Introducing a new AI model developed by Google DeepMind and Isomorphic Labs.Read More
Introducing a new AI model developed by Google DeepMind and Isomorphic Labs.Read More
Introducing a new AI model developed by Google DeepMind and Isomorphic Labs.Read More

This research paper was presented at the 12th International Conference on Learning Representations (opens in new tab) (ICLR 2024), the premier conference dedicated to the advancement of deep learning.

Large language models (LLMs) rely on complex internal mechanisms that require more memory than what is typically available to operate on standard devices. One such mechanism is the key-value (KV) cache, which stores and retrieves previously computed data, helping the model generate responses quickly without needing to recalculate information it has already processed. This method uses a substantial amount of memory because it keeps a large amount of this data readily accessible to enhance the model’s speed and efficiency. Consequently, the KV cache can become prohibitively large as the complexity of the tasks increases, sometimes requiring up to 320 GB for a single operation. To address this, we developed FastGen, a novel method aimed at reducing the memory demands for LLMs.
Our paper, “Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs (opens in new tab),” presented at ICLR 2024, we describe how FastGen optimizes the way LLMs store and access data, potentially cutting memory use by half while preserving their efficiency. This approach represents a significant step toward making sophisticated AI tools more accessible and affordable for broader applications. We are honored to share that this paper has been awarded an Honorable Mention for the Outstanding Paper Award (opens in new tab).
The development of FastGen is underpinned by our observations of how the KV cache functions. We first observed that not all the data in the KV cache is needed for LLMs to complete their required tasks, as shown in Figure 1. By providing the KV cache with the mechanism to discard unnecessary data, it is possible to significantly cut memory use. For example, some LLM modules don’t require broad contexts to process input. For this, it is possible to construct a KV cache that removes data that contains less important long-range contexts, such as several sentences or paragraphs. Also, some LLM modules primarily attend only to special tokens, such as punctuation, for which it is possible to create a KV cache that retains only those tokens. Finally, some LLM modules broadly need all tokens, and for these we can employ the standard KV cache and store all words.
Another key observation in our study is that attention modules in different layers and positions in the LLM behave differently and need different preferences for their KV cache, as shown on the right in Figure 1.
Spotlight: Event Series

Join us for a continuous exchange of ideas about research in the era of general AI. Watch Episodes 1 & 2 on-demand.

Because different KV caches have different structures, they need to be handled differently. We based the development of the FastGen algorithm on our observations, enabling it to categorize and optimize the data that is stored in a given KV cache. FastGen first analyzes the specific behaviors of different modules to understand their structures, a method called profiling. It then uses the results to adjust how data is stored in real-time, making the process more efficient. Our tests show that FastGen can reduce the amount of memory by 50% without sacrificing quality. Additional experiments, discussed in detail in our paper, confirm that the profiling process is crucial and significantly improves the efficiency of the KV cache.
Fueled by unprecedented advances in data handling and computational capabilities, LLM pretraining has emerged as a cornerstone of deep learning, transforming natural language processing tasks and continuously challenging our understanding of learning and cognition.
However, greater capabilities can bring challenges. As models scale larger, customizing them for specific tasks can become more resource-intensive. At Microsoft Research, we are exploring different approaches to more efficient model editing. A critical strategy involves targeted model profiling, which identifies essential components of a model that align with predefined goals. This profiling informs precise model modifications, optimizing resource use and effectiveness.
The two research projects we are presenting at ICLR 2024 support these goals. Both adopt the profile-then-edit paradigm to address different problems. FastGen reduces memory consumption. Our related work, Post-hoc Attention Steering for LLMs (PASTA), focuses on better controllability. These approaches are designed to be resource-efficient, as they do not require tuning or back propagation. Looking ahead, our goal is to further develop these techniques to improve the resource-efficiency of LLM applications, making them more accessible to a wider audience.
The post LLM profiling guides KV cache optimization appeared first on Microsoft Research.
Introducing a new AI model developed by Google DeepMind and Isomorphic Labs.Read More
 Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.Read More
Our new AI model AlphaFold 3 can predict the structure and interactions of all life’s molecules with unprecedented accuracy.Read More

AI tools accelerated by NVIDIA RTX have made it easier than ever to edit and work with video.
Case in point: Blackmagic Design’s DaVinci Resolve 19 recently added AI features that make video editing workflows more streamlined. These new features — along with all its other AI-powered effects — get a big boost from optimization for NVIDIA RTX PCs and workstations.
Editors use Blackmagic Design’s DaVinci Resolve — one of the leading nonlinear video editing platforms — to bring their creative vision to life, incorporating visual effects (VFX), color correction, motion graphics and more to their high-resolution footage and audio clips.

