In November 2023, we announced Knowledge Bases for Amazon Bedrock as generally available.
Knowledge bases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the language model’s generation process. This feature allows organizations to harness the power of large language models (LLMs) while making sure that the generated responses are tailored to their specific domain knowledge, regulations, and business requirements. By incorporating their unique data sources, such as internal documentation, product catalogs, or transcribed media, organizations can enhance the relevance, accuracy, and contextual awareness of the language model’s outputs.
Knowledge bases effectively bridge the gap between the broad knowledge encapsulated within foundation models and the specialized, domain-specific information that businesses possess, enabling a truly customized and valuable generative artificial intelligence (AI) experience.
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. For example, if your data contains documents from different products, departments, or time periods, you can use metadata filtering to limit retrieval to only the most relevant subset of data for a given query or conversation. This helps improve the relevance and quality of retrieved context while reducing potential hallucinations or noise from irrelevant data. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
In this post, we discuss how to implement metadata filtering within Knowledge Bases for Amazon Bedrock by implementing access control and ensuring data privacy and security in RAG applications.
Access control with metadata filters
Metadata filtering in knowledge bases enables access control for your data. By defining metadata fields based on attributes such as user roles, departments, or data sensitivity levels, you can ensure that the retrieval only fetches and uses information that a particular user or application is authorized to access. This helps maintain data privacy and security, preventing sensitive or restricted information from being inadvertently surfaced or used in generated responses. With this access control capability, you can safely use retrieval across different user groups or scenarios while complying with company specific data governance policies and regulations.
During retrieval of contextually relevant chunks, metadata filters add an additional layer of selection to those vectors that are returned to the LLM for response generation. In addition, metadata filtering requires fewer computation resources, thereby improving the overall performance and reducing costs associated with the search.
Let’s explore some practical applications of metadata filtering in Knowledge Bases for Amazon Bedrock. Here are a few examples and use cases across different domains:
- A company uses a chatbot to help HR personnel navigate employee files. There is sensitive information present in the documents and only certain employees should be able to have access and converse with them. With metadata filters on access IDs, a user can only chat with documents that have metadata associated with their access ID. The access ID associated with their authentication when the chat is initiated can be passed as a filter.
