With Knowledge Bases for Amazon Bedrock, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for Retrieval Augmented Generation (RAG). Access to additional data helps the model generate more relevant, context-specific, and accurate responses without retraining the FMs.
In this post, we discuss two new features of Knowledge Bases for Amazon Bedrock specific to the RetrieveAndGenerate API: configuring the maximum number of results and creating custom prompts with a knowledge base prompt template. You can now choose these as query options alongside the search type.
Overview and benefits of new features
The maximum number of results option gives you control over the number of search results to be retrieved from the vector store and passed to the FM for generating the answer. This allows you to customize the amount of background information provided for generation, thereby giving more context for complex questions or less for simpler questions. It allows you to fetch up to 100 results. This option helps improve the likelihood of relevant context, thereby improving the accuracy and reducing the hallucination of the generated response.
The custom knowledge base prompt template allows you to replace the default prompt template with your own to customize the prompt that’s sent to the model for response generation. This allows you to customize the tone, output format, and behavior of the FM when it responds to a user’s question. With this option, you can fine-tune terminology to better match your industry or domain (such as healthcare or legal). Additionally, you can add custom instructions and examples tailored to your specific workflows.
In the following sections, we explain how you can use these features with either the AWS Management Console or SDK.
Prerequisites
To follow along with these examples, you need to have an existing knowledge base. For instructions to create one, see Create a knowledge base.
Configure the maximum number of results using the console
To use the maximum number of results option using the console, complete the following steps:
- On the Amazon Bedrock console, choose Knowledge bases in the left navigation pane.
- Select the knowledge base you created.
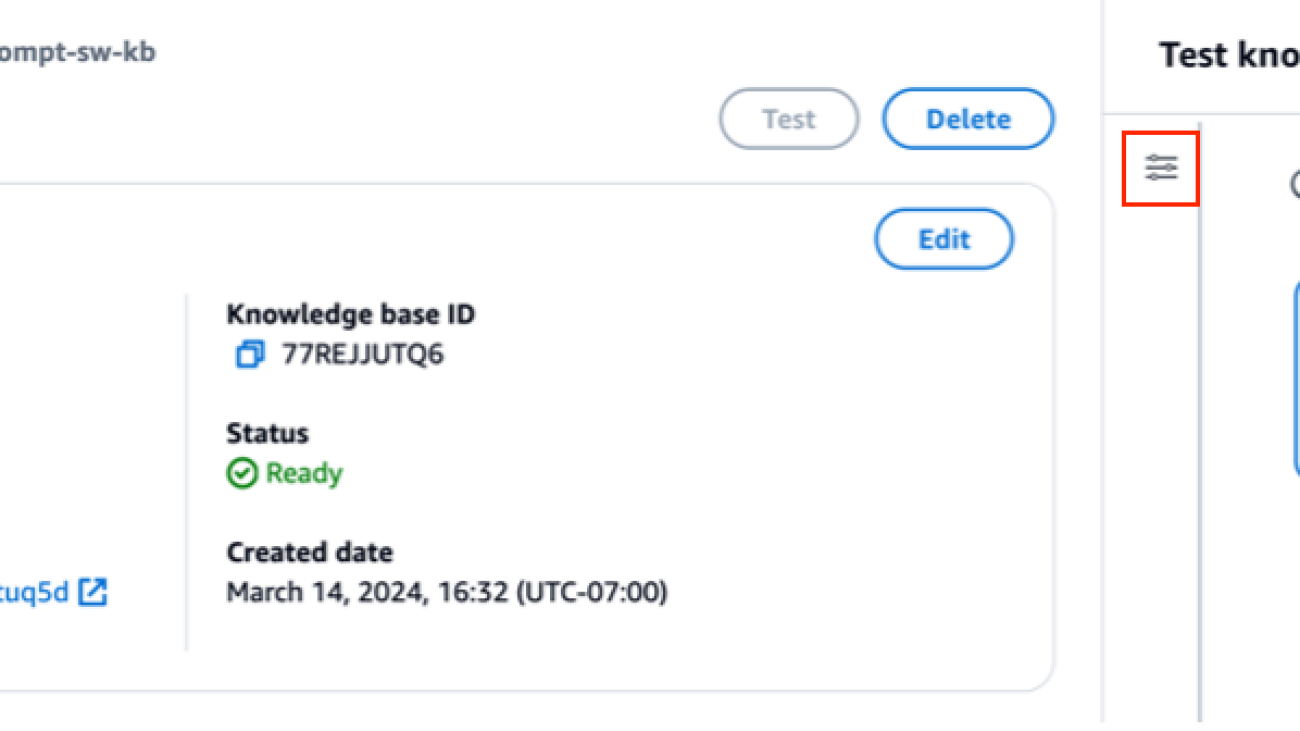
- Choose Test knowledge base.
- Choose the configuration icon.
- Choose Sync data source before you start testing your knowledge base.

