Amazon SageMaker is a machine learning (ML) platform designed to simplify the process of building, training, deploying, and managing ML models at scale. With a comprehensive suite of tools and services, SageMaker offers developers and data scientists the resources they need to accelerate the development and deployment of ML solutions.
In today’s fast-paced technological landscape, efficiency and agility are essential for businesses and developers striving to innovate. AWS plays a critical role in enabling this innovation by providing a range of services that abstract away the complexities of infrastructure management. By handling tasks such as provisioning, scaling, and managing resources, AWS allows developers to focus more on their core business logic and iterate quickly on new ideas.
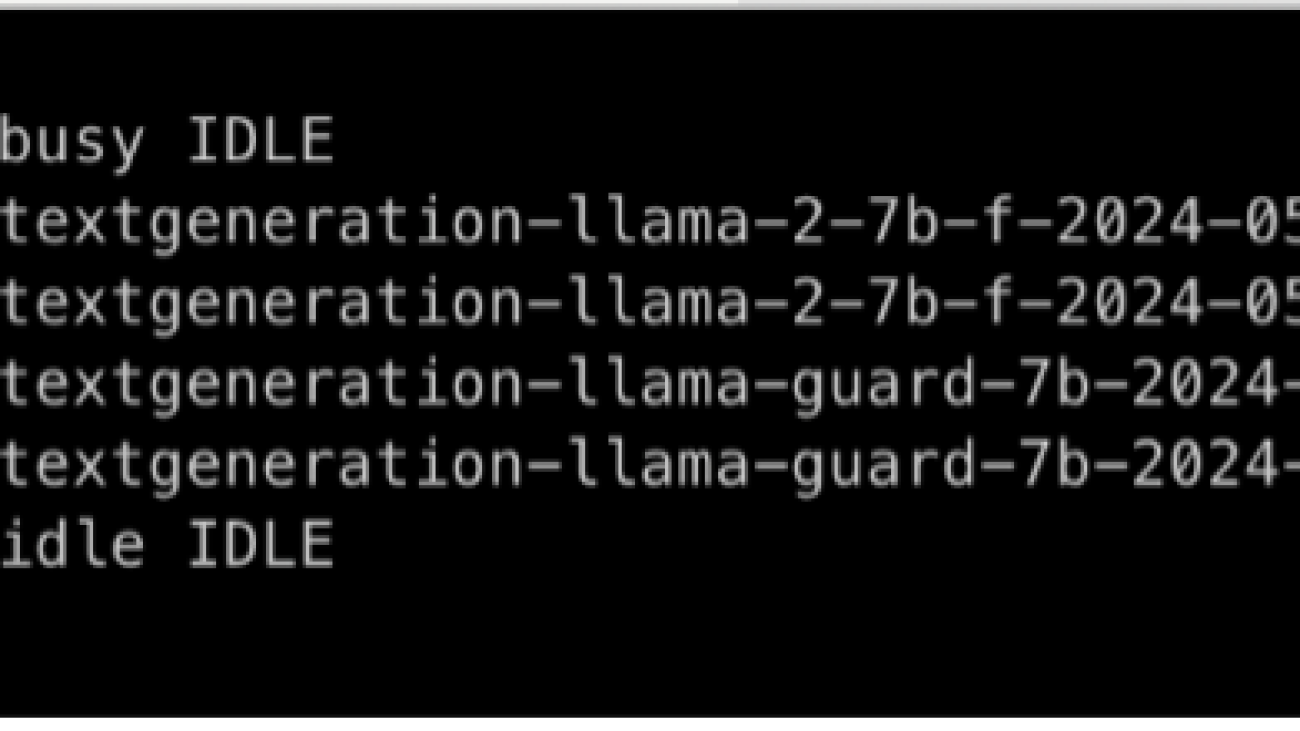
As developers deploy and scale applications, unused resources such as idle SageMaker endpoints can accumulate unnoticed, leading to higher operational costs. This post addresses the issue of identifying and managing idle endpoints in SageMaker. We explore methods to monitor SageMaker endpoints effectively and distinguish between active and idle ones. Additionally, we walk through a Python script that automates the identification of idle endpoints using Amazon CloudWatch metrics.
