Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More


Multi-agent approaches to AI applications, where multiple foundation model-based agents collaborate to solve problems, are emerging as a powerful paradigm for accomplishing increasingly complex tasks. In September 2023, we released AutoGen – a flexible and open-source Python-based framework for defining, configuring, and composing AI agents to drive multi-agent applications. Today, we are introducing AutoGen Studio (version 0.1.0) – a low-code interface for rapidly building, testing, and sharing multi-agent solutions. AutoGen Studio is built on AutoGen and inherits its features and functionalities, while providing a user-friendly and intuitive interface to create and customize agents, with little to no coding required.
During the nine months since it was released, AutoGen (opens in new tab) has been widely adopted by researchers, developers, and enthusiasts who have created a variety of novel and exciting applications (opens in new tab) – from market research to interactive educational tools to data analysis pipelines in the medical domain. With more than 290 community contributors on GitHub and 890,000 downloads of the Python package (as of May 2024), AutoGen continues to be a leading framework for building and researching multi-agent AI applications.

AutoGen Studio is the next step forward in enabling developers to advance the multi-agent paradigm. We want to make multi-agent solutions responsibly available to diverse audiences – from academic researchers to professional developers across industries – who want to build multi-agent applications to solve real-world problems. Imagine having access to agents that can automate your vacation planning and grocery shopping, manage your personal finances, help you accomplish your learning goals, or perform any other task you care about. How would you build such agents? What capabilities would you give them? How would you make them work together? How would you ensure they are working as intended?
These questions motivated us to build AutoGen Studio. With AutoGen Studio, developers can rapidly build, test, deploy, and share agents and agent-teams (workflows), with the community.
Note: AutoGen is primarily a developer tool to enable rapid prototyping and research. It is not a production ready tool. Please see the GitHub repository (opens in new tab) and documentation (opens in new tab) for instructions on how to get started.
We built AutoGen Studio with the following goals in mind:
With AutoGen Studio’s early release (v 0.1.0), users can rapidly author agent workflows via a user interface, interactively test and debug agents, reuse artifacts, and deploy workflows.
AutoGen Studio provides a “Build” section where users can choose from a library of pre-defined agents and compose them into teams (workflows) that can address tasks in minutes. Furthermore, users can customize agents and agent teams with foundation models, prompts, skills (python functions that accomplish a specific task e.g., fetching the weather from a weather provider), and workflows via a graphical user interface. Workflows may be sequential (where agents act in a predefined sequential order) or autonomous chat (where the order in which agents act may be driven by a large language model, custom logic, all based on the state of the task).

AutoGen Studio allows developers to immediately test workflows on a variety of tasks and review resulting artifacts (such as images, code, and documents). Developers can also review the “inner monologue” of agent workflows as they address tasks, and view profiling information such as costs associated with the run (such as number of turns and number of tokens), and agent actions (such as whether tools were called and the outcomes of code execution).


Users can download the skills, agents, and workflow configurations they create as well as share and reuse these artifacts. AutoGen Studio also offers a seamless process to export workflows and deploy them as application programming interfaces (APIs) that can be consumed in other applications deploying workflows as APIs.
Specifically, workflows can be exported as JavaScript Object Notation (JSON) files and loaded into any python application, launched as an API endpoint from the command line or wrapped into a Dockerfile that can be deployed on cloud services like Azure Container Apps or Azure Web Apps.

