New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More

New research analyzes the misuse of multimodal generative AI today, in order to help build safer and more responsible technologies.Read More
The rapid evolution of Large Language Models (LLMs) and conversational assistants necessitates dynamic, scalable, and configurable conversational datasets for training and evaluation. These datasets must accommodate diverse user interaction modes, including text and voice, each presenting unique modeling challenges. Knowledge Graphs (KGs), with their structured and evolving nature, offer an ideal foundation for current and precise knowledge. Although human-curated KG-based conversational datasets exist, they struggle to keep pace with the rapidly changing user information needs. We present…Apple Machine Learning Research
Underwriting is a fundamental function within the insurance industry, serving as the foundation for risk assessment and management. Underwriters are responsible for evaluating insurance applications, determining the level of risk associated with each applicant, and making decisions on whether to accept or reject the application based on the insurer’s guidelines and risk appetite.
In this post, we discuss how to use AWS generative artificial intelligence (AI) solutions like Amazon Bedrock to improve the underwriting process, including rule validation, underwriting guidelines adherence, and decision justification. We’ve also provided an accompanying GitHub repo so you can try the solution.
The underwriting process typically involves several key steps:
Effective underwriting is crucial for the financial stability and profitability of insurance companies. By accurately assessing risk and setting appropriate premiums, underwriters help insurers maintain a balanced risk portfolio and avoid adverse selection of potential policy holders.
Document understanding is a critical and complex aspect of the underwriting process that poses significant challenges for insurers. Underwriters must review and analyze a wide range of documents submitted by applicants, and the manual extraction of relevant information is a time-consuming and error-prone task. The challenges in document understanding can be broadly categorized into three areas:
The impact of these challenges on the underwriting process is significant. Manual data extraction and analysis can slow down the workflow, leading to longer processing times and lower customer retention. Errors in data interpretation or inconsistencies in applying guidelines can result in incorrect risk assessments, premium leakage, and lost customers for the insurer.
To address these challenges, insurers are increasingly turning to advanced technologies such as machine learning, natural language processing, and intelligent document processing solutions.
However, implementing these technologies has been challenging for carriers. Building rules and pipelines for each document or insurance product may require dedicated teams, subject matter expertise in new technologies, and security and compliance controls. Additionally, traditional approaches lack contextual understanding that come with underwriting, causing fragility in existing solutions. In the next section, we explore how generative AI and Amazon Bedrock can help insurers overcome these challenges and streamline the underwriting process through intelligent document understanding and automation.
One of the key advantages of generative AI is its ability to understand and interpret context within documents. Unlike traditional rule-based systems that rely on strict pattern matching, generative AI models can grasp the nuances and semantics of language, allowing them to extract meaningful insights even from complex and varied document formats. This contextual understanding is particularly valuable in underwriting, where the interpretation of information often requires domain-specific knowledge and reasoning.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock simplifies the deployment, scaling, implementation, and management of generative AI models for insurers. With Amazon Bedrock, insurers can easily integrate pre-trained models or custom-built models into their existing underwriting workflows and systems, without the need for extensive ML expertise or infrastructure management. Using the power of AI to automate tedious and time-consuming tasks enables underwriters to focus on their core competencies.
To equip FMs with up-to-date and proprietary information, such as underwriting manuals, you can use Retrieval Augmented Generation (RAG), a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. Knowledge Bases for Amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows.
In this solution, we use the knowledge base capability offered by Amazon Bedrock to enhance the reasoning and decision-making process of the generative AI models. Knowledge Bases for Amazon Bedrock allows us to ingest and incorporate relevant underwriting guidelines and manuals into the models’ knowledge base. Knowledge Bases for Amazon Bedrock simplifies the integration process by eliminating the need for custom integrations with data sources and the management of complex data flows. It streamlines the ingestion and retrieval of underwriting manuals, so models have access to the most current and relevant information. We can fetch specific information from the ingested underwriting manuals and enrich the prompts provided to the models. This makes sure the models have access to the most up-to-date and relevant information, enabling them to provide more accurate and context-aware responses. Knowledge Bases for Amazon Bedrock provides a crucial advantage by allowing insurers to infuse their proprietary domain knowledge and underwriting policies into the generative AI models. This empowers the models to make decisions that are fully aligned with the insurer’s risk management strategies, guidelines, and regulatory requirements.
