end-users find the output helpful and select Helpful, the application follows these steps:
In the event that a user selects Not Helpful, no action is taken. This iterative process makes sure that the system continually improves by incorporating user-contributed examples.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
By incorporating human auditing, the quantity of examples in OpenSearch Service available for prompt embedding grows as the app gains usage. This expanded embedding dataset results in enhanced search accuracy over time. Specifically, for challenging NLQs, the FM’s response accuracy reaches approximately 90% when dynamically inserting similar examples to construct custom prompts for each NLQ question. This represents a notable 28% increase compared to scenarios without multi-shot prompts.
On the Streamlit app’s Captured Image Summary tab, you can directly upload an image file. This initiates the Amazon Rekognition API (detect_text API), extracting text from the image label detailing machine specifications. Subsequently, the extracted text data is sent to the Amazon Bedrock Claude model as the context of a prompt, resulting in a 200-word summary.
From a user experience perspective, enabling streaming functionality for a text summarization task is paramount, allowing users to read the FM-generated summary in smaller chunks rather than waiting for the entire output. Amazon Bedrock facilitates streaming via its API (bedrock_runtime.invoke_model_with_response_stream).
In this scenario, we’ve developed a chatbot application focused on root cause analysis, employing the RAG approach. This chatbot draws from multiple documents related to bearing equipment to facilitate root cause analysis. This RAG-based root cause analysis chatbot uses knowledge bases for generating vector text representations, or embeddings. Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources or manage data flows and RAG implementation details.
When you’re satisfied with the knowledge base response from Amazon Bedrock, you can integrate the root cause response from the knowledge base to the Streamlit app.
To save costs, delete the resources you created in this post:
Generative AI applications have already transformed various business processes, enhancing worker productivity and skill sets. However, the limitations of FMs in handling time series data analysis have hindered their full utilization by industrial clients. This constraint has impeded the application of generative AI to the predominant data type processed daily.
In this post, we introduced a generative AI Application solution designed to alleviate this challenge for industrial users. This application uses an open source agent, PandasAI, to strengthen an FM’s time series analysis capability. Rather than sending time series data directly to FMs, the app employs PandasAI to generate Python code for the analysis of unstructured time series data. To enhance the accuracy of Python code generation, a custom prompt generation workflow with human auditing has been implemented.
Empowered with insights into their asset health, industrial workers can fully harness the potential of generative AI across various use cases, including root cause diagnosis and part replacement planning. With Knowledge Bases for Amazon Bedrock, the RAG solution is straightforward for developers to build and manage.
The trajectory of enterprise data management and operations is unmistakably moving towards deeper integration with generative AI for comprehensive insights into operational health. This shift, spearheaded by Amazon Bedrock, is significantly amplified by the growing robustness and potential of LLMs like Amazon Bedrock Claude 3 to further elevate solutions. To learn more, visit consult the Amazon Bedrock documentation, and get hands-on with the Amazon Bedrock workshop.
 Julia Hu is a Sr. AI/ML Solutions Architect at Amazon Web Services. She is specialized in Generative AI, Applied Data Science and IoT architecture. Currently she is part of the Amazon Q team, and an active member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative AI solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges.
Julia Hu is a Sr. AI/ML Solutions Architect at Amazon Web Services. She is specialized in Generative AI, Applied Data Science and IoT architecture. Currently she is part of the Amazon Q team, and an active member/mentor in Machine Learning Technical Field Community. She works with customers, ranging from start-ups to enterprises, to develop AWSome generative AI solutions. She is particularly passionate about leveraging Large Language Models for advanced data analytics and exploring practical applications that address real-world challenges.
 Sudeesh Sasidharan is a Senior Solutions Architect at AWS, within the Energy team. Sudeesh loves experimenting with new technologies and building innovative solutions that solve complex business challenges. When he is not designing solutions or tinkering with the latest technologies, you can find him on the tennis court working on his backhand.
Sudeesh Sasidharan is a Senior Solutions Architect at AWS, within the Energy team. Sudeesh loves experimenting with new technologies and building innovative solutions that solve complex business challenges. When he is not designing solutions or tinkering with the latest technologies, you can find him on the tennis court working on his backhand.
 Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (AI), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide AI services specialist solutions architects who help customers build innovative Generative AI-powered solutions, share best practices with customers, and drive product roadmap. In his previous roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held leadership roles in developing and launching innovative products and services that have helped companies improve their operations, reduce costs, and increase revenue. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success.
Neil Desai is a technology executive with over 20 years of experience in artificial intelligence (AI), data science, software engineering, and enterprise architecture. At AWS, he leads a team of Worldwide AI services specialist solutions architects who help customers build innovative Generative AI-powered solutions, share best practices with customers, and drive product roadmap. In his previous roles at Vestas, Honeywell, and Quest Diagnostics, Neil has held leadership roles in developing and launching innovative products and services that have helped companies improve their operations, reduce costs, and increase revenue. He is passionate about using technology to solve real-world problems and is a strategic thinker with a proven track record of success.
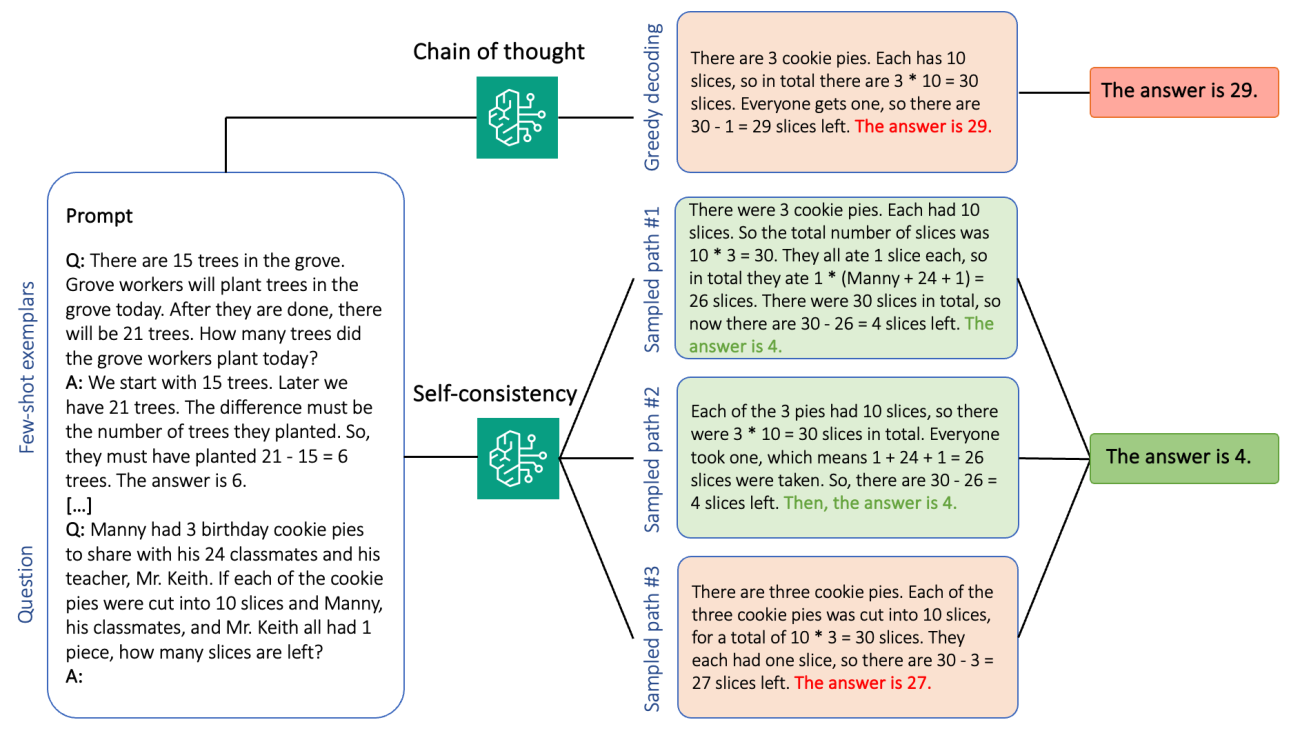
Generative language models have proven remarkably skillful at solving logical and analytical natural language processing (NLP) tasks. Furthermore, the use of prompt engineering can notably enhance their performance. For example, chain-of-thought (CoT) is known to improve a model’s capacity for complex multi-step problems. To additionally boost accuracy on tasks that involve reasoning, a self-consistency prompting approach has been suggested, which replaces greedy with stochastic decoding during language generation.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. With the batch inference API, you can use Amazon Bedrock to run inference with foundation models in batches and get responses more efficiently. This post shows how to implement self-consistency prompting via batch inference on Amazon Bedrock to enhance model performance on arithmetic and multiple-choice reasoning tasks.