Resolve includes a large variety of built-in tools. Some are corrective in nature, letting editors match colors from two sets of footage, reframe footage after the fact or remove objects that weren’t meant to be in a shot. Others give editors the power to manipulate footage and audio in new ways, including smooth slow-motion effects and footage upscaling.
In the past, many of these tools required significant time and effort from users to implement. Resolve now uses AI acceleration to speed up many of these workflows, leaving more time for users to focus on creativity rather than batch processing.
Even better, the entire app is optimized for NVIDIA TensorRT deep learning inference software to get the best performance from GPU-reliant effects and other features, boosting performance by 2x.
The newest release, DaVinci Resolve 19, adds two new AI features that make video editing more efficient: the IntelliTrack AI point tracker for object tracking, stabilization and audio panning, and UltraNR, which uses AI for spatial noise reduction.
IntelliTrack AI makes it easy to stabilize footage during the editing process. It can also be used in Resolve’s Fairlight tool to track on-screen subjects, and automatically generate audio panning within a scene by tracking people or objects as they move across 2D and 3D spaces. With AI audio panning to video, editors can quickly pan, or move audio across the stereo field, multiple actors in a scene, controlling their voice positions in the mix environment. All of this can be done by hand, but IntelliTrack’s AI acceleration speeds up the entire process.
UltraNR is an AI-accelerated denoise mode in Resolve’s spatial noise reduction palette. Editors can use it to dramatically reduce digital noise — undesired fluctuations of color or luminance that obscure detail — from a frame while maintaining image clarity. They can also combine the tool with temporal noise reduction for even more effective denoising in images with motion, where fluctuations can be more noticeable.
Both IntelliTrack and UltraNR get a big boost when running on NVIDIA RTX PCs and workstations. TensorRT lets them run up to 3x faster on a GeForce GTX 4090 laptop vs. the Macbook Pro M3 Max.
In fact, all DaVinci Resolve AI effects are accelerated on RTX GPUs by NVIDIA TensorRT. The new Resolve update also includes GPU acceleration for Beauty, Edge Detect and Watercolor effects, doubling their performance on NVIDIA GPUs.
Find out more about DaVinci Resolve 19, and try it yourself for free, at Blackmagic Design.
Learn how AI is supercharging creativity, and how to get the most from your own creative process, with NVIDIA Studio.
Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.

