Modern deep learning approaches usually utilize modality-specific processing. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate modality-independent representation learning by performing classification directly on file bytes, without the need for decoding files at inference time. This enables models to operate on various modalities without any hand-designed, modality-specific processing. Our model, ByteFormer, improves ImageNet Top-1 classification…Apple Machine Learning Research
MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
We introduce MIA-Bench, a new benchmark designed to evaluate multimodal large language models (MLLMs) on their ability to strictly adhere to complex instructions. Our benchmark comprises a diverse set of 400 image-prompt pairs, each crafted to challenge the models’ compliance with layered instructions in generating accurate responses that satisfy specific requested patterns. Evaluation results from a wide array of state-of-the-art MLLMs reveal significant variations in performance, highlighting areas for improvement in instruction fidelity. Additionally, we create extra training data and…Apple Machine Learning Research
Private Vector Mean Estimation in the Shuffle Model: Optimal Rates Require Many Messages
We study the problem of private vector mean estimation in the shuffle model of privacy where nnn users each have a unit vector in ddd dimensions. We propose a new multi-message protocol that achieves the optimal error using O~(min(nε2,d))tilde{mathcal{O}}left(min(nvarepsilon^2,d)right)O~(min(nε2,d)) messages per user. Moreover, we show that any (unbiased) protocol that achieves optimal error requires each user to send Ω(min(nε2,d)/log(n))Omega(min(nvarepsilon^2,d)/log(n))Ω(min(nε2,d)/log(n)) messages, demonstrating the optimality of our message complexity up to logarithmic…Apple Machine Learning Research

GeForce NOW Beats the Heat With 22 New Games in July
GeForce NOW is bringing 22 new games to members this month.
Dive into the four titles available to stream on the cloud gaming service this week to stay cool and entertained throughout the summer — whether poolside, on a long road trip or in the air-conditioned comfort of home.
Plus, get great games at great deals to stream across devices during the Steam Summer Sale. In total, more than 850 titles on GeForce NOW can be found at discounts in a dedicated Steam Summer Sale row on the GeForce NOW app, from now until July 11.
Time to Grind

In The First Descendant from NEXON, take on the role of Descendants tasked with safeguarding the powerful Iron Heart from relentless Vulgus invaders. Set in a captivating sci-fi universe, the game is a third-person co-op action role-playing shooter that seamlessly blends looting mechanics with strategic combat. Engage in intense gunplay, face off against formidable bosses and collect valuable loot while fighting to preserve humanity’s future.
Check out the list of new games this week:
- The Falconeer (Free on Epic Games Store, July 4)
- The First Descendant (Steam)
- Star Traders: Frontiers (Steam)
- Wuthering Waves (Native and Epic Games Store)
And members can look for the following later this month:
- Once Human (New release on Steam, July 9)
- Anger Foot (New release on Steam, July 11)
- The Crust (New release on Steam, July 15)
- Gestalt: Steam & Cinder (New release on Steam, July 16)
- Flintlock: The Siege of Dawn (New release Steam and Xbox, available on PC Game Pass, July 18)
- Dungeons of Hinterberg (New release Steam and Xbox, available on PC Game Pass, July 18)
- Norland (New release on Steam, July 18)
- Cataclismo (New release on Steam, July 22
- CONSCRIPT (New release on Steam, July 23)
- F1 Manager 2024 (New release on Steam, July 23)
- EARTH DEFENSE FORCE 6 (New release on Steam, July 25)
- Stormgate Early Access (New release on Steam, July 30)
- Cyber Knights: Flashpoint (Steam)
- Content Warning (Steam)
- Crime Boss: Rockay City (Steam)
- Gang Beasts (Steam and Xbox, available on PC Game Pass)
- HAWKED (Steam)
- Kingdoms and Castles (Steam)
Jam-Packed June
In addition to the 17 games announced last month, 10 more joined the GeForce NOW library:
- Killer Klowns from Outer Space: The Game (New release on Steam, June 4)
- Sneak Out (New release on Steam, June 6)
- Beyond Good & Evil – 20th Anniversary Edition (New release on Steam and Ubisoft, June 24)
- As Dusk Falls (Steam and Xbox, available on PC Game Pass)
- Bodycam (Steam)
- Drug Dealer Simulator 2 (Steam)
- Sea of Thieves (Steam and Xbox, available on PC Game Pass)
- Skye: The Misty Isle (New release on Steam, June 19)
- XDefiant (Ubisoft)
- Tell Me Why (Steam and Xbox, available on PC Game Pass)
Torque Drift 2 didn’t make it in June due to technical issues. Stay tuned to GFN Thursday for updates.
What are you planning to play this weekend? Let us know on X or in the comments below.
Fill in the blank:
Game that you’ve played for over a year: _____
Multiplayer game you can’t stop playing: _____
Game that makes you rage: _____
—
NVIDIA GeForce NOW (@NVIDIAGFN) July 3, 2024
Interpretable ensemble models improve product retrieval
Gradient-boosted decision trees aggregate model outputs, and Shapley values help identify the most useful models for the ensemble.Read More
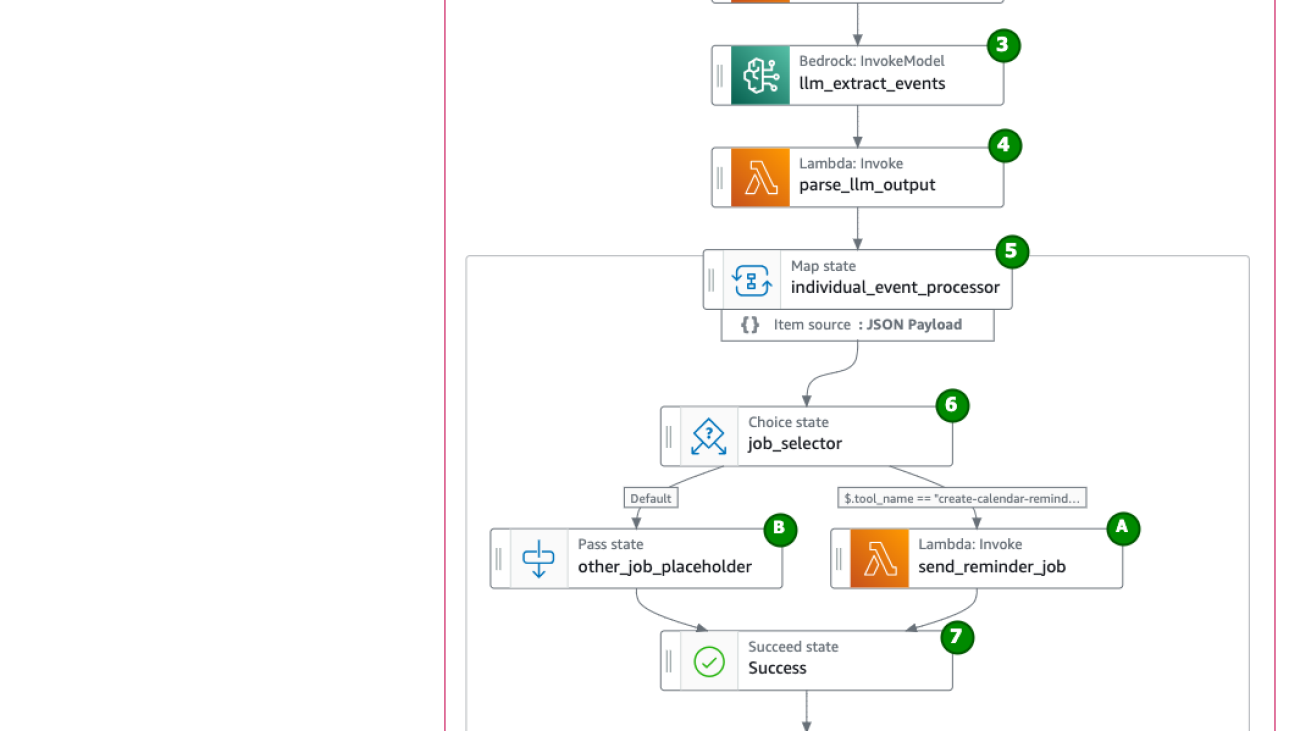
Build your multilingual personal calendar assistant with Amazon Bedrock and AWS Step Functions
Foreigners and expats living outside of their home country deal with a large number of emails in various languages daily. They often find themselves struggling with language barriers when it comes to setting up reminders for events like business gatherings and customer meetings. To solve this problem, this post shows you how to apply AWS services such as Amazon Bedrock, AWS Step Functions, and Amazon Simple Email Service (Amazon SES) to build a fully-automated multilingual calendar artificial intelligence (AI) assistant. It understands the incoming messages, translates them to the preferred language, and automatically sets up calendar reminders.
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that’s best suited for your use case. With Amazon Bedrock, you can get started quickly, privately customize FMs with your own data, and easily integrate and deploy them into your applications using AWS tools without having to manage any infrastructure.
AWS Step Functions is a visual workflow service that helps developers build distributed applications, automate processes, orchestrate microservices, and create data and machine learning (ML) pipelines. It lets you orchestrate multiple steps in the pipeline. The steps could be AWS Lambda functions that generate prompts, parse foundation models’ output, or send email reminders using Amazon SES. Step Functions can interact with over 220 AWS services, including optimized integrations with Amazon Bedrock. Step Functions pipelines can contain loops, map jobs, parallel jobs, conditions, and human interaction, which can be useful for AI-human interaction scenarios.
This post shows you how to quickly combine the flexibility and capability of both Amazon Bedrock FMs and Step Functions to build a generative AI application in a few steps. You can reuse the same design pattern to implement more generative AI applications with low effort. Both Amazon Bedrock and Step Functions are serverless, so you don’t need to think about managing and scaling the infrastructure.
The source code and deployment instructions are available in the Github repository.
Overview of solution