Self-consistency prompting of language models relies on the generation of multiple responses that are aggregated into a final answer. In contrast to single-generation approaches like CoT, the self-consistency sample-and-marginalize procedure creates a range of model completions that lead to a more consistent solution. The generation of different responses for a given prompt is possible due to the use of a stochastic, rather than greedy, decoding strategy.
The following figure shows how self-consistency differs from greedy CoT in that it generates a diverse set of reasoning paths and aggregates them to produce the final answer.

Text generated by decoder-only language models unfolds word by word, with the subsequent token being predicted on the basis of the preceding context. For a given prompt, the model computes a probability distribution indicating the likelihood of each token to appear next in the sequence. Decoding involves translating these probability distributions into actual text. Text generation is mediated by a set of inference parameters that are often hyperparameters of the decoding method itself. One example is the temperature, which modulates the probability distribution of the next token and influences the randomness of the model’s output.
Greedy decoding is a deterministic decoding strategy that at each step selects the token with the highest probability. Although straightforward and efficient, the approach risks falling into repetitive patterns, because it disregards the broader probability space. Setting the temperature parameter to 0 at inference time essentially equates to implementing greedy decoding.
Sampling introduces stochasticity into the decoding process by randomly selecting each subsequent token based on the predicted probability distribution. This randomness results in greater output variability. Stochastic decoding proves more adept at capturing the diversity of potential outputs and often yields more imaginative responses. Higher temperature values introduce more fluctuations and increase the creativity of the model’s response.
The reasoning ability of language models can be augmented via prompt engineering. In particular, CoT has been shown to elicit reasoning in complex NLP tasks. One way to implement a zero-shot CoT is via prompt augmentation with the instruction to “think step by step.” Another is to expose the model to exemplars of intermediate reasoning steps in few-shot prompting fashion. Both scenarios typically use greedy decoding. CoT leads to significant performance gains compared to simple instruction prompting on arithmetic, commonsense, and symbolic reasoning tasks.
Self-consistency prompting is based on the assumption that introducing diversity in the reasoning process can be beneficial to help models converge on the correct answer. The technique uses stochastic decoding to achieve this goal in three steps:
Self-consistency is shown to outperform CoT prompting on popular arithmetic and commonsense reasoning benchmarks. A limitation of the approach is its larger computational cost.
This post shows how self-consistency prompting enhances performance of generative language models on two NLP reasoning tasks: arithmetic problem-solving and multiple-choice domain-specific question answering. We demonstrate the approach using batch inference on Amazon Bedrock:
This walkthrough assumes the following prerequisites:
iam:PassRole policies to run Jupyter inside the SageMaker notebook instance.BedrockBatchInferenceRole role for batch inference with Amazon Bedrock with Amazon Simple Storage Service (Amazon S3) access and sts:AssumeRole trust policies. For more information, refer to Set up permissions for batch inference.
The estimated cost to run the code shown in this post is $100, assuming you run self-consistency prompting one time with 30 reasoning paths using one value for the temperature-based sampling.
GSM8K is a dataset of human-assembled grade school math problems featuring a high linguistic diversity. Each problem takes 2–8 steps to solve and requires performing a sequence of elementary calculations with basic arithmetic operations. This data is commonly used to benchmark the multi-step arithmetic reasoning capabilities of generative language models. The GSM8K train set comprises 7,473 records. The following is an example:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Batch inference allows you to run multiple inference calls to Amazon Bedrock asynchronously and improve the performance of model inference on large datasets. The service is in preview as of this writing and only available through the API. Refer to Run batch inference to access batch inference APIs via custom SDKs.
After you have downloaded and unzipped the Python SDK in a SageMaker notebook instance, you can install it by running the following code in a Jupyter notebook cell:
Input data for batch inference needs to be prepared in JSONL format with recordId and modelInput keys. The latter should match the body field of the model to be invoked on Amazon Bedrock. In particular, some supported inference parameters for Cohere Command are temperature for randomness, max_tokens for output length, and num_generations to generate multiple responses, all of which are passed together with the prompt as modelInput:
See Inference parameters for foundation models for more details, including other model providers.