Amid an AI revolution sweeping through trillion-dollar industries worldwide, NVIDIA founder and CEO Jensen Huang will deliver a keynote address ahead of COMPUTEX 2024, in Taipei, outlining what’s next for the AI ecosystem.
Slated for June 2 at the National Taiwan University Sports Center, the address kicks off before the COMPUTEX trade show scheduled to run from June 3-6 at the Taipei Nangang Exhibition Center.
The keynote will be livestreamed at 7 p.m. Taiwan time (4 a.m. PT) on Sunday, June 2, with a replay available at NVIDIA.com.
With over 1,500 exhibitors from 26 countries and an expected crowd of 50,000 attendees, COMPUTEX is one of the world’s premier technology events.
It has long showcased the vibrant technology ecosystem anchored by Taiwan and has become a launching pad for the cutting-edge systems required to scale AI globally.
As a leader in AI, NVIDIA continues to nurture and expand the AI ecosystem. Last year, Huang’s keynote and appearances in partner press conferences exemplified NVIDIA’s role in helping advance partners across the technology industry.
These partners will be out in force this year.
NVIDIA’s partners, including Acer, ASUS, Asrock Rack, Colorful, GIGABYTE, Ingrasys, Inno3D, Inventec, MSI, Palit, Pegatron, PNY, QCT, Supermicro, Wistron, Wiwynn and Zotac will spotlight new products featuring NVIDIA technology.
In addition to the exhibition and demonstrations, Marc Hamilton, vice president of solutions architecture and engineering at NVIDIA, will take the stage at the TAITRA forum, a key segment of COMPUTEX dedicated to cutting-edge discussions in technology.
As part of the “Let’s Talk Generative AI” forum, Hamilton will present his talk, titled “Infra Build Train Go,” on June 5, from 10-10:30 a.m. at the 701 Conference Room, 7F, Taipei Nangang Exhibition Center Hall 2.
Following the keynote, the NVIDIA AI Summit on June 5 at the Grand Hilai Taipei will delve into the practical applications of AI in manufacturing, healthcare, research and more.
The summit will feature over 20 sessions from industry experts and innovators as well as training sessions for developers. Kimberly Powell, vice president of healthcare and life sciences at NVIDIA, will host a special address on how generative AI is advancing the healthcare technology industry.
Register for the AI Summit.
This paper introduces a novel generative modeling framework grounded in phase space dynamics, taking inspiration from the principles underlying Critically Damped Langevin Dynamics (CLD). Leveraging insights from stochastic optimal control, we construct a favorable path measure in the phase space that proves highly advantageous for generative sampling. A distinctive feature of our approach is the early-stage data prediction capability within the context of propagating generating Ordinary Differential Equations (ODEs) or Stochastic Differential Equations (SDEs) processes. This early prediction…Apple Machine Learning Research
The prevalence of virtual business meetings in the corporate world, largely accelerated by the COVID-19 pandemic, is here to stay. Based on a survey conducted by American Express in 2023, 41% of business meetings are expected to take place in hybrid or virtual format by 2024. Attending multiple meetings daily and keeping track of all ongoing topics gets increasingly more difficult to manage over time. This can have a negative impact in many ways, from delayed project timelines to loss of customer trust. Writing meeting summaries is the usual remedy to overcome this challenge, but it disturbs the focus required to listen to ongoing conversations.
A more efficient way to manage meeting summaries is to create them automatically at the end of a call through the use of generative artificial intelligence (AI) and speech-to-text technologies. This allows attendees to focus solely on the conversation, knowing that a transcript will be made available automatically at the end of the call.
This post presents a solution to automatically generate a meeting summary from a recorded virtual meeting (for example, using Amazon Chime) with several participants. The recording is transcribed to text using Amazon Transcribe and then processed using Amazon SageMaker Hugging Face containers to generate the meeting summary. The Hugging Face containers host a large language model (LLM) from the Hugging Face Hub.
If you prefer to generate post call recording summaries with Amazon Bedrock rather than Amazon SageMaker, checkout this Bedrock sample solution. For a generative AI powered Live Meeting Assistant that creates post call summaries, but also provides live transcripts, translations, and contextual assistance based on your own company knowledge base, see our new LMA solution.
The entire infrastructure of the solution is provisioned using the AWS Cloud Development Kit (AWS CDK), which is an infrastructure as code (IaC) framework to programmatically define and deploy AWS resources. The framework provisions resources in a safe, repeatable manner, allowing for a significant acceleration of the development process.
Amazon Transcribe is a fully managed service that seamlessly runs automatic speech recognition (ASR) workloads in the cloud. The service allows for simple audio data ingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. Amazon Transcribe’s new ASR foundation model supports 100+ language variants. In this post, we use the speaker diarization feature, which enables Amazon Transcribe to differentiate between a maximum of 10 unique speakers and label a conversation accordingly.
Hugging Face is an open-source machine learning (ML) platform that provides tools and resources for the development of AI projects. Its key offering is the Hugging Face Hub, which hosts a vast collection of over 200,000 pre-trained models and 30,000 datasets. The AWS partnership with Hugging Face allows a seamless integration through SageMaker with a set of Deep Learning Containers (DLCs) for training and inference, and Hugging Face estimators and predictors for the SageMaker Python SDK.
Generative AI CDK Constructs, an open-source extension of AWS CDK, provides well-architected multi-service patterns to quickly and efficiently create repeatable infrastructure required for generative AI projects on AWS. For this post, we illustrate how it simplifies the deployment of foundation models (FMs) from Hugging Face or Amazon SageMaker JumpStart with SageMaker real-time inference, which provides persistent and fully managed endpoints to host ML models. They are designed for real-time, interactive, and low-latency workloads and provide auto scaling to manage load fluctuations. For all languages that are supported by Amazon Transcribe, you can find FMs from Hugging Face supporting summarization in corresponding languages
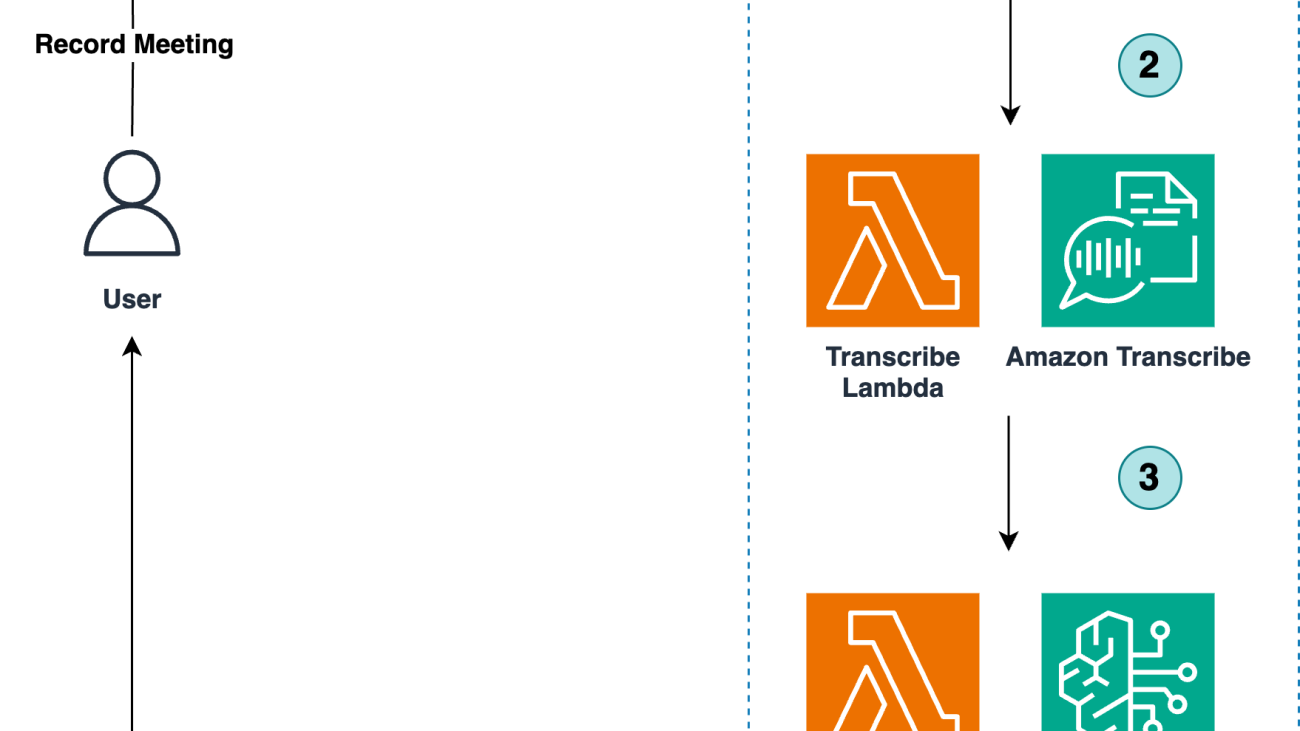
The following diagram depicts the automated meeting summarization workflow.