Figure 1: Solution architecture
As shown in Figure 1, the workflow starts from the Amazon API Gateway, then goes through different steps in the Step Functions state machine. Pay attention to how the original message flows through the pipeline and how it changes. First, the message is added to the prompt. Then, it is transformed into structured JSON by the foundation model. Finally, this structured JSON is used to carry out actions.
- The original message (example in Norwegian) is sent to a Step Functions state machine using API Gateway.
- A Lambda function generates a prompt that includes system instructions, the original message, and other needed information such as the current date and time. (Here’s the generated prompt from the example message).
- Sometimes, the original message might not specify the exact date but instead says something like “please RSVP before this Friday,” implying the date based on the current context. Therefore, the function inserts the current date into the prompt to assist the model in interpreting the correct date for this Friday.
- Invoke the Bedrock FM to run the following tasks, as outlined in the prompt, and pass the output to the next step to the parser:
- Translate and summarize the original message in English.
- Extract events information such as subject, location, and time from the original message.
- Generate an action plan list for events. For now, the instruction only asks the FM to generate action plan for sending calendar reminder emails for attending an event.
- Parse the FM output to ensure it has a valid schema. (Here’s the parsed result of the sample message.)
- Anthropic Claude on Amazon Bedrock can control the output format and generate JSON, but it might still produce the result as “this is the json {…}.” To enhance robustness, we implement an output parser to ensure adherence to the schema, thereby strengthening this pipeline.
- Iterate through the action-plan list and perform step 6 for each item. Every action item follows the same schema:
- Choose the right tool to do the job:
- If the
tool_nameequalscreate-calendar-reminder, then run sub-flow A to send out a calendar reminder email using Lambda Function. - For future support of other possible jobs, you can expand the prompt to create a different action plan (assign different values to
tool_name), and run the appropriate action outlined in sub-flow B.
- If the
- Done.
Prerequisites
To run this solution, you must have the following prerequisites:
- An AWS account
- Enable model access to the Anthropic Claude 3 Sonnet model on Amazon Bedrock in the deployment AWS Region by following the steps in Amazon Bedrock access setup.
- Create and verify identities in Amazon SES: If your Amazon SES is in sandbox mode, you must verify the email addresses of the sender and recipient.
Deployment and testing
Thanks to AWS Cloud Development Kit (AWS CDK), you can deploy the full stack with a single command line by following the deployment instructions from the Github repository. The deployment will output the API Gateway endpoint URL and an API key.
Use a tool such as curl to send messages in different languages to API Gateway for testing:
Within 1–2 minutes, email invitations should be sent to the recipient from your sender email address, as shown in Figure 2.

Figure 2: Email generated by the solution
Cleaning up
To avoid incurring future charges, delete the resources by running the following command in the root path of the source code:
$ cdk destroy
Future extension of the solution
In the current implementation, the solution only sends out calendar reminder emails; the prompt only instructs the foundation model to generate action items where tool_name equals create-calendar-reminder. You can extend the solution to support more actions. For example, automatically send an email to the event originator and politely decline it if the event is in July (summer vacation for many):
- Modify the prompt instruction: If the event date is in July, create an action item and set the value of
tool_nametosend-decline-mail. - Similar to the sub-flow A, create a new sub-flow C where
tool_namematchessend-decline-mail:- Invoke the Amazon Bedrock FM to generate email content explaining that you cannot attend the event because it’s in July (summer vacation).
- Invoke a Lambda function to send out the decline email with the generated content.
In addition, you can experiment with different foundation models on Amazon Bedrock, such as Meta Llma 3 or Mistral AI, for better performance or lower cost. You can also explore Agents for Amazon Bedrock, which can orchestrate and run multistep tasks.
Conclusion
In this post, we explored a solution pattern for using generative AI within a workflow. With the flexibility and capabilities offered by both Amazon Bedrock FMs and AWS Step Functions, you can build a powerful generative AI assistant in a few steps. This assistant can streamline processes, enhance productivity, and handle various tasks efficiently. You can easily modify or upgrade its capacity without being burdened by the operational overhead of managed services.
You can find the solution source code in the Github repository and deploy your own multilingual calendar assistant by following the deployment instructions.
Check out the following resources to learn more:
- Visit aws community to discover how our builder communities are using Amazon Bedrock in their solutions.
- Learn more about Generative AI on AWS
- Learn more about Amazon Bedrock
About the Author
 Feng Lu is a Senior Solutions Architect at AWS with 20 years professional experience. He is passionate about helping organizations to craft scalable, flexible, and resilient architectures that address their business challenges. Currently, his focus lies in leveraging Artificial Intelligence (AI) and Internet of Things (IoT) technologies to enhance the intelligence and efficiency of our physical environment.
Feng Lu is a Senior Solutions Architect at AWS with 20 years professional experience. He is passionate about helping organizations to craft scalable, flexible, and resilient architectures that address their business challenges. Currently, his focus lies in leveraging Artificial Intelligence (AI) and Internet of Things (IoT) technologies to enhance the intelligence and efficiency of our physical environment.
Medical content creation in the age of generative AI
Generative AI and transformer-based large language models (LLMs) have been in the top headlines recently. These models demonstrate impressive performance in question answering, text summarization, code, and text generation. Today, LLMs are being used in real settings by companies, including the heavily-regulated healthcare and life sciences industry (HCLS). The use cases can range from medical information extraction and clinical notes summarization to marketing content generation and medical-legal review automation (MLR process). In this post, we explore how LLMs can be used to design marketing content for disease awareness.
Marketing content is a key component in the communication strategy of HCLS companies. It’s also a highly non-trivial balance exercise, because the technical content should be as accurate and precise as possible, yet engaging and empowering for the target audience. The main goal of the marketing content is to raise awareness about certain health conditions and disseminate knowledge of possible therapies among patients and healthcare providers. By accessing up-to-date and accurate information, healthcare providers can adapt their patients’ treatment in a more informed and knowledgeable way. However, medical content being highly sensitive, the generation process can be relatively slow (from days to weeks), and may go through numerous peer-review cycles, with thorough regulatory compliance and evaluation protocols.
Could LLMs, with their advanced text generation capabilities, help streamline this process by assisting brand managers and medical experts in their generation and review process?
To answer this question, the AWS Generative AI Innovation Center recently developed an AI assistant for medical content generation. The system is built upon Amazon Bedrock and leverages LLM capabilities to generate curated medical content for disease awareness. With this AI assistant, we can effectively reduce the overall generation time from weeks to hours, while giving the subject matter experts (SMEs) more control over the generation process. This is accomplished through an automated revision functionality, which allows the user to interact and send instructions and comments directly to the LLM via an interactive feedback loop. This is especially important since the revision of content is usually the main bottleneck in the process.
Since every piece of medical information can profoundly impact the well-being of patients, medical content generation comes with additional requirements and hinges upon the content’s accuracy and precision. For this reason, our system has been augmented with additional guardrails for fact-checking and rules evaluation. The goal of these modules is to assess the factuality of the generated text and its alignment with pre-specified rules and regulations. With these additional features, you have more transparency and control over the underlying generative logic of the LLM.
This post walks you through the implementation details and design choices, focusing primarily on the content generation and revision modules. Fact-checking and rules evaluation require special coverage and will be discussed in an upcoming post.