Generative AI and Amazon Bedrock can address specific challenges in document understanding for underwriting:
By adopting generative AI and Amazon Bedrock, insurers can enhance underwriting efficiency, reduce processing times, minimize errors, adhere to fairness and regulatory compliance, and improve transparency and customer satisfaction. In this post, we show a simple use case of validating documents against a set of underwriting guidelines, and in future posts, we will show more complex scenarios across a large corpus of documents, and more advanced underwriting rules.
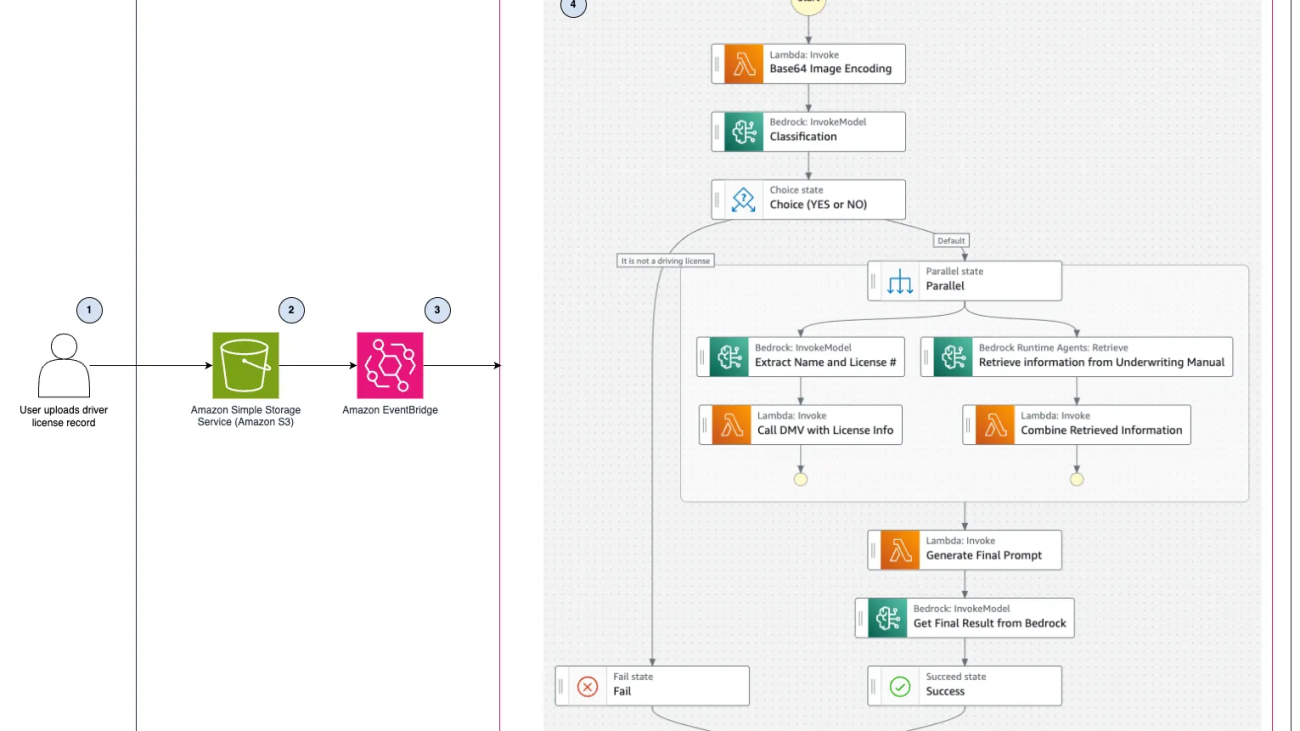
The following diagram illustrates the automated process for verifying driver’s license records and validating underwriting rules using various AWS services.

The solution includes the following steps:
By combining these AWS services and taking advantage of the capabilities of the Anthropic Claude 3 Haiku model, this solution offers a streamlined and intelligent approach to processing driver’s license records for underwriting rules validation purposes. It automates various tasks, reduces manual effort, and enhances the accuracy and efficiency of the underwriting process.
You need to have the following to run the solution:
You can download all the necessary code with instructions from the GitHub repo. Follow the instructions in the GitHub repo README to deploy the solution.
