Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world.Read More

Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world.Read More

Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world.Read More
Whether looking for a time-traveling adventure, strategic roleplay or epic action, anyone can find something to play on GeForce NOW, with over 2,000 games in the cloud.
The GeForce NOW library continues to grow with seven titles arriving this week, including the role-playing game GreedFall II: The Dying World from developer Spiders and publisher Nacon.
Plus, be sure to claim the new in-game reward for Guild Wars 2 for extra style points.
GeForce NOW is improving experiences for members using Windows on Arm laptops. Support for these products is currently in beta, and improvements will be included in the GeForce NOW 2.0.67 app update, rolling out this week to bring GeForce NOW streaming at up to 4K resolution, 120 frames per second and high dynamic range to Arm-based laptops.

GreedFall II: The Dying World, the sequel to the acclaimed GreedFall, transports players to a captivating world set three years before the events of the original game. It features a revamped combat system, offering players enhanced control over Companions, and introduces a tactic pause feature during live battles for strategic planning. In this immersive adventure, step into the shoes of a person native to the magical archipelago uprooted from their homeland and thrust into the complex political landscape of the Old Continent. GreedFall II delivers an immersive experience filled with alliances, schemes and intense battles as players navigate the treacherous waters of colonial conflict and supernatural forces.
Members can shape the destiny of the Old Continent all from the cloud. Ultimate and Priority members can elevate their gaming experiences with longer gaming sessions and higher-resolution gameplay over free members. Upgrade today to get immersed in the fight for freedom.
The Guild Wars 2: Janthir Wilds expansion is here, bringing new adventures and challenges to explore in the world of Tyria. To celebrate this release, GeForce NOW is offering a special member reward: a unique style bundle to enliven members’ in-game experiences.

Transform characters’ hairstyle, horns and facial hair, customize armor and tailor a wardrobe for epic quests. The reward allows players to stand out as a true champion of Tyria while exploring the new lands of Janthir.
Members enrolled in the GeForce NOW rewards program can check their email for instructions on how to claim the reward. Ultimate and Priority members can redeem their style packages today, and free members can access the reward beginning on Friday, Sept. 27. Don’t miss out — the offer is available through Saturday, Oct. 26, on a first-come, first-served basis.

The hit survival action shooter Remnant II from Arc Games this week released its newest and final downloadable content (DLC), The Dark Horizon, along with a free update that brings a brand-new game mode called Boss Rush. In the DLC, players return to N’Erud and uncover a mysterious place preserved in time, where alien farmlands are tended by robots for inhabitants who have long since perished. But time corrupts all, and robotic creations threaten at every turn. Stream the game instantly on GeForce NOW without waiting for downloads or updates.
Members can look for the following games available to stream in the cloud this week:
What are you planning to play this weekend? Let us know on X or in the comments below.
Combat or diplomacy—what’s your go-to approach in RPGs?
—
NVIDIA GeForce NOW (@NVIDIAGFN) September 25, 2024

Microsoft Research Forum is a continuous exchange of ideas about science and technology research in the era of general AI. In the latest episode (opens in new tab), researchers discussed the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization. Researchers at Microsoft are working to explore breakthrough technology that can help advance everything from weather prediction to materials design.
Below is a brief recap of the event, including select quotes from the presentations. Register to join future Research Forum episodes and view previous sessions. Transcripts and additional resources can be found in the Research Forum briefing book.

Jianfeng Gao introduced Phi-3-Vision, an advanced and economical open-source multimodal model. As a member of the Phi-3 model family, Phi-3-Vision enhances language models by integrating multisensory skills, seamlessly combining language and vision capabilities.
“Phi-3-Vision is the first multimodal model in the Phi small model family. It matches and sometimes exceeds some of the capabilities of much larger models … at a much lower cost. And to help everyone build more affordable and accessible AI systems, we have released the model weights into the open-source community.”
— Jianfeng Gao, Distinguished Scientist and Vice President, Microsoft Research Redmond

This discussion examined the transformative potential and core challenges of multimodal models across various domains, including precision health, game intelligence, and foundation models. Microsoft researchers John Langford, Hoifung Poon, Katja Hofmann, and Jianwei Yang shared their thoughts on future directions, bridging gaps, and fostering synergies within the field.
“One of the really cutting-edge treatments for cancer these days is immunotherapy. That works by mobilizing the immune system to fight the cancer. And then one of the blockbuster drugs is a KEYTRUDA, that really can work miracles for some of the late- stage cancers … Unfortunately, only 20 to 30 percent of the patients actually respond. So that’s … a marquee example of what are the growth opportunity in precision health.”
— Hoifung Poon, General Manager, Microsoft Research Health Futures
“We experience the world through vision, touch, and all our other senses before we start to make sense of any of the language that is spoken around us. So, it’s really, really interesting to think through the implications of that, and potentially, as we start to understand more about the different modalities that we can model and the different ways in which we combine them.”
— Katja Hofmann, Senior Principal Researcher, Microsoft Research
“To really have a capable multimodal model, we need to encode different information from different modalities, for example, from vision, from language, from even audio, speech, etc. We need to develop a very capable encoder for each of these domains and then … tokenize each of these raw data.”
— Jianwei Yang, Principal Researcher, Microsoft Research Redmond

This talk presented a new kind of computer—an analog optical computer—that has the potential to accelerate AI inference and hard optimization workloads by 100x, leveraging hardware-software co-design to improve the efficiency and sustainability of real-world applications.
“Most likely, you or your loved ones have been inside an MRI scan — not really a great place to be in. Imagine if you can reduce that amount of time from 20 to 40 minutes to less than five minutes.”
— Francesca Parmigiani, Principal Researcher, Microsoft Research Cambridge
“I’m really excited to share that we have just completed the second generation of [this] computer. It is much smaller in physical size, and this is a world first in that exactly the same computer is simultaneously solving hard optimization problems and accelerating machine learning inference. Looking ahead, we estimate that at scale, this computer can achieve around 450 tera operations per second per watt, which is a 100-times improvement as compared to state-of-the-art GPUs.”
— Jiaqi Chu, Principal Researcher, Microsoft Research Cambridge

This talk explored teaching language models to self-improve using AI preference feedback, challenging the model to play against itself and a powerful teacher until it arrives at a Nash equilibrium, resulting in state-of-the-art win rates against GPT-4 Turbo on benchmarks such as AlpacaEval and MT-Bench.
“The traditional way to fine-tune an LLM for post-training … basically tells the model to emulate good behaviors, but it does not target or correct any mistakes or bad behaviors that it makes explicitly. … Self-improving post-training explicitly identifies and tries to correct bad behaviors or mistakes that the model makes.”
— Corby Rosset, Senior Researcher, Microsoft Research AI Frontiers

This talk presented Aurora, a cutting-edge foundation model that offers a new approach to weather forecasting that could transform our ability to predict and mitigate the impacts of extreme events, air pollution, and the changing climate.
“If we look at Aurora’s ability to predict pollutants such as nitrogen dioxide that are strongly related to emissions from human activity, we can see that the model has learned to make these predictions with no emissions data provided. It’s learned the implicit patterns that cause the gas concentrations, which is very impressive.”
— Megan Stanley, Senior Researcher, Microsoft Research AI for Science

This talk explored how deep learning enables generation of novel and useful biomolecules, allowing researchers and practitioners to better understand biology. This includes EvoDiff, a general-purpose diffusion framework that combines evolutionary-scale data with the distinct conditioning capabilities of diffusion models to generate new proteins, given a protein sequence.
“Often, protein engineers want proteins that perform a similar function to a natural protein, or they want to produce a protein that performs the same function but has other desirable properties, such as stability. By conditioning EvoDiff with a family of related sequences, we can generate new proteins that are very different in sequence space to the natural proteins but are predicted to fold into similar three-dimensional structures. These may be good starting points for finding new functions or for discovering versions of a protein with desirable properties.”
— Kevin Yang, Senior Researcher, Microsoft Research New England