- A business-to-business (B2B) platform is developed for companies to allow their end-users to access all their uploaded documents, search over them conversationally, and complete various tasks using those documents. To ensure that end-users can only chat with their data, metadata filters on user access tokens—such as those obtained through an authentication service—can enable secure access to their information. This provides customers with peace of mind while maintaining compliance with various data security standards.
- A work organization application has a conversational search feature. Documents, kanbans, meeting recording transcripts, and other assets can be searched more intently and with more granular control. The app uses a single sign-on (SSO) functionality that allows them to access company-wide resources and other services and follows a company’s data level access protocol. With metadata filters on work groups and a privilege level (for example Limited, Standard, or Admin) derived from their SSO authentication, you can enforce data security while personalizing the chat experience to streamline a user’s work and collaboration with others.
Access control with metadata filtering in the healthcare domain
To demonstrate the access-control capabilities enabled by metadata filtering in knowledge bases, let’s consider a use case where a healthcare provider has a knowledge base that contains transcripts of conversations between doctors and patients. In this scenario, it is crucial that each doctor can only access transcripts from their own patient interactions during the search, and not have access to transcripts from other doctors’ patient interactions.
By defining a metadata field for patient_id and associating each transcript with the corresponding patient’s identifier, the healthcare provider can implement access control within their search application. When a doctor initiates a conversation, the knowledge base can filter the vector store to retrieve context only from transcripts where the patient_id metadata matches either a specific patient ID or the list of patient IDs associated with the authenticated doctor. This way, the generated responses will be augmented solely with information from that doctor’s past patient interactions, maintaining patient privacy and confidentiality.
This access control approach can be extended to other relevant metadata fields, such as year or department, further refining the subset of data accessible to each user or application. By using metadata filtering in knowledge bases, the healthcare provider can achieve compliance with data governance policies and regulations while enabling doctors to have personalized, contextually relevant conversations tailored to their specific patient histories and needs.
Solution overview
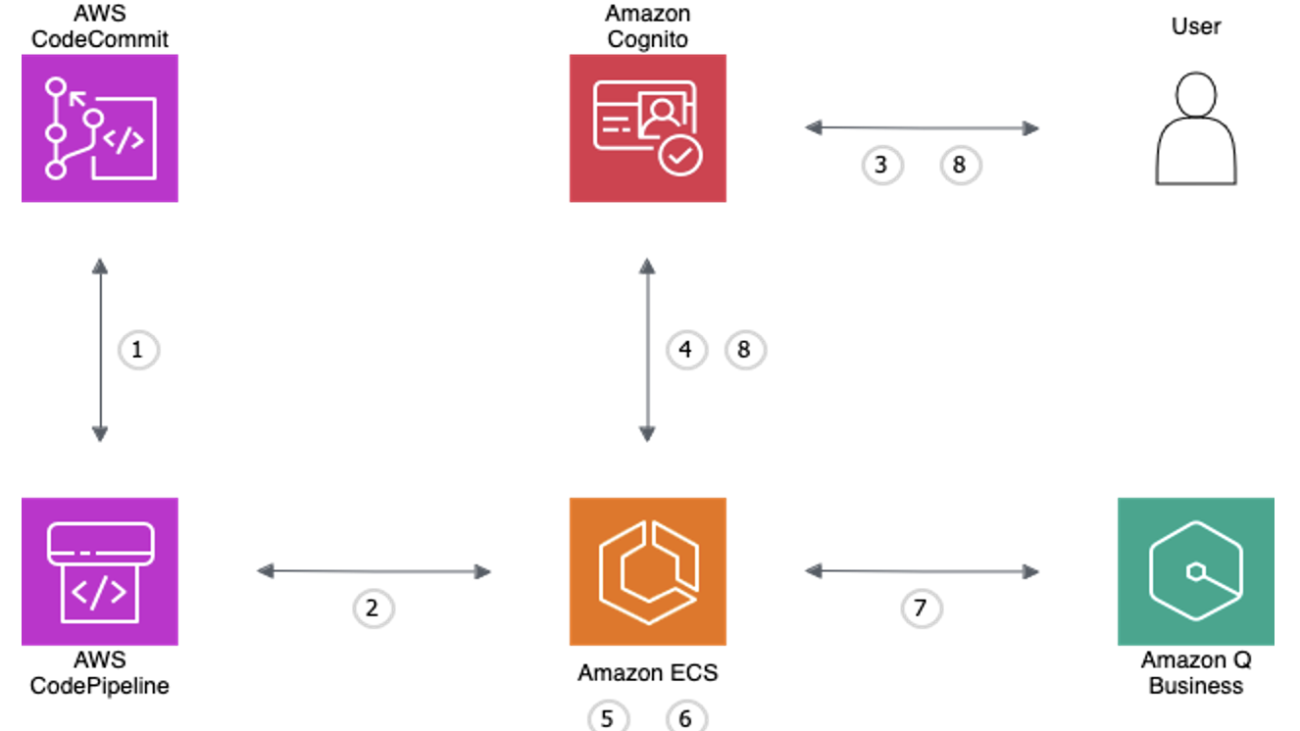
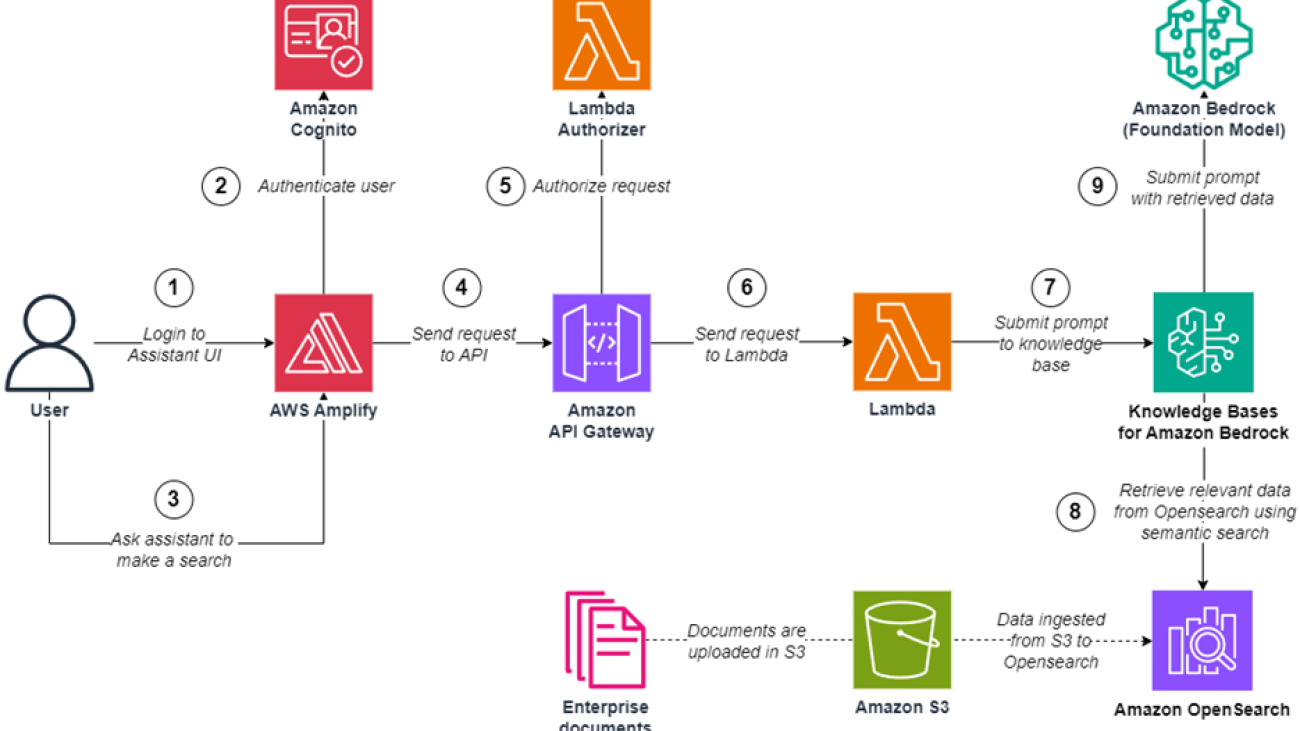
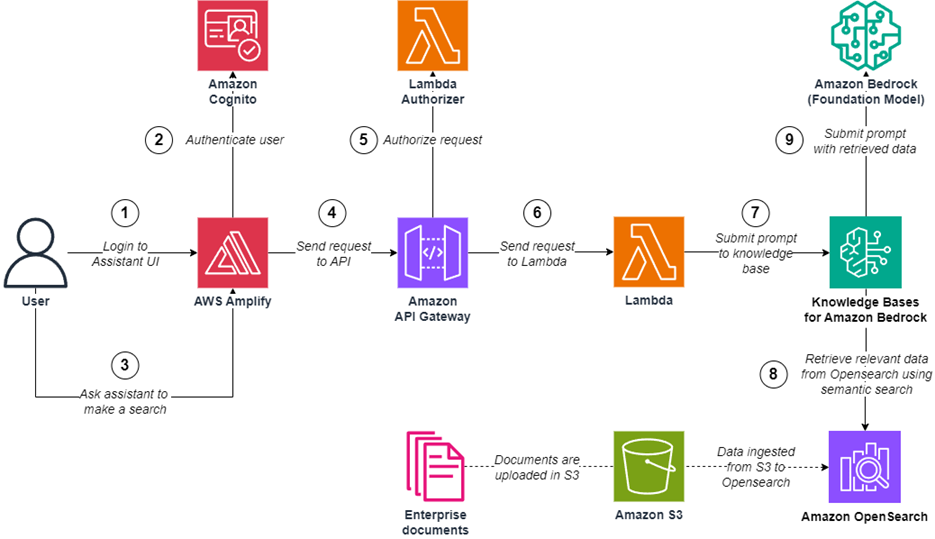
Let’s walk through the high-level steps to implement access control with Knowledge Bases for Amazon Bedrock. The following GitHub repository provides a guided notebook that you can follow to deploy this example in your own account.
The following diagram illustrates the solution architecture.

