Starting with the AWS Neuron 2.18 release, you can now launch Neuron DLAMIs (AWS Deep Learning AMIs) and Neuron DLCs (AWS Deep Learning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. When a Neuron SDK is released, you’ll now be notified of the support for Neuron DLAMIs and Neuron DLCs in the Neuron SDK release notes, with a link to the AWS documentation containing the DLAMI and DLC release notes. In addition, this release introduces a number of features that help improve user experience for Neuron DLAMIs and DLCs. In this post, we walk through some of the support highlights with Neuron 2.18.
Neuron DLC and DLAMI overview and announcements
The DLAMI is a pre-configured AMI that comes with popular deep learning frameworks like TensorFlow, PyTorch, Apache MXNet, and others pre-installed. This allows machine learning (ML) practitioners to rapidly launch an Amazon Elastic Compute Cloud (Amazon EC2) instance with a ready-to-use deep learning environment, without having to spend time manually installing and configuring the required packages. The DLAMI supports various instance types, including Neuron Trainium and Inferentia powered instances, for accelerated training and inference.
AWS DLCs provide a set of Docker images that are pre-installed with deep learning frameworks. The containers are optimized for performance and available in Amazon Elastic Container Registry (Amazon ECR). DLCs make it straightforward to deploy custom ML environments in a containerized manner, while taking advantage of the portability and reproducibility benefits of containers.
Multi-Framework DLAMIs
The Neuron Multi-Framework DLAMI for Ubuntu 22 provides separate virtual environments for multiple ML frameworks: PyTorch 2.1, PyTorch 1.13, Transformers NeuronX, and TensorFlow 2.10. DLAMI offers you the convenience of having all these popular frameworks readily available in a single AMI, simplifying their setup and reducing the need for multiple installations.
This new Neuron Multi-Framework DLAMI is now the default choice when launching Neuron instances for Ubuntu through the AWS Management Console, making it even faster for you to get started with the latest Neuron capabilities right from the Quick Start AMI list.
Existing Neuron DLAMI support
The existing Neuron DLAMIs for PyTorch 1.13 and TensorFlow 2.10 have been updated with the latest 2.18 Neuron SDK, making sure you have access to the latest performance optimizations and features for both Ubuntu 20 and Amazon Linux 2 distributions.
AWS Systems Manager Parameter Store support
Neuron 2.18 also introduces support in Parameter Store, a capability of AWS Systems Manager, for Neuron DLAMIs, allowing you to effortlessly find and query the DLAMI ID with the latest Neuron SDK release. This feature streamlines the process of launching new instances with the most up-to-date Neuron SDK, enabling you to automate your deployment workflows and make sure you’re always using the latest optimizations.
Availability of Neuron DLC Images in Amazon ECR
To provide customers with more deployment options, Neuron DLCs are now hosted both in the public Neuron ECR repository and as private images. Public images provide seamless integration with AWS ML deployment services such as Amazon EC2, Amazon Elastic Container Service (Amazon ECS), and Amazon Elastic Kubernetes Service (Amazon EKS); private images are required when using Neuron DLCs with Amazon SageMaker.
Updated Dockerfile locations
Prior to this release, Dockerfiles for Neuron DLCs were located within the AWS/Deep Learning Containers repository. Moving forward, Neuron containers can be found in the AWS-Neuron/ Deep Learning Containers repository.
Improved documentation
The Neuron SDK documentation and AWS documentation sections for DLAMI and DLC now have up-to-date user guides about Neuron. The Neuron SDK documentation also includes a dedicated DLAMI section with guides on discovering, installing, and upgrading Neuron DLAMIs, along with links to release notes in AWS documentation.
Using the Neuron DLC and DLAMI with Trn and Inf instances
AWS Trainium and AWS Inferentia are custom ML chips designed by AWS to accelerate deep learning workloads in the cloud.
You can choose your desired Neuron DLAMI when launching Trn and Inf instances through the console or infrastructure automation tools like AWS Command Line Interface (AWS CLI). After a Trn or Inf instance is launched with the selected DLAMI, you can activate the virtual environment corresponding to your chosen framework and begin using the Neuron SDK. If you’re interested in using DLCs, refer to the DLC documentation section in the Neuron SDK documentation or the DLC release notes section in the AWS documentation to find the list of Neuron DLCs with the latest Neuron SDK release. Each DLC in the list includes a link to the corresponding container image in the Neuron container registry. After choosing a specific DLC, please refer to the DLC walkthrough in the next section to learn how to launch scalable training and inference workloads using AWS services like Kubernetes (Amazon EKS), Amazon ECS, Amazon EC2, and SageMaker. The following sections contain walkthroughs for both the Neuron DLC and DLAMI.
DLC walkthrough
In this section, we provide resources to help you use containers for your accelerated deep learning model acceleration on top of AWS Inferentia and Trainium enabled instances.
The section is organized based on the target deployment environment and use case. In most cases, it is recommended to use a preconfigured DLC from AWS. Each DLC is preconfigured to have all the Neuron components installed and is specific to the chosen ML framework.