The workflow consists of the following steps:
/recordings folder./transcriptions/TranscribeOutput/./summaries/InvokeInput/processed-TranscribeOutput/, and invokes a SageMaker endpoint. The endpoint hosts the Hugging Face model that summarizes the processed transcript. The summary is loaded into the S3 bucket under the prefix /summaries. Note that the prompt template used in this example includes a single instruction, however for more sophisticated requirements the template can be easily extended to tailor the solution to your own use case.In this post, we deploy the Mistral 7B Instruct, an LLM available in the Hugging Face Model Hub, to a SageMaker endpoint to perform the summarization tasks. Mistral 7B Instruct is developed by Mistral AI. It is equipped with over 7 billion parameters, enabling it to process and generate text based on user instructions. It has been trained on a wide-ranging corpus of text data to understand various contexts and nuances of language. The model is designed to perform tasks such as answering questions, summarizing information, and creating content, among others, by following specific prompts given by users. Its effectiveness is measured through metrics like perplexity, accuracy, and F1 score, and it is fine-tuned to respond to instructions with relevant and coherent text outputs.
To follow along with this post, you should have the following prerequisites:
To deploy the solution in your own AWS account, refer to the GitHub repository to access the full source code of the AWS CDK project in Python:
If you are deploying AWS CDK assets for the first time in your AWS account and the AWS Region you specified, you need to run the bootstrap command first. It sets up the baseline AWS resources and permissions required for AWS CDK to deploy AWS CloudFormation stacks in a given environment:
Finally, run the following command to deploy the solution. Specify the summary’s recipient mail address in the SubscriberEmailAddress parameter:
We have provided a few sample meeting recordings in the data folder of the project repository. You can upload the test.mp4 recording into the project’s S3 bucket under the /recordings folder. The summary will be saved in Amazon S3 and sent to the subscriber. The end-to-end duration is approximately 2 minutes given an input of approximately 250 tokens.
The following figure shows the input conversation and output summary.
![]()
This solution has the following limitations:
To delete the deployed resources and stop incurring charges, run the following command:
Alternatively, to use the AWS Management Console, complete the following steps:
In this post, we proposed an architecture pattern to automatically transform your meeting recordings into insightful conversation summaries. This workflow showcases how the AWS Cloud and Hugging Face can help you accelerate with your generative AI application development by orchestrating a combination of managed AI services such as Amazon Transcribe, and externally sourced ML models from the Hugging Face Hub such as those from Mistral AI.
If you are eager to learn more about how conversation summaries can apply to a contact center environment, you can deploy this technique in our suite of solutions for Live Call Analytics and Post Call Analytics.
Mistral 7B release post, by Mistral AI
This post has been created by AWS Professional Services, a global team of experts that can help realize desired business outcomes when using the AWS Cloud. We work together with your team and your chosen member of the AWS Partner Network (APN) to implement your enterprise cloud computing initiatives. Our team provides assistance through a collection of offerings that help you achieve specific outcomes related to enterprise cloud adoption. We also deliver focused guidance through our global specialty practices, which cover a variety of solutions, technologies, and industries.
 Gabriel Rodriguez Garcia is a Machine Learning engineer at AWS Professional Services in Zurich. In his current role, he has helped customers achieve their business goals on a variety of ML use cases, ranging from setting up MLOps inference pipelines to developing a fraud detection application. Whenever he is not working, he enjoys doing physical activities, listening to podcasts, or reading books.
Gabriel Rodriguez Garcia is a Machine Learning engineer at AWS Professional Services in Zurich. In his current role, he has helped customers achieve their business goals on a variety of ML use cases, ranging from setting up MLOps inference pipelines to developing a fraud detection application. Whenever he is not working, he enjoys doing physical activities, listening to podcasts, or reading books.
 Jahed Zaïdi is an AI & Machine Learning specialist at AWS Professional Services in Paris. He is a builder and trusted advisor to companies across industries, helping businesses innovate faster and on a larger scale with technologies ranging from generative AI to scalable ML platforms. Outside of work, you will find Jahed discovering new cities and cultures, and enjoying outdoor activities.