Since AI systems are probabilistic, they can make mistakes. One of the main challenges in human-AI interaction is to avoid overreliance on AI and empower people to determine when to accept or not accept an AI system’s recommendation. This talk explores Microsoft’s work in this area.
“This is where I think it is our responsibility as people working in UX disciplines—as people researching UX and human-computer interaction—to really, really step up to the front and see how it is our moment to shine and to address this problem.”
— Mihaela Vorvoreanu, Director UX Research and Responsible AI Education, Microsoft AI Ethics and Effects in Engineering and Research (Aether)
The post Microsoft Research Forum Episode 4: The future of multimodal models, a new “small” language model, and other AI updates appeared first on Microsoft Research.
Large language models (LLMs) have shown superb capability of modeling multimodal signals including audio and text, allowing the model to generate spoken or textual response given a speech input. However, it remains a challenge for the model to recognize personal named entities, such as contacts in a phone book, when the input modality is speech. In this work, we start with a speech recognition task and propose a retrieval-based solution to contextualize the LLM: we first let the LLM detect named entities in speech without any context, then use this named entity as a query to retrieve…Apple Machine Learning Research
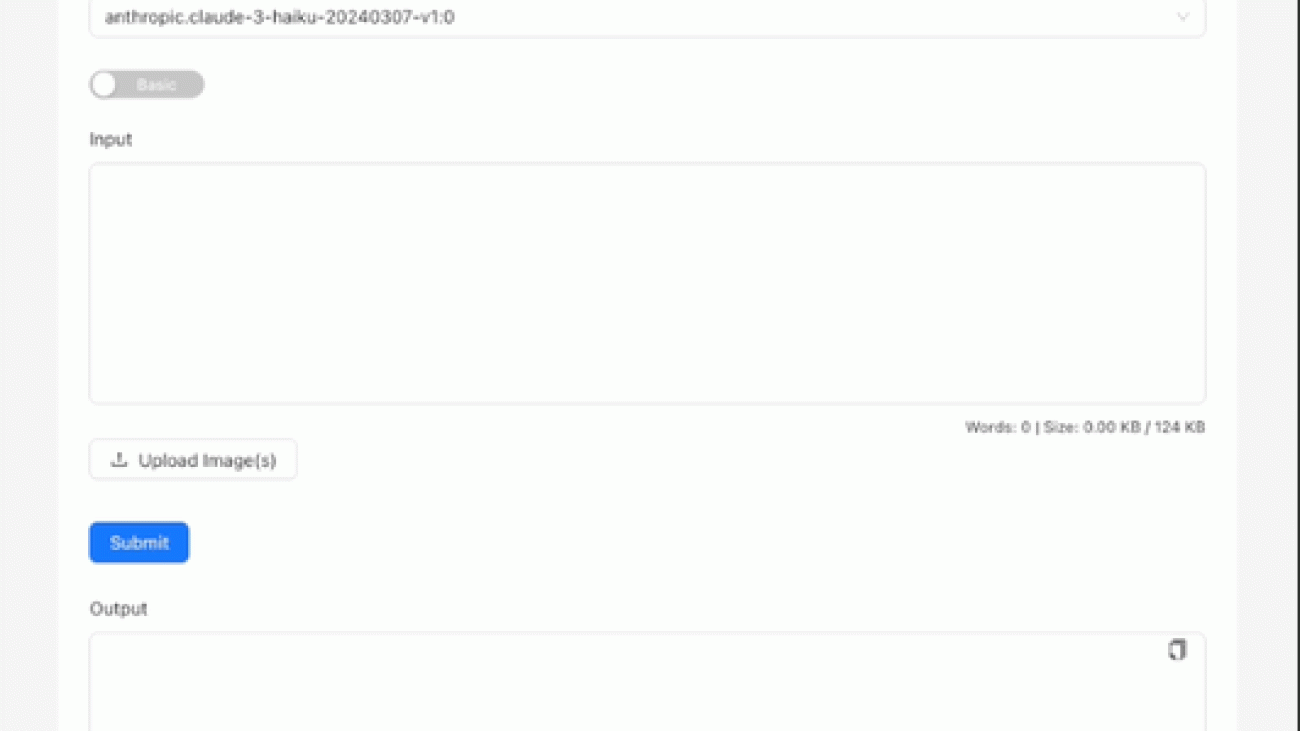
The Employee Productivity GenAI Assistant Example is a practical AI-powered solution designed to streamline writing tasks, allowing teams to focus on creativity rather than repetitive content creation. Built on AWS technologies like AWS Lambda, Amazon API Gateway, and Amazon DynamoDB, this tool automates the creation of customizable templates and supports both text and image inputs. Using generative AI models such as Anthropic’s Claude 3 from Amazon Bedrock, it provides a scalable, secure, and efficient way to generate high-quality content. Whether you’re new to AI or an experienced user, this simplified interface allows you to quickly take advantage of the power of this sample code, enhancing your team’s writing capabilities and enabling them to focus on more valuable tasks.
By using Amazon Bedrock and generative AI on AWS, organizations can accelerate their innovation cycles, unlock new business opportunities, and deliver innovative solutions powered by the latest advancements in generative AI technology, while maintaining high standards of security, scalability, and operational efficiency.
AWS takes a layered approach to generative AI, providing a comprehensive stack that covers the infrastructure for training and inference, tools to build with large language models (LLMs) and other foundation models (FMs), and applications that use these models. At the bottom layer, AWS offers advanced infrastructure like graphics processing units (GPUs), AWS Trainium, AWS Inferentia, and Amazon SageMaker, along with capabilities like UltraClusters, Elastic Fabric Adapter (EFA), and Amazon EC2 Capacity Blocks for efficient model training and inference. The middle layer, Amazon Bedrock, provides a managed service that allows you to choose from industry-leading models, customize them with your own data, and use security, access controls, and other features. This layer includes capabilities like guardrails, agents, Amazon Bedrock Studio, and customization options. The top layer consists of applications like Amazon Q Business, Amazon Q Developer, Amazon Q in QuickSight, and Amazon Q in Connect, which enable you to use generative AI for various tasks and workflows. This post focuses exclusively on the middle layer, tools with LLMs and other FMs, specifically Amazon Bedrock and its capabilities for building and scaling generative AI applications.
In this section, we discuss the key features of the Employee Productivity GenAI Assistant Example and its console options.
The Playground page of the Employee Productivity GenAI Assistant Example is designed to interact with Anthropic’s Claude language models on Amazon Bedrock. In this example, we explore how to use the Playground feature to request a poem about New York City, with the model’s response dynamically streamed back to the user.

This process includes the following steps:
claude-3:sonnet-202402229-v1.0, which is a version of Anthropic’s Claude 3.As the AI model processes the request and generates the poem, it’s streamed back to Output in real time, allowing you to observe the text being generated word by word or line by line.
The Templates page lists various predefined sample prompt templates, such as Interview Question Crafter, Perspective Change Prompt, Grammar Genie, and Tense Change Prompt.

Now let’s create a template called Product Naming Pro:
Product Naming Pro as the name and Create catchy product names from descriptions and keywords as the description.anthropic.claude-3:sonnet-202402229-v1.0 as the model.The template section includes a System Prompt option. In this example, we provide the System Prompt with guidance on creating effective product names that capture the essence of the product and leave a lasting impression.
The ${INPUT_DATA} field is a placeholder variable that allows template users to provide their input text, which will be incorporated into the prompt used by the system. The visibility of the template can be set as Public or Private. A public template can be seen by authenticated users within the deployment of the solution, making sure that only those with an account and proper authentication can access it. In contrast, a private template is only visible to your own authenticated user, keeping it exclusive to you. Additional information, such as the creator’s email address, is also displayed.
The interface showcases the creation of a Product Naming Pro template designed to generate catchy product names from descriptions and keywords, enabling efficient prompt engineering.
On the Activity page, you can choose a prompt template to generate output based on provided input.

