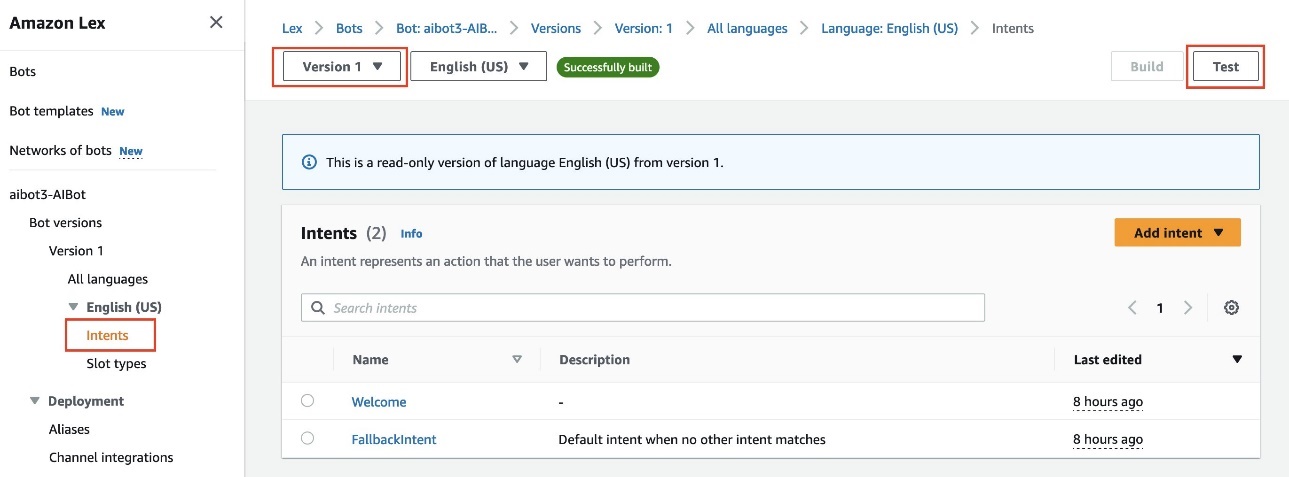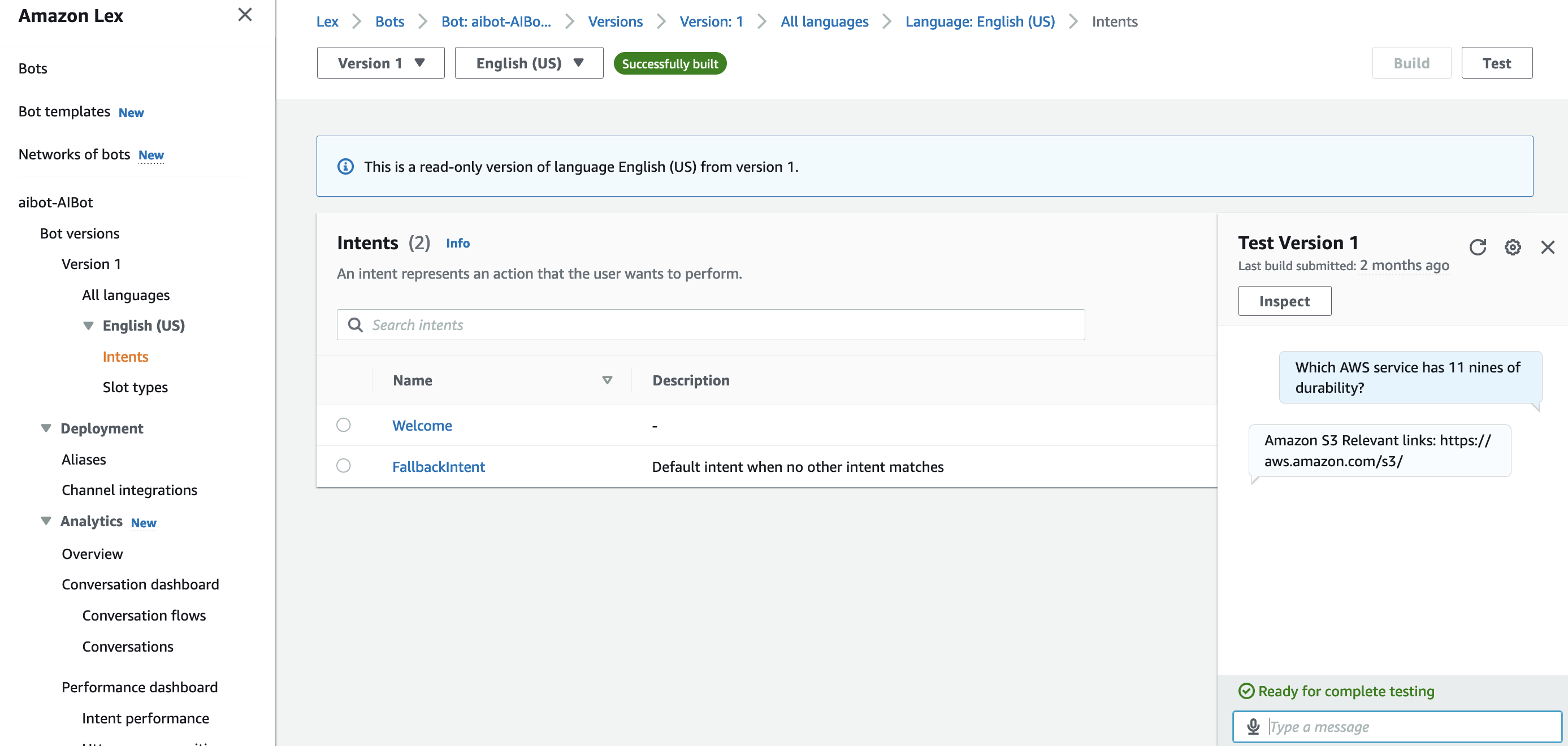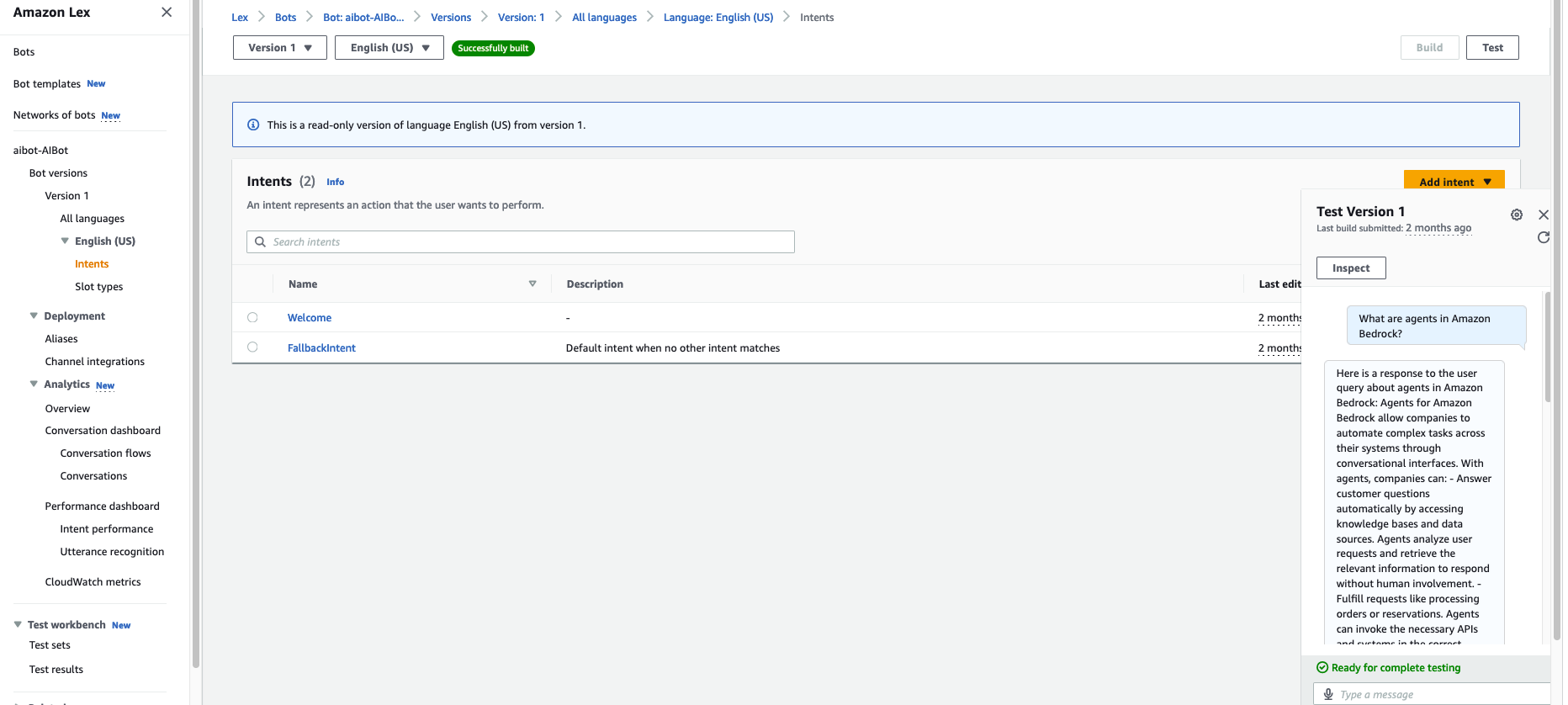
The U.S. healthcare system is adopting digital health agents to harness AI across the board, from research laboratories to clinical settings.