- Under Configurations, for Search Type, select a search type based on your use case.
For this post, we use hybrid search because it combines semantic and text search to provider greater accuracy. To learn more about hybrid search, see Knowledge Bases for Amazon Bedrock now supports hybrid search.
- Expand Maximum number of source chunks and set your maximum number of results.

To demonstrate the value of the new feature, we show examples of how you can increase the accuracy of the generated response. We used Amazon 10K document for 2023 as the source data for creating the knowledge base. We use the following query for experimentation: “In what year did Amazon’s annual revenue increase from $245B to $434B?”
The correct response for this query is “Amazon’s annual revenue increased from $245B in 2019 to $434B in 2022,” based on the documents in the knowledge base. We used Claude v2 as the FM to generate the final response based on the contextual information retrieved from the knowledge base. Claude 3 Sonnet and Claude 3 Haiku are also supported as the generation FMs.
We ran another query to demonstrate the comparison of retrieval with different configurations. We used the same input query (“In what year did Amazon’s annual revenue increase from $245B to $434B?”) and set the maximum number of results to 5.
As shown in the following screenshot, the generated response was “Sorry, I am unable to assist you with this request.”

Next, we set the maximum results to 12 and ask the same question. The generated response is “Amazon’s annual revenue increase from $245B in 2019 to $434B in 2022.”

As shown in this example, we are able to retrieve the correct answer based on the number of retrieved results. If you want to learn more about the source attribution that constitutes the final output, choose Show source details to validate the generated answer based on the knowledge base.
Customize a knowledge base prompt template using the console
You can also customize the default prompt with your own prompt based on the use case. To do so on the console, complete the following steps:
- Repeat the steps in the previous section to start testing your knowledge base.
- Enable Generate responses.

- Select the model of your choice for response generation.
We use the Claude v2 model as an example in this post. The Claude 3 Sonnet and Haiku model is also available for generation.
- Choose Apply to proceed.

After you choose the model, a new section called Knowledge base prompt template appears under Configurations.
- Choose Edit to start customizing the prompt.

- Adjust the prompt template to customize how you want to use the retrieved results and generate content.
For this post, we gave a few examples for creating a “Financial Advisor AI system” using Amazon financial reports with custom prompts. For best practices on prompt engineering, refer to Prompt engineering guidelines.
We now customize the default prompt template in several different ways, and observe the responses.
Let’s first try a query with the default prompt. We ask “What was the Amazon’s revenue in 2019 and 2021?” The following shows our results.

From the output, we find that it’s generating the free-form response based on the retrieved knowledge. The citations are also listed for reference.
Let’s say we want to give extra instructions on how to format the generated response, like standardizing it as JSON. We can add these instructions as a separate step after retrieving the information, as part of the prompt template:
If you are asked for financial information covering different years, please provide precise answers in JSON format. Use the year as the key and the concise answer as the value. For example: {year:answer}
The final response has the required structure.

By customizing the prompt, you can also change the language of the generated response. In the following example, we instruct the model to provide an answer in Spanish.

