How summits in Seoul, France and beyond can galvanize international cooperation on frontier AI safetyRead More

How summits in Seoul, France and beyond can galvanize international cooperation on frontier AI safetyRead More

How summits in Seoul, France and beyond can galvanize international cooperation on frontier AI safetyRead More
Much of early literacy education happens at home with caretakers reading books to young children. Prior research demonstrates how having dialogue with children during co-reading can develop critical reading readiness skills, but most adult readers are unsure if and how to lead effective conversations. We present ContextQ, a tablet-based reading application to unobtrusively present auto-generated dialogic questions to caretakers to support this dialogic reading practice. An ablation study demonstrates how our method of encoding educator expertise into the question generation pipeline can…Apple Machine Learning Research
Application developers advertise their Apps by creating product pages with App images, and bidding on search terms. It is then crucial for App images to be highly relevant with the search terms. Solutions to this problem require an image-text matching model to predict the quality of the match between the chosen image and the search terms. In this work, we present a novel approach to matching an App image to search terms based on fine-tuning a pre-trained LXMERT model. We show that compared to the CLIP model and a baseline using a Transformer model for search terms, and a ResNet model for…Apple Machine Learning Research
Today, we are excited to announce the Mixtral-8x22B large language model (LLM), developed by Mistral AI, is available for customers through Amazon SageMaker JumpStart to deploy with one click for running inference. You can try out this model with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms and models so you can quickly get started with ML. In this post, we walk through how to discover and deploy the Mixtral-8x22B model.
Mixtral 8x22B is Mistral AI’s latest open-weights model and sets a new standard for performance and efficiency of available foundation models, as measured by Mistral AI across standard industry benchmarks. It is a sparse Mixture-of-Experts (SMoE) model that uses only 39 billion active parameters out of 141 billion, offering cost-efficiency for its size. Continuing with Mistral AI’s belief in the power of publicly available models and broad distribution to promote innovation and collaboration, Mixtral 8x22B is released under Apache 2.0, making the model available for exploring, testing, and deploying. Mixtral 8x22B is an attractive option for customers selecting between publicly available models and prioritizing quality, and for those wanting a higher quality from mid-sized models, such as Mixtral 8x7B and GPT 3.5 Turbo, while maintaining high throughput.
