 The award is for their work on AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More
The award is for their work on AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More
The award is for their work on AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

Welcome to Research Focus, a series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.

In a recent paper: Securely Training Decision Trees Efficiently that will appear at ACM CCS 2024, researchers from Microsoft significantly reduce the communication complexity of secure decision tree training. Decision trees are an important class of supervised learning algorithms. In this approach, a classification or regression tree is built based on a set of features or attributes present in the training dataset. As with many learning algorithms, the accuracy of decision trees can be greatly improved with larger volumes of data. However, this can be a challenge, since data may come from multiple independent sources and require attention to data privacy concerns. In this case, the use of a privacy-enhancing technology, such as secure multi-party computation (MPC), can help protect the underlying training data.
When the number of elements in the dataset is 𝑁, the number of attributes is 𝑚 and the height of the tree to be built is ℎ, the researchers construct a protocol with communication complexity O(𝑚𝑁 log 𝑁 + ℎ𝑚𝑁 + ℎ𝑁 log 𝑁 ), thereby achieving an improvement of ≈ min(ℎ, 𝑚, log 𝑁 ) over the previous state of the art. The essential feature is an improved protocol to regroup sorted private elements further into additional groups (according to a flag vector) while maintaining their relative ordering. Implementing this protocol in the MP-SPDZ framework shows that it requires 10× lesser communication and is 9× faster than existing approaches.
Improving the real-world accuracy of audio content detection (ACD) is an important problem for streaming platforms, operating systems and playback devices. It’s similar to audio tagging, i.e., labeling sounds present in a given audio segment of several seconds length or longer. However, ACD may consist of a small number of higher-level labels or super-classes, e.g. speech, music, traffic, machines, animals, etc., where each label can include a multitude of specific sounds.
In a recent paper: Multi-label audio classification with a noisy zero-shot teacher, researchers from Microsoft propose a novel training scheme using self-label correction and data augmentation methods to deal with noisy labels and improve real-world accuracy on a polyphonic audio content detection task. The augmentation method reduces label noise by mixing multiple audio clips and joining their labels, while being compatible with multiple active labels. The researchers show that performance can be improved by a self-label correction method using the same pretrained model. They also show that it is feasible to use a strong zero-shot model such as CLAP to generate labels for unlabeled data and improve the results using the proposed training and label enhancement methods. The resulting model performs similar to CLAP while providing an efficient mobile device friendly architecture which can be quickly adapted to unlabeled sound classes.
Tables are commonly used to store and present data. These tables are often moved as free-form text when copied from documents and applications without proper tabular support like PDF documents, web pages, or images. Users are dependent on manual effort or programming abilities to parse this free-form text back into structured tables.
In a recent paper: Tabularis Revilio: Converting Text to Tables, researchers from Microsoft present a novel neurosymbolic system for reconstructing tables when their column boundaries have been lost. Revilio addresses this task by detecting headers, generating an initial table sketch using a large language model (LLM), and using that sketch as a guiding representation during an enumerate-and-test strategy that evaluates syntactic and semantic table structures. Revilio was evaluated on a diverse set of datasets, demonstrating significant improvements over existing table parsing methods. Revilio outperforms traditional techniques in both accuracy and scalability, handling large tables with over 100,000 rows. The researchers’ experiments using publicly available datasets show an increase in reconstruction accuracy by 5.8–11.3% over both neural and symbolic baseline state-of-the-art systems.
on-demand event