Figure 1: Solution architecture
The workflow for the solution is as follows:
- The doctor interacts with the Streamlit frontend, which serves as the application interface. Amazon Cognito handles user authentication and access control, ensuring only authorized doctors can access the application. For production use, it is recommended to use a more robust frontend framework such as AWS Amplify, which provides a comprehensive set of tools and services for building scalable and secure web applications.
- After the doctor has successfully signed in, the application retrieves the list of patients associated with the doctor’s ID from the Amazon DynamoDB database. The doctor is then presented with this list of patients, from which they can select one or more patients to filter their search.
- When the doctor interacts with the Streamlit frontend, it sends a request to an AWS Lambda function, which acts as the application backend. The request includes the doctor’s ID, a list of patient IDs to filter by, and the text query.
- Before querying the knowledge base, the Lambda function retrieves data from the DynamoDB database, which stores doctor-patient associations. This step validates that the doctor is authorized to access the requested patient or list of patient’s information.
- If the validation is successful, the Lambda function queries the knowledge base using the provided patient or list of patient’s IDs. The knowledge base is pre-populated with transcript and metadata files stored in Amazon Simple Storage Service (Amazon S3).
- The knowledge base returns the relevant results, which are then sent back to the Streamlit application and displayed to the doctor.
User authentication with Amazon Cognito
To implement the access control solution for the healthcare provider use case, you can use Amazon Cognito user pools to manage the authentication and user identities of the doctors.
To start, you will create an Amazon Cognito user pool that will store the doctor user accounts. During the user pool setup, you define the necessary attributes for each doctor, including their name and a unique identifier (sub or custom attribute). For patients, their identifier will be used as the patient_id metadata field. This unique identifier will be associated with each patient’s account and used for metadata filtering in the knowledge base retrieval process.