Image 1: High-level overview of the AI-assistant and its different components
Architecture
The overall architecture and the main steps in the content creation process are illustrated in Image 2. The solution has been designed using the following services:
- Amazon Elastic Container Service (ECS): to deploy and manage our Streamlit UI.
- Amazon Lambda: to run the backend code, which encompasses the generative logic.
- Amazon Textract: for documents parsing, text, and layout extraction.
- Amazon Bedrock: to interact with supported LLMs and embedding models.
- Amazon Translate: for content translation.
- Amazon Simple Storage Service (S3): for documents and processed data caching.

Image 2: Content generation steps
The workflow is as follows:
- In step 1, the user selects a set of medical references and provides rules and additional guidelines on the marketing content in the brief.
- In step 2, the user interacts with the system through a Streamlit UI, first by uploading the documents and then by selecting the target audience and the language.
- In step 3, the frontend sends the HTTPS request via the WebSocket API and API gateway and triggers the first Amazon Lambda function.
- In step 5, the lambda function triggers the Amazon Textract to parse and extract data from pdf documents.
- The extracted data is stored in an S3 bucket and then used as in input to the LLM in the prompts, as shown in steps 6 and 7.
- In step 8, the Lambda function encodes the logic of the content generation, summarization, and content revision.
- Optionally, in step 9, the content generated by the LLM can be translated to other languages using the Amazon Translate.
- Finally, the LLM generates new content conditioned on the input data and the prompt. It sends it back to the WebSocket via the Lambda function.
Preparing the generative pipeline’s input data
To generate accurate medical content, the LLM is provided with a set of curated scientific data related to the disease in question, e.g. medical journals, articles, websites, etc. These articles are chosen by brand managers, medical experts and other SMEs with adequate medical expertise.
The input also consists of a brief, which describes the general requirements and rules the generated content should adhere to (tone, style, target audience, number of words, etc.). In the traditional marketing content generation process, this brief is usually sent to content creation agencies.
It is also possible to integrate more elaborate rules or regulations, such as the HIPAA privacy guidelines for the protection of health information privacy and security. Moreover, these rules can either be general and universally applicable or they can be more specific to certain cases. For example, some regulatory requirements may apply to some markets/regions or a particular disease. Our generative system allows a high degree of personalization so you can easily tailor and specialize the content to new settings, by simply adjusting the input data.
The content should be carefully adapted to the target audience, either patients or healthcare professionals. Indeed, the tone, style, and scientific complexity should be chosen depending on the readers’ familiarity with medical concepts. The content personalization is incredibly important for HCLS companies with a large geographical footprint, as it enables synergies and yields more efficiencies across regional teams.
From a system design perspective, we may need to process a large number of curated articles and scientific journals. This is especially true if the disease in question requires sophisticated medical knowledge or relies on more recent publications. Moreover, medical references contain a variety of information, structured in either plain text or more complex images, with embedded annotations and tables. To scale the system, it is important to seamlessly parse, extract, and store this information. For this purpose, we use Amazon Textract, a machine learning (ML) service for entity recognition and extraction.
Once the input data is processed, it is sent to the LLM as contextual information through API calls. With a context window as large as 200K tokens for Anthropic Claude 3, we can choose to either use the original scientific corpus, hence improving the quality of the generated content (though at the price of increased latency), or summarize the scientific references before using them in the generative pipeline.
Medical reference summarization is an essential step in the overall performance optimization and is achieved by leveraging LLM summarization capabilities. We use prompt engineering to send our summarization instructions to the LLM. Importantly, when performed, summarization should preserve as much article’s metadata as possible, such as the title, authors, date, etc.

Image 3: A simplified version of the summarization prompt
To start the generative pipeline, the user can upload their input data to the UI. This will trigger the Textract and optionally, the summarization Lambda functions, which, upon completion, will write the processed data to an S3 bucket. Any subsequent Lambda function can read its input data directly from S3. By reading data from S3, we avoid throttling issues usually encountered with Websockets when dealing with large payloads.

Image 4: A high-level schematic of the content generation pipeline
Content Generation
Our solution relies primarily on prompt engineering to interact with Bedrock LLMs. All the inputs (articles, briefs and rules) are provided as parameters to the LLM via a LangChain PrompteTemplate object. We can guide the LLM further with few-shot examples illustrating, for instance, the citation styles. Fine-tuning – in particular, Parameter-Efficient Fine-Tuning techniques – can specialize the LLM further to the medical knowledge and will be explored at a later stage.

Image 5: A simplified schematic of the content generation prompt
Our pipeline is multilingual in the sense it can generate content in different languages. Claude 3, for example, has been trained on dozens of different languages besides English and can translate content between them. However, we recognize that in some cases, the complexity of the target language may require a specialized tool, in which case, we may resort to an additional translation step using Amazon Translate.
 Image 6: Animation showing the generation of an article on Ehlers-Danlos syndrome, its causes, symptoms, and complications
Image 6: Animation showing the generation of an article on Ehlers-Danlos syndrome, its causes, symptoms, and complications
Content Revision
Revision is an important capability in our solution because it enables you to further tune the generated content by iteratively prompting the LLM with feedback. Since the solution has been designed primarily as an assistant, these feedback loops allow our tool to seamlessly integrate with existing processes, hence effectively assisting SMEs in the design of accurate medical content. The user can, for instance, enforce a rule that has not been perfectly applied by the LLM in a previous version, or simply improve the clarity and accuracy of some sections. The revision can be applied to the whole text. Alternatively, the user can choose to correct individual paragraphs. In both cases, the revised version and the feedback are appended to a new prompt and sent to the LLM for processing.

