This post was written in collaboration with Liran Zelkha and Eyal Solnik from Lili.
Small business proprietors tend to prioritize the operational aspects of their enterprises over administrative tasks, such as maintaining financial records and accounting. While hiring a professional accountant can provide valuable guidance and expertise, it can be cost-prohibitive for many small businesses. Moreover, the availability of accountants might not always align with the immediate needs of business owners, leaving them with unanswered questions or delayed decision-making processes.
In the rapidly evolving world of large language models (LLMs) and generative artificial intelligence (AI), Lili recognized an opportunity to use this technology to address the financial advisory needs of their small business customers. Using Anthropic’s Claude 3 Haiku on Amazon Bedrock, Lili developed an intelligent AccountantAI chatbot capable of providing on-demand accounting advice tailored to each customer’s financial history and unique business requirements. The AccountantAI chatbot serves as a virtual assistant, offering affordable and readily available financial guidance, empowering small business owners to focus on their core expertise while ensuring the financial health of their operations.
About Lili
Lili is a financial platform designed specifically for businesses, offering a combination of advanced business banking with built-in accounting and tax preparation software.
By consolidating financial tools into a user-friendly interface, Lili streamlines and simplifies managing business finances and makes it an attractive solution for business owners seeking a centralized and efficient way to manage their financial operations.
In this post, we’ll explore how Lili, a financial platform designed specifically for businesses, used Amazon Bedrock to build a secure and intelligent AccountantAI chatbot for small business owners. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Meta, Mistral AI, Stability AI, Cohere, AI21 Labs, and Amazon through a single API, along with a broad set of capabilities that you need to build generative AI applications with security, privacy, and responsible AI.
Solution overview
The AccountantAI chatbot provides small business owners with accurate and relevant financial accounting advice in a secure manner. To achieve this, the solution is designed to address two key requirements:
- Question validation: Implementing guardrails to ensure that the user’s input is a valid and a legitimate financial accounting question. This step helps filter out irrelevant or inappropriate queries, maintaining the integrity of the system.
- Context enrichment: Augmenting the user’s question with relevant contextual data, such as up-to-date accounting information and user-specific financial data. This step ensures that the chatbot’s responses are tailored to the individual user’s business and financial situation, providing more personalized and actionable advice.
To address the two key requirements of question validation and context enrichment, the AccountantAI solution employs a two-stage architecture comprising an ingestion workflow and a retrieval workflow.
Ingestion workflow

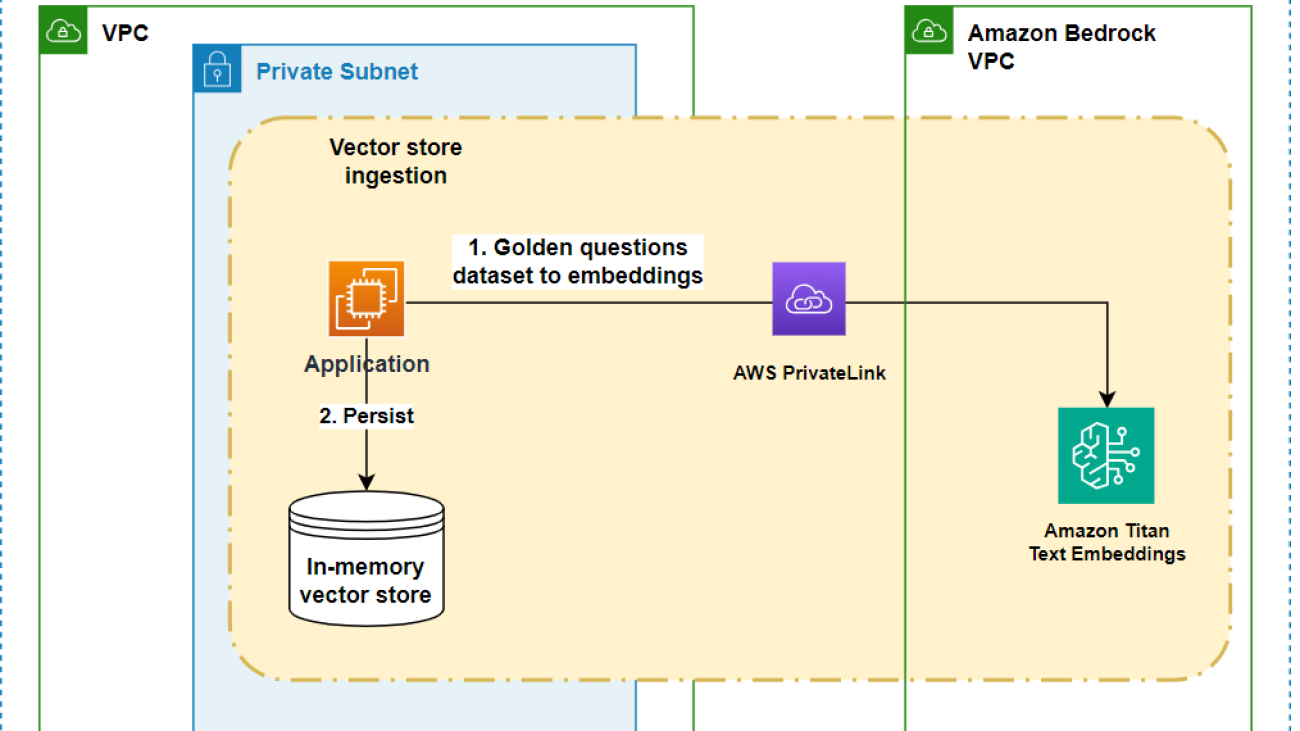
The ingestion workflow is an offline process that prepares the system for serving customer queries. For this stage, Lili curated a comprehensive golden collection of financial accounting questions, drawing from common inquiries as well as real-world questions from their customer base over the years. This diverse and high-quality collection serves as a reference corpus, ensuring that the chatbot can handle a wide range of relevant queries. The ingestion workflow transforms these curated questions into vector embeddings using Amazon Titan Text Embeddings model API. This process occurs over AWS PrivateLink for Amazon Bedrock, a protected and private connection in your VPC. The vector embeddings are persisted in the application in-memory vector store. These vectors will help to validate user input during the retrieval workflow.
Each curated vector embedding is paired with a matching prompt template that was evaluated during testing to be the most effective.
Example prompt template
Retrieval workflow