To test the solution, upload a sample driver’s license to the underwriting document bucket.
To find the URL of the underwriting document bucket, follow these steps:

To upload the sample driver’s license to the underwriting document bucket, follow these steps:

To review the workflow of the Step Functions state machine, follow these steps:



After you try out the solution, follow the cleanup instructions in the GitHub repo README to avoid accruing charges.
This solution is composed of four primary services: Amazon Bedrock, Amazon S3, EventBridge, and Step Functions. We discuss On-Demand Amazon Bedrock pricing in this post. For the other services, review the service’s pricing page.
With On-Demand mode, you pay only for what you use, with no time-based term commitments. For Anthropic Claude 3 models, you’re charged for every input token processed and every output token generated.
As shown in the following graph, pricing varies for each Anthropic models: Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus.

Claude 3 Haiku is Anthropic’s fastest, most compact model for near-instant responsiveness. Claude 3 Sonnet strikes the ideal balance between intelligence and speed—particularly for enterprise workloads. This solution uses the sophisticated vision capabilities of Haiku to process photos of drivers’ licenses and uses Sonnet to perform RAG-powered rule validation of a driver’s license record against an underwriting manual document.
In this post, we explored the critical and complex challenges of document understanding within the underwriting process for insurers. Manually extracting relevant information from applicant documents, validating adherence to underwriting guidelines, and providing clear justifications for decisions is time-consuming and error-prone, and can lead to inconsistencies. Generative AI and Amazon Bedrock offer a powerful solution to help overcome these obstacles. We discussed how the reasoning and contextual understanding capabilities of generative AI models allow them to accurately interpret complex documents and extract meaningful insights aligned with an insurer’s specific domain knowledge (such as property and casualty, healthcare, and so on) and corresponding guidelines. We provided a reference architecture that uses Amazon Bedrock FMs and RAG capabilities using Knowledge Bases for Amazon Bedrock, along with orchestration services such as Step Functions, that allow insurers to improve automation in key underwriting tasks like rules validation.
Additionally, you learned about how you can use AWS generative AI solutions to extract relevant information, compare it against defined rules, and flag any non-compliance issues automatically. You can use this innovative approach to improve underwriting efficiency, reduce processing times, minimize human error, achieve fairness and regulatory compliance, and improve transparency with applicants. We showed how insurers can adopt generative AI and Amazon Bedrock to modernize their underwriting processes through intelligent document understanding and automation, gaining a competitive edge through mitigating risks more effectively.
Lastly, we offered a working solution with code you can deploy within your sandbox environment to accelerate the development of your own intelligent document understanding solution using AWS generative AI.
 Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with generative AI on AWS. Outside of work, Paul enjoys spending time with his wife and golfing.
Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with generative AI on AWS. Outside of work, Paul enjoys spending time with his wife and golfing.
 Alfredo Castillo is a Sr. Solutions Architect at AWS, where he works with Financial Services customers on all aspects of internet-scale distributed systems, and specializes in Machine learning, Natural Language Processing, Intelligent Document Processing, and GenAI. Alfredo has a background in both electrical engineering and computer science. He is passionate about family, technology, and endurance sports.
Alfredo Castillo is a Sr. Solutions Architect at AWS, where he works with Financial Services customers on all aspects of internet-scale distributed systems, and specializes in Machine learning, Natural Language Processing, Intelligent Document Processing, and GenAI. Alfredo has a background in both electrical engineering and computer science. He is passionate about family, technology, and endurance sports.
 Max Tybar is a Solutions Architect at AWS with a background in computer science and application development. He enjoys leveraging DevOps practices to architect and build reliable cloud infrastructure that helps solve customer problems. His personal interests lie around leveraging Machine Learning and High-Performance Computing to help solve complex problems faced by Financial Service customers in Banking, Capital Markets and Life Insurance.
Max Tybar is a Solutions Architect at AWS with a background in computer science and application development. He enjoys leveraging DevOps practices to architect and build reliable cloud infrastructure that helps solve customer problems. His personal interests lie around leveraging Machine Learning and High-Performance Computing to help solve complex problems faced by Financial Service customers in Banking, Capital Markets and Life Insurance.
 Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative AI, Natural Language Processing, Intelligent Document Processing, and MLOps.
Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative AI, Natural Language Processing, Intelligent Document Processing, and MLOps.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. Amazon Bedrock also provides a broad set of capabilities needed to build generative AI applications with security, privacy, and responsible AI practices.
Some FMs are publicly available, which allows for customization tailored to specific use cases and domains. However, deploying customized FMs to support generative AI applications in a secure and scalable manner isn’t a trivial task. Hosting large models involves complexity around the selection of instance type and deployment parameters. To address this challenge, AWS recently announced the preview of Amazon Bedrock Custom Model Import, a feature that you can use to import customized models created in other environments—such as Amazon SageMaker, Amazon Elastic Compute Cloud (Amazon EC2) instances, and on premises—into Amazon Bedrock. This feature abstracts the complexity of the deployment process through simple APIs for model deployment and invocation. Currently, Custom Model Import supports importing custom weights for selected model architectures (Meta Llama 2 and Llama 3, Flan, and Mistral) and precisions (FP32, FP16, and BF16), and serving the models on demand and with provisioned throughput.
Customizing FMs can unlock significant value by tailoring their capabilities to specific domains or tasks. This is the first in a series of posts about model customization scenarios that can be imported into Amazon Bedrock to simplify the process of building scalable and secure generative AI applications. By demonstrating the process of deploying fine-tuned models, we aim to empower data scientists, ML engineers, and application developers to harness the full potential of FMs while addressing unique application requirements.
In this post, we demonstrate the process of fine-tuning Meta Llama 3 8B on SageMaker to specialize it in the generation of SQL queries (text-to-SQL). Meta Llama 3 8B is a relatively small model that offers a balance between performance and resource efficiency. AWS customers have explored fine-tuning Meta Llama 3 8B for the generation of SQL queries—especially when using non-standard SQL dialects—and have requested methods to import their customized models into Amazon Bedrock to benefit from the managed infrastructure and security that Amazon Bedrock provides when serving those models.
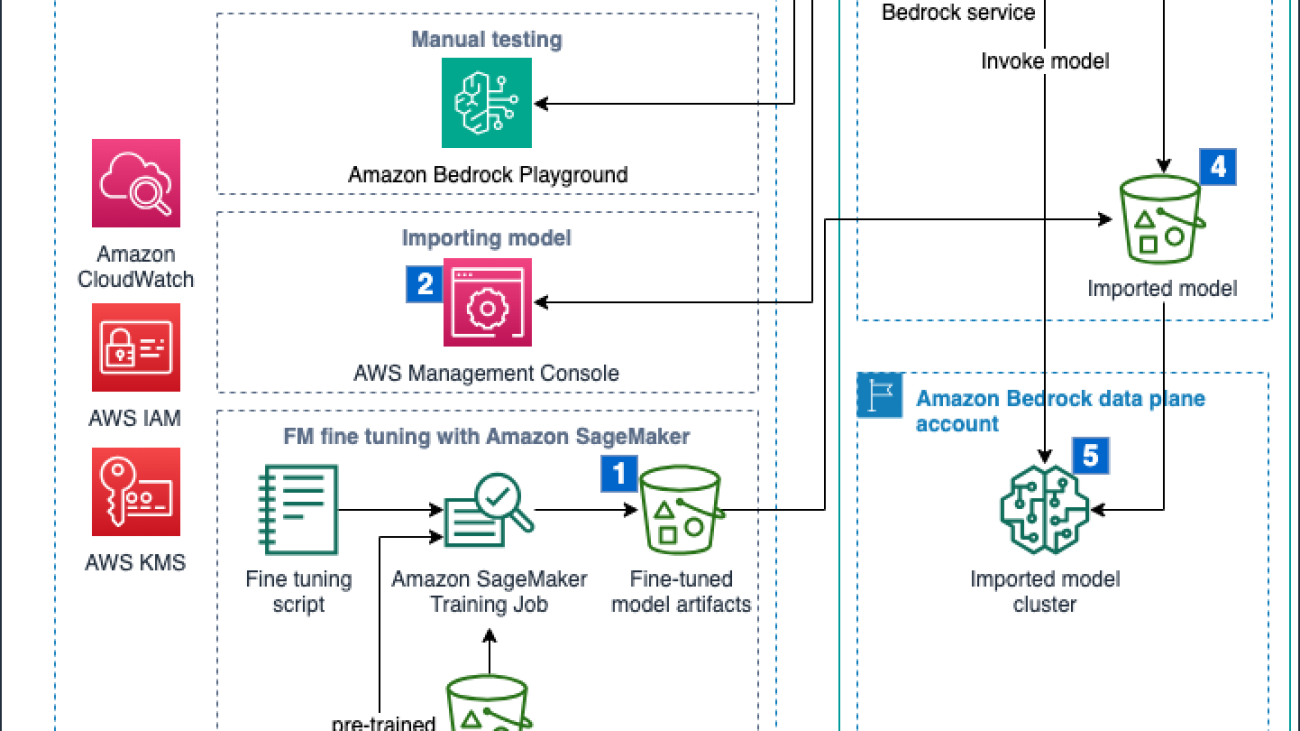
We walk through the steps of fine-tuning an FM with using SageMaker, and importing and evaluating the fine-tuned FM for SQL query generation using Amazon Bedrock. The complete flow is shown in the following figure and it covers the following steps:

All data remains within the selected AWS Region, the model artifacts are imported into the AWS operated deployment account using a VPC endpoint, and you can encrypt your model data with your own Amazon Key Management Service (AWS KMS) keys. The scripts for fine-tuning and evaluation are available on the GitHub repository.
