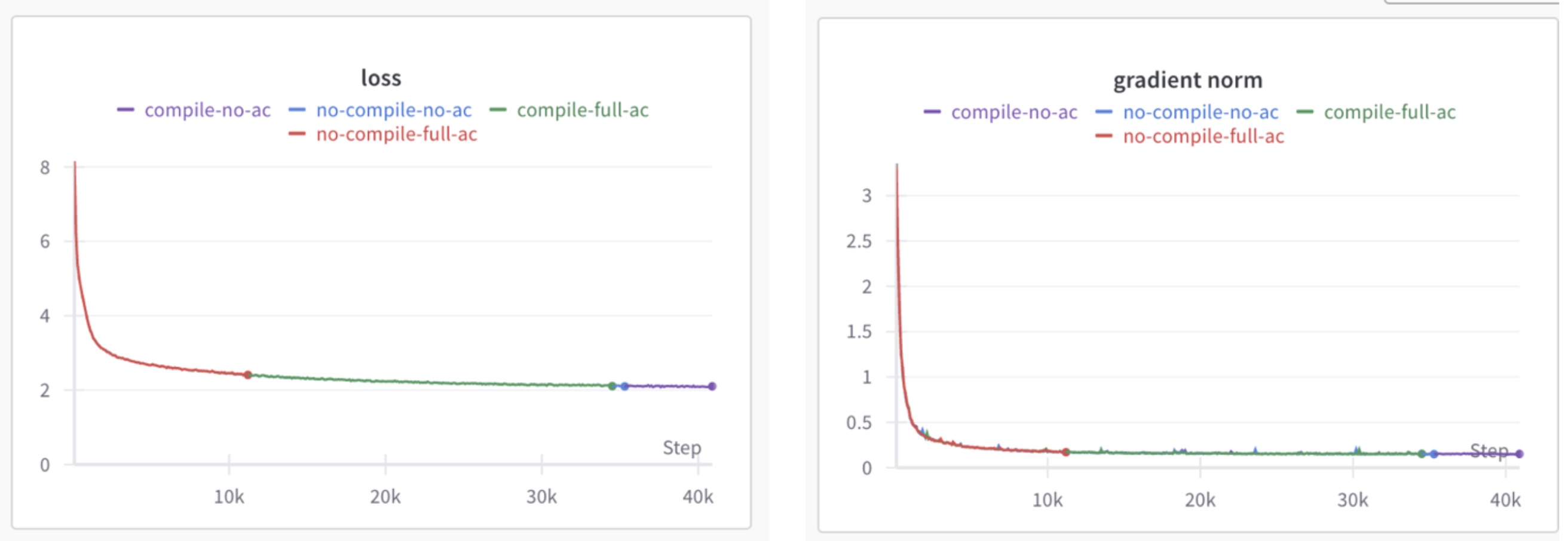
If optimized AI workflows are like a perfectly tuned orchestra — where each component, from hardware infrastructure to software libraries, hits exactly the right note — then the long-standing harmony between NVIDIA and Microsoft is music to developers’ ears.
The latest AI models developed by Microsoft, including the Phi-3 family of small language models, are being optimized to run on NVIDIA GPUs and made available as NVIDIA NIM inference microservices. Other microservices developed by NVIDIA, such as the cuOpt route optimization AI, are regularly added to Microsoft Azure Marketplace as part of the NVIDIA AI Enterprise software platform.
In addition to these AI technologies, NVIDIA and Microsoft are delivering a growing set of optimizations and integrations for developers creating high-performance AI apps for PCs powered by NVIDIA GeForce RTX and NVIDIA RTX GPUs.
Building on the progress shared at NVIDIA GTC, the two companies are furthering this ongoing collaboration at Microsoft Build, an annual developer event, taking place this year in Seattle through May 23.
Accelerating Microsoft’s Phi-3 Models
Microsoft is expanding its family of Phi-3 open small language models, adding small (7-billion-parameter) and medium (14-billion-parameter) models similar to its Phi-3-mini, which has 3.8 billion parameters. It’s also introducing a new 4.2-billion-parameter multimodal model, Phi-3-vision, that supports images and text.
All of these models are GPU-optimized with NVIDIA TensorRT-LLM and available as NVIDIA NIMs, which are accelerated inference microservices with a standard application programming interface (API) that can be deployed anywhere.
APIs for the NIM-powered Phi-3 models are available at ai.nvidia.com and through NVIDIA AI Enterprise on the Azure Marketplace.
NVIDIA cuOpt Now Available on Azure Marketplace
NVIDIA cuOpt, a GPU-accelerated AI microservice for route optimization, is now available in Azure Marketplace via NVIDIA AI Enterprise. cuOpt features massively parallel algorithms that enable real-time logistics management for shipping services, railway systems, warehouses and factories.
The model has set two dozen world records on major routing benchmarks, demonstrating the best accuracy and fastest times. It could save billions of dollars for the logistics and supply chain industries by optimizing vehicle routes, saving travel time and minimizing idle periods.
Through Azure Marketplace, developers can easily integrate the cuOpt microservice with Azure Maps to support teal-time logistics management and other cloud-based workflows, backed by enterprise-grade management tools and security.
Optimizing AI Performance on PCs With NVIDIA RTX
The NVIDIA accelerated computing platform is the backbone of modern AI — helping developers build solutions for over 100 million Windows GeForce RTX-powered PCs and NVIDIA RTX-powered workstations worldwide.