Figure 2: User information
Doctor and patient association in DynamoDB
To facilitate the access control mechanism based on the doctor-patient relationship, the healthcare provider can create a DynamoDB table to store these associations. This table will act as a centralized repository, allowing efficient retrieval of the patient IDs associated with each authenticated doctor during the knowledge base search process. When a doctor authenticates through Amazon Cognito, their unique identifier can be used to query the doctor_patient_list_associations table and retrieve the list of patient_id values associated with that doctor.

Figure 3: Items retrieved based on the doctor_ID and patient relationships
This approach offers flexibility in managing doctor-patient associations. If a doctor changes over time, only the corresponding entries in the DynamoDB table need to be updated. This update does not require modifying the metadata files of the transcripts themselves.
Now that you have your doctor and patients set up with their relationships defined, let’s examine the dataset format required for effective metadata filtering.
Dataset format
When working with Knowledge Bases for Amazon Bedrock, the dataset format plays a crucial role in providing seamless integration and effective metadata filtering. This example uses a series of PDF files containing transcripts of doctor-patient conversations.
These files need to be uploaded to an S3 bucket for processing. To use metadata filtering, you need to create a separate metadata JSON file for each transcript file. The metadata file should share the same name as the corresponding PDF file (including the extension). For instance, if the transcript file is named transcript_001.pdf, the metadata file should be named transcript_001.pdf.metadata.json. This nomenclature is crucial for the knowledge base to identify the metadata for specific files during the ingestion process.
The metadata JSON file will contain key-value pairs representing the relevant metadata fields associated with the transcript. In the healthcare provider use case, the most important metadata field is patient_id, which will be used to implement access control. You assign each transcript to a specific patient by including their unique identifier from the Amazon Cognito user pool in the patient_id field of the metadata file, as in the following example:
{"metadataAttributes": {"patient_id": 669}}
By structuring the dataset with transcript PDF files accompanied by their corresponding metadata JSON files, you can effectively use the metadata filtering capabilities of Knowledge Bases for Amazon Bedrock. This approach enables you to implement access control, so each doctor can only retrieve and use content from their own patient transcripts during the retrieval process. For customers processing thousands of files, automating the generation of the metadata files using Lambda functions or a similar solution could be a more efficient approach to scale.
Knowledge base creation
With the dataset properly structured and organized, you can now create the knowledge base in Amazon Bedrock. The process is straightforward, thanks to the user-friendly interface and step-by-step guidance provided by the AWS Management Console. See Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock for instructions to create a new knowledge base, upload your dataset, and configure the necessary settings to achieve optimal performance. Alternatively, you can create a knowledge base using the AWS SDK, API, or AWS CloudFormation template, which provides programmatic and automated ways to set up and manage your knowledge bases.

Figure 4: Using the console to create a knowledge base
After you create the knowledge base and sync it with your dataset, you can immediately experience the power of metadata filtering.
In the test pane, navigate to the settings section and locate the filters option. Here, you can define specific filter conditions by specifying the patient_id field along with the unique IDs or list of identifiers of the patients you wish to test. By applying this filter, the retrieval process will fetch and incorporate only the relevant context from transcripts associated with the specified patient or patients. This filter-based retrieval approach means that the generated responses are tailored to the doctor’s individual patient interactions, maintaining data privacy and confidentiality.