Image 7: A simplified version of the content revision prompt
Upon submission of the instructions to the LLM, a Lambda function triggers a new content generation process with the updated prompt. To preserve the overall syntactic coherence, it is preferable to re-generate the whole article, keeping the other paragraphs untouched. However, one can improve the process by re-generating only those sections for which feedback has been provided. In this case, proper attention should be paid to the consistency of the text. This revision process can be applied recursively, by improving upon the previous versions, until the content is deemed satisfactory by the user.

Image 8: Animation showing the revision of the Ehlers-Danlos article. The user can ask, for example, for additional information
Conclusion
With the recent improvements in the quality of LLM-generated text, generative AI has become a transformative technology with the potential to streamline and optimize a wide range of processes and businesses.
Medical content generation for disease awareness is a key illustration of how LLMs can be leveraged to generate curated and high-quality marketing content in hours instead of weeks, hence yielding a substantial operational improvement and enabling more synergies between regional teams. Through its revision feature, our solution can be seamlessly integrated with existing traditional processes, making it a genuine assistant tool empowering medical experts and brand managers.
Marketing content for disease awareness is also a landmark example of a highly regulated use case, where precision and accuracy of the generated content are critically important. To enable SMEs to detect and correct any possible hallucination and erroneous statements, we designed a factuality checking module with the purpose of detecting potential misalignment in the generated text with respect to source references.
Furthermore, our rule evaluation feature can help SMEs with the MLR process by automatically highlighting any inadequate implementation of rules or regulations. With these complementary guardrails, we ensure both scalability and robustness of our generative pipeline, and consequently, the safe and responsible deployment of AI in industrial and real-world settings.
Bibliography
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, & Illia Polosukhin. (2023). Attention Is All You Need.
- Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, & Dario Amodei. (2020). Language Models are Few-Shot Learners.
- Mesko, B., & Topol, E. (2023). The imperative for regulatory oversight of large language models (or generative AI) in healthcare. NPJ digital medicine, 6, 120.
- Clusmann, J., Kolbinger, F.R., Muti, H.S. et al. The future landscape of large language models in medicine. Commun Med 3, 141 (2023). https://doi.org/10.1038/s43856-023-00370-1
- Kai He, Rui Mao, Qika Lin, Yucheng Ruan, Xiang Lan, Mengling Feng, & Erik Cambria. (2023). A Survey of Large Language Models for Healthcare: from Data, Technology, and Applications to Accountability and Ethics.
- Mu W, Muriello M, Clemens JL, Wang Y, Smith CH, Tran PT, Rowe PC, Francomano CA, Kline AD, Bodurtha J. Factors affecting quality of life in children and adolescents with hypermobile Ehlers-Danlos syndrome/hypermobility spectrum disorders. Am J Med Genet A. 2019 Apr;179(4):561-569. doi: 10.1002/ajmg.a.61055. Epub 2019 Jan 31. PMID: 30703284; PMCID: PMC7029373.
- Berglund B, Nordström G, Lützén K. Living a restricted life with Ehlers-Danlos syndrome (EDS). Int J Nurs Stud. 2000 Apr;37(2):111-8. doi: 10.1016/s0020-7489(99)00067-x. PMID: 10684952.
About the authors
 Sarah Boufelja Y. is a Sr. Data Scientist with 8+ years of experience in Data Science and Machine Learning. In her role at the GenAII Center, she worked with key stakeholders to address their Business problems using the tools of machine learning and generative AI. Her expertise lies at the intersection of Machine Learning, Probability Theory and Optimal Transport.
Sarah Boufelja Y. is a Sr. Data Scientist with 8+ years of experience in Data Science and Machine Learning. In her role at the GenAII Center, she worked with key stakeholders to address their Business problems using the tools of machine learning and generative AI. Her expertise lies at the intersection of Machine Learning, Probability Theory and Optimal Transport.
 Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
Liza (Elizaveta) Zinovyeva is an Applied Scientist at AWS Generative AI Innovation Center and is based in Berlin. She helps customers across different industries to integrate Generative AI into their existing applications and workflows. She is passionate about AI/ML, finance and software security topics. In her spare time, she enjoys spending time with her family, sports, learning new technologies, and table quizzes.
 Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he builds and advances generative AI and ML solutions to solve real-world business problems for customers across industries. In his spare time, he loves playing beach volleyball.
Nikita Kozodoi is an Applied Scientist at the AWS Generative AI Innovation Center, where he builds and advances generative AI and ML solutions to solve real-world business problems for customers across industries. In his spare time, he loves playing beach volleyball.
 Marion Eigner is a Generative AI Strategist who has led the launch of multiple Generative AI solutions. With expertise across enterprise transformation and product innovation, she specializes in empowering businesses to rapidly prototype, launch, and scale new products and services leveraging Generative AI.
Marion Eigner is a Generative AI Strategist who has led the launch of multiple Generative AI solutions. With expertise across enterprise transformation and product innovation, she specializes in empowering businesses to rapidly prototype, launch, and scale new products and services leveraging Generative AI.
 Nuno Castro is a Sr. Applied Science Manager at AWS Generative AI Innovation Center. He leads Generative AI customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 17 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 10 years.
Nuno Castro is a Sr. Applied Science Manager at AWS Generative AI Innovation Center. He leads Generative AI customer engagements, helping AWS customers find the most impactful use case from ideation, prototype through to production. He’s has 17 years experience in the field in industries such as finance, manufacturing, and travel, leading ML teams for 10 years.
 Aiham Taleb, PhD, is an Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
Aiham Taleb, PhD, is an Applied Scientist at the Generative AI Innovation Center, working directly with AWS enterprise customers to leverage Gen AI across several high-impact use cases. Aiham has a PhD in unsupervised representation learning, and has industry experience that spans across various machine learning applications, including computer vision, natural language processing, and medical imaging.
Introducing guardrails in Knowledge Bases for Amazon Bedrock
Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you securely connect foundation models (FMs) in Amazon Bedrock to your company data using Retrieval Augmented Generation (RAG). This feature streamlines the entire RAG workflow, from ingestion to retrieval and prompt augmentation, eliminating the need for custom data source integrations and data flow management.
We recently announced the general availability of Guardrails for Amazon Bedrock, which allows you to implement safeguards in your generative artificial intelligence (AI) applications that are customized to your use cases and responsible AI policies. You can create multiple guardrails tailored to various use cases and apply them across multiple FMs, standardizing safety controls across generative AI applications.
Today’s launch of guardrails in Knowledge Bases for Amazon Bedrock brings enhanced safety and compliance to your generative AI RAG applications. This new functionality offers industry-leading safety measures that filter harmful content and protect sensitive information in your documents, improving user experience and aligning with organizational standards.
Solution overview
Knowledge Bases for Amazon Bedrock allows you to configure your RAG applications to query your knowledge base using the RetrieveAndGenerate API, generating responses from the retrieved information.
By default, knowledge bases allow your RAG applications to query the entire vector database, accessing all records and retrieving relevant results. This may lead to the generation of inappropriate or undesirable content or provide sensitive information, which could potentially violate certain policies or guidelines set by your company. Integrating guardrails with your knowledge base provides a mechanism to filter and control the generated output, complying with predefined rules and regulations.
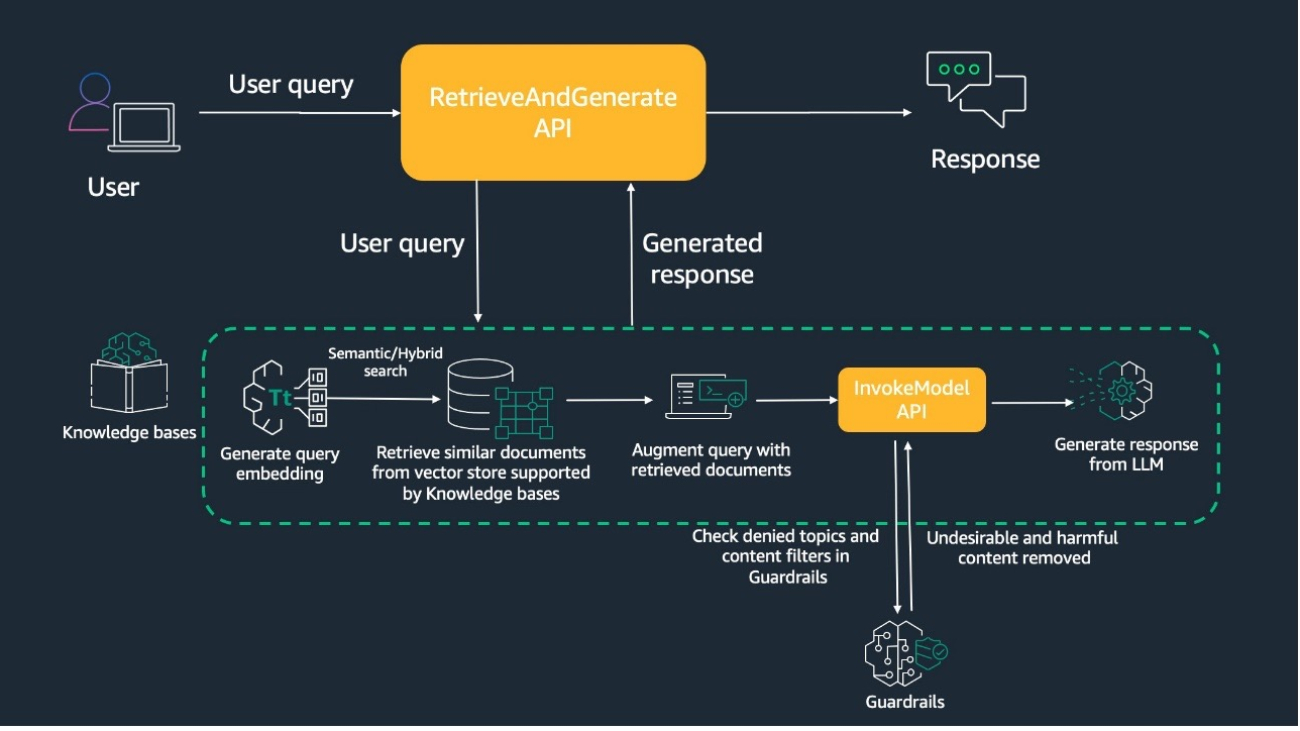
The following diagram illustrates an example workflow.

