Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over…Apple Machine Learning Research
Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over…Apple Machine Learning Research
Comparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speaker identification, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and…Apple Machine Learning Research
Conformer-Based Speech Recognition on Extreme Edge-Computing Devices
This paper was accepted at the Industry Track at NAACL 2024.
With increasingly more powerful compute capabilities and resources in today’s devices, traditionally compute-intensive automatic speech recognition (ASR) has been moving from the cloud to devices to better protect user privacy. However, it is still challenging to implement on-device ASR on resource-constrained devices, such as smartphones, smart wearables, and other small home automation devices. In this paper, we propose a series of model architecture adaptions, neural network graph transformations, and numerical optimizations to…Apple Machine Learning Research
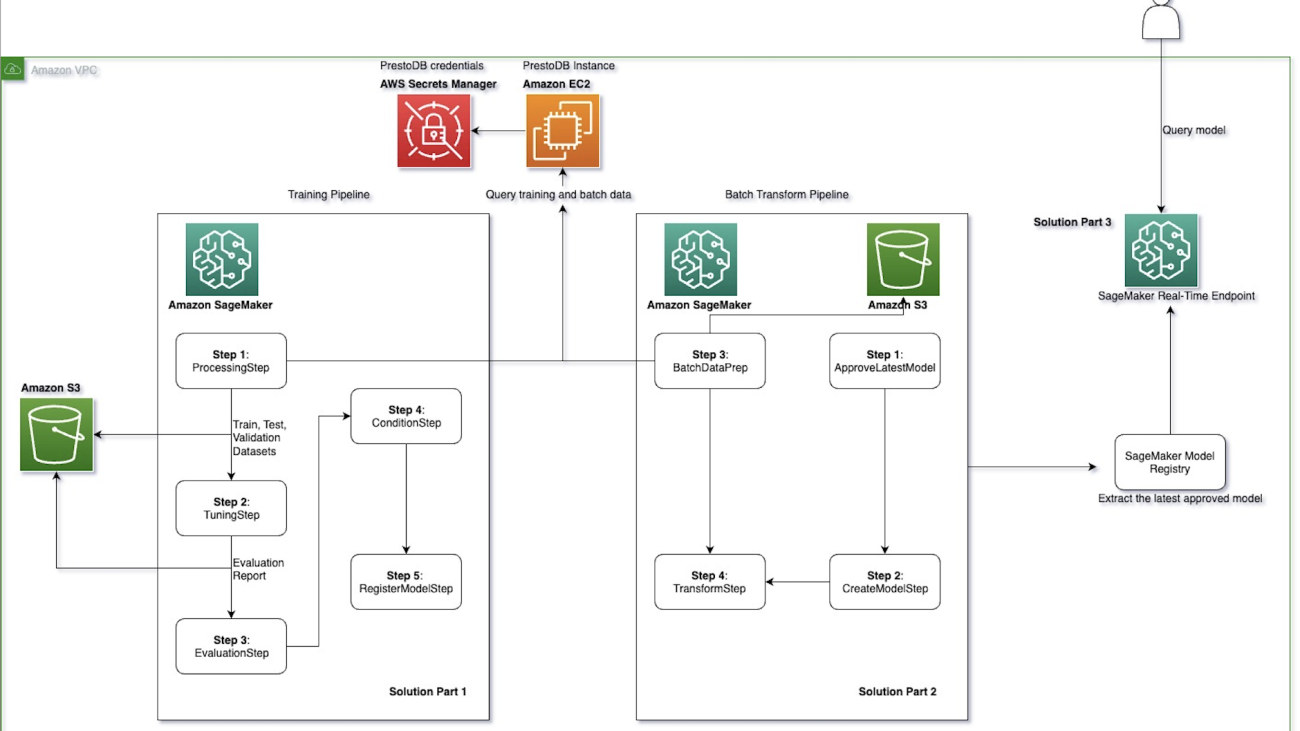
How Twilio used Amazon SageMaker MLOps pipelines with PrestoDB to enable frequent model retraining and optimized batch transform
This post is co-written with Shamik Ray, Srivyshnav K S, Jagmohan Dhiman and Soumya Kundu from Twilio.
Today’s leading companies trust Twilio’s Customer Engagement Platform (CEP) to build direct, personalized relationships with their customers everywhere in the world. Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth and customer service, and many more engagement use cases in a flexible, programmatic way. Across 180 countries, millions of developers and hundreds of thousands of businesses use Twilio to create magical experiences for their customers. Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. This post outlines the steps AWS and Twilio took to migrate Twilio’s existing machine learning operations (MLOps), the implementation of training models, and running batch inferences to Amazon SageMaker.
ML models don’t operate in isolation. They must integrate into existing production systems and infrastructure to deliver value. This necessitates considering the entire ML lifecycle during design and development. With the right processes and tools, MLOps enables organizations to reliably and efficiently adopt ML across their teams for their specific use cases. SageMaker includes a suite of features for MLOps that includes Amazon SageMaker Pipelines and Amazon SageMaker Model Registry. Pipelines allow for straightforward creation and management of ML workflows while also offering storage and reuse capabilities for workflow steps. The model registry simplifies model deployment by centralizing model tracking.
This post focuses on how to achieve flexibility in using your data source of choice and integrate it seamlessly with Amazon SageMaker Processing jobs. With SageMaker Processing jobs, you can use a simplified, managed experience to run data preprocessing or postprocessing and model evaluation workloads on the SageMaker platform.
Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. PrestoDB is an open source SQL query engine that is designed for fast analytic queries against data of any size from multiple sources.
In this post, we show you a step-by-step implementation to achieve the following:
- Read data available in PrestoDB from a SageMaker Processing job
- Train a binary classification model using SageMaker training jobs, and tune the model using SageMaker automatic model tuning
- Run a batch transform pipeline for batch inference on data fetched from PrestoDB
- Deploy the trained model as a real-time SageMaker endpoint
Use case overview
Twilio trained a binary classification ML model using scikit-learn’s RandomForestClassifier to integrate into their MLOps pipeline. This model is used as part of a batch process that runs periodically for their daily workloads, making training and inference workflows repeatable to accelerate model development. The training data used for this pipeline is made available through PrestoDB and read into Pandas through the PrestoDB Python client.
The end goal was to convert the existing steps into two pipelines: a training pipeline and a batch transform pipeline that connected the data queried from PrestoDB to a SageMaker Processing job, and finally deploy the trained model to a SageMaker endpoint for real-time inference.
In this post, we use an open source dataset available through the TPCH connector that is packaged with PrestoDB to illustrate the end-to-end workflow that Twilio used. Twilio was able to use this solution to migrate their existing MLOps pipeline to SageMaker. All the code for this solution is available in the GitHub repo.
Solution overview
This solution is divided into three main steps:
- Model training pipeline – In this step, we connect a SageMaker Processing job to fetch data from a PrestoDB instance, train and tune the ML model, evaluate it, and register it with the SageMaker model registry.
- Batch transform pipeline – In this step, we run a preprocessing data step that reads data from a PrestoDB instance and runs batch inference on the registered ML model (from the model registry) that we approve as a part of this pipeline. This model is approved either programmatically or manually through the model registry.
- Real-time inference – In this step, we deploy the latest approved model as a SageMaker endpoint for real-time inference.