Locate the Neuron DLC image
The PyTorch Neuron DLC images are published to ECR Public Gallery, which is the recommended URL to use for most cases. If you’re working within SageMaker, use the Amazon ECR URL instead of the Amazon ECR Public Gallery. TensorFlow DLCs are not updated with the latest release. For earlier releases, refer to Neuron Containers. In the following sections, we provide the recommended steps for running an inference or training job in Neuron DLCs.
Prerequisites
Prepare your infrastructure (Amazon EKS, Amazon ECS, Amazon EC2, and SageMaker) with AWS Inferentia or Trainium instances as worker nodes, making sure they have the necessary roles attached for Amazon ECR read access to retrieve container images from Amazon ECR: arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly.
When setting up hosts for Amazon EC2 and Amazon ECS, using Deep Learning AMI (DLAMI) is recommended. An Amazon EKS optimized GPU AMI is recommended to use in Amazon EKS.
You also need the ML job scripts ready with a command to invoke them. In the following steps, we use a single file, train.py, as the ML job script. The command to invoke it is torchrun —nproc_per_node=2 —nnodes=1 train.py.
Extend the Neuron DLC
Extend the Neuron DLC to include your ML job scripts and other necessary logic. As the simplest example, you can have the following Dockerfile:
FROM public.ecr.aws/neuron/pytorch-training-neuronx:2.1.2-neuronx-py310-sdk2.18.2-ubuntu20.04
COPY train.py /train.py
This Dockerfile uses the Neuron PyTorch training container as a base and adds your training script, train.py, to the container.
Build and push to Amazon ECR
Complete the following steps:
- Build your Docker image:
docker build -t <your-repo-name>:<your-image-tag>
- Authenticate your Docker client to your ECR registry:
aws ecr get-login-password --region <your-region> | docker login --username AWS --password-stdin <your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com
- Tag your image to match your repository:
docker tag <your-repo-name>:<your-image-tag> <your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag>
- Push this image to Amazon ECR:
docker push <your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag>
You can now run the extended Neuron DLC in different AWS services.
Amazon EKS configuration
For Amazon EKS, create a simple pod YAML file to use the extended Neuron DLC. For example:
apiVersion: v1
kind: Pod
metadata:
name: training-pod
spec:
containers:
- name: training-container
image: <your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag>
command: ["torchrun"]
args: ["--nproc_per_node=2", "--nnodes=1", "/train.py"]
resources:
limits:
aws.amazon.com/neuron: 1
requests:
aws.amazon.com/neuron: 1
Use kubectl apply -f <pod-file-name>.yaml to deploy this pod in your Kubernetes cluster.
Amazon ECS configuration
For Amazon ECS, create a task definition that references your custom Docker image. The following is an example JSON task definition:
{
"family": "training-task",
"requiresCompatibilities": ["EC2"],
"containerDefinitions": [
{
"command": [
"torchrun --nproc_per_node=2 --nnodes=1 /train.py"
],
"linuxParameters": {
"devices": [
{
"containerPath": "/dev/neuron0",
"hostPath": "/dev/neuron0",
"permissions": [
"read",
"write"
]
}
],
"capabilities": {
"add": [
"IPC_LOCK"
]
}
},
"cpu": 0,
"memoryReservation": 1000,
"image": "<your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag>",
"essential": true,
"name": "training-container",
}
]
}
This definition sets up a task with the necessary configuration to run your containerized application in Amazon ECS.
Amazon EC2 configuration
For Amazon EC2, you can directly run your Docker container:
docker run --name training-job --device=/dev/neuron0 <your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag> "torchrun --nproc_per_node=2 --nnodes=1 /train.py"
SageMaker configuration
For SageMaker, create a model with your container and specify the training job command in the SageMaker SDK:
import sagemaker
from sagemaker.pytorch import PyTorch
role = sagemaker.get_execution_role()
pytorch_estimator = PyTorch(entry_point='train.py',
role=role,
image_uri='<your-aws-account-id>.dkr.ecr.<your-region>.amazonaws.com/<your-repo-name>:<your-image-tag>',
instance_count=1,
instance_type='ml.trn1.2xlarge',
framework_version='2.1.2',
py_version='py3',
hyperparameters={"nproc-per-node": 2, "nnodes": 1},
script_mode=True)
pytorch_estimator.fit()
DLAMI walkthrough
This section walks through launching an Inf1, Inf2, or Trn1 instance using the Multi-Framework DLAMI in the Quick Start AMI list and getting the latest DLAMI that supports the newest Neuron SDK release easily.
The Neuron DLAMI is a multi-framework DLAMI that supports multiple Neuron frameworks and libraries. Each DLAMI is pre-installed with Neuron drivers and support all Neuron instance types. Each virtual environment that corresponds to a specific Neuron framework or library comes pre-installed with all the Neuron libraries, including the Neuron compiler and Neuron runtime needed for you to get started.
This release introduces a new Multi-Framework DLAMI for Ubuntu 22 that you can use to quickly get started with the latest Neuron SDK on multiple frameworks that Neuron supports as well as Systems Manager (SSM) parameter support for DLAMIs to automate the retrieval of the latest DLAMI ID in cloud automation flows.