The latest AI-accelerated tools — on display at the NVIDIA AI Summit taking place this week in Washington, D.C. — include NVIDIA NIM, a collection of cloud-native microservices that support AI model deployment and execution, and NVIDIA NIM Agent Blueprints, a catalog of pretrained, customizable workflows.
These technologies are already in use in the public sector to advance the analysis of medical images, aid the search for new therapeutics and extract information from massive PDF databases containing text, tables and graphs.
For example, researchers at the National Cancer Institute, part of the National Institutes of Health (NIH), are using several AI models built with NVIDIA MONAI for medical imaging — including the VISTA-3D NIM foundation model for segmenting and annotating 3D CT images. A team at NIH’s National Center for Advancing Translational Sciences (NCATS) is using the NIM Agent Blueprint for generative AI-based virtual screening to reduce the time and cost of developing novel drug molecules.
With NVIDIA NIM and NIM Agent Blueprints, medical researchers across the public sector can jump-start their adoption of state-of-the-art, optimized AI models to accelerate their work. The pretrained models are customizable based on an organization’s own data and can be continually refined based on user feedback.
NIM microservices and NIM Agent Blueprints are available at ai.nvidia.com and accessible through a wide variety of cloud service providers, global system integrators and technology solutions providers.
Building With NIM Agent Blueprints
Dozens of NIM microservices and a growing set of NIM Agent Blueprints are available for developers to experience and download for free. They can be deployed in production with the NVIDIA AI Enterprise software platform.
- The blueprint for generative virtual screening for drug discovery brings together three NIM microservices to help researchers search and optimize libraries of small molecules to identify promising candidates that bind to a target protein.
- The multimodal PDF data extraction blueprint uses NVIDIA NeMo Retriever NIM microservices to extract insights from enterprise documents, helping developers build powerful AI agents and chatbots.
- The digital human blueprint supports the creation of interactive, AI-powered avatars for customer service. These avatars have potential applications in telehealth and nonclinical aspects of patient care, such as scheduling appointments, filling out intake forms and managing prescriptions.
Two new NIM microservices for drug discovery are now available on ai.nvidia.com to help researchers understand how proteins bind to target molecules, a crucial step in drug design. By conducting more of this preclinical research digitally, scientists can narrow down their pool of drug candidates before testing in the lab — making the discovery process more efficient and less expensive.
With the AlphaFold2-Multimer NIM microservice, researchers can accurately predict protein structure from their sequences in minutes, reducing the need for time-consuming tests in the lab. The RFdiffusion NIM microservice uses generative AI to design novel proteins that are promising drug candidates because they’re likely to bind with a target molecule.
NCATS Accelerates Drug Discovery Research
ASPIRE, a research laboratory at NCATS, is evaluating the NIM Agent Blueprint for virtual screening and is using RAPIDS, a suite of open-source software libraries for GPU-accelerated data science, to accelerate its drug discovery research. Using the cuGraph library for graph data analytics and cuDF library for accelerating data frames, the lab’s researchers can map chemical reactions across the vast unknown chemical space.
The NCATS informatics team reported that with NVIDIA AI, processes that used to take hours on CPU-based infrastructure are now done in seconds.