Learn about the latest multimodal AI models, advanced benchmarks for AI evaluation and model self-improvement, and an entirely new kind of computer for AI inference and hard optimization.
Container-based technologies empower cloud tenants to develop highly portable software and deploy services in the cloud at a rapid pace. Cloud privacy, meanwhile, is important as a large number of container deployments operate on privacy-sensitive data, but challenging due to the increasing frequency and sophistication of attacks. State-of-the-art confidential container-based designs leverage process-based trusted execution environments (TEEs), but face security and compatibility issues that limit their practical deployment.
In a recent article in Communications of the ACM: Confidential Container Groups: Implementing Confidential Computing on Azure Container Instances (opens in new tab), researchers from Microsoft with external colleagues present the Parma architecture, which provides lift-and-shift deployment of unmodified containers while providing strong security protection against a powerful attacker who controls the untrusted host and hypervisor. Parma leverages VM-level isolation to execute a container group within a unique VM-based TEE. Besides container integrity and user data confidentiality and integrity, Parma also offers container attestation and execution integrity based on an attested execution policy. This policy, which is specified by the customer, delimits the actions that the cloud service provider is allowed to take on their behalf when managing the container group.
The result is that customers receive the security protections of TEEs for their container workloads with minimal costs to perfromance. To learn more, check out Confidential Containers on Azure Container Instances (opens in new tab), which is based on Microsoft’s Parma architecture.
Generative AI is changing how businesses operate and how stakeholders talk to each other. The building blocks for large scale AI transformation are now in place, but we are only beginning to imagine how it will unfold. Learn what Microsoft research leaders discovered from some early AI innovation in healthcare, and how businesses can prepare for what’s ahead.
In this new three-part video series, Microsoft Research President Peter Lee and Corporate Vice President Vijay Mital discuss how Microsoft is helping businesses navigate this transformation, along with the critical role of data and how emerging multimodal AI models could turbocharge business innovation.
The post Research Focus: Week of October 7, 2024 appeared first on Microsoft Research.