When you test the knowledge base using the Amazon Bedrock console or call the RetrieveAndGenerate API using one of the AWS SDKs, the system generates a query embedding and performs a semantic search to retrieve similar documents from the vector store.
The query is then augmented to have the retrieved document chunks, prompt, and guardrails configuration. Guardrails are applied to check for denied topics and filter out harmful content before the augmented query is sent to the InvokeModel API. Finally, the InvokeModel API generates a response from the large language model (LLM), making sure the output is free of any undesirable content.
In the following sections, we demonstrate how to create a knowledge base with guardrails. We also compare query results using the same knowledge base with and without guardrails.
Use cases for guardrails with Knowledge Bases for Amazon Bedrock
The following are common use cases for integrating guardrails in the knowledge base:
- Internal knowledge management for a legal firm — This helps legal professionals search through case files, legal precedents, and client communications. Guardrails can prevent the retrieval of confidential client information and filter out inappropriate language. For instance, a lawyer might ask, “What are the key points from the latest case law on intellectual property?” and guardrails will make sure no confidential client details or inappropriate language are included in the response, maintaining the integrity and confidentiality of the information.
- Conversational search for financial services — This enables financial advisors to search through investment portfolios, transaction histories, and market analyses. Guardrails can prevent the retrieval of unauthorized investment advice and filter out content that violates regulatory compliance. An example query could be, “What are the recent performance metrics for our high-net-worth clients?” with guardrails making sure only permissible information is shared.
- Customer support for an ecommerce platform — This allows customer service representatives to access order histories, customer queries, and product details. Guardrails can block sensitive customer data (like names, emails, or addresses) from being exposed in responses. For example, when a representative asks, “Can you summarize the recent complaints about our new product line?” guardrails will redact any personally identifiable information (PII), enforcing privacy and compliance with data protection regulations.
Prepare a dataset for Knowledge Bases for Amazon Bedrock
For this post, we use a sample dataset containing multiple fictional emergency room reports, such as detailed procedural notes, preoperative and postoperative diagnoses, and patient histories. These records illustrate how to integrate knowledge bases with guardrails and query them effectively.
- If you want to follow along in your AWS account, download the file. Each medical record is a Word document.
- We store the dataset in an Amazon Simple Storage Service (Amazon S3) bucket. For instructions to create a bucket, see Creating a bucket.
- Upload the unzipped files to this S3 bucket.
Create a knowledge base for Amazon Bedrock
For instructions to create a new knowledge base, see Create a knowledge base. For this example, we use the following settings:
- On the Configure data source page, under Amazon S3, choose the S3 bucket with your dataset.
- Under Chunking strategy, select No chunking because the documents in the dataset are preprocessed to be within a certain length.
- In the Embeddings model section, choose model Titan G1 Embeddings – Text.
- In the Vector database section, choose Quick create a new vector store.

Synchronize the dataset with the knowledge base
After you create the knowledge base, and your data files are in an S3 bucket, you can start the incremental ingestion. For instructions, see Sync to ingest your data sources into the knowledge base.
While you wait for the sync job to finish, you can move on to the next section, where you create guardrails.
Create a guardrail on the Amazon Bedrock console
Complete the following steps to create a guardrail:
- On the Amazon Bedrock console, choose Guardrails in the navigation pane.
- Choose Create guardrail.
- On the Provide guardrail details page, under Guardrail details, provide a name and optional description for the guardrail.
- In the Denied topics section, add the information for two topics as shown in the following screenshot.
- In the Add sensitive information filters section, under PII types, add all the PII types.
- Choose Create guardrail.

Query the knowledge base on the Amazon Bedrock console
Let’s now test our knowledge base with guardrails:
- On the Amazon Bedrock console, choose Knowledge bases in the navigation pane.
- Choose the knowledge base you created.
- Choose Test knowledge base.
- Choose the Configurations icon, then scroll down to Guardrails.
The following screenshots show some side-by-side comparisons of querying a knowledge base without (left) and with (right) guardrails.
The first example illustrates querying against denied topics.

Next, we query data that contains PII.