Massive quantities of healthcare data — including research papers, radiology reports and patient records — are unstructured and locked in PDF documents, making it difficult for researchers to quickly search for information.
The Genetic and Rare Diseases Information Center, also run by NCATS, is exploring using the PDF data extraction blueprint to develop generative AI tools that enhance the center’s ability to glean information from previously unsearchable databases. These tools will help answer questions from those affected by rare diseases.
“The center analyzes data sources spanning the National Library of Medicine, the Orphanet database and other institutes and centers within the NIH to answer patient questions,” said Sam Michael, chief information officer of NCATS. “AI-powered PDF data extraction can make it massively easier to extract valuable information from previously unsearchable databases.”
Mi-NIM-al Effort, Maximum Benefit: Getting Started With NIM
A growing number of startups, cloud service providers and global systems integrators include NVIDIA NIM microservices and NIM Agent Blueprints as part of their platforms and services, making it easy for federal healthcare researchers to get started.
Abridge, an NVIDIA Inception startup and NVentures portfolio company, was recently awarded a contract from the U.S. Department of Veterans Affairs to help transcribe and summarize clinical appointments, reducing the burden on doctors to document each patient interaction.
The company uses NVIDIA TensorRT-LLM to accelerate AI inference and NVIDIA Triton Inference Server for deploying its audio-to-text and content summarization models at scale, some of the same technologies that power NIM microservices.
The NIM Agent Blueprint for virtual screening is now available through AWS HealthOmics, a purpose-built service that helps customers orchestrate biological data analyses.
Amazon Web Services (AWS) is a partner of the NIH Science and Technology Research Infrastructure for Discovery, Experimentation, and Sustainability Initiative, aka STRIDES Initiative, which aims to modernize the biomedical research ecosystem by reducing economic and process barriers to accessing commercial cloud services. NVIDIA and AWS are collaborating to make NIM Agent Blueprints broadly accessible to the biomedical research community.
ConcertAI, another NVIDIA Inception member, is an oncology AI technology company focused on research and clinical standard-of-care solutions. The company is integrating NIM microservices, NVIDIA CUDA-X microservices and the NVIDIA NeMo platform into its suite of AI solutions for large-scale clinical data processing, multi-agent models and clinical foundation models.
NVIDIA NIM microservices are supporting ConcertAI’s high-performance, low-latency AI models through its CARA AI platform. Use cases include clinical trial design, optimization and patient matching — as well as solutions that can help boost the standard of care and augment clinical decision-making.
Global systems integrator Deloitte is bringing the NIM Agent Blueprint for virtual screening to its customers worldwide. With Deloitte Atlas AI, the company can help clients at federal health agencies easily use NIM to adopt and deploy the latest generative AI pipelines for drug discovery.
Experience NVIDIA NIM microservices and NIM Agent Blueprints today.
NVIDIA AI Summit Highlights Healthcare Innovation
At the NVIDIA AI Summit in Washington, NVIDIA leaders, customers and partners are presenting over 50 sessions highlighting impactful work in the public sector.
Register for a free virtual pass to hear how healthcare researchers are accelerating innovation with NVIDIA-powered AI in these sessions:
- Federal Healthcare Leadership Panel: The Growing Importance of AI to U.S. Government Health features leaders from NVIDIA, NIH, the U.S. Department of Health and Human Services and more.
- Boosting U.S. Innovation and Competitiveness in AI-Enabled Healthcare and Biology features Renee Wegrzyn, director of the Advanced Research Projects Agency for Health, and Rory Kelleher, global head of business development for life sciences at NVIDIA.
- Accelerated Computing Improves Translational Genomics Research features Justin Zook, coleader of the biomarker and genomic sciences group at the National Institute of Standards and Technology, and Laura Egolf, computational scientist at the National Cancer Institute’s Frederick National Laboratory for Cancer Research, discussing their use of NVIDIA Parabricks software for genomics research.
- Building a Specialized Interactive Foundation Model for 3D CT Segmentation features Baris Turkbey, senior clinician and head of MRI and Artificial Intelligence Resource in the National Cancer Institute’s Molecular Imaging Branch, and Pengfei Guo, applied research scientist at NVIDIA.
Watch the AI Summit special address by Bob Pette, vice president of enterprise platforms at NVIDIA:
See notice regarding software product information.