Spotlight: AI-POWERED EXPERIENCE

Discover more about research at Microsoft through our AI-powered experience
Over the last few months, we have shared an early version of AutoGen Studio, which has been downloaded more than 154,000 times on pypi (January – May 2024). Our observations of early usage patterns (based on feedback from social platforms like GitHub discussions (opens in new tab) , Discord (opens in new tab) and Youtube (opens in new tab) (opens in new tab)) suggest that AutoGen Studio is driving a new group of users who have basic technical capabilities (that is, they can install the tool) and are interested in rapidly testing out ideas but have limited programming skills.
We have seen these users prototype examples covering tasks like travel planning, pdf brochure generation, market research, structured data extraction, video generation, and visualization generation among others. Importantly, these tasks are accomplished simply by defining agents, giving them access to large language models and skills, adding agents to a workflow, and running tasks with these workflows.
Orchestrating teams of agents that can explore plans, reflect on actions, and collaborate offers opportunities to build tools that address challenging tasks. We believe that we are just scratching the surface of what may be possible with the multi-agent paradigm, and much is unknown about how best to harness foundation models, let alone foundation model-based agents and multi-agent solutions.
This leaves open many opportunities for further research.
For example, the sophisticated interplay between agents in multi-agent paradigms, particularly for increasingly more complex and dynamic domains, highlights many opportunities for multi-agent evaluation and tooling. Open questions include:
These questions require novel methods and metrics that can capture the multi-faceted aspects of multi-agent paradigms and provide actionable insights for developers and users.
As our understanding of the multi-agent paradigm matures, another opportunity is in distilling design patterns and best practices for building effective agent teams for different types of tasks. For instance:
These questions require systematic studies and empirical evaluations to discover the key dimensions and principles for designing multi-agent solutions.
Finally, as agents become more long-lived and ubiquitous in our digital world, an open challenge is in automating and optimizing the agent-creation process itself. For example:
Naturally, we see AutoGen Studio as a potential vehicle to study many of these research questions – from improvements in the user experience of authoring workflows to a gallery of shareable artifacts to advanced tools for making sense of agent behaviors.
We are currently working on a new drag-and-drop experience in AutoGen Studio, designed to transform how users’ author multi-agent workflows. Our new visual canvas allows users to easily orchestrate and connect agents, providing an intuitive interface for defining collaboration dynamics.

Visual workflow design: The heart of our enhanced user interface is a visual canvas where you can literally see your workflow come to life. Drag and drop different agents onto the canvas to build complex conversation patterns. This graphical approach not only simplifies the initial setup but also makes the process of modifying agents and workflows more intuitive.

Configurable agents, models, and skills: Customize each agent’s role and skills through simple, direct interactions on the canvas. Whether you’re adding new capabilities or tweaking existing ones, the process is straightforward and user-friendly.

Dynamic prototyping and testing: Experimentation is key to perfecting agent workflows. With our new interface, you can prototype various agent configurations and immediately test them in a live environment. This real-time interaction allows you to chat with the workflow, observe all agent messages, and pinpoint areas for improvement on the fly.

Finally, we are developing a community gallery within AutoGen Studio where users can share, discover, and learn from one another. This gallery will allow you to publish your workflows, agents, and skills, fostering a collaborative environment where everyone can benefit from shared knowledge and innovations.
AutoGen Studio is designed to provide a low-code environment for rapidly prototyping and testing multi-agent workflows. Our goal is to responsibly advance research and practice in solving problems with multiple agents and to develop tools that contribute to human well-being. Along with AutoGen, AutoGen Studio is committed to implementing features that promote safe and reliable outcomes. For example, AutoGen Studio offers profiling tools to make sense of agent actions and safeguards, such as support for Docker environments for code execution. This feature helps ensure that agents operate within controlled and secure environments, reducing the risk of unintended or harmful actions. For more information on our approach to responsible AI in AutoGen, please refer to transparency FAQS here: https://github.com/microsoft/autogen/blob/main/TRANSPARENCY_FAQS.md (opens in new tab). Finally, AutoGen Studio is not production ready i.e., it does not focus on implementing authentication and other security measures that are required for production ready deployments.
We would like to thank members of the open-source software (OSS) community and the AI Frontiers organization at Microsoft for discussions and feedback along the way. Specifically, we would like to thank Piali Choudhury, Ahmed Awadallah, Robin Moeur, Jack Gerrits, Robert Barber, Grace Proebsting, Michel Pahud, and others for feedback and comments.
The post Introducing AutoGen Studio: A low-code interface for building multi-agent workflows appeared first on Microsoft Research.