Jahed Zaïdi is an AI & Machine Learning specialist at AWS Professional Services in Paris. He is a builder and trusted advisor to companies across industries, helping businesses innovate faster and on a larger scale with technologies ranging from generative AI to scalable ML platforms. Outside of work, you will find Jahed discovering new cities and cultures, and enjoying outdoor activities.
 Mateusz Zaremba is a DevOps Architect at AWS Professional Services. Mateusz supports customers at the intersection of machine learning and DevOps specialization, helping them to bring value efficiently and securely. Beyond tech, he is an aerospace engineer and avid sailor.
Mateusz Zaremba is a DevOps Architect at AWS Professional Services. Mateusz supports customers at the intersection of machine learning and DevOps specialization, helping them to bring value efficiently and securely. Beyond tech, he is an aerospace engineer and avid sailor.
 Kemeng Zhang is currently working at AWS Professional Services in Zurich, Switzerland, with a specialization in AI/ML. She has been part of multiple NLP projects, from behavioral change in digital communication to fraud detection. Apart from that, she is interested in UX design and playing cards.
Kemeng Zhang is currently working at AWS Professional Services in Zurich, Switzerland, with a specialization in AI/ML. She has been part of multiple NLP projects, from behavioral change in digital communication to fraud detection. Apart from that, she is interested in UX design and playing cards.
This post is co-written with Tim Camara, Senior Product Manager at Veritone.
Veritone is an artificial intelligence (AI) company based in Irvine, California. Founded in 2014, Veritone empowers people with AI-powered software and solutions for various applications, including media processing, analytics, advertising, and more. It offers solutions for media transcription, facial recognition, content summarization, object detection, and other AI capabilities to solve the unique challenges professionals face across industries.
Veritone began its journey with its foundational AI operating system, aiWARETM, solving industry and brand-specific challenges by building applications on top of this powerful technology. Growing in the media and entertainment space, Veritone solves media management, broadcast content, and ad tracking issues. Alongside these applications, Veritone offers media services including AI-powered audio advertising and influencer marketing, content licensing and media monetization services, and professional services to build bespoke AI solutions.
With a decade of enterprise AI experience, Veritone supports the public sector, working with US federal government agencies, state and local government, law enforcement agencies, and legal organizations to automate and simplify evidence management, redaction, person-of-interest tracking, and eDiscovery. Veritone has also expanded into the talent acquisition space, serving HR teams worldwide with its powerful programmatic job advertising platform and distribution network.
Using generative AI and new multimodal foundation models (FMs) could be very strategic for Veritone and the businesses they serve, because it would significantly improve media indexing and retrieval based on contextual meaning—a critical first step to eventually generating new content. Building enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content, allowing customers to produce customized media more efficiently.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. With recent advances in large language models (LLMs), Veritone has updated its platform with these powerful new AI capabilities. Looking ahead, Veritone wants to take advantage of new advanced FM techniques to improve the quality of media search results of “Digital Media Hub”( DMH ) and grow the number of users by achieving a better user experience.
In this post, we demonstrate how to use enhanced video search capabilities by enabling semantic retrieval of videos based on text queries. We match the most relevant videos to text-based search queries by incorporating new multimodal embedding models like Amazon Titan Multimodal Embeddings to encode all visual, visual-meta, and transcription data. The primary focus is building a robust text search that goes beyond traditional word-matching algorithms as well as an interface for comparing search algorithms. Additionally, we explore narrowing retrieval to specific shots within videos (a shot is a series of interrelated consecutive pictures taken contiguously by a single camera representing a continuous action in time and space). Overall, we aim to improve video search through cutting-edge semantic matching, providing an efficient way to find videos relevant to your rich textual queries.
We use the following AWS services to implement the solution:
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon within a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
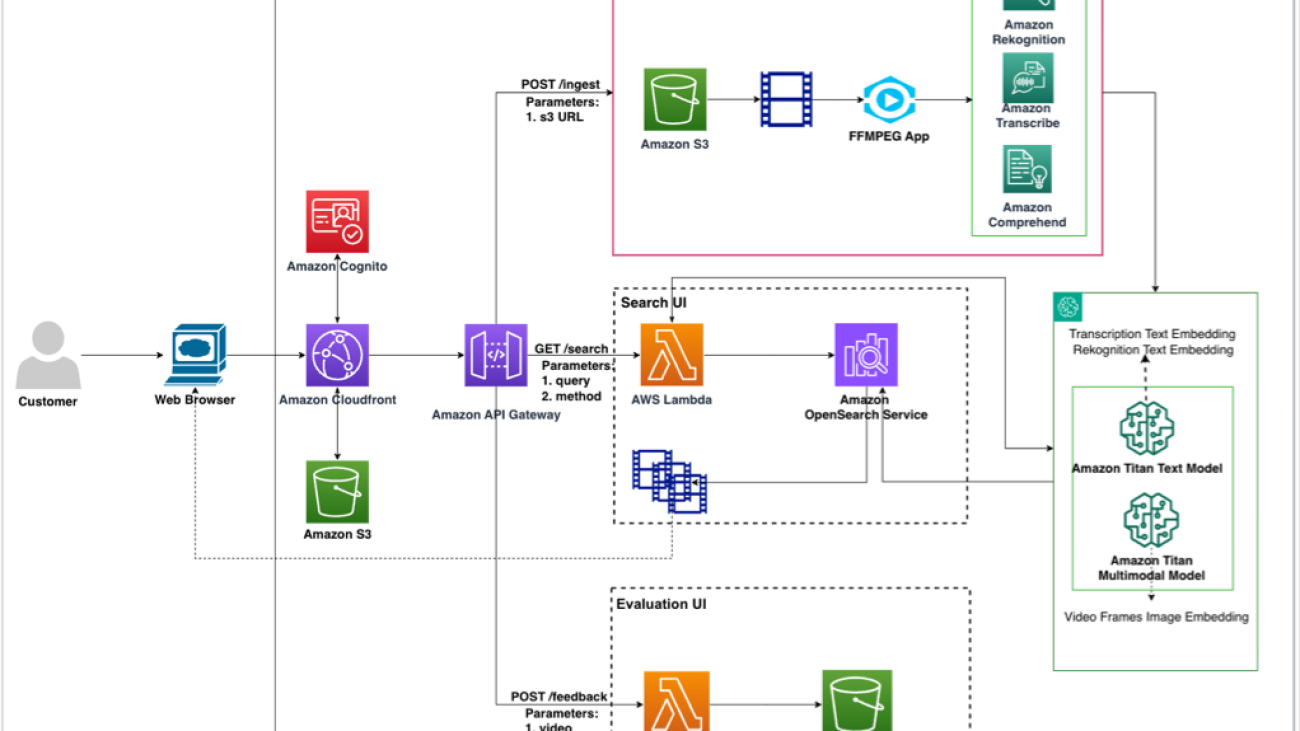
The current architecture consists of three components:
The following diagram illustrates the solution architecture.