Finally, we query about another denied topic.

Query the knowledge base with using the AWS SDK
You can use the following sample code to query the knowledge base with guardrails using the AWS SDK for Python (Boto3):
import boto3
client = boto3.client('bedrock-agent-runtime')
response = client.retrieve_and_generate(
input={
'text': 'Example input text'
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'generationConfiguration': {
'guardrailConfiguration': {
'guardrailId': 'your-guardrail-id',
'guardrailVersion': 'your-guardrail-version'
}
},
'knowledgeBaseId': 'your-knowledge-base-id',
'modelArn': 'your-model-arn'
},
'type': 'KNOWLEDGE_BASE'
},
sessionId='your-session-id'
)Clean up
To clean up your resources, complete the following steps:
- Delete the knowledge base:
- On the Amazon Bedrock console, choose Knowledge bases under Orchestration in the navigation pane.
- Choose the knowledge base you created.
- Take note of the AWS Identity and Access Management (IAM) service role name in the Knowledge base overview
- In the Vector database section, take note of the Amazon OpenSearch Serverless collection ARN.
- Choose Delete, then enter delete to confirm.
- Delete the vector database:
- On the Amazon OpenSearch Service console, choose Collections under Serverless in the navigation pane.
- Enter the collection ARN you saved in the search bar.
- Select the collection and chose Delete.
- Enter confirm in the confirmation prompt, then choose Delete.
- Delete the IAM service role:
- On the IAM console, choose Roles in the navigation pane.
- Search for the role name you noted earlier.
- Select the role and choose Delete.
- Enter the role name in the confirmation prompt and delete the role.
- Delete the sample dataset:
- On the Amazon S3 console, navigate to the S3 bucket you used.
- Select the prefix and files, then choose Delete.
- Enter permanently delete in the confirmation prompt to delete.
Conclusion
In this post, we covered the integration of guardrails with Knowledge Bases for Amazon Bedrock. With this, you can benefit from a robust and customizable safety framework that aligns with your application’s unique requirements and responsible AI practices. This integration aims to enhance the overall security, compliance, and responsible usage of foundation models within the knowledge base ecosystem, providing you with greater control and confidence in your AI-driven applications.
For pricing information, visit Amazon Bedrock Pricing. To get started using Knowledge Bases for Amazon Bedrock, refer to Create a knowledge base. For deep-dive technical content and to learn how our Builder communities are using Amazon Bedrock in their solutions, visit our community.aws website.
About the Authors
 Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
Hardik Vasa is a Senior Solutions Architect at AWS. He focuses on Generative AI and Serverless technologies, helping customers make the best use of AWS services. Hardik shares his knowledge at various conferences and workshops. In his free time, he enjoys learning about new tech, playing video games, and spending time with his family.
 Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers, modernization and currently working on gaining depth in Generative AI. Prior to AWS, Bani worked in various technical roles for a large Telecom provider and worked as a Senior Developer for a multi-national bank.
Bani Sharma is a Sr Solutions Architect with Amazon Web Services (AWS), based out of Denver, Colorado. As a Solutions Architect, she works with a large number of Small and Medium businesses, and provides technical guidance and solutions on AWS. She has an area of depth in Containers, modernization and currently working on gaining depth in Generative AI. Prior to AWS, Bani worked in various technical roles for a large Telecom provider and worked as a Senior Developer for a multi-national bank.

Prompt engineering techniques and best practices: Learn by doing with Anthropic’s Claude 3 on Amazon Bedrock
You have likely already had the opportunity to interact with generative artificial intelligence (AI) tools (such as virtual assistants and chatbot applications) and noticed that you don’t always get the answer you are looking for, and that achieving it may not be straightforward. Large language models (LLMs), the models behind the generative AI revolution, receive instructions on what to do, how to do it, and a set of expectations for their response by means of a natural language text called a prompt. The way prompts are crafted greatly impacts the results generated by the LLM. Poorly written prompts will often lead to hallucinations, sub-optimal results, and overall poor quality of the generated response, whereas good-quality prompts will steer the output of the LLM to the output we want.
In this post, we show how to build efficient prompts for your applications. We use the simplicity of Amazon Bedrock playgrounds and the state-of-the-art Anthropic’s Claude 3 family of models to demonstrate how you can build efficient prompts by applying simple techniques.
Prompt engineering
Prompt engineering is the process of carefully designing the prompts or instructions given to generative AI models to produce the desired outputs. Prompts act as guides that provide context and set expectations for the AI. With well-engineered prompts, developers can take advantage of LLMs to generate high-quality, relevant outputs. For instance, we use the following prompt to generate an image with the Amazon Titan Image Generation model:
An illustration of a person talking to a robot. The person looks visibly confused because he can not instruct the robot to do what he wants.
We get the following generated image.