Identify idle endpoints with a Python script
To effectively manage SageMaker endpoints and optimize resource utilization, we use a Python script that uses the AWS SDK for Python (Boto3) to interact with SageMaker and CloudWatch. This script automates the process of querying CloudWatch metrics to determine endpoint activity and identifies idle endpoints based on the number of invocations over a specified time period.
Let’s break down the key components of the Python script and explain how each part contributes to the identification of idle endpoints:
- Global variables and AWS client initialization – The script begins by importing necessary modules and initializing global variables such as
NAMESPACE,METRIC,LOOKBACK, andPERIOD. These variables define parameters for querying CloudWatch metrics and SageMaker endpoints. Additionally, AWS clients for interacting with SageMaker and CloudWatch services are initialized using Boto3.
from datetime import datetime, timedelta
import boto3
import logging
# AWS clients initialization
cloudwatch = boto3.client("cloudwatch")
sagemaker = boto3.client("sagemaker")
# Global variables
NAMESPACE = "AWS/SageMaker"
METRIC = "Invocations"
LOOKBACK = 1 # Number of days to look back for activity
PERIOD = 86400 # We opt for a granularity of 1 Day to reduce the volume of metrics retrieved while maintaining accuracy.
# Calculate time range for querying CloudWatch metrics
ago = datetime.utcnow() - timedelta(days=LOOKBACK)
now = datetime.utcnow()
- Identify idle endpoints – Based on the CloudWatch metrics data, the script determines whether an endpoint is idle or active. If an endpoint has received no invocations over the defined period, it’s flagged as idle. In this case, we select a cautious default threshold of zero invocations over the analyzed period. However, depending on your specific use case, you can adjust this threshold to suit your requirements.
# Helper function to extract endpoint name from CloudWatch metric
def get_endpoint_name_from_metric(metric):
for d in metric["Dimensions"]:
if d["Name"] == "EndpointName" or d["Name"] == "InferenceComponentName" :
yield d["Value"]
# Helper Function to aggregate individual metrics for a designated endpoint and output the total. This validation helps in determining if the endpoint has been idle during the specified period.
def list_metrics():
paginator = cloudwatch.get_paginator("list_metrics")
response_iterator = paginator.paginate(Namespace=NAMESPACE, MetricName=METRIC)
return [m for r in response_iterator for m in r["Metrics"]]
# Helper function to check if endpoint is in use based on CloudWatch metrics
def is_endpoint_busy(metric):
metric_values = cloudwatch.get_metric_data(
MetricDataQueries=[{
"Id": "metricname",
"MetricStat": {
"Metric": {
"Namespace": metric["Namespace"],
"MetricName": metric["MetricName"],
"Dimensions": metric["Dimensions"],
},
"Period": PERIOD,
"Stat": "Sum",
"Unit": "None",
},
}],
StartTime=ago,
EndTime=now,
ScanBy="TimestampAscending",
MaxDatapoints=24 * (LOOKBACK + 1),
)
return sum(metric_values.get("MetricDataResults", [{}])[0].get("Values", [])) > 0
# Helper function to log endpoint activity
def log_endpoint_activity(endpoint_name, is_busy):
status = "BUSY" if is_busy else "IDLE"
log_message = f"{datetime.utcnow()} - Endpoint {endpoint_name} {status}"
print(log_message)
- Main function – The
main()function serves as the entry point to run the script. It orchestrates the process of retrieving SageMaker endpoints, querying CloudWatch metrics, and logging endpoint activity.
# Main function to identify idle endpoints and log their activity status
def main():
endpoints = sagemaker.list_endpoints()["Endpoints"]
if not endpoints:
print("No endpoints found")
return
existing_endpoints_name = []
for endpoint in endpoints:
existing_endpoints_name.append(endpoint["EndpointName"])
for metric in list_metrics():
for endpoint_name in get_endpoint_name_from_metric(metric):
if endpoint_name in existing_endpoints_name:
is_busy = is_endpoint_busy(metric)
log_endpoint_activity(endpoint_name, is_busy)
else:
print(f"Endpoint {endpoint_name} not active")
if __name__ == "__main__":
main()
By following along with the explanation of the script, you’ll gain a deeper understanding of how to automate the identification of idle endpoints in SageMaker, paving the way for more efficient resource management and cost optimization.