Video-to-audio research uses video pixels and text prompts to generate rich soundtracksRead More

NVIDIA researchers are at the forefront of the rapidly advancing field of visual generative AI, developing new techniques to create and interpret images, videos and 3D environments.
More than 50 of these projects will be showcased at the Computer Vision and Pattern Recognition (CVPR) conference, taking place June 17-21 in Seattle. Two of the papers — one on the training dynamics of diffusion models and another on high-definition maps for autonomous vehicles — are finalists for CVPR’s Best Paper Awards.
NVIDIA is also the winner of the CVPR Autonomous Grand Challenge’s End-to-End Driving at Scale track — a significant milestone that demonstrates the company’s use of generative AI for comprehensive self-driving models. The winning submission, which outperformed more than 450 entries worldwide, also received CVPR’s Innovation Award.
NVIDIA’s research at CVPR includes a text-to-image model that can be easily customized to depict a specific object or character, a new model for object pose estimation, a technique to edit neural radiance fields (NeRFs) and a visual language model that can understand memes. Additional papers introduce domain-specific innovations for industries including automotive, healthcare and robotics.
Collectively, the work introduces powerful AI models that could enable creators to more quickly bring their artistic visions to life, accelerate the training of autonomous robots for manufacturing, and support healthcare professionals by helping process radiology reports.
“Artificial intelligence, and generative AI in particular, represents a pivotal technological advancement,” said Jan Kautz, vice president of learning and perception research at NVIDIA. “At CVPR, NVIDIA Research is sharing how we’re pushing the boundaries of what’s possible — from powerful image generation models that could supercharge professional creators to autonomous driving software that could help enable next-generation self-driving cars.”
At CVPR, NVIDIA also announced NVIDIA Omniverse Cloud Sensor RTX, a set of microservices that enable physically accurate sensor simulation to accelerate the development of fully autonomous machines of every kind.
Creators harnessing diffusion models, the most popular method for generating images based on text prompts, often have a specific character or object in mind — they may, for example, be developing a storyboard around an animated mouse or brainstorming an ad campaign for a specific toy.
Prior research has enabled these creators to personalize the output of diffusion models to focus on a specific subject using fine-tuning — where a user trains the model on a custom dataset — but the process can be time-consuming and inaccessible for general users.