All pipeline parameters used in this solution exist in a single config.yml file. This file includes the necessary AWS and PrestoDB credentials to connect to the PrestoDB instance, information on the training hyperparameters and SQL queries that are run at training, and inference steps to read data from PrestoDB. This solution is highly customizable for industry-specific use cases so that it can be used with minimal code changes through simple updates in the config file.
The following code shows an example of how a query is configured within the config.yml file. This query is used at the data processing step of the training pipeline to fetch data from the PrestoDB instance. Here, we predict whether an order is a high_value_order or a low_value_order based on the orderpriority as given from the TPC-H data. For more information on the TPC-H data, its database entities, relationships, and characteristics, refer to TPC Benchmark H. You can change the query for your use case within the config file and run the solution with no code changes.
The main steps of this solution are described in detail in the following sections.
Data preparation and training
The data preparation and training pipeline includes the following steps:
- The training data is read from a PrestoDB instance, and any feature engineering needed is done as part of the SQL queries run in PrestoDB at retrieval time. The queries that are used to fetch data at training and batch inference steps are configured in the config file.
- We use the FrameworkProcessor with SageMaker Processing jobs to read data from PrestoDB using the Python PrestoDB client.
- For the training and tuning step, we use the SKLearn estimator from the SageMaker SDK and the
RandomForestClassifierfrom scikit-learn to train the ML model. The HyperparameterTuner class is used for running automatic model tuning, which finds the best version of the model by running many training jobs on the dataset using the algorithm and the ranges of hyperparameters. - The model evaluation step checks that the trained and tuned model has an accuracy level above a user-defined threshold and only then register that model within the model registry. If the model accuracy doesn’t meet the threshold, the pipeline fails and the model is not registered with the model registry.
- The model training pipeline is then run with pipeline.start, which invokes and instantiates all the preceding steps.
Batch transform
The batch transform pipeline consists of the following steps:
- The pipeline implements a data preparation step that retrieves data from a PrestoDB instance (using a data preprocessing script) and stores the batch data in Amazon Simple Storage Service (Amazon S3).
- The latest model registered in the model registry from the training pipeline is approved.
- A Transformer instance is used to runs a batch transform job to get inferences on the entire dataset stored in Amazon S3 from the data preparation step and store the output in Amazon S3.
SageMaker real-time inference
The SageMaker endpoint pipeline consists of the following steps:
- The latest approved model is retrieved from the model registry using the describe_model_package function from the SageMaker SDK.
- The latest approved model is deployed as a real-time SageMaker endpoint.
- The model is deployed on a ml.c5.xlarge instance with a minimum instance count of 1 and a maximum instance count of 3 (configurable by the user) with the automatic scaling policy set to ENABLED. This removes unnecessary instances so you don’t pay for provisioned instances that you aren’t using.
Prerequisites
To implement the solution provided in this post, you should have an AWS account, a SageMaker domain to access Amazon SageMaker Studio, and familiarity with SageMaker, Amazon S3, and PrestoDB.
The following prerequisites also need to be in place before running this code:
- PrestoDB – We use the built-in datasets available in PrestoDB through the TPCH connector for this solution. Follow the instructions in the GitHub README.md to set up PrestoDB on an Amazon Elastic Compute Cloud (Amazon EC2) instance in your account. If you already have access to a PrestoDB instance, you can skip this step but note its connection details (see the presto section in the config file). When you have your PrestoDB credentials, fill out the presto section in the config file as follows (enter your host public IP, port, credentials, catalog and schema):
- VPC network configurations – We also define the encryption, network isolation, and VPC configurations of the ML model and operations in the config file. For more information on network configurations and preferences, refer to Connect to SageMaker Within your VPC. If you are using the default VPC and security groups then you can leave these configuration parameters empty, see example in this configuration file. If not, then in the
awssection, specify theenable_network_isolationstatus,security_group_ids, and subnets based on your network isolation preferences. :
- IAM role – Set up an AWS Identity and Access Management (IAM) role with appropriate permissions to allow SageMaker to access AWS Secrets Manager, Amazon S3, and other services within your AWS account. Until an AWS CloudFormation template is provided that creates the role with the requisite IAM permissions, use a SageMaker role that allows the