For instructions on getting started with the multi-framework DLAMI through the console, refer to Get Started with Neuron on Ubuntu 22 with Neuron Multi-Framework DLAMI. If you want to use the Neuron DLAMI in your cloud automation flows, Neuron also supports SSM parameters to retrieve the latest DLAMI ID.
Launch the instance using Neuron DLAMI
Complete the following steps:
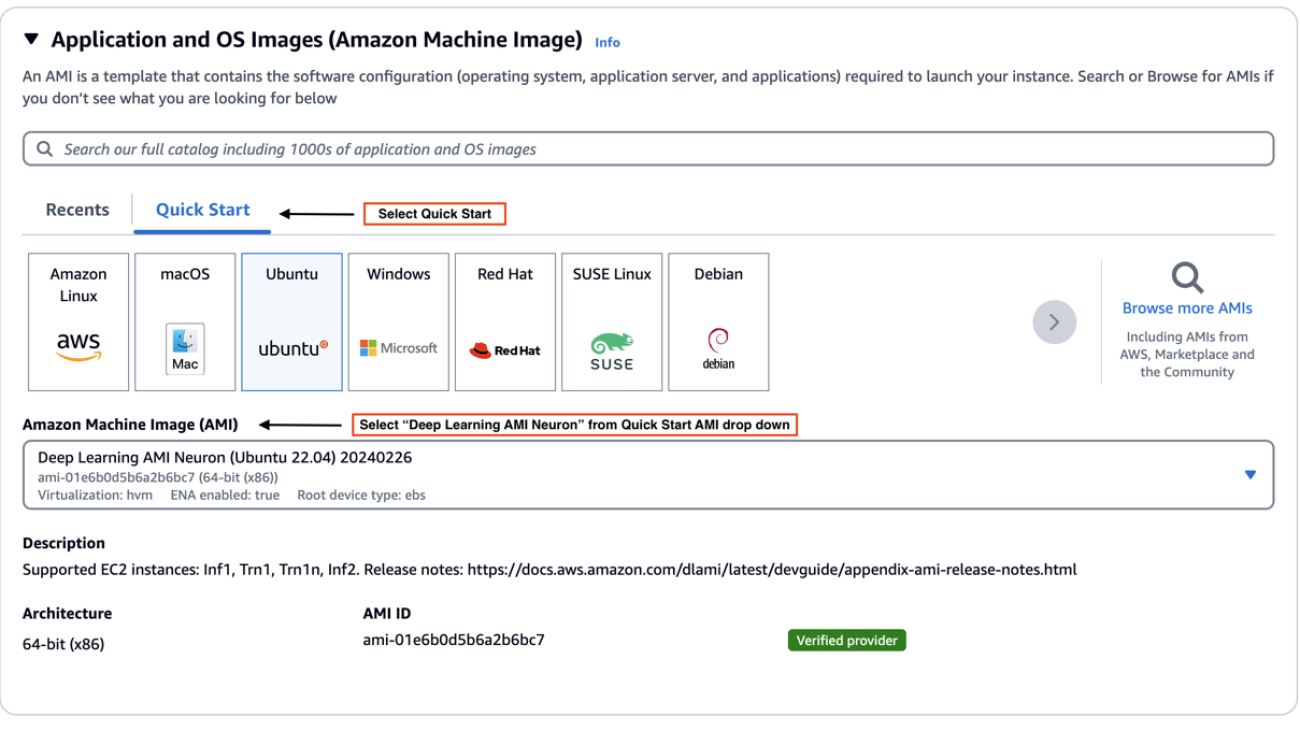
- On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance.
- On the Quick Start tab, choose Ubuntu.
- For Amazon Machine Image, choose Deep Learning AMI Neuron (Ubuntu 22.04).
- Specify your desired Neuron instance.
- Configure disk size and other criteria.
- Launch the instance.

Activate the virtual environment
Activate your desired virtual environment, as shown in the following screenshot.
After you have activated the virtual environment, you can try out one of the tutorials listed in the corresponding framework or library training and inference section.

Use SSM parameters to find specific Neuron DLAMIs
Neuron DLAMIs support SSM parameters to quickly find Neuron DLAMI IDs. As of this writing, we only support finding the latest DLAMI ID that corresponds to the latest Neuron SDK release with SSM parameter support. In the future releases, we will add support for finding the DLAMI ID using SSM parameters for a specific Neuron release.
You can find the DLAMI that supports the latest Neuron SDK by using the get-parameter command:
aws ssm get-parameter
--region us-east-1
--name <dlami-ssm-parameter-prefix>/latest/image_id
--query "Parameter.Value"
--output text
For example, to find the latest DLAMI ID for the Multi-Framework DLAMI (Ubuntu 22), you can use the following code:
aws ssm get-parameter
--region us-east-1
--name /aws/service/neuron/dlami/multi-framework/ubuntu-22.04/latest/image_id
--query "Parameter.Value"
--output text
You can find all available parameters supported in Neuron DLAMIs using the AWS CLI:
aws ssm get-parameters-by-path
--region us-east-1
--path /aws/service/neuron
--recursive
You can also view the SSM parameters supported in Neuron through Parameter Store by selecting the neuron service.