The following steps demonstrate how to use the Activity feature:
Product Naming Pro template created in the previous section.A noise-canceling, wireless, over-ear headphone with a 20-hour battery life and touch controls. Designed for audiophiles and frequent travelers.immersive, comfortable, high-fidelity, long-lasting, convenient.The output section displays five suggested product names that were generated based on the input. For example, SoundScape Voyager, AudioOasis Nomad, EnvoyAcoustic, FidelityTrek, and SonicRefuge Traveler.
The template has processed the product description and keywords to create catchy and descriptive product name suggestions that capture the essence of the noise-canceling, wireless, over-ear headphones designed for audiophiles and frequent travelers.
The History page displays logs of the interactions and activities performed within the application, including requests made on the Playground and Activity pages.

At the top of the interface, a notification indicates that text has been copied to the clipboard, enabling you to copy generated outputs or prompts for use elsewhere.
The View and Delete options allow you to review the full details of the interaction or delete the entry from the history log, respectively.
The History page provides a way to track and revisit past activities within the application, providing transparency and allowing you to reference or manage your previous interactions with the system. The history saves your inputs and outputs on the Playground and Activity page (at the time of writing, Chat page history is not yet supported). You can only see the history of your own user requests, safeguarding security and privacy, and no other users can access your data. Additionally, you have the option to delete records stored in the history at any time if you prefer not to keep them.

The interactive chat interface displays a chat conversation. The user is greeted by the assistant, and then chooses the Product Naming Pro template and provides a product description for a noise-canceling, wireless headphone designed for audiophiles and frequent travelers. The assistant responds with an initial product name recommendation based on the description. The user then requests additional recommendations, and the assistant provides five more product name suggestions. This interactive conversation highlights how the chat functionality allows continued natural language interaction with the AI model to refine responses and explore multiple options.
In the following example, the user chooses an AI model (for example, anthropic.claude-3-sonnet-202402280-v1.0) and provides input for that model. An image named headphone.jpg has been uploaded and the user asks “Please describe the image uploaded in detail to me.”

The user chooses Submit and the AI model’s output is displayed, providing a detailed description of the headphone image. It describes the headphones as “over-ear wireless headphones in an all-black color scheme with a sleek and modern design.” It mentions the matte black finish on the ear cups and headband, as well as the well-padded soft leather or leatherette material for comfort during extended listening sessions.
This demonstrates the power of multi-modality models like the Anthropic’s Claude 3 family on Amazon Bedrock, allowing you to upload and use up to six images on the Playground or Activity pages as inputs for generating context-rich, multi-modal responses.
The Employee Productivity GenAI Assistant Example is built on robust AWS serverless technologies such as AWS Lambda, API Gateway, DynamoDB, and Amazon Simple Storage Service (Amazon S3), maintaining scalability, high availability, and security through Amazon Cognito. These technologies provide a foundation that allows the Employee Productivity GenAI Assistant Example to respond to user needs on-demand while maintaining strict security standards. The core of its generative abilities is derived from the powerful AI models available in Amazon Bedrock, which help deliver tailored and high-quality content swiftly.
The following diagram illustrates the solution architecture.

The workflow of the Employee Productivity GenAI Assistant Example includes the following steps:
Running generative AI workloads in Amazon Bedrock offers a robust and secure environment that seamlessly scales to help meet the demanding computational requirements of generative AI models. The layered security approach of Amazon Bedrock, built on the foundational principles of the comprehensive security services provided by AWS, provides a fortified environment for handling sensitive data and processing AI workloads with confidence. Its flexible architecture lets organizations use AWS elastic compute resources to scale dynamically with workload demands, providing efficient performance and cost control. Furthermore, the modular design of Amazon Bedrock empowers organizations to integrate their existing AI and machine learning (ML) pipelines, tools, and frameworks, fostering a seamless transition to a secure and scalable generative AI infrastructure within the AWS ecosystem.
In addition to the interactive features, the Employee Productivity GenAI Assistant Example provides a robust architectural pattern for building generative AI solutions on AWS. By using Amazon Bedrock and AWS serverless services such as Lambda, API Gateway, and DynamoDB, the Employee Productivity GenAI Assistant Example demonstrates a scalable and secure approach to deploying generative AI applications. You can use this architecture pattern as a foundation to build various generative AI solutions tailored to different use cases. Furthermore, the solution includes a reusable component-driven UI built on the React framework, enabling developers to quickly extend and customize the interface to fit their specific needs. The example also showcases the implementation of streaming support using WebSockets, allowing for real-time responses in both chat-based interactions and one-time requests, enhancing the user experience and responsiveness of the generative AI assistant.
You should have the following prerequisites:
To deploy and use the application, complete the following steps:
The cost of running the Employee Productivity GenAI Assistant Example will vary depending on the Amazon Bedrock model you choose and your usage patterns, as well as the Region you use. The primary cost drivers are the Amazon Bedrock model pricing and the AWS services used to host and run the application.
For this example, let’s assume a scenario with 50 users, each using this example code five times a day, with an average of 500 input tokens and 200 output tokens per use.
The total monthly token usage calculation is as follows:
The estimated monthly costs (us-east-1 Region) for different Anthropic’s Claude models on Amazon Bedrock would be the following:
These estimates don’t consider the AWS Free Tier for eligible services, so your actual costs might be lower if you’re still within the Free Tier limits. Additionally, the pricing for AWS services might change over time, so the actual costs might vary from these estimates.
The beauty of this serverless architecture is that you can scale resources up or down based on demand, making sure that you only pay for the resources you consume. Some components, such as Lambda, Amazon S3, CloudFront, DynamoDB, and Amazon Cognito, might not incur additional costs if you’re still within the AWS Free Tier limits.
For a detailed breakdown of the cost estimate, including assumptions and calculations, refer to the Cost Estimator.
When you’re done, delete any resources you no longer need to avoid ongoing costs.
To delete the stack, use the command
For example:
For more information about how to delete the resources from your AWS account, see the How to Deploy Locally section in the GitHub repo.
The Employee Productivity GenAI Assistant Example is a cutting-edge sample code that uses generative AI to automate repetitive writing tasks, freeing up resources for more meaningful work. It uses Amazon Bedrock and generative AI models to create initial templates that can be customized. You can input both text and images, benefiting from the multimodal capabilities of AI models. Key features include a user-friendly playground, template creation and application, activity history tracking, interactive chat with templates, and support for multi-modal inputs. The solution is built on robust AWS serverless technologies such as Lambda, API Gateway, DynamoDB, and Amazon S3, maintaining scalability, security, and high availability.
Visit our GitHub repository and try it firsthand.
By using Amazon Bedrock and generative on AWS, organizations can accelerate innovation cycles, unlock new business opportunities, and deliver AI-powered solutions while maintaining high standards of security and operational efficiency.
 Samuel Baruffi is a seasoned technology professional with over 17 years of experience in the information technology industry. Currently, he works at AWS as a Principal Solutions Architect, providing valuable support to global financial services organizations. His vast expertise in cloud-based solutions is validated by numerous industry certifications. Away from cloud architecture, Samuel enjoys soccer, tennis, and travel.
Samuel Baruffi is a seasoned technology professional with over 17 years of experience in the information technology industry. Currently, he works at AWS as a Principal Solutions Architect, providing valuable support to global financial services organizations. His vast expertise in cloud-based solutions is validated by numerous industry certifications. Away from cloud architecture, Samuel enjoys soccer, tennis, and travel.
 Somnath Chatterjee is an accomplished Senior Technical Account Manager at AWS, Somnath Chatterjee is dedicated to guiding customers in crafting and implementing their cloud solutions on AWS. He collaborates strategically with customers to help them run cost-optimized and resilient workloads in the cloud. Beyond his primary role, Somnath holds specialization in the Compute technical field community. He is an SAP on AWS Specialty certified professional and EFS SME. With over 14 years of experience in the information technology industry, he excels in cloud architecture and helps customers achieve their desired outcomes on AWS.
Somnath Chatterjee is an accomplished Senior Technical Account Manager at AWS, Somnath Chatterjee is dedicated to guiding customers in crafting and implementing their cloud solutions on AWS. He collaborates strategically with customers to help them run cost-optimized and resilient workloads in the cloud. Beyond his primary role, Somnath holds specialization in the Compute technical field community. He is an SAP on AWS Specialty certified professional and EFS SME. With over 14 years of experience in the information technology industry, he excels in cloud architecture and helps customers achieve their desired outcomes on AWS.
 Mohammed Nawaz Shaikh is a Technical Account Manager at AWS, dedicated to guiding customers in crafting and implementing their AWS strategies. Beyond his primary role, Nawaz serves as an AWS GameDay Regional Lead and is an active member of the AWS NextGen Developer Experience technical field community. With over 16 years of expertise in solution architecture and design, he is not only a passionate coder but also an innovator, holding three US patents.
Mohammed Nawaz Shaikh is a Technical Account Manager at AWS, dedicated to guiding customers in crafting and implementing their AWS strategies. Beyond his primary role, Nawaz serves as an AWS GameDay Regional Lead and is an active member of the AWS NextGen Developer Experience technical field community. With over 16 years of expertise in solution architecture and design, he is not only a passionate coder but also an innovator, holding three US patents.
In today’s digital age, social media has revolutionized the way brands interact with their consumers, creating a need for dynamic and engaging content that resonates with their target audience. There’s growing competition for consumer attention in this space; content creators and influencers face constant challenges to produce new, engaging, and brand-consistent content. The challenges come from three key factors: the need for rapid content production, the desire for personalized content that is both captivating and visually appealing and reflects the unique interests of the consumer, and the necessity for content that is consistent with a brand’s identity, messaging, aesthetics, and tone.
Traditionally, the content creation process has been a time-consuming task involving multiple steps such as ideation, research, writing, editing, design, and review. This slow cycle of creation does not fit for the rapid pace of social media.
Generative AI offers new possibilities to address this challenge and can be used by content teams and influencers to enhance their creativity and engagement while maintaining brand consistency. More specifically, multimodal capabilities of large language models (LLMs) allow us to create the rich, engaging content spanning text, images, audio, and video formats that are omnipresent in advertising, marketing, and social media content. With recent advancements in vision LLMs, creators can use visual input, such as reference images, to start the content creation process. Image similarity search and text semantic search further enhance the process by quickly retrieving relevant content and context.
In this post, we walk you through a step-by-step process to create a social media content generator app using vision, language, and embedding models (Anthropic’s Claude 3, Amazon Titan Image Generator, and Amazon Titan Multimodal Embeddings) through Amazon Bedrock API and Amazon OpenSearch Serverless. Amazon Bedrock is a fully managed service that provides access to high-performing foundation models (FMs) from leading AI companies through a single API. OpenSearch Serverless is a fully managed service that makes it easier to store vectors and other data types in an index and allows you to perform sub second query latency when searching billions of vectors and measuring the semantic similarity.
Here’s how the proposed process for content creation works:

In this solution, we start with data preparation, where the raw datasets can be stored in an Amazon Simple Storage Service (Amazon S3) bucket. We provide a Jupyter notebook to preprocess the raw data and use the Amazon Titan Multimodal Embeddings model to convert the image and text into embedding vectors. These vectors are then saved on OpenSearch Serverless as collections, as shown in the following figure.

Next is the content generation. The GUI webpage is hosted using a Streamlit application, where the user can provide an initial product image and a brief description of how they expect the enriched image to look. From the application, the user can also select the brand (which will link to a specific brand template later), choose the image style (such as photographic or cinematic), and select the tone for the post text (such as formal or casual).
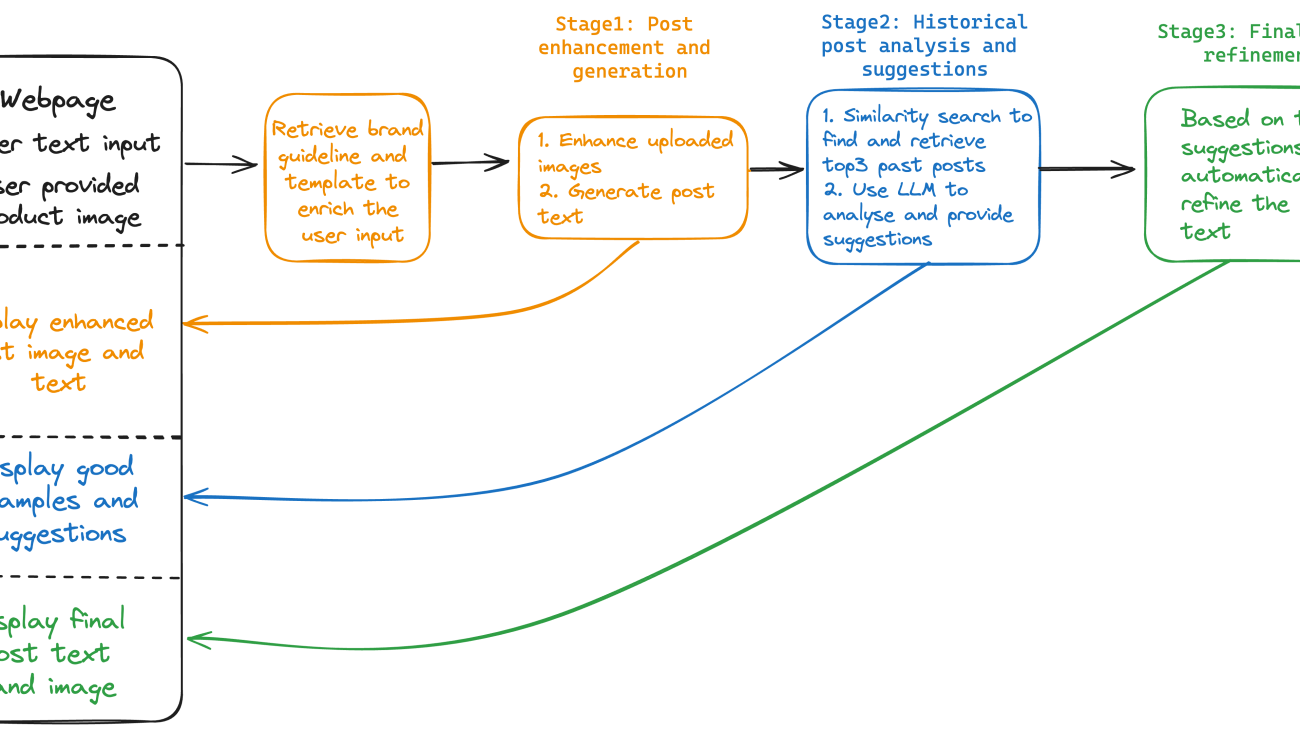
After all the configurations are provided, the content creation process, shown in the following figure, is launched.
In stage 1, the solution retrieves the brand-specific template and guidelines from a CSV file. In a production environment, you could maintain the brand template table in Amazon DynamoDB for scalability, reliability, and maintenance. The user input is used to generate the enriched image with the Amazon Titan Image Generator. Together with all the other information, it’s fed into the Claude 3 model, which has vision capability, to generate the initial post text that closely aligns with the brand guidelines and the enriched image. At the end of this stage, the enriched image and initial post text are created and sent back to the GUI to display to users.
In stage 2, we combine the post text and image and use the Amazon Titan Multimodal Embeddings model to generate the embedding vector. Multimodal embedding models integrate information from different data types, such as text and images, into a unified representation. This enables searching for images using text descriptions, identifying similar images based on visual content, or combining both text and image inputs to refine search results. In this solution, the multimodal embedding vector is used to search and retrieve the top three similar historical posts from the OpenSearch vector store. The retrieved results are fed into the Anthropic’s Claude 3 model to generate a caption, provide insights on why these historical posts are engaging, and offer recommendations on how the user can improve their post.
In stage 3, based on the recommendations from stage 2, the solution automatically refines the post text and provides a final version to the user. The user has the flexibility to select the version they like and make changes before publishing. For the end-to-end content generation process, steps are orchestrated with the Streamlit application.
The whole process is shown in the following image:

This solution has been tested in AWS Region us-east-1. However, it can also work in other Regions where the following services are available. Make sure you have the following set up before moving forward:
We use Amazon SageMaker Studio to generate historical post embeddings and save those embedding vectors to OpenSearch Serverless. Additionally, you will run the Streamlit app from the SageMaker Studio terminal to visualize and test the solution. Testing the Streamlit app in a SageMaker environment is intended for a temporary demo. For production, we recommend deploying the Streamlit app on Amazon Elastic Compute Cloud (Amazon EC2) or Amazon Elastic Container Service (Amazon ECS) services with proper security measures such as authentication and authorization.
We use the following models from Amazon Bedrock in the solution. Please see Model support by AWS Region and select the Region that supports all three models:
JupyterLab space is a private or shared space within Sagemaker Studio that manages the storage and compute resources needed to run the JupyterLab application.
To set up a JupyterLab space
In the code repository, we provide some sample product images (bag, car, perfume, and candle) that were created using the Amazon Titan Image Generator model. Next, you can generate some synthetic social media posts using the notebook: synthetic-data-generation.ipynb by using the following steps. The generated posts’ texts are saved in the metadata.jsonl file (if you prepared your own product images and post texts, you can skip this step). Then, compute multimodal embeddings for the pairs of images and generated texts. Finally, ingest the multimodal embeddings into a vector store on Amazon OpenSearch Serverless.
To generate sample posts
social-media-generator/embedding-generation.synthetic-data-generation.ipynb.data_mapping.csv.multimodal_embedding_generation.ipynb. The notebook first creates the multimodal embeddings for the post-image pair. It then ingests the computed embeddings into a vector store on Amazon OpenSearch Serverless.
The preparation steps are complete. If you want to try out the solution directly, you can skip to Run the solution with Streamlit App to quickly test the solution in your SageMaker environment. However, if you want a more detailed understanding of each step’s code and explanations, continue reading.
In this solution, we use FMs through Amazon Bedrock for content creation. We start by enhancing the input product image using the Amazon Titan Image Generator model, which adds a dynamically relevant background around the target product.
The get_titan_ai_request_body function creates a JSON request body for the Titan Image Generator model, using its Outpainting feature. It accepts four parameters: outpaint_prompt (for example, “Christmas tree, holiday decoration” or “Mother’s Day, flowers, warm lights”), negative_prompt (elements to exclude from the generated image), mask_prompt (specifies areas to retain, such as “bag” or “car”), and image_str (the input image encoded as a base64 string).
The generate_image function requires model_id and body (the request body from get_titan_ai_request_body). It invokes the model using bedrock.invoke_model and returns the response containing the base64-encoded generated image.
Finally, the code snippet calls get_titan_ai_request_body with the provided prompts and input image string, then passes the request body to generate_image, resulting in the enhanced image.
The following images showcase the enhanced versions generated based on input prompts like “Christmas tree, holiday decoration, warm lights,” a selected position (such as bottom-middle), and a brand (“Luxury Brand”). These settings influence the output images. If the generated image is unsatisfactory, you can repeat the process until you achieve the desired outcome.

Next, generate the post text, taking into consideration the user inputs, brand guidelines (provided in the brand_guideline.csv file, which you can replace with your own data), and the enhanced image generated from the previous step.
The generate_text_with_claude function is the higher-level function that handles the image and text input, prepares the necessary data, and calls generate_vision_answer to interact with the Amazon Bedrock model (Claude 3 models) and receive the desired response. The generate_vision_answer function performs the core interaction with the Amazon Bedrock model, processes the model’s response, and returns it to the caller. Together, they enable generating text responses based on combined image and text inputs.
In the following code snippet, an initial post prompt is constructed using formatting placeholders for various elements such as role, product name, target brand, tone, hashtag, copywriting, and brand messaging. These elements are provided in the brand_guideline.csv file to make sure that the generated text aligns with the brand preferences and guidelines. This initial prompt is then passed to the generate_text_with_claude function, along with the enhanced image to generate the final post text.
The following example shows the generated post text. It provides a detailed description of the product, aligns well with the brand guidelines, and incorporates elements from the image (such as the Christmas tree). Additionally, we instructed the model to include hashtags and emojis where appropriate, and the results demonstrate that it followed the prompt instructions effectively.
|
Post text: Elevate your style with Luxury Brand’s latest masterpiece. Crafted with timeless elegance and superior quality, this exquisite bag embodies unique craftsmanship. Indulge in the epitome of sophistication and let it be your constant companion for life’s grandest moments. |
The next step involves using the generated image and text to search for the top three similar historical posts from a vector database. We use the Amazon Titan Multimodal Embeddings model to create embedding vectors, which are stored in Amazon OpenSearch Serverless. The relevant historical posts, which might have many likes, are displayed on the application webpage to give users an idea of what successful social media posts look like. Additionally, we analyze these retrieved posts and provide actionable improvement recommendations for the user. The following code snippet shows the implementation of this step.
The code defines two functions: find_similar_items and process_images. find_similar_items performs semantic search using the k-nearest neighbors (kNN) algorithm on the input image prompt. It computes a multimodal embedding for the image and query prompt, constructs an OpenSearch kNN query, runs the search, and retrieves the top matching images and post texts. process_images analyzes a list of similar images in parallel using multiprocessing. It generates analysis texts for the images by calling generate_text_with_claude with an analysis prompt, running the calls in parallel, and collecting the results.
In the snippet, find_similar_items is called to retrieve the top three similar images and post texts based on the input image and a combined query prompt. process_images is then called to generate analysis texts for the first three similar images in parallel, displaying the results simultaneously.
An example of historical post retrieval and analysis is shown in the following screenshot. Post images are listed on the left. On the right, the full text content of each post is retrieved and displayed. We then use an LLM model to generate a comprehensive scene description for the post image, which can serve as a prompt to inspire image generation. Next, the LLM model generates automatic recommendations for improvement. In this solution, we use the Claude 3 Sonnet model for text generation.
As the final step, the solution incorporates the recommendations and refines the post text to make it more appealing and likely to attract more attention from social media users.

You can download the solution from this Git repository. Use the following steps to run the Streamlit application and quickly test out the solution in your SageMaker Studio environment.
streamlit-app folder in a terminal:
https://[USER-PROFILE-ID].studio.[REGION].sagemaker.aws/jupyter/default/proxy/8501/
sh status.sh in the terminal.sh cleanup.sh.With the Streamlit app downloaded, you can begin by providing initial prompts and selecting the products you want to retain in the image. You have the option to upload an image from your local machine, plug in your camera to take an initial product picture on the fly, or quickly test the solution by selecting a pre-uploaded image example. You can then optionally adjust the product’s location in the image by setting its position. Next, select the brand for the product. In the demo, we use the luxury brand and the fast fashion brand, each with its own preferences and guidelines. Finally, choose the image style. Choose Submit to start the process.
The application will automatically handle post-image and text generation, retrieve similar posts for analysis, and refine the final post. This end-to-end process can take approximately 30 seconds. If you aren’t satisfied with the result, you can repeat the process a few times. An end-to-end demo is shown below.