NVIDIA and Microsoft are delivering new optimizations and integrations to Windows developers to accelerate AI in next-generation PC and workstation applications. These include:
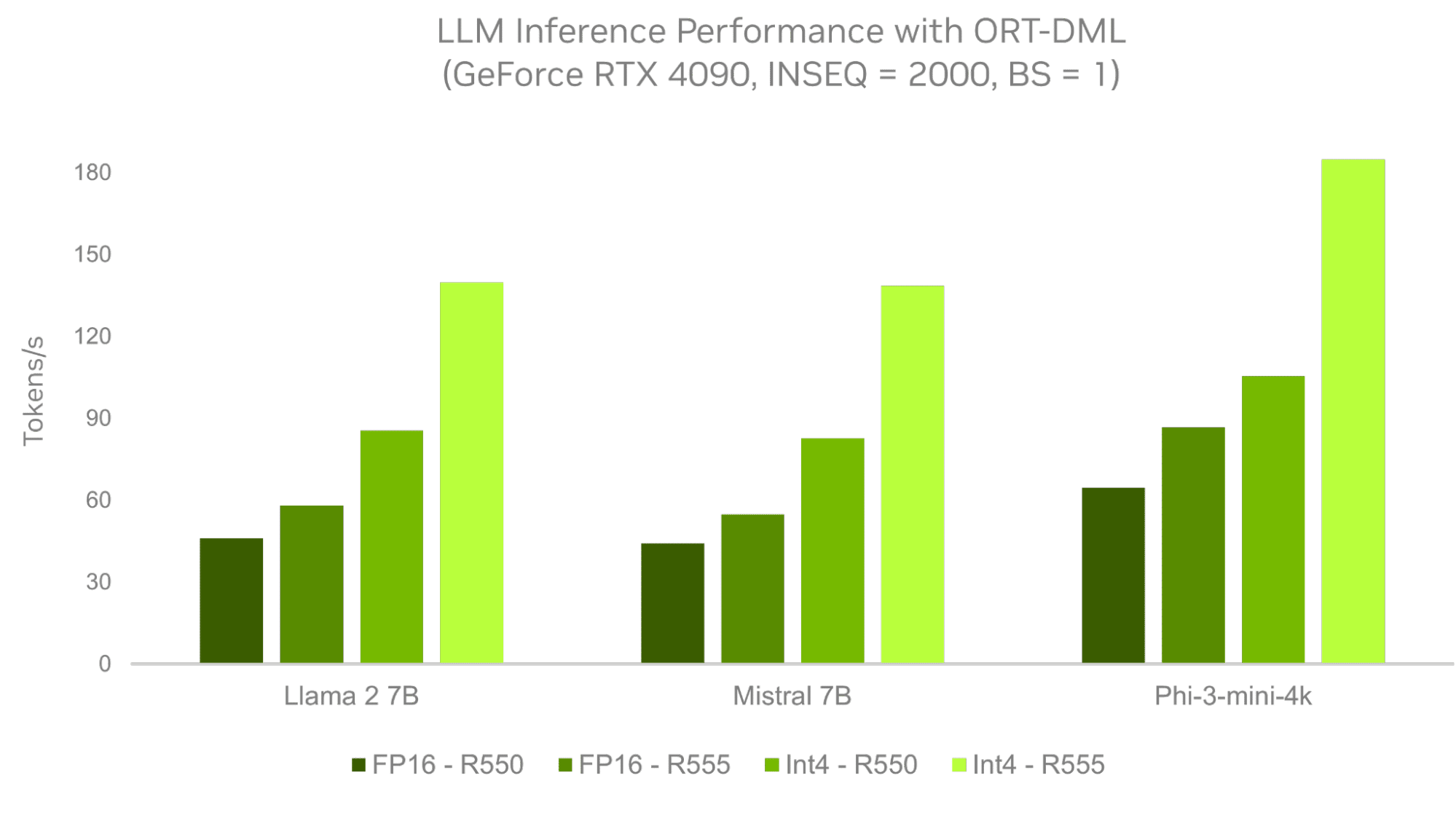
- Faster inference performance for large language models via the NVIDIA DirectX driver, the Generative AI ONNX Runtime extension and DirectML. These optimizations, available now in the GeForce Game Ready, NVIDIA Studio and NVIDIA RTX Enterprise Drivers, deliver up to 3x faster performance on NVIDIA and GeForce RTX GPUs.
- Optimized performance on RTX GPUs for AI models like Stable Diffusion and Whisper via WebNN, an API that enables developers to accelerate AI models in web applications using on-device hardware.
- With Windows set to support PyTorch through DirectML, thousands of Hugging Face models will work in Windows natively. NVIDIA and Microsoft are collaborating to scale performance on more than 100 million RTX GPUs.
Join NVIDIA at Microsoft Build
Conference attendees can visit NVIDIA booth FP28 to meet developer experts and experience live demos of NVIDIA NIM, NVIDIA cuOpt, NVIDIA Omniverse and the NVIDIA RTX AI platform. The booth also highlights the NVIDIA MONAI platform for medical imaging workflows and NVIDIA BioNeMo generative AI platform for drug discovery — both available on Azure as part of NVIDIA AI Enterprise.
Attend sessions with NVIDIA speakers to dive into the capabilities of the NVIDIA RTX AI platform on Windows PCs and discover how to deploy generative AI and digital twin tools on Microsoft Azure.
And sign up for the Developer Showcase, taking place Wednesday, to discover how developers are building innovative generative AI using NVIDIA AI software on Azure.