Use SSM parameters to launch an instance directly using the AWS CLI
You can use the AWS CLI to find the latest DLAMI ID and launch the instance simultaneously. The following code snippet shows an example of launching an Inf2 instance using a multi-framework DLAMI:
aws ec2 run-instances
--region us-east-1
--image-id resolve:ssm:/aws/service/neuron/dlami/pytorch-1.13/amazon-linux-2/latest/image_id
--count 1
--instance-type inf2.48xlarge
--key-name <my-key-pair>
--security-groups <my-security-group>
Use SSM parameters in EC2 launch templates
You can also use SSM parameters directly in launch templates. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
Clean up
When you’re done running the resources that you deployed as part of this post, make sure to delete or stop them from running and accruing charges:
- Stop your EC2 instance.
- Delete your ECS cluster.
- Delete your EKS cluster.
- Clean up your SageMaker resources.
Conclusion
In this post, we introduced several enhancements incorporated into Neuron 2.18 that improve the user experience and time-to-value for customers working with AWS Inferentia and Trainium instances. Neuron DLAMIs and DLCs with the latest Neuron SDK on the same day as the release means you can immediately benefit from the latest performance optimizations, features, and documentation for installing and upgrading Neuron DLAMIs and DLCs.
Additionally, you can now use the Multi-Framework DLAMI, which simplifies the setup process by providing isolated virtual environments for multiple popular ML frameworks. Finally, we discussed Parameter Store support for Neuron DLAMIs that streamlines the process of launching new instances with the most up-to-date Neuron SDK, enabling you to automate your deployment workflows with ease.
Neuron DLCs are available both private and public ECR repositories to help you deploy Neuron in your preferred AWS service. Refer to the following resources to get started:
About the Authors
 Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
Niithiyn Vijeaswaran is a Solutions Architect at AWS. His area of focus is generative AI and AWS AI Accelerators. He holds a Bachelor’s degree in Computer Science and Bioinformatics. Niithiyn works closely with the Generative AI GTM team to enable AWS customers on multiple fronts and accelerate their adoption of generative AI. He’s an avid fan of the Dallas Mavericks and enjoys collecting sneakers.
 Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps customers integrate cutting-edge generative AI capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
Armando Diaz is a Solutions Architect at AWS. He focuses on generative AI, AI/ML, and data analytics. At AWS, Armando helps customers integrate cutting-edge generative AI capabilities into their systems, fostering innovation and competitive advantage. When he’s not at work, he enjoys spending time with his wife and family, hiking, and traveling the world.
 Sebastian Bustillo is an Enterprise Solutions Architect at AWS. He focuses on AI/ML technologies and has a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI, assisting with the overall process from ideation to production. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the outdoors with his wife.
Sebastian Bustillo is an Enterprise Solutions Architect at AWS. He focuses on AI/ML technologies and has a profound passion for generative AI and compute accelerators. At AWS, he helps customers unlock business value through generative AI, assisting with the overall process from ideation to production. When he’s not at work, he enjoys brewing a perfect cup of specialty coffee and exploring the outdoors with his wife.
 Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
Ziwen Ning is a software development engineer at AWS. He currently focuses on enhancing the AI/ML experience through the integration of AWS Neuron with containerized environments and Kubernetes. In his free time, he enjoys challenging himself with badminton, swimming and other various sports, and immersing himself in music.
 Anant Sharma is a software engineer at AWS Annapurna Labs specializing in DevOps. His primary focus revolves around building, automating and refining the process of delivering software to AWS Trainium and Inferentia customers. Beyond work, he’s passionate about gaming, exploring new destinations and following latest tech developments.
Anant Sharma is a software engineer at AWS Annapurna Labs specializing in DevOps. His primary focus revolves around building, automating and refining the process of delivering software to AWS Trainium and Inferentia customers. Beyond work, he’s passionate about gaming, exploring new destinations and following latest tech developments.
 Roopnath Grandhi is a Sr. Product Manager at AWS. He leads large-scale model inference and developer experiences for AWS Trainium and Inferentia AI accelerators. With over 15 years of experience in architecting and building AI based products and platforms, he holds multiple patents and publications in AI and eCommerce.
Roopnath Grandhi is a Sr. Product Manager at AWS. He leads large-scale model inference and developer experiences for AWS Trainium and Inferentia AI accelerators. With over 15 years of experience in architecting and building AI based products and platforms, he holds multiple patents and publications in AI and eCommerce.
 Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions and conducting research to help customers hyperscale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers & acquisitions. Marco is based in Seattle, WA and enjoys writing, reading, exercising, and building applications in his free time.
Marco Punio is a Solutions Architect focused on generative AI strategy, applied AI solutions and conducting research to help customers hyperscale on AWS. He is a qualified technologist with a passion for machine learning, artificial intelligence, and mergers & acquisitions. Marco is based in Seattle, WA and enjoys writing, reading, exercising, and building applications in his free time.