If you find yourself lacking ideas for initial prompts to create the enhanced image, consider using a reverse search approach. During the retrieve and analyze posts step mentioned earlier, scene descriptions are also generated, which can serve as inspiration. You can modify these descriptions as needed and use them to generate new images and accompanying text. This method effectively uses existing content to stimulate creativity and enhance the application’s output.

In the preceding example, the top three similar images to our generated images show perfume pictures posted to social media by users. This insight helps brands understand their target audience and the environments in which their products are used. By using this information, brands can create dynamic and engaging content that resonates with their users. For instance, in the example provided, “a hand holding a glass perfume bottle in the foreground, with a scenic mountain landscape visible in the background,” is unique and visually more appealing than a dull picture of “a perfume bottle standing on a branch in a forest.” This illustrates how capturing the right scene and context can significantly enhance the attractiveness and impact of social media content.
When you finish experimenting with this solution, use the following steps to clean up the AWS resources to avoid unnecessary costs:
In this blog post, we introduced a multimodal social media content generator solution that uses FMs from Amazon Bedrock, such as the Amazon Titan Image Generator, Claude 3, and Amazon Titan Multimodal Embeddings. The solution streamlines the content creation process, enabling brands and influencers to produce engaging and brand-consistent content rapidly. You can try out the solution using this code sample.
The solution involves enhancing product images with relevant backgrounds using the Amazon Titan Image Generator, generating brand-aligned text descriptions through Claude 3, and retrieving similar historical posts using Amazon Titan Multimodal Embeddings. It provides actionable recommendations to refine content for better audience resonance. This multimodal AI approach addresses challenges in rapid content production, personalization, and brand consistency, empowering creators to boost creativity and engagement while maintaining brand identity.
We encourage brands, influencers, and content teams to explore this solution and use the capabilities of FMs to streamline their content creation processes. Additionally, we invite developers and researchers to build upon this solution, experiment with different models and techniques, and contribute to the advancement of multimodal AI in the realm of social media content generation.
See this announcement blog post for information about the Amazon Titan Image Generator and Amazon Titan Multimodal Embeddings model. For more information, see Amazon Bedrock and Amazon Titan in Amazon Bedrock.
 Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS, specialising in building GenAI applications with customers, including RAG and agent solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. Outside of work, she enjoys spending quality time with her family, getting lost in novels, and hiking in the UK’s national parks.
Ying Hou, PhD, is a Machine Learning Prototyping Architect at AWS, specialising in building GenAI applications with customers, including RAG and agent solutions. Her expertise spans GenAI, ASR, Computer Vision, NLP, and time series prediction models. Outside of work, she enjoys spending quality time with her family, getting lost in novels, and hiking in the UK’s national parks.
 Bishesh Adhikari, is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and AI/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends.
Bishesh Adhikari, is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and AI/ML. Specializing in GenAI, LLMs, NLP, CV, and GeoSpatial ML, he collaborates with AWS customers to build solutions for challenging problems through co-development. His expertise accelerates customers’ journey from concept to production, tackling complex use cases across various industries. In his free time, he enjoys hiking, traveling, and spending time with family and friends.
In the realm of generative artificial intelligence (AI), Retrieval Augmented Generation (RAG) has emerged as a powerful technique, enabling foundation models (FMs) to use external knowledge sources for enhanced text generation.
Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock Knowledge Bases is a fully managed capability that helps you implement the entire RAG workflow—from ingestion to retrieval and prompt augmentation—without having to build custom integrations to data sources and manage data flows. However, RAG has had its share of challenges, especially when it comes to using it for numerical analysis. This is the case when you have information embedded in complex nested tables. Latest innovations in Amazon Bedrock Knowledge Base provide a resolution to this issue.
In this post, we explore how Amazon Bedrock Knowledge Bases address the use case of numerical analysis across a number of documents.
With RAG, an information retrieval component is introduced that utilizes the user input to first pull relevant information from a data source. The user query and the relevant information are both given to the large language model (LLM). The LLM uses the new knowledge and its training data to create better responses.
Although this approach holds a lot of promise for textual documents, the presence of non-textual elements, such as tables, pose a significant challenge. One issue is that the table structure by itself can be difficult to interpret when directly queried against documents in PDFs or Word. This can be addressed by transforming the data into a format such as text, markdown, or HTML.
Another issue relates to search, retrieval, and chunking of documents that contain tables. The first step in RAG is to chunk a document so you can transform that chunk of data into a vector for a meaningful representation of text. However, when you apply this method to a table, even if converted into a text format, there is a risk that the vector representation doesn’t capture all the relationships in the table. As a result, when you try to retrieve information, a lot of information is missed. Because this information isn’t retrieved, the LLM doesn’t provide accurate answers to your questions.
Amazon Bedrock Knowledge Bases provide three capabilities to resolve this issue:
Using a combination of these features can enhance numerical analysis of information across multiple documents that contain data in tables. In the next section, we demonstrate this approach using a set of earnings documents from Amazon.
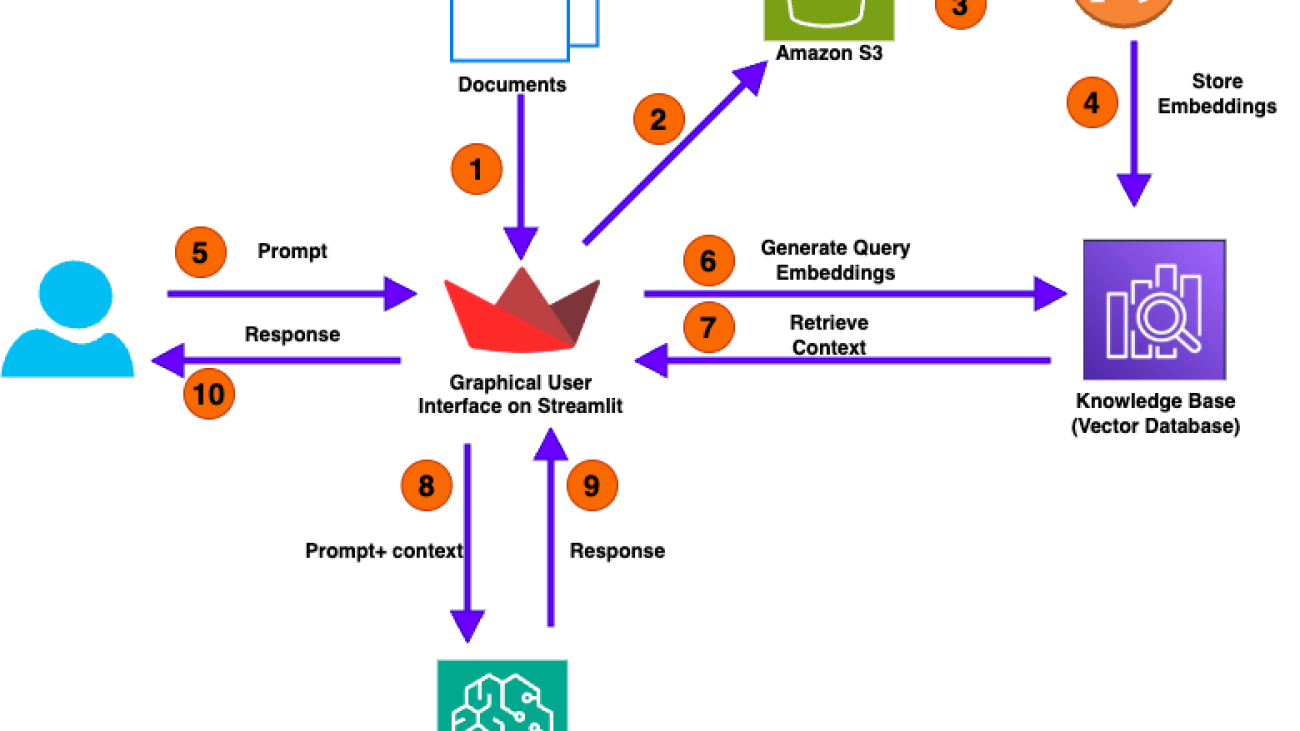
The following diagram illustrates the high-level architecture of our solution for analyzing numerical documents.