Figure 5:Knowledge Bases console test configuration Panel

Figure 6: Knowledge Bases console test panel
Querying the knowledge base programmatically
You have seen how to implement access control with metadata filtering through the console, but what if you want to integrate knowledge bases directly into your applications? AWS provides SDKs that allow you to programmatically interact with Amazon Bedrock features, including knowledge bases.
The following code snippet demonstrates how to call the retrieve_and_generate API using the Boto3 library in Python. It includes metadata filtering capabilities within the vectorSearchConfiguration, where you can now add filter conditions. For this specific use case, you first need to retrieve the list of patient_ids associated with a doctor from the DynamoDB table. This allows you to filter the search results based on the authenticated user’s identity.
import boto3
import json
bedrock_agent = boto3.client('bedrock-agent-runtime')
# Retrieve and generate API
response = bedrock_agent.retrieve_and_generate(
input={
"text": "Who is Kelly?"
},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
'knowledgeBaseId': <<KnowledgeBase id>>,
"modelArn": "arn:aws:bedrock:us-west-2::foundation-model/anthropic.claude-v2:1",
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"numberOfResults":5,
"filter": {
"in": {
"key": "patient_id",
"value": <<patient_ids>> # Amazon Cognito Id once the doctor is authenticated.
}
}
}
}
}
}
)
print(response['output']['text'],end='n'*2)
You can create a Lambda function that serves as the backend for the application. This Lambda function uses the Boto3 library to interact with Amazon Bedrock, specifically to retrieve relevant information from the knowledge base using the retrieve_and_generate API.
Now that the architectural components are in place, you can create a visual interface to display the results.
Streamlit sample app
To showcase the interaction between doctors and the knowledge base, we developed a user-friendly web application using Streamlit, a popular open source Python library for building interactive data apps. Streamlit provides a simple and intuitive way to create custom interfaces that can seamlessly integrate with the various AWS services involved in this solution.
The Streamlit application acts as the frontend for doctors to initiate conversations and interact with the knowledge base. It uses Amazon Cognito for user authentication, so only authorized doctors can access the application and the corresponding patient data. Upon successful authentication, the application interacts with Lambda to handle the RAG workflow using the Amazon Cognito user ID.
Figure 7: Demo
Clean up
It’s important to clean up and delete the resources created during this solution deployment to avoid unnecessary costs. In the provided GitHub repository, you’ll find a section at the end of the notebook dedicated to deleting all the resources created as part of this solution to ensure that you don’t incur any ongoing charges for resources that are no longer needed.
Conclusion
This post has demonstrated the powerful capabilities of metadata filtering within Knowledge Bases for Amazon Bedrock by implementing access control and ensuring data privacy and security in RAG applications. By using metadata fields, organizations can precisely control the subset of data accessible to different users or applications during the RAG process while also improving the relevancy and performance of the search.
Get started with Knowledge Bases for Amazon Bedrock, and let us know your thoughts in the comments section.
About the Authors
 Dani Mitchell is an Generative AI Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
Dani Mitchell is an Generative AI Specialist Solutions Architect at Amazon Web Services. He is focused on computer vision use cases and helping customers across EMEA accelerate their ML journey.
 Chris Pecora is a Generative AI Data Scientist at Amazon Web Services. He is passionate about building innovative products and solutions while also focused on customer-obsessed science. When not running experiments and keeping up with the latest developments in generative AI, he loves spending time with his kids.
Chris Pecora is a Generative AI Data Scientist at Amazon Web Services. He is passionate about building innovative products and solutions while also focused on customer-obsessed science. When not running experiments and keeping up with the latest developments in generative AI, he loves spending time with his kids.
 Kshitiz Agarwal is an Engineering Leader at Amazon Web Services (AWS), where he leads the development of Knowledge Bases for Amazon Bedrock. With a decade of experience at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing landscape. His passion lies in engaging with customers and understanding the innovative ways they leverage AWS to drive their business success. Through his work, Kshitiz aims to contribute to the continuous improvement of AWS services, enabling customers to unlock the full potential of the cloud.
Kshitiz Agarwal is an Engineering Leader at Amazon Web Services (AWS), where he leads the development of Knowledge Bases for Amazon Bedrock. With a decade of experience at Amazon, having joined in 2012, Kshitiz has gained deep insights into the cloud computing landscape. His passion lies in engaging with customers and understanding the innovative ways they leverage AWS to drive their business success. Through his work, Kshitiz aims to contribute to the continuous improvement of AWS services, enabling customers to unlock the full potential of the cloud.
Read More











 Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance.
Sonali Sahu is leading the Generative AI Specialist Solutions Architecture team in AWS. She is an author, thought leader, and passionate technologist. Her core area of focus is AI and ML, and she frequently speaks at AI and ML conferences and meetups around the world. She has both breadth and depth of experience in technology and the technology industry, with industry expertise in healthcare, the financial sector, and insurance. Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative AI solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing.
Chinmayee Rane is a Generative AI Specialist Solutions Architect at AWS. She is passionate about applied mathematics and machine learning. She focuses on designing intelligent document processing and generative AI solutions for AWS customers. Outside of work, she enjoys salsa and bachata dancing. Himesh Kumar is a seasoned Senior Software Engineer, currently working at Amazon Q Business in AWS. He is passionate about building distributed systems in the generative AI/ML space. His expertise extends to develop scalable and efficient systems, ensuring high availability, performance, and reliability. Beyond the technical skills, he is dedicated to continuous learning and staying at the forefront of technological advancements in AI and machine learning.
Himesh Kumar is a seasoned Senior Software Engineer, currently working at Amazon Q Business in AWS. He is passionate about building distributed systems in the generative AI/ML space. His expertise extends to develop scalable and efficient systems, ensuring high availability, performance, and reliability. Beyond the technical skills, he is dedicated to continuous learning and staying at the forefront of technological advancements in AI and machine learning. Qing Wei is a Senior Software Developer for Amazon Q Business team in AWS, and passionate about building modern applications using AWS technologies. He loves community-driven learning and sharing of technology especially for machine learning hosting and inference related topics. His main focus right now is on building serverless and event-driven architectures for RAG data ingestion.
Qing Wei is a Senior Software Developer for Amazon Q Business team in AWS, and passionate about building modern applications using AWS technologies. He loves community-driven learning and sharing of technology especially for machine learning hosting and inference related topics. His main focus right now is on building serverless and event-driven architectures for RAG data ingestion.


 Sunita Nadampalli is a Software Development Manager and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.
Sunita Nadampalli is a Software Development Manager and AI/ML expert at AWS. She leads AWS Graviton software performance optimizations for AI/ML and HPC workloads. She is passionate about open source software development and delivering high-performance and sustainable software solutions for SoCs based on the Arm ISA.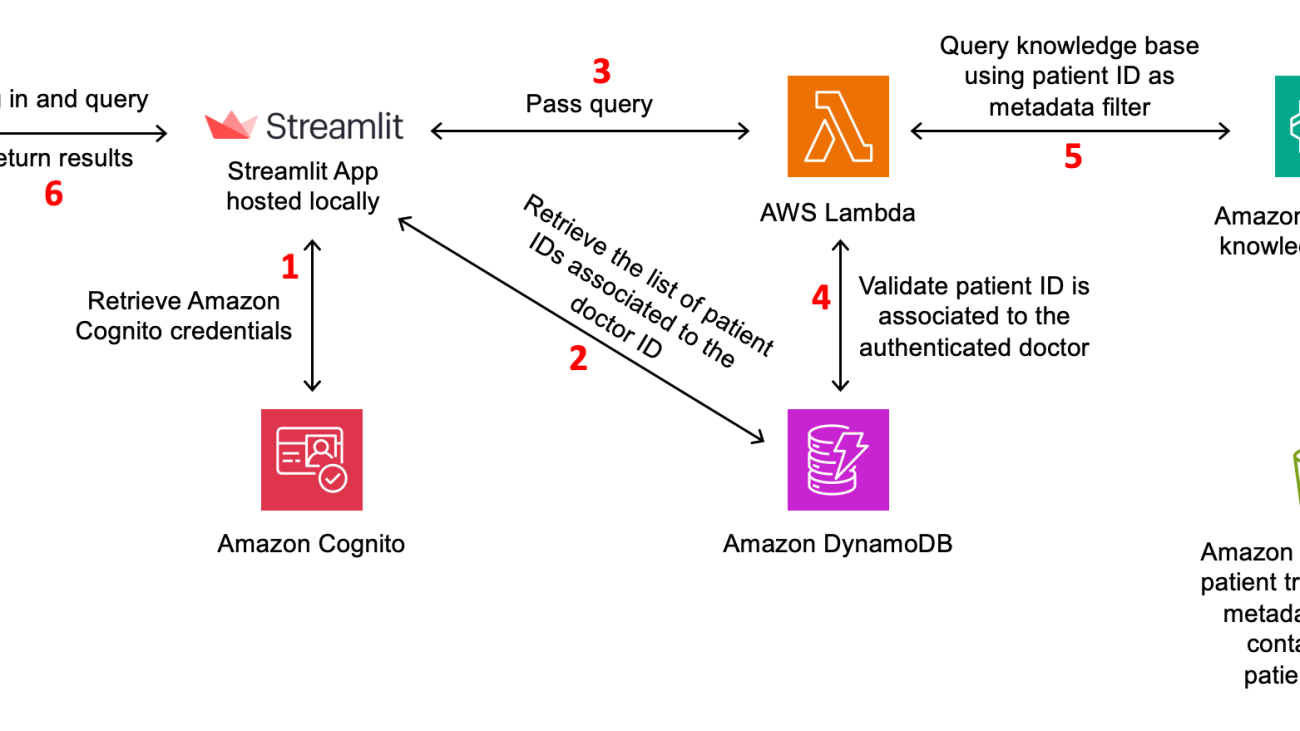