JeDi, a paper by researchers from Johns Hopkins University, Toyota Technological Institute at Chicago and NVIDIA, proposes a new technique that allows users to easily personalize the output of a diffusion model within a couple of seconds using reference images. The team found that the model achieves state-of-the-art quality, significantly outperforming existing fine-tuning-based and fine-tuning-free methods.
JeDi can also be combined with retrieval-augmented generation, or RAG, to generate visuals specific to a database, such as a brand’s product catalog.
NVIDIA researchers at CVPR are also presenting FoundationPose, a foundation model for object pose estimation and tracking that can be instantly applied to new objects during inference, without the need for fine-tuning.
The model, which set a new record on a popular benchmark for object pose estimation, uses either a small set of reference images or a 3D representation of an object to understand its shape. It can then identify and track how that object moves and rotates in 3D across a video, even in poor lighting conditions or complex scenes with visual obstructions.
FoundationPose could be used in industrial applications to help autonomous robots identify and track the objects they interact with. It could also be used in augmented reality applications where an AI model is used to overlay visuals on a live scene.
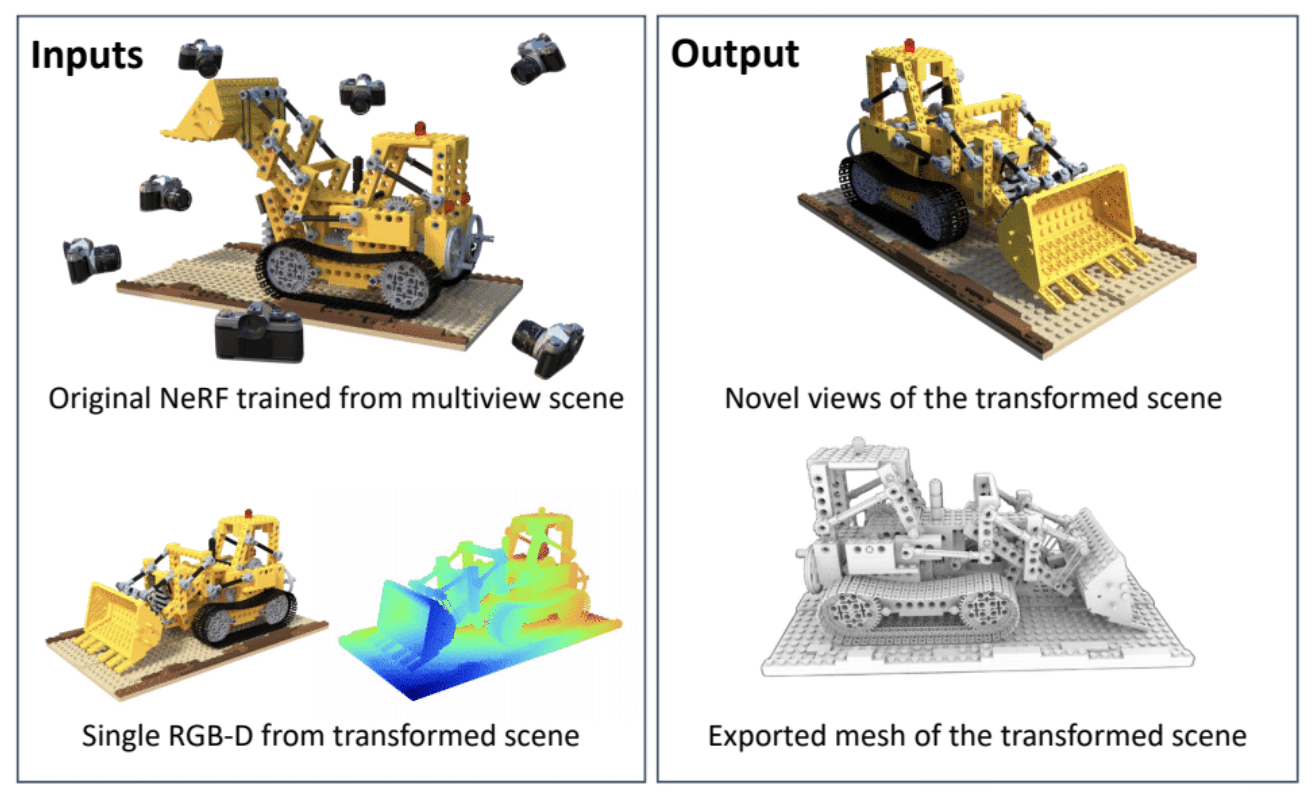
A NeRF is an AI model that can render a 3D scene based on a series of 2D images taken from different positions in the environment. In fields like robotics, NeRFs can be used to generate immersive 3D renders of complex real-world scenes, such as a cluttered room or a construction site. However, to make any changes, developers would need to manually define how the scene has transformed — or remake the NeRF entirely.
Researchers from the University of Illinois Urbana-Champaign and NVIDIA have simplified the process with NeRFDeformer. The method, being presented at CVPR, can successfully transform an existing NeRF using a single RGB-D image, which is a combination of a normal photo and a depth map that captures how far each object in a scene is from the camera.
A CVPR research collaboration between NVIDIA and the Massachusetts Institute of Technology is advancing the state of the art for vision language models, which are generative AI models that can process videos, images and text.
The group developed VILA, a family of open-source visual language models that outperforms prior neural networks on key benchmarks that test how well AI models answer questions about images. VILA’s unique pretraining process unlocked new model capabilities, including enhanced world knowledge, stronger in-context learning and the ability to reason across multiple images.