AmazonSageMakerFullAccessAWS managed policy for your role. - Secrets Manager secret – Set up a secret in Secrets Manager for the PrestoDB user name and password. Call the secret prestodb-credentials and add a username field and password field to it. For instructions, refer to Create and manage secrets with AWS Secrets Manager.
Deploy the solution
Complete the following steps to deploy the solution:
- Clone the GitHub repository in SageMaker Studio. For instructions, see Clone a Git Repository in SageMaker Studio Classic.
- Edit the
config.ymlfile as follows:- Edit the parameter values in the presto section. These parameters define the connectivity to PrestoDB.
- Edit the parameter values in the
awssection. These parameters define the network connectivity, IAM role, bucket name, AWS Region, and other AWS Cloud-related parameters. - Edit the parameter values in the sections corresponding to the pipeline steps (
training_step, tuning_step, transform_step, and so on). - Review all the parameters in these sections carefully and edit them as appropriate for your use case.
When the prerequisites are complete and the config.yml file is set up correctly, you’re ready to run the mlops-pipeline-prestodb solution. The following architecture diagram provides a visual representation of the steps that you implement.
The diagram shows the following three steps:
- Part 1: Training – This pipeline includes the data preprocessing step, the training and tuning step, the model evaluation step, the condition step, and the register model step. The train, test, and validation datasets and evaluation report that are generated in this pipeline are sent to an S3 bucket.
- Part 2: Batch transform – This pipeline includes the batch data preprocessing step, approving the latest model from the model registry, creating the model instance, and performing batch transformation on data that is stored and retrieved from an S3 bucket.
- The PrestoDB server is hosted on an EC2 instance, with credentials stored in Secrets Manager.
- Part 3: SageMaker real-time inference – Finally, the latest approved model from the SageMaker model registry is deployed as a SageMaker real-time endpoint for inference.
Test the solution
In this section, we walk through the steps of running the solution.
Training pipeline
Complete the following steps to run the training pipeline
(0_model_training_pipeline.ipynb):
- On the SageMaker Studio console, choose
0_model_training_pipeline.ipynbin the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook demonstrates how you can use SageMaker Pipelines to string together a sequence of data processing, model training, tuning, and evaluation steps to train a binary classification ML model using scikit-learn.
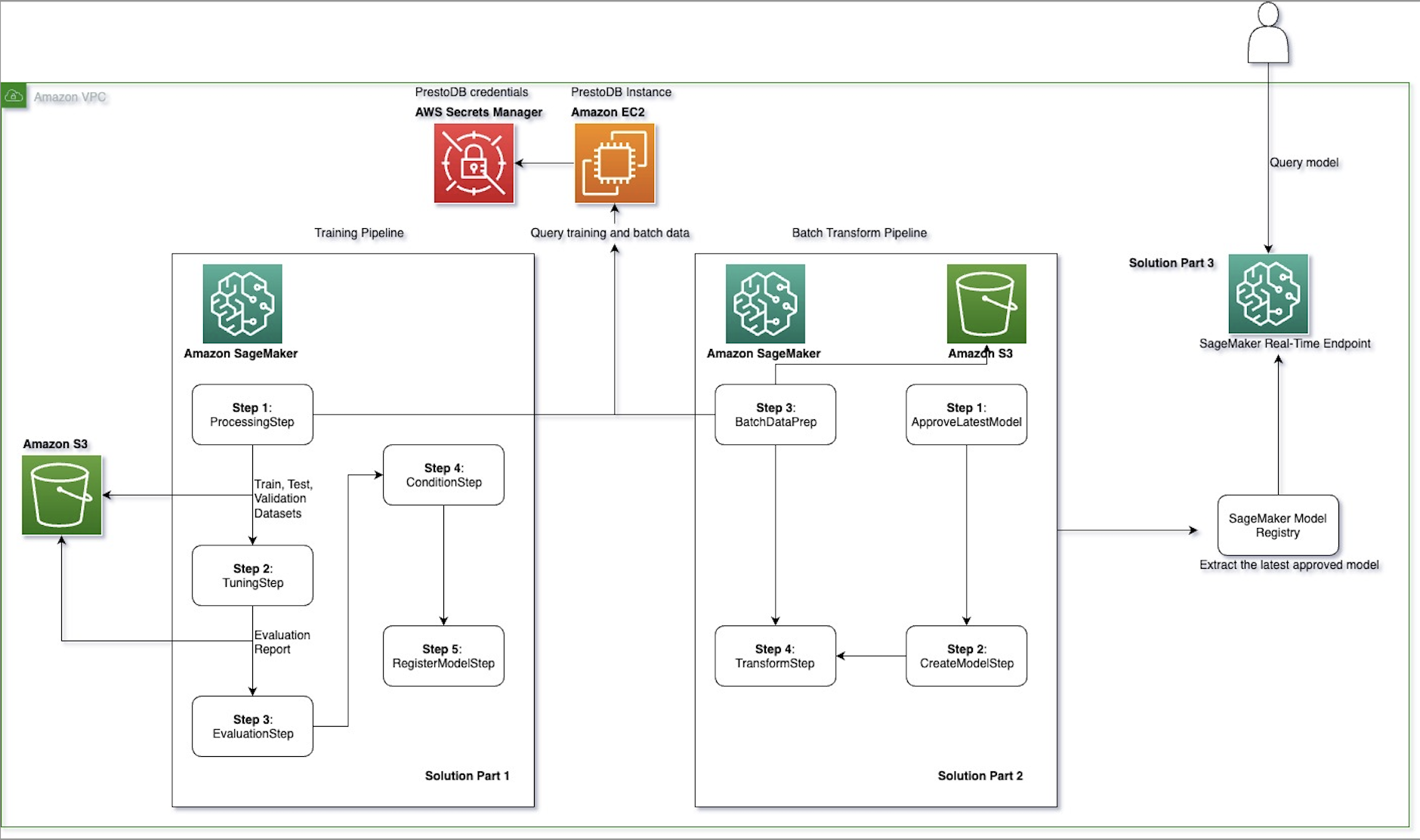
At the end of this run, navigate to pipelines in the navigation pane. Your pipeline structure on SageMaker Pipelines should look like the following figure.
The training pipeline consists of the following steps that are implemented through the notebook run:
- Preprocess the data – In this step, we create a processing job for data preprocessing. For more information on processing jobs, see Process data. We use a preprocessing script to connect and query data from a PrestoDB instance using the user-specified SQL query in the config file. This step splits and sends data retrieved from PrestoDB as train, test, and validation files to an S3 bucket. The ML model is trained using the data in these files.
- The sklearn_processor is used in the ProcessingStep to run the scikit-learn script that preprocesses data. The step is defined as follows:
Here, we use config['scripts']['source_dir'], which points to the data preprocessing script that connects to the PrestoDB instance. Parameters used as arguments in step_args are configurable and fetched from the config file.
- Train the model – In this step, we create a training job to train a model. For more information on training jobs, see Train a Model with Amazon SageMaker. Here, we use the Scikit Learn Estimator from the SageMaker SDK to handle the end-to-end training and deployment of custom Scikit-learn code. The
RandomForestClassifieris used to train the ML model for our binary classification use case. TheHyperparameterTunerclass is used for running automatic model tuning to determine the set of hyperparameters that provide the best performance based on a user-defined metric threshold (for example, maximizing the AUC metric).
In the following code, the sklearn_estimator object is used with parameters that are configured in the config file and uses a training script to train the ML model. This step accesses the train, test, and validation files that were created as a part of the previous data preprocessing step.
- Evaluate the model – This step checks if the trained and tuned model has an accuracy level above a user-defined threshold, and only then registers the model with the model registry. If the model accuracy doesn’t meet the user-defined threshold, the pipeline fails and the model is not registered with the model registry. We use the ScriptProcessor with an evaluation script that a user creates to evaluate the trained model based on a metric of choice.
The evaluation step uses the evaluation script as a code entry. This script prepares the features and target values, and calculates the prediction probabilities using model.predict. At the end of the run, an evaluation report is sent to Amazon S3 that contains information on precision, recall, and accuracy metrics.
The following screenshot shows an example of an evaluation report.