 Rohit Talluri is a Generative AI GTM Specialist (Tech BD) at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Rohit Talluri is a Generative AI GTM Specialist (Tech BD) at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect, and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Read More
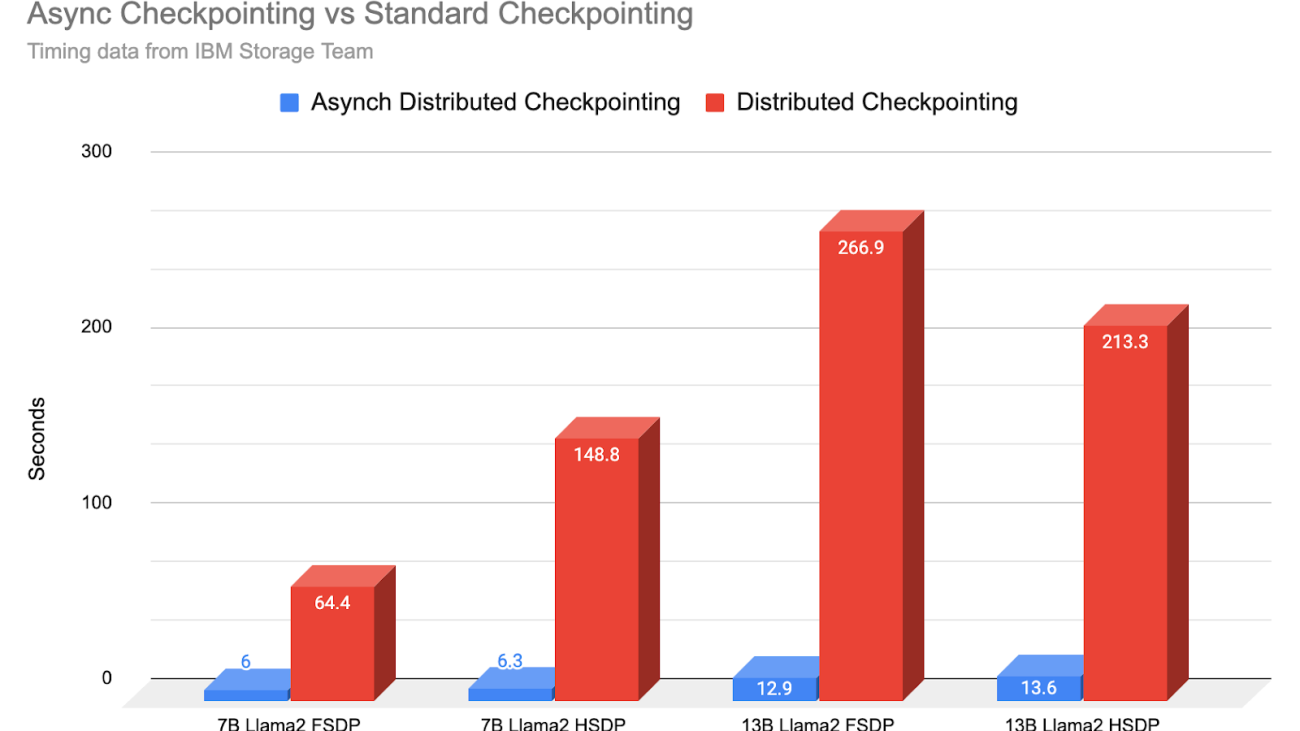
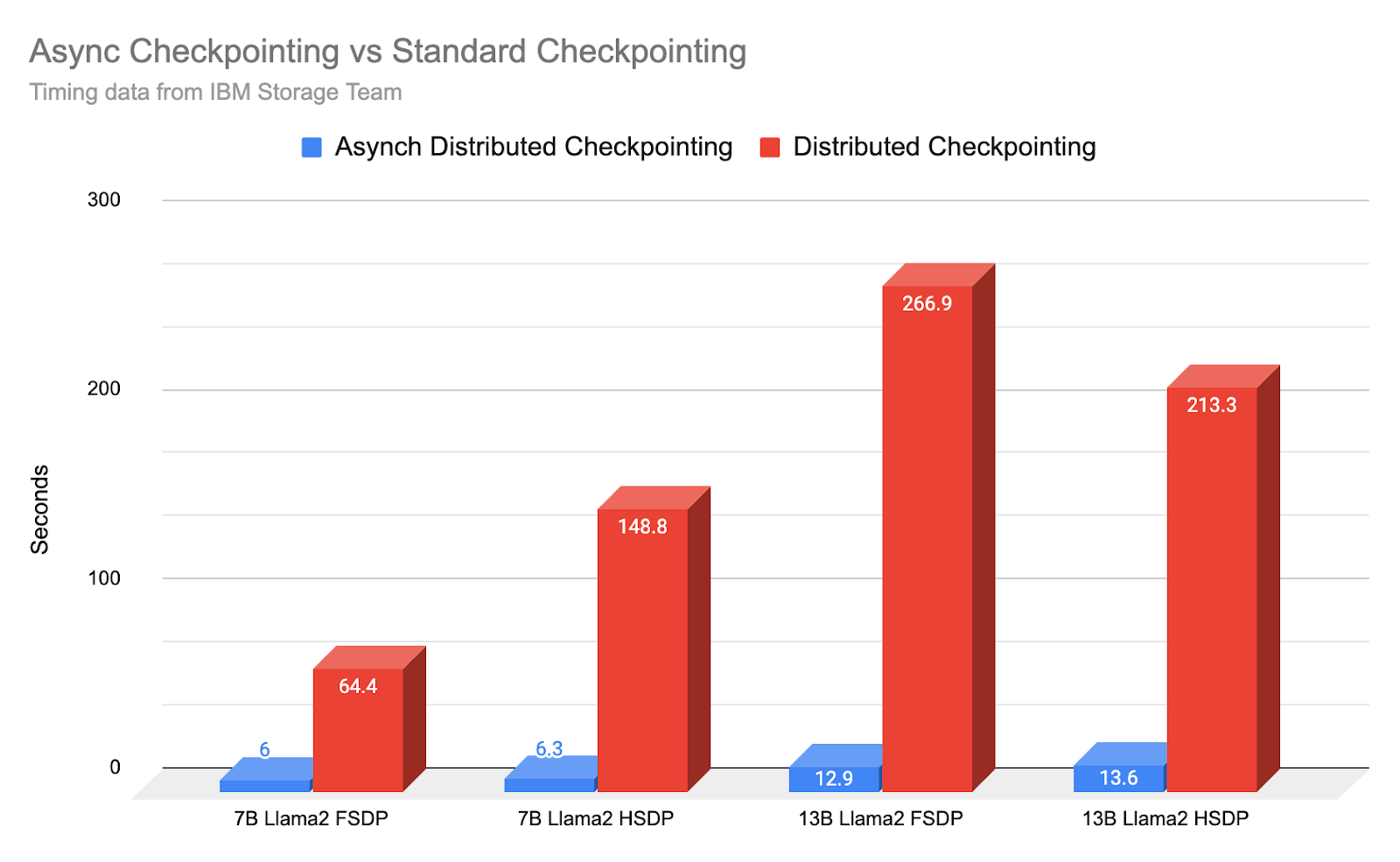