The VILA model family can be optimized for inference using the NVIDIA TensorRT-LLM open-source library and can be deployed on NVIDIA GPUs in data centers, workstations and even edge devices.
Read more about VILA on the NVIDIA Technical Blog and GitHub.
A dozen of the NVIDIA-authored CVPR papers focus on autonomous vehicle research. Other AV-related highlights include:
Also at CVPR, NVIDIA contributed the largest ever indoor synthetic dataset to the AI City Challenge, helping researchers and developers advance the development of solutions for smart cities and industrial automation. The challenge’s datasets were generated using NVIDIA Omniverse, a platform of APIs, SDKs and services that enable developers to build Universal Scene Description (OpenUSD)-based applications and workflows.
NVIDIA Research has hundreds of scientists and engineers worldwide, with teams focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics. Learn more about NVIDIA Research at CVPR.

Making moves to accelerate self-driving car development, NVIDIA was today named an Autonomous Grand Challenge winner at the Computer Vision and Pattern Recognition (CVPR) conference, running this week in Seattle.
Building on last year’s win in 3D Occupancy Prediction, NVIDIA Research topped the leaderboard this year in the End-to-End Driving at Scale category with its Hydra-MDP model, outperforming more than 400 entries worldwide.
This milestone shows the importance of generative AI in building applications for physical AI deployments in autonomous vehicle (AV) development. The technology can also be applied to industrial environments, healthcare, robotics and other areas.
The winning submission received CVPR’s Innovation Award as well, recognizing NVIDIA’s approach to improving “any end-to-end driving model using learned open-loop proxy metrics.”
In addition, NVIDIA announced NVIDIA Omniverse Cloud Sensor RTX, a set of microservices that enable physically accurate sensor simulation to accelerate the development of fully autonomous machines of every kind.
The race to develop self-driving cars isn’t a sprint but more a never-ending triathlon, with three distinct yet crucial parts operating simultaneously: AI training, simulation and autonomous driving. Each requires its own accelerated computing platform, and together, the full-stack systems purpose-built for these steps form a powerful triad that enables continuous development cycles, always improving in performance and safety.
To accomplish this, a model is first trained on an AI supercomputer such as NVIDIA DGX. It’s then tested and validated in simulation — using the NVIDIA Omniverse platform and running on an NVIDIA OVX system — before entering the vehicle, where, lastly, the NVIDIA DRIVE AGX platform processes sensor data through the model in real time.
Building an autonomous system to navigate safely in the complex physical world is extremely challenging. The system needs to perceive and understand its surrounding environment holistically, then make correct, safe decisions in a fraction of a second. This requires human-like situational awareness to handle potentially dangerous or rare scenarios.
AV software development has traditionally been based on a modular approach, with separate components for object detection and tracking, trajectory prediction, and path planning and control.
End-to-end autonomous driving systems streamline this process using a unified model to take in sensor input and produce vehicle trajectories, helping avoid overcomplicated pipelines and providing a more holistic, data-driven approach to handle real-world scenarios.
Watch a video about the Hydra-MDP model, winner of the CVPR Autonomous Grand Challenge for End-to-End Driving:
This year’s CVPR challenge asked participants to develop an end-to-end AV model, trained using the nuPlan dataset, to generate driving trajectory based on sensor data.
The models were submitted for testing inside the open-source NAVSIM simulator and were tasked with navigating thousands of scenarios they hadn’t experienced yet. Model performance was scored based on metrics for safety, passenger comfort and deviation from the original recorded trajectory.
NVIDIA Research’s winning end-to-end model ingests camera and lidar data, as well as the vehicle’s trajectory history, to generate a safe, optimal vehicle path for five seconds post-sensor input.
The workflow NVIDIA researchers used to win the competition can be replicated in high-fidelity simulated environments with NVIDIA Omniverse. This means AV simulation developers can recreate the workflow in a physically accurate environment before testing their AVs in the real world. NVIDIA Omniverse Cloud Sensor RTX microservices will be available later this year. Sign up for early access.
In addition, NVIDIA ranked second for its submission to the CVPR Autonomous Grand Challenge for Driving with Language. NVIDIA’s approach connects vision language models and autonomous driving systems, integrating the power of large language models to help make decisions and achieve generalizable, explainable driving behavior.
More than 50 NVIDIA papers were accepted to this year’s CVPR, on topics spanning automotive, healthcare, robotics and more. Over a dozen papers will cover NVIDIA automotive-related research, including:
Sanja Fidler, vice president of AI research at NVIDIA, will speak on vision language models at the CVPR Workshop on Autonomous Driving.
Learn more about NVIDIA Research, a global team of hundreds of scientists and engineers focused on topics including AI, computer graphics, computer vision, self-driving cars and robotics.