A copy of your model artifacts is stored in an AWS operated deployment account. This copy will remain until the custom model is deleted. Deleting artifacts in the user’s account won’t delete the model or the artifacts in the AWS operated account. If different versions of a model are imported into Amazon Bedrock, each version will be managed as an independent project with its own set of artifacts. You can apply tags to models and import jobs to keep track of different projects and versions.
Meta Llama3 8B is a gated model on Hugging Face, which means that users must be granted access before they’re allowed to download and customize the model. Sign in to your Hugging Face account, read the Meta Llama 3 Acceptable Use Policy, and submit your contact information to be granted access. This process might take a couple of hours.
We use the sql-create-context dataset available on Hugging Face for fine-tuning. The dataset contains 78,577 tuples of context (table schema), question (query expressed in natural language), and answer (SQL query). Refer to the licensing information regarding this dataset before proceeding further.
We use Amazon SageMaker Studio to create a remote fine-tuning job, which will run as a SageMaker training job. SageMaker Studio is a single web-based interface for end-to-end machine learning (ML) development. If you need help configuring your SageMaker Studio domain and your JupyterLab environment, see Launch Amazon SageMaker Studio. The training job will use QLoRA and the PyTorch FullyShardedDataParallel API (FSDP) to fine-tune the Meta Llama 3 model. QLoRA quantizes a pretrained language model to 4 bits and attaches smaller low-rank adapters (LoRA), which are fine-tuned with our training data. PyTorch FSDP is a parallelism technique that shards the model across GPUs for efficient training. See the following notebook for the complete code sample.
In the data preparation stage, we use the following prompt template to insert specific instructions for interpreting the context and fulfilling the request, and store the modified training dataset as JSON files that are uploaded to Amazon S3:
Refer to the run_fsdp_qlora.py file defined in the notebook for a full description of the fine-tuning script. The following snippets describe the configuration of the QLoRA job:
The trainer class is based on Supervised Fine-tuning Trainer (SFT Trainer) from Hugging Face, which is an API to create your SFT models and train them with a few lines of code:
Once the adapter is trained, it is merged with the original model before persisting the weights. Custom Model Import does not support LoRA adapters at the moment.
For this use case, we use an ml.g5.12xlarge instance, which has four NVIDIA A10 accelerators. The key configurations are as follows:
In our testing, the training job completed two epochs in approximately 2.5 hours on a single ml.g5.12xlarge instance, which incurred approximately $18 for training cost. After training is complete, model weights in the Hugging Face safetensors format, the tokenizer, and the configuration file will be uploaded to the S3 bucket defined in the training script. This path should be stored to be used as the base directory for the import job in the next section.