Our experiments on arithmetic reasoning are performed in the few-shot setting without customizing or fine-tuning Cohere Command. We use the same set of eight few-shot exemplars from the chain-of-thought (Table 20) and self-consistency (Table 17) papers. Prompts are created by concatenating the exemplars with each question from the GSM8K train set.
We set max_tokens to 512 and num_generations to 5, the maximum allowed by Cohere Command. For greedy decoding, we set temperature to 0 and for self-consistency, we run three experiments at temperatures 0.5, 0.7, and 1. Each setting yields different input data according to the respective temperature values. Data is formatted as JSONL and stored in Amazon S3.
Batch inference job creation requires an Amazon Bedrock client. We specify the S3 input and output paths and give each invocation job a unique name:
Jobs are created by passing the IAM role, model ID, job name, and input/output configuration as parameters to the Amazon Bedrock API:
Listing, monitoring, and stopping batch inference jobs is supported by their respective API calls. On creation, jobs appear first as Submitted, then as InProgress, and finally as Stopped, Failed, or Completed.
If the jobs are successfully complete, the generated content can be retrieved from Amazon S3 using its unique output location.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
Self-consistency prompting of Cohere Command outperforms a greedy CoT baseline in terms of accuracy on the GSM8K dataset. For self-consistency, we sample 30 independent reasoning paths at three different temperatures, with topP and topK set to their default values. Final solutions are aggregated by choosing the most consistent occurrence via majority voting. In case of a tie, we randomly choose one of the majority responses. We compute accuracy and standard deviation values averaged over 100 runs.
The following figure shows the accuracy on the GSM8K dataset from Cohere Command prompted with greedy CoT (blue) and self-consistency at temperature values 0.5 (yellow), 0.7 (green), and 1.0 (orange) as a function of the number of sampled reasoning paths.

The preceding figure shows that self-consistency enhances arithmetic accuracy over greedy CoT when the number of sampled paths is as low as three. Performance increases consistently with further reasoning paths, confirming the importance of introducing diversity in the thought generation. Cohere Command solves the GSM8K question set with 51.7% accuracy when prompted with CoT vs. 68% with 30 self-consistent reasoning paths at T=1.0. All three surveyed temperature values yield similar results, with lower temperatures being comparatively more performant at less sampled paths.
Self-consistency is limited by the increased response time and cost incurred when generating multiple outputs per prompt. As a practical illustration, batch inference for greedy generation with Cohere Command on 7,473 GSM8K records finished in less than 20 minutes. The job took 5.5 million tokens as input and generated 630,000 output tokens. At current Amazon Bedrock inference prices, the total cost incurred was around $9.50.
For self-consistency with Cohere Command, we use inference parameter num_generations to create multiple completions per prompt. As of this writing, Amazon Bedrock allows a maximum of five generations and three concurrent Submitted batch inference jobs. Jobs proceed to the InProgress status sequentially, therefore sampling more than five paths requires multiple invocations.
The following figure shows the runtimes for Cohere Command on the GSM8K dataset. Total runtime is shown on the x axis and runtime per sampled reasoning path on the y axis. Greedy generation runs in the shortest time but incurs a higher time cost per sampled path.

Greedy generation completes in less than 20 minutes for the full GSM8K set and samples a unique reasoning path. Self-consistency with five samples requires about 50% longer to complete and costs around $14.50, but produces five paths (over 500%) in that time. Total runtime and cost increase step-wise with every extra five sampled paths. A cost-benefit analysis suggests that 1–2 batch inference jobs with 5–10 sampled paths is the recommended setting for practical implementation of self-consistency. This achieves enhanced model performance while keeping cost and latency at bay.
A crucial question to prove the suitability of self-consistency prompting is whether the method succeeds across further NLP tasks and language models. As an extension to an Amazon-related use case, we perform a small-sized analysis on sample questions from the AWS Solutions Architect Associate Certification. This is a multiple-choice exam on AWS technology and services that requires domain knowledge and the ability to reason and decide among several options.