The high-level takeaways from this work are the following:
Detailed quantitative analysis of these conclusions is discussed later in this post.
The video metadata generation pipeline consists of processing video files using AWS services such as Amazon Transcribe, Amazon Rekognition, and Amazon Comprehend, as shown in the following diagram. The metadata is generated at the shot level for a video.

In this section, we discuss the details of each service and the workflow in more detail.
The transcription for the entire video is generated using the StartTranscriptionJob API. When the job is complete, you can obtain the raw transcript data using GetTranscriptionJob. The GetTranscriptionJob returns a TranscriptFileUri, which can be processed to get the speakers and transcripts based on a timestamp. The file formats supported by Amazon Transcribe are AMR, FLAC (recommended), M4A, MP3, MP4, Ogg, WebM, and WAV (recommended).
The raw transcripts are further processed to be stored using timestamps, as shown in the following example.

Amazon Rekognition requires the video to be encoded using the H.264 codec and formatted to either MPEG-4 or MOV. We used FFmpeg to format the videos in Amazon S3 to the required vcodec. FFmpeg is a free and open-source software project in the form of a command line tool designed for processing video, audio, and other multimedia files and streams. Python provides a wrapper library around the tool called ffmpeg-python.
The solution runs Amazon Rekognition APIs for label detection, text detection, celebrity detection, and face detection on videos. The metadata generated for each video by the APIs is processed and stored with timestamps. The videos are then segmented into individual shots. With Amazon Rekognition, you can detect the start, end, and duration of each shot as well as the total shot count for a content piece. The video shot detection job starts with the StartSegmentDetection API, which returns a jobId that can be used to monitor status with the GetSegmentDetection API. When the video segmentation status changes to Succeeded, for each shot, you parse the previously generated Amazon Rekognition API metadata using the shot’s timestamp. You then append this parsed metadata to the shot record. Similarly, the full transcript from Amazon Transcribe is segmented using the shot start and end timestamps to create shot-level transcripts.
The temporal transcripts are then processed by Amazon Comprehend to detect entities and sentiments using the DetectEntities, DetectSentiment, and DetectTargetedSentiment APIs. The following code gives more details on the API requests and responses used to generate metadata by using sample shot-level metadata generated for a video:

The shot-level metadata generated by the pipeline is processed to stage it for embedding generation. The goal of this processing is to aggregate useful information and remove null or less significant information that wouldn’t add value for embedding generation.
The processing algorithm is as follows:
rekognition_metadata - shot_metadata: extract StartFrameNumber and EndFrameNumber - celeb_metadata: extract celeb_metadata - label_metadata: extract unique labels - text_metadata: extract unique text labels if there are more than 3 words (comes noisy with "-", "null" and other values) - face_analysis_metadata: extract unique list of AgeRange, Emotions, GenderWe combine all rekognition text data into `rek_text_metadata` stringtranscribe_metadata - transcribe_metadata: check the wordcount of the conversation across all speakers.if it is more than 50 words, mark it for summarization task with Amazon Bedrockcomprehend_metadata - comprehend_metadata: extract sentiment - comprehend_metadata: extract target sentiment scores for words with score > 0.9
Large transcripts from the processed metadata are summarized through the Anthropic Claude 2 model. After summarizing the transcript, we extract the names of the key characters mentioned in the summary as well the important keywords.
In this section, we discuss the details for generating shot-level and video-level embeddings.
We generate two types of embeddings: text and multimodal. To understand which metadata and service contributes to the search performance and by how much, we create a varying set of embeddings for experimental analysis.
We implement the following with Amazon Titan Multimodal Embeddings:
We implement the following with the Amazon Titan Text Embeddings model:
If a video has only one shot (a small video capturing a single action), the embeddings will be the same as shot-level embeddings.
For videos that have more than one shot, we implement the following using the Amazon Titan Multimodal Embeddings Model:
We implement the following using the Amazon Titan Text Embeddings model:
In this section, we discuss the components of the search pipeline.
We use an OpenSearch cluster (OpenSearch Service domain) with t3.medium.search to store and retrieve indexes for our experimentation with text, knn_vector, and Boolean fields indexed. We recommend exploring Amazon OpenSearch Serverless for production deployment for indexing and retrieval. OpenSearch Serverless can index billions of records and has expanded its auto scaling capabilities to efficiently handle tens of thousands of query transactions per minute.
The following screenshots are examples of the text, Boolean, and embedding fields that we created.