Mixtral 8x22B provides the following strengths:
Mistral AI is a Paris-based company founded by seasoned researchers from Meta and Google DeepMind. During his time at DeepMind, Arthur Mensch (Mistral CEO) was a lead contributor on key LLM projects such as Flamingo and Chinchilla, while Guillaume Lample (Mistral Chief Scientist) and Timothée Lacroix (Mistral CTO) led the development of LLaMa LLMs during their time at Meta. The trio are part of a new breed of founders who combine deep technical expertise and operating experience working on state-of-the-art ML technology at the largest research labs. Mistral AI has championed small foundational models with superior performance and commitment to model development. They continue to push the frontier of artificial intelligence (AI) and make it accessible to everyone with models that offer unmatched cost-efficiency for their respective sizes, delivering an attractive performance-to-cost ratio. Mixtral 8x22B is a natural continuation of Mistral AI’s family of publicly available models that include Mistral 7B and Mixtral 8x7B, also available on SageMaker JumpStart. More recently, Mistral launched commercial enterprise-grade models, with Mistral Large delivering top-tier performance and outperforming other popular models with native proficiency across multiple languages.
With SageMaker JumpStart, ML practitioners can choose from a growing list of best-performing foundation models. ML practitioners can deploy foundation models to dedicated Amazon SageMaker instances within a network isolated environment, and customize models using SageMaker for model training and deployment. You can now discover and deploy Mixtral-8x22B with a few clicks in Amazon SageMaker Studio or programmatically through the SageMaker Python SDK, enabling you to derive model performance and MLOps controls with SageMaker features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your VPC controls, providing data encryption at rest and in-transit.
SageMaker also adheres to standard security frameworks such as ISO27001 and SOC1/2/3 in addition to complying with various regulatory requirements. Compliance frameworks like General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA), Health Insurance Portability and Accountability Act (HIPAA), and Payment Card Industry Data Security Standard (PCI DSS) are supported to make sure data handling, storing, and process meet stringent security standards.
SageMaker JumpStart availability is dependent on the model; Mixtral-8x22B v0.1 is currently supported in the US East (N. Virginia) and US West (Oregon) AWS Regions.
You can access Mixtral-8x22B foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all ML development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
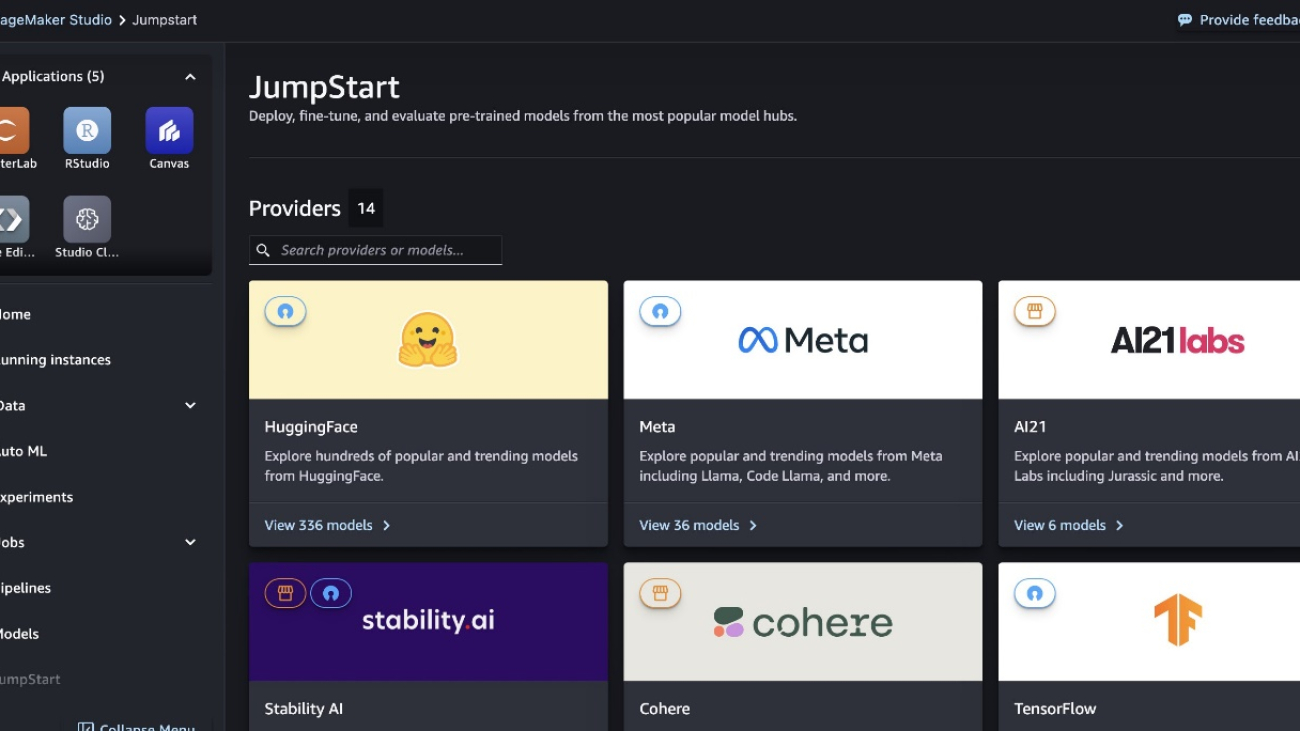
In SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane.