- Add conditions – After the model is evaluated, we can add conditions to the pipeline with a ConditionStep. This step registers the model only if the given user-defined metric threshold is met. In our solution, we only want to register the new model version with the model registry if the new model meets a specific accuracy condition of above 70%.
If the accuracy condition is not met, a step_fail step is run that sends an error message to the user, and the pipeline fails. For instance, because the user-defined accuracy condition is set to 0.7 in the config file, and the accuracy calculated during the evaluation step exceeds it (73.8%), the outcome of this step is set to True and the model moves to the last step of the training pipeline.
- Register the model – The
RegisterModelstep registers a sagemaker.model.Model or a sagemaker.pipeline.PipelineModel with the SageMaker model registry. When the trained model meets the model performance requirements, a new version of the model is registered with the SageMaker model registry.
The model is registered with the model registry with an approval status set to PendingManualApproval. This means the model can’t be deployed on a SageMaker endpoint unless its status in the registry is changed to Approved manually on the SageMaker console, programmatically, or through an AWS Lambda function.
Now that the model is registered, you can get access to the registered model manually on the SageMaker Studio model registry console or programmatically in the next notebook, approve it, and run the batch transform pipeline.
Batch transform pipeline
Complete the following steps to run the batch transform pipeline (1_batch_transform_pipeline.ipynb):
- On the SageMaker Studio console, choose
1_batch_transform_pipeline.ipynbin the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook will run a batch transform pipeline using the model trained in the previous notebook.
At the end of the batch transform pipeline, your pipeline structure on SageMaker Pipelines should look like the following figure.
![]()
The batch transform pipeline consists of the following steps that are implemented through the notebook run:
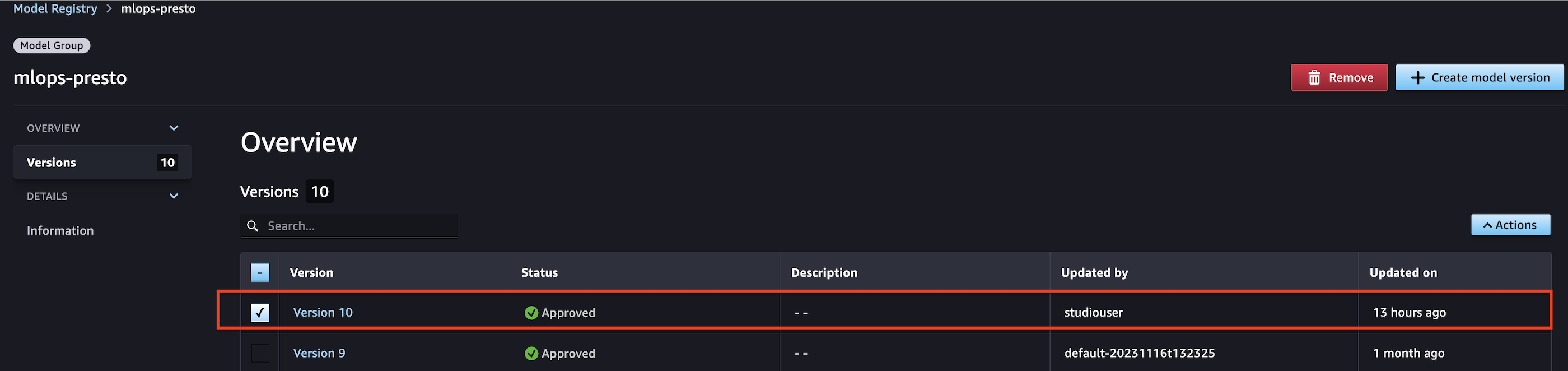
- Extract the latest approved model from the SageMaker model registry – In this step, we extract the latest model from the model registry and set the
ModelApprovalStatustoApproved:
Now we have extracted the latest model from the SageMaker model registry and programmatically approved it. You can also approve the model manually on the SageMaker model registry page in SageMaker Studio as shown in the following screenshot.
- Read raw data for inference from PrestoDB and store it in an S3 bucket – After the latest model is approved, batch data is fetched from the PrestoDB instance and used for the batch transform step. In this step, we use a batch preprocessing script that queries data from PrestoDB and saves it in a batch directory within an S3 bucket. The query that is used to fetch batch data is configured by the user within the config file in the
transform_stepsection:
After the batch data is extracted into the S3 bucket, we create a model instance and point to the inference.py script, which contains code that runs as part of getting inference from the trained model:
- Create a batch transform step to perform inference on the batch data stored in Amazon S3 – Now that a model instance is created, create a Transformer instance with the appropriate model type, compute instance type, and desired output S3 URI. Specifically, pass in the
ModelNamefrom the CreateModelStepstep_create_modelproperties. TheCreateModelStepproperties attribute matches the object model of theDescribeModelresponse object. Use a transform step for batch transformation to run inference on an entire dataset. For more information about batch transform, see Run Batch Transforms with Inference Pipelines. - A transform step requires a transformer and the data on which to run batch inference:
Now that the transformer object is created, pass the transformer input (which contains the batch data from the batch preprocess step) into the TransformStep declaration. Store the output of this pipeline in an S3 bucket.
SageMaker real-time inference
Complete the following steps to run the real-time inference pipeline (2_realtime_inference.ipynb):
- On the SageMaker Studio console, choose
2_realtime_inference_pipeline.ipynb in the navigation pane. - When the notebook is open, on the Run menu, choose Run All Cells to run the code in this notebook.
This notebook extracts the latest approved model from the model registry and deploys it as a SageMaker endpoint for real-time inference. It does so by completing the following steps:
- Extract the latest approved model from the SageMaker model registry – To deploy a real-time SageMaker endpoint, first fetch the image URI of your choice and extract the latest approved model from the model registry. After the latest approved model is extracted, we use a container list with the specified inference.py as the script for the deployed model to use at inference. This model creation and endpoint deployment are specific to the scikit-learn model configuration.
- In the following code, we use the
inference.pyfile specific to the scikit-learn model. We then create our endpoint configuration, setting ourManagedInstanceScalingtoENABLEDwith our desiredMaxInstanceCountandMinInstanceCountfor automatic scaling:
- Run inference on the deployed real-time endpoint – After you have extracted the latest approved model, created the model from the desired image URI, and configured the endpoint configuration, you can deploy it as a real-time SageMaker endpoint:
Upon deployment, you can view the endpoint in service on the SageMaker Endpoints page.