We prepare a dataset from SAA-C01 and SAA-C03 sample exam questions. From the 20 available questions, we use the first 4 as few-shot exemplars and prompt the model to answer the remaining 16. This time, we run inference with the AI21 Labs Jurassic-2 Mid model and generate a maximum of 10 reasoning paths at temperature 0.7. Results show that self-consistency enhances performance: although greedy CoT produces 11 correct answers, self-consistency succeeds on 2 more.
The following table shows the accuracy results for 5 and 10 sampled paths averaged over 100 runs.
| . | Greedy decoding | T = 0.7 |
| # sampled paths: 5 | 68.6 | 74.1 ± 0.7 |
| # sampled paths: 10 | 68.6 | 78.9 ± 0.3 |
In the following table, we present two exam questions that are incorrectly answered by greedy CoT while self-consistency succeeds, highlighting in each case the correct (green) or incorrect (red) reasoning traces that led the model to produce correct or incorrect responses. Although not every sampled path generated by self-consistency is correct, the majority converges on the true answer as the number of sampled paths increases. We observe that 5–10 paths are typically enough to improve over the greedy results, with diminishing returns in terms of efficiency past those values.
| Question |
A web application allows customers to upload orders to an S3 bucket. The resulting Amazon S3 events trigger a Lambda function that inserts a message to an SQS queue. A single EC2 instance reads messages from the queue, processes them, and stores them in a DynamoDB table partitioned by unique order ID. Next month traffic is expected to increase by a factor of 10 and a Solutions Architect is reviewing the architecture for possible scaling problems. Which component is MOST likely to need re-architecting to be able to scale to accommodate the new traffic? A. Lambda function |
An application running on AWS uses an Amazon Aurora Multi-AZ DB cluster deployment for its database. When evaluating performance metrics, a solutions architect discovered that the database reads are causing high I/O and adding latency to the write requests against the database. What should the solutions architect do to separate the read requests from the write requests? A. Enable read-through caching on the Aurora database. |
| Correct answer | C – A single EC2 instance will not scale and is a single point of failure in the architecture. A much better solution would be to have EC2 instances in an Auto Scaling group across 2 availability zones read messages from the queue. The other responses are all managed services that can be configured to scale or will scale automatically. | C – Aurora Replicas provide a way to offload read traffic. Aurora Replicas share the same underlying storage as the main database, so lag time is generally very low. Aurora Replicas have their own endpoints, so the application will need to be configured to direct read traffic to the new endpoints. |
| Greedy decoding | Scaling the EC2 instance directly may not be possible, as it may not be possible to resize the instance. Scaling the Lambda function may not be sufficient, as Lambda functions have a 6 GB of memory allocation limit. Scaling the SQS queue may not be sufficient, as SQS has a 10,000 message limit. DynamoDB tables can be scaled by provisioning more capacity units. The correct answer is D. | Modifying the application to read from the Multi-AZ standby instance (option B) is the best approach. The standby instance is asynchronously replicated from the primary instance, so read operations will not interfere with write operations. Enabling read-through caching (option A) or creating an Aurora replica (option C) will not solve the I/O contention issue. Creating a second Aurora database and linking it as a read replica (option D) will not solve the I/O contention issue either. The correct answer is B. |
| Sampled path #1 | Scaling the EC2 instance to 10 times its current size may not be feasible, either from a cost or performance perspective. It would require a larger instance, which can be expensive. A more cost-effective approach might be to use a swarm of smaller instances (e.g., Auto Scaling Group) to share the load. In this case, the EC2 instance would likely need to be re-architected. The correct answer is C. | Modifying the application to use the appropriate endpoints is not a practical solution as it would require changes to the application code. The correct answer is C: Create an Aurora replica and modify the application to use the appropriate endpoints. |
| Sampled path #2 | Scaling a single EC2 instance is more difficult and problematic than scaling the other service components. Amazon SQS, Lambda, and DynamoDB can all scale automatically to cope with the increased load. The correct answer is C. |
(C) Create an Aurora replica and modify the application to use the appropriate endpoints. By configuring an Aurora Replica, you can separate read traffic from write traffic. The Aurora Replicas use different endpoint URLs, allowing you to direct read traffic to the replica instead of the primary database. The replica can process read requests in parallel with write requests to the primary database, reducing I/O and latency. |
Running batch inference in Amazon Bedrock is subject to charges according to the Amazon Bedrock Pricing. When you complete the walkthrough, delete your SageMaker notebook instance and remove all data from your S3 buckets to avoid incurring future charges.