From the SageMaker JumpStart landing page, you can search for “Mixtral” in the search box. You will see search results showing Mixtral 8x22B Instruct, various Mixtral 8x7B models, and Dolphin 2.5 and 2.7 models.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You will also find the Deploy button, which you can use to deploy the model and create an endpoint.
SageMaker has seamless logging, monitoring, and auditing enabled for deployed models with native integrations with services like AWS CloudTrail for logging and monitoring to provide insights into API calls and Amazon CloudWatch to collect metrics, logs, and event data to provide information into the model’s resource utilization.

Deployment starts when you choose Deploy. After deployment finishes, an endpoint has been created. You can test the endpoint by passing a sample inference request payload or selecting your testing option using the SDK. When you select the option to use the SDK, you will see example code that you can use in your preferred notebook editor in SageMaker Studio. This will require an AWS Identity and Access Management (IAM) role and policy attached to it to restrict model access. Additionally, if you choose to deploy the model endpoint within SageMaker Studio, you will be prompted to choose an instance type, initial instance count, and maximum instance count. The ml.p4d.24xlarge and ml.p4de.24xlarge instance types are the only instance types currently supported for Mixtral 8x22B Instruct v0.1.
To deploy using the SDK, we start by selecting the Mixtral-8x22b model, specified by the model_id with value huggingface-llm-mistralai-mixtral-8x22B-instruct-v0-1. You can deploy any of the selected models on SageMaker with the following code. Similarly, you can deploy Mixtral-8x22B instruct using its own model ID.
This deploys the model on SageMaker with default configurations, including the default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel.
After it’s deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
You can interact with a Mixtral-8x22B model like any standard text generation model, where the model processes an input sequence and outputs predicted next words in the sequence. In this section, we provide example prompts.
The instruction-tuned version of Mixtral-8x22B accepts formatted instructions where conversation roles must start with a user prompt and alternate between user instruction and assistant (model answer). The instruction format must be strictly respected, otherwise the model will generate sub-optimal outputs. The template used to build a prompt for the Instruct model is defined as follows:
<s> and </s> are special tokens for beginning of string (BOS) and end of string (EOS), whereas [INST] and [/INST] are regular strings.
The following code shows how you can format the prompt in instruction format:
You can use the following code to get a response for a summarization:
The following is an example of the expected output:
You can use the following code to get a response for a multilingual translation:
The following is an example of the expected output:
You can use the following code to get a response for code generation:
You get the following output:
You can use the following code to get a response for reasoning and math:
You get the following output:
After you’re done running the notebook, delete all resources that you created in the process so your billing is stopped. Use the following code:
In this post, we showed you how to get started with Mixtral-8x22B in SageMaker Studio and deploy the model for inference. Because foundation models are pre-trained, they can help lower training and infrastructure costs and enable customization for your use case. Visit SageMaker JumpStart in SageMaker Studio now to get started.
Now that you are aware of Mistral AI and their Mixtral 8x22B models, we encourage you to deploy an endpoint on SageMaker to perform inference testing and try out responses for yourself. Refer to the following resources for more information:
 Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers and acquisitions. Marco is based in Seattle, WA, and enjoys writing, reading, exercising, and building applications in his free time.
Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions, and conducting research to help customers hyper-scale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers and acquisitions. Marco is based in Seattle, WA, and enjoys writing, reading, exercising, and building applications in his free time.
 Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
Preston Tuggle is a Sr. Specialist Solutions Architect working on generative AI.
 June Won is a product manager with Amazon SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery.
June Won is a product manager with Amazon SageMaker JumpStart. He focuses on making foundation models easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping application and last mile delivery.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
 Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers.
Shane Rai is a Principal GenAI Specialist with the AWS World Wide Specialist Organization (WWSO). He works with customers across industries to solve their most pressing and innovative business needs using AWS’s breadth of cloud-based AI/ML services including model offerings from top tier foundation model providers.
 Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Hemant Singh is an Applied Scientist with experience in Amazon SageMaker JumpStart. He got his master’s from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He has experience in working on a diverse range of machine learning problems within the domain of natural language processing, computer vision, and time series analysis.
Generative AI is a type of artificial intelligence (AI) that can be used to create new content, including conversations, stories, images, videos, and music. Like all AI, generative AI works by using machine learning models—very large models that are pretrained on vast amounts of data called foundation models (FMs). FMs are trained on a broad spectrum of generalized and unlabeled data. They’re capable of performing a wide variety of general tasks with a high degree of accuracy based on input prompts. Large language models (LLMs) are one class of FMs. LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction.
FMs and LLMs, even though they’re pre-trained, can continue to learn from data inputs or prompts during inference. This means that you can develop comprehensive outputs through carefully curated prompts. A prompt is the information you pass into an LLM to elicit a response. This includes task context, data that you pass to the model, conversation and action history, instructions, and even examples. The process of designing and refining prompts to get specific responses from these models is called prompt engineering.
While LLMs are good at following instructions in the prompt, as a task gets complex, they’re known to drop tasks or perform a task not at the desired accuracy. LLMs can handle complex tasks better when you break them down into smaller subtasks. This technique of breaking down a complex task into subtasks is called prompt chaining. With prompt chaining, you construct a set of smaller subtasks as individual prompts. Together, these subtasks make up the overall complex task. To accomplish the overall task, your application feeds each subtask prompt to the LLM in a pre-defined order or according to a set of rules.
While Generative AI can create highly realistic content, including text, images, and videos, it can also generate outputs that appear plausible but are verifiably incorrect. Incorporating human judgment is crucial, especially in complex and high-risk decision-making scenarios. This involves building a human-in-the-loop process where humans play an active role in decision making alongside the AI system.
In this blog post, you will learn about prompt chaining, how to break a complex task into multiple tasks to use prompt chaining with an LLM in a specific order, and how to involve a human to review the response generated by the LLM.
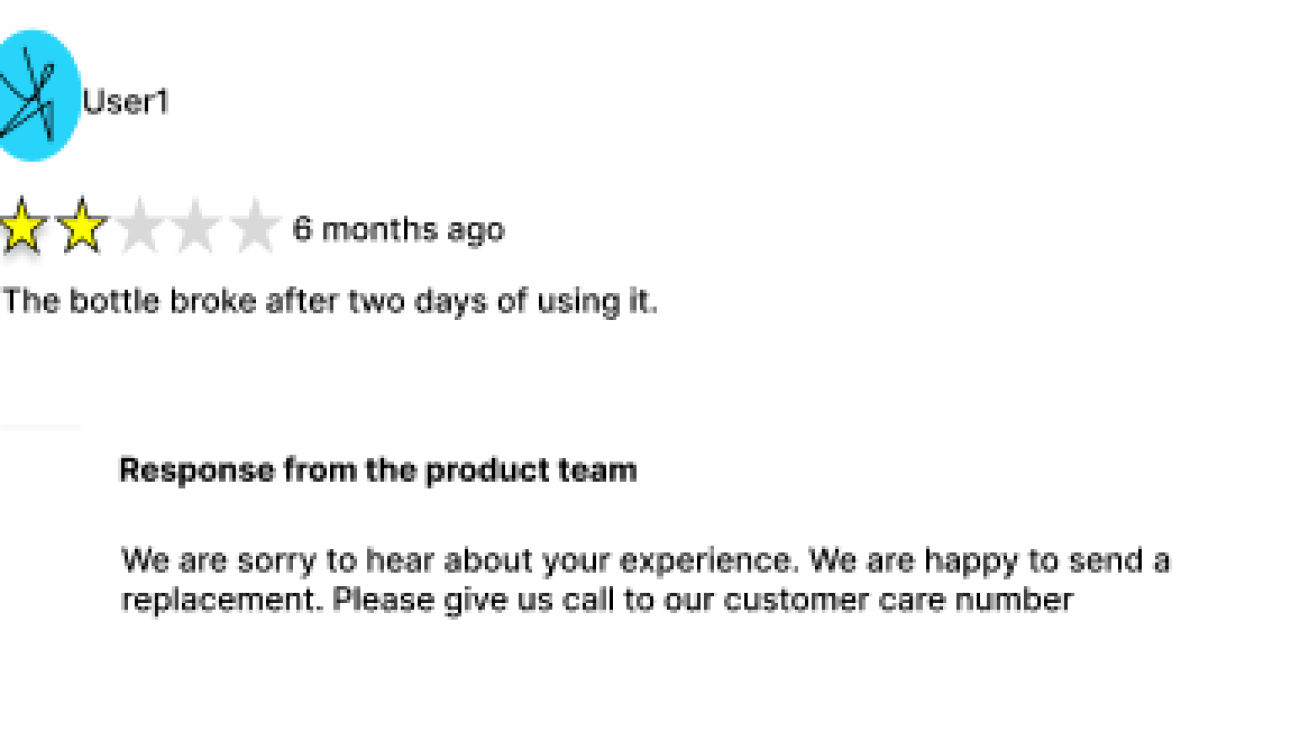
To illustrate this example, consider a retail company that allows purchasers to post product reviews on their website. By responding promptly to those reviews, the company demonstrates its commitments to customers and strengthens customer relationships.