Now you can run inference against the data extracted from PrestoDB:
Results
Here is an example of an inference request and response from the real time endpoint using the implementation above:
Inference request format (view and change this example as you would like for your custom use case)
Response from the real time endpoint
Clean up
To clean up the endpoint used in this solution to avoid extra charges, complete the following steps:
- On the SageMaker console, choose Endpoints in the navigation pane.
- Select the endpoint to delete.
- On the Actions menu, choose Delete.

Conclusion
In this post, we demonstrated an end-to-end MLOps solution on SageMaker. The process involved fetching data by connecting a SageMaker Processing job to a PrestoDB instance, followed by training, evaluating, and registering the model. We approved the latest registered model from the training pipeline and ran batch inference against it using batch data queried from PrestoDB and stored in Amazon S3. Lastly, we deployed the latest approved model as a real-time SageMaker endpoint to run inferences.
The rise of generative AI increases the demand for training, deploying, and running ML models, and consequently, the use of data. By integrating SageMaker Processing jobs with PrestoDB, you can seamlessly migrate your workloads to SageMaker pipelines without additional data preparation, storage, or accessibility burdens. You can build, train, evaluate, run batch inferences, and deploy models as real-time endpoints while using your existing data engineering pipelines with minimal or no code changes.
Explore SageMaker Pipelines and open source data querying engines like PrestoDB, and build a solution using the sample implementation provided.
Get started today by referring to the GitHub repository.
For more information and tutorials on SageMaker Pipelines, refer to the SageMaker Pipelines documentation.
About the Authors
 Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
Madhur Prashant is an AI and ML Solutions Architect at Amazon Web Services. He is passionate about the intersection of human thinking and generative AI. His interests lie in generative AI, specifically building solutions that are helpful and harmless, and most of all optimal for customers. Outside of work, he loves doing yoga, hiking, spending time with his twin, and playing the guitar.
 Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
Amit Arora is an AI and ML Specialist Architect at Amazon Web Services, helping enterprise customers use cloud-based machine learning services to rapidly scale their innovations. He is also an adjunct lecturer in the MS data science and analytics program at Georgetown University in Washington D.C.
 Antara Raisa is an AI and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital-centered customers.
Antara Raisa is an AI and ML Solutions Architect at Amazon Web Services supporting strategic customers based out of Dallas, Texas. She also has experience working with large enterprise partners at AWS, where she worked as a Partner Success Solutions Architect for digital-centered customers.
 Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and AI.
Johnny Chivers is a Senior Solutions Architect working within the Strategic Accounts team at AWS. With over 10 years of experience helping customers adopt new technologies, he guides them through architecting end-to-end solutions spanning infrastructure, big data, and AI.
 Shamik Ray is a Senior Engineering Manager at Twilio, leading the Data Science and ML team. With 12 years of experience in software engineering and data science, he excels in overseeing complex machine learning projects and ensuring successful end-to-end execution and delivery.
Shamik Ray is a Senior Engineering Manager at Twilio, leading the Data Science and ML team. With 12 years of experience in software engineering and data science, he excels in overseeing complex machine learning projects and ensuring successful end-to-end execution and delivery.
 Srivyshnav K S is a Senior Machine Learning Engineer at Twilio with over 5 years of experience. His expertise lies in leveraging statistical and machine learning techniques to develop advanced models for detecting patterns and anomalies. He is adept at building projects end-to-end.
Srivyshnav K S is a Senior Machine Learning Engineer at Twilio with over 5 years of experience. His expertise lies in leveraging statistical and machine learning techniques to develop advanced models for detecting patterns and anomalies. He is adept at building projects end-to-end.
 Jagmohan Dhiman is a Senior Data Scientist with 7 years of experience in machine learning solutions. He has extensive expertise in building end-to-end solutions, encompassing data analysis, ML-based application development, architecture design, and MLOps pipelines for managing the model lifecycle.
Jagmohan Dhiman is a Senior Data Scientist with 7 years of experience in machine learning solutions. He has extensive expertise in building end-to-end solutions, encompassing data analysis, ML-based application development, architecture design, and MLOps pipelines for managing the model lifecycle.
 Soumya Kundu is a Senior Data Engineer with almost 10 years of experience in Cloud and Big Data technologies. He specialises in AI/ML based large scale Data Processing systems and an avid IoT enthusiast in his spare time.
Soumya Kundu is a Senior Data Engineer with almost 10 years of experience in Cloud and Big Data technologies. He specialises in AI/ML based large scale Data Processing systems and an avid IoT enthusiast in his spare time.
Accelerate deep learning training and simplify orchestration with AWS Trainium and AWS Batch
In large language model (LLM) training, effective orchestration and compute resource management poses a significant challenge. Automation of resource provisioning, scaling, and workflow management is vital for optimizing resource usage and streamlining complex workflows, thereby achieving efficient deep learning training processes. Simplified orchestration enables researchers and practitioners to focus more on model experimentation, hyperparameter tuning, and data analysis, rather than dealing with cumbersome infrastructure management tasks. Straightforward orchestration also accelerates innovation, shortens time-to-market for new models and applications, and ultimately enhances the overall efficiency and effectiveness of LLM research and development endeavors.
This post explores the seamless integration of AWS Trainium with AWS Batch, showcasing how the powerful machine learning (ML) acceleration capabilities of Trainium can be harnessed alongside the efficient orchestration functionalities offered by AWS Batch. Trainium provides massive scalability, enables effortless scaling of training jobs from small models to LLMs, and offers cost-effective access to computational power, making training LLMs affordable and accessible. AWS Batch is a managed service facilitating batch computing workloads on the AWS Cloud, handling tasks like infrastructure management and job scheduling, while enabling you to focus on application development and result analysis. AWS Batch provides comprehensive features, including managed batch computing, containerized workloads, custom compute environments, and prioritized job queues, along with seamless integration with other AWS services.
Solution overview
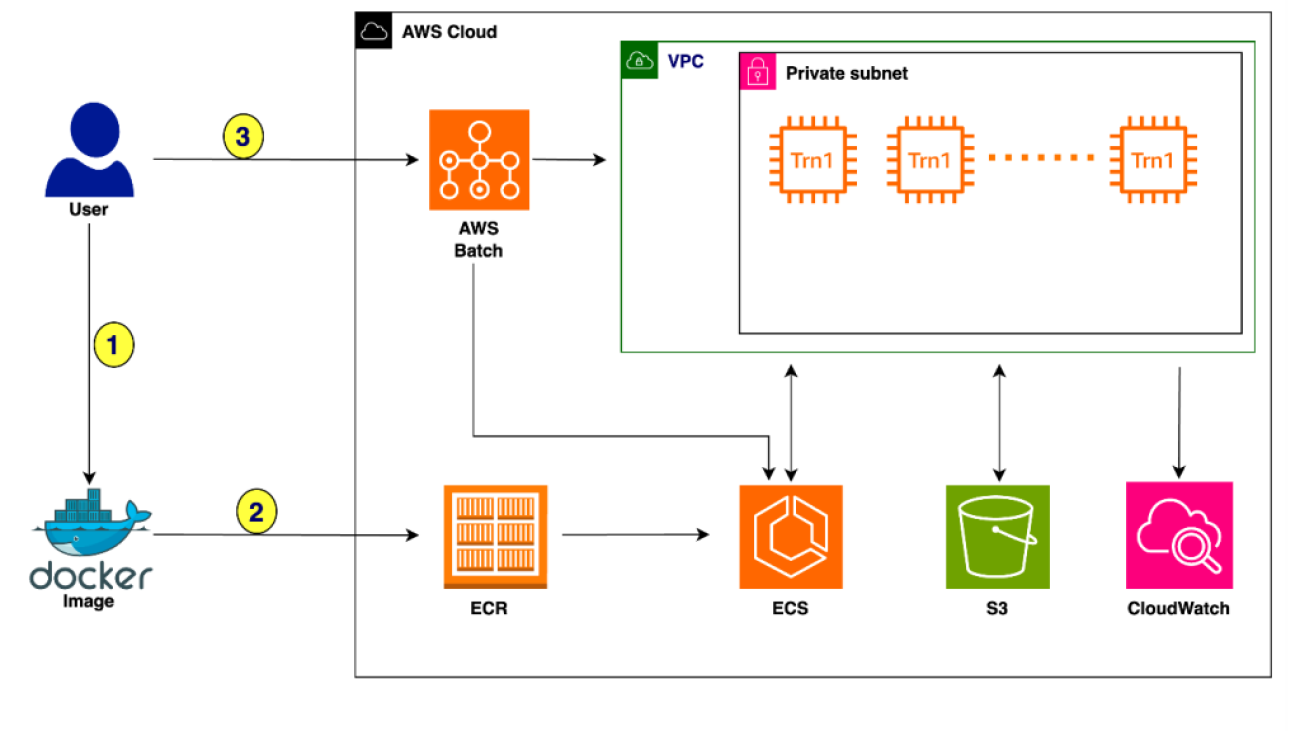
The following diagram illustrates the solution architecture.