The user call flow consists of the following steps:
In the following sections, we walk through the steps to create an S3 bucket and knowledge base, deploy the Streamlit application with AWS CloudFormation, and test the solution.
You should have the following prerequisites:
Complete the following steps to create your S3 bucket:
Complete the following steps to create a knowledge base with default settings:





After the knowledge base is setup using the above 9 steps, complete the following steps to create the Streamlit application using the CloudFormation template:

When the stack is complete, you can refer to the stack’s Outputs tab for the Streamlit application URL.
Now that we have deployed the Streamlit application, let’s see how users can interact with it and ask questions.
We can divide the UI experience into two phases: document ingestion and document querying.
The document ingestion workflow consists of the following steps:
The document querying workflow consists of the following steps:
To test this setup, we deployed this solution in an AWS account and analyzed Amazon earnings for the last 16 quarters. The results from a semantic search with default chunking vs. a hybrid search with fixed size chunking and maximum results are displayed in the following table.
| Question | Semantic Search with Default Chunking | Hybrid Search with Fixed Size Chunking |
| What is the change in total operating expenses for technology and infrastructure from 2020 to 2023? | Based on the information provided in the search results, I could not find the exact change in total operating expenses for technology and infrastructure from 2020 to 2023. The search results provide some financial data, but do not break down the operating expenses into specific categories like technology and infrastructure. Without that level of detail, I cannot determine the exact change in those expenses over that time period |
Based on the financial information provided, Amazon’s operating expenses for technology and infrastructure increased from 42.7billion in 2020 to 85.6 billion in 2023, an increase of $42.9 billion. |
| What are the international operating expenses in 2020, 2021 and 2022? | Based on the search results, I could not find any information about Amazon’s international operating expenses for the years 2020, 2021, and 2022. The financial information provided in the search results focuses on Amazon’s overall operating expenses, cash flows, and other financial metrics, but does not break down the expenses by international operations. |
The international operating expenses for Amazon were: 2020: 103,695 million 2021:128,711 million 2022: $125,753 million |
As seen in the results, the hybrid search option provides correct answers to all the questions.
To prevent incurring costs after deploying and testing this solution, delete the S3 bucket, knowledge base, and CloudFormation stack.
In this post, we discussed how Amazon Bedrock Knowledge Bases provides a powerful solution that enables numerical analysis on documents. You can deploy this solution in an AWS account and use it to analyze different types of documents. As we continue to push the boundaries of generative AI, solutions like this will play a pivotal role in bridging the gap between unstructured data and actionable insights, enabling organizations to unlock the full potential of their data assets.
To further explore the advanced RAG capabilities of Amazon Bedrock Knowledge Bases, refer to the following resources:
 Sanjeev Pulapaka is a Principal Solutions architect and the Single Threaded Leader for AI/ML in the US federal civilian team at AWS. He advises customers on AI/ML-related solutions that advance their mission. Sanjeev has extensive experience in leading, architecting, and implementing high-impact technology solutions that address diverse business needs in multiple sectors, including commercial, federal, and state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
Sanjeev Pulapaka is a Principal Solutions architect and the Single Threaded Leader for AI/ML in the US federal civilian team at AWS. He advises customers on AI/ML-related solutions that advance their mission. Sanjeev has extensive experience in leading, architecting, and implementing high-impact technology solutions that address diverse business needs in multiple sectors, including commercial, federal, and state and local governments. He has an undergraduate degree in engineering from the Indian Institute of Technology and an MBA from the University of Notre Dame.
 Muhammad Qazafi is a Solutions Architect based in the US. He assists customers in designing, developing, and implementing secure, scalable, and innovative solutions on AWS. His objective is to help customers achieve measurable business outcomes through the effective utilization of AWS services. With over 15 years of experience, Muhammad brings a wealth of knowledge and expertise across a diverse range of industries. This extensive experience enables him to understand the unique challenges faced by different businesses and help customers create solutions on AWS.
Muhammad Qazafi is a Solutions Architect based in the US. He assists customers in designing, developing, and implementing secure, scalable, and innovative solutions on AWS. His objective is to help customers achieve measurable business outcomes through the effective utilization of AWS services. With over 15 years of experience, Muhammad brings a wealth of knowledge and expertise across a diverse range of industries. This extensive experience enables him to understand the unique challenges faced by different businesses and help customers create solutions on AWS.
 Venkata Kampana is a Senior Solutions architect in the AWS Health and Human Services team and is based in Sacramento, California. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Venkata Kampana is a Senior Solutions architect in the AWS Health and Human Services team and is based in Sacramento, California. In this role, he helps public sector customers achieve their mission objectives with well-architected solutions on AWS.
Welcoming proposals related to data validation, life cycle assessment, biodiversity and more.Read More
Today, we are excited to announce the availability of Llama 3.2 models in Amazon SageMaker JumpStart. Llama 3.2 offers multi-modal vision and lightweight models representing Meta’s latest advancement in large language models (LLMs), providing enhanced capabilities and broader applicability across various use cases. With a focus on responsible innovation and system-level safety, these new models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features that help you build a new generation of AI experiences. SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML.
In this post, we show how you can discover and deploy the Llama 3.2 11B Vision model using SageMaker JumpStart. We also share the supported instance types and context for all the Llama 3.2 models available in SageMaker JumpStart. Although not highlighted in this blog, you can also use the lightweight models along with fine-tuning using SageMaker JumpStart.
Llama 3.2 models are available in SageMaker JumpStart initially in the US East (Ohio) AWS Region. Please note that Meta has restrictions on your usage of the multi-modal models if you are located in the European Union. See Meta’s community license agreement for more details.
Llama 3.2 represents Meta’s latest advancement in LLMs. Llama 3.2 models are offered in various sizes, from small and medium-sized multi-modal models. The larger Llama 3.2 models come in two parameter sizes—11B and 90B—with 128,000 context length, and are capable of sophisticated reasoning tasks including multi-modal support for high resolution images. The lightweight text-only models come in two parameter sizes—1B and 3B—with 128,000 context length, and are suitable for edge devices. Additionally, there is a new safeguard Llama Guard 3 11B Vision parameter model, which is designed to support responsible innovation and system-level safety.
Llama 3.2 is the first Llama model to support vision tasks, with a new model architecture that integrates image encoder representations into the language model. With a focus on responsible innovation and system-level safety, Llama 3.2 models help you build and deploy cutting-edge generative AI models to ignite new innovations like image reasoning and are also more accessible for on-edge applications. The new models are also designed to be more efficient for AI workloads, with reduced latency and improved performance, making them suitable for a wide range of applications.
SageMaker JumpStart offers access to a broad selection of publicly available foundation models (FMs). These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can now use state-of-the-art model architectures, such as language models, computer vision models, and more, without having to build them from scratch.
With SageMaker JumpStart, you can deploy models in a secure environment. The models can be provisioned on dedicated SageMaker Inference instances, including AWS Trainium and AWS Inferentia powered instances, and are isolated within your virtual private cloud (VPC). This enforces data security and compliance, because the models operate under your own VPC controls, rather than in a shared public environment. After deploying an FM, you can further customize and fine-tune it using the extensive capabilities of Amazon SageMaker, including SageMaker Inference for deploying models and container logs for improved observability. With SageMaker, you can streamline the entire model deployment process.
To try out the Llama 3.2 models in SageMaker JumpStart, you need the following prerequisites:
SageMaker JumpStart provides FMs through two primary interfaces: SageMaker Studio and the SageMaker Python SDK. This provides multiple options to discover and use hundreds of models for your specific use case.
SageMaker Studio is a comprehensive IDE that offers a unified, web-based interface for performing all aspects of the ML development lifecycle. From preparing data to building, training, and deploying models, SageMaker Studio provides purpose-built tools to streamline the entire process. In SageMaker Studio, you can access SageMaker JumpStart to discover and explore the extensive catalog of FMs available for deployment to inference capabilities on SageMaker Inference.
In SageMaker Studio, you can access SageMaker JumpStart by choosing JumpStart in the navigation pane or by choosing JumpStart from the Home page.