NVIDIA contributed the largest ever indoor synthetic dataset to the Computer Vision and Pattern Recognition (CVPR) conference’s annual AI City Challenge — helping researchers and developers advance the development of solutions for smart cities and industrial automation.
The challenge, garnering over 700 teams from nearly 50 countries, tasks participants to develop AI models to enhance operational efficiency in physical settings, such as retail and warehouse environments, and intelligent traffic systems.
Teams tested their models on the datasets that were generated using NVIDIA Omniverse, a platform of application programming interfaces (APIs), software development kits (SDKs) and services that enable developers to build Universal Scene Description (OpenUSD)-based applications and workflows.
In large indoor spaces like factories and warehouses, daily activities involve a steady stream of people, small vehicles and future autonomous robots. Developers need solutions that can observe and measure activities, optimize operational efficiency, and prioritize human safety in complex, large-scale settings.
Researchers are addressing that need with computer vision models that can perceive and understand the physical world. It can be used in applications like multi-camera tracking, in which a model tracks multiple entities within a given environment.
To ensure their accuracy, the models must be trained on large, ground-truth datasets for a variety of real-world scenarios. But collecting that data can be a challenging, time-consuming and costly process.
AI researchers are turning to physically based simulations — such as digital twins of the physical world — to enhance AI simulation and training. These virtual environments can help generate synthetic data used to train AI models. Simulation also provides a way to run a multitude of “what-if” scenarios in a safe environment while addressing privacy and AI bias issues.
Creating synthetic data is important for AI training because it offers a large, scalable, and expandable amount of data. Teams can generate a diverse set of training data by changing many parameters including lighting, object locations, textures and colors.
This year’s AI City Challenge consists of five computer vision challenge tracks that span traffic management to worker safety.
NVIDIA contributed datasets for the first track, Multi-Camera Person Tracking, which saw the highest participation, with over 400 teams. The challenge used a benchmark and the largest synthetic dataset of its kind — comprising 212 hours of 1080p videos at 30 frames per second spanning 90 scenes across six virtual environments, including a warehouse, retail store and hospital.
Created in Omniverse, these scenes simulated nearly 1,000 cameras and featured around 2,500 digital human characters. It also provided a way for the researchers to generate data of the right size and fidelity to achieve the desired outcomes.
The benchmarks were created using Omniverse Replicator in NVIDIA Isaac Sim, a reference application that enables developers to design, simulate and train AI for robots, smart spaces or autonomous machines in physically based virtual environments built on NVIDIA Omniverse.
Omniverse Replicator, an SDK for building synthetic data generation pipelines, automated many manual tasks involved in generating quality synthetic data, including domain randomization, camera placement and calibration, character movement, and semantic labeling of data and ground-truth for benchmarking.
Ten institutions and organizations are collaborating with NVIDIA for the AI City Challenge:
Researchers and companies around the world are developing infrastructure automation and robots powered by physical AI — which are models that can understand instructions and autonomously perform complex tasks in the real world.
Generative physical AI uses reinforcement learning in simulated environments, where it perceives the world using accurately simulated sensors, performs actions grounded by laws of physics, and receives feedback to reason about the next set of actions.
Developers can tap into developer SDKs and APIs, such as the NVIDIA Metropolis developer stack — which includes a multi-camera tracking reference workflow — to add enhanced perception capabilities for factories, warehouses and retail operations. And with the latest release of NVIDIA Isaac Sim, developers can supercharge robotics workflows by simulating and training AI-based robots in physically based virtual spaces before real-world deployment.
Researchers and developers are also combining high-fidelity, physics-based simulation with advanced AI to bridge the gap between simulated training and real-world application. This helps ensure that synthetic training environments closely mimic real-world conditions for more seamless robot deployment.
NVIDIA is taking the accuracy and scale of simulations further with the recently announced NVIDIA Omniverse Cloud Sensor RTX, a set of microservices that enable physically accurate sensor simulation to accelerate the development of fully autonomous machines.
This technology will allow autonomous systems, whether a factory, vehicle or robot, to gather essential data to effectively perceive, navigate and interact with the real world. Using these microservices, developers can run large-scale tests on sensor perception within realistic, virtual environments, significantly reducing the time and cost associated with real-world testing.
Omniverse Cloud Sensor RTX microservices will be available later this year. Sign up for early access.
Participants submitted research papers for the AI City Challenge and a few achieved top rankings, including:
All accepted papers will be presented at the AI City Challenge 2024 Workshop, taking place on June 17.
At CVPR 2024, NVIDIA Research will present over 50 papers, introducing generative physical AI breakthroughs with potential applications in areas like autonomous vehicle development and robotics.
Papers that used NVIDIA Omniverse to generate synthetic data or digital twins of environments for model simulation, testing and validation include:
Read more about NVIDIA Research at CVPR, and learn more about the AI City Challenge.
Get started with NVIDIA Omniverse by downloading the standard license free, access OpenUSD resources and learn how Omniverse Enterprise can connect teams. Follow Omniverse on Instagram, Medium, LinkedIn and X. For more, join the Omniverse community on the forums, Discord server, Twitch and YouTube channels.
This paper was accepted in the Industry Track at SIGIR 2024.
Virtual Assistants (VAs) are important Information Retrieval platforms that help users accomplish various tasks through spoken commands. The speech recognition system (speech-to-text) uses query priors, trained solely on text, to distinguish between phonetically confusing alternatives. Hence, the generation of synthetic queries that are similar to existing VA usage can greatly improve upon the VA’s abilities-especially for use-cases that do not (yet) occur in paired audio/text data.
In this paper, we provide a preliminary exploration…Apple Machine Learning Research