Although the demonstrated solution shows improved performance of language models when prompted with self-consistency, it’s important to note that the walkthrough is not production-ready. Before you deploy to production, you should adapt this proof of concept to your own implementation, keeping in mind the following requirements:
This post shows that self-consistency prompting enhances performance of generative language models in complex NLP tasks that require arithmetic and multiple-choice logical skills. Self-consistency uses temperature-based stochastic decoding to generate various reasoning paths. This increases the ability of the model to elicit diverse and useful thoughts to arrive at correct answers.
With Amazon Bedrock batch inference, the language model Cohere Command is prompted to generate self-consistent answers to a set of arithmetic problems. Accuracy improves from 51.7% with greedy decoding to 68% with self-consistency sampling 30 reasoning paths at T=1.0. Sampling five paths already enhances accuracy by 7.5 percent points. The approach is transferable to other language models and reasoning tasks, as demonstrated by results of the AI21 Labs Jurassic-2 Mid model on an AWS Certification exam. In a small-sized question set, self-consistency with five sampled paths increases accuracy by 5 percent points over greedy CoT.
We encourage you to implement self-consistency prompting for enhanced performance in your own applications with generative language models. Learn more about Cohere Command and AI21 Labs Jurassic models available on Amazon Bedrock. For more information about batch inference, refer to Run batch inference.
The author thanks technical reviewers Amin Tajgardoon and Patrick McSweeney for helpful feedback.

Lucía Santamaría is a Sr. Applied Scientist at Amazon’s ML University, where she’s focused on raising the level of ML competency across the company through hands-on education. Lucía has a PhD in astrophysics and is passionate about democratizing access to tech knowledge and tools.
NVIDIA recognized 14 partners in the Americas for their achievements in transforming businesses with AI, this week at GTC.
The winners of the NVIDIA Partner Network Americas Partner of the Year awards have helped customers across industries advance their operations with the software, systems and services needed to integrate AI into their businesses.
NPN awards categories span a multitude of competencies and industries, including service delivery, data center networking, public sector, healthcare and higher education.
Three new categories were created this year. One recognizes a partner driving AI-powered success in the financial services industry; one celebrates a partner exhibiting overall AI excellence; and another honors a partner’s dedication to advancing NVIDIA’s full-stack portfolio across a multitude of industries.
All awards reflect the spirit of the NPN ecosystem in driving business success through accelerated full-stack computing and software.
“NVIDIA’s work driving innovation in generative AI has helped partners empower their customers with cutting-edge technology — as well reduced costs and fostered growth opportunities while solving intricate business challenges,” said Rob Enderle, president and principal analyst at the Enderle Group. “The recipients of the 2024 NPN awards embody a diverse array of AI expertise, offering rich knowledge to help customers deploy transformative solutions across industries.”
The 2024 NPN award winners for the Americas are:
Learn how to join NPN, or find your local NPN partner.


Health datasets play a crucial role in research and medical education, but it can be challenging to create a dataset that represents the real world. For example, dermatology conditions are diverse in their appearance and severity and manifest differently across skin tones. Yet, existing dermatology image datasets often lack representation of everyday conditions (like rashes, allergies and infections) and skew towards lighter skin tones. Furthermore, race and ethnicity information is frequently missing, hindering our ability to assess disparities or create solutions.
To address these limitations, we are releasing the Skin Condition Image Network (SCIN) dataset in collaboration with physicians at Stanford Medicine. We designed SCIN to reflect the broad range of concerns that people search for online, supplementing the types of conditions typically found in clinical datasets. It contains images across various skin tones and body parts, helping to ensure that future AI tools work effectively for all. We’ve made the SCIN dataset freely available as an open-access resource for researchers, educators, and developers, and have taken careful steps to protect contributor privacy.
 |
| Example set of images and metadata from the SCIN dataset. |
The SCIN dataset currently contains over 10,000 images of skin, nail, or hair conditions, directly contributed by individuals experiencing them. All contributions were made voluntarily with informed consent by individuals in the US, under an institutional-review board approved study. To provide context for retrospective dermatologist labeling, contributors were asked to take images both close-up and from slightly further away. They were given the option to self-report demographic information and tanning propensity (self-reported Fitzpatrick Skin Type, i.e., sFST), and to describe the texture, duration and symptoms related to their concern.