Let’s look at another example. All the examples in this post are run using Claude 3 Haiku in an Amazon Bedrock playground. Although the prompts can be run using any LLM, we discuss best practices for the Claude 3 family of models. In order to get access to the Claude 3 Haiku LLM on Amazon Bedrock, refer to Model access.
We use the following prompt:
Claude 3 Haiku’s response:
The request prompt is actually very ambiguous. 10 + 10 may have several valid answers; in this case, Claude 3 Haiku, using its internal knowledge, determined that 10 + 10 is 20. Let’s change the prompt to get a different answer for the same question:
Claude 3 Haiku’s response:
The response changed accordingly by specifying that 10 + 10 is an addition. Additionally, although we didn’t request it, the model also provided the result of the operation. Let’s see how, through a very simple prompting technique, we can obtain an even more succinct result:
Claude 3 Haiku response:
Well-designed prompts can improve user experience by making AI responses more coherent, accurate, and useful, thereby making generative AI applications more efficient and effective.
The Claude 3 model family
The Claude 3 family is a set of LLMs developed by Anthropic. These models are built upon the latest advancements in natural language processing (NLP) and machine learning (ML), allowing them to understand and generate human-like text with remarkable fluency and coherence. The family is comprised of three models: Haiku, Sonnet, and Opus.
Haiku is the fastest and most cost-effective model on the market. It is a fast, compact model for near-instant responsiveness. For the vast majority of workloads, Sonnet is two times faster than Claude 2 and Claude 2.1, with higher levels of intelligence, and it strikes the ideal balance between intelligence and speed—qualities especially critical for enterprise use cases. Opus is the most advanced, capable, state-of-the-art foundation model (FM) with deep reasoning, advanced math, and coding abilities, with top-level performance on highly complex tasks.
Among the key features of the model’s family are:
- Vision capabilities – Claude 3 models have been trained to not only understand text but also images, charts, diagrams, and more.
- Best-in-class benchmarks – Claude 3 exceeds existing models on standardized evaluations such as math problems, programming exercises, and scientific reasoning. Specifically, Opus outperforms its peers on most of the common evaluation benchmarks for AI systems, including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), basic mathematics (GSM8K), and more. It exhibits high levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence.
- Reduced hallucination – Claude 3 models mitigate hallucination through constitutional AI techniques that provide transparency into the model’s reasoning, as well as improved accuracy. Claude 3 Opus shows an estimated twofold gain in accuracy over Claude 2.1 on difficult open-ended questions, reducing the likelihood of faulty responses.
- Long context window – Claude 3 models excel at real-world retrieval tasks with a 200,000-token context window, the equivalent of 500 pages of information.
To learn more about the Claude 3 family, see Unlocking Innovation: AWS and Anthropic push the boundaries of generative AI together, Anthropic’s Claude 3 Sonnet foundation model is now available in Amazon Bedrock, and Anthropic’s Claude 3 Haiku model is now available on Amazon Bedrock.
The anatomy of a prompt
As prompts become more complex, it’s important to identify its various parts. In this section, we present the components that make up a prompt and the recommended order in which they should appear:
- Task context: Assign the LLM a role or persona and broadly define the task it is expected to perform.
- Tone context: Set a tone for the conversation in this section.
- Background data (documents and images): Also known as context. Use this section to provide all the necessary information for the LLM to complete its task.
- Detailed task description and rules: Provide detailed rules about the LLM’s interaction with its users.
- Examples: Provide examples of the task resolution for the LLM to learn from them.
- Conversation history: Provide any past interactions between the user and the LLM, if any.
- Immediate task description or request: Describe the specific task to fulfill within the LLMs assigned roles and tasks.
- Think step-by-step: If necessary, ask the LLM to take some time to think or think step by step.
- Output formatting: Provide any details about the format of the output.
- Prefilled response: If necessary, prefill the LLMs response to make it more succinct.
The following is an example of a prompt that incorporates all the aforementioned elements:
Best prompting practices with Claude 3
In the following sections, we dive deep into Claude 3 best practices for prompt engineering.
Text-only prompts
For prompts that deal only with text, follow this set of best practices to achieve better results:
- Mark parts of the prompt with XLM tags – Claude has been fine-tuned to pay special attention to XML tags. You can take advantage of this characteristic to clearly separate sections of the prompt (instructions, context, examples, and so on). You can use any names you prefer for these tags; the main idea is to delineate in a clear way the content of your prompt. Make sure you include <> and </> for the tags.
- Always provide good task descriptions – Claude responds well to clear, direct, and detailed instructions. When you give an instruction that can be interpreted in different ways, make sure that you explain to Claude what exactly you mean.
- Help Claude learn by example – One way to enhance Claude’s performance is by providing examples. Examples serve as demonstrations that allow Claude to learn patterns and generalize appropriate behaviors, much like how humans learn by observation and imitation. Well-crafted examples significantly improve accuracy by clarifying exactly what is expected, increase consistency by providing a template to follow, and boost performance on complex or nuanced tasks. To maximize effectiveness, examples should be relevant, diverse, clear, and provided in sufficient quantity (start with three to five examples and experiment based on your use case).
- Keep the responses aligned to your desired format – To get Claude to produce output in the format you want, give clear directions, telling it exactly what format to use (like JSON, XML, or markdown).
- Prefill Claude’s response – Claude tends to be chatty in its answers, and might add some extra sentences at the beginning of the answer despite being instructed in the prompt to respond with a specific format. To improve this behavior, you can use the assistant message to provide the beginning of the output.
- Always define a persona to set the tone of the response – The responses given by Claude can vary greatly depending on which persona is provided as context for the model. Setting a persona helps Claude set the proper tone and vocabulary that will be used to provide a response to the user. The persona guides how the model will communicate and respond, making the conversation more realistic and tuned to a particular personality. This is especially important when using Claude as the AI behind a chat interface.
- Give Claude time to think – As recommended by Anthropic’s research team, giving Claude time to think through its response before producing the final answer leads to better performance. The simplest way to encourage this is to include the phrase “Think step by step” in your prompt. You can also capture Claude’s step-by-step thought process by instructing it to “please think about it step-by-step within <thinking></thinking> tags.”
- Break a complex task into subtasks – When dealing with complex tasks, it’s a good idea to break them down and use prompt chaining with LLMs like Claude. Prompt chaining involves using the output from one prompt as the input for the next, guiding Claude through a series of smaller, more manageable tasks. This improves accuracy and consistency for each step, makes troubleshooting less complicated, and makes sure Claude can fully focus on one subtask at a time. To implement prompt chaining, identify the distinct steps or subtasks in your complex process, create separate prompts for each, and feed the output of one prompt into the next.
- Take advantage of the long context window – Working with long documents and large amounts of text can be challenging, but Claude’s extended context window of over 200,000 tokens enables it to handle complex tasks that require processing extensive information. This feature is particularly useful with Claude Haiku because it can help provide high-quality responses with a cost-effective model. To take full advantage of this capability, it’s important to structure your prompts effectively.
- Allow Claude to say “I don’t know” – By explicitly giving Claude permission to acknowledge when it’s unsure or lacks sufficient information, it’s less likely to generate inaccurate responses. This can be achieved by adding a preface to the prompt, such as, “If you are unsure or don’t have enough information to provide a confident answer, simply say ‘I don’t know’ or ‘I’m not sure.’”
Prompts with images
The Claude 3 family offers vision capabilities that can process images and return text outputs. It’s capable of analyzing and understanding charts, graphs, technical diagrams, reports, and other visual assets. The following are best practices when working with images with Claude 3:
- Image placement and size matters – For optimal performance, when working with Claude 3’s vision capabilities, the ideal placement for images is at the very start of the prompt. Anthropic also recommends resizing an image before uploading and striking a balance between image clarity and image size. For more information, refer to Anthropic’s guidance on image sizing.
- Apply traditional techniques – When working with images, you can apply the same techniques used for text-only prompts (such as giving Claude time to think or defining a role) to help Claude improve its responses.
Consider the following example, which is an extraction of the picture “a fine gathering” (Author: Ian Kirck, https://en.m.wikipedia.org/wiki/File:A_fine_gathering_(8591897243).jpg).

We ask Claude 3 to count how many birds are in the image:
Claude 3 Haiku’s response:
In this example, we asked Claude to take some time to think and put its
reasoning in an XML tag and the final answer in another. Also, we gave Claude time to think and clear instructions to pay attention to details, which helped Claude to provide the correct response.
- Take advantage of visual prompts – The ability to use images also enables you to add prompts directly within the image itself instead of providing a separate prompt.
Let’s see an example with the following image:

In this case, the image itself is the prompt:
Claude 3 Haiku’s response:
- Examples are also valid using images – You can provide multiple images in the same prompt and take advantage of Claude’s vision capabilities to provide examples and additional valuable information using the images. Make sure you use image tags to clearly identify the different images. Because this question is a reasoning and mathematical question, set the temperature to 0 for a more deterministic response.
Let’s look at the following example:
Prompt:
<image1>
</image1>
<image2>
</image2>
Claude 3 Haiku’s response:
- Use detailed descriptions when working with complicated charts or graphics – Working with charts or graphics is a relatively straightforward task when using Claude’s models. We simply take advantage of Claude’s vision capabilities, pass the charts or graphics in image format, and then ask questions about the provided images. However, when working with complicated charts that have lots of colors (which look very similar) or a lot of data points, it’s a good practice to help Claude better understand the information with the following methods:
- Ask Claude to describe in detail each data point that it sees in the image.
- Ask Claude to first identify the HEX codes of the colors in the graphics to clearly see the difference in colors.
Let’s see an example. We pass to Claude the following map chart in image format (source: https://ourworldindata.org/co2-and-greenhouse-gas-emissions), then we ask about Japan’s greenhouse gas emissions.
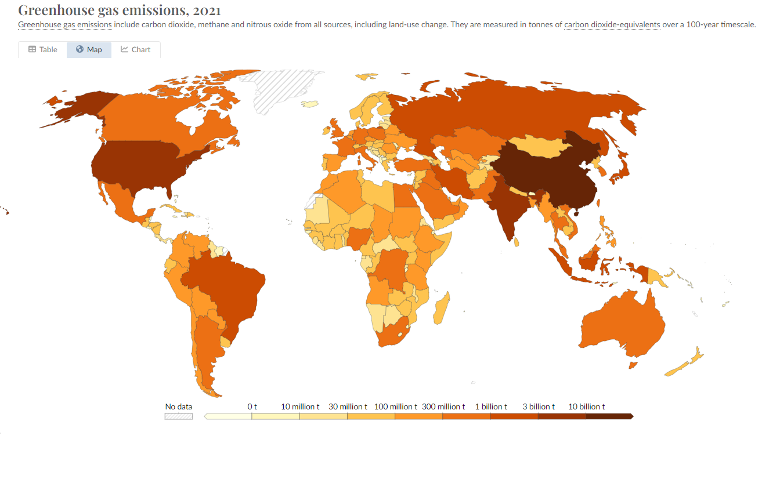
Prompt:
Claude 3 Haiku’s response:






Decoding How the Generative AI Revolution BeGAN
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and showcases new hardware, software, tools and accelerations for RTX PC users.
Generative models have completely transformed the AI landscape — headlined by popular apps such as ChatGPT and Stable Diffusion.
Paving the way for this boom were foundational AI models and generative adversarial networks (GANs), which sparked a leap in productivity and creativity.
NVIDIA’s GauGAN, which powers the NVIDIA Canvas app, is one such model that uses AI to transform rough sketches into photorealistic artwork.
How It All BeGAN
GANs are deep learning models that involve two complementary neural networks: a generator and a discriminator.
These neural networks compete against each other. The generator attempts to create realistic, lifelike imagery, while the discriminator tries to tell the difference between what’s real and what’s generated. As its neural networks keep challenging each other, GANs get better and better at making realistic-looking samples.
GANs excel at understanding complex data patterns and creating high-quality results. They’re used in applications including image synthesis, style transfer, data augmentation and image-to-image translation.
NVIDIA’s GauGAN, named after post-Impressionist painter Paul Gauguin, is an AI demo for photorealistic image generation. Built by NVIDIA Research, it directly led to the development of the NVIDIA Canvas app — and can be experienced for free through the NVIDIA AI Playground.
GauGAN has been wildly popular since it debuted at NVIDIA GTC in 2019 — used by art teachers, creative agencies, museums and millions more online.
Giving Sketch to Scenery a Gogh
Powered by GauGAN and local NVIDIA RTX GPUs, NVIDIA Canvas uses AI to turn simple brushstrokes into realistic landscapes, displaying results in real time.
Users can start by sketching simple lines and shapes with a palette of real-world elements like grass or clouds —- referred to in the app as “materials.”
The AI model then generates the enhanced image on the other half of the screen in real time. For example, a few triangular shapes sketched using the “mountain” material will appear as a stunning, photorealistic range. Or users can select the “cloud” material and with a few mouse clicks transform environments from sunny to overcast.
The creative possibilities are endless — sketch a pond, and other elements in the image, like trees and rocks, will reflect in the water. Change the material from snow to grass, and the scene shifts from a cozy winter setting to a tropical paradise.
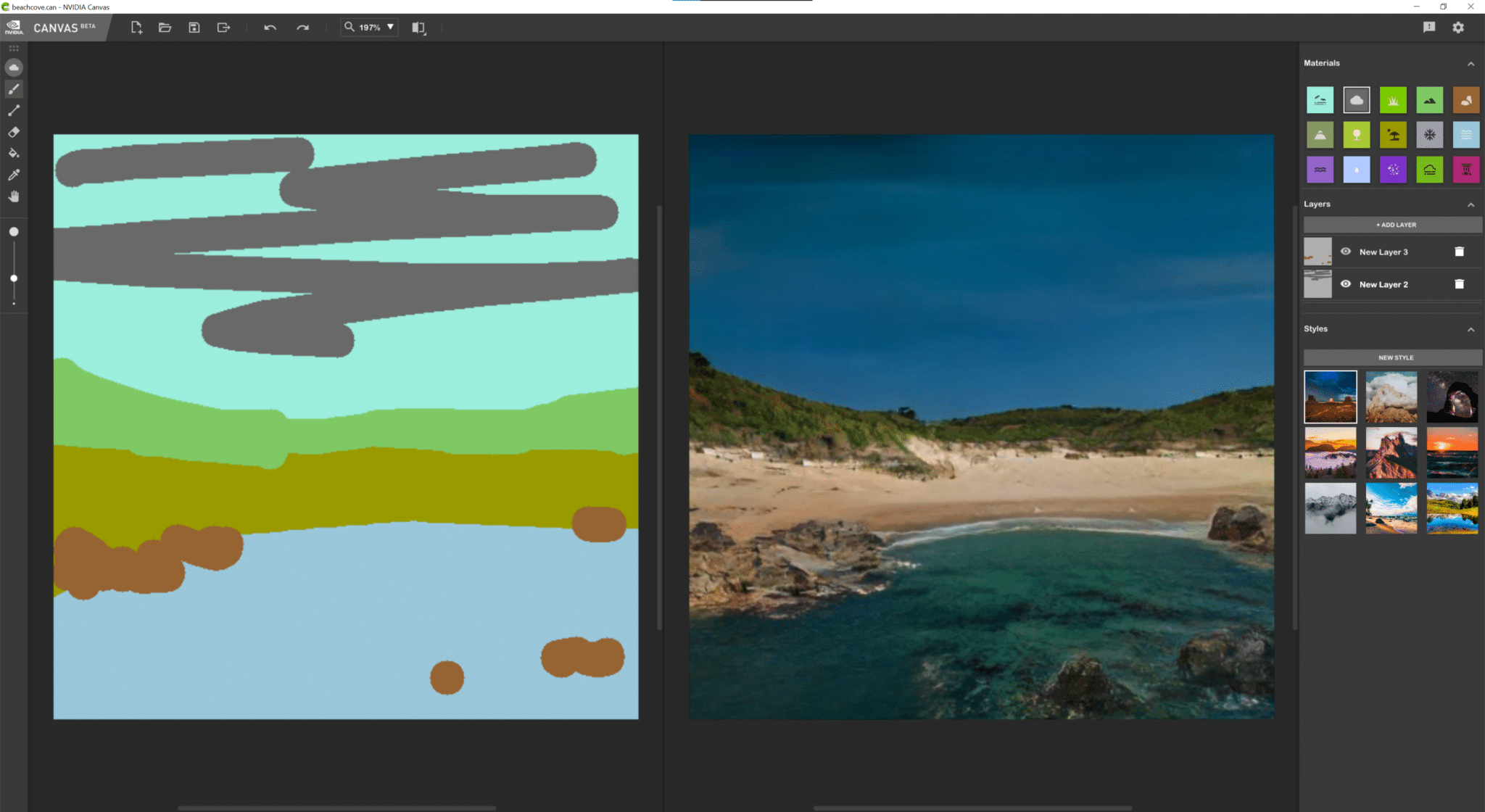
Canvas features a Panorama mode that enables artists to create 360-degree images for use in 3D apps. YouTuber Greenskull AI demonstrated Panorama mode by painting an ocean cove, before then importing it into Unreal Engine 5.
Download the NVIDIA Canvas app to get started.
Consider exploring NVIDIA Broadcast, another AI-powered content creation app that transforms any room into a home studio. Broadcast is free for RTX GPU owners.
Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.