After removing $output_format_instructions$ from the default prompt, the citation from the generated response is removed.
In the following sections, we explain how you can use these features with the SDK.
Configure the maximum number of results using the SDK
To change the maximum number of results with the SDK, use the following syntax. For this example, the query is “In what year did Amazon’s annual revenue increase from $245B to $434B?” The correct response is “Amazon’s annual revenue increase from $245B in 2019 to $434B in 2022.”
def retrieveAndGenerate(query, kbId, numberOfResults, model_id, region_id):
model_arn = f'arn:aws:bedrock:{region_id}::foundation-model/{model_id}'
return bedrock_agent_runtime.retrieve_and_generate(
input={
'text': query
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': numberOfResults,
'overrideSearchType': "SEMANTIC", # optional'
}
}
},
'type': 'KNOWLEDGE_BASE'
},
)
response = retrieveAndGenerate("In what year did Amazon’s annual revenue increase from $245B to $434B?",
"<knowledge base id>", numberOfResults, model_id, region_id)['output']['text']
The ‘numberOfResults’ option under ‘retrievalConfiguration’ allows you to select the number of results you want to retrieve. The output of the RetrieveAndGenerate API includes the generated response, source attribution, and the retrieved text chunks.
The following are the results for different values of ‘numberOfResults’ parameters. First, we set numberOfResults = 5.
Then we set numberOfResults = 12.
Customize the knowledge base prompt template using the SDK
To customize the prompt using the SDK, we use the following query with different prompt templates. For this example, the query is “What was the Amazon’s revenue in 2019 and 2021?”
The following is the default prompt template:
"""You are a question answering agent. I will provide you with a set of search results and a user's question, your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Here are the search results in numbered order:
<context>
$search_results$
</context>
Here is the user's question:
<question>
$query$
</question>
$output_format_instructions$
Assistant:
"""
The following is the customized prompt template:
"""Human: You are a question answering agent. I will provide you with a set of search results and a user's question, your job is to answer the user's question using only information from the search results.If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question.Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Here are the search results in numbered order:
<context>
$search_results$
</context>
Here is the user's question:
<question>
$query$
</question>
If you're being asked financial information over multiple years, please be very specific and list the answer concisely using JSON format {key: value},
where key is the year in the request and value is the concise response answer.
Assistant:
"""
def retrieveAndGenerate(query, kbId, numberOfResults,promptTemplate, model_id, region_id):
model_arn = f'arn:aws:bedrock:{region_id}::foundation-model/{model_id}'
return bedrock_agent_runtime.retrieve_and_generate(
input={
'text': query
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': model_arn,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'numberOfResults': numberOfResults,
'overrideSearchType': "SEMANTIC", # optional'
}
},
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': promptTemplate
}
}
},
'type': 'KNOWLEDGE_BASE'
},
)
response = retrieveAndGenerate("What was the Amazon's revenue in 2019 and 2021?”",
"<knowledge base id>", <numberOfResults>, <promptTemplate>, <model_id>, <region_id>)['output']['text']
With the default prompt template, we get the following response:

If you want to provide additional instructions around the output format of the response generation, like standardizing the response in a specific format (like JSON), you can customize the existing prompt by providing more guidance. With our custom prompt template, we get the following response.

The ‘promptTemplate‘ option in ‘generationConfiguration‘ allows you to customize the prompt for better control over answer generation.
Conclusion
In this post, we introduced two new features in Knowledge Bases for Amazon Bedrock: adjusting the maximum number of search results and customizing the default prompt template for the RetrieveAndGenerate API. We demonstrated how to configure these features on the console and via SDK to improve performance and accuracy of the generated response. Increasing the maximum results provides more comprehensive information, whereas customizing the prompt template allows you to fine-tune instructions for the foundation model to better align with specific use cases. These enhancements offer greater flexibility and control, enabling you to deliver tailored experiences for RAG-based applications.
For additional resources to start implementing in your AWS environment, refer to the following:
About the authors
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
 Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Read More



 Posted by
Posted by 





 Discover how companies are using AI technologies to fuel innovation, create new customer experiences and develop better tools for employees.
Discover how companies are using AI technologies to fuel innovation, create new customer experiences and develop better tools for employees.
 Google and Alphabet CEO Sundar Pichai shares new generative AI capabilities for organizations, announced at Cloud Next 2024.
Google and Alphabet CEO Sundar Pichai shares new generative AI capabilities for organizations, announced at Cloud Next 2024.