Permissions required to run the script
Before you run the provided Python script to identify idle endpoints in SageMaker, make sure your AWS Identity and Access Management (IAM) user or role has the necessary permissions. The permissions required for the script include:
- CloudWatch permissions – The IAM entity running the script must have permissions for the CloudWatch actions
cloudwatch:GetMetricDataandcloudwatch:ListMetrics - SageMaker permissions – The IAM entity must have permissions to list SageMaker endpoints using the
sagemaker:ListEndpointsaction
Run the Python script
You can run the Python script using various methods, including:
- The AWS CLI – Make sure the AWS Command Line Interface (AWS CLI) is installed and configured with the appropriate credentials.
- AWS Cloud9 – If you prefer a cloud-based integrated development environment (IDE), AWS Cloud9 provides an IDE with preconfigured settings for AWS development. Simply create a new environment, clone the script repository, and run the script within the Cloud9 environment.
In this post, we demonstrate running the Python script through the AWS CLI.

Actions to take after identifying idle endpoints
After you’ve successfully identified idle endpoints in your SageMaker environment using the Python script, you can take proactive steps to optimize resource utilization and reduce operational costs. The following are some actionable measures you can implement:
- Delete or scale down endpoints – For endpoints that consistently show no activity over an extended period, consider deleting or scaling them down to minimize resource wastage. SageMaker allows you to delete idle endpoints through the AWS Management Console or programmatically using the AWS SDK.
- Review and refine the model deployment strategy – Evaluate the deployment strategy for your ML models and assess whether all deployed endpoints are necessary. Sometimes, endpoints may become idle due to changes in business requirements or model updates. By reviewing your deployment strategy, you can identify opportunities to consolidate or optimize endpoints for better efficiency.
- Implement auto scaling policies – Configure auto scaling policies for active endpoints to dynamically adjust the compute capacity based on workload demand. SageMaker supports auto scaling, allowing you to automatically increase or decrease the number of instances serving predictions based on predefined metrics such as CPU utilization or inference latency.
- Explore serverless inference options – Consider using SageMaker serverless inference as an alternative to traditional endpoint provisioning. Serverless inference eliminates the need for manual endpoint management by automatically scaling compute resources based on incoming prediction requests. This can significantly reduce idle capacity and optimize costs for intermittent or unpredictable workloads.
Conclusion
In this post, we discussed the importance of identifying idle endpoints in SageMaker and provided a Python script to help automate this process. By implementing proactive monitoring solutions and optimizing resource utilization, SageMaker users can effectively manage their endpoints, reduce operational costs, and maximize the efficiency of their machine learning workflows.
Get started with the techniques demonstrated in this post to automate cost monitoring for SageMaker inference. Explore AWS re:Post for valuable resources on optimizing your cloud infrastructure and maximizing AWS services.
Resources
For more information about the features and services used in this post, refer to the following:
- Inference cost optimization best practices
- Optimizing costs for machine learning with Amazon SageMaker
- Serverless Inference
- Use Amazon CloudWatch metrics
About the authors
 Pablo Colazurdo is a Principal Solutions Architect at AWS where he enjoys helping customers to launch successful projects in the Cloud. He has many years of experience working on varied technologies and is passionate about learning new things. Pablo grew up in Argentina but now enjoys the rain in Ireland while listening to music, reading or playing D&D with his kids.
Pablo Colazurdo is a Principal Solutions Architect at AWS where he enjoys helping customers to launch successful projects in the Cloud. He has many years of experience working on varied technologies and is passionate about learning new things. Pablo grew up in Argentina but now enjoys the rain in Ireland while listening to music, reading or playing D&D with his kids.
 Ozgur Canibeyaz is a Senior Technical Account Manager at AWS with 8 years of experience. Ozgur helps customers optimize their AWS usage by navigating technical challenges, exploring cost-saving opportunities, achieving operational excellence, and building innovative services using AWS products.
Ozgur Canibeyaz is a Senior Technical Account Manager at AWS with 8 years of experience. Ozgur helps customers optimize their AWS usage by navigating technical challenges, exploring cost-saving opportunities, achieving operational excellence, and building innovative services using AWS products.

 Despite the rising popularity and capabilities of LLMs, the language most often used to converse with the LLM, often through a chat-like interface, is English. And although progress has been made in adapting open source models to comprehend and respond in
Despite the rising popularity and capabilities of LLMs, the language most often used to converse with the LLM, often through a chat-like interface, is English. And although progress has been made in adapting open source models to comprehend and respond in 