Lili’s web chatbot web interface allows users to submit queries and receive real-time responses. When a customer asks a question, it’s sent to the backend system for processing.
- The system first converts the query into a vector embedding using the Amazon Titan Text Embeddings model API, which is accessed securely through PrivateLink.
- Next, the system performs a similarity search on the pre-computed embeddings of the golden collection, to find the most relevant matches for the user’s query. The system evaluates the similarity scores of the search results against a predetermined threshold. If the user’s question yields matches with low similarity scores, it’s deemed malformed or unclear, and the user is prompted to rephrase or refine their query.
- However, if the user’s question produces matches with high similarity scores, it’s considered a legitimate query. In this case, Lili’s backend system proceeds with further processing using the golden question that has the highest similarity score to the user’s query.
- Based on the golden question with the highest similarity score, the system retrieves the corresponding prompt template.
This template is augmented with up-to-date accounting information and the customer’s specific financial data from external sources such as Amazon RDS for MySQL. The resulting contextualized prompt is sent to Anthropic’s Claude 3 Haiku on Amazon Bedrock, which generates a tailored response addressing the customer’s query within their unique business context.
Because model providers continually enhance their offerings with innovative updates, Amazon Bedrock simplifies the ability to adopt emerging advancements in generative AI across multiple model providers. This approach has demonstrated its advantages right from the initial rollout of AccountantAI. Lili transitioned from Anthropic’s Claude Instant to Claude 3 within two weeks of its official release on the Amazon Bedrock environment and three weeks after its general availability.
Lili selected Anthropic’s Claude model family for AccountantAI after reviewing industry benchmarks and conducting their own quality assessment. Anthropic Claude on Amazon Bedrock consistently outperformed other models in understanding financial concepts, generating coherent natural language, and providing accurate, tailored recommendations.
After the initial release of AcountantAI, Amazon Bedrock introduced Anthropic’s Claude 3 Haiku model, which Lili evaluated against Anthropic Claude Instant version. The Anthropic Claude 3 Haiku model demonstrated significant improvements across three key evaluation metrics:
- Quality – Anthropic Claude 3 Haiku delivered higher quality outputs, providing more detailed and better-phrased responses compared to its predecessor.
- Response time – Anthropic Claude 3 Haiku exhibited a 10 percent to 20 percent improvement in response times over Claude Instant, offering faster performance.
- Cost – Anthropic Claude 3 Haiku on Amazon Bedrock is the most cost-effective choice. For instance, it is up to 68 percent less costly per 1,000 input/output tokens compared to Anthropic Claude Instant, while delivering higher levels of intelligence and performance. See Anthropic’s Claude 3 models on Amazon Bedrock for more information.
For customers like Lili, this underscores the importance of having access to a fully managed service like Amazon Bedrock, which offers a choice of high-performing foundation models to meet diverse enterprise AI needs. There is no “one size fits all” model, and the ability to select from a range of cutting-edge FMs is crucial for organizations seeking to use the latest advancements in generative AI effectively and cost-efficiently.
Conclusion
The AccountantAI feature, exclusively available to Lili customers, reduces the need for hiring a professional accountant. While professional accountants can provide valuable guidance and expertise, their services can be cost-prohibitive for many small businesses. AccountantAI has already answered thousands of questions, delivering real value to businesses and providing quality responses to financial, tax, and accounting inquiries.
Using Amazon Bedrock for easy, secure, and reliable access to high-performing foundation models from leading AI companies, Lili integrates accounting knowledge at scale with each customer’s unique data. This innovative solution offers affordable expertise on optimizing cash flow, streamlining tax planning, and enabling informed decisions to drive growth. AccountantAI bridges the gap in accounting resources, democratizing access to high-quality financial intelligence for every business.
Explore Lili’s AccountantAI feature powered by Amazon Bedrock to gain affordable and accessible financial intelligence for your business today, or use Amazon Bedrock Playgrounds to experiment with running inference on different models on your data.
About the authors
 Doron Bleiberg is a senior AWS Startups Solution Architect helping Fintech customers in their cloud journey.
Doron Bleiberg is a senior AWS Startups Solution Architect helping Fintech customers in their cloud journey.
 Liran Zelkha is the co-founder and CTO at Lili, leading our development and data efforts.
Liran Zelkha is the co-founder and CTO at Lili, leading our development and data efforts.
 Eyal Solnik is the head of Data at Lili and leads our AccountantAI product.
Eyal Solnik is the head of Data at Lili and leads our AccountantAI product.