NVIDIA founder and CEO Jensen Huang on Friday encouraged Caltech graduates to pursue their craft with dedication and resilience — and to view setbacks as new opportunities.
“I hope you believe in something. Something unconventional, something unexplored. But let it be informed, and let it be reasoned, and dedicate yourself to making that happen,” he said. “You may find your GPU. You may find your CUDA. You may find your generative AI. You may find your NVIDIA.”
Trading his signature leather jacket for black and yellow academic regalia, Huang addressed the nearly 600 graduates at their commencement ceremony in Pasadena, Calif., starting with the tale of the computing industry’s decades-long evolution to reach this pivotal moment of AI transformation.
“Computers today are the single most important instrument of knowledge, and it’s foundational to every single industry in every field of science,” Huang said. “As you enter industry, it’s important you know what’s happening.”
He shared how, over a decade ago, NVIDIA — a small company at the time — bet on deep learning, investing billions of dollars and years of engineering resources to reinvent every computing layer.
“No one knew how far deep learning could scale, and if we didn’t build it, we’d never know,” Huang said. Referencing the famous line from Field of Dreams — if you build it, he will come — he said, “Our logic is: If we don’t build it, they can’t come.”
Looking to the future, Huang said, the next wave of AI is robotics, a field where NVIDIA’s journey resulted from a series of setbacks.
He reflected on a period in NVIDIA’s past when the company each year built new products that “would be incredibly successful, generate enormous amounts of excitement. And then one year later, we were kicked out of those markets.”
These roadblocks pushed NVIDIA to seek out untapped areas — what Huang refers to as “zero-billion-dollar markets.”
“With no more markets to turn to, we decided to build something where we are sure there are no customers,” Huang said. “Because one of the things you can definitely guarantee is where there are no customers, there are also no competitors.”
Robotics was that new market. NVIDIA built the first robotics computer, Huang said, processing a deep learning algorithm. Over a decade later, that pivot has given the company the opportunity to create the next wave of AI.
“One setback after another, we shook it off and skated to the next opportunity. Each time, we gain skills and strengthen our character,” Huang said. “No setback that comes our way doesn’t look like an opportunity these days.”
Huang stressed the importance of resilience and agility as superpowers that strengthen character.
“The world can be unfair and deal you with tough cards. Swiftly shake it off,” he said, with a tongue-in-cheek reference to one of Taylor Swift’s biggest hits. “There’s another opportunity out there — or create one.”
Huang concluded by sharing a story from his travels to Japan, where, as he watched a gardener painstakingly tending to Kyoto’s famous moss garden, he realized that when a person is dedicated to their craft and prioritizes doing their life’s work, they always have plenty of time.
“Prioritize your life,” he said, “and you will have plenty of time to do the important things.”
Main image courtesy of Caltech.