 Dominik Juran works as a full stack developer at Accenture with a focus on AWS technologies and AI. He also has a passion for ice hockey.
Dominik Juran works as a full stack developer at Accenture with a focus on AWS technologies and AI. He also has a passion for ice hockey. Milica Bozic works as Cloud Engineer at Accenture, specializing in AWS Cloud solutions for the specific needs of clients with background in telecommunications, particularly 4G and 5G technologies. Mili is passionate about art, books, and movement training, finding inspiration in creative expression and physical activity.
Milica Bozic works as Cloud Engineer at Accenture, specializing in AWS Cloud solutions for the specific needs of clients with background in telecommunications, particularly 4G and 5G technologies. Mili is passionate about art, books, and movement training, finding inspiration in creative expression and physical activity. Zdenko Estok works as a cloud architect and DevOps engineer at Accenture. He works with AABG to develop and implement innovative cloud solutions, and specializes in infrastructure as code and cloud security. Zdenko likes to bike to the office and enjoys pleasant walks in nature.
Zdenko Estok works as a cloud architect and DevOps engineer at Accenture. He works with AABG to develop and implement innovative cloud solutions, and specializes in infrastructure as code and cloud security. Zdenko likes to bike to the office and enjoys pleasant walks in nature. Selimcan “Can” Sakar is a cloud first developer and solution architect at Accenture with a focus on artificial intelligence and a passion for watching models converge.
Selimcan “Can” Sakar is a cloud first developer and solution architect at Accenture with a focus on artificial intelligence and a passion for watching models converge.






 Mehdi Amrane is a Senior Solutions Architect at Amazon Web Services. He supports customers on their initiatives and provides them prescriptive guidance to achieve their goals, and accelerate their cloud journey. He is passionate about creating content on application architecture, DevOps and Serverless technologies.
Mehdi Amrane is a Senior Solutions Architect at Amazon Web Services. He supports customers on their initiatives and provides them prescriptive guidance to achieve their goals, and accelerate their cloud journey. He is passionate about creating content on application architecture, DevOps and Serverless technologies.
 Our 2024 Environmental Report looks at our use of technology to drive environmental change and operate our business sustainably.
Our 2024 Environmental Report looks at our use of technology to drive environmental change and operate our business sustainably.




 This will populate the S3 URI, as shown in the following screenshot.
This will populate the S3 URI, as shown in the following screenshot.












 You should see a Successfully built message when the build is complete.
You should see a Successfully built message when the build is complete.



 Supriya Puragundla is a Senior Solutions Architect at AWS. She has over 15 years of IT experience in software development, design and architecture. She helps key customer accounts on their data, generative AI and AI/ML journeys. She is passionate about data-driven AI and the area of depth in ML and generative AI.
Supriya Puragundla is a Senior Solutions Architect at AWS. She has over 15 years of IT experience in software development, design and architecture. She helps key customer accounts on their data, generative AI and AI/ML journeys. She is passionate about data-driven AI and the area of depth in ML and generative AI. Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing cloud-centered big data workloads. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom.
Manjula Nagineni is a Senior Solutions Architect with AWS based in New York. She works with major financial service institutions, architecting and modernizing their large-scale applications while adopting AWS Cloud services. She is passionate about designing cloud-centered big data workloads. She has over 20 years of IT experience in software development, analytics, and architecture across multiple domains such as finance, retail, and telecom. Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.