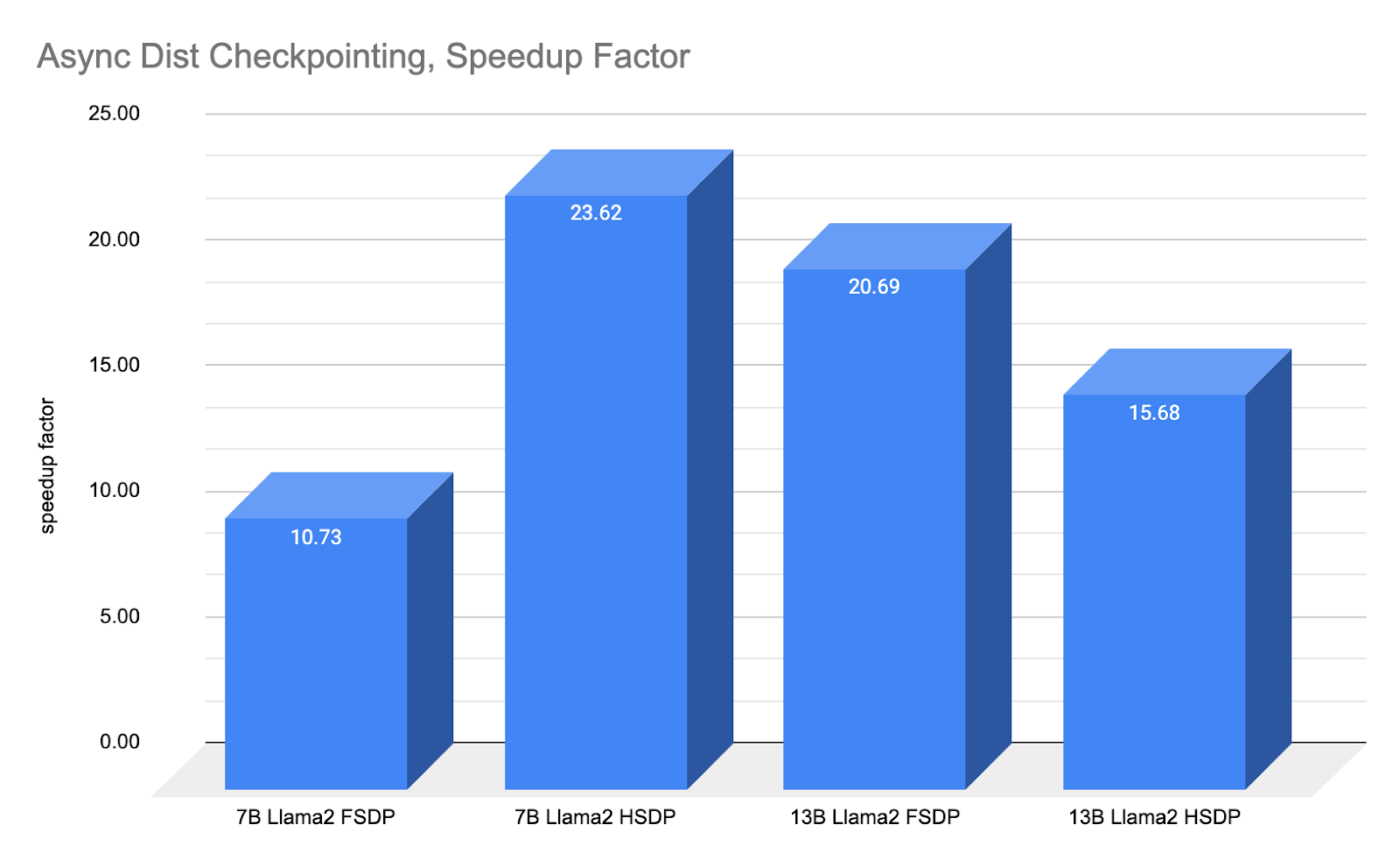

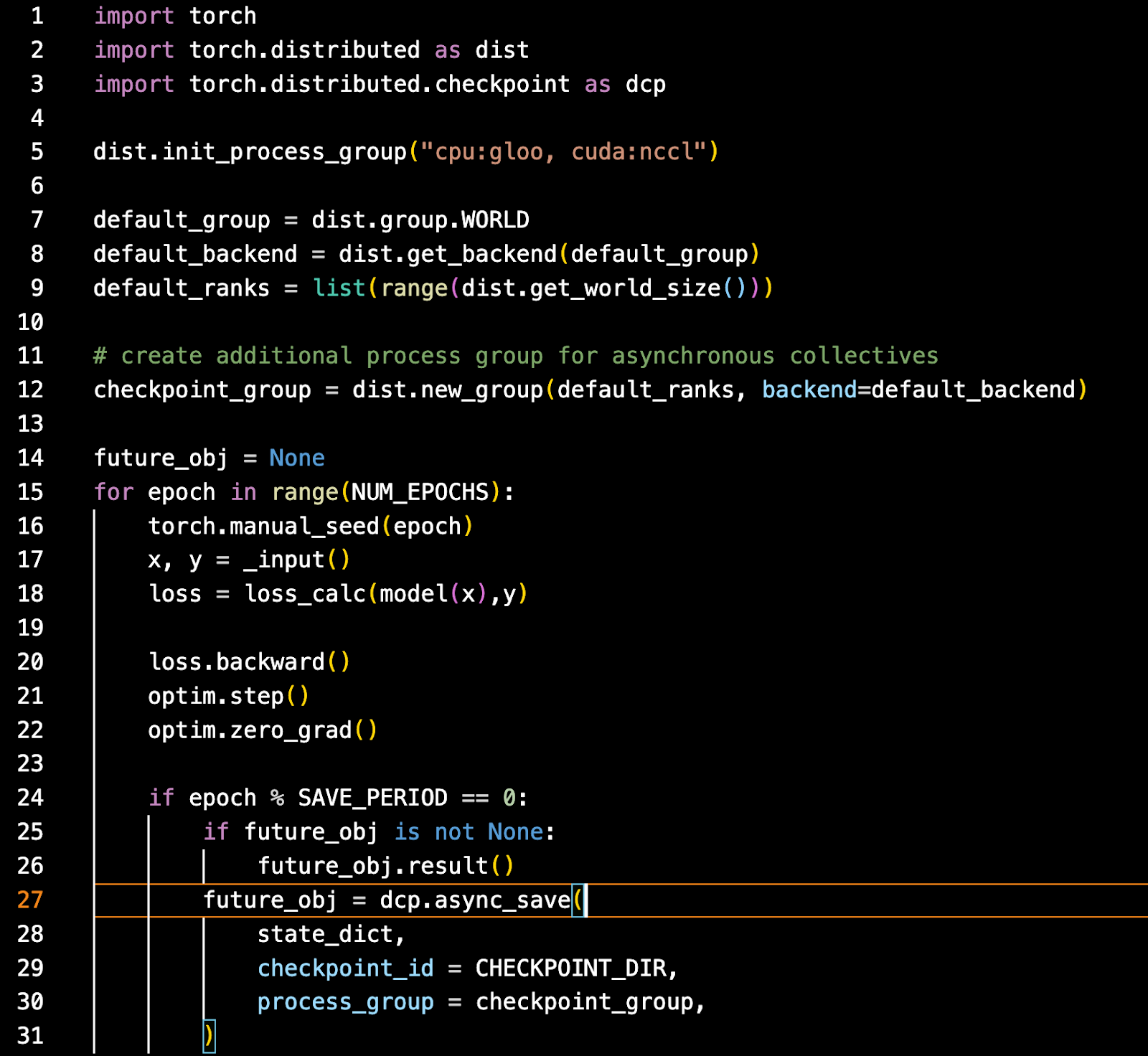










 Christian Bock is an applied scientist at Amazon Web Services working on AI for code.