The training process proceeds as follows:
- The user creates a Docker image configured to suit the demands of the underlying training task.
- The image is pushed to Amazon Elastic Container Registry (Amazon ECR) to make it ready for deployment.
- The user submits the training job to AWS Batch with the Docker image.
Let’s deep dive into this solution to see how you can integrate Trainium with AWS Batch. The following example demonstrates how to train the Llama 2-7B model using AWS Batch with Trainium.
Prerequisites
It is advised to not run the following scripts on your local machine. Instead, clone the GitHub repository and run the provided scripts on an x86_64-based instance, preferably using a C5.xlarge instance type with the Linux/Ubuntu operating system. For this post, we run the example on an Amazon Linux 2023 instance.
You should have the following resources and tools before getting started with the training on AWS Batch:
- VPC – For this example, you require a VPC that has at least two subnets (one public and one private) and a NAT gateway. For instructions to create a VPC with a NAT gateway, refer to Configure a VPC with Private Subnets and a NAT Gateway.
- ECR repository – You need an ECR repository to store your Docker container image. For setup instructions, see Creating a private repository.
- S3 bucket – You need an Amazon Simple Storage Service (Amazon S3) to store tokenized datasets, Neuron compile cache artifacts, and Llama checkpoint files. For instructions, refer to Create your first S3 bucket.
- IAM role – You need an AWS Identity and Access Management (IAM) role that is associated with the Trn1 instances. Make sure this role has the AmazonEC2ContainerServiceforEC2Role and AmazonS3FullAccess policies associated with it. To learn more about IAM roles, refer Creating IAM roles.
- AWS CLI – The AWS Command Line Interface (AWS CLI) should be installed and configured with permissions for AWS Batch and Amazon ECR. This isn’t needed if you’re using Amazon Linux 2023, but for other operating systems, you can follow the instructions in Install or update to the latest version of the AWS CLI to install the AWS CLI.
- Other tools – Docker and jq should also be installed. You can use the following commands to install them on AL2023:
Clone the repo
Clone the GitHub repo and navigate to the required directory:
Update the configuration
First, update the config.txt file to specify values for the following variables:
After you provide these values, your config.txt file should look something like the following code
Get the Llama tokenizer
To tokenize the dataset, you would need to get the tokenizer from Hugging Face. Follow the instructions to access the Llama tokenizer. (You need to acknowledge and accept the license terms.) After you’re granted access, you can download the tokenizer from Hugging Face. After a successful download, place the tokenizer.model file in the root directory (llama2).
Set up Llama training
Run the setup.sh script, which streamlines the prerequisite steps for initiating the AWS Batch training. This script downloads the necessary Python files for training the Llama 2-7B model. Additionally, it performs environment variable substitution within the provided templates and scripts designed to establish AWS Batch resources. When it runs, it makes sure your directory structure conforms to the following setup:
Tokenize the dataset
Next, run the download_and_tokenize_data.sh script to complete the data preprocessing steps for Llama 2-7B training. In this instance, we use the wikicorpus dataset sourced from Hugging Face. After the dataset retrieval, the script performs tokenization and uploads the tokenized dataset to the predefined S3 location specified within the config.txt configuration file. The following screenshots show the preprocessing results.