The following diagram illustrates the query workflow.

You can use a user query to compare the video records using text or semantic (embedding) search for retrieval.
For text-based retrieval, we use the search query as input to retrieve results from OpenSearch Service using the search fields transcribe_metadata, transcribe_summary, transcribe_keyword, transcribe_speakers, and rek_text_metadata:
OpenSearch Input
search_fields=[
"transcribe_metadata",
"transcribe_summary",
"transcribe_keyword",
"transcribe_speakers",
"rek_text_metadata"
]search_body = {
"query": {
"multi_match": {
"query": search_query,
"fields": search_fields
}
}
}For semantic retrieval, the query is embedded using the amazon.Titan-embed-text-v1 or amazon.titan-embed-image-v1 model, which is then used as an input to retrieve results from OpenSearch Service using the search field name, which could match with the metadata embedding of choice:
OpenSearch Input
search_body = {
"size": <number of top results>,
"fields": ["name"],
"query": {
"knn": {
vector_field: {"vector": <embedding>, "k": <length of embedding>}
}
},
}
Exact match and semantic search have their own benefits depending on the application. Users who search for a specific celebrity or movie name would benefit from an exact match search, whereas users looking for thematic queries like “summer beach vibes” and “candlelit dinner” would find semantic search results more applicable. To enable the best of both, we combine the results from both types of searches. Additionally, different embeddings could capture different semantics (for example, Amazon Transcribe text embedding vs. image embedding with a multimodal model). Therefore, we also explore combining different semantic search results.
To combine search results from different search methods and different score ranges, we used the following logic:
rank_norm.We use the rank_norm method, where the score is calculated based on the rank of each video in the list. The following is the Python implementation of this method:
def rank_norm(results):
n_results = len(results)
normalized_results = {}
for i, doc_id in enumerate(results.keys()):
normalized_results[doc_id] = 1 - (i / n_results)
ranked_normalized_results = sorted(
normalized_results.items(), key=lambda x: x[1], reverse=True
)
return dict(ranked_normalized_results)
In this section, we discuss the components of the evaluation pipeline.
The following diagram illustrates the architecture of the search and evaluation UI.

The UI webpage is hosted in an S3 bucket and deployed using Amazon CloudFront distributions. The current approach uses an API key for authentication. This can be enhanced by using Amazon Cognito and registering users. The user can perform two actions on the webpage:
We create two API endpoints using Amazon API Gateway: GET /search and POST /feedback. The following screenshot illustrates our UI with two retrieval methods that have been anonymized for the user for a bias-free evaluation.

We pass two QueryStringParameters with this API call:
This API is created with a proxy integration with a Lambda function invoked. The Lambda function processes the query and, based on the method used, retrieves results from OpenSearch Service. The results are then processed to retrieve videos from the S3 bucket and displayed on the webpage. In the search UI, we use a specific method (search setting) to retrieve results:
Request?query=<>&method=<>
Response
{
"results": [
{"name": <video-name>, "score": <score>},
{"name": <video-name>, "score": <score>},
...
]
}
The following is a sample request:
?query=candlelit dinner&method=MethodB
The following screenshot shows our results.

Given a query, each method will have video content and the video name displayed on the webpage. Based on the relevance of the results, the user can vote if a particular method has better performance over the other (win or lose) or if the methods are tied. The API has a proxy connection to Lambda. Lambda stores these results into an S3 bucket. In the evaluation UI, you can analyze the method search results to find the best search configuration setting. The request body includes the following syntax:
Request Body
{
"result": <winning method>,
"searchQuery":<query>,
"sessionId":<current-session-id>,
"Method<>":{
"methodType": <Type of method used>,
"results":"[{"name":<video-name>,"score":<score>}]"},
"Method<>":{
"methodType": <Type of method used>,
"results":"[{"name":"1QT426_s01","score":1.5053753}]"}
}The following screenshot shows a sample request.

In this section, we discuss the datasets used in our experiments and the quantitative and qualitative evaluations based on the results.
This dataset includes 500 videos with an average length of 20 seconds. Each video has manually written metadata such as keywords and descriptions. In general, the videos in this dataset are related to travel, vacations, and restaurants topics.
The majority of videos are less than 20 seconds and the maximum is 400 seconds, as illustrated in the following figure.

The second dataset has 300 high-definition videos with a video length ranging from 20–160 minutes, as illustrated in the following figure.