The configuration file config.json will inform Amazon Bedrock how to load the weights from the safetensors files. Some parameters to keep in mind are the model_type, which must be one of the types currently supported by Amazon Bedrock, max_position_embeddings, which sets the maximum length of input sequence that the model can handle, the model dimensions (hidden_size, intermediate_size, num_hidden_layers, and num_attention_heads), and rotary position embedding (RoPE) parameters, which describe the encoding of position information. See the following configuration:
To import the fine-tuned Meta Llama 3 model into Amazon Bedrock, compete the following steps:


llama-3-8b-text-to-sql. The model import job should take 15–18 minutes to complete.
The model import job should take 15–18 minutes to complete.
In this section, we provide two examples to evaluate the SQL queries generated by the fine-tuned model: one using the Amazon Bedrock Text Playground and one using a large language model (LLM) as a judge.
You can test the model using the Amazon Bedrock Text Playground. For optimal results, use the same prompt template used to preprocess your training data:
The following animation shows the results.

On the same example notebook, we used the Amazon Bedrock InvokeModel API to call our imported model on demand to generate SQL queries for records in our test dataset. We use the same prompt template used with the training data in the fine-tuning step. The imported model will only support parameters that were supported by the base model (max_tokens, top_p, and temperature). Imported models don’t support penalty terms (repetition_penalty or length_penalty) or the use of token sampling instead of greedy decoding (do_sample). See the following code:
After we generate model predictions, we use a different (more powerful) model to act as a judge and evaluate our fine-tuned model responses. For this example, we use the Anthropic Claude 3 Sonnet LLM on Amazon Bedrock to measure the similarity between the desired answer and the predicted answer using the following prompt:
The predicted score based on our holdout split of the dataset was 96.65%, which is excellent for a small model tuned to a specific task.
The model will spin down to zero after a period of no activity and your cost will stop accruing. However, we recommend deleting the imported model using the Amazon Bedrock console. Remember to also delete model artifacts from your S3 bucket when the fine-tuned model is no longer needed to prevent incurring costs.
This post presented an overview of the process of fine-tuning a small model using SageMaker to help generate more accurate SQL queries based on questions asked in natural language and then importing the fine-tuned model into Amazon Bedrock using the Custom Model Import feature. After we imported the model, it was made available on demand through the Amazon Bedrock Playground and the InvokeModel API, which was used to evaluate the performance of the fine-tuned model against a holdout dataset using an LLM as a judge.
The following are recommended best practices that may be helpful when using fine-tuned FMs for code generation tasks:
Explore the Amazon Bedrock Custom Model Import feature as a way to deploy FMs fine-tuned for code generation tasks in a secure and scalable manner. Visit our GitHub repository to explore samples prepared for fine-tuning and importing models from various families.
 Evandro Franco is a Sr. AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 18 years working with technology, from software development, infrastructure, serverless, to machine learning.
Evandro Franco is a Sr. AI/ML Specialist Solutions Architect working on Amazon Web Services. He helps AWS customers overcome business challenges related to AI/ML on top of AWS. He has more than 18 years working with technology, from software development, infrastructure, serverless, to machine learning.
 Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
Felipe Lopez is a Senior AI/ML Specialist Solutions Architect at AWS. Prior to joining AWS, Felipe worked with GE Digital and SLB, where he focused on modeling and optimization products for industrial applications.
 Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He has 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
Jay Pillai is a Principal Solution Architect at Amazon Web Services. In this role, he functions as the Global Generative AI Lead Architect and also the Lead Architect for Supply Chain Solutions with AABG. As an Information Technology Leader, Jay specializes in artificial intelligence, data integration, business intelligence, and user interface domains. He has 23 years of extensive experience working with several clients across supply chain, legal technologies, real estate, financial services, insurance, payments, and market research business domains.
 Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on the serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in Generative AI, Artificial Intelligence, Machine Learning, and System Design. He is passionate about developing state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Ragha Prasad is a Principal Engineer and a founding member of Amazon Bedrock, where he has had the privilege to listen to customer needs first-hand and understands what it takes to build and launch scalable and secure Gen AI products. Prior to Bedrock, he worked on numerous products in Amazon, ranging from devices to Ads to Robotics.
Ragha Prasad is a Principal Engineer and a founding member of Amazon Bedrock, where he has had the privilege to listen to customer needs first-hand and understands what it takes to build and launch scalable and secure Gen AI products. Prior to Bedrock, he worked on numerous products in Amazon, ranging from devices to Ads to Robotics.