Alternatively, you can use the SageMaker Python SDK to programmatically access and use SageMaker JumpStart models. This approach allows for greater flexibility and integration with existing AI/ML workflows and pipelines. By providing multiple access points, SageMaker JumpStart helps you seamlessly incorporate pre-trained models into your AI/ML development efforts, regardless of your preferred interface or workflow.
On the SageMaker JumpStart landing page, you can discover all public pre-trained models offered by SageMaker. You can choose the Meta model provider tab to discover all the Meta models available in SageMaker.
If you’re using SageMaker Classic Studio and don’t see the Llama 3.2 models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Classic Apps.

You can choose the model card to view details about the model such as license, data used to train, and how to use. You can also find two buttons, Deploy and Open Notebook, which help you use the model.

When you choose either button, a pop-up window will show the End-User License Agreement (EULA) and acceptable use policy for you to accept.

Upon acceptance, you can proceed to the next step to use the model.
When you choose Deploy and accept the terms, model deployment will start. Alternatively, you can deploy through the example notebook by choosing Open Notebook. The notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy using a notebook, you start by selecting an appropriate model, specified by the model_id. You can deploy any of the selected models on SageMaker.
You can deploy a Llama 3.2 11B Vision model using SageMaker JumpStart with the following SageMaker Python SDK code:
This deploys the model on SageMaker with default configurations, including default instance type and default VPC configurations. You can change these configurations by specifying non-default values in JumpStartModel. To successfully deploy the model, you must manually set accept_eula=True as a deploy method argument. After it’s deployed, you can run inference against the deployed endpoint through the SageMaker predictor:
The following table lists all the Llama 3.2 models available in SageMaker JumpStart along with the model_id, default instance types, and the maximum number of total tokens (sum of number of input tokens and number of generated tokens) supported for each of these models. For increased context length, you can modify the default instance type in the SageMaker JumpStart UI.
| Model Name | Model ID | Default instance type | Supported instance types |
| Llama-3.2-1B | meta-textgeneration-llama-3-2-1b, meta-textgenerationneuron-llama-3-2-1b |
ml.g6.xlarge (125K context length), ml.trn1.2xlarge (125K context length) |
All g6/g5/p4/p5 instances; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-1B-Instruct | meta-textgeneration-llama-3-2-1b-instruct, meta-textgenerationneuron-llama-3-2-1b-instruct |
ml.g6.xlarge (125K context length), ml.trn1.2xlarge (125K context length) |
All g6/g5/p4/p5 instances; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-3B | meta-textgeneration-llama-3-2-3b, meta-textgenerationneuron-llama-3-2-3b |
ml.g6.xlarge (125K context length), ml.trn1.2xlarge (125K context length) |
All g6/g5/p4/p5 instances; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-3B-Instruct | meta-textgeneration-llama-3-2-3b-instruct, meta-textgenerationneuron-llama-3-2-3b-instruct |
ml.g6.xlarge (125K context length), ml.trn1.2xlarge (125K context length) |
All g6/g5/p4/p5 instances; ml.inf2.xlarge, ml.inf2.8xlarge, ml.inf2.24xlarge, ml.inf2.48xlarge, ml.trn1.2xlarge, ml.trn1.32xlarge, ml.trn1n.32xlarge |
| Llama-3.2-11B-Vision | meta-vlm-llama-3-2-11b-vision | ml.p4d.24xlarge (125K context length) | p4d.24xlarge, p4de.24xlarge, p5.48xlarge |
| Llama-3.2-11B-Vision-Instruct | meta-vlm-llama-3-2-11b-vision-instruct | ml.p4d.24xlarge (125K context length) | p4d.24xlarge, p4de.24xlarge, p5.48xlarge |
| Llama-3.2-90B-Vision | meta-vlm-llama-3-2-90b-vision | ml.p5.24xlarge (125K context length) | p4d.24xlarge, p4de.24xlarge, p5.48xlarge |
| Llama-3.2-90B-Vision-Instruct | meta-vlm-llama-3-2-90b-vision-instruct | ml.p5.24xlarge (125K context length) | p4d.24xlarge, p4de.24xlarge, p5.48xlarge |
| Llama-Guard-3-11B-Vision | meta-vlm-llama-guard-3-11b-vision | ml.p4d.24xlarge | p4d.24xlarge, p4de.24xlarge, p5.48xlarge |
Llama 3.2 models have been evaluated on over 150 benchmark datasets, demonstrating competitive performance with leading FMs.
You can use Llama 3.2 11B and 90B models for text and image or vision reasoning use cases. You can perform a variety of tasks, such as image captioning, image text retrieval, visual question answering and reasoning, document visual question answering, and more. Input payload to the endpoint looks like the following code examples.
The following is an example of text-only input:
This produces the following response:
You can set up vision-based reasoning tasks with Llama 3.2 models with SageMaker JumpStart as follows:
Let’s load an image from the open source MATH-Vision dataset:
We can structure the message object with our base64 image data:
This produces the following response:
The following code is an example of multi-image input:
This produces the following response:
To avoid incurring unnecessary costs, when you’re done, delete the SageMaker endpoints using the following code snippets:
Alternatively, to use the SageMaker console, complete the following steps:
In this post, we explored how SageMaker JumpStart empowers data scientists and ML engineers to discover, access, and deploy a wide range of pre-trained FMs for inference, including Meta’s most advanced and capable models to date. Get started with SageMaker JumpStart and Llama 3.2 models today. For more information about SageMaker JumpStart, see Train, deploy, and evaluate pretrained models with SageMaker JumpStart and Getting started with Amazon SageMaker JumpStart.
Supriya Puragundla is a Senior Solutions Architect at AWS
Armando Diaz is a Solutions Architect at AWS
Sharon Yu is a Software Development Engineer at AWS
Siddharth Venkatesan is a Software Development Engineer at AWS
Tony Lian is a Software Engineer at AWS
Evan Kravitz is a Software Development Engineer at AWS
Jonathan Guinegagne is a Senior Software Engineer at AWS
Tyler Osterberg is a Software Engineer at AWS
Sindhu Vahini Somasundaram is a Software Development Engineer at AWS
Hemant Singh is an Applied Scientist at AWS
Xin Huang is a Senior Applied Scientist at AWS
Adriana Simmons is a Senior Product Marketing Manager at AWS
June Won is a Senior Product Manager at AWS
Karl Albertsen is a Head of ML Algorithm and JumpStart at AWS


 #LuxuryBrand #TimelessElegance #ExclusiveCollection
#LuxuryBrand #TimelessElegance #ExclusiveCollection