 Hemmy Yona is a Solutions Architect at Amazon Web Services based in Israel. With 20 years of experience in software development and group management, Hemmy is passionate about helping customers build innovative, scalable, and cost-effective solutions. Outside of work, you’ll find Hemmy enjoying sports and traveling with family.
Hemmy Yona is a Solutions Architect at Amazon Web Services based in Israel. With 20 years of experience in software development and group management, Hemmy is passionate about helping customers build innovative, scalable, and cost-effective solutions. Outside of work, you’ll find Hemmy enjoying sports and traveling with family. Tzahi Mizrahi is a Solutions Architect at Amazon Web Services, specializing in container solutions with over 10 years of experience in development and DevOps lifecycle processes. His expertise includes designing scalable, container-based architectures and optimizing deployment workflows. In his free time, he enjoys music and plays the guitar.
Tzahi Mizrahi is a Solutions Architect at Amazon Web Services, specializing in container solutions with over 10 years of experience in development and DevOps lifecycle processes. His expertise includes designing scalable, container-based architectures and optimizing deployment workflows. In his free time, he enjoys music and plays the guitar. Gili Nachum is a Principal solutions architect at AWS, specializing in Generative AI and Machine Learning. Gili is helping AWS customers build new foundation models, and to leverage LLMs to innovate in their business. In his spare time Gili enjoys family time and Calisthenics.
Gili Nachum is a Principal solutions architect at AWS, specializing in Generative AI and Machine Learning. Gili is helping AWS customers build new foundation models, and to leverage LLMs to innovate in their business. In his spare time Gili enjoys family time and Calisthenics. Maciej Mensfeld is a principal product architect at Mend, focusing on data acquisition, aggregation, and AI/LLM security research. He’s the creator of diffend.io (acquired by Mend) and Karafka. As a Software Architect, Security Researcher, and conference speaker, he teaches Ruby, Rails, and Kafka. Passionate about OSS, Maciej actively contributes to various projects, including Karafka, and is a member of the RubyGems security team.
Maciej Mensfeld is a principal product architect at Mend, focusing on data acquisition, aggregation, and AI/LLM security research. He’s the creator of diffend.io (acquired by Mend) and Karafka. As a Software Architect, Security Researcher, and conference speaker, he teaches Ruby, Rails, and Kafka. Passionate about OSS, Maciej actively contributes to various projects, including Karafka, and is a member of the RubyGems security team.
 Posted by the TensorFlow team
Posted by the TensorFlow team

 Google research teams spoke with high school students, parents and teachers to understand how AI can help support learning.
Google research teams spoke with high school students, parents and teachers to understand how AI can help support learning.
 Google announces the Coalition for Secure AI (CoSAI) alongside founding member organizations.
Google announces the Coalition for Secure AI (CoSAI) alongside founding member organizations.

 We’re partnering with Team USA and NBCUniversal to showcase our features in NBCU’s coverage of the Olympics and Paralympics.
We’re partnering with Team USA and NBCUniversal to showcase our features in NBCU’s coverage of the Olympics and Paralympics.



 NVIDIA GeForce NOW (@NVIDIAGFN)
NVIDIA GeForce NOW (@NVIDIAGFN) 