Christian Bock is an applied scientist at Amazon Web Services working on AI for code. Laurent Callot is a Principal Applied Scientist at Amazon Web Services leading teams creating AI solutions for developers.
Laurent Callot is a Principal Applied Scientist at Amazon Web Services leading teams creating AI solutions for developers. Tim Esler is a Senior Applied Scientist at Amazon Web Services working on Generative AI and Coding Agents for building developer tools and foundational tooling for Amazon Q products.
Tim Esler is a Senior Applied Scientist at Amazon Web Services working on Generative AI and Coding Agents for building developer tools and foundational tooling for Amazon Q products. Prabhu Teja is an Applied Scientist at Amazon Web Services. Prabhu works on LLM assisted code generation with a focus on natural language interaction.
Prabhu Teja is an Applied Scientist at Amazon Web Services. Prabhu works on LLM assisted code generation with a focus on natural language interaction. Martin Wistuba is a senior applied scientist at Amazon Web Services. As part of Amazon Q Developer, he is helping developers to write more code in less time.
Martin Wistuba is a senior applied scientist at Amazon Web Services. As part of Amazon Q Developer, he is helping developers to write more code in less time. Giovanni Zappella is a Principal Applied Scientist working on the creations of intelligent agents for code generation. While at Amazon he also contributed to the creation of new algorithms for Continual Learning, AutoML and recommendations systems.
Giovanni Zappella is a Principal Applied Scientist working on the creations of intelligent agents for code generation. While at Amazon he also contributed to the creation of new algorithms for Continual Learning, AutoML and recommendations systems.






 Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for Machine Learning and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions with Arm SoCs.
Sunita Nadampalli is a Software Development Manager at AWS. She leads Graviton software performance optimizations for Machine Learning and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions with Arm SoCs. Gaurav Garg is a Sr. Technical Account Manager at AWS with 15 years of experience. He has a strong operations background. In his role he works with Independent Software Vendors to build scalable and cost-effective solutions with AWS that meet the business requirements. He is passionate about Security and Databases.
Gaurav Garg is a Sr. Technical Account Manager at AWS with 15 years of experience. He has a strong operations background. In his role he works with Independent Software Vendors to build scalable and cost-effective solutions with AWS that meet the business requirements. He is passionate about Security and Databases. Ratnesh Jamidar is a AVP Engineering at Sprinklr with 8 years of experience. He is a seasoned Machine Learning professional with expertise in designing, implementing large-scale, distributed, and highly available AI products and infrastructure.
Ratnesh Jamidar is a AVP Engineering at Sprinklr with 8 years of experience. He is a seasoned Machine Learning professional with expertise in designing, implementing large-scale, distributed, and highly available AI products and infrastructure. Vinayak Trivedi is an Associate Director of Engineering at Sprinklr with 4 years of experience in Backend & AI. He is proficient in Applied Machine Learning & Data Science, with a history of building large-scale, scalable and resilient systems.
Vinayak Trivedi is an Associate Director of Engineering at Sprinklr with 4 years of experience in Backend & AI. He is proficient in Applied Machine Learning & Data Science, with a history of building large-scale, scalable and resilient systems.



 Shaked Rotlevi is a Technical Product Marketing Manager at Wiz focusing on AI security. Prior to Wiz she was a Solutions Architect at AWS working with public sector customers as well as a Technical Program Manager for a security service team. In her spare time she enjoys playing beach volleyball and hiking.
Shaked Rotlevi is a Technical Product Marketing Manager at Wiz focusing on AI security. Prior to Wiz she was a Solutions Architect at AWS working with public sector customers as well as a Technical Program Manager for a security service team. In her spare time she enjoys playing beach volleyball and hiking. Itay Arbel is a Lead Product Manager at Wiz. Before joining Wiz, Itay was a product manager at Microsoft and did an MBA in Oxford University, majoring in high tech and emerging technologies. Itay is Wiz’s product lead for the effort of helping organizations securing their AI pipeline and usage of this new emerging technology.
Itay Arbel is a Lead Product Manager at Wiz. Before joining Wiz, Itay was a product manager at Microsoft and did an MBA in Oxford University, majoring in high tech and emerging technologies. Itay is Wiz’s product lead for the effort of helping organizations securing their AI pipeline and usage of this new emerging technology. Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS. He works with AWS customers to provide guidance and technical assistance, helping them build and operate Generative AI and Machine Learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS. He works with AWS customers to provide guidance and technical assistance, helping them build and operate Generative AI and Machine Learning solutions on AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles. Adi Avni is a Senior Solutions Architect at AWS based in Israel. Adi works with AWS ISV customers, helping them to build innovative, scalable and cost-effective solutions on AWS. In his spare time, he enjoys sports and traveling with family and friends.
Adi Avni is a Senior Solutions Architect at AWS based in Israel. Adi works with AWS ISV customers, helping them to build innovative, scalable and cost-effective solutions on AWS. In his spare time, he enjoys sports and traveling with family and friends.
 Applications are open for two new Google for Startups Accelerator programs in Europe and Israel.
Applications are open for two new Google for Startups Accelerator programs in Europe and Israel.