Provision resources
Next, run the create_resources.sh script, which orchestrates the provisioning of the required resources for the training task. This includes creation of a placement group, launch template, compute environment, job queue, and job definition. The following screenshots illustrate this process.




Build and push the Docker image
Now you can run the script build_and_push_docker_image.sh, which constructs a Docker container image customized for your specific training task. This script uses a Deep Learning Container Image published by the Neuron team, which contains the required software stack, and then added instructions for running the Llama 2-7B training on top of it. The training script uses the neuronx_distributed library with tensor parallelism along with the ZeRO-1 Optimizer. Subsequently, the newly generated Docker container image is uploaded to your designated ECR repository as specified by the variable ECR_REPO in the configuration file config.txt.
If you want to modify any of the Llama training hyperparameters, make the required changes in ./docker/llama_batch_training.sh before running build_and_push_docker_image.sh.
The following screenshots illustrate the process for building and pushing the Docker image.


Submit the training job
Run the submit_batch_job.sh script to initiate the AWS Batch job and start the Llama2 model training, as shown in the following screenshots.


Upon batch job submission, an Amazon Elastic Container Service (Amazon ECS) cluster is dynamically provisioned. When it’s operational, you can navigate to the cluster to monitor all tasks actively running on the Trn1.32xl instances, launched through this job. By default, this example is configured to use 4 trn1.32xl instances. To customize this setting, you can modify the numNodes parameter in the submit_batch_job.sh script.


Logs and monitoring
After the job submission, you can use Amazon CloudWatch Logs for comprehensive monitoring, storage, and viewing of all logs generated by AWS Batch. Complete the following steps to access the logs:
- On the CloudWatch console, choose Log groups under Logs in the navigation pane.
- Choose
/aws/batch/jobto view the batch job logs. - Look for log groups that match your AWS Batch job names or job definitions.
- Choose the job to view its details.
The following screenshot shows an example.

Checkpoints
Checkpoints generated during training will be stored in the predefined S3 location specified as CHECKPOINT_SAVE_URI in the config.txt file. By default, the checkpoint is saved when training is complete. However, you can adjust this behavior by opting to save the checkpoint after every N steps within the training loop. For detailed instructions on this customization, refer to Checkpointing.

Clean up
When you’re done, run the cleanup.sh script to manage the removal of resources created during the post. This script takes care of removing various components, such as the launch template, placement group, job definition, job queue, and compute environment. AWS Batch automatically handles the cleanup of the ECS stack and Trainium instances, so there’s no need to manually remove or stop them.
Conclusion
The seamless integration of Trainium with AWS Batch represents a significant advancement in the realm of ML training. By combining the unparalleled capabilities of Trainium with the powerful orchestration functionalities of AWS Batch, you stand to benefit in numerous ways. Firstly, you gain access to massive scalability, with the ability to effortlessly scale training jobs from small models to LLMs. With up to 16 Trainium chips per instance and the potential for distributed training across tens of thousands of accelerators, you can tackle even the most demanding training tasks with ease by virtue of Trainium instances. Additionally, it offers a cost-effective solution, helping you harness the power you need at an appealing price point. With the fully managed service offered by AWS Batch for computing workloads, you can offload operational complexities such as infrastructure provisioning and job scheduling, allowing you to focus your efforts on building applications and analyzing results. Ultimately, the integration of Trainium with AWS Batch empowers you to accelerate innovation, shorten time-to-market for new models and applications, and enhance the overall efficiency and effectiveness of your ML endeavors.
Now that you have learned about orchestrating Trainium using AWS Batch, we encourage you to try it out for your next deep learning training job. You can explore more tutorials that will help you gain hands-on experience with AWS Batch and Trainium, and enable you to manage your deep learning training workloads and resources for better performance and cost-efficiency. So why wait? Start exploring these tutorials today and take your deep learning training to the next level with Trainium and AWS Batch!
About the authors
 Scott Perry is a Solutions Architect on the Annapurna ML accelerator team at AWS. Based in Canada, he helps customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium. His interests include large language models, deep reinforcement learning, IoT, and genomics.
Scott Perry is a Solutions Architect on the Annapurna ML accelerator team at AWS. Based in Canada, he helps customers deploy and optimize deep learning training and inference workloads using AWS Inferentia and AWS Trainium. His interests include large language models, deep reinforcement learning, IoT, and genomics.
 Sadaf Rasool is a Machine Learning Engineer with Annapurna ML Accelerator team at AWS. As an enthusiastic and optimistic AI/ML professional, he holds firm to the belief that the ethical and responsible application of AI has the potential to enhance society in the years to come, fostering both economic growth and social well-being.
Sadaf Rasool is a Machine Learning Engineer with Annapurna ML Accelerator team at AWS. As an enthusiastic and optimistic AI/ML professional, he holds firm to the belief that the ethical and responsible application of AI has the potential to enhance society in the years to come, fostering both economic growth and social well-being.