Large language models and the applications they power enable unprecedented opportunities for organizations to get deeper insights from their data reservoirs and to build entirely new classes of applications.
But with opportunities often come challenges.
Both on premises and in the cloud, applications that are expected to run in real time place significant demands on data center infrastructure to simultaneously deliver high throughput and low latency with one platform investment.
To drive continuous performance improvements and improve the return on infrastructure investments, NVIDIA regularly optimizes the state-of-the-art community models, including Meta’s Llama, Google’s Gemma, Microsoft’s Phi and our own NVLM-D-72B, released just a few weeks ago.
Performance improvements let our customers and partners serve more complex models and reduce the needed infrastructure to host them. NVIDIA optimizes performance at every layer of the technology stack, including TensorRT-LLM, a purpose-built library to deliver state-of-the-art performance on the latest LLMs. With improvements to the open-source Llama 70B model, which delivers very high accuracy, we’ve already improved minimum latency performance by 3.5x in less than a year.
We’re constantly improving our platform performance and regularly publish performance updates. Each week, improvements to NVIDIA software libraries are published, allowing customers to get more from the very same GPUs. For example, in just a few months’ time, we’ve improved our low-latency Llama 70B performance by 3.5x.
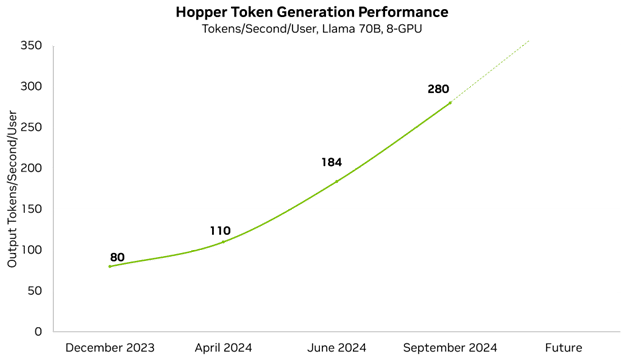
In the most recent round of MLPerf Inference 4.1, we made our first-ever submission with the Blackwell platform. It delivered 4x more performance than the previous generation.
This submission was also the first-ever MLPerf submission to use FP4 precision. Narrower precision formats, like FP4, reduces memory footprint and memory traffic, and also boost computational throughput. The process takes advantage of Blackwell’s second-generation Transformer Engine, and with advanced quantization techniques that are part of TensorRT Model Optimizer, the Blackwell submission met the strict accuracy targets of the MLPerf benchmark.
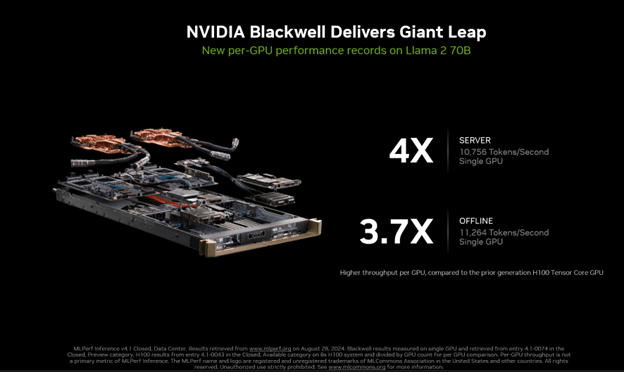
Improvements in Blackwell haven’t stopped the continued acceleration of Hopper. In the last year, Hopper performance has increased 3.4x in MLPerf on H100 thanks to regular software advancements. This means that NVIDIA’s peak performance today, on Blackwell, is 10x faster than it was just one year ago on Hopper.
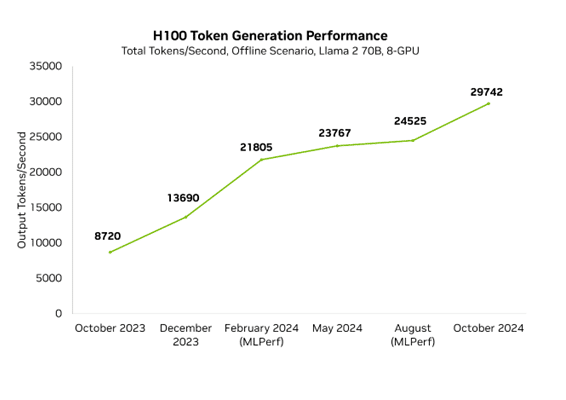
Our ongoing work is incorporated into TensorRT-LLM, a purpose-built library to accelerate LLMs that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM is built on top of the TensorRT Deep Learning Inference library and leverages much of TensorRT’s deep learning optimizations with additional LLM-specific improvements.
More recently, we’ve continued optimizing variants of Meta’s Llama models, including versions 3.1 and 3.2 as well as model sizes 70B and the biggest model, 405B. These optimizations include custom quantization recipes, as well as efficient use of parallelization techniques to more efficiently split the model across multiple GPUs, leveraging NVIDIA NVLink and NVSwitch interconnect technologies. Cutting-edge LLMs like Llama 3.1 405B are very demanding and require the combined performance of multiple state-of-the-art GPUs for fast responses.
Parallelism techniques require a hardware platform with a robust GPU-to-GPU interconnect fabric to get maximum performance and avoid communication bottlenecks. Each NVIDIA H200 Tensor Core GPU features fourth-generation NVLink, which provides a whopping 900GB/s of GPU-to-GPU bandwidth. Every eight-GPU HGX H200 platform also ships with four NVLink Switches, enabling every H200 GPU to communicate with any other H200 GPU at 900GB/s, simultaneously.
Many LLM deployments use parallelism over choosing to keep the workload on a single GPU, which can have compute bottlenecks. LLMs seek to balance low latency and high throughput, with the optimal parallelization technique depending on application requirements.
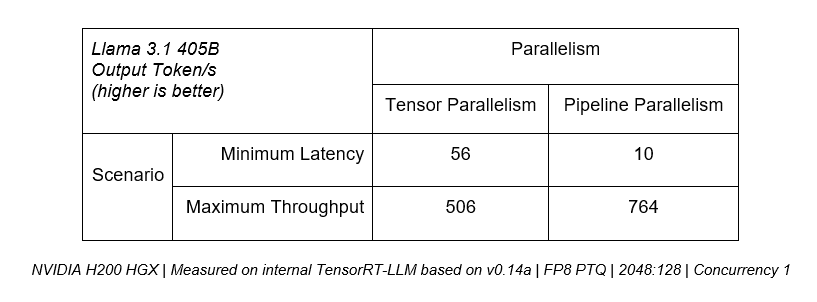
For instance, if lowest latency is the priority, tensor parallelism is critical, as the combined compute performance of multiple GPUs can be used to serve tokens to users more quickly. However, for use cases where peak throughput across all users is prioritized, pipeline parallelism can efficiently boost overall server throughput.
The table below shows that tensor parallelism can deliver over 5x more throughput in minimum latency scenarios, whereas pipeline parallelism brings 50% more performance for maximum throughput use cases.
For production deployments that seek to maximize throughput within a given latency budget, a platform needs to provide the ability to effectively combine both techniques like in TensorRT-LLM.
Read the technical blog on boosting Llama 3.1 405B throughput to learn more about these techniques.
Over the lifecycle of our architectures, we deliver significant performance gains from ongoing software tuning and optimization. These improvements translate into additional value for customers who train and deploy on our platforms. They’re able to create more capable models and applications and deploy their existing models using less infrastructure, enhancing their ROI.
As new LLMs and other generative AI models continue to come to market, NVIDIA will continue to run them optimally on its platforms and make them easier to deploy with technologies like NIM microservices and NIM Agent Blueprints.
Learn more with these resources:

Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and showcases new hardware, software, tools and accelerations for GeForce RTX PC and NVIDIA RTX workstation users.
Image generation models — a popular subset of generative AI — can parse and understand written language, then translate words into images in almost any style.
Representing the cutting edge of what’s possible in image generation, a new series of models from Black Forest Labs — now available to try on PC and workstations — run fastest on GeForce RTX and NVIDIA RTX GPUs.
FLUX.1 AI is a text-to-image generation model suite developed by Black Forest Labs. The models are built on the diffusion transformer (DiT) architecture, which allows models with a high number of parameters to maintain efficiency. The Flux models are trained on 12 billion parameters for high-quality image generation.
DiT models are efficient and computationally intensive — and NVIDIA RTX GPUs are essential for handling these new models, the largest of which can’t run on non-RTX GPUs without significant tweaking. Flux models now support the NVIDIA TensorRT software development kit, which improves their performance up to 20%. Users can try Flux and other models with TensorRT in ComfyUI.

FLUX.1 excels in generating high-quality, diverse images with exceptional prompt adherence, which refers to how accurately the AI interprets and executes instructions. High prompt adherence means the generated image closely matches the text prompt’s described elements, style and mood. Low prompt adherence results in images that may partially or completely deviate from given instructions.
FLUX.1 is noted for its ability to render the human anatomy accurately, including for challenging, intricate features like hands and faces. FLUX.1 also significantly improves the generation of legible text within images, addressing another common challenge in text-to-image models. This makes FLUX.1 models suitable for applications that require precise text representation, such as promotional materials and book covers.
FLUX.AI is available in three variants, offering users choices to best fit their workflows without sacrificing quality:
The dev and schnell models are open source, and Black Forest Labs provides access to its weights on the popular platform Hugging Face. This encourages innovation and collaboration within the image generation community by allowing researchers and developers to build upon and enhance the models.
The Flux models’ dev and schnell variants were downloaded more than 2 million times on HuggingFace in less than three weeks since their launch.
Users have praised FLUX.1 for its abilities to produce visually stunning images with exceptional detail and realism, as well as to process complex prompts without requiring extensive parameter adjustments.


In addition, FLUX.1’s versatility in handling various artistic styles and efficiency in quickly generating images makes it a valuable tool for both personal and professional projects.
Users can access FLUX.1 using popular community webpages like ComfyUI. The community-run ComfyUI Wiki includes step-by-step instructions for getting started.
Many YouTube creators also offer video tutorials on Flux models, like this one from MDMZ:
Share your generated images on social media using the hashtag #fluxRTX for a chance to be featured on NVIDIA AI’s channels.
Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More

The award recognizes their work developing AlphaFold, a groundbreaking AI system that predicts the 3D structure of proteins from their amino acid sequences.Read More