One to three dermatologists labeled each contribution with up to five dermatology conditions, along with a confidence score for each label. The SCIN dataset contains these individual labels, as well as an aggregated and weighted differential diagnosis derived from them that could be useful for model testing or training. These labels were assigned retrospectively and are not equivalent to a clinical diagnosis, but they allow us to compare the distribution of dermatology conditions in the SCIN dataset with existing datasets.
 |
| The SCIN dataset contains largely allergic, inflammatory and infectious conditions while datasets from clinical sources focus on benign and malignant neoplasms. |
While many existing dermatology datasets focus on malignant and benign tumors and are intended to assist with skin cancer diagnosis, the SCIN dataset consists largely of common allergic, inflammatory, and infectious conditions. The majority of images in the SCIN dataset show early-stage concerns — more than half arose less than a week before the photo, and 30% arose less than a day before the image was taken. Conditions within this time window are seldom seen within the health system and therefore are underrepresented in existing dermatology datasets.
We also obtained dermatologist estimates of Fitzpatrick Skin Type (estimated FST or eFST) and layperson labeler estimates of Monk Skin Tone (eMST) for the images. This allowed comparison of the skin condition and skin type distributions to those in existing dermatology datasets. Although we did not selectively target any skin types or skin tones, the SCIN dataset has a balanced Fitzpatrick skin type distribution (with more of Types 3, 4, 5, and 6) compared to similar datasets from clinical sources.
 |
| Self-reported and dermatologist-estimated Fitzpatrick Skin Type distribution in the SCIN dataset compared with existing un-enriched dermatology datasets (Fitzpatrick17k, PH², SKINL2, and PAD-UFES-20). |
The Fitzpatrick Skin Type scale was originally developed as a photo-typing scale to measure the response of skin types to UV radiation, and it is widely used in dermatology research. The Monk Skin Tone scale is a newer 10-shade scale that measures skin tone rather than skin phototype, capturing more nuanced differences between the darker skin tones. While neither scale was intended for retrospective estimation using images, the inclusion of these labels is intended to enable future research into skin type and tone representation in dermatology. For example, the SCIN dataset provides an initial benchmark for the distribution of these skin types and tones in the US population.
The SCIN dataset has a high representation of women and younger individuals, likely reflecting a combination of factors. These could include differences in skin condition incidence, propensity to seek health information online, and variations in willingness to contribute to research across demographics.
To create the SCIN dataset, we used a novel crowdsourcing method, which we describe in the accompanying research paper co-authored with investigators at Stanford Medicine. This approach empowers individuals to play an active role in healthcare research. It allows us to reach people at earlier stages of their health concerns, potentially before they seek formal care. Crucially, this method uses advertisements on web search result pages — the starting point for many people’s health journey — to connect with participants.
Our results demonstrate that crowdsourcing can yield a high-quality dataset with a low spam rate. Over 97.5% of contributions were genuine images of skin conditions. After performing further filtering steps to exclude images that were out of scope for the SCIN dataset and to remove duplicates, we were able to release nearly 90% of the contributions received over the 8-month study period. Most images were sharp and well-exposed. Approximately half of the contributions include self-reported demographics, and 80% contain self-reported information relating to the skin condition, such as texture, duration, or other symptoms. We found that dermatologists’ ability to retrospectively assign a differential diagnosis depended more on the availability of self-reported information than on image quality.
 |
| Dermatologist confidence in their labels (scale from 1-5) depended on the availability of self-reported demographic and symptom information. |
While perfect image de-identification can never be guaranteed, protecting the privacy of individuals who contributed their images was a top priority when creating the SCIN dataset. Through informed consent, contributors were made aware of potential re-identification risks and advised to avoid uploading images with identifying features. Post-submission privacy protection measures included manual redaction or cropping to exclude potentially identifying areas, reverse image searches to exclude publicly available copies and metadata removal or aggregation. The SCIN Data Use License prohibits attempts to re-identify contributors.
We hope the SCIN dataset will be a helpful resource for those working to advance inclusive dermatology research, education, and AI tool development. By demonstrating an alternative to traditional dataset creation methods, SCIN paves the way for more representative datasets in areas where self-reported data or retrospective labeling is feasible.