Figure 1: Customer review and response
The example application in this post automates the process of responding to customer reviews. For most reviews, the system auto-generates a reply using an LLM. However, if the review or LLM-generated response contains uncertainty around toxicity or tone, the system flags it for a human reviewer. The human reviewer then assesses the flagged content to make the final decision about the toxicity or tone.
The application uses event-driven architecture (EDA), a powerful software design pattern that you can use to build decoupled systems by communicating through events. As soon as the product review is created, the review receiving system uses Amazon EventBridge to send an event that a product review is posted, along with the actual review content. The event starts an AWS Step Functions workflow. The workflow runs through a series of steps including generating content using an LLM and involving human decision making.

Figure 2: Review workflow
The process of generating a review response includes evaluating the toxicity of the review content, identifying sentiment, generating a response, and involving a human approver. This naturally fits into a workflow type of application because it’s a single process containing multiple sequential steps along with the need to manage state between steps. Hence the example uses Step Functions for workflow orchestration. Here are the steps in the review response workflow.
HARMFUL_CONTENT_DETECTED message.NEW_REVIEW_RESPONSE_CREATED event.RESPONSE_GENERATION_FAILED event.
Figure 3: product review evaluation and response workflow
Use the instructions in the GitHub repository to deploy and run the application.
Prompt chaining simplifies the problem for the LLM by dividing single, detailed, and monolithic tasks into smaller, more manageable tasks. Some, but not all, LLMs are good at following all the instructions in a single prompt. The simplification results in writing focused prompts for the LLM, leading to a more consistent and accurate response. The following is a sample ineffective single prompt.
Read the below customer review, filter for harmful content and provide your thoughts on the overall sentiment in JSON format. Then construct an email response based on the sentiment you determine and enclose the email in JSON format. Based on the sentiment, write a report on how the product can be improved.
To make it more effective, you can split the prompt into multiple subtasks:
You can even run some of the tasks in parallel. By breaking down to focused prompts, you achieve the following benefits:
Step Functions is a natural fit to build prompt chaining because it offers multiple different ways to chain prompts: sequentially, in parallel, and iteratively by passing the state data from one state to another. Consider the situation where you have built the product review response prompt chaining workflow and now want to evaluate the responses from different LLMs to find the best fit using an evaluation test suite. The evaluation test suite consists of hundreds of test product reviews, a reference response to the review, and a set of rules to evaluate the LLM response against the reference response. You can automate the evaluation activity using a Step Functions workflow. The first task in the workflow asks the LLM to generate a review response for the product review. The second task then asks the LLM to compare the generated response to the reference response using the rules and generate an evaluation score. Based on the evaluation score for each review, you can decide if the LLM passes your evaluation criteria or not. You can use the map state in Step Functions to run the evaluations for each review in your evaluation test suite in parallel. See this repository for more prompt chaining examples.
Involving human decision making in the example allows you to improve the accuracy of the system when the toxicity of the content cannot be determined to be either safe or harmful. You can implement human review within the Step Functions workflow using Wait for a Callback with the Task Token integration. When you use this integration with any supported AWS SDK API, the workflow task generates a unique token and then pauses until the token is returned. You can use this integration to include human decision making, call a legacy on-premises system, wait for completion of long running tasks, and so on.
In the sample application, the send email for approval task includes a wait for the callback token. It invokes an AWS Lambda function with a token and waits for the token. The Lambda function builds an email message along with the link to an Amazon API Gateway URL. Lambda then uses Amazon Simple Notification Service (Amazon SNS) to send an email to a human reviewer. The reviewer reviews the content and either accepts or rejects the message by selecting the appropriate link in the email. This action invokes the Step Functions SendTaskSuccess API. The API sends back the task token and a status message of whether to accept or reject the review. Step Functions receives the token, resumes the send email for approval task and then passes control to the choice state. The choice state decides whether to go through acceptance or rejection of the review based on the status message.

Figure 4: Human-in-the-loop workflow
EDA enables building extensible architectures. You can add consumers at any time by subscribing to the event. For example, consider moderating images and videos attached to a product review in addition to the text content. You also need to write code to delete the images and videos if they are found harmful. You can add a consumer, the image moderation system, to the NEW_REVIEW_POSTED event without making any code changes to the existing event consumers or producers. Development of the image moderation system and the review response system to delete harmful images can proceed in parallel which in turn improves development velocity.
When the image moderation workflow finds toxic content, it publishes a HARMFULL_CONTENT_DETECTED event. The event can be processed by a review response system that decides what to do with the event. By decoupling systems through events, you gain many advantages including improved development velocity, variable scaling, and fault tolerance.

Figure 5: Event-driven workflow
Use the instructions in the GitHub repository to delete the sample application.
In this blog post, you learned how to build a generative AI application with prompt chaining and a human-review process. You learned how both techniques improve the accuracy and safety of a generative AI application. You also learned how event-driven architectures along with workflows can integrate existing applications with generative AI applications.
Visit Serverless Land for more Step Functions workflows.
 Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker.
Veda Raman is a Senior Specialist Solutions Architect for Generative AI and machine learning based at AWS. Veda works with customers to help them architect efficient, secure and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon Sagemaker.
 Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.
Uma Ramadoss is a Principal Solutions Architect at Amazon Web Services, focused on the Serverless and Integration Services. She is responsible for helping customers design and operate event-driven cloud-native applications using services like Lambda, API Gateway, EventBridge, Step Functions, and SQS. Uma has a hands on experience leading enterprise-scale serverless delivery projects and possesses strong working knowledge of event-driven, micro service and cloud architecture.
A novel loss function and a way to aggregate multimodal input data are key to dramatic improvements on some test data.Read More

Our approach to analyzing and mitigating future risks posed by advanced AI modelsRead More

Our approach to analyzing and mitigating future risks posed by advanced AI modelsRead More

Our approach to analyzing and mitigating future risks posed by advanced AI modelsRead More