Microsoft at CVPR 2024: Innovations in computer vision and AI research

Microsoft is proud to sponsor the 41st annual Conference on Computer Vision and Pattern Recognition (CVPR 2024), held from June 17 to June 21. This premier conference covers a broad spectrum of topics in the field, including 3D reconstruction and modeling, action and motion analysis, video and image processing, synthetic data generation, neural networks, and many more. This year, 63 papers from Microsoft have been accepted, with six selected for oral presentations. This post highlights these contributions.
The diversity of these research projects reflects the interdisciplinary approach that Microsoft research teams have taken, from techniques that precisely recreate 3D human figures and perspectives in augmented reality (AR) to combining advanced image segmentation with synthetic data to better replicate real-world scenarios. Other projects demonstrate how researchers are combining machine learning with natural language processing and structured data, developing models that not only visualize but also interact with their environments. Collectively, these projects aim to improve machine perception and enable more accurate and responsive interactions with the world.
Microsoft Research Podcast

What’s Your Story: Jacki O’Neill
Jacki O’Neill saw an opportunity to expand Microsoft research efforts to Africa. She now leads Microsoft Research Africa, Nairobi (formerly MARI). O’Neill talks about the choices that got her there, the lab’s impact, and how living abroad is good for innovation.
Oral presentations
BIOCLIP: A Vision Foundation Model for the Tree of Life
Samuel Stevens, Jiaman Wu, Matthew J Thompson, Elizabeth G. Campolongo, Chan Hee Song, David Carlyn, Li Dong, W. Dahdul, Charles Stewart, Tanya Y. Berger-Wolf, Wei-Lun Chao, Yu Su
The surge in images captured from diverse sources—from drones to smartphones—offers a rich source of biological data. To harness this potential, we introduce TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images, and BioCLIP, a foundation model intended for the biological sciences. BioCLIP, utilizing the TreeOfLife-10M’s vast array of organism images and structured knowledge, excels in fine-grained biological classification, outperforming existing models by significant margins and demonstrating strong generalizability.
EgoGen: An Egocentric Synthetic Data Generator
Gen Li, Kaifeng Zhao, Siwei Zhang, Xiaozhong Lyu, Mihai Dusmanu, Yan Zhang, Marc Pollefeys
A critical challenge in augmented reality (AR) is simulating realistic anatomical movements to guide cameras for authentic egocentric views. To overcome this, the authors developed EgoGen, a sophisticated synthetic data generator that not only improves training data accuracy for egocentric tasks but also refines the integration of motion and perception. It offers a practical solution for creating realistic egocentric training data, with the goal of serving as a useful tool for egocentric computer vision research.
Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, Lu Yuan
Florence-2 introduces a unified, prompt-based vision foundation model capable of handling a variety of tasks, from captioning to object detection and segmentation. Designed to interpret text prompts as task instructions, Florence-2 generates text outputs across a spectrum of vision and vision-language tasks. This model’s training utilizes the FLD-5B dataset, which includes 5.4 billion annotations on 126 million images, developed using an iterative strategy of automated image annotation and continual model refinement.
LISA: Reasoning Segmentation via Large Language Model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, Jiaya Jia
This work introduces reasoning segmentation, a new segmentation task using complex query texts to generate segmentation masks. The authors also established a new benchmark, comprising over a thousand image-instruction-mask data samples, incorporating intricate reasoning and world knowledge for evaluation. Finally, the authors present Large Language Instructed Segmentation Assistant (LISA), a tool that combines the linguistic capabilities of large language models with the ability to produce segmentation masks. LISA effectively handles complex queries and shows robust zero-shot learning abilities, further enhanced by minimal fine-tuning.
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Zeren Jiang, Chen Guo, Manuel Kaufmann, Tianjian Jiang, Julien Valentin (opens in new tab), Otmar Hilliges, Jie Song
MultiPly is a new framework for reconstructing multiple people in 3D from single-camera videos in natural settings. This technique employs a layered neural representation for the entire scene, refined through layer-wise differentiable volume rendering. Enhanced by a hybrid instance segmentation that combines self-supervised 3D and promptable 2D techniques, it provides reliable segmentation even with close interactions. The process uses confidence-guided optimization to alternately refine human poses and shapes, achieving high-fidelity, consistent 3D models.
SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes
Alexandros Delitzas, Ayça Takmaz, Federico Tombari, Robert Sumner, Marc Pollefeys, Francis Engelmann
Traditional 3D scene understanding methods are heavily focused on 3D sematic and instance segmentation, but the true challenge lies in interacting with functional interactive elements like handles, knobs, and buttons to achieve specific tasks. Enter SceneFun3D: a robust dataset featuring over 14,800 precise interaction annotations across 710 high-resolution real-world 3D indoor scenes. This dataset enriches scene comprehension with motion parameters and task-specific natural language descriptions, facilitating advanced research in functionality segmentation, task-driven affordance grounding, and 3D motion estimation.
Discover more about our work and contributions to CVPR 2024, including our full list of publications and sessions, on our conference webpage.
The post Microsoft at CVPR 2024: Innovations in computer vision and AI research appeared first on Microsoft Research.

Generating audio for video
Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

Generating audio for video
Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

Generating audio for video
Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More