We are grateful to all our co-authors Abbi Ward, Jimmy Li, Julie Wang, Sriram Lakshminarasimhan, Ashley Carrick, Bilson Campana, Jay Hartford, Pradeep Kumar S, Tiya Tiyasirisokchai, Sunny Virmani, Renee Wong, Yossi Matias, Greg S. Corrado, Dale R. Webster, Dawn Siegel (Stanford Medicine), Steven Lin (Stanford Medicine), Justin Ko (Stanford Medicine), Alan Karthikesalingam and Christopher Semturs. We also thank Yetunde Ibitoye, Sami Lachgar, Lisa Lehmann, Javier Perez, Margaret Ann Smith (Stanford Medicine), Rachelle Sico, Amit Talreja, Annisah Um’rani and Wayne Westerlind for their essential contributions to this work. Finally, we are grateful to Heather Cole-Lewis, Naama Hammel, Ivor Horn, Michael Howell, Yun Liu, and Eric Teasley for their insightful comments on the study design and manuscript.

NVIDIA today was named the world’s most innovative company by Fast Company magazine.
The accolade comes on the heels of company founder and CEO Jensen Huang being inducted into the U.S. National Academy of Engineering.
A team of several dozen journalists at Fast Company — a business media brand launched in 1995 by two Harvard Business Review editors — ranked NVIDIA the leader in its 2024 list of the world’s 50 most innovative companies.
“Nvidia isn’t just in the business of providing ever-more-powerful computing hardware and letting everybody else figure out what to do with it,” Fast Company wrote in an article detailing its selection.
“Across an array of industries, the company’s technologies, platforms, and partnerships are doing much of the heavy lifting of putting AI to work,” citing advances in automotive, drug discovery, gaming and retail announced in one recent week.
The article noted the central role of the CUDA compute platform. It also shared an eye-popping experience using NVIDIA Omniverse to interact with a digital twin of a Nissan Z sport coupe.
“Even for AI’s titans, building on what Nvidia has created — the more ambitiously, the better — is often how progress happens,” the article concluded.
Last year, OpenAI led the list for ChatGPT, the large language model that started a groundswell in generative AI. In 2021, Moderna and Pfizer-BioNTech topped the ranking for rapidly developing a Covid vaccine.
Fast Company bases its ranking on four criteria: innovation, impact, timeliness and relevance. Launched in 2008, the annual list recognizes organizations that have introduced groundbreaking products, fostered positive social impact and reshaped industries.
NVIDIA invented the GPU in 1999, redefining computer graphics and igniting the era of modern AI. NVIDIA is now driving the platform shift to accelerated computing and generative AI, transforming the world’s largest industries.
Last month, Huang was elected to the National Academy of Engineering (NAE) for contributions in “high-powered graphics processing units, fueling the artificial intelligence revolution.”
Academy membership honors those who have made outstanding contributions such as pioneering new fields of technology. Founded in 1964, the NAE provides a trusted source of engineering advice for creating a healthier, more secure and sustainable world.
“Jensen Huang’s induction into the National Academy of Engineering is a testament to his enduring contributions to our industry and world,” said Satya Nadella, chairman and CEO of Microsoft.
“His visionary leadership has forever transformed computing, from the broad adoption of advanced 3D graphics to today’s GPUs — and, more importantly, has driven foundational innovations across every sector, from gaming and productivity, to digital biology and healthcare. All of us at Microsoft congratulate Jensen on this distinction, and we are honored to partner with him and the entire NVIDIA team on defining this new era of AI,” he added.
“Jensen’s election is incredibly well deserved,” said John Hennessy, president emeritus of Stanford University and an NAE member since 1992.
“His election recognizes both his transformative technical contributions, as well as his incredible leadership of NVIDIA for almost 30 years. I have seen many NAE nominations over the past 30 years, Jensen’s was one of the best!”
Morris Chang, founder of Taiwan Semiconductor Manufacturing Co. and an NAE member since 2002, added his congratulations.
“Jensen is one of the most visionary engineers and charismatic business leaders I have had the pleasure to work with in the last three decades,” he said.
Huang is also a recipient of the Semiconductor Industry Association’s highest honor, the Robert N. Noyce Award, as well as honorary doctorate degrees from Taiwan’s National Chiao Tung University, National Taiwan University and Oregon State University.