We use the following metrics in our quantitative evaluation:
A, B, C are related (GT)A, D, N, M, G are the TopK retrieved videosRecall @TOP5 = 1/3
We compute these metrics using a ground truth dataset provided by Veritone that had mappings of search query examples to relevant video IDs.
The following table summarizes the top three retrieval methods from the long videos dataset (% improvement over baseline).
| Methods | Video Level: MRR vs. Video-level Baseline MRR | Shot Level: MRR vs. Video-level Baseline MRR | Video Level: Recall@top10 vs. Video-level Baseline Recall@top10 | Shot Level: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Raw Text: Amazon Transcribe + Amazon Rekognition | Baseline comparison | N/A | . | . |
| Semantic: Amazon Transcribe + Amazon Rekognition | 0.84% | 52.41% | 19.67% | 94.00% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 37.31% | 81.19% | 71.00% | 93.33% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 15.56% | 58.54% | 61.33% | 121.33% |
The following are our observations on the MRR and recall results:
The following table summarizes the top three retrieval methods from the short videos dataset (% improvement over baseline).
| Methods | Video Level: MRR vs. Video-level Baseline MRR | Shot Level: MRR vs. Video-level Baseline MRR | Video Level: Recall@top10 vs. Video-Level Baseline Recall@top10 | Shot Level: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Raw Text: Amazon Transcribe + Amazon Rekognition | Baseline | N/A | Baseline | N/A |
| Semantic: Amazon Titan Multimodal | 226.67% | 226.67% | 373.57% | 382.61% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 100.00% | 60.00% | 299.28% | 314.29% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 53.33% | 53.33% | 307.21% | 312.77% |
We made the following observations on the MRR and recall results:
We evaluated the quantitative results from our pipeline to find matches with the ground truth shared by Veritone. However, there could be other relevant videos in the retrieved results from our pipeline that are not part of the ground truth, which could further improve some of these metrics. Therefore, to qualitatively evaluate our pipeline, we used an A/B testing framework, where a user can view results from two anonymized methods (the metadata used by the method is not exposed to reduce any bias) and rate which results were more aligned with the query entered.
The aggregated results across the method comparison were used to calculate the win rate to select the final embedding method for search pipeline.
The following methods were shortlisted based on Veritone’s interest to reduce multiple comparison methods.
| Method Name (Exposed to User) | Retrieval Type (Not Exposed to User) |
| Method E | Just semantic Amazon Transcribe retrieval results |
| Method F | Fusion of semantic Amazon Transcribe + Amazon Titan Multimodal retrieval results |
| Method G | Fusion of semantic Amazon Transcribe + semantic Amazon Rekognition + Amazon Titan Multimodal retrieval results |
The following table summarizes the quantitative results and winning rate.
| Experiment | Winning Method (Count of Queries) | . | . |
| Method E | Method F | Tie | |
| Method E vs. Method F | 10% | 85% | 5% |
| Method F | Method G | Tie | |
| Method F vs. Method G | 30% | 60% | 10% |
Based on the results, we see that adding Amazon Titan Multimodal Embeddings to the transcription method (Method F) is better than just using semantic transcription retrieval (Method E). Adding Amazon Rekognition based retrieval results (Method G) improves over Method F.
We had the following key takeaways:
We recommend the following security guidelines for building secure applications on AWS:
In this post, we showed how Veritone upgraded their classical search pipelines with Amazon Titan Multimodal Embeddings in Amazon Bedrock through a few API calls. We showed how videos can be indexed in different representations, text vs. text embeddings vs. multimodal embeddings, and how they can be analyzed to produce a robust search based on the data characteristics and use case.
If you are interested in working with the AWS Generative AI Innovation Center, please reach out to the GenAIIC.
 Tim Camara is a Senior Product Manager on the Digital Media Hub team at Veritone. With over 15 years of experience across a range of technologies and industries, he’s focused on finding ways to use emerging technologies to improve customer experiences.
Tim Camara is a Senior Product Manager on the Digital Media Hub team at Veritone. With over 15 years of experience across a range of technologies and industries, he’s focused on finding ways to use emerging technologies to improve customer experiences.
 Mohamad Al Jazaery is an Applied Scientist at the Generative AI Innovation Center. As a scientist and tech lead, he helps AWS customers envision and build GenAI solutions to address their business challenges in different domains such as Media and Entertainment, Finance, and Lifestyle.
Mohamad Al Jazaery is an Applied Scientist at the Generative AI Innovation Center. As a scientist and tech lead, he helps AWS customers envision and build GenAI solutions to address their business challenges in different domains such as Media and Entertainment, Finance, and Lifestyle.

Meghana Ashok is a Machine Learning Engineer at the Generative AI Innovation Center. She collaborates closely with customers, guiding them in developing secure, cost-efficient, and resilient solutions and infrastructure tailored to their generative AI needs.
 Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding and retrieval, knowledge graph augmented large language models, and personalized advertising use cases.
Divya Bhargavi is a Senior Applied Scientist Lead at the Generative AI Innovation Center, where she solves high-value business problems for AWS customers using generative AI methods. She works on image/video understanding and retrieval, knowledge graph augmented large language models, and personalized advertising use cases.
 Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he uses his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.